一、下载selenium
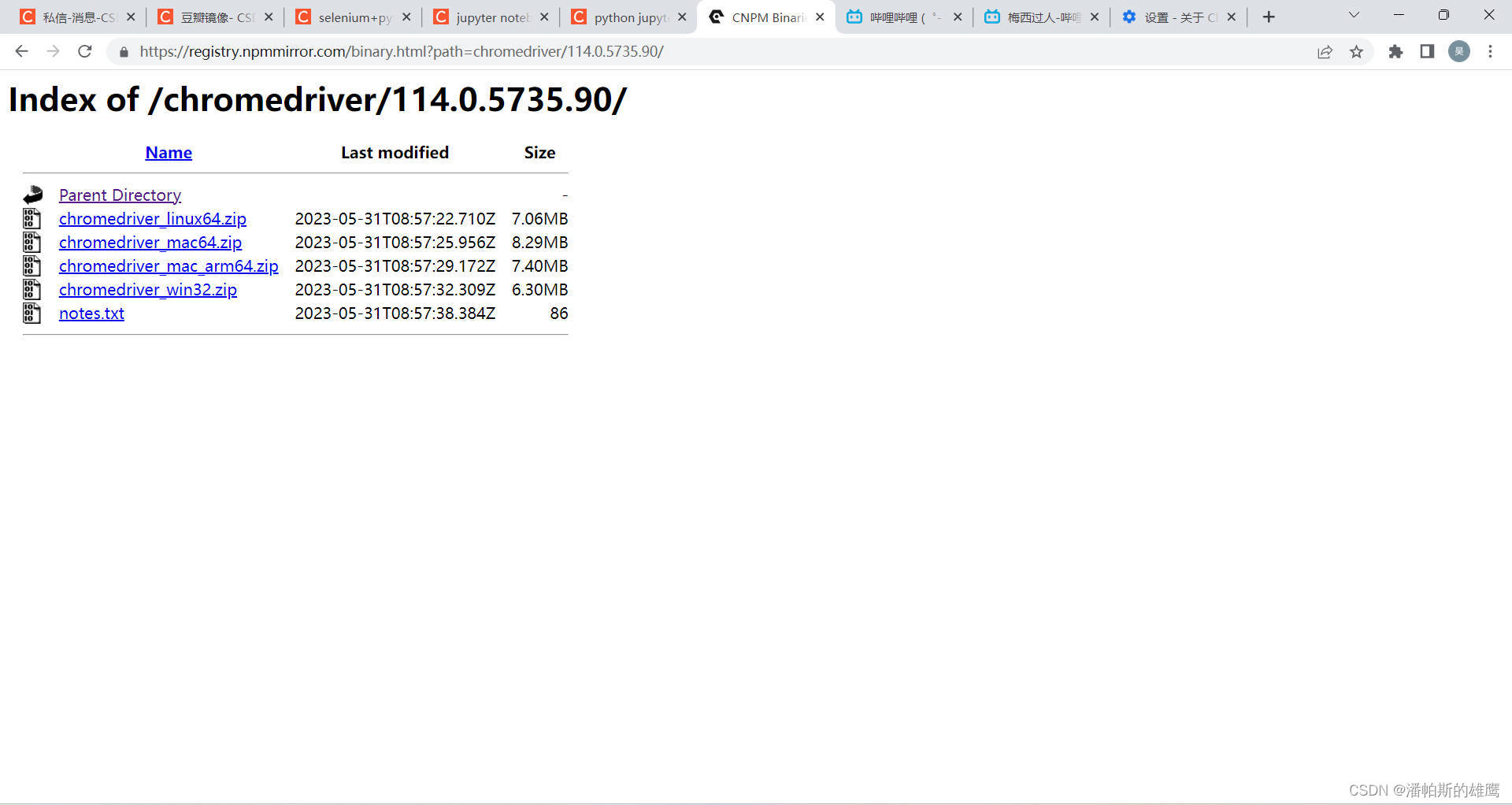
1. 下载对应版本的浏览器驱动

2. 安装selenium

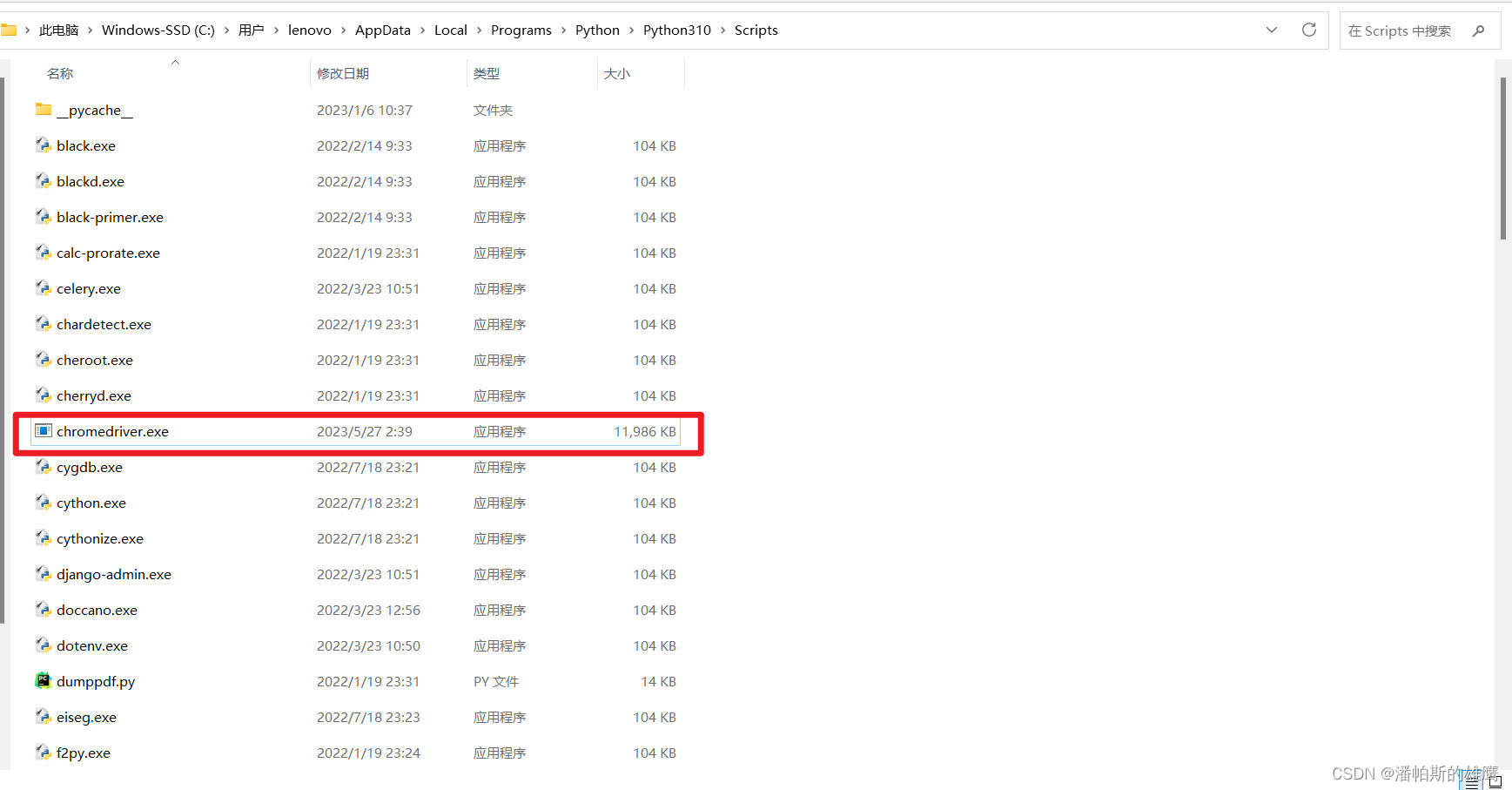
3.把浏览器驱动放到使用的python内核的script目录中
 二、测试效果模拟登录b站
二、测试效果模拟登录b站
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome() # 打开浏览器
url='https://search.bilibili.com/all?keyword=%E6%A2%85%E8%A5%BF%E8%BF%87%E4%BA%BA&from_source=webtop_search&spm_id_from=333.1007&search_source=5'#以该链接为例
browser.get(url)#访问相对应链接
time.sleep(5)
browser.quit()#关闭浏览器
三、登录账号
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
import json
browser = webdriver.Chrome()
browser.get('https://www.bilibili.com')
browser.delete_all_cookies()#先删除cookies
time.sleep(30)#这个时间用于手动登录,扫码登录可以适当缩短这个等待时间
dictcookies = browser.get_cookies()#读取登录之后浏览器的cookies
jsoncookies = json.dumps(dictcookies)#将字典数据转成json数据便于保存
with open('我的b站cookies.txt','w') as f:#写进文本保存
f.write(jsoncookies)
print("well done")
browser.quit()四、登录账号+开始爬取
注意每个cookies只能使用一段时间,所以要每次都要重新执行下登录账号这两段代码
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import StaleElementReferenceException
import time
browser = webdriver.Chrome()
browser.get('https://www.bilibili.com')
f = open('我的b站cookies.txt','r')
listcookie = json.loads(f.read())#读取文件中的cookies数据
for cookie in listcookie:
browser.add_cookie(cookie)#将cookies数据添加到浏览器
browser.refresh()#刷新网页
# 搜索关键词并进入该页面
search_box = browser.find_element(By.CLASS_NAME, "nav-search-input")
search_box.send_keys("梅西过人")
search_box.send_keys(Keys.ENTER)
# 获取所有窗口的句柄(可以理解为每个打开过的窗口的顺序)
handles = browser.window_handles
# 把窗口句柄切换到第二个窗口的,即搜索的结果页面,用于爬取
browser.switch_to.window(handles[1])
titles = browser.find_elements(By.TAG_NAME,'h3')
with open("b站梅西过人视频标题.txt", 'a', encoding='utf-8') as f:
for title in titles:
f.write(title.text + "\n")
i = 2
while True:
# 滑动页面的操作
document = browser.execute_script('return document.body.scrollHeight;') # 滑动之前的页面高度
time.sleep(2)
browser.execute_script(f'window.scrollTo(0,{document})') # 滑动页面
time.sleep(2)
document2 = browser.execute_script('return document.body.scrollHeight;')# 滑动之后的页面高度
# 防止页面刷新元素id改变,多次执行代码
attempts = 0
while attempts < 2:
try:
a = browser.find_elements(By.CSS_SELECTOR, '.vui_pagenation--btns button')
a[-1].click() # 点击下一页
break
except StaleElementReferenceException:
attempts += 1
# 防止页面刷新元素id改变,多次执行代码
attempts = 0
while attempts < 2:
try:
titles = browser.find_elements(By.TAG_NAME,'h3')
with open("b站梅西过人视频标题.txt", 'a', encoding='utf-8') as f:
for title in titles:
content = title.text
f.write(content + "\n")
break
except StaleElementReferenceException:
attempts += 1
time.sleep(2)
print(f"完成第{i}页标题爬取")
i += 1