循环链表的特点是无须增加存储量,仅对表的链接方式稍作改变,即可使得表处理更加方便灵活。
【例】在链表上实现将两个线性表(a1,a2,…,an)和(b1,b2,…,bm)连接成一个线性表(a1,…,an,b1,…bm)的运算。
分析:若在单链表或头指针表示的单循环表上做这种链接操作,都需要遍历第一个链表,找到结点an,然后将结点b1链到an的后面,其执行时间是O(n)。若在尾指针表示的单循环链表上实现,则只需修改指针,无须遍历,其执行时间是O(1)。
相应的算法如下:
LinkListConnect(LinkListA,LinkListB)
{//假设A,B为非空循环链表的尾指针
LinkListp=A->next;//①保存A表的头结点位置
A->next=B->next->next;//②B表的开始结点链接到A表尾
free(B->next);//③释放B表的头结点
B->next=p;//④
returnB;//返回新循环链表的尾指针
}
注意:
①循环链表中没有NULL指针。涉及遍历操作时,其终止条件就不再是像非循环链表那样判别p或p->next是否为空,而是判别它们是否等于某一指定指针,如头指针或尾指针等。
②在单链表中,从一已知结点出发,只能访问到该结点及其后续结点,无法找到该结点之前的其它结点。而在单循环链表中,从任一结点出发都可访问到表中所有结点,这一优点使某些运算在单循环链表上易于实现。今天我们学习单循环链表
在学习单循环链表之前
我们可以对比之前学习的普通的单链表结构
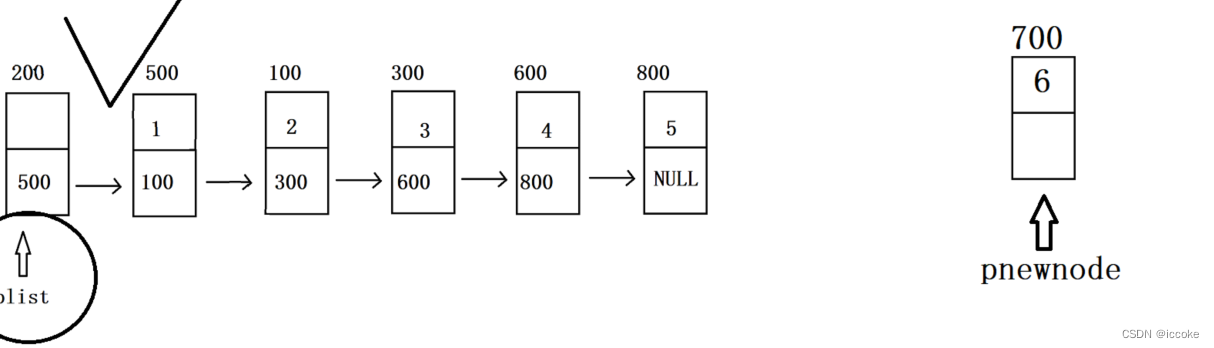
可以看到这里最后一个结点的next域为NULL
那么单循环链表相对比单链表就很简单
将最后一个结点的next域改变为头节点的地址
这样就 可以实现一种循环的概念
那么相比较于普通单链表的来说
单循环链表对比它的代码就改动比较少
我们可以 预测 在 尾插 尾删 此处有不同
接下来我们直接来进行单循环链表的构造
typedef int ELEM_TYPE;
typedef struct CNode
{
ELEM_TYPE data;//数据域
struct CNode *next;//指针域
}CNode, *PCNode;
/*
struct CNode
{
ELEM_TYPE data;//数据域
struct CNode *next;//指针域
};
typedef struct CNode CNode;
typedef struct CNode* PCNode;
*/
//可实现的操作:
//初始化
void Init_clist(struct CNode *pclist);
//头插
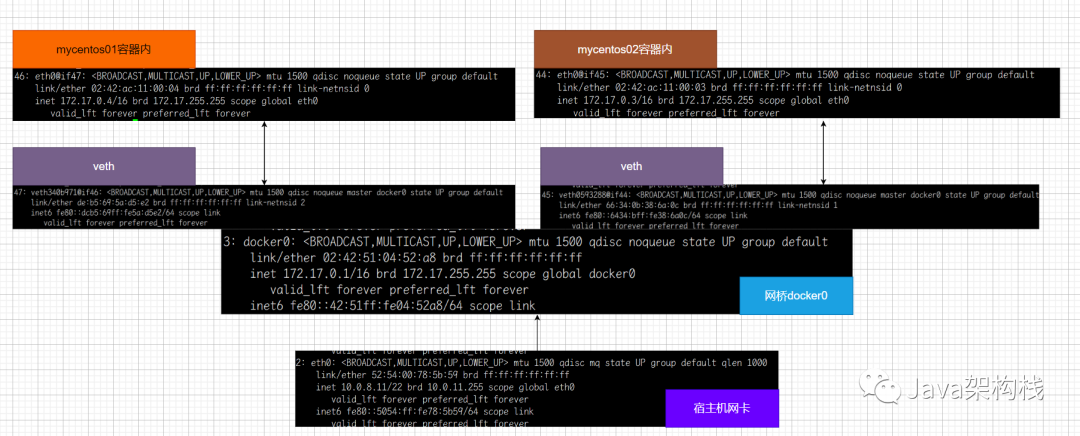
bool Insert_head(PCNode pclist, ELEM_TYPE val);
//尾插
bool Insert_tail(PCNode pclist, ELEM_TYPE val);
//按位置插
bool Insert_pos(PCNode pclist, int pos, ELEM_TYPE val);
//头删
bool Del_head(PCNode pclist);
//尾删
bool Del_tail(PCNode pclist);
//按位置删
bool Del_pos(PCNode pclist, int pos);
//按值删
bool Del_val(PCNode pclist, ELEM_TYPE val);
//查找 //查找到,返回的是查找到的这个节点的地址
struct CNode *Search(PCNode pclist, ELEM_TYPE val);
//获取有效值个数
int Get_length(PCNode pclist);
//判空
bool IsEmpty(PCNode pclist);
//清空
void Clear(PCNode pclist);
//销毁1 无限头删
void Destroy1(PCNode pclist);
//销毁2 不借助头结点,有两个辅助指针
void Destroy2(PCNode pclist);
//打印
void Show(PCNode pclist);
可以看到这个单循环链表的结构体涉及以及实现代码与单链表基本类似
具体可以参考我上一文实现的单链表
基础数据结构链表_iccoke的博客-CSDN博客
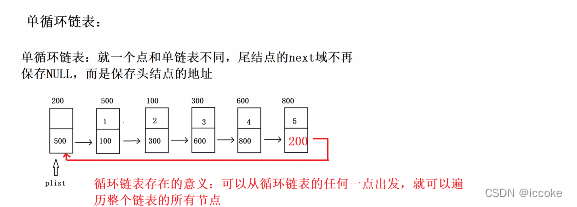
这就是和普通单链表唯一不同的地方
我们直接给出单循环链表的实现
重点关注关于尾部的函数操作 其他的函数和普通单链表几乎是相同的
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#include "clist.h"
//可实现的操作:
//初始化
void Init_clist(struct CNode *pclist)
{
//0.安全性处理
assert(pclist != NULL);
//1.对pclist指向的头结点里面的成员进行赋值:
//头结点的数据域不使用,只需要对指针域赋值即可,赋值为自身地址
pclist->next = pclist;
}
//头插
bool Insert_head(PCNode pclist, ELEM_TYPE val)
{
assert(pclist != NULL);//保证pclist这个指针 指向的单循环链表的头结点 确确实实存在
struct CNode *pnewnode = (struct CNode *)malloc(1 * sizeof(struct CNode));
assert(pnewnode != NULL);
pnewnode->data = val; //-> ==(*).
//合适的插入位置不用找,因为头插就是在头结点后面插,所以使用pclist即可
pnewnode->next = pclist->next;
pclist->next = pnewnode;
return true;
}
//尾插
bool Insert_tail(PCNode pclist, ELEM_TYPE val)
{
//0.安全性处理
assert(pclist != NULL);
//1.购买新节点
struct CNode *pnewnode = (struct CNode *)malloc(1 * sizeof(struct CNode));
assert(pnewnode != NULL);
pnewnode->data = val;
//2.找到合适的插入位置(也就是说找到在哪一个节点后面插入)
//尾插,找尾结点,用指针p指向
//通过判断,确实使用需要前驱的for循环,也就是说,申请一个临时指针p,执行头结点
struct CNode *p = pclist;
for(; p->next!=pclist; p=p->next);
//此时,for循环,跑完,p指向尾结点
//3.插入即可
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}
//按位置插
bool Insert_pos(PCNode pclist, int pos, ELEM_TYPE val)
{
//0.安全性处理
assert(pclist != NULL);
assert(pos>=0 && pos<=Get_length(pclist));
//1.购买新节点
struct CNode *pnewnode = (struct CNode *)malloc(1 * sizeof(struct CNode));
assert(pnewnode != NULL);
pnewnode->data = val;
//2.找到合适的插入位置(也就是说找到在哪一个节点后面插入)
struct CNode * p = pclist; //判断这个是插入函数,需要使用带前驱的for循环
for(int i=0; i<pos; i++)
{
p=p->next;
}
//3.插入即可
pnewnode->next = p->next;
p->next = pnewnode;
return true;
}
//头删
bool Del_head(PCNode pclist)
{
//0:安全性处理
assert(pclist != NULL);
if(IsEmpty(pclist))
{
return false;
}//确保至少存在一个有效节点
//1.找到待删除节点,用指针p指向(头删的话,待删除节点就是第一个有效节点)
struct CNode *p = pclist->next;
//2.找到待删除节点的前驱,用指针q指向
//这里不用处理,因为这里pclist就可以代替q
//3.跨越指向+释放
pclist->next = p->next;
free(p);
return true;
}
//尾删
bool Del_tail(PCNode pclist)
{
assert(pclist != NULL);//保证pclist这个指针 指向的单循环链表的头结点 确确实实存在
if(IsEmpty(pclist))//保证pclist指向的这个头结点 后边存在有效节点
{
return false;
}
struct CNode *p = pclist;
for( ; p->next!=pclist; p=p->next);
struct CNode *q = pclist;
for(; q->next!=p; q=q->next);
q->next = p->next;
free(p);
return true;
}
//按位置删
bool Del_pos(PCNode pclist, int pos)
{
//0.assert pclist
assert(pos >=0 && pos<Get_length(pclist));
if(IsEmpty(pclist))//保证pclist指向的这个头结点 后边存在有效节点
{
return false;
}
//1.先找q 从头结点开始出发,向后走pos步
struct CNode *q = pclist;
for(int i=0; i<pos; ++i)
{
q = q->next;
}
//这时q就为
//2.再找p
struct CNode *p = q->next;
//3.跨越指向+释放
q->next = p->next;
free(p);
return true;
}
//按值删
bool Del_val(PCNode pclist, ELEM_TYPE val)
{
//0.安全性处理
//1.先需要判断val值,是否存在于单循环链表中
struct CNode*p = Search(pclist, val);
//2.若存在,则删除,若不存在,则return false
if(p == NULL)
{
return false;
}
//反之,找到val这个待删除节点了,且现在由指针p指针
//3.找带删除节点的上一个节点,用指针q指向
struct CNode *q = pclist;
for(; q->next!=p; q=q->next);
//4.跨越指向+释放
q->next = p->next;
free(p);
return true;
}
//查找 //查找到,返回的是查找到的这个节点的地址
struct CNode *Search(PCNode pclist, ELEM_TYPE val)
{
//assert pclist
//将单循环链表遍历一遍即可,对每一个有效节点都判断一次
struct CNode *p = pclist->next;
for(; p!=pclist; p=p->next)
{
if(p->data == val)
{
return p;
}
}
return NULL;
}
//获取有效值个数
int Get_length(PCNode pclist)
{
//assert pclist
//将单循环链表遍历一遍即可,对每一个有效节点都判断一次
int count = 0;//有效值个数
struct CNode *p = pclist->next;
for(; p!=pclist; p=p->next)
{
count++;
}
return count;;
}
//判空
bool IsEmpty(PCNode pclist)
{
return pclist->next == pclist;
}
//清空
void Clear(PCNode pclist)
{
return Destroy1(pclist);
}
//销毁1 无限头删
void Destroy1(PCNode pclist)
{
while(pclist->next != pclist)
{
struct CNode *p = pclist->next;
pclist->next = p->next;
free(p);
}
}
//销毁2 不借助头结点,有两个辅助指针
void Destroy2(PCNode pclist)
{
assert(pclist != NULL);
if(IsEmpty(pclist)) //保证至少存在一个有效节点
{
return;
}
//如果在定义指针q的时候,直接赋值为p->next 则一定一定要保证指针p百分之百存在
struct CNode *p = pclist->next;
struct CNode *q = p->next;
//将头结点断开链接
pclist->next = pclist;
while(p!=pclist)
{
q = p->next;
free(p);
p = q;
}
}
//打印
void Show(PCNode pclist)
{
//判定使用不需要前驱的for循环
struct CNode *p = pclist->next;
for(; p!=pclist; p=p->next)
{
printf("%d ", p->data);
}
printf("\n");
}








![[附源码]Node.js计算机毕业设计电影售票管理系统Express](https://img-blog.csdnimg.cn/cebd50264dde49abb772efd0d12bfdb1.png)