APE是ICCV2023的一篇文章,也是我在这个领域里接触的第一篇文章,这里主要做一下记录。
论文链接:2304.01195.pdf (arxiv.org)
代码链接:yangyangyang127/APE: [ICCV 2023] Code for "Not All Features Matter: Enhancing Few-shot CLIP with Adaptive Prior Refinement" (github.com)
概述
对于多模态任务而言,大量数据的获得是耗费人力和物力的,因此few-shot的训练方式一直备受关注。目前已经证实了CLIP模型的超强性能,很多研究人员提出了基于CLIP的检测算法,然而多数都是在研究如何更好地利用CLIP提取出的features,本文则从“Not All Features Matter”的角度进行了新的探索,提出了一个Adaptive Prior rEfinement方法,用于处理特征中的冗余信息,除此之外还提出了无需训练的APE和需要训练的APE-T方法。
相关介绍
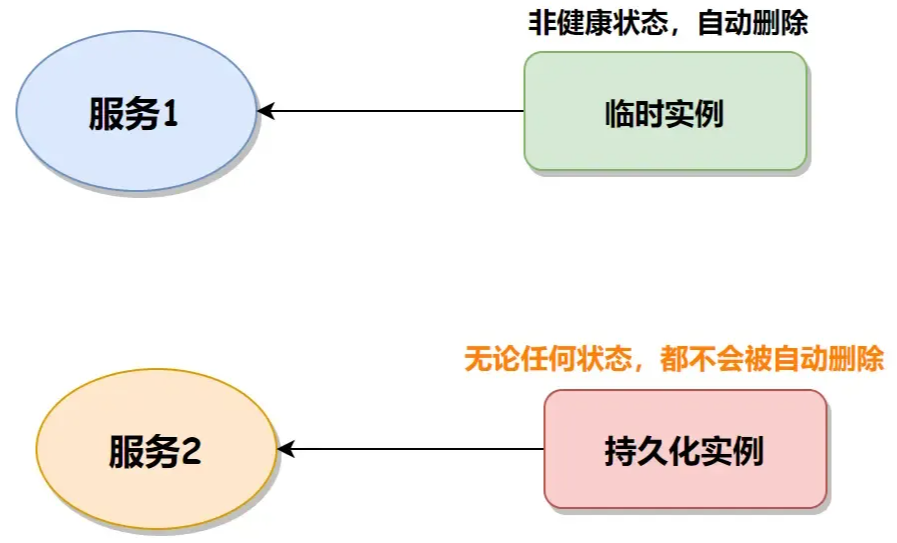
基于CLIP的few-shot的图像分类工作已经存在很多,大致可以分为两类——Non-prior Methods和Prior-based Methods。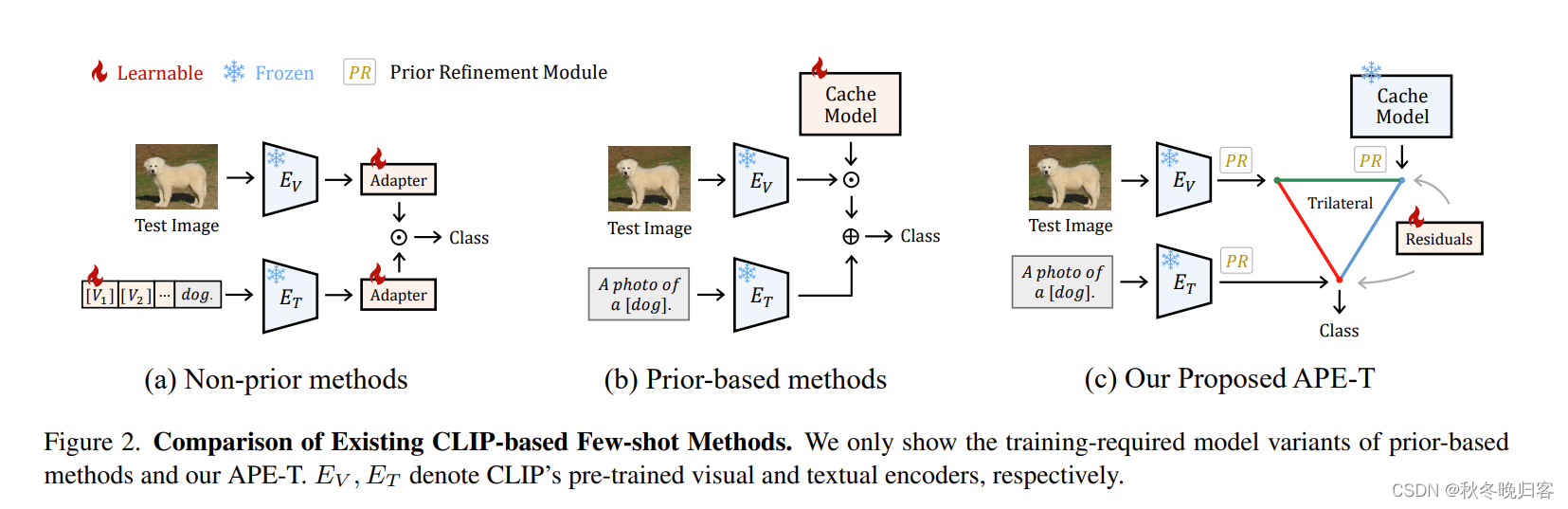
如上图所示,图(a)就是前者[CLIP-Adapter],这种方法随机初始化无CLIP先验的可学习模块,并在少量训练中进行优化。这种网络只引入了轻量级的可学习参数,但由于没有为附加模块明确考虑预训练的先验知识,因此其精度有限。图(b)为Prior-based Methods,基于先验的方法(Prior-based Methods)通过从少数镜头数据中提取clip提取的特征构建键值缓存模型,能够以不需要训练的方式进行识别,包括Tip-Adapter和Tip-X。他们可以进一步将缓存模型视为执行良好的初始化,并微调缓存键以获得更好的分类精度。这些基于先验的方法明确地将先验知识注入到训练过程中,但由于缓存大小大且可学习参数多,因此比较麻烦。而作者的想法就是将二者结合起来,提出了一个对the test image, the refined cache model, and the textual representations的三角关系进行探究的APE方法。
模型结构
Prior Refinement of CLIP
这个模块主要是通过提出的两个指标对特征进行去冗余操作,实现对不同的下游任务场景提取出重要的特征通道,从而改善特征质量。
Inter-class Similarity

如果直接按照上图计算,那么计算成本过大,由于预训练好的CLIP已经能够很好对视觉语言信息进行匹配,因此作者选择使用文本特征替代图像的计算。通过计算得到了特征通道之间的相似度,从而能够选择出相似度较小的一部分特征通道,作为重要信息。

Inter-class Variance
除了计算Inter-class Similarity,作者还引入了 Inter-class Variance用于提出差异度较大的一部分特征通道。

最后通过调节系数对二者进行调整,构成了文章所提出了Prior Refinement of CLIP。其实,可以看出这个操作和通道注意力存在类似的思想,都是在通道维度上进行信息加强,还有很多其他的工作也是基于了类似的思想,可以作为一个idea用于不同领域,值得借鉴。
Training-free APE
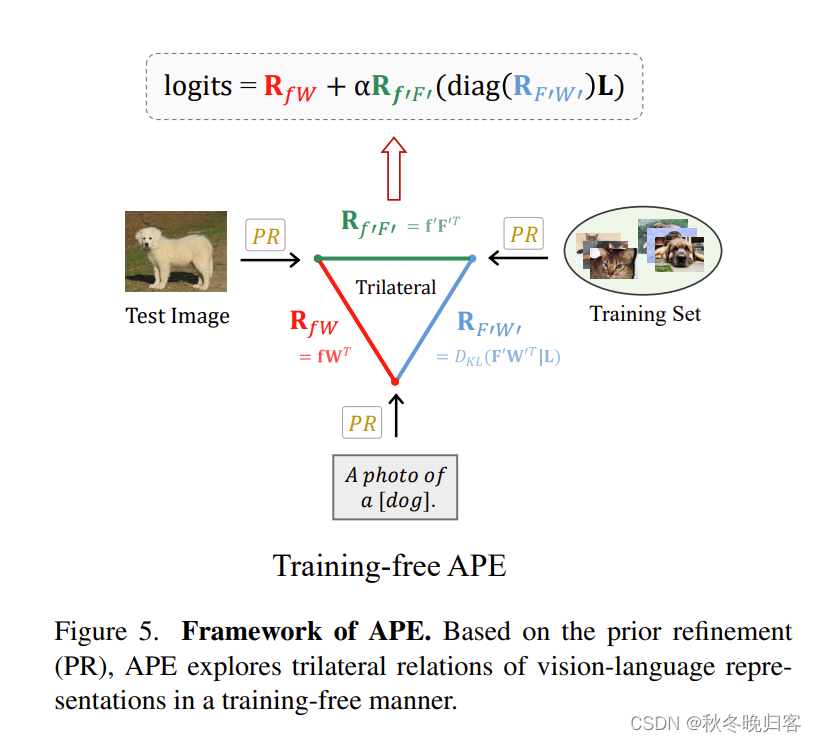
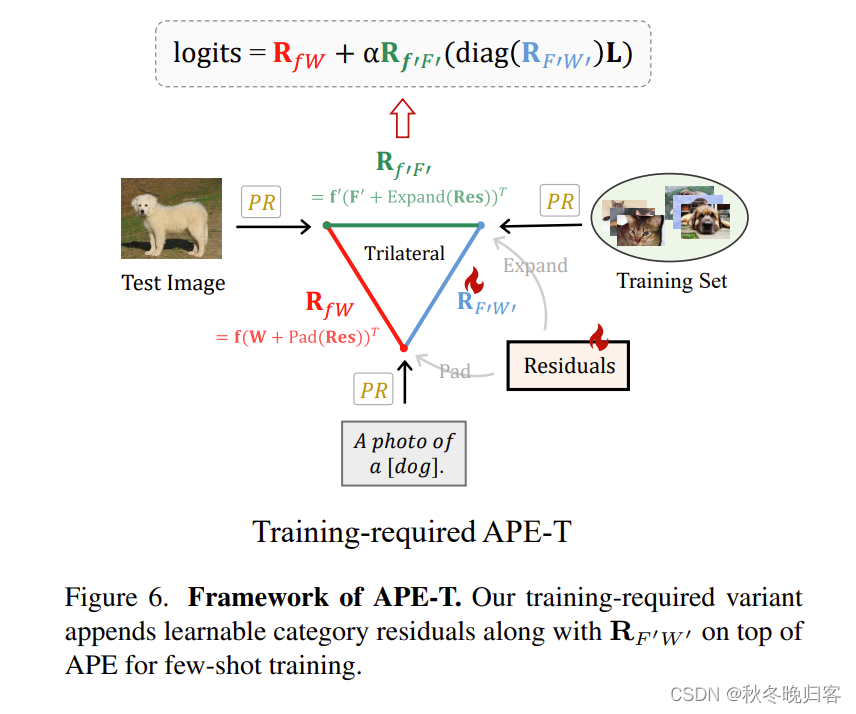
如上图所示,基于先验优化(PR), APE以无训练的方式探索了视觉语言表征的三边关系。

Training-required APE-T