什么是透视表?
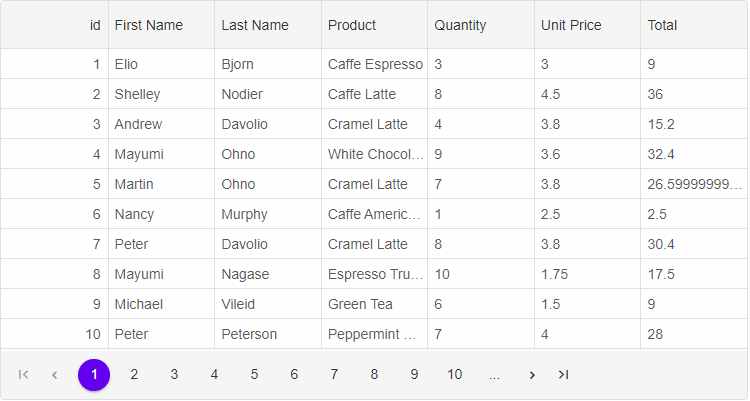
透视表是一种可以对数据动态排布并且分类汇总的表格格式,可以以多种方式和视角查看数据特征
Pandas库提供了一个名为pivot_table的函数,它将一个特性的值汇总在一个整洁的二维表中。
使用示例
pivot_table函数说明
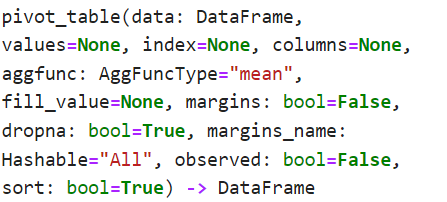
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc=’mean’, fill_value=None, margins=False, dropna=True, margins_name=’All’)
Parameters:
-
data : DataFrame
-
values : column to aggregate, optional
-
index: column, Grouper, array, or list of the previous
-
columns: column, Grouper, array, or list of the previous
-
aggfunc: function, list of functions, dict, default numpy.mean (If list of functions passed, the resulting pivot table will have hierarchical columns whose top level are the function names. If dict is passed, the key is column to aggregate and value is function or list of function)
-
fill_value[scalar, default None] : Value to replace missing values with 对缺失值的填充
-
margins[boolean, default False] : Add all row / columns (e.g. for subtotal / grand totals) 是否启用总计行/列
-
dropna[boolean, default True] : Do not include columns whose entries are all NaN 删除缺失
-
margins_name[string, default ‘All’] : Name of the row / column that will contain the totals when margins is True. 总计行/列的名称
-
Returns: DataFrame
代码示例
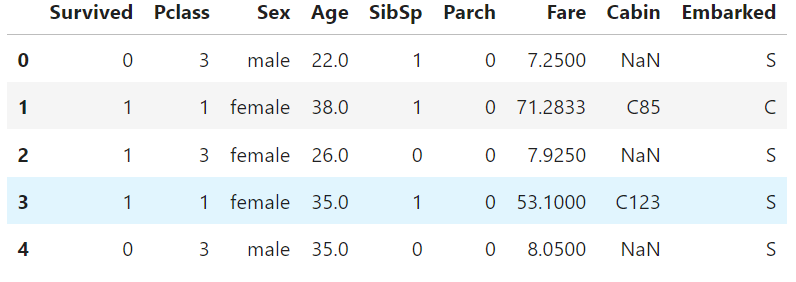
分析的数据使用Titanic 的训练数据集
导入数据并做基本处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.pylab import rcParams
rcParams['figure.figsize'] = 12,6
plt.style.use('ggplot')
df = pd.read_csv('data/titanic/train.csv') # reading data into dataframe
df.drop(['PassengerId','Ticket','Name'],axis=1,inplace=True)
df.head() # displaying first five values
在数据透视表中使用索引分组数据
table1 = pd.pivot_table(data=df.head(100),index=['Sex'],values=['Survived','Pclass','Age','SibSp','Parch','Fare'])
table1
table1.plot(kind='bar')
table2 = pd.pivot_table(df,index=['Sex','Pclass'],values=['Survived','Age','SibSp','Parch','Fare'],
margins=True,margins_name='汇总')
table2
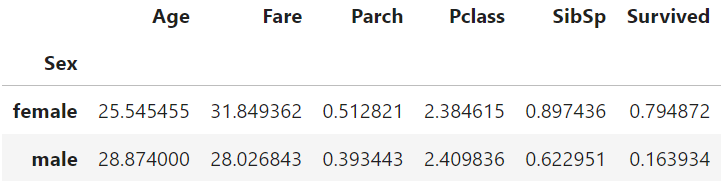
可以使用多个特性作为索引来对数据进行分组。这增加了结果表的粒度级别,这样可以获得更具体的发现:
使用数据集上的多个索引,可以一致认为,在泰坦尼克号的每个头等舱中,男女乘客的票价差异都是有效的。

针对不同的特征,使用不同的聚合函数
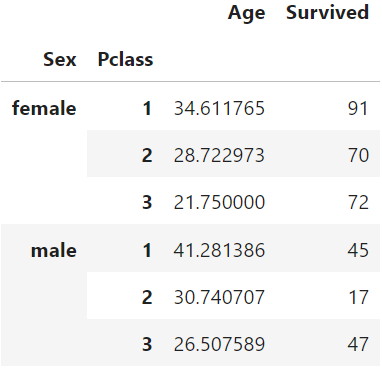
table3 = pd.pivot_table(df,index=['Sex','Pclass'],
aggfunc={'Age':np.mean,'Survived':np.sum})
table3
使用value参数聚合特定的特征
Values参数告诉函数在哪些特征上聚合。这是一个可选字段,如果你不指定这个值,那么函数将聚合数据集的所有数值特征:
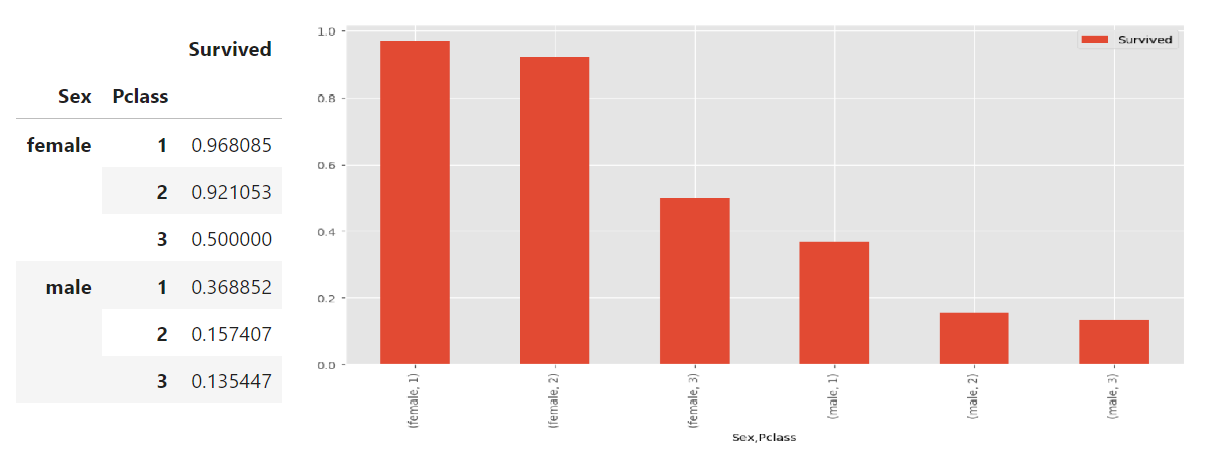
研究发现:泰坦尼克号上乘客的存活率随着等级Pclass的降低而降低。此外,在任何给定的p舱位中,男性乘客的存活率都低于女性乘客。
table4 = pd.pivot_table(df,index=['Sex','Pclass'],
values=['Survived'],
aggfunc=np.mean)
table4
table4.plot(kind='bar');
使用columns参数的特征之间的关系
Columns参数是可选的,它在结果表的顶部水平显示这些值。
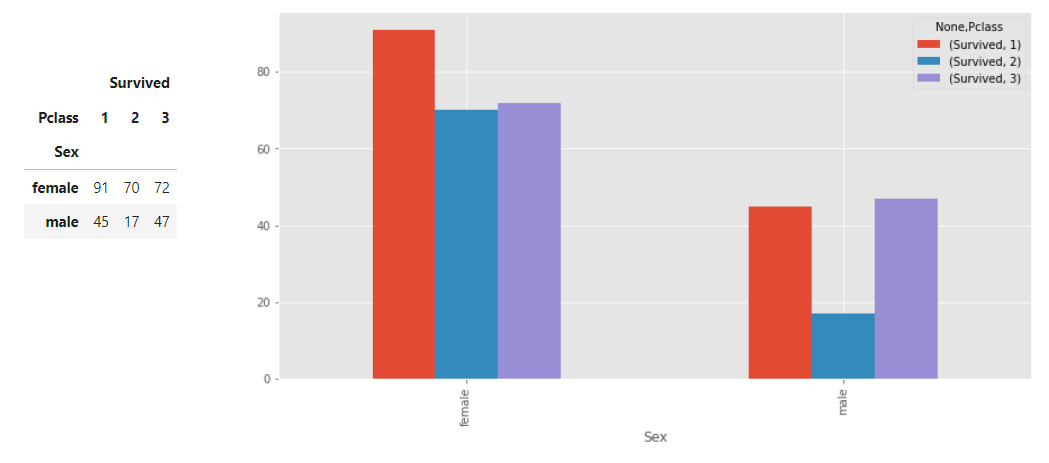
table5 = pd.pivot_table(df,index=['Sex'],
columns=['Pclass'],
values=['Survived'],
aggfunc=np.sum)
table5
table5.plot(kind='bar');
处理丢失的数据
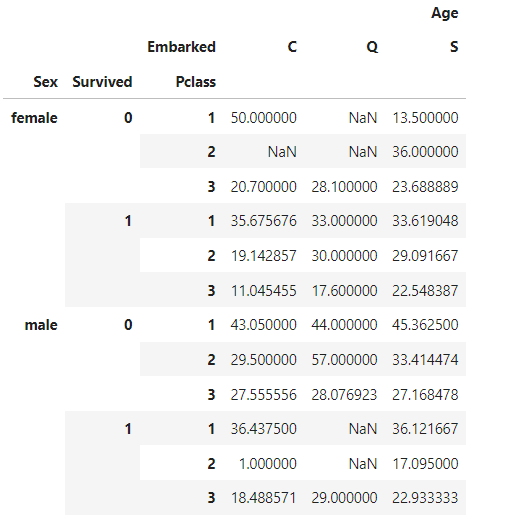
table6 = pd.pivot_table(df,index=['Sex','Survived','Pclass'],
columns=['Embarked'],
values=['Age'],
aggfunc=np.mean)
table6
## 用' Age '列的平均值替换NaN值:
table7 = pd.pivot_table(df,index=['Sex','Survived','Pclass'],
columns=['Embarked'],
values=['Age'],
aggfunc=np.mean,
fill_value=np.mean(df['Age']))
table7
## 用固定的值-1替换NaN值:
table7 = pd.pivot_table(df,index=['Sex','Survived','Pclass'],
columns=['Embarked'],
values=['Age'],
aggfunc=np.mean,
fill_value=-1)
table7