1. 分布式系统CAP原理
CAP原理:指在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partitontolerance(分区容忍性),三者不可得兼。
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。简单说就是所有节点在同一时刻的数据完全一致,这就意味着节点越多数据同步的时候消耗时间越多。
可用性(A):负载过大后,集群整体是否还能响应用户正常的读写请求。简单说就是项目系统对于用户请求的响应时间一定在能接受的范围内,需要照顾用户体验。
分区容忍性(P):分区容忍性,就是高可用性,一个节点崩了不会影响其他节点。简单说就是服务器节点崩了几个没事,只要有正常的服务器就可以,意思是节点越多就越好了。
2. 一致性
◦ 强一致性:数据库一致性,牺牲了性能
◦ 弱一致性:数据库和缓存,延迟双删、重试
◦ 单调读一致性:缓存一致性,ID或者IP哈希
◦ 最终一致性:边缘业务,消息队列
业内常用解决方案:
XA方案:
2PC协议:两阶段提交协议,P是指准备阶段,C是指提交阶段
• 准备阶段:询问是否可以开始,写Undo、Redo日志,收到响应
• 提交阶段:执行Redo日志进行Commit,执行Undo日志进行Rollback
3PC协议:将提交阶段分为CanCommit、PreCommit、DoCommit三个阶段
CanCommit:发送canCommit请求,并开始等待
PreCommit:收到全部Yes,写Undo、Redo日志。超时或者No,则中断
DoCommit:执行Redo日志进行Commit,执行Undo日志进行Rollback
区别是第二步,参与者自身增加了超时,如果失败可以及时释放资源
3.Paxos算法
4.ZAB算法
Raft 是一种为了管理复制日志的一致性算法
Raft使用心跳机制来触发选举。当server启动时,初始状态都是follower。每一个server都有一个定时器,超时时间为election timeout(一般为150-300ms),如果某server没有超时的情况下收到来自领导者或者候选者的任何消息,定时器重启,如果超时,它就开始一次选举。
Leader异常:异常期间Follower会超时选举,完成后Leader比较彼此步长
Follower异常:恢复后直接同步至Leader当前状态
多个Candidate:选举时失败,失败后超时继续选举
5.分布式事务
XA方案
两阶段提交 | 三阶段提交
• 准备阶段的资源锁定,存在性能问题,严重时会造成死锁问题
• 提交事务请求后,出现网络异常,部分数据收到并执行,会造成一致性问
TCC方案
Try Confirm Cancel / 短事务
• Try 阶段:这个阶段说的是对各个服务的资源做检测以及对资源进行锁定或者预留
• Confirm 阶段:这个阶段说的是在各个服务中执行实际的操作
• Cancel 阶段:如果任何一个服务的业务方法执行出错,那么就需要进行补偿/回滚
MQ最终一致性
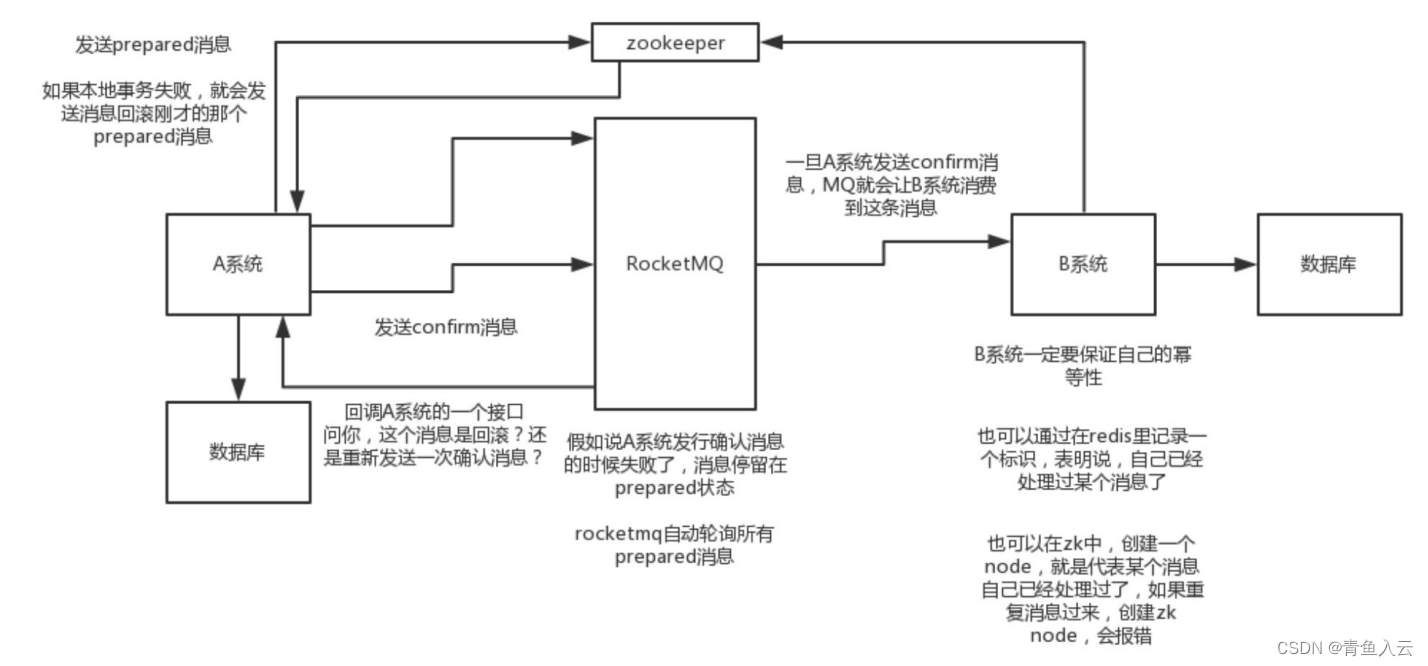
比如阿里的 RocketMQ 就支持消息事务(核心:双端确认,重试幂等)
- A(订单) 系统先发送一个 prepared 消息到 mq,prepared 消息发送失败则取消操作不执行了
- 发送成功后,那么执行本地事务,执行成功和和失败发送确认和回滚消息到mq
- 如果发送了确认消息,那么此时 B(仓储) 系统会接收到确认消息,然后执行本地的事务
- mq 会自动定时轮询所有 prepared 消息回调的接口,确认事务执行状态
- B 的事务失败后自动不断重试直到成功,达到一定次数后发送报警由人工来手工回滚和补偿
最大努力通知方案(订单 -> 积分)
- 系统 A 本地事务执行完之后,发送个消息到 MQ;
- 这里会有个专门消费 MQ 的最大努力通知服务,接着调用系统 B 的接口;
- 要是系统 B 执行失败了,就定时尝试重新调用系统 B,反复 N 次,最后还是不行就放弃




![[HDLBits] Exams/m2014 q4g](https://img-blog.csdnimg.cn/img_convert/f63e666da5a7a7ce032c242a744414ea.png)