前言
在我们的业务应用中越来越多的应用到编码内容,例如在 API 中,给到后端的 SQL 都是通过 Base64 加密的数据等等。
能够发现我们的代码中,使用的 window 对象上的 btoa 方法实现的 Base64 编码,那 btoa 具体是如何实现的呢?将在下面的内容中为大家讲解。
那我们就先从一些基础知识开始深入了解吧~
什么是编码
编码,是信息从一种形式转变为另一种形式的过程,简要来说就是语言的翻译。
将机器语言(二进制)转变为自然语言。
五花八门的编码
ASCII 码
ASCII 码是一种字符编码标准,用于将数字、字母和其他字符转换为计算机可以理解的二进制数。
它最初是由美国信息交换标准所制定的,它包含了 128 个字符,其中包括了数字、大小写字母、标点符号、控制字符等等。
在计算机中一个字节可以表示256众不同的状态,就对应256字符,从 00000000 到 11111111。ASCII 码一共规定了128字符,所以只需要占用一个字节的后面7位,最前面一位均为0,所以 ASCII 码对应的二进制位 00000000 到 01111111。

非 ASCII 码
当其他国家需要使用计算机显示的时候就无法使用 ASCII 码如此少量的映射方法。因此技术革新开始啦。
- GB2312
收录了6700+的汉字,使用两个字节作为编码字符集的空间 - GBK
GBK 在保证不和 GB2312/ASCII 冲突的情况下,使用两个字节的方式编码了更多的汉字,达到了2w - 等等
全面统一的 Unicode
面对五花八门的编码方式,同一个二进制数会被解释为不同的符号,如果使用错误的编码的方式去读区文件,就会出现乱码的问题。
那能否创建一种编码能够将所有的符号纳入其中,每一个符号都有唯一对应的编码,那么乱码问题就会消失。因此 Unicode 借此机会统一江湖。是由一个叫做 Unicode 联盟的官方组织在维护。
Unicode 最常用的就是使用两个字节来表示一个字符(如果是更为偏僻的字符,可能所需字节更多)。现代操作系统都直接支持 Unicode。
Unicode 和 ASCII 的区别
- ASCII 编码通常是一个字节,Unicode 编码通常是两个字节.
字母 A 用 ASCII 编码十进制为 65,二进制位 01000001;而在 Unicode 编码中,需要在前面全部补0,即为 00000000 01000001 - 问题产生了,虽然使用 Unicode 解决乱码的问题,但是为纯英文的情况,存储空间会大一倍,传输和存储都不划算。
问题对应的解决方案之UTF-8
UTF-8 全名为 8-bit Unicode Transformation Format
本着节约的精神,又出现了把 Unicode 编码转为可变长编码的 UTF-8。可以根据不同字符而变化字节长度,使用1~4字节表示一个符号。UTF-8 是 Unicode 的实现方式之一。
UTF-8 的编码规则
- 对于单字节的符号,字节的第一位设置为0,后面七位为该字符的 Unicode 码。因此对于英文字母,UTF-8 编码和 ASCII 编码是相同的。
- 对于 n 字节的符号,第一个字节的前 n 位都是1,第 n+1 位为0,后面的字节的前两位均为10。剩下的位所填充的二进制就是这个字符的 Unicode 码
对应的编码表格
| Unicode 符号范围 | UTF-8 编码方式 |
|---|---|
| 0000 0000-0000 007F (0-127) | 0xxxxxxx |
| 0000 0080-0000 07FF (128-2047) | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF (2048-65535) | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF (65536往上) | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxxx |
在 Unicode 对应表中查找到“杪”所在的位置,以及其对应的十六进制 676A,对应的十进制为 26474(110011101101010),对应三个字节 1110xxxx 10xxxxxx 10xxxxxx
将110011101101010的最后一个二进制依次填充到1110xxxx 10xxxxxx 10xxxxxx从后往前的 x ,多出的位补0即可,中,得到11100110 10011101 10101010 ,转换得到39a76a,即是杪字对应的 UTF-8 的编码

- >> 向右移动,前面补 0, 如 104 >> 2 即 01101000=> 00011010
- & 与运算,只有两个操作数相应的比特位都是 1 时,结果才为 1,否则为 0。如 104 & 3即 01101000 & 00000011 => 00000000,& 运算也用在取位时
- | 或运算,对于每一个比特位,当两个操作数相应的比特位至少有一个 1 时,结果为 1,否则为 0。如 01101000 | 00000011 => 01101011
function unicodeToByte(input) {
if (!input) return;
const byteArray = [];
for (let i = 0; i < input.length; i++) {
const code = input.charCodeAt(i); // 获取到当前字符的 Unicode 码
if (code < 127) {
byteArray.push(code);
} else if (code >= 128 && code < 2047) {
byteArray.push((code >> 6) | 192);
byteArray.push((code & 63) | 128);
} else if (code >= 2048 && code < 65535) {
byteArray.push((code >> 12) | 224);
byteArray.push(((code >> 6) & 63) | 128);
byteArray.push((code & 63) | 128);
}
}
return byteArray.map((item) => parseInt(item.toString(2)));
}
问题对应的解决方案之UTF-16
UTF-16 全名为 16-bit Unicode Transformation Format
在 Unicode 编码中,最常用的字符是0-65535,UTF-16 将0–65535范围内的字符编码成2个字节,超过这个的用4个字节编码
UTF-16 编码规则
- 对于 Unicode 码小于 0x10000 的字符, 使用2个字节存储,并且是直接存储 Unicode 码,不用进行编码转换
- 对于 Unicode 码在 0x10000 和 0x10FFFF 之间的字符,使用 4 个字节存储,这 4 个字节分成前后两部分,每个部分各两个字节,其中,前面两个字节的前 6 位二进制固定为 110110,后面两个字节的前 6 位二进制固定为 110111,前后部分各剩余 10 位二进制表示符号的 Unicode 码 减去 0x10000 的结果
- 大于 0x10FFFF 的 Unicode 码无法用 UTF-16 编码
对应的编码表格
| Unicode 符号范围 | 具体Unicode码 | UTF-16 编码方式 | 字节 |
|---|---|---|---|
| 0000 0000-0000 FFFF (0-65535) | xxxxxxxx xxxxxxxx | xxxxxxxx xxxxxxxx | 2字节 |
| 0001 0000-0010 FFFF (65536往上) | yy yyyyyyyy xx xxxxxxxx | 110110yy yyyyyyyy 110111xx xxxxxxxx | 4字节 |
“杪”字的 Unicode 码为 676A(26474),小于 65535,所以对应的 UTF-16 编码也为 676A
找一个大于 0x10000 的字符,0x1101F,进行 UTF-16 编码

字节序
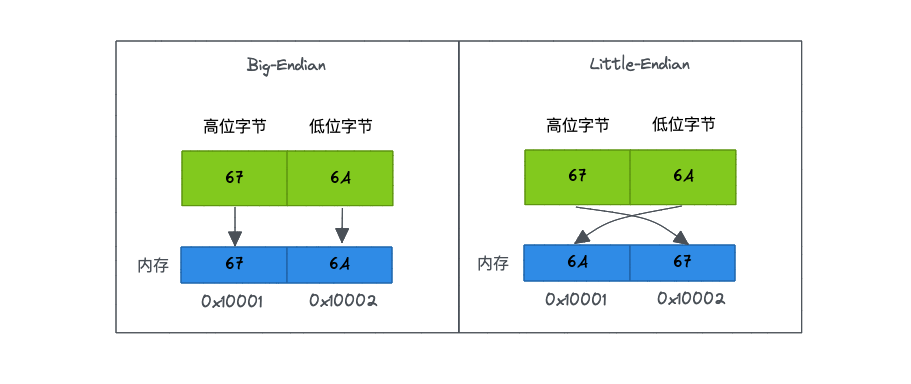
对于上述讲到的 UTF-16 来说,它存在一个字节序的概念。
字节序就是字节之间的顺序,当传输或者存储时,如果超过一个字节,需要指定字节间的顺序。
最小编码单元是多字节才会有字节序的问题存在,UTF-8 最小编码单元是一个字节,所以它是没有字节序的问题,UTF-16 最小编码单元是两个字节,在解析一个 UTF-16 字符之前,需要知道每个编码单元的字节序。
为什么会出现字节序?
计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以,计算机的内部处理都是小端字节序。但是,人类还是习惯读写大端字节序。
所以,除了计算机的内部处理,其他的场合比如网络传输和文件储存,几乎都是用的大端字节序。
正是因为这些原因才有了字节序。
比如:前面提到过,"杪"字的 Unicode 码是 676A,"橧"字的 Unicode 码是 6A67,当我们收到一个 UTF-16 字节流 676A 时,计算机如何识别它表示的是字符 "杪"还是 字符 "橧"呢 ?
对于多字节的编码单元需要有一个标识显式的告诉计算机,按着什么样的顺序解析字符,也就是字节序。
- 大端字节序(Big-Endian),表示高位字节在前面,低位字节在后面。高位字节保存在内存的低地址端,低位字节保存在在内存的高地址端。
- 小端字节序(Little-Endian),表示低位字节在前,高位字节在后面。高位字节保存在内存的高地址端,而低位字节保存在内存的低地址端。
简单聊聊 ArrayBuffer 和 TypedArray、DataView
ArrayBuffer
ArrayBuffer 是一段存储二进制的内存,是字节数组。
它不能够被直接读写,需要创建视图来对它进行操作,指定具体格式操作二进制数据。
可以通过它创建连续的内存区域,参数是内存大小(byte),默认初始值都是 0
TypedArray
ArrayBuffer 的一种操作视图,数据都存储到底层的 ArrayBuffer 中
const buf = new ArrayBuffer(8);
const int8Array = new Int8Array(buf);
int8Array[3] = 44;
const int16Array = new Int16Array(buf);
int16Array[0] = 42;
console.log(int16Array); // [42, 11264, 0, 0]
console.log(int8Array); // [42, 0, 0, 44, 0, 0, 0, 0]
使用 int8 和 int16 两种方式新建的视图是相互影响的,都是直接修改的底层 buffer 的数据
DataView
DataView 是另一种操作视图,并且支持设置字节序
const buf = new ArrayBuffer(24);
const dataview = new DataView(buf);
dataView.setInt16(1, 3000, true); // 小端序
明确电脑的字节序
上述讲到,在存储多字节的时候,我们会采用不同的字节序来做存储。那对我们的操作系统来说是有一种默认的字节序的。下面就用上述知识来明确 MacOS 的默认字节序。
function isLittleEndian() {
const buf = new ArrayBuffer(2);
const view = new Int8Array(buf);
view[0]=1;
view[1]=0;
console.log(view);
const int16Array = new Int16Array(buf);
return int16Array[0] === 1;
}
console.log(isLittleEndian());
通过上述代码我们可以得出此款 MacOS 是小端序列存储
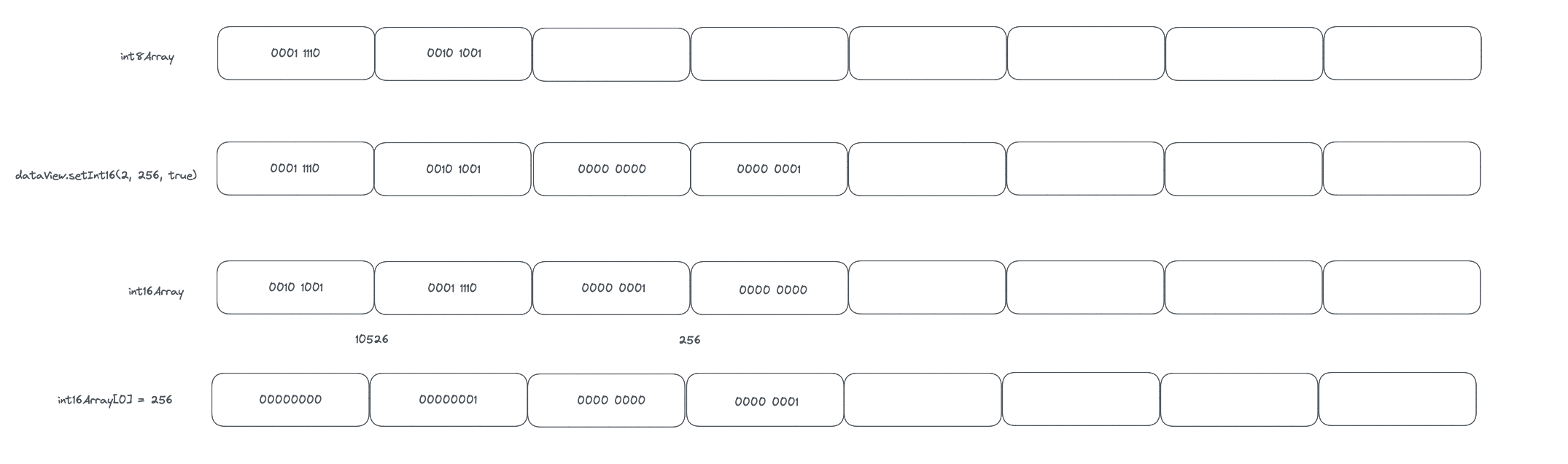
一个🌰,大家可以计算一下,是否真正明白了字节序
const buffer = new ArrayBuffer(8);
const int8Array = new Int8Array(buffer);
int8Array[0] = 30;
int8Array[1] = 41;
const dataView = new DataView(buffer);
dataView.setInt16(2, 256, true);
const int16Array = new Int16Array(buffer);
console.log(int16Array); // [10526, 256, 0, 0]
int16Array[0] = 256;
const int8Array1 = new Int8Array(buffer);
console.log(int8Array1);
虽然 TypedArray 无法指定字节序,但是在存储的时候采用操作系统默认的字节序。所以当我们设置 int16Array[0] = 256 时,内存中存储的为 00 01
Base64 编码解码
什么是 Base64
Base64 是一种基于64个字符来表示二进制数据的方式。
A-Z、a-z、0-9、+、/、= 65个字符组成,值得注意的是 = 用于补位操作
const _base64Str = 'ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=';
Base64 原理
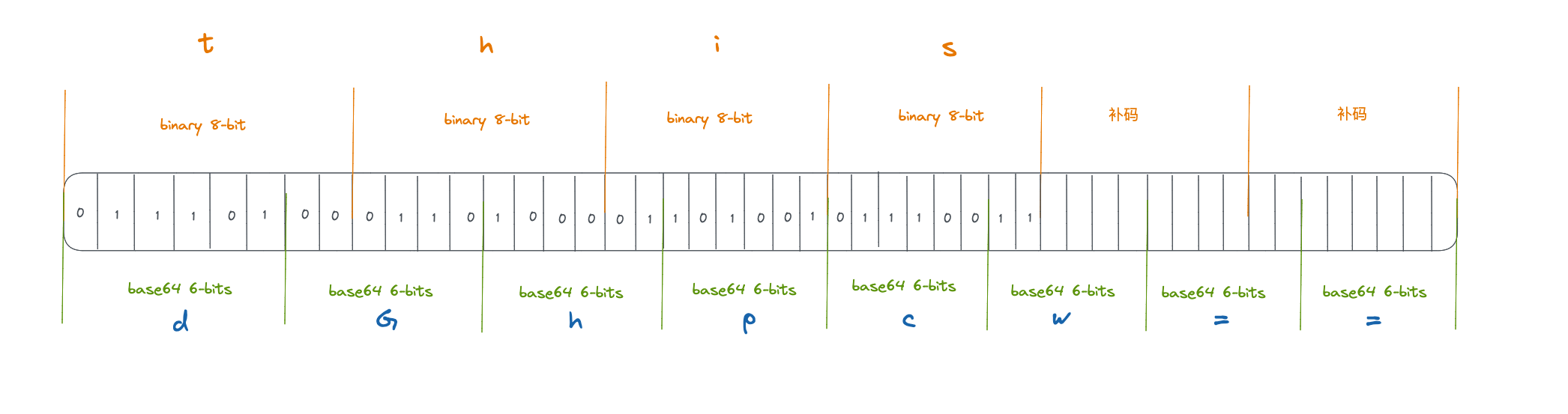
除去 = 这个补位符号,64个字符(即2^6),可表示二进制 000000 至111111共6个比特位,一个字节有8个比特位,因此可以推算出3个字节的数据需要用4个 Base64 字符表示
举个🌰,this 的 Base64 编码为 dGhpcw== ,具体编码如下
Base64 编码解码实现
在我们的项目中,实现 Base64 编码通常使用 btoa 和 atob 实现编码和解码,下面来尝试实现 btoa/atob
前置所需要了解函数
- 获取相应字符 ASCII 码方法 String.charCodeAt(index)
- 取得 Base64 对应的字符方法 String.charAt(index)
编码实现思路
- 三个字符分别为 char1/char2/char3,对应的 base64 字符为 encode1/encode2/encode3/encode4
- encode1 是 char1 取前六位,即 char1 右移2位,encode1 = char1 >> 2
- encode2 是 char1 后两位 + char2 前四位组成,encode2 = ((char1 & 3) << 4) | (char2 >> 4)
- encode3 是 char2 后四位 + char3 前两位组成,encode3 = ((char2 & 15) << 2) | (char3 >> 6)
- encode4 是 char3 的后六位,encode4 = char3 & 63
function encodeBase64(input) {
if (!input) return;
let base64String = "";
for (let i = 0; i < input.length; ) {
const char1 = input.charCodeAt(i++);
const encode1 = char1 >> 2;
const char2 = input.charCodeAt(i++);
const encode2 = ((char1 & 3) << 4) | (char2 >> 4);
const char3 = input.charCodeAt(i++);
let encode3 = ((char2 & 15) << 2) | (char3 >> 6);
let encode4 = char3 & 63;
if (Number.isNaN(char2)) encode3 = encode4 = 64;
if (Number.isNaN(char3)) encode4 = 64;
base64String +=
_base64Str.charAt(encode1) +
_base64Str.charAt(encode2) +
_base64Str.charAt(encode3) +
_base64Str.charAt(encode4);
}
return base64String;
}
解码实现思路
- base64 字符为 encode1/encode2/encode3/encode4,三个字符分别为 char1/char2/char3
- char1 是 encode1 + encode2 前两位,char1 = (encode1 << 2) | (encode2 >> 4)
- char2 是 encode2 后四位 + encode3 前四位,char2 = ((encode2 & 15) << 4) | (encode3 >> 2)
- char3 是 encode3 后两位 + encode4,char3 = ((encode3 & 3) << 6) | encode4
function decodeBase64(input) {
if (!input) return;
let output = "";
for (let i = 0; i < input.length; ) {
const encode1 = _base64Str.indexOf(input.charAt(i++));
const encode2 = _base64Str.indexOf(input.charAt(i++));
const encode3 = _base64Str.indexOf(input.charAt(i++));
const encode4 = _base64Str.indexOf(input.charAt(i++));
const char1 = (encode1 << 2) | (encode2 >> 4);
const char2 = ((encode2 & 15) << 4) | (encode3 >> 2);
const char3 = ((encode3 & 3) << 6) | encode4;
output += String.fromCharCode(char1);
if (encode3 != 64) {
output += String.fromCharCode(char2);
}
if (encode4 != 64) {
output += String.fromCharCode(char3);
}
}
return output;
}
一些问题
当我们使用上述代码去编码中文的时候,就能够发现一些问题了。
console.log(encodeBase64("霜序")); // 8=
console.log(decodeBase64(encodeBase64("霜序"))); // ô
其实是当字符的 Unicode 码大于255时,上述魔法就会失灵。同样的 window 上的 btoa 和 atob 方法也会失效。
霜序 两个字的 Unicode 分别为 38684/24207,那我们可以把这些数字转化为多个255内的数字,也就是用多个字节表示,就可以使用我们上述 Unicode 转 UTF-8 的方法,得到对应的字符,在对齐进行编码
function encodeTransform(input) {
if (!input) return;
const byteArray = [];
for (let i = 0; i < input.length; i++) {
const code = input.charCodeAt(i); // 获取到当前字符的 Unicode 码
if (code < 128) {
byteArray.push(code);
} else if (code >= 128 && code < 2048) {
byteArray.push((code >> 6) | 192);
byteArray.push((code & 63) | 128);
} else if (code >= 2048 && code < 65535) {
byteArray.push((code >> 12) | 224);
byteArray.push(((code >> 6) & 63) | 128);
byteArray.push((code & 63) | 128);
}
}
return byteArray; // 返回 UTF-8 编码的数据
}
function encodeBase64(input) {
if (!input) return;
let base64String = "";
const byteArray = encodeTransform(input);
for (let i = 0; i < byteArray.length; ) {
const char1 = byteArray[i++];
const encode1 = char1 >> 2;
const char2 = byteArray[i++];
const encode2 = ((char1 & 3) << 4) | (char2 >> 4);
const char3 = byteArray[i++];
let encode3 = ((char2 & 15) << 2) | (char3 >> 6);
let encode4 = char3 & 63;
if (Number.isNaN(char2)) encode3 = encode4 = 64;
if (Number.isNaN(char3)) encode4 = 64;
base64String +=
_base64Str.charAt(encode1) +
_base64Str.charAt(encode2) +
_base64Str.charAt(encode3) +
_base64Str.charAt(encode4);
}
return base64String;
}
console.log(encodeBase64("霜序")); // 6Zyc5bqP
同样的我们也需要对解码的内容做相应的转换,我们需要把 Base64 解码完成的数据,通过UTF-8的编码规则还原回 Unicode 码,找到对应的字符。
function decodeTransform(byteArray) {
let i = 0;
const output = [];
while (i < byteArray.length) {
const code = byteArray[i];
if (code < 128) {
output.push(code);
i++;
} else if (code > 191 && code < 224) {
const code1 = byteArray[i + 1];
output.push(((code & 31) << 6) | (code1 & 63));
i += 2;
} else {
const code1 = byteArray[i + 1];
const code2 = byteArray[i + 2];
output.push(
((code & 15) << 12) | ((code1 & 63) << 6) | (code2 & 63)
);
i += 3;
}
}
return output.map((item) => String.fromCharCode(item)).join("");
}
function decodeBase64(input) {
if (!input) return;
const byteArray = [];
for (let i = 0; i < input.length; ) {
const encode1 = _base64Str.indexOf(input.charAt(i++));
const encode2 = _base64Str.indexOf(input.charAt(i++));
const encode3 = _base64Str.indexOf(input.charAt(i++));
const encode4 = _base64Str.indexOf(input.charAt(i++));
const char1 = (encode1 << 2) | (encode2 >> 4);
const char2 = ((encode2 & 15) << 4) | (encode3 >> 2);
const char3 = ((encode3 & 3) << 6) | encode4;
byteArray.push(char1);
if (encode3 != 64) {
byteArray.push(char2);
}
if (encode4 != 64) {
byteArray.push(char3);
}
}
return decodeTransform(byteArray);
}
总结
在本文中,重点是要实现 Base64 编码的内容,然后先给大家讲述了相关字符集(ASCII/Unicode)出现的原因。
Unicode 编码相关的缺点,由此引出了 UTF-8/UTF-16 编码。
对于 UTF-16 来说,最小的编码单元为两个字节,由此引出了字节序的内容。
当我们有了上述知识之后,最后开始 Base64 编码的实现。