👨🎓博主简介
🏅云计算领域优质创作者
🏅华为云开发者社区专家博主
🏅阿里云开发者社区专家博主
💊交流社区:运维交流社区 欢迎大家的加入!
🐋 希望大家多多支持,我们一起进步!😄
🎉如果文章对你有帮助的话,欢迎 点赞 👍🏻 评论 💬 收藏 ⭐️ 加关注+💗
常用的文本处理命令目录
- 1、rename 批量修改文件名
- rename 介绍:
- rename 格式:
- rename 实例:
- 2、dirname 去除文件名中的非目录部分(取路径的目录部分)
- dirname 介绍:
- dirname 格式:
- dirname 实例:
- 3、basename 显示文件路径名的基本文件名(取路径中的文件名)
- basename 介绍:
- basename 格式:
- basename 实例:
- 4、cut 按列提取文件内容(切割文本内容)
- cut 介绍:
- cut 格式:
- cut 实例:
- 5、sort 对文件内容进行排序
- sort 介绍:
- sort 格式:
- sort 实例:
- 6、uniq 去除文件中的重复内容行(去重 相邻 的重复行)
- uniq 介绍:
- uniq 格式:
- uniq 实例:
- 7、tee 读取标准输入的数据(双重重定向)
- tee 介绍:
- tee 格式:
- tee 实例:
- 8、tr 字符转换工具(字符串替换)
- tr 介绍:
- tr 格式:
- tr 实例:
- 9、join 连接两个文件-->以某列为主,相同合并两个文件(不相同的话先排序)
- join 介绍:
- join 格式:
- join 实例:
- 10、paste 合并两个文件-->合并文件的列,把每个文件以列队列的方式合并显示
- paste 介绍:
- paste 格式:
- paste 实例:
- 11、split 分割文件内容
- split 介绍:
- split 格式:
- split 实例:
- 12、diff / vimdiff [多]文本比较
- diff / vimdiff 介绍:
- diff / vimdiff 格式:
- diff / vimdiff 实例:
- 13、xagrs 给其他命令传参数的过滤器
- xagrs 介绍:
- xagrs 格式:
- xagrs 实例:
- 14、rev 将文件中的每行内容反序输出(以列为单位)
- rev 介绍:
- rev 格式:
- rev 实例:
- 15、shuf 产生随机的排列(指定输出内容,随机输出没有顺序)
- shuf 介绍:
- shuf 格式:
- shuf 实例:
- 16、Shell脚本的调式
- 方法一:set 方式
- 脚本 外 使用调式
- 脚本 内 使用调式
- 方法二:bashdb 第三方调试工具
- bashdb的安装
- bashdb的使用
1、rename 批量修改文件名
首先:批量创建文件(20个)
touch test-{1..20}.txt

rename 介绍:
rename命令的功能是用于批量修改文件名称。与mv命令一次只能修改一个文件名不同,rename命令能够基于正则表达式对文件名进行批量修改,但要求是把匹配规则准确地描述给系统。
rename命令的参数有三项:其一是当前文件名中要被修改的字符,其二是其要被修改为的新字符,其三是要被执行的对象文件列表。初次可能有点难理解,动手尝试下吧~
rename 格式:
rename 原字符 新字符 文件名
rename 实例:
实例1:修改名为 test-18.txt 为 cs-18.txt
单个修改还是推荐mv命令;
rename test-18.txt cs-18.txt test-18.txt

实例2:将所有test开头的文件全部修改为abc开头的
rename test abc test*

实例3:将所有的txt后缀改为cfg
rename txt cfg *

实例4:将所有的a都改为A
rename a A *

2、dirname 去除文件名中的非目录部分(取路径的目录部分)
dirname 介绍:
dirname命令去除文件名中的非目录部分,仅显示与目录有关的内容。dirname命令读取指定路径名保留最后一个/及其后面的字符,删除其他部分,并写结果到标准输出。如果最后一个/后无字符,dirname命令使用倒数第二个/,并忽略其后的所有字符。dirname 和 basename 通常在 shell 内部命令替换使用,以指定一个与指定输入文件名略有差异的输出文件名。
dirname 格式:
dirname [参数]
dirname 实例:
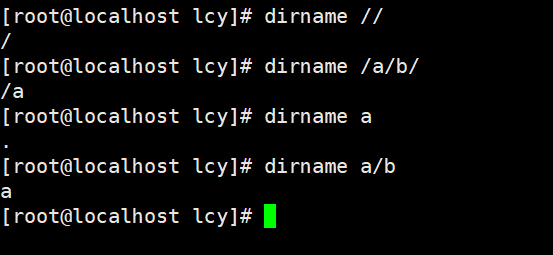
实例1:去除 // 的非目录部分结果为 / :
dirname //
#结果为
/
实例2:去除 /a/b/ 的非目录部分结果为 /a :
dirname /a/b/
#结果为
/a
实例3:去除 a 的非目录部分结果为 :
dirname a
#结果为
.
实例4:去除 a/b 的非目录部分结果为路径名 a :
dirname a/b
#结果为
a
3、basename 显示文件路径名的基本文件名(取路径中的文件名)
basename 介绍:
basename命令主要用于显示文件路径名剔除目录部分后的显示文件名。如何指定了后缀参数suffix,同时也删除文件的扩展名。其中,name是文件的路径名,suffix是文件名的后缀。
basename 格式:
basename [参数]
basename 实例:
显示文件路径名/usr/bin/lcy的基本文件名lcy:
basename /usr/bin/lcy
#结果为
lcy

4、cut 按列提取文件内容(切割文本内容)
cut 介绍:
cut命令的功能是用于按列提取文件内容。常用的grep命令仅能对关键词进行按行提取过滤,而cut命令则是可以根据指定的关键词信息,针对特定的列内容进行过滤。
cut 格式:
cut [参数] 文件名
cat 文件名 | cut [参数]
常用参数:
| 参数 | 解析 |
|---|---|
| -d | 指定分隔符 |
| -f | 指定取第几段,与-d一起使用 |
| -b | 按字节进行切割(一般是英文) |
| -c | 按字符进行切割(一般是中文) |
cut 实例:
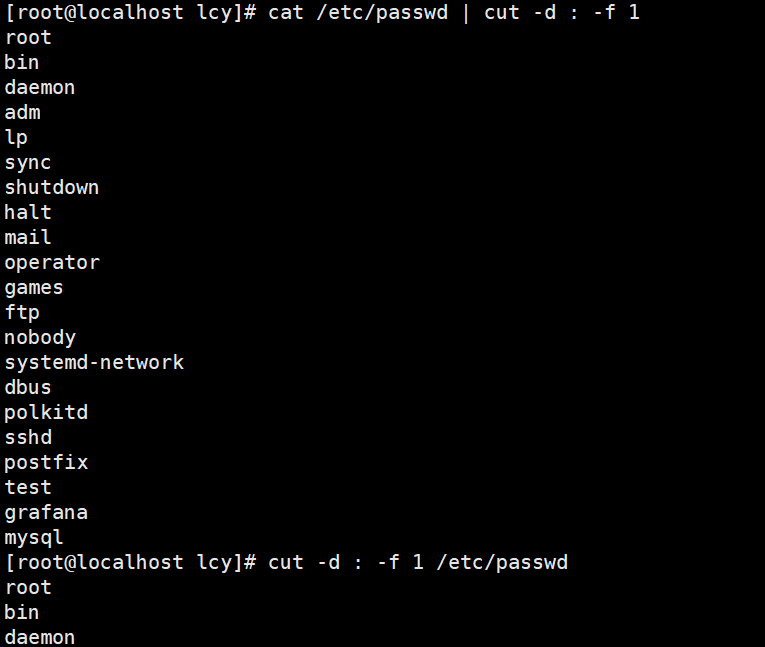
实例1:以冒号为间隔符,仅提取指定文件中第一列的内容:
cat /etc/passwd | cut -d : -f 1
cut -d : -f 1 /etc/passwd
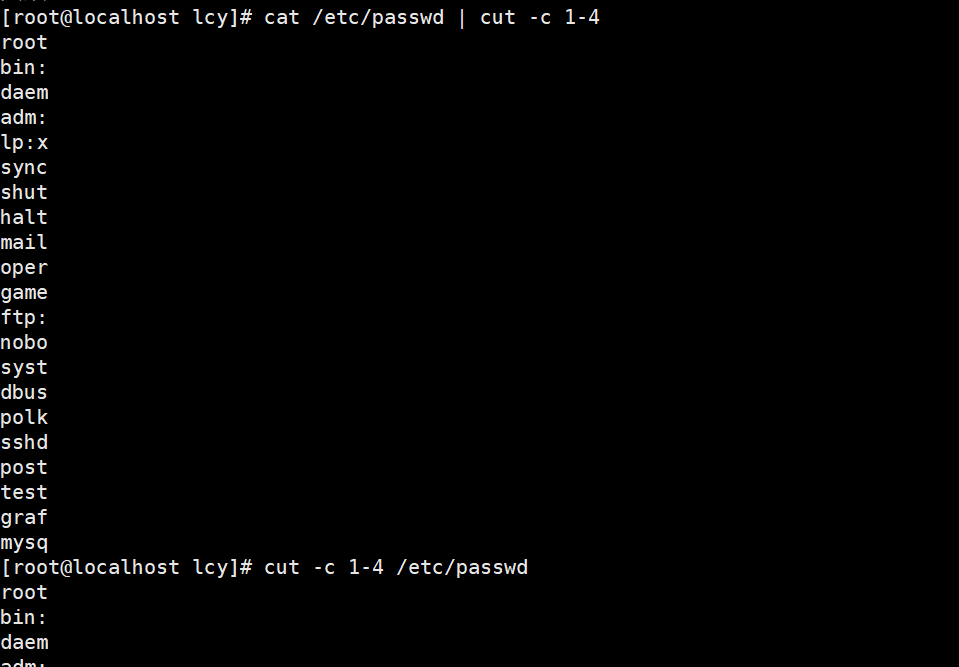
实例2:仅提取指定文件中每行的前4个字符:
cat /etc/passwd | cut -c 1-4
cut -c 1-4 /etc/passwd
实例3:以空格为单位切割只要成功、失败两个字

cat a.txt | cut -d " " -f 1 | cut -c 4-5

实例4:切割passwd中只有root四个字
head -1 /etc/passwd | cut -d ":" -f 1

5、sort 对文件内容进行排序
sort 介绍:
sort命令的功能是对文件内容进行排序。有时文本中的内容顺序不正确,一行行的手动修改实在太麻烦了。此时使用sort命令就再合适不过了,它能够对文本内容进行再次排序。
sort 格式:
sort [参数] 文件名
cat 文件名 | sort [参数]
常用参数:
| 参数 | 解析 |
|---|---|
| -n(number) | 以数字为单位进行排序 |
| -r | 降序排 |
| -t | 指定分隔符,默认是空格 |
| -k | 以某段进行排序 |
| -b | 忽略每行前面出现的字符 |
| -c | 检查文件是否已经按照顺序排序 |
| -d | 除字母、数字及空格字符外,忽略其他字符 |
| -f | 将小写字母视为大写字母 |
| -h | 以更易读的格式输出信息(以人类可读的方式) |
| -i | 除040至176之间的ASCII字符外,忽略其他字符 |
| -m | 将几个排序号的文件进行合并 |
| -M | 将前面3个字母依照月份的缩写进行排序 |
| -o | 将排序后的结果写入指定文件 |
| -R | 依据随机哈希值进行排序 |
| -T | 设置临时目录 |
| -z | 使用0字节结尾, 而不是换行 |
sort 实例:
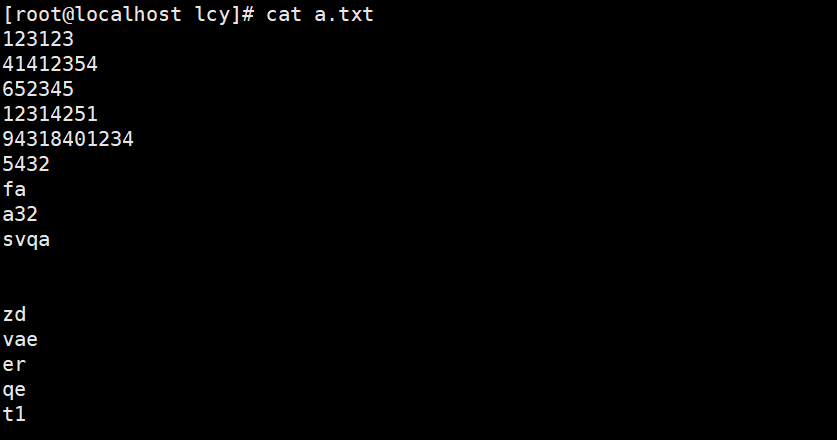
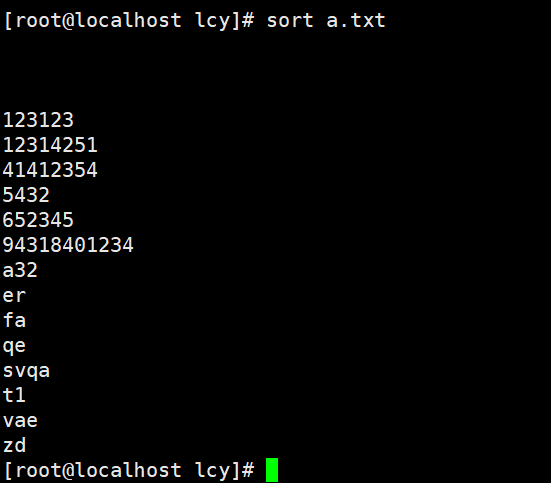
实例1:整体文件内容排序(优先空格–>数字–>字母–>中文)
不加任何参数默认只给首字母排序
sort a.txt
cat a.txt | sort
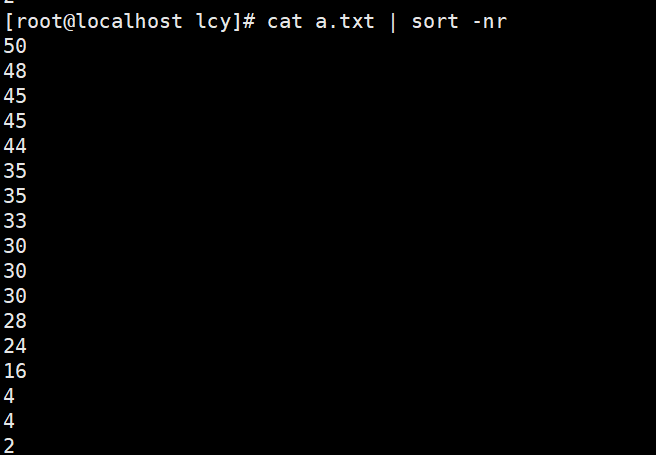
实例2:文本中数字从大到小排序(降序)
sort -nr a.txt
cat a.txt | sort -nr
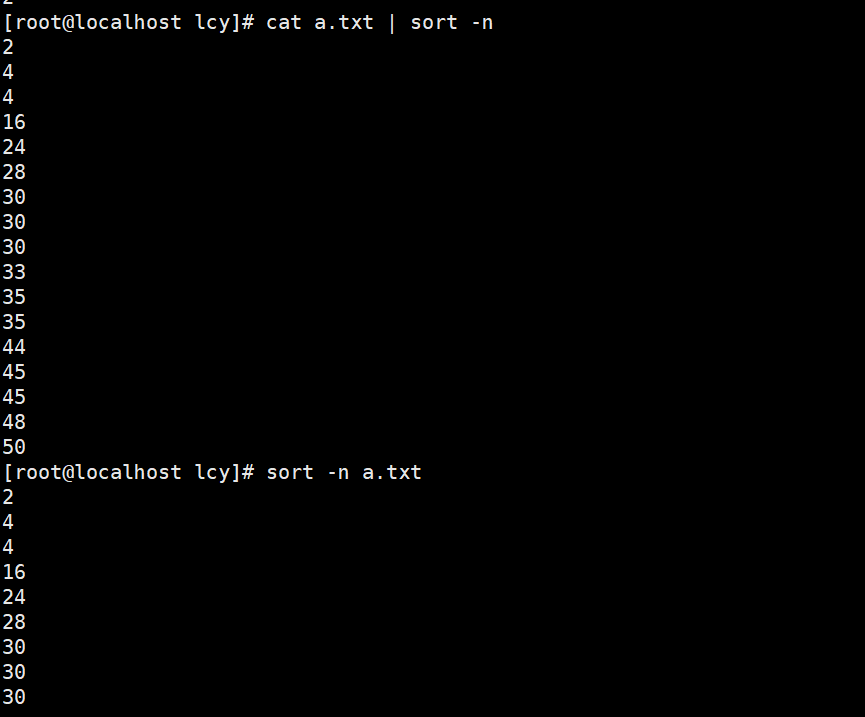
实例3:文本中数字从小到大排序(升序)
sort -n a.txt
cat a.txt | sort -n
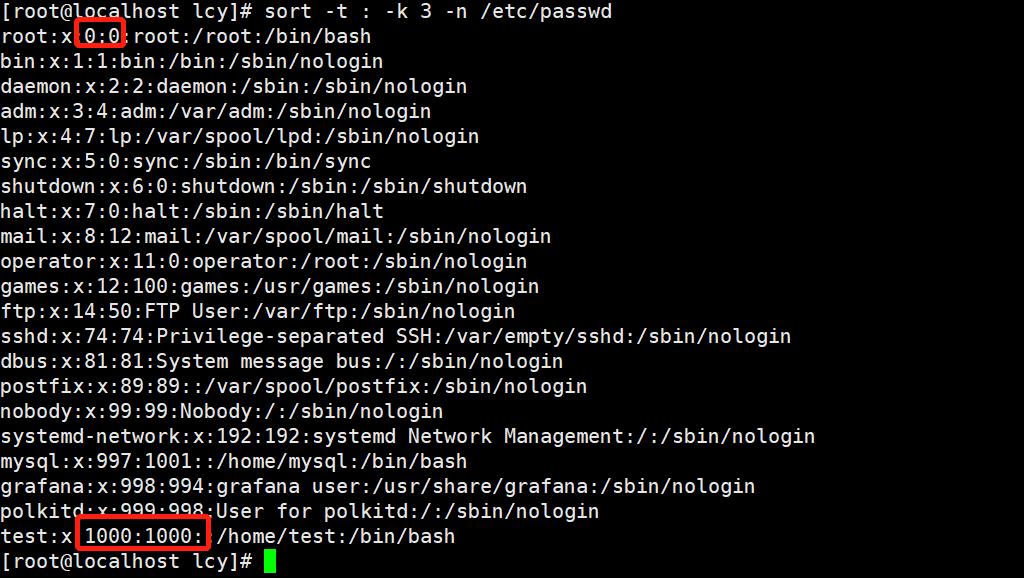
实例4:以冒号(:)为间隔符,对指定的文件内容按照数字大小对第3列进行排序(降序)
sort -t : -k 3 -n /etc/passwd
6、uniq 去除文件中的重复内容行(去重 相邻 的重复行)
uniq 介绍:
uniq命令来自英文单词unique的缩写,中文译为独特的、唯一的,其功能是用于去除文件中的重复内容行。uniq命令能够去除掉文件中相邻的重复内容行,如果两端相同内容中间夹杂了其他文本行,则需要先使用sort命令进行排序后再去重复,这样保留下来的内容就都是唯一的了。
uniq 格式:
uniq [参数] 文件名
cat 文件名 | uniq [参数]
常用参数
| 参数 | 解析 |
|---|---|
| -c | 统计,显示每行在文本中重复出现的次数 |
| -d | 设置每个重复纪录只出现一次 |
| -u | 仅显示没有重复的纪录 |
| -D | 显示所有相邻的重复行 |
| -f | 跳过对前N个列的比较 |
| -i | 忽略大小写 |
| -s | 跳过对前N个字符的比较 |
| -w | 仅对前N个字符进行比较 |
| -z | 设置终止符(默认为换行符) |
uniq 实例:
文本原文
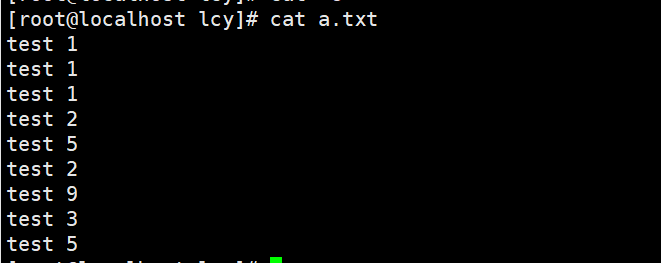
实例1:去除相邻的重复行,并显示重复次数
uniq -c a.txt
cat a.txt | uniq -c
前面的3、1代表的是统计的 相邻 重复行次数。
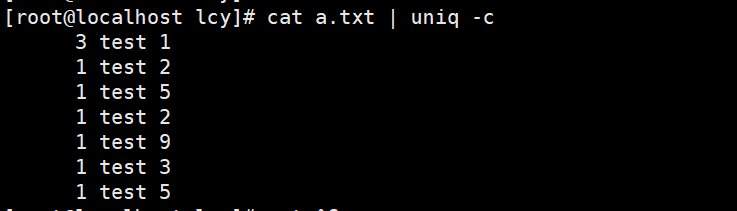
可以看到有几个也是一样的,但是没有进行统计,那是因为他们不是相邻的行,这时候我们可以结合sort命令排序来进行统计;
cat a.txt | sort -n | uniq -c

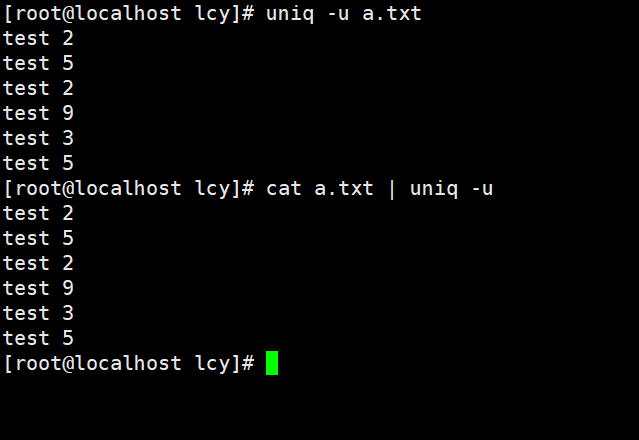
实例2:只统计没有重复的相邻的行的数据
uniq -u a.txt
cat a.txt | uniq -u
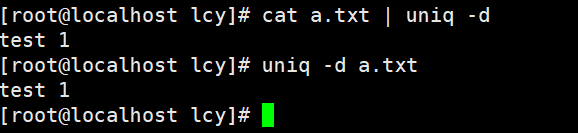
实例3:只统计重复的相邻的行的数据
cat a.txt | uniq -d
uniq -d a.txt
实例4:忽略大小写去除相邻相邻的重复行,并显示重复次数
初始数据:
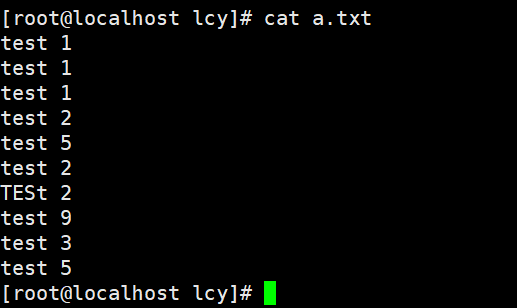
uniq -ic a.txt
cat a.txt | uniq -ic
7、tee 读取标准输入的数据(双重重定向)
默认覆盖到文件中
tee 介绍:
tee命令的功能是用于读取标准输入的数据,将其内容转交到标准输出设备中,同时保存成文件,并在页面上显示出来。
tee 格式:
tee [参数] 文件名
cat 文件名 | tee [参数]
常用参数
| 参数 | 解析 |
|---|---|
| -a | 追加 |
| -i | 忽略中断信号 |
| -p | 诊断写入非管道的错误 |
tee 实例:
实例1:执行uptime指定的命令,并将其执行结果即输出到屏幕,又写入到文件中
uptime | tee cs.txt

实例2:将要输入的结果即输出到屏幕上,又追加到cs.txt中
echo "123123" | tee -a cs.txt

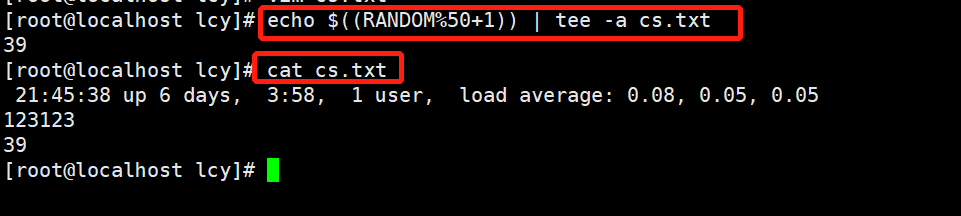
实例3:随机输出1-50之间的随机数,将结果输出到屏幕上,并追加到cs.txt文件中
echo $((RANDOM%50+1)) | tee -a cs.txt
8、tr 字符转换工具(字符串替换)
tr 介绍:
tr命令来自英文单词“transform”的缩写,中文译为“转换”,其功能是用于字符转换。tr命令是一款批量字符转换、压缩、删除的文本工具,但仅能从标准输入中读取文本内容,需要与管道符或输入重定向操作符搭配使用。
tr 格式:
tr [参数] 原字符串 替换的字符串
ehco "字符串"|tr "原字符串" "替换的字符串"
常用参数
| 参数 | 解析 |
|---|---|
| -c | 排除某个字符替换其他字符 |
| -d | 删除指定的字符串 |
| -s | 去除相邻重复的字符 |
| -t | 将字符串1截断为字符串2的长度 |
tr 实例:
实例1:直接展示输出abc,将abc替换为大写的ABC
echo "abc" | tr "abc" "ABC"

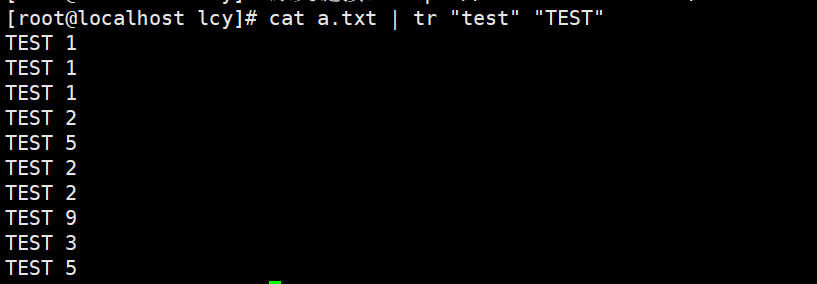
实例2:将文本中的小写的test全部变为大写的TEST
这个转换并没有起到修改的作用,因此看着是都转换了,但文本中还是小写的。
cat a.txt | tr "test" "TEST"
实例3:输出一长串字符串,只删除a-z的字母,其他都留着
echo "aaaaaaaaabbbbbbbbbbbbbbbbbb1c2c3cc" | tr -d "a-z"
echo "aaaaaaaaabbbbbbbbbbbbbbbbbb1c2c3cc" | tr -d [a-z]

实例4:去除相邻的相同字符,只保留一个
echo "aaaaaaaabbbbbbbccccccc" | tr -s "a-z"
echo "aaaaaaaabbbbbbbccccccc" | tr -s [a-z]

实例5:只保留字符abc,其余字符都替换成逗号
echo "aaaaaaaaabbbbbbbbbbbbbbbbbb1c2c3cc" | tr -c "abc" ","

实例6:将所有的a-z的小写,全部替换为大写
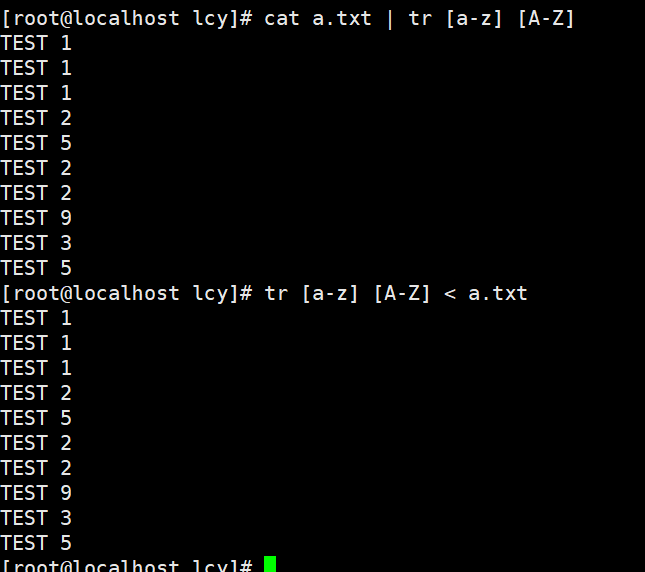
cat a.txt | tr [a-z] [A-Z]
tr [a-z] [A-Z] < a.txt
9、join 连接两个文件–>以某列为主,相同合并两个文件(不相同的话先排序)
join 介绍:
join的连接操作简言之就是将两个具有相同域的纪录给挑选出来,再将这些纪录所有的域放到一行。
注意:join在对两个文件进行连接时,两个文件必须都是按照连接域排好序的,按其他域排序是无效的。
join 格式:
join [参数] [文件1] [文件2]
常用参数
| 参数 | 解析 |
|---|---|
| -a1或-a2 | 除了显示共同域的纪录之外,-a1显示第一个文件没有共同域的纪录,-a2显示第二个文件中没有共同域的纪录 |
| -i | 忽略大小写 |
| -o | 设置结果显示的格式 |
| -t | 改变域的分隔符 |
| -v1或-v2 | 不显示共同域的纪录之外,-v1显示第一个文件没有共同域的纪录,-v2显示第二个文件中没有共同域的纪录 |
| -1或-2 | -1用来设置文件1连接的域,-2用来设置文件2连接的域 |
join 实例:
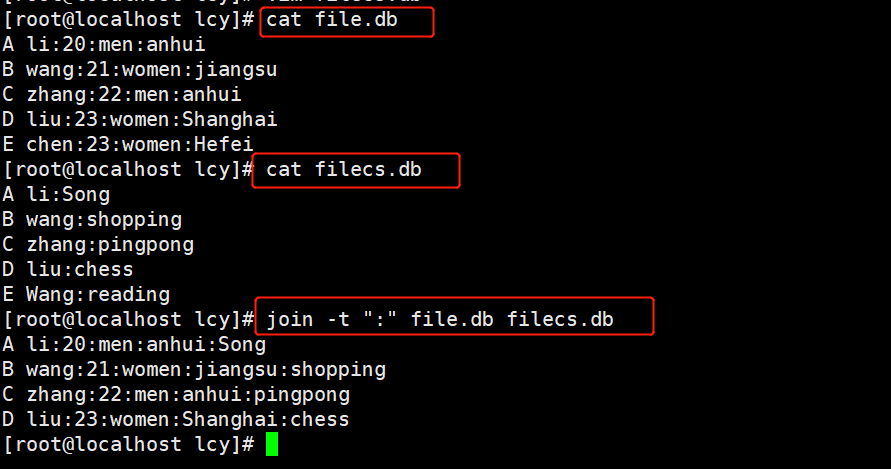
实例1:将两个文件的具有共同域的记录连接在一起
[root@localhost lcy]# cat file.db
A li:20:men:anhui
B wang:21:women:jiangsu
C zhang:22:men:anhui
D liu:23:women:Shanghai
E chen:23:women:Hefei
[root@localhost lcy]# cat filecs.db
A li:Song
B wang:shopping
C zhang:pingpong
D liu:chess
E Wang:reading
[root@localhost lcy]# join -t ":" file.db filecs.db
A li:20:men:anhui:Song
B wang:21:women:jiangsu:shopping
C zhang:22:men:anhui:pingpong
D liu:23:women:Shanghai:chess
实例2:-a1还显示第一个文件中没有共同域的纪录,-a2则显示第二个
文本内容:
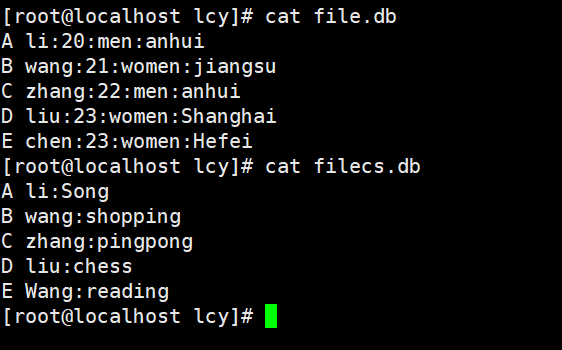
[root@localhost lcy]# join -t ":" -a1 file.db filecs.db
A li:20:men:anhui:Song
B wang:21:women:jiangsu:shopping
C zhang:22:men:anhui:pingpong
D liu:23:women:Shanghai:chess
E chen:23:women:Hefei
[root@localhost lcy]# join -t ":" -a2 file.db filecs.db
A li:20:men:anhui:Song
B wang:21:women:jiangsu:shopping
C zhang:22:men:anhui:pingpong
D liu:23:women:Shanghai:chess
E Wang:reading
实例3:设置指定格式的域来显示出来(将具有共同纪录的域按照姓名+性别+爱好的格式显示出来)
[root@localhost lcy]# join -t ":" -o 1.1 1.3 2.2 file.db filecs.db
A li:men:Song
B wang:women:shopping
C zhang:men:pingpong
D liu:women:chess
10、paste 合并两个文件–>合并文件的列,把每个文件以列队列的方式合并显示
paste 介绍:
paste命令来自英文单词“粘贴”,其功能是用于合并两个文件。paste命令能够将两个文件以列对列的方式进行合并,相当于是把两个不同的文件内容粘贴到了一起,形成新的文件,如需先将内容合并成一行,再以行粘贴的方式合并,可以用-s参数搞定。
paste 格式:
paste [参数] 文件名1 文件名2
常用参数
| 参数 | 解析 |
|---|---|
| -d | 设置自定义间隔符【指定连接符】 |
| -s | 将每个文件粘贴成一行【将文件多行变成一行输出】 |
| - - | 从标准输入中读取数据 |
paste 实例:
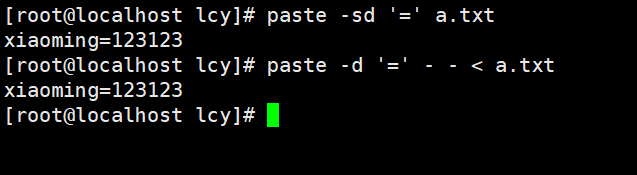
实例1:将2行字符串修改为1行,在第一行后面添加=用于连接第二行
文本初始内容:

#以=和\n轮流做分隔符
paste -sd '=' a.txt
#一个-表示读入一行
paste -d '=' - - < a.txt
实例2:将2个文件进行合并
[root@localhost lcy]# cat a.txt
aaa
bbb
ccc
ddd
eee
[root@localhost lcy]# cat b.txt
AAA
BBB
CCC
DDD
EEE
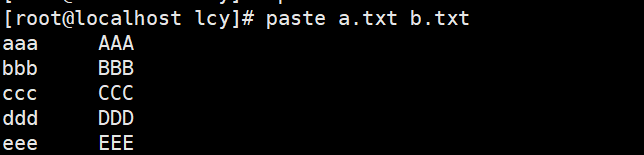
[root@localhost lcy]# paste a.txt b.txt
aaa AAA
bbb BBB
ccc CCC
ddd DDD
eee EEE
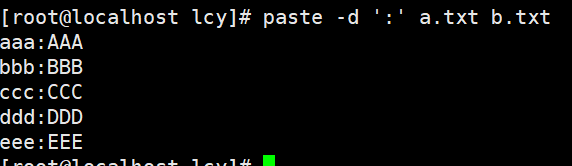
实例3:将2个文件进行合并,并添加:为分隔符
paste -d ':' a.txt b.txt
实例4:将每个文件的内容转为一行,在进行合并
paste -s a.txt b.txt

11、split 分割文件内容
split 介绍:
split命令来自英文单词“分裂”,其功能是用于分割文件内容。Linux系统运维人员可以使用split命令对指定的大文件进行内容分割,默认会按照每1000行切割成一个小文件来执行,也可以自定义分割大小,方便阅读和传输。
split 格式:
split [参数] 文件名 [要修改的文件名前缀]
常用参数:
| 参数 | 解析 |
|---|---|
| -数字 | 设置要分割的行数 |
| -a | 设置后缀长度 |
| -l | 以行为单位进行切割 |
| -b | 以字节为单位进行切割 |
| -C | 保持每行的完整性 |
| -d | 以数字做后缀而不是字母 |
| -t | 设置间隔符 |
| –verbose | 显示执行过程详细信息 |
split 实例:
实例1:文件"a.txt"每6行切割成一个文件
split -6 a.txt
将文件中的文字以每6行切割为一份文件,切割成多个以"x"开头的小文件。
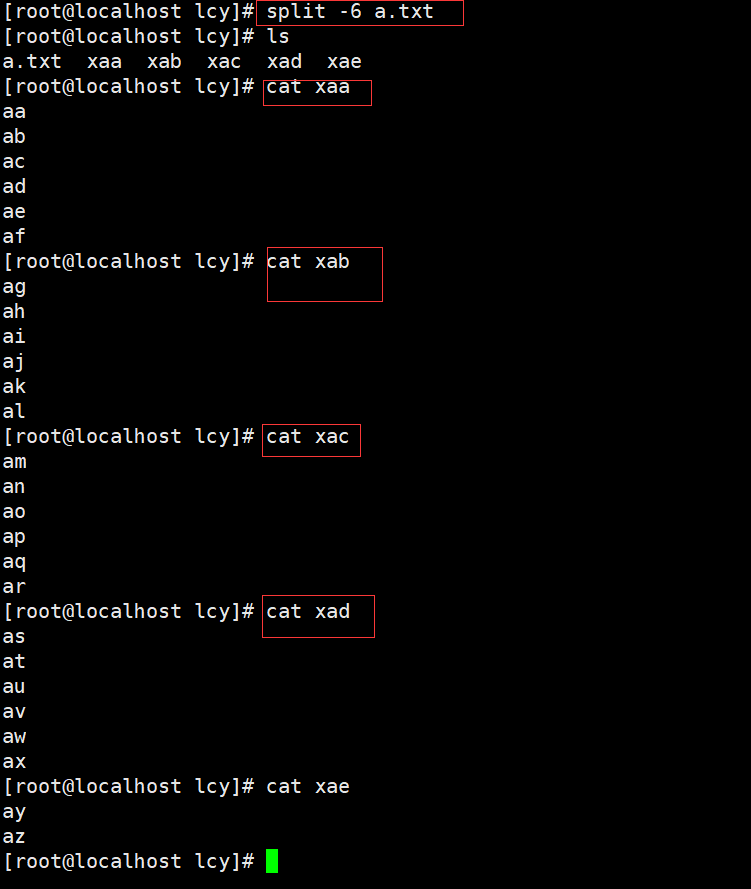
linux中split命令切割出来的文件名为什么是xaa、xab之类的????
在 Linux 中,split命令用于将文件分割成指定大小的较小文件。默认情况下,split 命令会以字母序列来命名分割后的文件,第一个文件会被命名为x,第二个文件会被命名为aa,第三个文件会被命名为ab,以此类推。
这是因为在 Linux 中,split 命令默认使用 6 位数来表示文件名,其中前两个字符用于表示文件大小,后四个字符用于表示文件名的唯一性。例如,如果原始文件名为example.txt,则第一个分割后的文件可能会被命名为 xaa.txt,第二个分割后的文件可能会被命名为 xab.txt,以此类推。
可以通过在 split 命令中使用 -d 选项来指定使用数字序列来命名文件,例如:
实例2:切割文件以字节为单位10字节,以lcy作为前缀,以数字作为后缀
split -d -b 10 a.txt lcy_
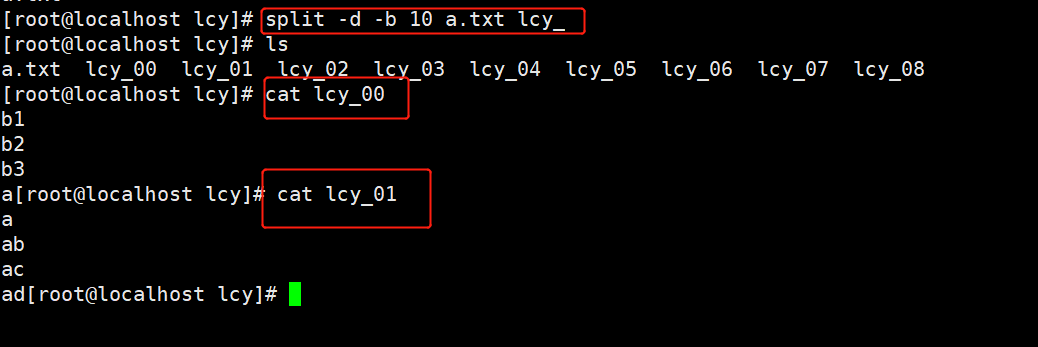
在上面的例子中,-d 选项用于指定使用数字序列来命名文件,
-b 10选项用于指定每个分割后的文件大小为 10字节,a.txt 是要分割的文件名,lcy_是用于指定前缀的字符串。这样,第一个分割后的文件会被命名为lcy_00,第二个分割后的文件会被命名为lcy_001,以此类推。
当然,其他单位也可以,比如m(兆比)或者k(K比),split -d -b 10k a.txt lcy_ && split -d -b 10m a.txt lcy_
实例3:以行为单位、以lcy.为单位进行切割
split -l 5 a.txt lcy.
以行为单位,每
五行切割一次,以lcy.为前缀,后缀为默认,默认从aa开始。

实例4:以行为单位、以lcy.为单位、并设置后缀为4为数字进行切割
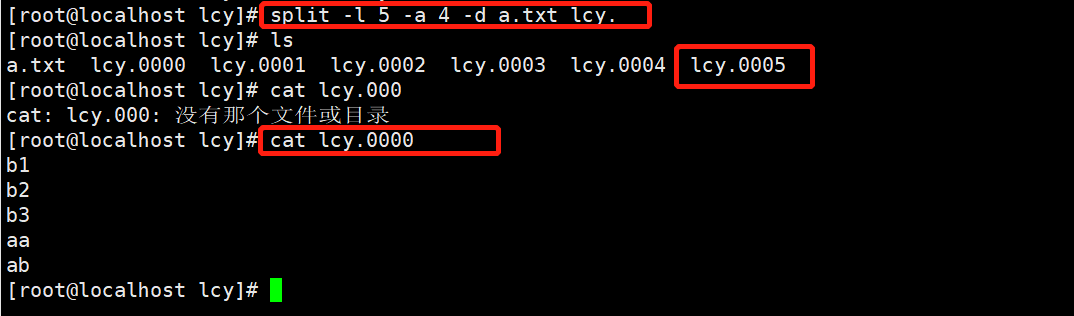
split -l 5 -a 4 -d a.txt lcy.
以行为单位,每
五行切割一次,以lcy.为前缀,后缀为数字形式,后缀长为4位数;
12、diff / vimdiff [多]文本比较
diff / vimdiff 介绍:
diff介绍:
diff命令来自英文单词“different”的缩写,其功能是用于比较文件内容差异。如果有多个内容相近的文件,如何快速定位到不同内容所在位置?此时用diff命令就再合适不过了~!
vimdiff介绍:
vimdiff命令来自英文词组“Vim differences”的缩写,其功能是用于同时编辑多个文本文件。对纯文本文件的比较和合并工具一直是软件开发过程中比较重要的组成部分,vimdiff命令能够比较多个文本文件之间的差异并快速定位,并很容易地进行文件合并操作。
diff的区别和vimdiff的区别:
diff是可以直接将不同的文件输出出来,就是对于新手不友好,看不出来是哪个文件少东西或者不一样,而且diff最多支持两个文件做比较。vimdiff是可以清晰的看出哪个文件少什么东西,或者是那行和哪行不一样,非常的清晰,而且还支持多文件比较,是非常友好的,但是就是退出有点麻烦,必须执行:q!退出。总结及推荐各有各的好,但我还是推荐使用 vimdiff。
diff / vimdiff 格式:
diff [参数] 文件名1 文件名2
vimdiff [参数] 文件名1 文件名2 [文件名N]
diff / vimdiff 实例:
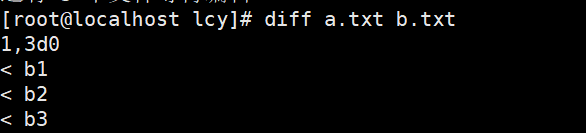
实例1:diff 比较两个文件
diff a.txt b.txt
看不出来是哪个少东西,很不友好。
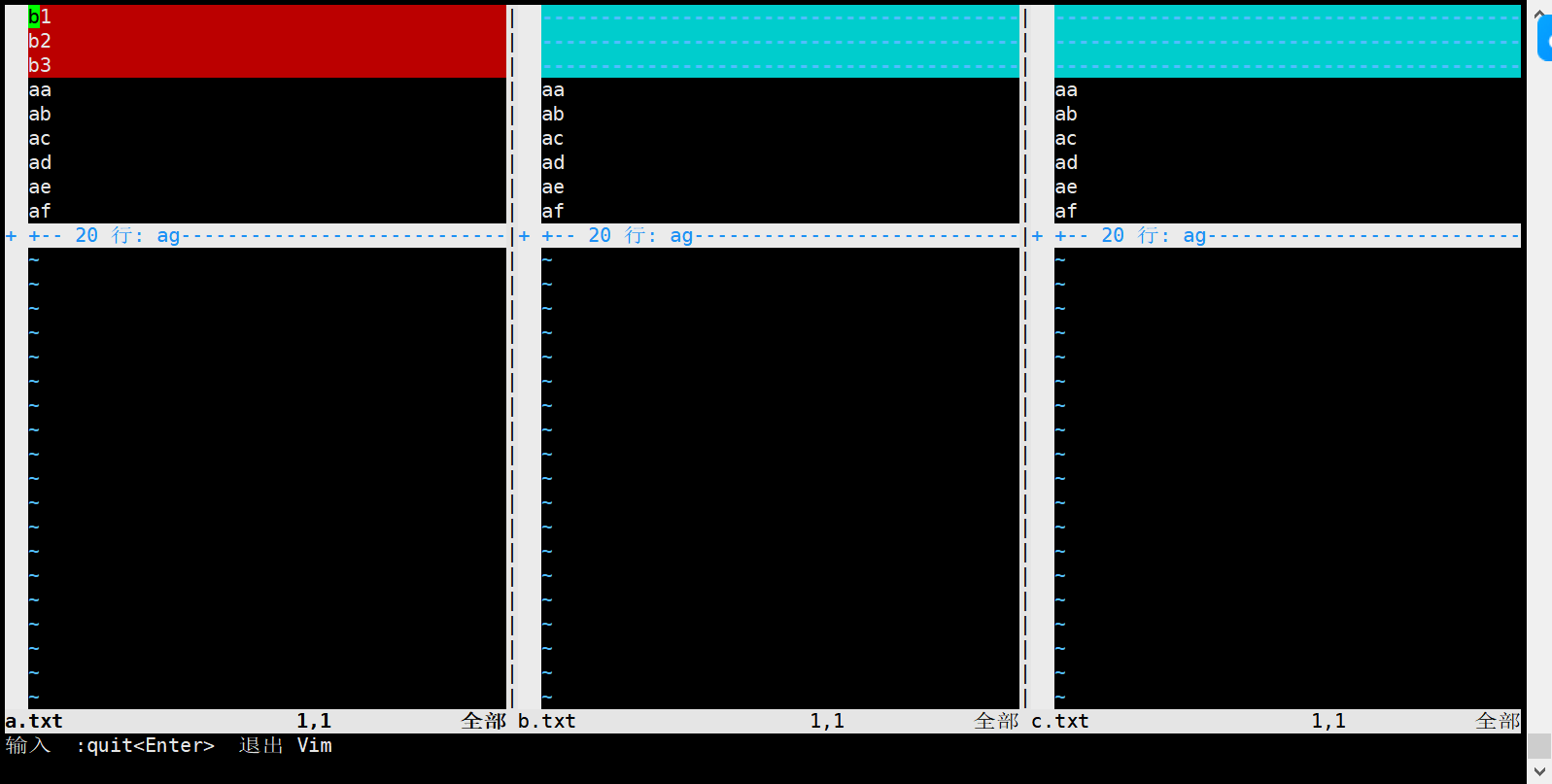
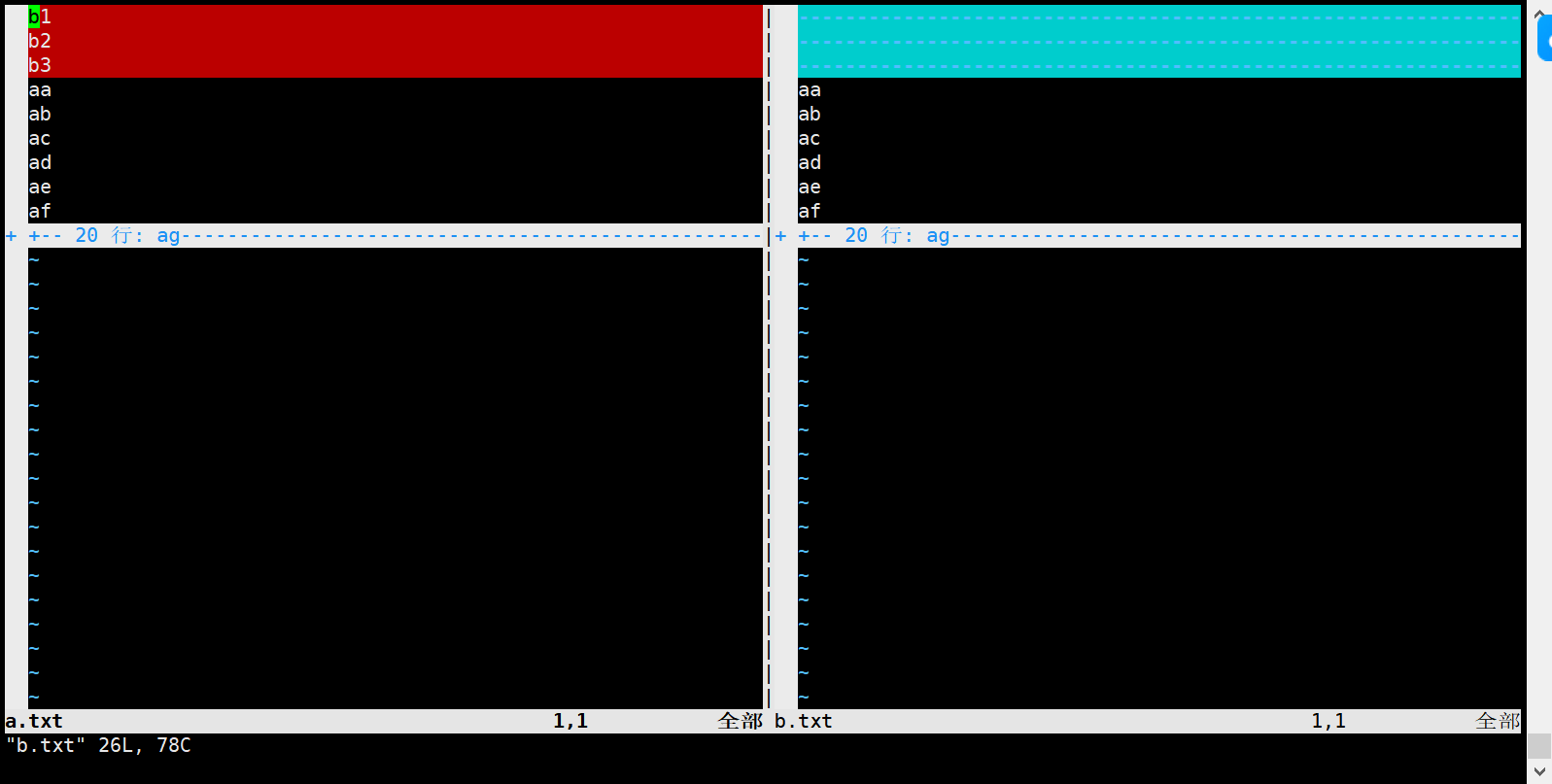
实例2:vimdiff 比较两个文件
vimdiff a.txt b.txt
实例3:vimdiff 比较多个文件
vimdiff a.txt b.txt c.txt
13、xagrs 给其他命令传参数的过滤器
将字符结果转化为参数传递个后命令,通常与管道连用
xagrs 介绍:
xargs命令来自英文词组“extended arguments”的缩写,其功能是用于给其他命令传递参数的过滤器。xargs命令能够处理从标准输入或管道符输入的数据,并将其转换成命令参数,也可以将单行或多行输入的文本转换成其他格式。
xargs命令默认接收的信息中,空格是默认定界符,所以可以接收包含换行和空白的内容。
xagrs 格式:
xargs [参数] [文件名]
命令 | xargs [参数]
常用参数:
| 参数 | 解析 |
|---|---|
| -a | 设置从文件中读取数据 |
| -d | 设置自定义定界符 |
| -I | 设置替换字符串 |
| -n | 设置多行输出;将标准输出的文本内容,多行转换一行,默认是空格隔开 |
| -p | 执行命令前询问用户是否确认 |
| -r | 如果输入数据为空,则不执行 |
| -s | 设置每条命令最大字符数 |
| -t | 显示xargs执行的命令 |
| -i | 以大括号保存管道前命令的执行结果 |
xagrs 实例:
实例1:删除/home/lcy/下的所有的a.txt文件
find /home/lcy/ -name "a.txt" |xargs rm -rf
实例2:删除/application/log/下的一天前的日志,类型为目录
find /application/log/ -mtime +0 -type d | xargs rm -rf
实例3:默认以空格为分割符,以多行形式输出文件内容,每行显示三段内容值:
cat a.txt | xargs -n 3
实例4:指定字符:为定界符,默认以单行的形式输出字符串内容:
cat a.txt | xargs -d ":"

14、rev 将文件中的每行内容反序输出(以列为单位)
rev 介绍:
使用rev命令可以把每一行字符的顺序颠倒过来显示文件内容
cat、tac、rev区别:
cat 为查看文件
tac 为反向查看文件(将文件倒过来看,行从后往前)
rev 文件内容反序输出(以列为单位,列从后往前)
rev 格式:
rev [文件]
rev 实例:
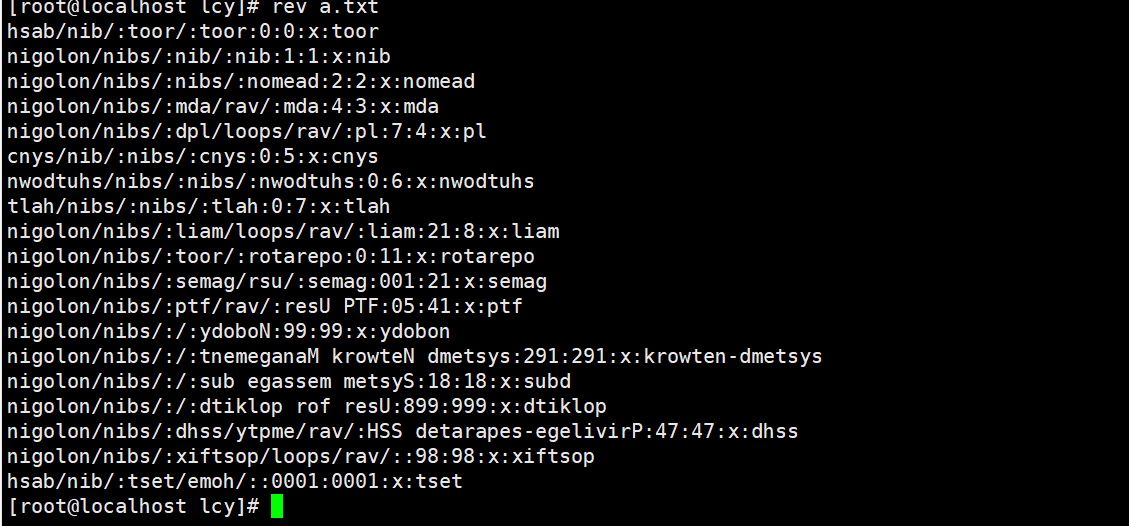
将a.txt每一行字符的顺序颠倒过来显示文件内容:
rev a.txt
15、shuf 产生随机的排列(指定输出内容,随机输出没有顺序)
shuf 介绍:
shuf命令将输入的内容随机排列并输出。 shuf命令当没有文件或文件为-时,读取标准输入。
shuf 格式:
shuf [参数]
常用参数:
| 参数 | 解析 |
|---|---|
| -e | 将每个ARG视为输入行 |
| -r | 重复输出行 [可以重复] |
| -n | 指定输出多少行 |
| -i | 将数字范围LO(最低)到HI(最高)之间的作为输入行 |
shuf 实例:
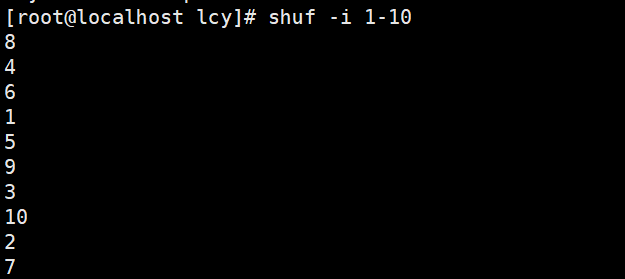
实例1:打乱顺序输出1-10
shuf -i 1-10
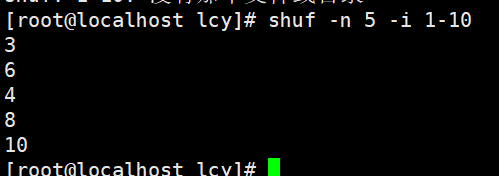
实例2:打乱顺序输出1-10并只显示5行
shuf -n 5 -i 1-10
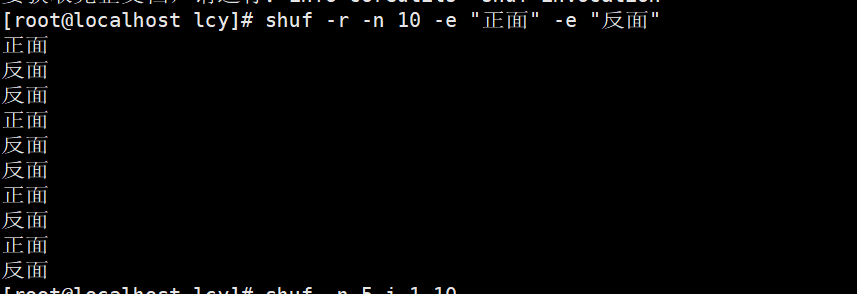
实例3:模拟硬币抛掷,获取前10个结果:
shuf -r -n 10 -e "正面" -e "反面"
实例4:模拟体彩超级大乐透:
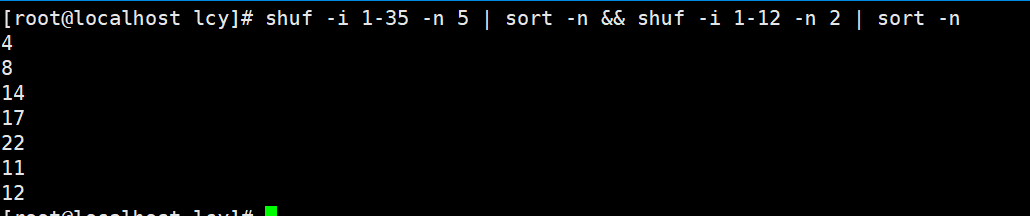
shuf -i 1-35 -n 5 | sort -n && shuf -i 1-12 -n 2 | sort -n
16、Shell脚本的调式
方法一:set 方式
- 可以在脚本中使用调式,在脚本中可以使用全部调式也可以只调试自己想要的部分;(有调试少部分代码时会使用)
- 可以在执行脚本时使用调试。(个人习惯使用)
bash
-n 将脚本读取一次,用于检测语法错误;
-x 执行每一条命令和结果依次打印;
-v 一边执行脚本,一边打印脚本。
测试:
脚本内容:
#!/bin/bash
email=$(netstat -lnt | grep 25 | wc -l)
if [ $email -ge 1 ];then
echo "端口已开启"
else
echo "端口未开启"
fi
脚本 外 使用调式
-x 打印出执行脚本的过程
sh -x cs.sh
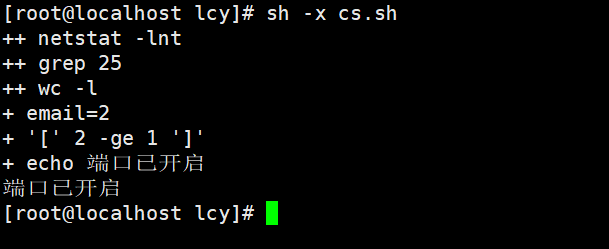
很清晰可以看到每一步执行的操作;
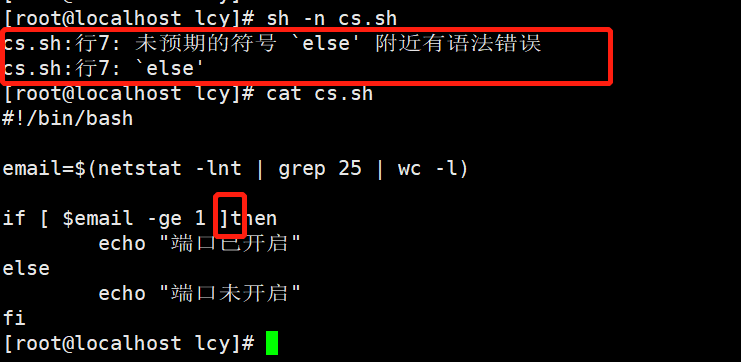
-n 测试脚本语法是否有问题
sh -n cs.sh
我们来修改一下脚本,将脚本的if判断的;分号去掉测试;
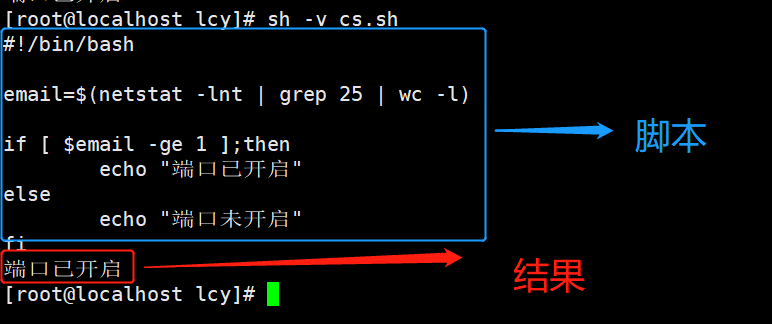
-v 一边执行脚本,一边打印脚本
脚本 内 使用调式
-x 打印出执行脚本的过程
如果对某一段进行调试,在那一段前面加一个set -x,后面加set +x。
if [ 1 -eq 1 ];then
set -x #检测s
echo0
set +x #禁止检测
fi
如果是全局调式,可以直接在最上面加个set -x
#!/bin/bash
#调式
set -x
if [ 1 -eq 1 ];then
echo 0
fi
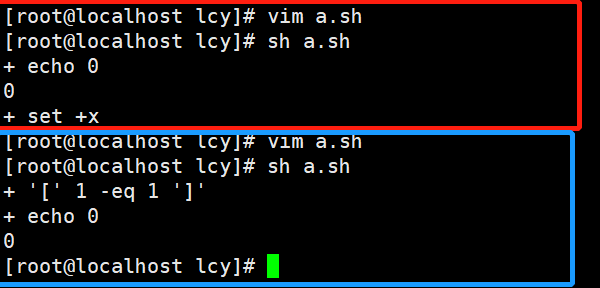
-n 测试脚本语法是否有问题
#!/bin/bash
#调式
set -n
if [ 1 -eq 1 ];then
echo 0
fi
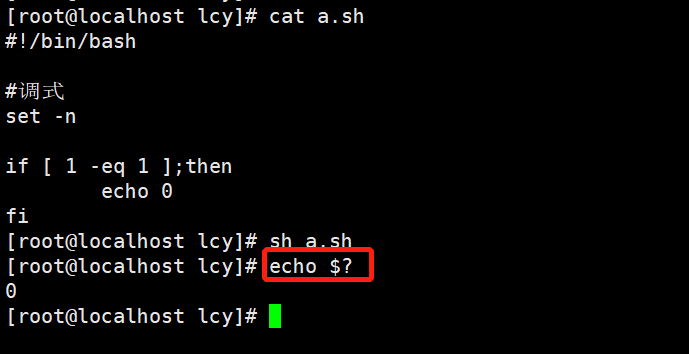
0 则为上条命令成功没有报错;
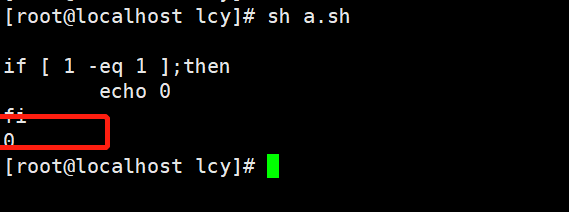
-v 一边执行脚本,一边打印脚本
#!/bin/bash
#调式
set -v
if [ 1 -eq 1 ];then
echo 0
fi
方法二:bashdb 第三方调试工具
bashdb是一个类GDB的调试工具,使用GDB的同学使用bashdb基本无障碍
bashdb可以运行断点设置、变量查看等常见调试操作 (这是非常好的一个功能)
bashdb需要单独安装
bashdb的安装
#拉取安装包
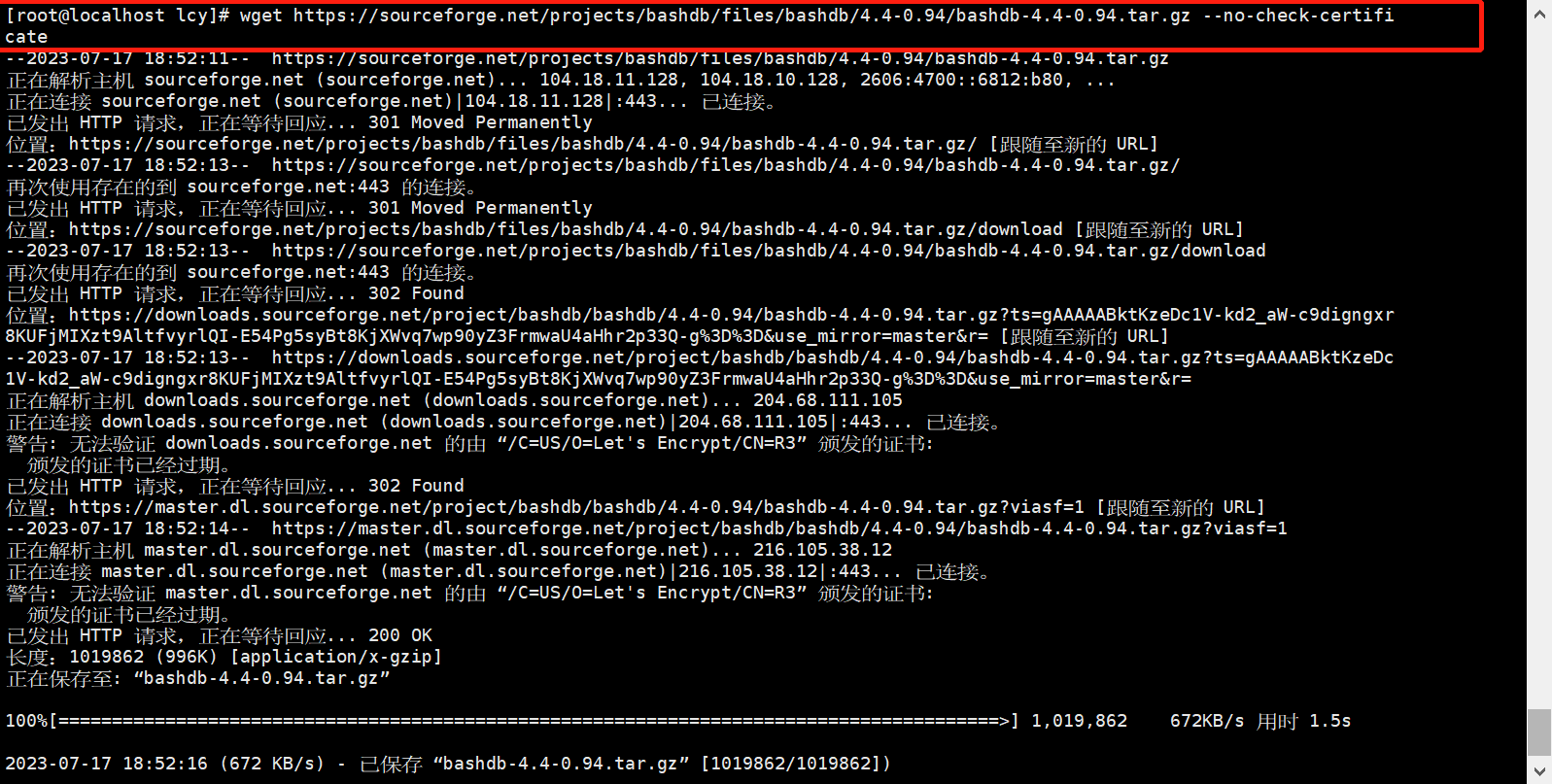
wget https://sourceforge.net/projects/bashdb/files/bashdb/4.4-0.94/bashdb-4.4-0.94.tar.gz
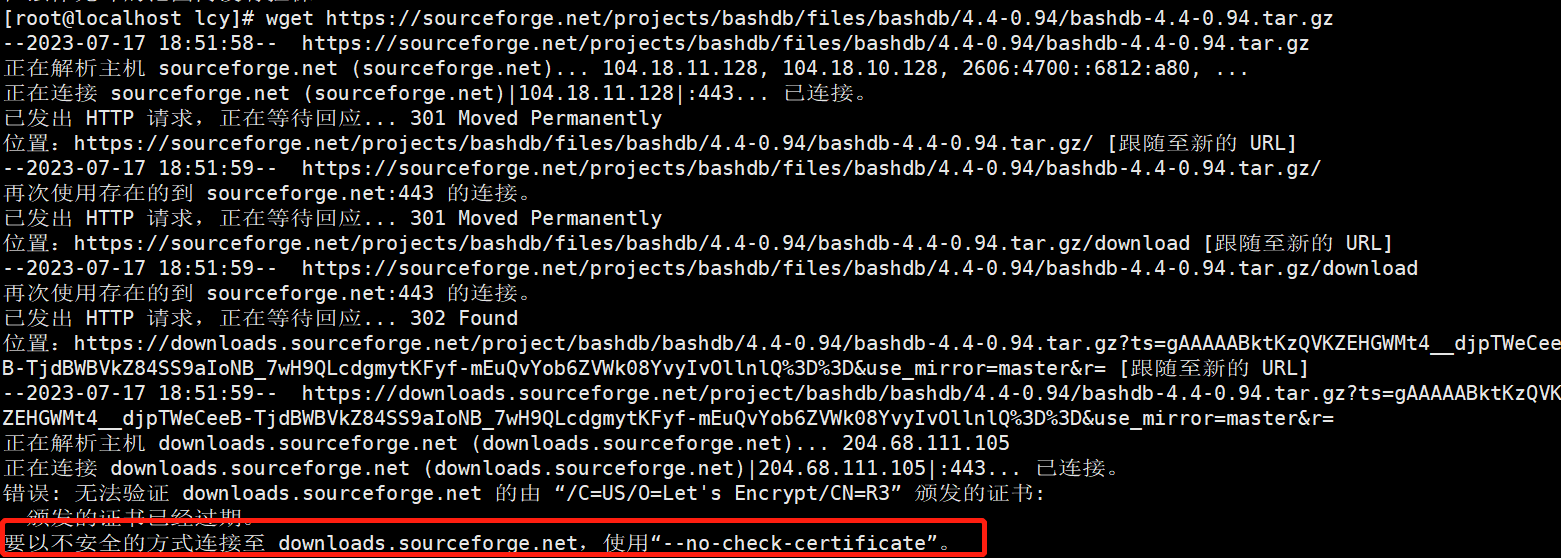
如果出现这个报错,可以在最后添加-no-check-certificate
#解压压缩包
tar xf bashdb-4.4-0.94.tar.gz
#进入解压目录
cd bashdb-4.4-0.94
#编译
./configure
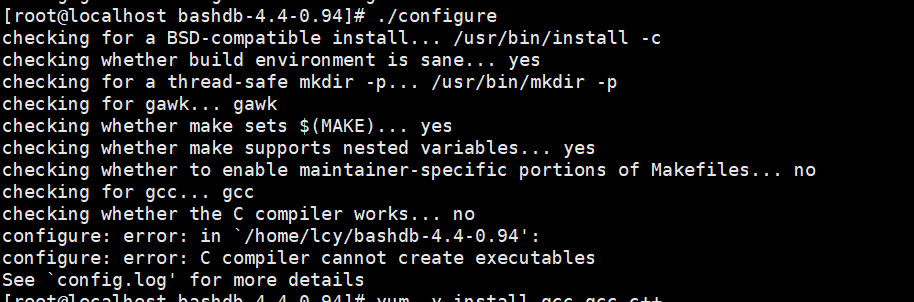
如果出现此报错,说的时没有编译环境,需要安装一下gcc gcc-c++命令,编译环境;
yum -y install gcc gcc-c++
安装完再次编译即可;
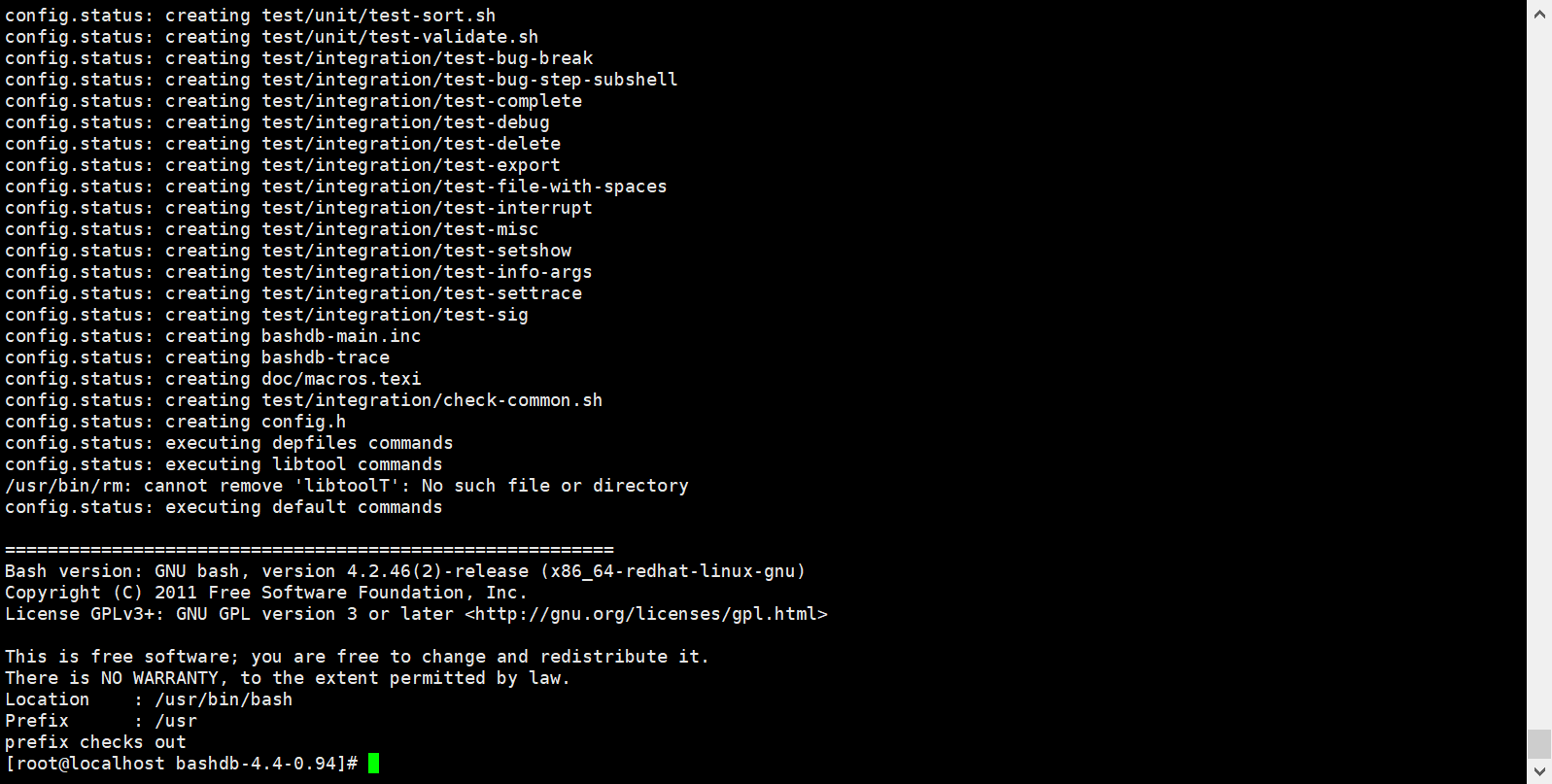
这样就编译完成了。
#安装
make && make check && make install
安装完成之后,查看版本
bashdb --version

这样就安装完成了;
bashdb的使用
使用方法:
bashdb --debug 脚本名
常用参数:
一、列出代码和查询代码类:
l 列出当前行以下的10行
- 列出正在执行的代码行的前面10行
. 回到正在执行的代码行
w 列出正在执行的代码行前后的代码
/pat/ 向后搜索pat
?pat?向前搜索pat
二、Debug控制类:
h 帮助
help 命令 得到命令的具体信息
q 退出bashdb
x 算数表达式 计算算数表达式的值,并显示出来
!! 空格Shell命令 参数 执行shell命令
使用bashdb进行debug的常用命令(cont.)
三、控制脚本执行类:
n 执行下一条语句,遇到函数,不进入函数里面执行,将函数当作黑盒
s n 单步执行n次,遇到函数进入函数里面
b 行号n 在行号n处设置断点
del 行号n 撤销行号n处的断点
c 行号n 一直执行到行号n处
R 重新启动当前调试脚本
Finish 执行到程序最后
cond n expr 条件断点
具体怎么用,我也没用过,大家可以去百度查一下;后续如果有用到的话我会补齐的!!!