可优化语句执行
- 概述
- 什么是列存储?
- 列存的优势
- 相关函数
- CopyTo
- CStoreCopyTo
- CopyState
- tupleDesc
- CStoreScanDesc
- CStoreBeginScan
- Relation
- Snapshot
- ProjectionInfo
- GetCStoreNextBatch
- RunScan
- FillVecBatch
- CStoreIsEndScan
- CStoreEndScan
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了 OpenGauss1.1.0 的开源代码
概述
本文主要围绕列存储进行学习。
什么是列存储?
列存储是一种数据库表的物理存储格式,与传统的行存储相对。在传统的行存储中,一行数据的各个列值都存储在一起,而在列存储中,表的各个列会被分别存储在不同的数据块中,这样有助于提高查询效率,特别是对于分析型查询。
列存的优势
列存储在一些特定的查询场景下具有很大的优势,尤其是在聚合、分组、过滤和连接等涉及多列的查询操作中。以下是一些列存储的优势:
- 列压缩: 列存储通常使用更高效的压缩算法,可以显著减小存储空间占用。
- 仅读取必要列: 列存储的特性使得查询时可以仅读取需要的列数据,减少不必要的磁盘 I/O。
- 向量化处理: 列存储在查询时可以进行向量化处理,即一次操作多个数据,从而提高查询效率。
- 列存储索引: 列存储可以结合列存储索引来进一步提高查询性能。
在OpenGauss中的列存储:
在OpenGauss中,CStore(Column Store)引擎是专门针对列存储技术的实现。它使用列存储格式来存储和管理表数据,适用于分析型查询,可以显著提高查询性能和数据压缩比。CStore引擎支持列压缩、向量化处理、列存储索引等特性,可以在合适的场景下取得良好的性能表现。
相关函数
CopyTo
在OpenGauss数据库中,CopyTo 函数用于将数据从数据库表或查询结果复制到文件中。它是用于执行数据库表数据导出的功能。具体而言,CopyTo 函数可以将数据以文本或二进制格式写入文件,支持多种选项和格式,例如CSV、文本、二进制等。
在 CopyTo 函数中有三个参数:
- cstate 表示复制状态;
- isFirst 表示是否是第一个批次;
- isLast 表示是否是最后一个批次。
以下为 CopyTo 函数的源代码及注释:(路径:src/gausskernel/optimizer/commands/copy.cpp)
/*
* Copy from relation or query TO file.
*/
static uint64 CopyTo(CopyState cstate, bool isFirst, bool isLast)
{
TupleDesc tupDesc; //用于存储数据库的元数据信息,包括表中的列的名称、数据类型、约束等信息
int num_phys_attrs; //用于存储表的物理属性数量,即表中的列数。(用于确定需要处理的列表的数量)
Form_pg_attribute* attr = NULL;
ListCell* cur = NULL;
uint64 processed; //用于记录处理的数据行数
#ifdef PGXC
/* Send COPY command to datanode */
if (IS_PGXC_COORDINATOR && cstate->remoteCopyState && cstate->remoteCopyState->rel_loc)
pgxc_datanode_copybegin(cstate->remoteCopyState, NULL);
#endif
if (cstate->curPartionRel) //检查当前要导出数据的关系
tupDesc = RelationGetDescr(cstate->curPartionRel); //获取关系的元数据描述符
else
tupDesc = cstate->queryDesc->tupDesc;
attr = tupDesc->attrs; // 获取元组描述符中的属性信息数组,这个数组包含了表中每个列的属性信息
num_phys_attrs = tupDesc->natts; //从给定的元组描述符 tupDesc 中获取属性的数量,存储在变量 num_phys_attrs 中,表示表中的物理列数
// 将 cstate 结构中的 null_print 字段赋值给 cstate 结构中的 null_print_client 字段
// 这里的赋值表示将默认的 null_print 值赋给客户端使用的 null_print_client
cstate->null_print_client = cstate->null_print; /* default */
/* We use fe_msgbuf as a per-row buffer regardless of copy_dest */
// 判断 fe_msgbuf 字段是否为空,即是否已经为输出创建了消息缓冲区。
if (cstate->fe_msgbuf == NULL) {
// 创建一个新的 StringInfo 结构,并将其赋值给 fe_msgbuf 字段
cstate->fe_msgbuf = makeStringInfo();
// 如果当前会话是 PGXC_COORDINATOR 或 SINGLE_NODE(单节点模式),执行以下操作
if (IS_PGXC_COORDINATOR || IS_SINGLE_NODE)
// 调用 ProcessFileHeader 函数,处理文件头信息
ProcessFileHeader(cstate);
}
/* Get info about the columns we need to process. */
//获取我们需要处理的列的信息,将其存储在'cstate->out_functions'数组中
cstate->out_functions = (FmgrInfo*)palloc(num_phys_attrs * sizeof(FmgrInfo));
foreach (cur, cstate->attnumlist) {
int attnum = lfirst_int(cur); //获取当前遍历到的属性(列)编号
Oid out_func_oid; //存储输出函数的 OID
bool isvarlena = false; //表示是否为可变长度类型
/* 判断是否为二进制复制 */
if (IS_BINARY(cstate))
/* 获取属性的二进制输出函数的 OID 和是否为可变长度类型 */
getTypeBinaryOutputInfo(attr[attnum - 1]->atttypid, &out_func_oid, &isvarlena);
else
/* 获取属性的文本输出函数的 OID 和是否为可变长度类型 */
getTypeOutputInfo(attr[attnum - 1]->atttypid, &out_func_oid, &isvarlena);
/* 通过输出函数的 OID 初始化 FmgrInfo 结构体,存储到 cstate->out_functions 数组中 */
fmgr_info(out_func_oid, &cstate->out_functions[attnum - 1]);
}
/*
* Create a temporary memory context that we can reset once per row to
* recover palloc'd memory. This avoids any problems with leaks inside
* datatype output routines, and should be faster than retail pfree's
* anyway. (We don't need a whole econtext as CopyFrom does.)
*/
cstate->rowcontext = AllocSetContextCreate(
CurrentMemoryContext, "COPY TO", ALLOCSET_DEFAULT_MINSIZE, ALLOCSET_DEFAULT_INITSIZE, ALLOCSET_DEFAULT_MAXSIZE);
// 判断数据导出方式是否为二进制
if (IS_BINARY(cstate)) {
#ifdef PGXC
if ((IS_PGXC_COORDINATOR || IS_SINGLE_NODE) && isFirst) {
#endif
/* Generate header for a binary copy */
int32 tmp;
/* Signature */
// 发送数据函数,用于向输出缓冲区发送二进制数据
CopySendData(cstate, BinarySignature, 11);
/* Flags field */
tmp = 0;
if (cstate->oids)
tmp |= (1 << 16);
CopySendInt32(cstate, tmp);
/* No header extension */
tmp = 0;
CopySendInt32(cstate, tmp);
#ifdef PGXC
/* Need to flush out the trailer */
CopySendEndOfRow<false>(cstate);
}
#endif
} else {
/*
* For non-binary copy, we need to convert null_print to file
* encoding, because it will be sent directly with CopySendString.
*/
// 判断是否需要字符编码转换
if (cstate->need_transcoding)
cstate->null_print_client =
pg_server_to_any(cstate->null_print, cstate->null_print_len, cstate->file_encoding);
/* if a header has been requested send the line */
// 如果请求了头部行,且是第一次进行复制操作,并且头部字符串不为空
if (cstate->header_line && isFirst && cstate->headerString != NULL) {
// 将头部字符串的内容追加到用于存储每行数据的缓冲区 cstate->fe_msgbuf 中
appendBinaryStringInfo(cstate->fe_msgbuf, cstate->headerString->data, cstate->headerString->len);
// 发送一行结束标记给目标
CopySendEndOfRow<true>(cstate);
}
}
#ifdef PGXC
if (IS_PGXC_COORDINATOR && cstate->remoteCopyState && cstate->remoteCopyState->rel_loc) {
RemoteCopyData* remoteCopyState = cstate->remoteCopyState;
RemoteCopyType remoteCopyType;
ExecNodes* en = NULL;
/* Set up remote COPY to correct operation */
if (cstate->copy_dest == COPY_FILE)
remoteCopyType = REMOTE_COPY_FILE;
else
remoteCopyType = REMOTE_COPY_STDOUT;
en = GetRelationNodes(remoteCopyState->rel_loc, NULL, NULL, NULL, NULL, RELATION_ACCESS_READ, false);
/*
* In case of a read from a replicated table GetRelationNodes
* returns all nodes and expects that the planner can choose
* one depending on the rest of the join tree
* Here we should choose the preferred node in the list and
* that should suffice.
* If we do not do so system crashes on
* COPY replicated_table (a, b) TO stdout;
* and this makes pg_dump fail for any database
* containing such a table.
*/
if (IsLocatorReplicated(remoteCopyState->rel_loc->locatorType))
en->nodeList = list_copy(remoteCopyState->exec_nodes->nodeList);
/*
* We don't know the value of the distribution column value, so need to
* read from all nodes. Hence indicate that the value is NULL.
*/
u_sess->cmd_cxt.dest_encoding_for_copytofile = cstate->file_encoding;
u_sess->cmd_cxt.need_transcoding_for_copytofile = cstate->need_transcoding;
processed = DataNodeCopyOut(en, remoteCopyState->connections, NULL, cstate->copy_file, NULL, remoteCopyType);
} else {
#endif
// cstate->curPartionRel 是一个指向当前处理的分区关系的指针。如果它存在,表示当前正在处理分区的数据
if (cstate->curPartionRel) {
Datum* values = NULL; // 存储元组的各个列的值
bool* nulls = NULL; // 判断属性是否为空
// 为 values 和 nulls 分配内存
values = (Datum*)palloc(num_phys_attrs * sizeof(Datum));
nulls = (bool*)palloc(num_phys_attrs * sizeof(bool));
processed = 0; // 记录已经处理的数据行数
// 判断是否是列存储表
if (RelationIsColStore(cstate->rel)) {
// 判断是否是 PAX 格式
if (RelationIsPAXFormat(cstate->rel)) {
// 调用 DFSCopyTo 进行复制操作
processed = DFSCopyTo(cstate, tupDesc, values, nulls);
} else {
// 调用 CStoreCopyTo 进行复制操作
processed = CStoreCopyTo(cstate, tupDesc, values, nulls);
}
} else {
HeapTuple tuple; // 用于存储扫描到的每行数据
TableScanDesc scandesc; // 用于表示当前数据扫描的描述符
// 开始扫描当前分区关系的数据
scandesc = scan_handler_tbl_beginscan(cstate->curPartionRel, GetActiveSnapshot(), 0, NULL);
// 通过'scan_handler_tbl_getnext'获取函数下一行数据(HeapTuple),并检查获取到的数据是否为空
while ((tuple = (HeapTuple) scan_handler_tbl_getnext(scandesc, ForwardScanDirection, cstate->curPartionRel)) != NULL) {
// 检查是否有中断请求
CHECK_FOR_INTERRUPTS();
// 将一个元组中的各列值解构(deform)出来,并存储到 values 数组中。
// 同时,它也会检查元组的每个列是否为 NULL,并将结果存储在 nulls 数组中。
// 这个函数可以高效地获取元组中的各个列值,而不需要使用多次的 heap_getattr 函数。
/* Deconstruct the tuple ... faster than repeated heap_getattr */
heap_deform_tuple2(tuple, tupDesc, values, nulls, GetTableScanDesc(scandesc, cstate->curPartionRel)->rs_cbuf);
/* Format and send the data */
// 将获取的一行数据输出到数据导出目标(cstate)中,并将处理的数据行数(processed)计数加1
CopyOneRowTo(cstate, HeapTupleGetOid(tuple), values, nulls);
processed++;
}
// 在数据扫描循环结束后,结束对当前关系表(cstate->curPartionRel)的数据扫描,释放相关资源
scan_handler_tbl_endscan(scandesc, cstate->curPartionRel);
}
pfree_ext(values);
pfree_ext(nulls);
} else {
// 导出操作时基于查询结构的数据拷贝
/* run the plan --- the dest receiver will send tuples */
// 执行查询计划,(cstate->queryDesc)是查询计划的描述符,(ForwardScanDirection)表示查询的扫描方式,0L表示查询超时时间为0,即无限制
ExecutorRun(cstate->queryDesc, ForwardScanDirection, 0L);
// 获取通过查询计划执行后的结果处理器(DR_copy)的'processed'属性值,即已处理的数据行数
processed = ((DR_copy*)cstate->queryDesc->dest)->processed;
}
#ifdef PGXC
}
#endif
#ifdef PGXC
/*
* In PGXC, it is not necessary for a Datanode to generate
* the trailer as Coordinator is in charge of it
*/
if (IS_BINARY(cstate) && IS_PGXC_COORDINATOR && isLast) {
#else
if (IS_BINARY(cstate) && isLast) {
#endif
/* Generate trailer for a binary copy */
CopySendInt16(cstate, -1);
/* Need to flush out the trailer */
CopySendEndOfRow<false>(cstate);
}
MemoryContextDelete(cstate->rowcontext);
return processed;
}
CStoreCopyTo
这里我们重点来看CStoreCopyTo函数,CStoreCopyTo 是OpenGauss数据库内部的函数,用于将数据从列存储表(Columnar Store)导出到文件。
CStoreCopyTo 函数源码及注释如下:(路径:src/gausskernel/optimizer/commands/copy.cpp)
/*
* 函数调用关系:exec_simple_query->
PortalRun->
PortalRunMulti->
PortalRunUtility->
ProcessUtility->
hypo_utility_hook->
pgaudit_ProcessUtility->
gsaudit_ProcessUtility_hook->
standard_ProcessUtility->
DoCopy->
DoCopyTo->
CopyToCompatiblePartions->
CopyTo
*
* CStoreCopyTo - CStore的CopyTo函数。
*
* 该函数用于执行COPY TO命令,将数据从数据库表复制到外部文件。它接受以下参数:
*
* cstate: 当前COPY TO命令的CopyState描述符。
* tupDesc: 目标表(关系)的TupleDesc。
* values: 数组,包含要复制的数据的值(Datum)。
* nulls: 数组,表示每个值是否为NULL的布尔值。
*
* 函数返回处理的元组数量(uint64)。
*/
static uint64 CStoreCopyTo(CopyState cstate, TupleDesc tupDesc, Datum* values, bool* nulls)
{
CStoreScanDesc scandesc; // CStoreScanDesc用于扫描列存储表。
VectorBatch* batch = NULL; // VectorBatch用于存储当前批次的数据。
int16* colIdx = (int16*)palloc0(sizeof(int16) * tupDesc->natts); // 数组用于存储目标表的列号。
FormData_pg_attribute* attrs = tupDesc->attrs; // 表属性的数组。
MemoryContext perBatchMcxt = AllocSetContextCreate(CurrentMemoryContext,
"COPY TO PER BATCH",
ALLOCSET_DEFAULT_MINSIZE,
ALLOCSET_DEFAULT_INITSIZE,
ALLOCSET_DEFAULT_MAXSIZE); // 用于每个批次的临时数据的内存上下文。
uint64 processed = 0; // 变量用于存储处理的元组数量。
// 使用目标表的属性号填充列索引数组。
for (int i = 0; i < tupDesc->natts; i++)
colIdx[i] = attrs[i].attnum;
// 初始化CStoreScanDesc以扫描列存储表。
scandesc = CStoreBeginScan(cstate->curPartionRel, tupDesc->natts, colIdx, GetActiveSnapshot(), true);
// 循环遍历列存储表,并以批次方式处理数据。
do {
batch = CStoreGetNextBatch(scandesc);
// 将数据批次batch中的数据解析为元组,并将解析后的数据存储在values和nulls数组中。
// DeformCopyTuple函数用于执行这一操作,其中perBatchMcxt是每个批次的临时数据内存上下文,
// cstate是当前COPY TO命令的描述符,tupDesc是目标表的TupleDesc,
// values和nulls分别是存储解析后数据的值和NULL信息的数组。
DeformCopyTuple(perBatchMcxt, cstate, batch, tupDesc, values, nulls);
processed += batch->m_rows;
} while (!CStoreIsEndScan(scandesc));
// 结束CStore扫描并删除内存上下文。
CStoreEndScan(scandesc);
MemoryContextDelete(perBatchMcxt);
return processed;
}
CopyState
CStoreCopyTo 函数中传入的 CopyState 结构体是用于在 COPY TO 操作期间跟踪和管理复制操作的上下文信息的数据结构。在 PostgreSQL 数据库中,CopyState 结构体用于处理 COPY 命令的输入和输出,它包含了执行 COPY 操作所需的各种参数和状态信息。
源码如下:(路径:src/include/commands/copy.h)
typedef struct CopyStateData* CopyState;
/*
* This struct contains all the state variables used throughout a COPY
* operation. For simplicity, we use the same struct for all variants of COPY,
* even though some fields are used in only some cases.
*
* Multi-byte encodings: all supported client-side encodings encode multi-byte
* characters by having the first byte's high bit set. Subsequent bytes of the
* character can have the high bit not set. When scanning data in such an
* encoding to look for a match to a single-byte (ie ASCII) character, we must
* use the full pg_encoding_mblen() machinery to skip over multibyte
* characters, else we might find a false match to a trailing byte. In
* supported server encodings, there is no possibility of a false match, and
* it's faster to make useless comparisons to trailing bytes than it is to
* invoke pg_encoding_mblen() to skip over them. encoding_embeds_ascii is TRUE
* when we have to do it the hard way.
*/
typedef struct CopyStateData {
/* low-level state data */
CopyDest copy_dest; /* type of copy source/destination */
bool is_from; /* Is this a Copy From or Copy To? */
FILE* copy_file; /* used if copy_dest == COPY_FILE */
StringInfo fe_msgbuf; /* used for all dests during COPY TO, only for
* dest == COPY_NEW_FE in COPY FROM */
bool fe_eof; /* true if detected end of copy data */
EolType eol_type; /* EOL type of input */
int file_encoding; /* file or remote side's character encoding */
bool need_transcoding; /* file encoding diff from server? */
bool encoding_embeds_ascii; /* ASCII can be non-first byte? */
/* parameters from the COPY command */
Relation rel; /* relation to copy to or from */
Relation curPartionRel; /* current partion to copy to*/
QueryDesc* queryDesc; /* executable query to copy from */
List* attnumlist; /* integer list of attnums to copy */
char* filename; /* filename, or NULL for STDIN/STDOUT */
char* null_print; /* NULL marker string (server encoding!) */
char* delim; /* column delimiter (must be no more than 10 bytes) */
int null_print_len; /* length of same */
int delim_len;
char* null_print_client; /* same converted to file encoding */
char* quote; /* CSV quote char (must be 1 byte) */
char* escape; /* CSV escape char (must be 1 byte) */
char* eol; /* user defined EOL string */
List* force_quote; /* list of column names */
bool* force_quote_flags; /* per-column CSV FQ flags */
List* force_notnull; /* list of column names */
bool* force_notnull_flags; /* per-column CSV FNN flags */
user_time_format date_format; /* user-defined date format */
user_time_format time_format; /* user-defined time format */
user_time_format timestamp_format; /* user-defined timestamp format */
user_time_format smalldatetime_format; /* user-defined smalldatetime format */
/* the flag used to control whether illegal characters can be fault-tolerant or not */
bool compatible_illegal_chars;
bool oids; /* include OIDs? */
bool freeze;
bool header_line; /* CSV header line? */
bool force_quote_all; /* FORCE QUOTE *? */
bool without_escaping;
/* these are just for error messages, see CopyFromErrorCallback */
const char* cur_relname; /* table name for error messages */
uint32 cur_lineno; /* line number for error messages */
const char* cur_attname; /* current att for error messages */
const char* cur_attval; /* current att value for error messages */
/*
* Working state for COPY TO/FROM
*/
MemoryContext copycontext; /* per-copy execution context */
/*
* Working state for COPY TO
*/
FmgrInfo* out_functions; /* lookup info for output functions */
MemoryContext rowcontext; /* per-row evaluation context */
/*
* Working state for COPY FROM
*/
AttrNumber num_defaults;
bool file_has_oids;
FmgrInfo oid_in_function;
Oid oid_typioparam;
FmgrInfo* in_functions; /* array of input functions for each attrs */
Oid* typioparams; /* array of element types for in_functions */
bool* accept_empty_str; /* is type of each column can accept empty string? */
int* defmap; /* array of default att numbers */
ExprState** defexprs; /* array of default att expressions */
bool volatile_defexprs; /* is any of defexprs volatile? */
List* range_table;
Datum copy_beginTime; /* log the query start time*/
bool log_errors; /* mark where we tolerate data exceptions and log them into copy_error_log */
int reject_limit; /* number of data exceptions we allow per Copy (on coordinator) */
bool logErrorsData; /* mark where we tolerate data exceptions and log them into copy_error_log and make sure
Whether to fill the rowrecord field of the copy_error_log*/
Relation err_table; /* opened copy_error_log table */
CopyErrorLogger* logger; /* logger used for copy from error logging*/
FmgrInfo* err_out_functions; /* lookup info for output functions of copy_error_log*/
/*
* These variables are used to reduce overhead in textual COPY FROM.
*
* attribute_buf holds the separated, de-escaped text for each field of
* the current line. The CopyReadAttributes functions return arrays of
* pointers into this buffer. We avoid palloc/pfree overhead by re-using
* the buffer on each cycle.
*/
StringInfoData attribute_buf;
/* field raw data pointers found by COPY FROM */
int max_fields;
char** raw_fields;
/*
* Similarly, line_buf holds the whole input line being processed. The
* input cycle is first to read the whole line into line_buf, convert it
* to server encoding there, and then extract the individual attribute
* fields into attribute_buf. line_buf is preserved unmodified so that we
* can display it in error messages if appropriate.
*/
StringInfoData line_buf;
bool line_buf_converted; /* converted to server encoding? */
/*
* Finally, raw_buf holds raw data read from the data source (file or
* client connection). CopyReadLine parses this data sufficiently to
* locate line boundaries, then transfers the data to line_buf and
* converts it. Note: we guarantee that there is a \0 at
* raw_buf[raw_buf_len].
*/
#define RAW_BUF_SIZE 65536 /* we palloc RAW_BUF_SIZE+1 bytes */
char* raw_buf;
int raw_buf_index; /* next byte to process */
int raw_buf_len; /* total # of bytes stored */
PageCompress* pcState;
#ifdef PGXC
/* Remote COPY state data */
RemoteCopyData* remoteCopyState;
#endif
bool fill_missing_fields;
bool ignore_extra_data; /* ignore overflowing fields */
Formatter* formatter;
FileFormat fileformat;
char* headerFilename; /* User define header filename */
char* out_filename_prefix;
char* out_fix_alignment;
StringInfo headerString;
/* For bulkload*/
BulkLoadStream* io_stream;
List* file_list;
ListCell* file_index;
ImportMode mode;
List* taskList;
ListCell* curTaskPtr;
long curReadOffset;
BulkLoadFunc bulkLoadFunc;
CopyGetDataFunc copyGetDataFunc;
CopyReadlineFunc readlineFunc;
CopyReadAttrsFunc readAttrsFunc;
GetNextCopyFunc getNextCopyFunc;
stringinfo_pointer inBuffer;
uint32 distSessionKey;
List* illegal_chars_error; /* used to record every illegal_chars_error for each imported data line. */
bool isExceptionShutdown; /* To differentiate normal end of a bulkload task or a task abort because of exceptions*/
// For export
//
uint64 distCopyToTotalSize;
CopyWriteLineFunc writelineFunc;
bool remoteExport;
StringInfo outBuffer;
// For Roach
void* roach_context;
Node* roach_routine;
// For OBS parallel import/export
ObsCopyOptions obs_copy_options;
/* adaptive memory assigned for the stmt */
AdaptMem memUsage;
} CopyStateData;
调试信息如下:


tupleDesc
来看看 CStoreCopyTo 函数的入参 tupleDesc 结构体。这个结构体的作用是描述数据库中元组(tuple)的结构。它包含了元组的属性数量、每个属性的描述信息、约束信息、默认值等。通过 TupleDesc 结构体,可以获取关于元组的各种信息,比如属性的数据类型、是否包含 OID 属性等。这个结构体在数据库内部被广泛用于处理元组的元数据以及元组数据的访问和操作。它在数据库系统中的元数据管理、查询优化和执行计划生成等方面都起着重要的作用。
/*
* This struct is passed around within the backend to describe the structure
* of tuples. For tuples coming from on-disk relations, the information is
* collected from the pg_attribute, pg_attrdef, and pg_constraint catalogs.
* Transient row types (such as the result of a join query) have anonymous
* TupleDesc structs that generally omit any constraint info; therefore the
* structure is designed to let the constraints be omitted efficiently.
*
* Note that only user attributes, not system attributes, are mentioned in
* TupleDesc; with the exception that tdhasoid indicates if OID is present.
*
* If the tupdesc is known to correspond to a named rowtype (such as a table's
* rowtype) then tdtypeid identifies that type and tdtypmod is -1. Otherwise
* tdtypeid is RECORDOID, and tdtypmod can be either -1 for a fully anonymous
* row type, or a value >= 0 to allow the rowtype to be looked up in the
* typcache.c type cache.
*
* Tuple descriptors that live in caches (relcache or typcache, at present)
* are reference-counted: they can be deleted when their reference count goes
* to zero. Tuple descriptors created by the executor need no reference
* counting, however: they are simply created in the appropriate memory
* context and go away when the context is freed. We set the tdrefcount
* field of such a descriptor to -1, while reference-counted descriptors
* always have tdrefcount >= 0.
*/
typedef struct tupleDesc {
// 用于访问单例 TableAccessorMethods 中的 Table Accessor 方法的索引
TableAmType tdTableAmType; /*index for accessing the Table Accessor methods on singleton TableAccessorMethods */
// 元组中属性的数量
int natts; /* number of attributes in the tuple */
// 是否为由 Redis 工具创建的用于数据重新分发的临时表
bool tdisredistable; /* temp table created for data redistribution by the redis tool */
// attrs[N] 是指向第 N+1 个属性描述的指针
Form_pg_attribute* attrs;
/* attrs[N] is a pointer to the description of Attribute Number N+1 */
// 约束信息,如果没有则为 NULL
TupleConstr* constr; /* constraints, or NULL if none */
// 由 ADD COLUMN 引起的初始化默认值
TupInitDefVal* initdefvals; /* init default value due to ADD COLUMN */
// 元组类型的复合类型 ID
Oid tdtypeid; /* composite type ID for tuple type */
// 元组类型的类型修饰符
int32 tdtypmod; /* typmod for tuple type */
// 元组头部是否有 OID 属性
bool tdhasoid; /* tuple has oid attribute in its header */
// 引用计数,如果不计数则为 -1
int tdrefcount; /* reference count, or -1 if not counting */
} * TupleDesc;
调试信息如下:

CStoreScanDesc
在 CStoreCopyTo 函数中,可以看到首先创建了一个 CStoreScanDesc 结构体变量 scandesc ,我们来看一看 CStoreScanDesc 结构体的内容吧:
struct CStoreScanState;
typedef CStoreScanState *CStoreScanDesc;
typedef CStoreScanState *CStoreScanDesc;:这是一个类型定义语句,它将指向 CStoreScanState 结构体的指针类型取名为 CStoreScanDesc。这样,在后续的代码中,可以使用 CStoreScanDesc 来声明变量,就等同于声明一个指向 CStoreScanState 结构体的指针。
CStoreScanState 结构体用于存储列存储扫描的各种状态和相关信息,包括扫描关系、扫描描述符、数据批次、扫描键等,以支持列存储的高效数据扫描操作。源码如下所示。
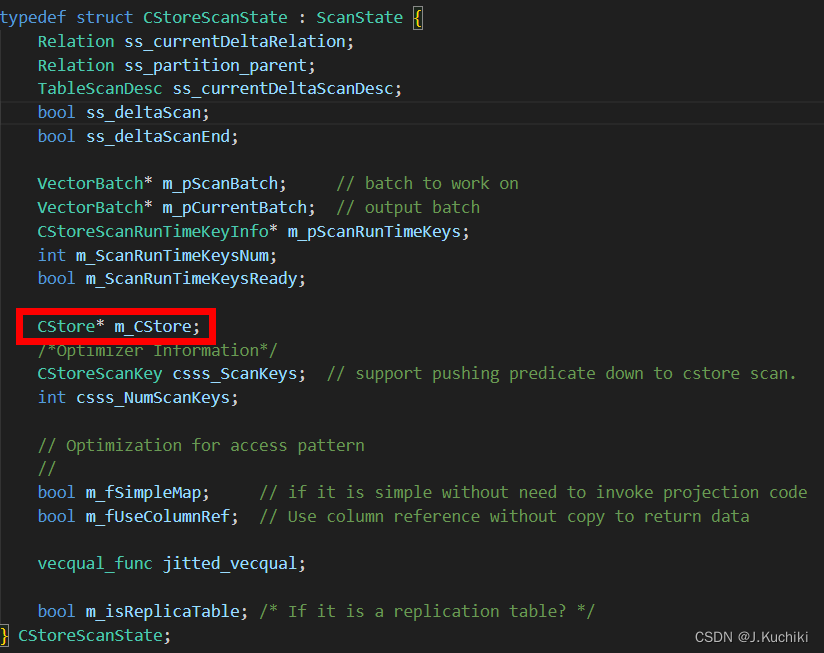
typedef struct CStoreScanState : ScanState {
Relation ss_currentDeltaRelation; //表示当前处理的增量表的关系(Relation)。
Relation ss_partition_parent; //表示当前分区表的父表的关系(Relation)。
TableScanDesc ss_currentDeltaScanDesc; //当前增量表的扫描描述符。
bool ss_deltaScan; //表示是否正在进行增量表的扫描。
bool ss_deltaScanEnd; //表示增量表的扫描是否已结束。
VectorBatch* m_pScanBatch; // batch to work on 用于扫描时存储读取的数据的向量批次。
VectorBatch* m_pCurrentBatch; // output batch 用于存储当前批次的向量数据,通常用于输出。
CStoreScanRunTimeKeyInfo* m_pScanRunTimeKeys; //运行时扫描键的信息,用于支持运行时扫描过滤条件。
int m_ScanRunTimeKeysNum; //运行时扫描键的数量。
bool m_ScanRunTimeKeysReady; //标志,表示运行时扫描键是否已准备好。
CStore* m_CStore; //指向列存储对象的指针,用于执行列存储的扫描操作。
/*Optimizer Information*/
CStoreScanKey csss_ScanKeys; // support pushing predicate down to cstore scan. 用于支持将谓词下推到 CStore 扫描的扫描键。
int csss_NumScanKeys; //扫描键的数量。
// Optimization for access pattern
//
bool m_fSimpleMap; // if it is simple without need to invoke projection code 表示扫描是否具有简单的映射,无需调用投影代码。
bool m_fUseColumnRef; // Use column reference without copy to return data 表示是否使用列引用(Column Reference)而不是进行数据复制来返回数据。
vecqual_func jitted_vecqual; //用于进行向量化的谓词评估的函数指针。
bool m_isReplicaTable; /* If it is a replication table? */ //表示是否为副本表。
} CStoreScanState;
通过调试可以打印出 scandesc 的内容:

接着我们再来看看 VectorBatch 的数据结构,VectorBatch 在 opengauss 中被广泛用于处理和传递批量的列数据。
VectorBatch 源码如下:(路径:src/include/vecexecutor/vectorbatch.h)
// A batch of vectorize rows
//
class VectorBatch : public BaseObject {
public:
// number of rows in the batch.
//
int m_rows;
// number of columns in the batch.
//
int m_cols;
// Shall we check the selection vector.
//
bool m_checkSel;
// Selection vector;
//
bool* m_sel;
// ScalarVector
//
ScalarVector* m_arr;
// SysColumns
//
SysColContainer* m_sysColumns;
// Compress buffer
//
StringInfo m_pCompressBuf;
public:
// Many Constructors
//
VectorBatch(MemoryContext cxt, TupleDesc desc);
VectorBatch(MemoryContext cxt, VectorBatch* batch);
VectorBatch(MemoryContext cxt, ScalarDesc* desc, int ncols);
// Deconstructor.
//
~VectorBatch();
// Serialize the particular data index of the batch into the buffer.
//
void Serialize(StringInfo buf, int idx);
// Deserialze the per-row msg into the batch
//
void Deserialize(char* msg);
// Serialize the batch into the buffer without compress.
//
void SerializeWithoutCompress(StringInfo buf);
// Deserialze the msg into the batch without compress.
//
void DeserializeWithoutDecompress(char* msg, size_t msglen);
// Serialize the batch into the buffer with lz4 compress.
//
void SerializeWithLZ4Compress(StringInfo buf);
// Deserialze the compressed msg into the batch with lz4 compress.
//
void DeserializeWithLZ4Decompress(char* msg, size_t msglen);
// Reset
//
void Reset(bool resetflag = false);
void ResetSelection(bool value);
// Test the batch is valid or not
//
bool IsValid();
void FixRowCount();
void FixRowCount(int rows);
// Pack the batch
//
void Pack(const bool* sel);
/* Optimzed Pack function */
void OptimizePack(const bool* sel, List* CopyVars);
/* Optimzed Pack function for later read. later read cols and ctid col*/
void OptimizePackForLateRead(const bool* sel, List* lateVars, int ctidColIdx);
// SysColumns
//
void CreateSysColContainer(MemoryContext cxt, List* sysVarList);
ScalarVector* GetSysVector(int sysColIdx);
int GetSysColumnNum();
template <bool deep, bool add>
void Copy(VectorBatch* batch, int start_idx = 0, int endIdx = -1);
void CopyNth(VectorBatch* batchSrc, int Nth);
public:
/* Pack template function. */
template <bool copyMatch, bool hasSysCol>
void PackT(_in_ const bool* sel);
/* Optimize template function. */
template <bool copyMatch, bool hasSysCol>
void OptimizePackT(_in_ const bool* sel, _in_ List* CopyVars);
/* Optimize template function for later read. */
template <bool copyMatch, bool hasSysCol>
void OptimizePackTForLateRead(_in_ const bool* sel, _in_ List* lateVars, int ctidColIdx);
private:
// init the vectorbatch.
void init(MemoryContext cxt, TupleDesc desc);
void init(MemoryContext cxt, VectorBatch* batch);
void init(MemoryContext cxt, ScalarDesc* desc, int ncols);
};
通过调试可以打印出 batch 的内容:

CStoreBeginScan
CStoreBeginScan 函数的作用是初始化一个用于扫描列存储表分区的扫描描述符(CStoreScanDesc),以便在数据复制操作中获取分区表的数据。这个函数设置了一些必要的信息,以便在扫描过程中访问和读取分区表中的数据。
以下是 CStoreBeginScan 函数的入参及其意义:
- cstate->curPartionRel:当前正在处理的分区关系(表的一个分区)。这是一个 Relation 类型的指针,表示正在进行 COPY 操作的分区表。
- tupDesc->natts:元组描述符 tupDesc 中的属性数量。表示分区表的属性数量,即分区表的列数。
- colIdx:用于指定需要处理的列索引,即要进行数据复制的列的索引。在分区表中,每个分区的列索引可能不同,这个参数可以帮助指定需要处理的列。
- GetActiveSnapshot():获取当前活动的快照,用于查询当前数据的一致性视图。
- true:一个布尔值,表示是否要开始列存储表的扫描。在这里设置为 true,表示开始实际的列存储扫描操作。
// CStoreHeapBeginScan - 开始CStore表的扫描
// 初始化CStoreScanDesc数据结构
CStoreScanDesc CStoreBeginScan(Relation relation, int colNum, int16* colIdx, Snapshot snapshot, bool scanDelta)
{
Assert(colNum > 0 && colIdx);
// 步骤1:创建CStoreScanState结构
CStoreScanDesc scanstate;
scanstate = makeNode(CStoreScanState);
scanstate->ps.plan = (Plan*)makeNode(CStoreScan); // 创建计划节点CStoreScan
scanstate->ps.ps_ProjInfo = makeNode(ProjectionInfo); // 创建投影信息节点ProjectionInfo
ProjectionInfo* projInfo = scanstate->ps.ps_ProjInfo; // 获取投影信息节点的指针
// 步骤2:构造被访问的列
List *accessAttrList = NULL; // 被访问的列索引列表
List *sysAttrList = NULL; // 系统列索引列表
for (int i = 0; i < colNum; ++i) {
/* 被删除的列和非系统列不访问 */
if (colIdx[i] >= 0 && relation->rd_att->attrs[colIdx[i] - 1].attisdropped)
continue;
// 检查给定的列索引是否为正常的用户列索引。如果大于等于 0,则表示是用户列索引,否则是系统列索引。
if (colIdx[i] >= 0)
// accessAttrList:这是一个整数列表,用于存储正常的用户列索引。lappend_int 函数用于将列索引添加到这个列表中。
accessAttrList = lappend_int(accessAttrList, colIdx[i]);
else
// sysAttrList:这是另一个整数列表,用于存储系统列索引。同样,lappend_int 函数也用于将系统列索引添加到这个列表中。
sysAttrList = lappend_int(sysAttrList, colIdx[i]);
}
projInfo->pi_acessedVarNumbers = accessAttrList; // 设置访问的列索引列表
projInfo->pi_sysAttrList = sysAttrList; // 设置系统列索引列表
projInfo->pi_const = false; // 投影信息节点不包含常量
// 步骤3:初始化CStoreScan
scanstate->ss_currentRelation = relation; // 设置当前扫描的关系
scanstate->csss_NumScanKeys = 0; // 扫描键的数量初始化为0
scanstate->csss_ScanKeys = NULL; // 扫描键数组初始化为空
/*
* 在扫描关系期间增加关系引用计数
*
* 这只是为了确保在扫描指向它的指针时,关系缓存条目不会被释放。调用者应该在任何正常的情况下都保持关系打开状态,因此这在所有正常情况下都是冗余的...
*/
RelationIncrementReferenceCount(relation); // 增加关系引用计数,防止在扫描期间关系被释放
scanstate->m_CStore = New(CurrentMemoryContext) CStore(); // 在当前内存上下文中创建CStore对象
scanstate->m_CStore->InitScan(scanstate, snapshot); // 初始化CStore扫描
// 步骤4:初始化scanBatch
scanstate->m_pScanBatch =
New(CurrentMemoryContext) VectorBatch(CurrentMemoryContext, scanstate->ss_currentRelation->rd_att); // 在当前内存上下文中创建VectorBatch对象
if (projInfo->pi_sysAttrList)
scanstate->m_pScanBatch->CreateSysColContainer(CurrentMemoryContext, projInfo->pi_sysAttrList); // 如果存在系统列,为其创建容器
// 步骤5:初始化delta扫描
if (scanDelta) { // 如果需要进行delta扫描
scanstate->ss_ScanTupleSlot = MakeTupleTableSlot(); // 创建TupleTableSlot用于扫描tuple
ExprContext* econtext = makeNode(ExprContext); // 创建表达式上下文
econtext->ecxt_per_tuple_memory = AllocSetContextCreate(CurrentMemoryContext,
"cstore delta scan",
ALLOCSET_DEFAULT_MINSIZE,
ALLOCSET_DEFAULT_INITSIZE,
ALLOCSET_DEFAULT_MAXSIZE); // 创建用于扫描的内存上下文
scanstate->ps.ps_ExprContext = econtext; // 设置表达式上下文
InitScanDeltaRelation(scanstate, (snapshot != NULL ? snapshot : GetActiveSnapshot())); // 初始化delta扫描关系
} else { // 如果
scanstate->ss_currentDeltaRelation = NULL; // 表示当前没有增量表
scanstate->ss_currentDeltaScanDesc = NULL; // 表示当前没有增量扫描描述符
scanstate->ss_deltaScan = false; // 表示当前不再进行增量扫描
scanstate->ss_deltaScanEnd = true; // 表示增量扫描结束
}
return scanstate;
}
这里解释一下这段代码:
scanstate->ps.ps_ExprContext = econtext;的作用
scanstate->ps.ps_ExprContext = econtext;这行代码的作用是将一个执行节点(scanstate)的表达式上下文(Expression Context)设置为给定的上下文(econtext)。这个操作在查询执行的过程中是非常常见的,它有着重要的意义。
表达式上下文是一个关键的数据结构,用于在执行查询过程中计算和管理表达式的计算结果。在查询执行过程中,需要对各种表达式进行求值,包括从表中选择列、进行计算等等。这些表达式在执行过程中会产生临时数据,而这些数据需要在正确的上下文中进行内存管理,以避免内存泄漏或者错误的内存访问。
scanstate->ps.ps_ExprContext的设置就是为了让执行节点知道在哪个上下文中进行表达式的求值,并在适当的时候进行内存分配和释放。通过将表达式上下文与执行节点关联起来,可以确保在执行查询过程中,产生的临时数据都在正确的上下文中进行内存分配,当不再需要时能够被正确地释放。
Relation
Relation 结构体在数据库系统中的作用是表示数据库中的一个关系(表、索引、视图等)。它是 PostgreSQL 中管理表、索引等对象的关键数据结构之一。
typedef struct RelationData* Relation;
Relation 的源码如下:(路径:src/include/utils/rel.h)
/*
* Here are the contents of a relation cache entry.
*/
typedef struct RelationData {
RelFileNode rd_node; /* relation physical identifier */
/* use "struct" here to avoid needing to include smgr.h: */
struct SMgrRelationData* rd_smgr; /* cached file handle, or NULL */
int rd_refcnt; /* reference count */
BackendId rd_backend; /* owning backend id, if temporary relation */
bool rd_isscannable; /* rel can be scanned */
bool rd_isnailed; /* rel is nailed in cache */
bool rd_isvalid; /* relcache entry is valid */
char rd_indexvalid; /* state of rd_indexlist: 0 = not valid, 1 =
* valid, 2 = temporarily forced */
bool rd_islocaltemp; /* rel is a temp rel of this session */
/*
* rd_createSubid is the ID of the highest subtransaction the rel has
* survived into; or zero if the rel was not created in the current top
* transaction. This should be relied on only for optimization purposes;
* it is possible for new-ness to be "forgotten" (eg, after CLUSTER).
* Likewise, rd_newRelfilenodeSubid is the ID of the highest
* subtransaction the relfilenode change has survived into, or zero if not
* changed in the current transaction (or we have forgotten changing it).
*/
SubTransactionId rd_createSubid; /* rel was created in current xact */
SubTransactionId rd_newRelfilenodeSubid; /* new relfilenode assigned in
* current xact */
Form_pg_class rd_rel; /* RELATION tuple */
TupleDesc rd_att; /* tuple descriptor */
Oid rd_id; /* relation's object id */
LockInfoData rd_lockInfo; /* lock mgr's info for locking relation */
RuleLock* rd_rules; /* rewrite rules */
MemoryContext rd_rulescxt; /* private memory cxt for rd_rules, if any */
TriggerDesc* trigdesc; /* Trigger info, or NULL if rel has none */
/* use "struct" here to avoid needing to include rewriteRlsPolicy.h */
struct RlsPoliciesDesc* rd_rlsdesc; /* Row level security policies, or NULL */
/* data managed by RelationGetIndexList: */
List* rd_indexlist; /* list of OIDs of indexes on relation */
Oid rd_oidindex; /* OID of unique index on OID, if any */
Oid rd_refSynOid; /* OID of referenced synonym Oid, if mapping indeed. */
/* data managed by RelationGetIndexAttrBitmap: */
Bitmapset* rd_indexattr; /* identifies columns used in indexes */
Bitmapset* rd_idattr; /* included in replica identity index */
/*
* The index chosen as the relation's replication identity or
* InvalidOid. Only set correctly if RelationGetIndexList has been
* called/rd_indexvalid > 0.
*/
Oid rd_replidindex;
/*
* rd_options is set whenever rd_rel is loaded into the relcache entry.
* Note that you can NOT look into rd_rel for this data. NULL means "use
* defaults".
*/
bytea* rd_options; /* parsed pg_class.reloptions */
/* These are non-NULL only for an index relation: */
Oid rd_partHeapOid; /* partition index's partition oid */
Form_pg_index rd_index; /* pg_index tuple describing this index */
/* use "struct" here to avoid needing to include htup.h: */
struct HeapTupleData* rd_indextuple; /* all of pg_index tuple */
Form_pg_am rd_am; /* pg_am tuple for index's AM */
int rd_indnkeyatts; /* index relation's indexkey nums */
TableAmType rd_tam_type; /*Table accessor method type*/
/*
* index access support info (used only for an index relation)
*
* Note: only default support procs for each opclass are cached, namely
* those with lefttype and righttype equal to the opclass's opcintype. The
* arrays are indexed by support function number, which is a sufficient
* identifier given that restriction.
*
* Note: rd_amcache is available for index AMs to cache private data about
* an index. This must be just a cache since it may get reset at any time
* (in particular, it will get reset by a relcache inval message for the
* index). If used, it must point to a single memory chunk palloc'd in
* rd_indexcxt. A relcache reset will include freeing that chunk and
* setting rd_amcache = NULL.
*/
MemoryContext rd_indexcxt; /* private memory cxt for this stuff */
RelationAmInfo* rd_aminfo; /* lookup info for funcs found in pg_am */
Oid* rd_opfamily; /* OIDs of op families for each index col */
Oid* rd_opcintype; /* OIDs of opclass declared input data types */
RegProcedure* rd_support; /* OIDs of support procedures */
FmgrInfo* rd_supportinfo; /* lookup info for support procedures */
int16* rd_indoption; /* per-column AM-specific flags */
List* rd_indexprs; /* index expression trees, if any */
List* rd_indpred; /* index predicate tree, if any */
Oid* rd_exclops; /* OIDs of exclusion operators, if any */
Oid* rd_exclprocs; /* OIDs of exclusion ops' procs, if any */
uint16* rd_exclstrats; /* exclusion ops' strategy numbers, if any */
void* rd_amcache; /* available for use by index AM */
Oid* rd_indcollation; /* OIDs of index collations */
/*
* foreign-table support
*
* rd_fdwroutine must point to a single memory chunk palloc'd in
* t_thrd.mem_cxt.cache_mem_cxt. It will be freed and reset to NULL on a relcache
* reset.
*/
/* use "struct" here to avoid needing to include fdwapi.h: */
struct FdwRoutine* rd_fdwroutine; /* cached function pointers, or NULL */
/*
* Hack for CLUSTER, rewriting ALTER TABLE, etc: when writing a new
* version of a table, we need to make any toast pointers inserted into it
* have the existing toast table's OID, not the OID of the transient toast
* table. If rd_toastoid isn't InvalidOid, it is the OID to place in
* toast pointers inserted into this rel. (Note it's set on the new
* version of the main heap, not the toast table itself.) This also
* causes toast_save_datum() to try to preserve toast value OIDs.
*/
Oid rd_toastoid; /* Real TOAST table's OID, or InvalidOid */
Oid rd_bucketoid;/* bucket OID in pg_hashbucket*/
/*bucket key info, indicating which keys are used to comoute hash value */
RelationBucketKey *rd_bucketkey;
/* For 1-level hash table, it points into a HashBucketMap instances;
* For 2-level hash table, e.g. range-hash, it points into a RangePartitionMap
* instances. */
PartitionMap* partMap;
Oid parentId; /*if this is construct by partitionGetRelation,this is Partition Oid,else this is InvalidOid*/
/* use "struct" here to avoid needing to include pgstat.h: */
struct PgStat_TableStatus* pgstat_info; /* statistics collection area */
#ifdef PGXC
RelationLocInfo* rd_locator_info;
PartitionMap* sliceMap;
#endif
Relation parent;
/* double linked list node, partition and bucket relation would be stored in fakerels list of resource owner */
dlist_node node;
Oid rd_mlogoid;
} RelationData;
调试打印 relation 结构如下:

详细解释一下这段代码:
relation->rd_att->attrs[colIdx[i] - 1]->attisdropped
relation->rd_att->attrs[colIdx[i] - 1]->attisdropped是在检查一个给定列是否被标记为 “已删除”(dropped)的属性。在 PostgreSQL 中,当表的结构发生变化(例如删除列)时,并不会立即从表的元数据中移除被删除的列,而是将这些列标记为 “已删除” 状态。这是为了支持一些特定的操作,例如还原(rollback)以及保持系统表的一致性。
下面是代码的分解解释:
- relation:一个表示关系(表)的 Relation 结构体。
- rd_att:在 Relation 结构体中的一个成员,表示关系的元数据信息,包括列定义等。
- attrs:rd_att 中的一个数组,存储了所有列的属性信息,每个元素是一个 Form_pg_attribute 结构体,描述了该列的元信息。
- colIdx[i]:一个索引值,用于访问 attrs 数组中的某个元素,表示第 i 个要操作的列。
- attisdropped:Form_pg_attribute 结构体中的一个成员,表示该列是否被标记为 “已删除”。
所以,这段代码的作用是检查给定列索引 colIdx[i] 对应的列是否被标记为 “已删除”,即检查该列的 attisdropped 属性的值。如果该值为 true,则说明该列已被删除,否则为 false。
Snapshot
这个结构体表示不同类型的快照(Snapshot),快照是用于实现多版本并发控制(MVCC)的关键概念。MVCC 允许多个事务同时访问数据库,而不会相互干扰,每个事务看到的数据状态是独立的。
Snapshot 的源码如下:(路径:src/include/utils/snapshot.h)
typedef struct SnapshotData* Snapshot;
/*
* Struct representing all kind of possible snapshots.
*
* There are several different kinds of snapshots:
* * Normal MVCC snapshots
* * MVCC snapshots taken during recovery (in Hot-Standby mode)
* * Historic MVCC snapshots used during logical decoding
* * snapshots passed to HeapTupleSatisfiesDirty()
* * snapshots used for SatisfiesAny, Toast, Self where no members are
* accessed.
*
* It's probably a good idea to split this struct using a NodeTag
* similar to how parser and executor nodes are handled, with one type for
* each different kind of snapshot to avoid overloading the meaning of
* individual fields.
*/
typedef struct SnapshotData {
SnapshotSatisfiesMethod satisfies; /* satisfies type. */
/*
* The remaining fields are used only for MVCC snapshots, and are normally
* just zeroes in special snapshots. (But xmin and xmax are used
* specially by HeapTupleSatisfiesDirty.)
*
* An MVCC snapshot can never see the effects of XIDs >= xmax. It can see
* the effects of all older XIDs except those listed in the snapshot. xmin
* is stored as an optimization to avoid needing to search the XID arrays
* for most tuples.
*/
TransactionId xmin; /* all XID < xmin are visible to me */
TransactionId xmax; /* all XID >= xmax are invisible to me */
/*
* For normal MVCC snapshot this contains the all xact IDs that are in
* progress, unless the snapshot was taken during recovery in which case
* it's empty. For historic MVCC snapshots, the meaning is inverted,
* i.e. it contains *committed* transactions between xmin and xmax.
*/
TransactionId* xip;
/*
* For non-historic MVCC snapshots, this contains subxact IDs that are in
* progress (and other transactions that are in progress if taken during
* recovery). For historic snapshot it contains *all* xids assigned to the
* replayed transaction, including the toplevel xid.
*/
TransactionId* subxip;
uint32 xcnt; /* # of xact ids in xip[] */
GTM_Timeline timeline; /* GTM timeline */
#ifdef PGXC /* PGXC_COORD */
uint32 max_xcnt; /* Max # of xact in xip[] */
#endif
/* note: all ids in xip[] satisfy xmin <= xip[i] < xmax */
int32 subxcnt; /* # of xact ids in subxip[] */
int32 maxsubxcnt; /* # max xids could store in subxip[] */
bool suboverflowed; /* has the subxip array overflowed? */
/*
* This snapshot can see the effects of all transactions with CSN <=
* snapshotcsn.
*/
CommitSeqNo snapshotcsn;
/* For GTMLite local snapshot, we keep an array of prepared transaction xids for MVCC */
int prepared_array_capacity;
int prepared_count;
TransactionId* prepared_array;
bool takenDuringRecovery; /* recovery-shaped snapshot? */
bool copied; /* false if it's a static snapshot */
/*
* note: all ids in subxip[] are >= xmin, but we don't bother filtering
* out any that are >= xmax
*/
CommandId curcid; /* in my xact, CID < curcid are visible */
uint32 active_count; /* refcount on ActiveSnapshot stack */
uint32 regd_count; /* refcount on RegisteredSnapshotList */
void* user_data; /* for local multiversion snapshot */
GTM_SnapshotType gtm_snapshot_type;
} SnapshotData;
调试 Snapshot 结构如下:

ProjectionInfo
这个结构体是用于执行投影操作的信息,投影操作是通过计算目标列表(targetlist)中的表达式来创建新的元组。在执行计划中需要进行投影操作的节点会创建这种结构体。
ProjectionInfo 结构源码如下:(路径:src/include/nodes/execnodes.h)
/* ----------------
* ProjectionInfo node information
*
* This is all the information needed to perform projections ---
* that is, form new tuples by evaluation of targetlist expressions.
* Nodes which need to do projections create one of these.
*
* ExecProject() evaluates the tlist, forms a tuple, and stores it
* in the given slot. Note that the result will be a "virtual" tuple
* unless ExecMaterializeSlot() is then called to force it to be
* converted to a physical tuple. The slot must have a tupledesc
* that matches the output of the tlist!
*
* The planner very often produces tlists that consist entirely of
* simple Var references (lower levels of a plan tree almost always
* look like that). And top-level tlists are often mostly Vars too.
* We therefore optimize execution of simple-Var tlist entries.
* The pi_targetlist list actually contains only the tlist entries that
* aren't simple Vars, while those that are Vars are processed using the
* varSlotOffsets/varNumbers/varOutputCols arrays.
*
* The lastXXXVar fields are used to optimize fetching of fields from
* input tuples: they let us do a slot_getsomeattrs() call to ensure
* that all needed attributes are extracted in one pass.
*
* targetlist target list for projection (non-Var expressions only)
* exprContext expression context in which to evaluate targetlist
* slot slot to place projection result in
* itemIsDone workspace array for ExecProject
* directMap true if varOutputCols[] is an identity map
* numSimpleVars number of simple Vars found in original tlist
* varSlotOffsets array indicating which slot each simple Var is from
* varNumbers array containing input attr numbers of simple Vars
* varOutputCols array containing output attr numbers of simple Vars
* lastInnerVar highest attnum from inner tuple slot (0 if none)
* lastOuterVar highest attnum from outer tuple slot (0 if none)
* lastScanVar highest attnum from scan tuple slot (0 if none)
* pi_maxOrmin column table optimize, indicate if get this column's max or min.
* ----------------
*/
typedef bool (*vectarget_func)(ExprContext* econtext, VectorBatch* pBatch);
typedef struct ProjectionInfo {
NodeTag type;
List* pi_targetlist; // 目标列表,用于存储需要计算的表达式,这些表达式是非 Var 表达式(通常不是简单的列引用)。
ExprContext* pi_exprContext; // 表达式计算的上下文环境。
TupleTableSlot* pi_slot; // 用于存储投影操作的结果的槽位(TupleTableSlot)。
ExprDoneCond* pi_itemIsDone; // 用于 ExecProject 函数的工作空间数组。
bool pi_directMap; // 如果 varOutputCols[] 是一个标识映射,则为 true。
int pi_numSimpleVars; // 原始目标列表中的简单 Var 的数量。
int* pi_varSlotOffsets; // 一个数组,指示每个简单 Var 所在的槽位。
int* pi_varNumbers; // 一个数组,包含简单 Var 的输入属性编号。
int* pi_varOutputCols; // 一个数组,包含简单 Var 的输出属性编号。
// 内部、外部和扫描元组槽位中的最高属性编号。
int pi_lastInnerVar;
int pi_lastOuterVar;
int pi_lastScanVar;
List* pi_acessedVarNumbers; // 用于记录在投影操作中访问过的变量的属性编号
List* pi_sysAttrList; // 存储系统属性的属性编号
List* pi_lateAceessVarNumbers;
List* pi_maxOrmin; // 用于表明是否获取此列的最大值或最小值。
List* pi_PackTCopyVars; /* VarList to record those columns what we need to move */
List* pi_PackLateAccessVarNumbers; /*VarList to record those columns what we need to move in late read cstore
scan.*/
bool pi_const; // 表示投影操作是否只涉及到常量表达式
VectorBatch* pi_batch; // 用于存储投影结果的向量批次(VectorBatch)
// 指向 LLVM 代码生成的目标列表表达式函数的函数指针
vectarget_func jitted_vectarget; /* LLVM function pointer to point to the codegened targetlist expr function */
VectorBatch* pi_setFuncBatch;
} ProjectionInfo;
调试 ProjectionInfo 结构如下:

GetCStoreNextBatch
GetCStoreNextBatch 函数的作用是执行列存储表的扫描操作,从表中读取一批数据,并将这些数据放入一个向量批次(VectorBatch)中,以便后续的查询操作可以高效地进行。这个函数通常在查询执行过程中的扫描阶段被调用,以获取下一个批次的数据。
在列存储中,数据按照列存储,而不是行存储。每个向量批次包含了多个列的数据,这样可以提高数据读取和处理的效率。GetCStoreNextBatch 函数的作用就是为了将这些列数据按照一定的规则读取到向量批次中,以便查询引擎可以对这些数据进行进一步的操作和分析。
GetCStoreNextBatch 函数源码如下:(路径:src/gausskernel/storage/cstore/cstore_am.cpp)
/*
* GetCStoreNextBatch
* 我们可以像这样调用该函数:CStoreScanDesc cstoreScanDesc = CStoreBeginScan();
*/
// 'CStoreScanDesc'结构体用于管理列存储表的扫描操作,它包含了与列存储表扫描相关的各种信息
VectorBatch* CStoreGetNextBatch(CStoreScanDesc cstoreScanState)
{
VectorBatch* vecBatch = cstoreScanState->m_pScanBatch; // 获取当前扫描的批量向量
vecBatch->Reset(); // 重置向量批次,清楚现有数据,为下一批数据做准备
// 通过CStore执行扫描并将扫描结果存储到vecBatch中
cstoreScanState->m_CStore->RunScan(cstoreScanState, vecBatch);
/* 扫描增量表 */
// 当CStore扫描结束并且当前批量向量为空时,需要扫描增量表
if (cstoreScanState->m_CStore->IsEndScan() && BatchIsNull(vecBatch)) {
ScanDeltaStore(cstoreScanState, vecBatch, NULL); // 扫描增量表并将结果存储到vecBatch中
Assert(vecBatch != NULL);
vecBatch->FixRowCount(); // 修正批量向量的行数
}
return vecBatch; // 返回扫描得到的批量向量
}
举个例子详细解释一下这三段代码:
VectorBatch* vecBatch = cstoreScanState->m_pScanBatch; // 获取当前扫描的批量向量
vecBatch->Reset(); // 重置向量批次,清楚现有数据,为下一批数据做准备
// 通过CStore执行扫描并将扫描结果存储到vecBatch中
cstoreScanState->m_CStore->RunScan(cstoreScanState, vecBatch);
假设你有一个装满水果的箱子,每个水果有不同的属性,如名称、数量和价格。你想要逐个检查箱子中的水果。
- 第一句代码:
VectorBatch* vecBatch = cstoreScanState->m_pScanBatch;
这就好像你准备了一个小篮子(扫描批次),你将在这个篮子里放入水果。- 第二句代码:
vecBatch->Reset();
这就是把篮子清空,以便你可以装新的水果。- 第三句代码:
cstoreScanState->m_CStore->RunScan(cstoreScanState, vecBatch);
这就是你从大箱子中拿出一个个水果并放入篮子中的过程。m_CStore->RunScan 是一个操作,它会将一些水果放入篮子中(vecBatch)。
所以,这三句代码一起完成了从一个大箱子(列存储表)中逐个取出水果(数据记录)并放入篮子(扫描批次)中的过程,以供进一步处理。
RunScan
在 CStoreGetNextBatch 中,cstoreScanState->m_CStore->RunScan(cstoreScanState, vecBatch); 这行代码的作用是执行列存储表的扫描操作,并将扫描结果填充到给定的向量批次 vecBatch 中。
由先前 CStoreScanState 结构体可以的定义可以看到,CStoreScanState 中存在一个指向 CStore 类对象的指针。它用于表示与当前列存储扫描状态相关联的列存储对象。
CStore 类是一个表示列存储(Column Store)数据管理和操作的核心类。列存储是一种数据存储方式,它将同一列的数据存储在一起,可以在某些查询场景下提供更高的性能和压缩率。CStore 类的定义如下:(路径:src/include/access/cstore_am.h)
/*
* CStore include a set of common API for ColStore.
* In future, we can add more API.
*/
class CStore : public BaseObject {
// public static area
public:
// create data files
static void CreateStorage(Relation rel, Oid newRelFileNode = InvalidOid);
// unlink data files
static void UnlinkColDataFile(const RelFileNode &rnode, AttrNumber attrnum, bool bcmIncluded);
static void InvalidRelSpaceCache(RelFileNode *rnode);
// trunccate data files which relation CREATE and TRUNCATE in same XACT block
static void TruncateStorageInSameXact(Relation rel);
// form and deform CU Desc tuple
static HeapTuple FormCudescTuple(_in_ CUDesc *pCudesc, _in_ TupleDesc pCudescTupDesc,
_in_ Datum values[CUDescMaxAttrNum], _in_ bool nulls[CUDescMaxAttrNum],
_in_ Form_pg_attribute pColAttr);
static void DeformCudescTuple(_in_ HeapTuple pCudescTup, _in_ TupleDesc pCudescTupDesc,
_in_ Form_pg_attribute pColAttr, _out_ CUDesc *pCudesc);
// Save CU description information into CUDesc table
static void SaveCUDesc(_in_ Relation rel, _in_ CUDesc *cuDescPtr, _in_ int col, _in_ int options);
// form and deform VC CU Desc tuple.
// We add a virtual column for marking deleted rows.
// The VC is divided into CUs.
static HeapTuple FormVCCUDescTup(_in_ TupleDesc cudesc, _in_ const char *delMask, _in_ uint32 cuId,
_in_ int32 rowCount, _in_ uint32 magic);
static void SaveVCCUDesc(_in_ Oid cudescOid, _in_ uint32 cuId, _in_ int rowCount, _in_ uint32 magic,
_in_ int options, _in_ const char *delBitmap = NULL);
static bool IsTheWholeCuDeleted(_in_ char *delBitmap, _in_ int rowsInCu);
bool IsTheWholeCuDeleted(_in_ int rowsInCu);
// get Min/Max value from given *pCudesc*.
// *min* = true, return the Min value.
// *min* = false, return the Max value.
static Datum CudescTupGetMinMaxDatum(_in_ CUDesc *pCudesc, _in_ Form_pg_attribute pColAttr, _in_ bool min,
_out_ bool *shouldFree);
static bool SetCudescModeForMinMaxVal(_in_ bool fullNulls, _in_ bool hasMinMaxFunc, _in_ bool hasNull,
_in_ int maxVarStrLen, _in_ int attlen, __inout CUDesc *cuDescPtr);
static bool SetCudescModeForTheSameVal(_in_ bool fullNulls, _in_ FuncSetMinMax SetMinMaxFunc, _in_ int attlen,
_in_ Datum attVal, __inout CUDesc *cuDescPtr);
static uint32 GetMaxCUID(_in_ Oid cudescHeap, _in_ TupleDesc cstoreRelTupDesc, _in_ Snapshot snapshotArg = NULL);
static uint32 GetMaxIndexCUID(_in_ Relation heapRel, _in_ List *btreeIndex);
static CUPointer GetMaxCUPointerFromDesc(_in_ int attrno, _in_ Oid cudescHeap);
static CUPointer GetMaxCUPointer(_in_ int attrno, _in_ Relation rel);
public:
CStore();
virtual ~CStore();
virtual void Destroy();
// Scan APIs
void InitScan(CStoreScanState *state, Snapshot snapshot = NULL);
void InitReScan();
void InitPartReScan(Relation rel);
bool IsEndScan() const;
// late read APIs
bool IsLateRead(int id) const;
void ResetLateRead();
// update cstore scan timing flag
void SetTiming(CStoreScanState *state);
// CStore scan : pass vector to VE.
void ScanByTids(_in_ CStoreIndexScanState *state, _in_ VectorBatch *idxOut, _out_ VectorBatch *vbout);
void CStoreScanWithCU(_in_ CStoreScanState *state, BatchCUData *tmpCUData, _in_ bool isVerify = false);
// Load CUDesc information of column according to loadInfoPtr
// LoadCUDescCtrl include maxCUDescNum for this load, because if we load all
// it need big memory to hold
//
bool LoadCUDesc(_in_ int col, __inout LoadCUDescCtl *loadInfoPtr, _in_ bool prefetch_control,
_in_ Snapshot snapShot = NULL);
// Get CU description information from CUDesc table
bool GetCUDesc(_in_ int col, _in_ uint32 cuid, _out_ CUDesc *cuDescPtr, _in_ Snapshot snapShot = NULL);
// Get tuple deleted information from VC CU description.
void GetCUDeleteMaskIfNeed(_in_ uint32 cuid, _in_ Snapshot snapShot);
bool GetCURowCount(_in_ int col, __inout LoadCUDescCtl *loadCUDescInfoPtr, _in_ Snapshot snapShot);
// Get live row numbers.
int64 GetLivedRowNumbers(int64 *deadrows);
// Get CU data.
// Note that the CU is pinned
CU *GetCUData(_in_ CUDesc *cuDescPtr, _in_ int colIdx, _in_ int valSize, _out_ int &slotId);
CU *GetUnCompressCUData(Relation rel, int col, uint32 cuid, _out_ int &slotId, ForkNumber forkNum = MAIN_FORKNUM,
bool enterCache = true) const;
// Fill Vector APIs
int FillVecBatch(_out_ VectorBatch *vecBatchOut);
// Fill Vector of column
template <bool hasDeadRow, int attlen>
int FillVector(_in_ int colIdx, _in_ CUDesc *cu_desc_ptr, _out_ ScalarVector *vec);
template <int attlen>
void FillVectorByTids(_in_ int colIdx, _in_ ScalarVector *tids, _out_ ScalarVector *vec);
template <int attlen>
void FillVectorLateRead(_in_ int seq, _in_ ScalarVector *tids, _in_ CUDesc *cuDescPtr, _out_ ScalarVector *vec);
void FillVectorByIndex(_in_ int colIdx, _in_ ScalarVector *tids, _in_ ScalarVector *srcVec,
_out_ ScalarVector *destVec);
// Fill system column into ScalarVector
int FillSysColVector(_in_ int colIdx, _in_ CUDesc *cu_desc_ptr, _out_ ScalarVector *vec);
template <int sysColOid>
void FillSysVecByTid(_in_ ScalarVector *tids, _out_ ScalarVector *destVec);
template <bool hasDeadRow>
int FillTidForLateRead(_in_ CUDesc *cuDescPtr, _out_ ScalarVector *vec);
void FillScanBatchLateIfNeed(__inout VectorBatch *vecBatch);
/* Set CU range for scan in redistribute. */
void SetScanRange();
// Judge whether dead row
bool IsDeadRow(uint32 cuid, uint32 row) const;
void CUListPrefetch();
void CUPrefetch(CUDesc *cudesc, int col, AioDispatchCUDesc_t **dList, int &count, File *vfdList);
/* Point to scan function */
typedef void (CStore::*ScanFuncPtr)(_in_ CStoreScanState *state, _out_ VectorBatch *vecBatchOut);
void RunScan(_in_ CStoreScanState *state, _out_ VectorBatch *vecBatchOut);
int GetLateReadCtid() const;
void IncLoadCuDescCursor();
public: // public vars
// Inserted/Scan Relation
Relation m_relation;
private: // private methods.
// CStore scan : pass vector to VE.
void CStoreScan(CStoreScanState *state, VectorBatch *vecBatchOut);
void CStoreMinMaxScan(CStoreScanState *state, VectorBatch *vecBatchOut);
// The number of holding CUDesc is max_loaded_cudesc
// if we load all CUDesc once, the memory will not enough.
// So we load CUdesc once for max_loaded_cudesc
void LoadCUDescIfNeed();
// Do RoughCheck if need
// elimiate CU by min/max value of CU.
void RoughCheckIfNeed(_in_ CStoreScanState *state);
// Refresh cursor
void RefreshCursor(int row, int deadRows);
void InitRoughCheckEnv(CStoreScanState *state);
void BindingFp(CStoreScanState *state);
void InitFillVecEnv(CStoreScanState *state);
// indicate whether only accessing system column or const column.
// true, means that m_virtualCUDescInfo is a new and single object.
// false, means that m_virtualCUDescInfo just a pointer to m_CUDescInfo[0].
//
inline bool OnlySysOrConstCol(void)
{
return ((m_colNum == 0 && m_sysColNum != 0) || m_onlyConstCol);
}
int LoadCudescMinus(int start, int end) const;
bool HasEnoughCuDescSlot(int start, int end) const;
bool NeedLoadCUDesc(int32 &cudesc_idx);
void IncLoadCuDescIdx(int &idx) const;
bool RoughCheck(CStoreScanKey scanKey, int nkeys, int cuDescIdx);
void FillColMinMax(CUDesc *cuDescPtr, ScalarVector *vec, int pos);
inline TransactionId GetCUXmin(uint32 cuid);
// only called by GetCUData()
CUUncompressedRetCode GetCUDataFromRemote(CUDesc *cuDescPtr, CU *cuPtr, int colIdx, int valSize, const int &slotId);
/* defence functions */
void CheckConsistenceOfCUDescCtl(void);
void CheckConsistenceOfCUDesc(int cudescIdx) const;
void CheckConsistenceOfCUData(CUDesc *cuDescPtr, CU *cu, AttrNumber col) const;
private:
// control private memory used locally.
// m_scanMemContext: for objects alive during the whole cstore-scan
// m_perScanMemCnxt: for memory per heap table scan and temp space
// during decompression.
MemoryContext m_scanMemContext;
MemoryContext m_perScanMemCnxt;
// current snapshot to use.
Snapshot m_snapshot;
// 1. Accessed user column id
// 2. Accessed system column id
// 3. flags for late read
// 4. each CU storage fro each user column.
int *m_colId;
int *m_sysColId;
bool *m_lateRead;
CUStorage **m_cuStorage;
// 1. The CUDesc info of accessed columns
// 2. virtual CUDesc for sys or const columns
LoadCUDescCtl **m_CUDescInfo;
LoadCUDescCtl *m_virtualCUDescInfo;
// Accessed CUDesc index array
// After RoughCheck, which CU will be accessed
//
int *m_CUDescIdx;
// adio param
int m_lastNumCUDescIdx;
int m_prefetch_quantity;
int m_prefetch_threshold;
bool m_load_finish;
// Current scan position inside CU
//
int *m_scanPosInCU;
// Rough Check Functions
//
RoughCheckFunc *m_RCFuncs;
typedef int (CStore::*m_colFillFun)(int seq, CUDesc *cuDescPtr, ScalarVector *vec);
typedef struct {
m_colFillFun colFillFun[2];
} colFillArray;
typedef void (CStore::*FillVectorByTidsFun)(_in_ int colIdx, _in_ ScalarVector *tids, _out_ ScalarVector *vec);
typedef void (CStore::*FillVectorLateReadFun)(_in_ int seq, _in_ ScalarVector *tids, _in_ CUDesc *cuDescPtr,
_out_ ScalarVector *vec);
FillVectorByTidsFun *m_fillVectorByTids;
FillVectorLateReadFun *m_fillVectorLateRead;
colFillArray *m_colFillFunArrary;
typedef void (CStore::*fillMinMaxFuncPtr)(CUDesc *cuDescPtr, ScalarVector *vec, int pos);
fillMinMaxFuncPtr *m_fillMinMaxFunc;
ScanFuncPtr m_scanFunc; // cstore scan function ptr
// node id of this plan
int m_plan_node_id;
// 1. Number of accessed user columns
// 2. Number of accessed system columns.
int m_colNum;
int m_sysColNum;
// 1. length of loaded CUDesc info or virtual CUDesc info
// 2. length of m_CUDescIdx
int m_NumLoadCUDesc;
int m_NumCUDescIdx;
// 1. CU id of current deleted mask.
// 2. Current access cursor in m_CUDescIdx
// 3. Current access row cursor inside CU
uint32 m_delMaskCUId;
int m_cursor;
int m_rowCursorInCU;
uint32 m_startCUID; /* scan start CU ID. */
uint32 m_endCUID; /* scan end CU ID. */
unsigned char m_cuDelMask[MaxDelBitmapSize];
// whether dead rows exist
bool m_hasDeadRow;
// Is need do rough check
bool m_needRCheck;
// Only access const column
bool m_onlyConstCol;
bool m_timing_on; /* timing CStoreScan steps */
RangeScanInRedis m_rangeScanInRedis; /* if it is a range scan at redistribution time */
// cbtree index flag
bool m_useBtreeIndex;
// the first column index, start from 0
int m_firstColIdx;
// for late read
// the cuDesc id of batch in the cuDescArray.
int m_cuDescIdx;
// for late read
// the first late read column idx which is filled with ctid.
int m_laterReadCtidColIdx;
};
调用类成员方法 RunScan 执行列存储数据的扫描操作,RunScan 方法的主要作用是根据传入的扫描状态(CStoreScanState),执行相应的扫描操作,并将扫描得到的数据填充到输出的向量批次 (vecBatchOut) 中。我们再来看看他是如何扫描的吧。
CStoreScan 源码如下:(路径:src/gausskernel/storage/cstore/cstore_am.cpp)
// CStoreScan
// Scan ColStore table and fill vecBatchOut
void CStore::CStoreScan(_in_ CStoreScanState* state, _out_ VectorBatch* vecBatchOut)
{
// step1: The number of holding CUDesc is max_loaded_cudesc
// if we load all CUDesc once, the memory will not enough.
// So we load CUdesc once for max_loaded_cudesc
CSTORESCAN_TRACE_START(LOAD_CU_DESC);
LoadCUDescIfNeed();
CSTORESCAN_TRACE_END(LOAD_CU_DESC);
// step2: Do RoughCheck if need
// elimiate CU by min/max value of CU.
CSTORESCAN_TRACE_START(MIN_MAX_CHECK);
RoughCheckIfNeed(state);
CSTORESCAN_TRACE_END(MIN_MAX_CHECK);
// step3: Have CU hitted
// we will not fill vector because no CU is hitted
ADIO_RUN()
{
if (unlikely(m_cursor == m_NumCUDescIdx)) {
return;
}
}
ADIO_ELSE()
{
if (unlikely(m_NumLoadCUDesc == 0)) {
return;
}
}
ADIO_END();
// step4: Fill VecBatch
CSTORESCAN_TRACE_START(FILL_BATCH);
int deadRows = FillVecBatch(vecBatchOut);
CSTORESCAN_TRACE_END(FILL_BATCH);
// step5: refresh cursor
RefreshCursor(vecBatchOut->m_rows, deadRows);
// step6: prefetch if need
ADIO_RUN()
{
CSTORESCAN_TRACE_START(PREFETCH_CU_LIST);
CUListPrefetch();
CSTORESCAN_TRACE_END(PREFETCH_CU_LIST);
}
ADIO_END();
}
下面逐步解释每个步骤的含义:
- 加载 CUDesc(CU 描述符)信息(LoadCUDescIfNeed):
首先,检查是否需要加载 CUDesc 信息。CUDesc 是指向 Column Unit(列单元)的描述信息,其中包含了该列中各个 CU 的元信息。这个步骤确保最多加载一定数量的 CUDesc 信息,以免占用过多内存。- 粗略检查(RoughCheckIfNeed):
这一步检查是否需要进行粗略检查,即通过 CU 的最小和最大值来排除不符合查询条件的 CU。这样可以减少不必要的数据访问,提高查询性能。- 判断是否有命中的 CU:
在这一步,根据之前的加载和检查,判断是否有命中的 CU。如果没有命中的 CU,就不需要填充向量,直接返回。- 填充 VectorBatch:
在这一步,执行实际的数据填充操作,将命中的 CU 中的数据填充到输出的 VectorBatch 中。函数 FillVecBatch 负责将命中的数据按照查询条件进行填充,并返回死行(已删除的行)的数量。- 刷新游标(RefreshCursor):
这一步更新游标,将游标位置设置为当前扫描结束时的位置。这在后续的扫描中非常重要,因为下一次扫描应从上一次结束的位置继续进行。- 预取(Prefetch):
如果使用了 ADIO(Asynchronous Direct I/O)加速,这一步会进行预取操作,提前将下一批 CU 数据加载到内存中,以加速后续访问。
FillVecBatch
这里我们重点学习一下 FillVecBatch 函数,FillVecBatch 函数是关于在列存储表中填充一个 VectorBatch(批量数据向量)的逻辑。VectorBatch 是一种数据结构,用于批量处理列存储表的查询结果。这个函数的主要目的是从列存储的 CUs(列单元)中提取数据并填充到输出的 VectorBatch 中,以供后续的查询处理。FillVecBatch 函数源码如下(路径:src/gausskernel/storage/cstore/cstore_am.cpp)
int CStore::FillVecBatch(_out_ VectorBatch* vecBatchOut)
{
Assert(vecBatchOut);
int idx = m_CUDescIdx[m_cursor];
int deadRows = 0, i;
this->m_cuDescIdx = idx;
bool hasCtidForLateRead = false;
/* Step 1: fill normal columns if need */
for (i = 0; i < m_colNum; ++i) {
int colIdx = m_colId[i];
if (m_relation->rd_att->attrs[colIdx]->attisdropped) {
ereport(PANIC,
(errmsg("Cannot fill VecBatch for a dropped column \"%s\" of table \"%s\"",
NameStr(m_relation->rd_att->attrs[colIdx]->attname),
RelationGetRelationName(m_relation))));
}
if (likely(colIdx >= 0)) {
Assert(colIdx < vecBatchOut->m_cols);
ScalarVector* vec = vecBatchOut->m_arr + colIdx;
CUDesc* cuDescPtr = m_CUDescInfo[i]->cuDescArray + idx;
GetCUDeleteMaskIfNeed(cuDescPtr->cu_id, m_snapshot);
// We can't late read data
if (!IsLateRead(i)) {
int funIdx = m_hasDeadRow ? 1 : 0;
deadRows = (this->*m_colFillFunArrary[i].colFillFun[funIdx])(i, cuDescPtr, vec);
} else {
// We haven't fill ctid for late read columns
if (!hasCtidForLateRead) {
if (!m_hasDeadRow)
deadRows = FillTidForLateRead<false>(cuDescPtr, vec);
else
deadRows = FillTidForLateRead<true>(cuDescPtr, vec);
hasCtidForLateRead = true;
this->m_laterReadCtidColIdx = colIdx;
} else
vec->m_rows = vecBatchOut->m_rows;
}
vecBatchOut->m_rows = vec->m_rows;
}
}
// Step 2: fill sys columns if need
for (i = 0; i < m_sysColNum; ++i) {
int sysColIdx = m_sysColId[i];
ScalarVector* sysVec = vecBatchOut->GetSysVector(sysColIdx);
deadRows = FillSysColVector(sysColIdx, m_virtualCUDescInfo->cuDescArray + idx, sysVec);
vecBatchOut->m_rows = sysVec->m_rows;
}
// Step 3: fill const columns if need
if (unlikely(m_onlyConstCol)) {
// We only set row count
CUDesc* cuDescPtr = m_virtualCUDescInfo->cuDescArray + idx;
int liveRows = 0, leftSize = cuDescPtr->row_count - m_rowCursorInCU;
ScalarVector* vec = vecBatchOut->m_arr;
errno_t rc = memset_s(vec->m_flag, sizeof(uint8) * BatchMaxSize, 0, sizeof(uint8) * BatchMaxSize);
securec_check(rc, "", "");
Assert(deadRows == 0 && leftSize > 0);
GetCUDeleteMaskIfNeed(cuDescPtr->cu_id, m_snapshot);
for (i = 0; i < leftSize && liveRows < BatchMaxSize; i++) {
if (IsDeadRow(cuDescPtr->cu_id, i + m_rowCursorInCU))
++deadRows;
else
++liveRows;
}
vec->m_rows = liveRows;
vecBatchOut->m_rows = vec->m_rows;
}
/* Step 4: fill other columns if need, most likely for the dropped column */
for (i = 0; i < vecBatchOut->m_cols; i++) {
if (m_relation->rd_att->attrs[i]->attisdropped) {
ScalarVector* vec = vecBatchOut->m_arr + i;
vec->m_rows = vecBatchOut->m_rows;
vec->SetAllNull();
}
}
return deadRows;
}
下面是这段代码的详细解释:
- 首先,代码开始进行一些断言检查,确保传入的 vecBatchOut 不为空。
- 代码初始化一些变量,如 idx 表示当前正在处理的 CU 的索引,deadRows 表示当前 CU 中已删除的行数,hasCtidForLateRead 表示是否已经填充了用于后续的 “late read” 的 ctid(行标识)列。
- 进入循环,首先处理普通用户列:
- 对于每一列,首先检查是否该列已被删除。如果是,则会抛出一个异常。
- 如果列索引合法(大于等于0且小于 vecBatchOut->m_cols),则从 vecBatchOut 中获取对应列的 ScalarVector,然后获取当前处理的 CU 的 CUDesc(CU 描述)信息,并获取该 CU 的删除标志位。
- 如果该列不支持 “late read”,则根据是否存在删除行的情况,调用相应的填充函数,将 CU 中的数据填充到对应的 ScalarVector 中,并更新 deadRows。
- 如果该列支持 “late read”,则首先检查是否已经填充了 ctid 列,如果没有,则填充 ctid 列,同时记录当前的列索引,以便后续使用。
- 最后,更新 vecBatchOut 的行数。
- 继续循环,处理系统列:
- 对于每一个系统列,从 vecBatchOut 获取对应的 ScalarVector,然后使用虚拟 CUDesc(存储系统列信息的 CU 描述)的信息,调用相应的填充函数,将系统列的数据填充到 ScalarVector 中,并更新 deadRows。
- 如果表中只有常数列:
- 该部分代码用于处理只包含常数列的情况。
- 根据当前处理的 CU 的 CUDesc,计算剩余的行数(leftSize)。
- 根据 CU 的删除标志位和当前处理的行数,计算存活行数和已删除行数(liveRows 和 deadRows)。
- 使用 memset_s 将当前列的标志位都设置为 0(不为空)。
- 更新当前列的行数。
- 更新 vecBatchOut 的行数。
- 最后,对于可能的已删除列,将对应的 ScalarVector 的数据设置为 NULL 值。
- 函数返回 deadRows,表示已删除的行数。
CStoreIsEndScan
CStoreIsEndScan 是一个宏定义,用于检查列存储表扫描是否结束。在代码中它会被替换成调用 IsEndScan 方法的结果,具体来说,会根据是否支持 ADIO 来选择调用 IsEndScan 的不同版本。在支持 ADIO 的情况下,会调用带有 ADIO 版本的 IsEndScan 方法,否则会调用不带 ADIO 版本的 IsEndScan 方法。
extern bool CStoreIsEndScan(CStoreScanDesc cstoreScanState);
IsEndScan 是一个方法,是实际用来检查列存储表扫描是否结束的函数。它的功能在前面的回答中已经详细解释过了。根据是否支持 ADIO,它会根据不同的条件判断扫描是否结束。
IsEndScan的源码如下(路径:src/gausskernel/storage/cstore/cstore_am.cpp)
// FORCE_INLINE
bool CStore::IsEndScan() const
{
// 如果支持 ADIO
ADIO_RUN()
{
// 如果当前游标等于已加载的 CUDesc 的数量,并且加载已经完成,返回 true
// 否则返回 false
return (m_cursor == m_NumCUDescIdx && m_load_finish) ? true : false;
}
// 如果不支持 ADIO
ADIO_ELSE()
{
// 如果没有加载任何 CUDesc,返回 true,表示扫描结束
// 否则返回 false
return (m_NumCUDescIdx == 0) ? true : false;
}
ADIO_END();
}
CStoreEndScan
CStoreEndScan 函数的作用是用于结束列存储表的扫描操作。在数据库系统中,当需要停止或结束对表的扫描时,需要进行一些清理工作以释放相关资源并确保不再执行扫描操作。
CStoreEndScan 函数函数源码如下:(路径:src/gausskernel/storage/cstore/cstore_am.cpp)
// 清理 cstoreScanState 的内存
void CStoreEndScan(CStoreScanDesc cstoreScanState)
{
// 获取投影信息
ProjectionInfo* projInfo = cstoreScanState->ps.ps_ProjInfo;
/*
* 减少关联关系的引用计数,并释放扫描描述符的存储空间
*/
RelationDecrementReferenceCount(cstoreScanState->ss_currentRelation);
// 释放内存
Assert(cstoreScanState->m_CStore != NULL);
Assert(projInfo);
DELETE_EX(cstoreScanState->m_CStore);
// 注意:不会清理在内存上下文中分配的内存
delete cstoreScanState->m_pScanBatch;
cstoreScanState->m_pScanBatch = NULL;
// 结束扫描增量表
if (cstoreScanState->ss_currentDeltaRelation != NULL) {
// 释放元组槽
ExecDropSingleTupleTableSlot(cstoreScanState->ss_ScanTupleSlot);
// 释放表达式上下文
ExecFreeExprContext(&cstoreScanState->ps);
// 结束扫描增量表
EndScanDeltaRelation(cstoreScanState);
}
// 释放投影信息中的资源
if (projInfo->pi_acessedVarNumbers) {
list_free(projInfo->pi_acessedVarNumbers);
}
if (projInfo->pi_sysAttrList) {
list_free(projInfo->pi_sysAttrList);
}
if (projInfo->pi_PackLateAccessVarNumbers) {
list
CStoreEndScan 函数的主要作用是确保扫描过程的正常结束,释放相关资源,以便系统可以继续进行其他操作。这有助于避免资源泄漏和系统状态的不一致性。