本文首发于 慕雪的寒舍
以tcpServer的计算器服务为例,实现一个自定义协议
阅读本文之前,请先阅读 tcpServer
本文完整代码详见 Gitee
1.重谈tcp
注意,当下所对tcp的描述都是以简单、方便理解起见,后续会对tcp协议进行深入解读
1.1 链接
我们知道,tcp是面向连接的,客户端和服务端要先建立链接,才能开始通信
- 在链接过程中,tcp采用三次握手
- 在断线过程中,tcp采用四次挥手
举个日常生活中的栗子,帮助理解3次握手和4次挥手

1.2 信息发送
假如我们现在需要发送结构化数据,那应该怎么办?
我们知道,tcp是面向字节流的,也就是其能够发送任意数据。也能够发送C语言结构体的二进制数据;
- 但能发送,就代表我们可以这么干吗?
- 答案自然是不行!
不同平台,对结构体对齐的配置不同,大小端不同,其最终对我们字节流的解析也就不一样。如果采用直接发送结构体数据的方式来通信,适配性极低,我们的客户端和服务端都会被限制在当前的系统环境中运行;
可是,哪怕是同一个系统,其内部对大小端的配置也有可能改变!到时候我们的代码恐怕就无法运行了!
同理,在当初编写C语言通讯录的代码的时候,也不能采用直接将结构体数据写入文件的方式。后续代码升级、环境改变,都可能导致我们存在文件中的数据失效,这肯定是我们不希望看到的情况。
所以,为了解决这个问题,我们就应该将数据进行序列化之后再发送,客户端接收到信息后,进行反序列化解析出数据!
2.序列化和反序列化
2.1 简介
所谓序列化,就是将结构化的数据(可以暂时理解为c的结构体)转换成字符串的方式,发送出去
struct date
{
int year;
int month;
int day;
};
比如上面这个日期结构体,我们要想将其序列化,就可以用一个很简单的方式拼接成一个字符串(序列化)
year-month-day
客户端收到这个字符串之后,就可以通过查找分隔符-的方式,取出三个变量,将其转成int后存放回结构体(反序列化)
这样,我们就算是规定了一个序列化和反序列化的方式,也就是一个简单的协议!
2.2 编码解码
这里还会出现另外一个问题,我要怎么知道我已经读取完毕了一个序列化后的数据呢?
2000-12-10
10000-01-01
如上,假设有一天,我们的年变成了五位数;这时候,服务端要怎么知道自己是否读取完毕了一个完整的序列化数据呢?
这就需要我们做好规定,将前n字节作为标识长度的数据。接收到数据后,先取出前n个字节,读取道此次消息的长度m,再往后读取m个字节的数据,成功取出完整的字符串;
- 这个过程可以称作编码和解码的过程
为了区分标识长度的数据和实际需要的序列化内容,我们可以在之中加上分隔符\t;但这也需要我们确认,传输的数据本身不能带上\t,否则会产生一系列的问题
10\t2000-12-10\t
11\t10000-01-01\t
以上的这一系列工作,都是协议定制的一部分!我们给服务端和客户端规定了一个序列化和反序列化的方式,让二者通信规避掉了平台的限制。毕竟任何平台对字符串解码出来的数据都会是相同的!
下面就用一个计算器的服务,来演示一下吧😏
3.计算器服务
因为本文的重心是对协议定制的演示,所以这里的计算器不考虑连续操作符的情况,
3.1 协议定制
要想实现一个计算器,我们首先要搞明白计算器有几个成员
x+y
x/y
x*y
...
一般情况下,一个计算器只需要3个成员,分别是两个操作数和一个运算符,就能开始计算。所以我们需要将这里的三个字段设计成一个字符串,实现序列化;
比如我们应该规定序列化之后的数据应该是如下的,两个操作数和操作符之间应该要有空格
a + b
再在开头添加上数据长度的标识
数据长度\t公式\t
7\t10 + 20\t
8\t100 / 30\t
9\t300 - 200\t
对于服务端,我们需要返回两个参数:状态码和结果
退出状态 结果
如果退出状态不为0,则代表出现错误,结果无效;只有退出结果为0,结果才是有效的。
同样的,也需要给服务器的序列化字符串添加上数据的长度
数据长度\t退出状态 结果\t
这样就搞定了一个计算器的自定义协议;
3.2 成员
依照如上的协议,先把请求和返回的成员变量写好
class Request
{
int _x;
int _y;
char _ops;
};
class Response
{
int _exitCode; //计算服务的退出码
int _result; // 结果
};
这些成员变量都设置为公有,方便在task里面进行处理(否则就需要写get函数,很麻烦)
同时,最好还是把协议中的分隔符给定义出来,方便后续统一使用or更改
#define CRLF "\t" //分隔符
#define CRLF_LEN strlen(CRLF) //分隔符长度
#define SPACE " " //空格
#define SPACE_LEN strlen(SPACE) //空格长度
#define OPS "+-*/%" //运算符
3.3 编码解码
对于请求和回应来说,编解码的操作是一样的,都是往字符串的开头添加上长度和分隔符
长度\t序列化字符串\t
解码就是将长度和分隔符去掉,只解析出序列化字符串
序列化字符串
编码解码的整个过程在注释里面都写明了😁为了方便请求和回应去使用,直接放到外头,不做类内封装
//参数len为in的长度,是一个输出型参数。如果为0代表err
std::string decode(std::string& in,size_t*len)
{
assert(len);//如果长度为0是错误的
// 1.确认in的序列化字符串完整(分隔符)
*len=0;
size_t pos = in.find(CRLF);//查找分隔符
//查找不到,err
if(pos == std::string::npos){
return "";//返回空串
}
// 2.有分隔符,判断长度是否达标
// 此时pos下标正好就是标识大小的字符长度
std::string inLenStr = in.substr(0,pos);//提取字符串长度
size_t inLen = atoi(inLenStr.c_str());//转int
size_t left = in.size() - inLenStr.size()- 2*CRLF_LEN;//剩下的字符长度
if(left<inLen){
return ""; //剩下的长度没有达到标明的长度
}
// 3.走到此处,字符串完整,开始提取序列化字符串
std::string ret = in.substr(pos+CRLF_LEN,inLen);
*len = inLen;
// 4.因为in中可能还有其他的报文(下一条)
// 所以需要把当前的报文从in中删除,方便下次decode,避免二次读取
size_t rmLen = inLenStr.size() + ret.size() + 2*CRLF_LEN;
in.erase(0,rmLen);
// 5.返回
return ret;
}
//编码不需要修改源字符串,所以const。参数len为in的长度
std::string encode(const std::string& in,size_t len)
{
std::string ret = std::to_string(len);//将长度转为字符串添加在最前面,作为标识
ret+=CRLF;
ret+=in;
ret+=CRLF;
return ret;
}
3.4 request
编码解码写好了,先来处理比较麻烦的请求部分;说麻烦吧,其实大多数也是c++的string操作,要熟练运用string的各类成员函数,才能很好的实现
3.4.1 构造
比较重要的是这个构造函数,我们需要将用户的输入转成内部的三个成员
用户可能输入x+y,x+ y,x +y,x + y等等格式
这里还需要注意,用户的输入不一定是标准的X+Y,里面可能在不同位置里面会有空格。为了统一方便处理,在解析之前,最好先把用户输入内的空格给去掉!
对于string而言,去掉空格就很简单了,直接一个遍历搞定
// 删除输入中的空格
void rmSpace(std::string& in)
{
std::string tmp;
for(auto e:in)
{
if(e!=' ')
{
tmp+=e;
}
}
in = tmp;
}
完成的构造如下,这里涉及到C语言的函数strtok,要复习复习
// 将用户的输入转成内部成员
// 用户可能输入x+y,x+ y,x +y,x + y等等格式
// 提前修改用户输入(主要还是去掉空格),提取出成员
Request(std::string in,bool* status)
:_x(0),_y(0),_ops(' ')
{
rmSpace(in);
// 这里使用c的字符串,因为有strtok
char buf[1024];
// 打印n个字符,多的会被截断
snprintf(buf,sizeof(buf),"%s",in.c_str());
char* left = strtok(buf,OPS);
if(!left){//找不到
*status = false;
return;
}
char*right = strtok(nullptr,OPS);
if(!right){//找不到
*status = false;
return;
}
// x+y, strtok会将+设置为\0
char mid = in[strlen(left)];//截取出操作符
//这是在原字符串里面取出来,buf里面的这个位置被改成\0了
_x = atoi(left);
_y = atoi(right);
_ops = mid;
*status=true;
}
3.4.2 序列化
解析出成员以后,我们要做的就是对成员进行序列化,将其按指定的位置摆成一个字符串。这里采用了输出型参数的方式来序列化字符串,也可以改成用返回值的方式来操作。
这里需要注意的是,操作符本身就是char不能使用to_string来操作,会被转成ascii码,不符合我们的需求
// 序列化 (入参应该是空的)
void serialize(std::string& out)
{
// x + y
out.clear(); // 序列化的入参是空的
out+= std::to_string(_x);
out+= SPACE;
out+= _ops;//操作符不能用tostring,会被转成ascii
out+= SPACE;
out+= std::to_string(_y);
// 不用添加分隔符(这是encode要干的事情)
}
3.4.3 反序列化
注意,思路不能搞错了。刚开始我认为request的反序列化应该针对的是服务器的返回值,实际并非如此!
在客户端和服务端都需要使用request,客户端进行序列化,服务端对接收到的结果利用request进行反序列化。request只关注于对请求的处理,而不处理服务器的返回值。
// 反序列化
bool deserialize(const std::string &in)
{
// x + y 需要取出x,y和操作符
size_t space1 = in.find(SPACE); //第一个空格
if(space1 == std::string::npos)
{
return false;
}
size_t space2 = in.rfind(SPACE); //第二个空格
if(space2 == std::string::npos)
{
return false;
}
// 两个空格都存在,开始取数据
std::string dataX = in.substr(0,space1);
std::string dataY = in.substr(space2+SPACE_LEN);//默认取到结尾
std::string op = in.substr(space1+SPACE_LEN,space2 -(space1+SPACE_LEN));
if(op.size()!=1)
{
return false;//操作符长度有问题
}
//没问题了,转内部成员
_x = atoi(dataX.c_str());
_y = atoi(dataY.c_str());
_ops = op[0];
return true;
}
3.5 response
3.5.1 构造
返回值的构造比较简单,因为是服务器处理结果之后的操作;这些成员变量都设置为了公有,方便后续修改。
Response(int code=0,int result=0)
:_exitCode(code),_result(result)
{}
3.5.2 序列化
// 入参是空的
void serialize(std::string& out)
{
// code ret
out.clear();
out+= std::to_string(_exitCode);
out+= SPACE;
out+= std::to_string(_result);
out+= CRLF;
}
3.5.3 反序列化
响应的反序列化只需要处理一个空格,相对来说较为简单
// 反序列化
bool deserialize(const std::string &in)
{
// 只有一个空格
size_t space = in.find(SPACE);
if(space == std::string::npos)
{
return false;
}
std::string dataCode = in.substr(0,space);
std::string dataRes = in.substr(space+SPACE_LEN);
_exitCode = atoi(dataCode.c_str());
_result = atoi(dataRes.c_str());
return true;
}
3.6 客户端
之前写的客户端,并没有进行序列化操作,所以我们需要添加上序列化操作,并对服务器的返回值进行反序列化。这期间需要加上一系列判断;
为了限制篇幅,下面只贴出来客户端的循环操作;详情参考注释。
// 客户端发现的消息
string message;
while (1)
{
message.clear();//每次循环开始,都清空一下msg
cout << "请输入你的消息# ";
getline(cin, message);//获取输入
// 如果客户端输入了quit,则退出
if (strcasecmp(message.c_str(), "quit") == 0)
break;
// 向服务端发送消息
// 1.创建一个request(分离参数)
bool reqStatus = true;
Request req(message,&reqStatus);
if(!reqStatus){
cout << "make req err!" << endl;
continue;
}
// 2.序列化和编码
string package;
req.serialize(package);//序列化
package = encode(package,package.size());//编码
// 3.发送给服务器
ssize_t s = write(sock,package.c_str(), package.size());
if (s > 0) // 写入成功
{
// 4.获取服务器的结果
char buff[BUFFER_SIZE];
size_t s = read(sock, buff, sizeof(buff)-1);
if(s > 0){
buff[s] = '\0';
}
std::string echoPackage = buff;
Response resp;
size_t len = 0;
// 5.解码和反序列化
std::string tmp = decode(echoPackage, &len);
if(len > 0)//解码成功
{
echoPackage = tmp;
if(resp.deserialize(echoPackage))//反序列化并判断
{
printf("ECHO [exitcode: %d] %d\n", resp._exitCode, resp._result);
}
else
{
cerr << "server echo deserialize err!" << endl;
}
}
else
{
cerr << "server echo decode err!" << endl;
}
}
else if (s <= 0) // 写入失败
{
break;
}
}
3.7 服务端
服务端无须修改代码,需要修改的是task消息队列中处理的任务;这就是之前做好封装的好处,因为只需要修改task里面传入的函数指针,就算是修改了服务器所进行的服务
// 提供服务(通过线程池)
Task t(conet,senderIP,senderPort,CaculateService);
_tpool->push(t);
如下是计算器服务的代码
void CaculateService(int sockfd, const std::string &clientIP, uint16_t clientPort)
{
assert(sockfd >= 0);
assert(!clientIP.empty());
assert(clientPort > 0);
std::string inbuf;
while(1)
{
Request req;
char buf[BUFFER_SIZE];
// 1.读取客户端发送的信息
ssize_t s = read(sockfd, buf, sizeof(buf) - 1);
if (s == 0)
{ // s == 0代表对方发送了空消息,视作客户端主动退出
logging(DEBUG, "client quit: %s[%d]", clientIP.c_str(), clientPort);
break;
}
else if(s<0)
{
// 出现了读取错误,打印日志后断开连接
logging(DEBUG, "read err: %s[%d] = %s", clientIP.c_str(), clientPort, strerror(errno));
break;
}
// 2.读取成功
buf[s] = '\0'; // 手动添加字符串终止符
if (strcasecmp(buf, "quit") == 0)
{ // 客户端主动退出
break;
}
// 3.开始服务
inbuf = buf;
size_t packageLen = inbuf.size();
// 3.1.解码和反序列化客户端传来的消息
std::string package = decode(inbuf, &packageLen);//解码
if(packageLen==0){
logging(DEBUG, "decode err: %s[%d] status: %d", clientIP.c_str(), clientPort, packageLen);
continue;//报文不完整或有误
}
logging(DEBUG,"package: %s[%d] = %s",clientIP.c_str(), clientPort,package.c_str());
bool deStatus = req.deserialize(package); // 反序列化
if(deStatus) // 获取消息反序列化成功
{
req.debug(); // 打印信息
// 3.2.获取结构化的相应
Response resp = Caculater(req);
// 3.3.序列化和编码响应
std::string echoStr;
resp.serialize(echoStr);
echoStr = encode(echoStr,echoStr.size());
// 3.4.写入,发送返回值给客户端
write(sockfd, echoStr.c_str(), echoStr.size());
}
else // 客户端消息反序列化失败
{
logging(DEBUG, "deserialize err: %s[%d] status: %d", clientIP.c_str(), clientPort, deStatus);
continue;
}
}
close(sockfd);
logging(DEBUG, "server quit: %s[%d] %d",clientIP.c_str(), clientPort, sockfd);
}
其中有一个计算函数,比较简单,通过switch case语句,计算结果,并判断操作数是否有问题。
Response Caculater(const Request& req)
{
Response resp;//构造函数中已经指定了exitcode为0
switch (req._ops)
{
case '+':
resp._result = req._x + req._y;
break;
case '-':
resp._result = req._x - req._y;
break;
case '*':
resp._result = req._x * req._y;
break;
case '%':
{
if(req._y == 0)
{
resp._exitCode = -1;//取模错误
break;
}
resp._result = req._x % req._y;//取模是可以操作负数的
break;
}
case '/':
{
if(req._y == 0)
{
resp._exitCode = -2;//除0错误
break;
}
resp._result = req._x / req._y;//取模是可以操作负数的
break;
}
default:
resp._exitCode = -3;//操作符非法
break;
}
return resp;
}
这样,我们的序列化处理就成功了!测试一下吧
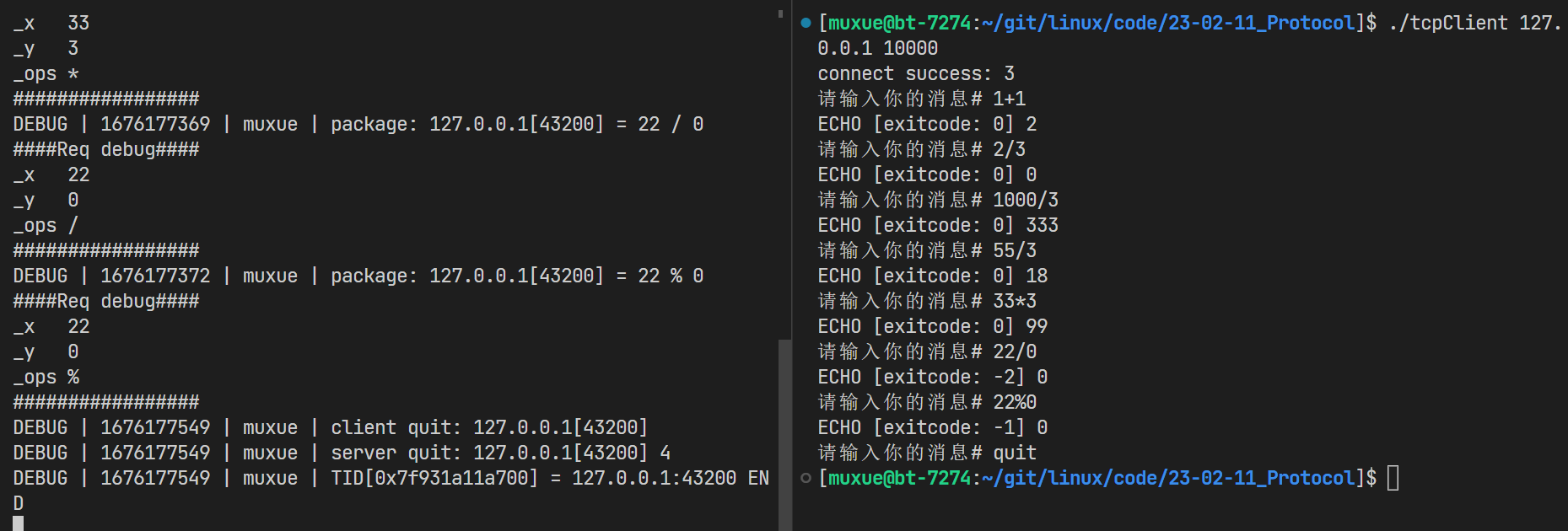
4.测试
运行服务器,可以看到,服务器能成功处理客户端的计算,并返回结果

输入quit,服务器会打印信息,并退出服务