【IDEA+Spark Streaming 3.4.1+Dstream监控套接字流统计WordCount保存至MySQL8】
把DStream写入到MySQL数据库中
- Spark 3.4.1
- MySQL 8.0.30
- sbt 1.9.2
文章目录
- 【IDEA+Spark Streaming 3.4.1+Dstream监控套接字流统计WordCount保存至MySQL8】
- 前言
- 一、背景说明
- 二、使用步骤
- 1.引入库
- 2.开发代码
- 运行测试
- 总结
前言
需要基于Spark Streaming 将实时监控的套接字流统计WordCount结果保存至MySQL
提示:本项目通过sbt控制依赖
一、背景说明
在Spark应用中,外部系统经常需要使用到Spark DStream处理后的数据,因此,需要采用输出操作把DStream的数据输出到数据库或者文件系统中
Spark Streaming是一个基于Spark的实时计算框架,它可以从多种数据源消费数据,并对数据进行高效、可扩展、容错的处理。Spark Streaming的工作原理有以下几个步骤:
- 数据接收:Spark Streaming可以从各种输入源接收数据,如Kafka、Flume、Twitter、Kinesis等,然后将数据分发到Spark集群中的不同节点上。每个节点上有一个接收器(Receiver)负责接收数据,并将数据存储在内存或磁盘中。
- 数据划分:Spark Streaming将连续的数据流划分为一系列小批量(Batch)的数据,每个批次包含一定时间间隔内的数据。这个时间间隔称为批处理间隔(Batch Interval),可以根据应用的需求进行设置。每个批次的数据都被封装成一个RDD,RDD是Spark的核心数据结构,表示一个不可变的分布式数据集。
- 数据处理:Spark Streaming对每个批次的RDD进行转换和输出操作,实现对流数据的处理和分析。转换操作可以使用Spark Core提供的各种函数,如map、reduce、join等,也可以使用Spark Streaming提供的一些特殊函数,如window、updateStateByKey等。输出操作可以将处理结果保存到外部系统中,如HDFS、数据库等。
- 数据输出:Spark Streaming将处理结果以DStream的形式输出,DStream是一系列连续的RDD组成的序列,表示一个离散化的数据流。DStream可以被进一步转换或输出到其他系统中。
DStream有状态转换操作是指在Spark Streaming中,对DStream进行一些基于历史数据或中间结果的转换,从而得到一个新的DStream。
二、使用步骤
1.引入库
ThisBuild / version := "0.1.0-SNAPSHOT"
ThisBuild / scalaVersion := "2.13.11"
lazy val root = (project in file("."))
.settings(
name := "SparkLearning",
idePackagePrefix := Some("cn.lh.spark"),
libraryDependencies += "org.apache.spark" %% "spark-sql" % "3.4.1",
libraryDependencies += "org.apache.spark" %% "spark-core" % "3.4.1",
libraryDependencies += "org.apache.hadoop" % "hadoop-auth" % "3.3.6",
libraryDependencies += "org.apache.spark" %% "spark-streaming" % "3.4.1",
libraryDependencies += "org.apache.spark" %% "spark-streaming-kafka-0-10" % "3.4.1",
libraryDependencies += "org.apache.spark" %% "spark-mllib" % "3.4.1" % "provided",
libraryDependencies += "mysql" % "mysql-connector-java" % "8.0.30"
)
2.开发代码
为了实现通过spark Streaming 监控控制台输入,需要开发两个代码:
- NetworkWordCountStatefultoMysql.scala
- StreamingSaveMySQL8.scala
NetworkWordCountStatefultoMysql.scala
package cn.lh.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object NetworkWordCountStatefultoMysql {
def main(args: Array[String]): Unit = {
// 定义状态更新函数
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
// 设置log4j日志级别
StreamingExamples.setStreamingLogLevels()
val conf: SparkConf = new SparkConf().setAppName("NetworkCountStateful").setMaster("local[2]")
val scc: StreamingContext = new StreamingContext(conf, Seconds(5))
// 设置检查点,具有容错机制
scc.checkpoint("F:\\niit\\2023\\2023_2\\Spark\\codes\\checkpoint")
val lines: ReceiverInputDStream[String] = scc.socketTextStream("192.168.137.110", 9999)
val words: DStream[String] = lines.flatMap(_.split(" "))
val wordDstream: DStream[(String, Int)] = words.map(x => (x, 1))
val stateDstream: DStream[(String, Int)] = wordDstream.updateStateByKey[Int](updateFunc)
// 打印出状态
stateDstream.print()
// 将统计结果保存到MySQL中
stateDstream.foreachRDD(rdd =>{
val repartitionedRDD = rdd.repartition(3)
repartitionedRDD.foreachPartition(StreamingSaveMySQL8.writeToMySQL)
})
scc.start()
scc.awaitTermination()
scc.stop()
}
}
StreamingSaveMySQL8.scala
package cn.lh.spark
import java.sql.DriverManager
object StreamingSaveMySQL8 {
// 定义写入 MySQL 的函数
def writeToMySQL(iter: Iterator[(String,Int)]): Unit = {
// 保存到MySQL
val ip = "192.168.137.110"
val port = "3306"
val db = "sparklearning"
val username = "lh"
val pwd = "Lh123456!"
val jdbcurl = s"jdbc:mysql://$ip:$port/$db"
val conn = DriverManager.getConnection(jdbcurl, username, pwd)
val statement = conn.prepareStatement("INSERT INTO wordcount (word,count) VALUES (?,?)")
try {
// 写入数据
iter.foreach { wc =>
statement.setString(1, wc._1.trim)
statement.setInt(2, wc._2.toInt)
statement.executeUpdate()
}
} catch {
case e:Exception => e.printStackTrace()
} finally {
if(statement != null){
statement.close()
}
if(conn!=null){
conn.close()
}
}
}
}
运行测试
准备工作:
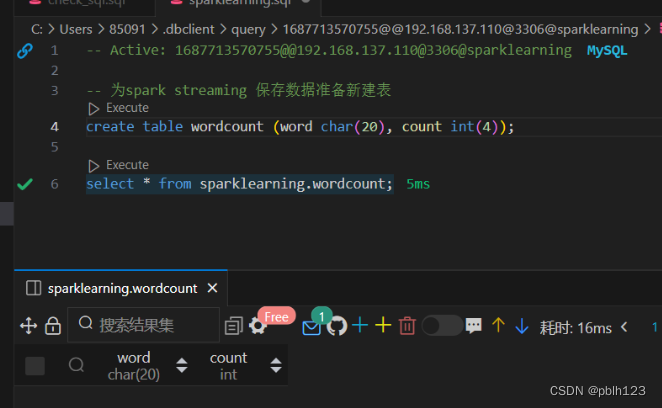
-
提前在mysql中新建数据表保存Spark Streaming写入的数据
-
启动nc -lk 9999

-
启动 NetworkWordCountStatefultoMysql.scala
![[Pasted image 20230804214904.png]]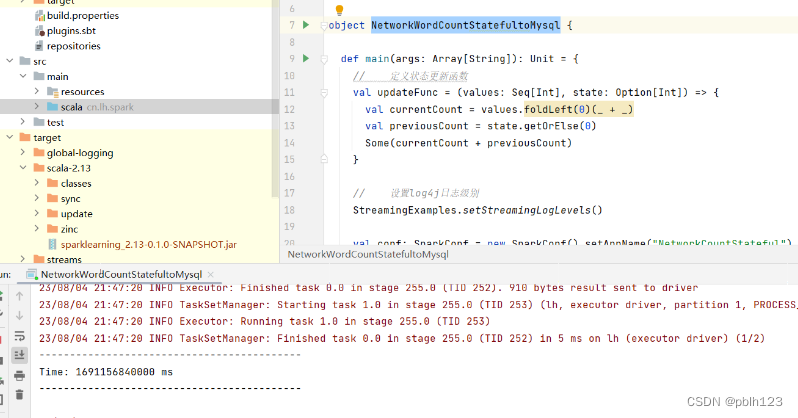
-
在nc端口输入字符,再分别到idea控制台和MySQL检查结果
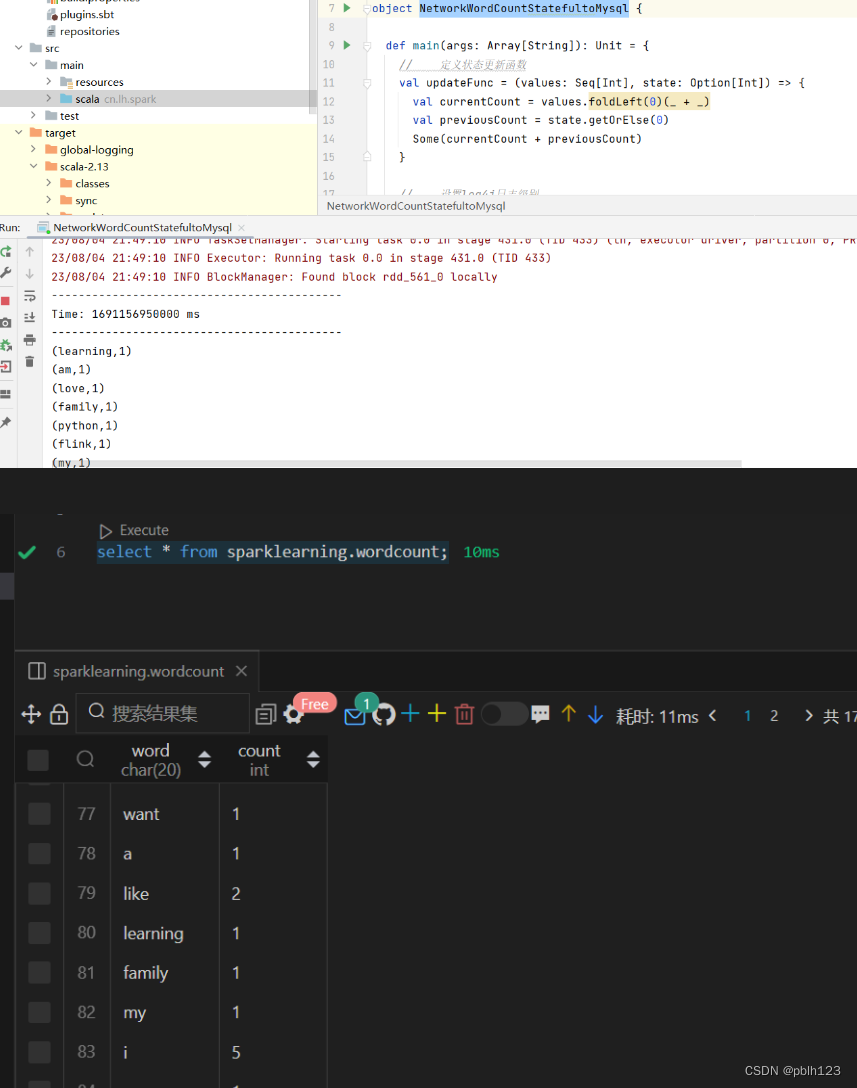
总结
本次实验通过IDEA基于Spark Streaming 3.4.1开发程序监控套接字流,并统计字符串,实现实时统计单词出现的数量。试验成功,相对简单。
后期改善点如下:
- 通过配置文件读取mysql数据库相应的配置信息,不要写死在代码里
- 写入数据时,sql语句【插入的表信息】,可以在调用方法时,当作参数输入
- iter: Iterator[(String,Int)] 应用泛型
- 插入表时,自动保存插入时间
欢迎各位开发者一同改进代码,有问题有疑问提出来交流。谢谢!