一、存储引擎的简介
MySQL 5.7 支持的存储引擎有 InnoDB、MyISAM、Memory、Merge、Archive、Federated、CSV、BLACKHOLE 等。
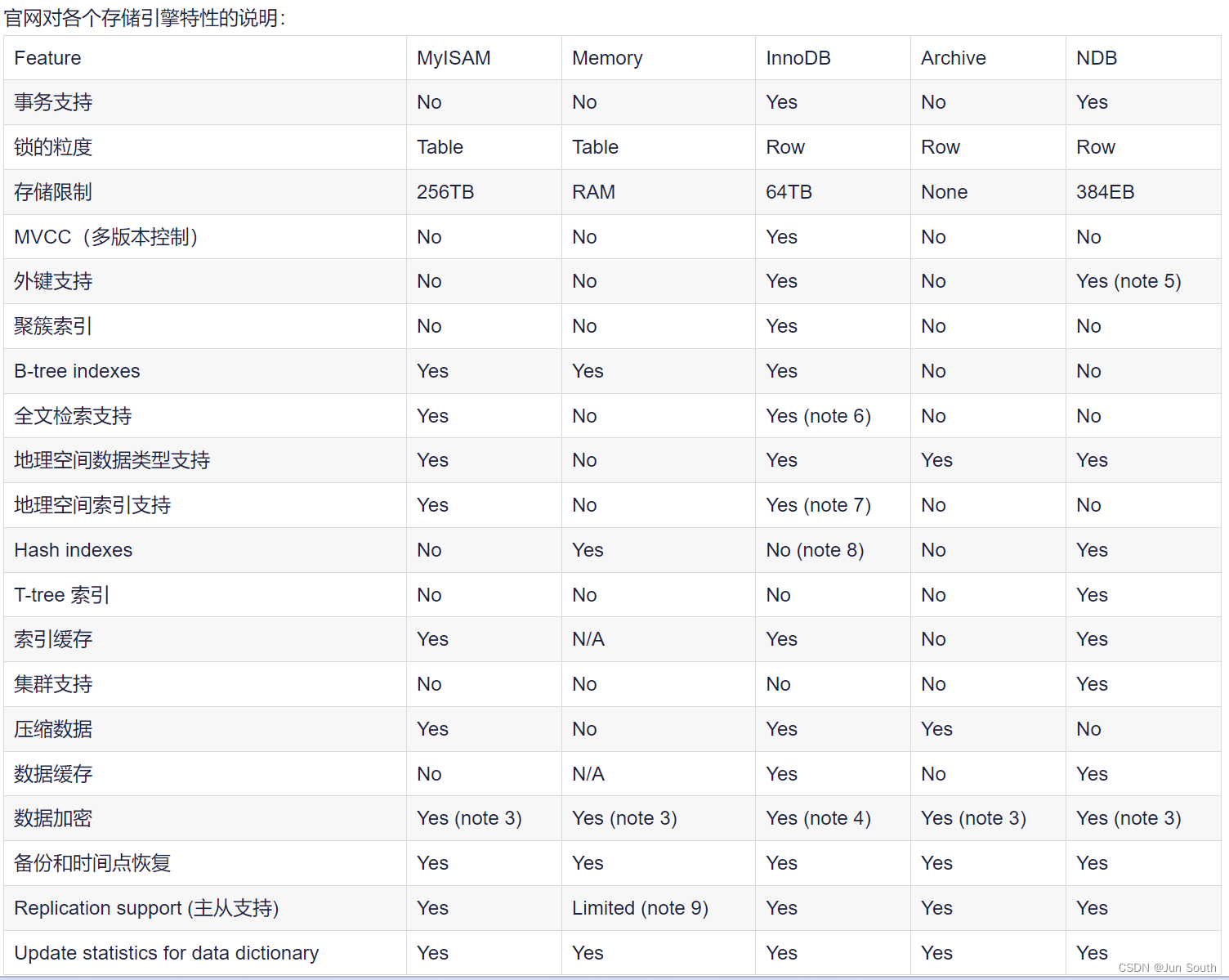
1、InnoDB存储引擎
从MySQL5.5版本之后,默认内置存储引擎是InnoDB,主要特点有:
(1)灾难恢复性比较好;
(2)支持事务。默认的事务隔离级别为可重复读,通过MVCC(并发版本控制)来实现的。
(3)使用的锁粒度为行级锁,可以支持更高的并发;
(4)支持外键;
(5)配合一些热备工具可以支持在线热备份;
(6)在InnoDB中存在着缓冲管理,通过缓冲池,将索引和数据全部缓存起来,加快查询的速度;
(7)支持聚簇索引。对于InnoDB类型的表,其数据的物理组织形式是聚簇表。所有的数据按照主键来组织。数据和索引放在一块,都位于B+数的叶子节点上,通过聚簇索引来查询可以减少回表查询。
(8)InnoDB不保存表的具体行数,执行select count(*) from table时需要全表扫描
(9)支持B-tree索引和全文检索( MySQL 5.6后InnoDB存储引擎开始支持全文检索)
(10)不支持Hash索引,但是内置了自适应hash索引。
2、MyISAM存储引擎
在5.5版本之前,MyISAM是MySQL的默认存储引擎,该存储引擎并发性差,不支持事务,所以使用场景比较少,主要特点为:
(1)不支持事务;
(2)不支持外键,如果强行增加外键,不会提示错误,只是外键不其作用;
(3)不支持聚簇索引,对数据的查询缓存只会缓存索引,不会像InnoDB一样缓存数据,而且是利用操作系统本身的缓存;
(4)默认的锁粒度为表级锁,所以并发度很差,加锁快,锁冲突较少,所以不太容易发生死锁;
(5)支持全文索引(MySQL5.6之后,InnoDB存储引擎也对全文索引做了支持),但是MySQL的全文索引基本不会使用,对于全文索引,现在有其他成熟的解决方案,比如:ElasticSearch,Solr,Sphinx等。
(6)数据库所在主机如果宕机,MyISAM的数据文件容易损坏,而且难恢复;
二、InnoDB的结构组成

1、内存结构
1.Buffer Pool(读缓冲池)
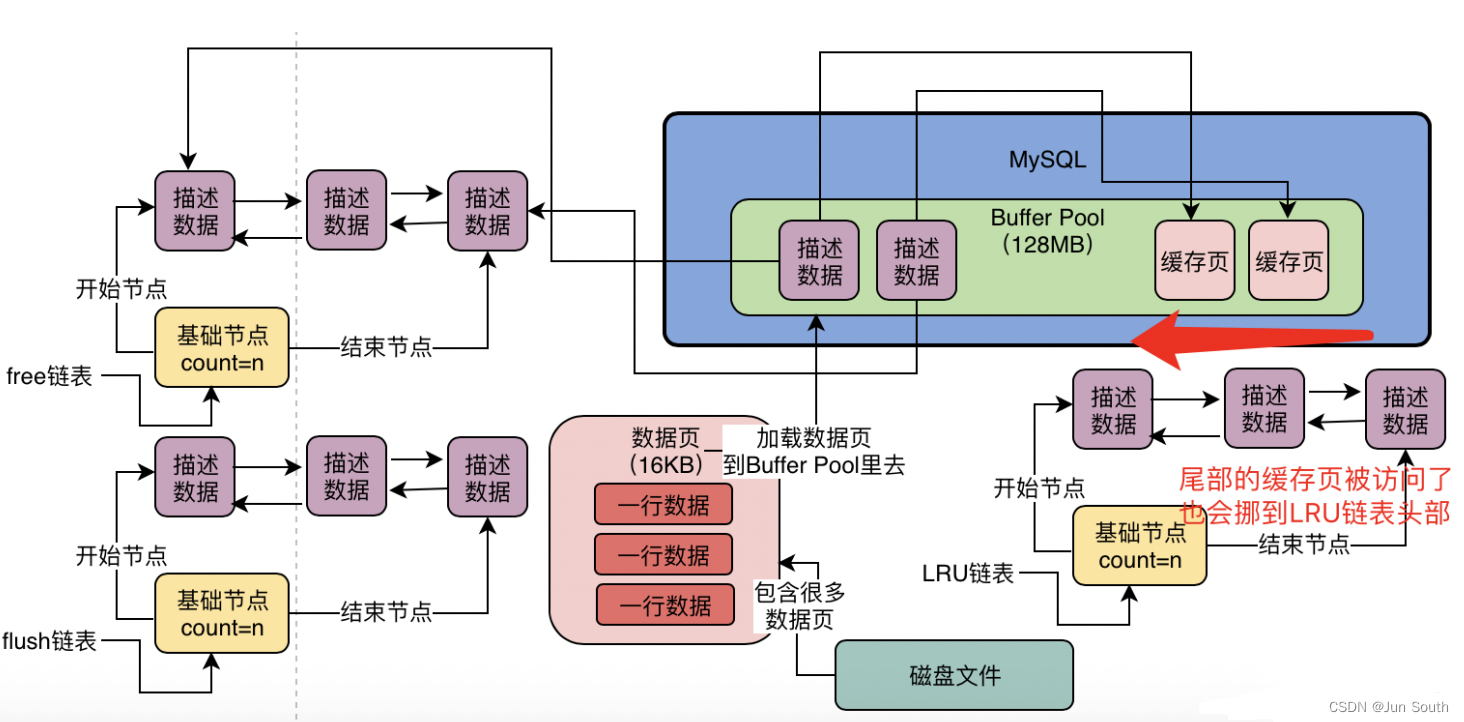
缓冲池是主内存中的一个区域,InnoDB在访问表和索引数据时会在其中进行缓存,避免每次访问都进行磁盘IO。
Buffer Pool的三个链表,LRU链表、free链表、flush链表。
free链表:双向链表,每个节点缓存页的描述数据块的地址。
flush链表:被修改过的缓存页的描述数据块,组成的双向链表,后续都是要flush刷新到磁盘上去。
LRU链表:将频繁访问的数据放在链表头部,不怎么访问的数据链表末尾,空间不够的时候就从尾部开始淘汰。
2.Change Buffer(写缓冲池)
如果发生变化的辅助索引页不在buffer pool里,由Change Buffer先缓存这些辅助索引页的变更动作。
等辅助索引页被读取时,再将数据再将数据合并(merge)恢复到缓冲池中的技术;或者定期对写辅助索引页的changes buffer进行合并,写到到buffer pool 中。目的是降低写操作的磁盘IO,提升数据库性能。
为什么change buffer只对辅助索引生效?
以insert新增操作为例,插入顺序一般是按照主键递增顺序进行插入的,插入聚集索引(主键索引)一般是顺序的,不需要磁盘的随机读取。
这种情况下对聚集索引的修改速度是非常快的,所以不需要进行写缓冲。
而对于辅助索引的插入或者更新操作,由于B+树的索引结构的特性决定了辅助索引插入的离散型。
所以,对于辅助索引的插入或者更新操作,InnoDB中不是每一次都直接插入到索引页中,而是先判断插入的辅助索引页是否在缓存区中,若在直接插入;
若不在,则先放入到change buffer中,然后再以一定频率和情况进行change buffer和辅助索引页子节点的merge(合并)操作,
这时通常能将多个插入合并到一个操作中(因为在一个索引页中),这就大大提高了对于辅助索引插入的性能。
3.自适应hash索引(Adaptive Hash Index,AHI)
InnoDB存储引擎会监控对表上各索引页的查询,如果观察到建立hash索引可以提高查询速度,则自动建立hash索引,索引的索引。
4. Log Buffer(日志缓冲)
保存要写入磁盘上的日志文件数据的内存区域,由innodb_log_buffer_size变量定义大小,默认16MB。
日志缓冲区的内容定期刷新到磁盘,较大的日志缓冲区使大型事务可以运行,而无需在事务提交之前将redo日志数据写入磁盘。
插入或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘I/O。
2、磁盘结构
1、表
2、索引
3、表空间

系统表空间
系统表空间是存放change buffer的区域。
表单文件表空间
每个表的数据和索引都会采用单独的文件进行保存。是否启动 file-per-table表空间是由innodb_file_per_table属性来控制的。
常规表空间
常规表空间是使用 CREATE TABLESPACE 语法创建的共享InnoDB表空间。是共享的表空间,一个文件能够存储多个表数据,常规表空间由于多表共享表空间,消耗的内存会更少一点,具有潜在的内存优势。
Undo表空间
回滚表空间,用来保存回滚日志,即undo logs。
临时表空间(Temporary Tablespaces)
InnoDB使用会话临时表空间和全局临时表空间。
4、Doublewrite Buffer(双写缓冲)
doublewrite 缓冲区是一个存储区域,InnoDB在将页面写入InnoDB数据文件中之前,会写入从缓冲池中刷新的页面。
如果在页面写入过程中发生操作系统,存储子系统或mysqld进程崩溃,则InnoDB可以在崩溃恢复期间从doublewrite缓冲区中找到该页面的良好副本。
MySQL 8.0.20之前,doublewrite缓冲区存储区位于InnoDB系统表空间中。
MySQL 8.0.20开始,doublewrite缓冲区存储区位于doublewrite文件中。
5、Redo Log(重做日志)
基于磁盘的数据结构,主要防止在崩溃恢复期间用于纠正不完整事务写入的数据。
正常操作时,重做日志对更改表数据的请求进行编码记录。初始化时,自动重播未完成意外关闭之前未完成更新数据文件的修改。
默认情况下,redo log会自动生成2个文件。
6、Undo Logs(回滚日志)
回滚日志主要是为了支持事务回滚功能。默认会生成2个回滚日志,保存在undo tablespaces下。
补充:二进制日志(binlog)
binlog是记录所有数据库表结构变更(例如CREATE、ALTER TABLE…)以及表数据修改(INSERT、UPDATE、DELETE…)的二进制日志。
用于数据恢复和数据复制
MySQL正是通过主服务器的二进制日志来实现数据的传递。主服务器上的二进制日志内容会被发送到各个从服务器,并在每个从服务器上执行,从而保证了主从服务器之间数据的一致性。
在默认配置下,MySQL不记录二进制日志。可以通过设置参数–log-bin=[base_name]启用二进制日志功能。
三、SQL的执行
1、查询流程
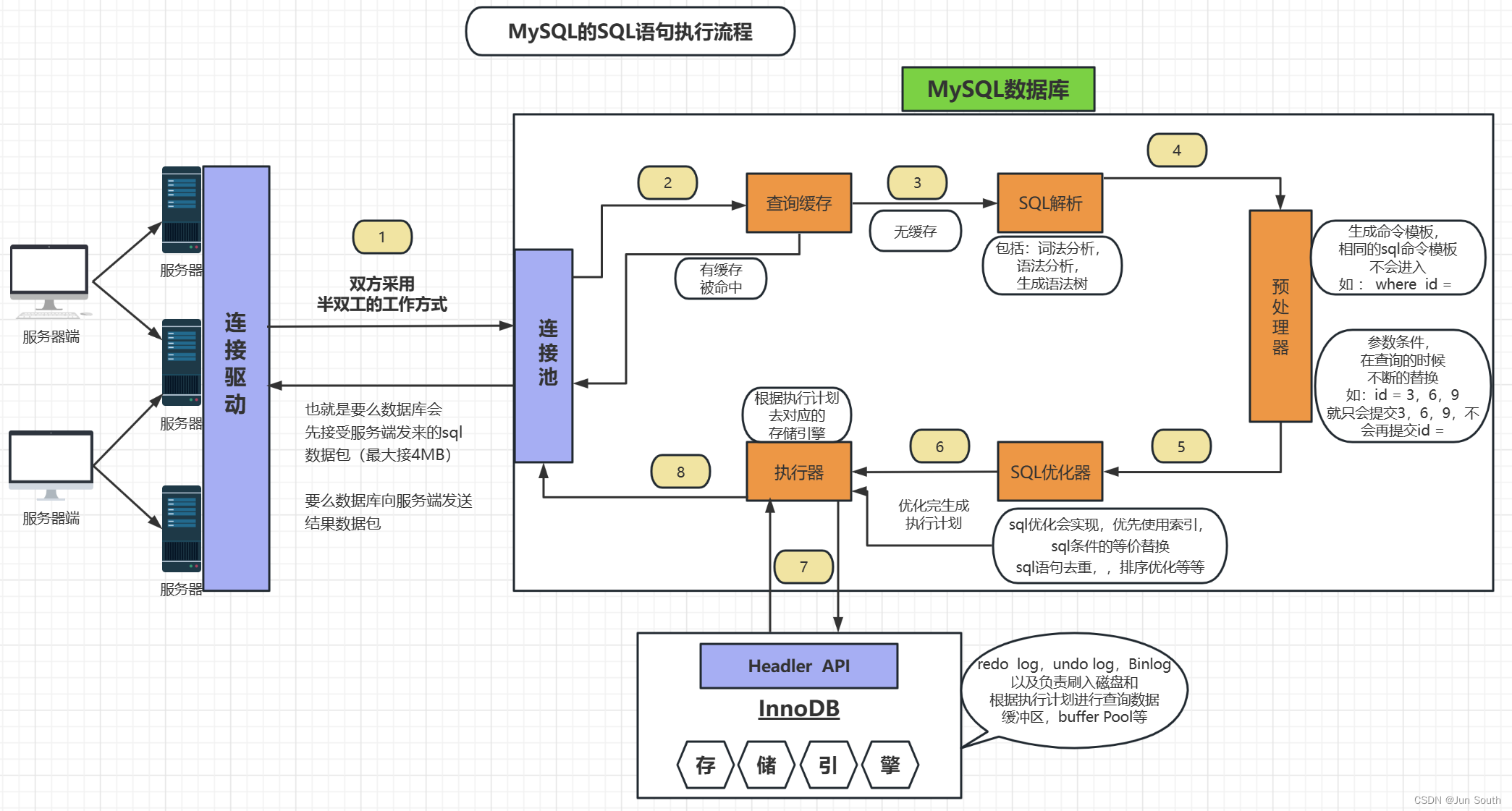
2、写入流程