mysql体系结构
mysql Server 架构自顶向下大致可以分为网络连接层,服务层,存储引擎和系统文件层.体系架构图如下:
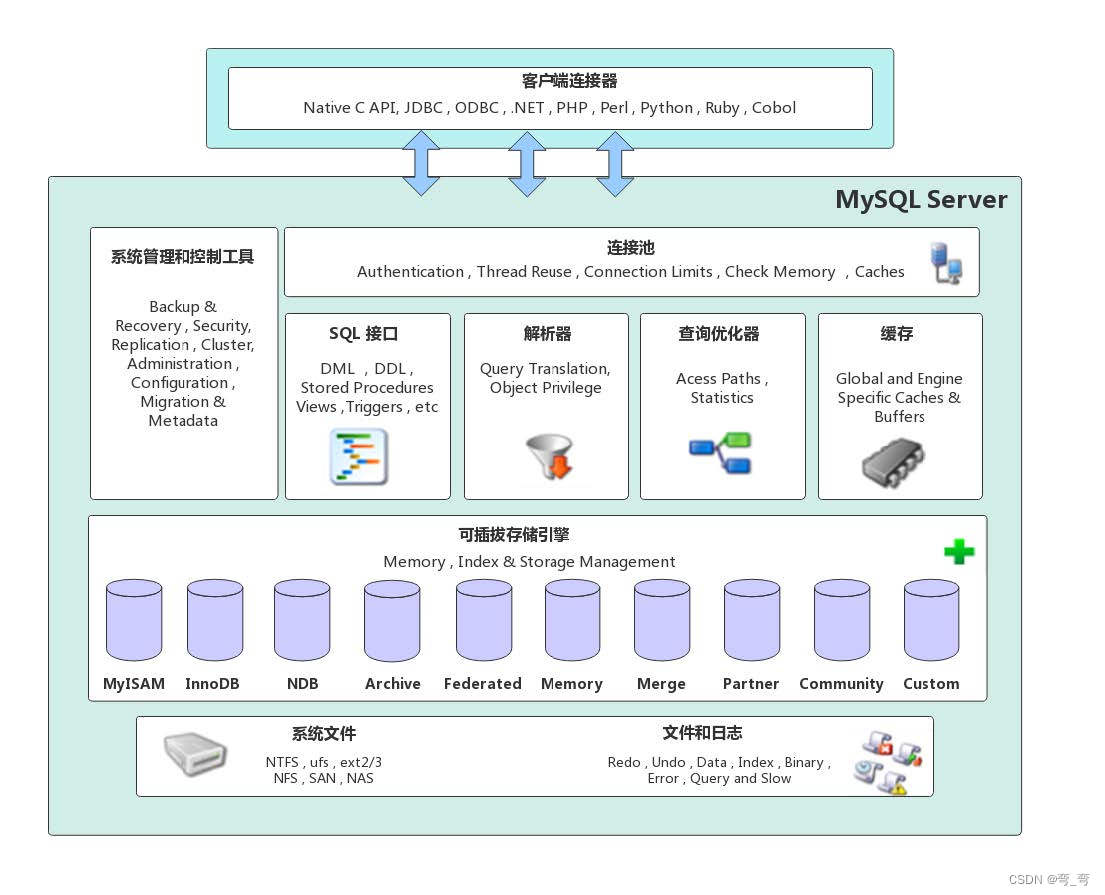
网络连接层提供与mysql服务器建立的支持.常见的java.c.python/.net ,它们通过各自API技术与mysql建立连接.
服务层是Mysql Server 的核心,主要包含系统管理和控制工具,连接池,SQL连接,解析器,查询优化器和缓存六部分.
存储引擎负责MySQL中数据的存储与提取,与底层系统文件进行交互.MySQL 存储引擎是插件式的,服务器中的查询执行引擎通过接口与存储引擎进行通信,接口屏蔽了不同存储引擎之间的差异.最常见的存储引擎是MYISAM和InnoDB.
系统文件层负责数据库的数据和日志存储在文件系统上, 并完成与存储引擎的交互,是文件的物理存储层, 主要包含日志文件,数据文件,配置文件.pid文件.socket文件等.
mysql的运行机制
mysql的逻辑架构如下:
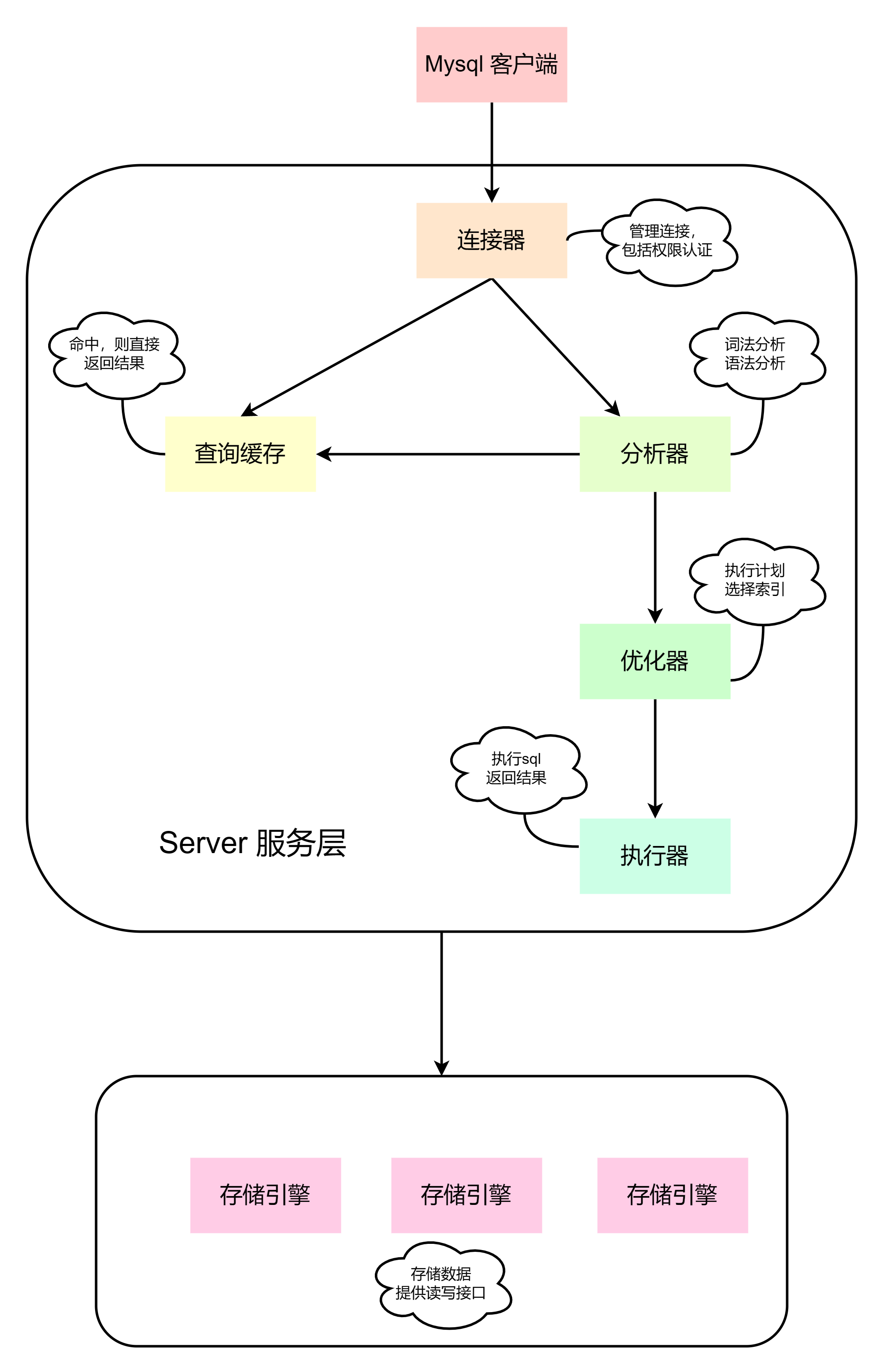
MYSQL 可以分为server层和存储引擎层, Server层包括连接器、查询缓存、分析器、优化器、执行器,包括大多数Mysql 中的核心功能, 所有跨存储引擎的功能也在这一层实现,包括存储过程、触发器、视图等。
存储引擎层包括Mysql 常见的存储引擎,包括MyISAM、InnoDB的鞥,最常用的是InnoDB,也是mysql5.5 以后的默认存储引擎。
mysql执行过程如下图
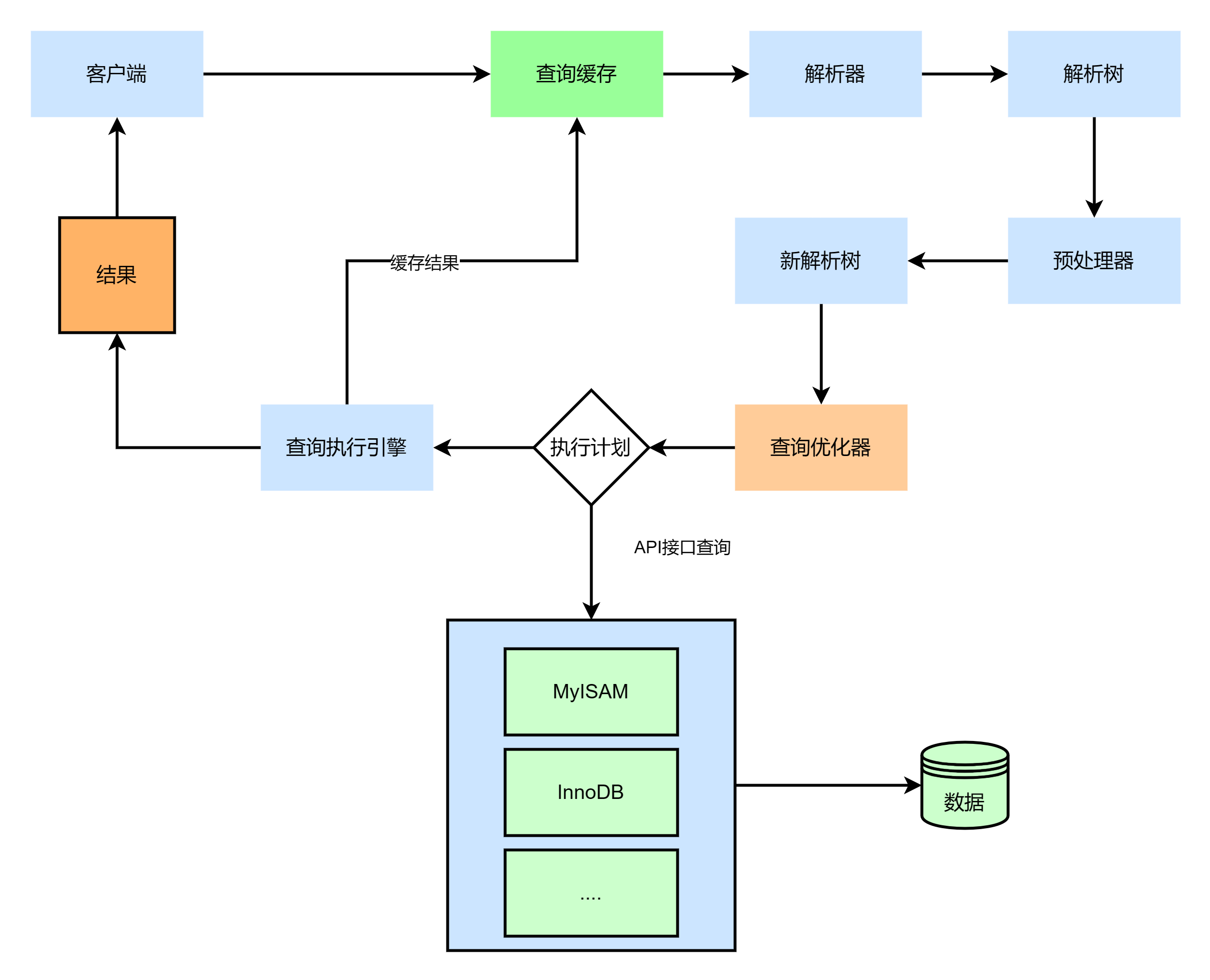
连接器
通过客户端/服务端通信协议与Mysql 建立连接,需要一个连接器来连接用户和Mysql 数据库。MySQL客户端与服务端的通信方式是"半双工". 对于每个MYSQL连接,时刻都有一个线程状态来标识这个连接正在做什么.
可以通过"show processlist" 查看用户正在运行的线程信息,root用户能查看所有线程,其他用户只鞥能自己的;
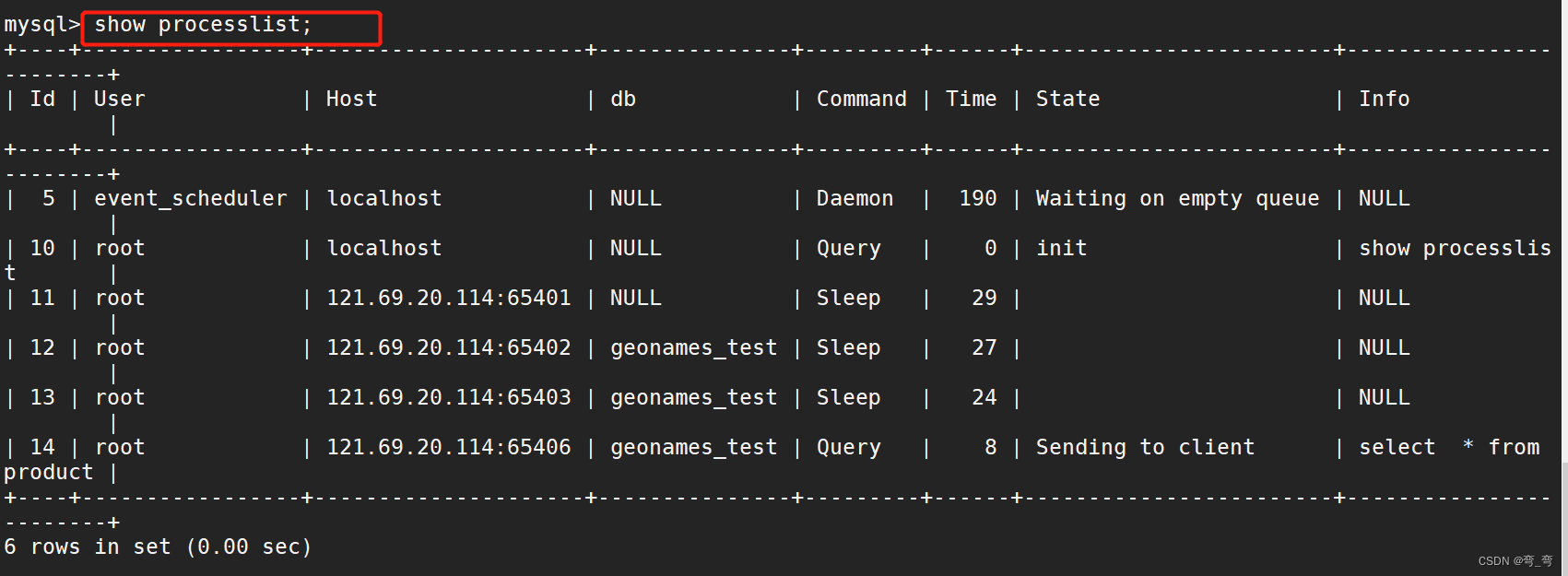
id: 线程ID,可以使用kill xx;
user: 启动这个线程的用户;
Host:发送请求的客户端的IP 和端口号
db: 当前命令在哪里库执行;
command: 该线程正在执行的操作命令
(1) Create DB:正在创建库操作;
(2) Drop DB:正在删除库操作;
(3)Execute:正在执行一个PreparedStatement
(4)Close Stmt:正在关闭一个PreparedStatement
(5)Query:正在执行一个语句
(6)Sleep:正在等待客户端发送语句
(7)Quit:正在退出
(8)Shutdown:正在关闭服务器
time: 表示该线程处于当前状态的时间,单位是秒;
State:线程状态
(1)Updating:正在搜索匹配记录,进行修改;
(2)Sleeping:正在等待客户端发送新请求;
(3)Starting:正在执行请求处理;
(4)Checking table:正在检查数据表;
(5)Closing table : 正在将表中数据刷新到磁盘中;
(6)Locked:被其他查询锁住了记录;
(7)Sending Data:正在处理Select查询,同时将结果发送给客户端;
Info:一般记录线程执行的语句,默认显示前100个字符。想查看完整的使用show full
processlist;
查询缓存
查询缓存(Cache&Buffer),这是MySQL的一个可优化查询的地方,如果开启了查询缓存且在查询缓存过程中查询到完全相同的SQL语句,则将查询结果直接返回给客户端;如果没有开启查询缓存或者没有查询到完全相同的 SQL 语句则会由解析器进行语法语义解析,并生成“解析树”。
执行Select查询时,先查询缓存,判断是否存在可用的记录集,要求是否完全相同(包括参数值),这样才会匹配缓存数据命中;即使开启查询缓存,以下SQL也不能缓存:
(1)查询语句使用SQL_NO_CACHE;
(2)查询的结果大于query_cache_limit设置;
(3)查询中有一些不确定的参数,比如now();
show variables like ‘%query_cache%’; //查看查询缓存是否启用,空间大小,限制等;
show status like ‘Qcache%’; //查看更详细的缓存参数,可用缓存空间,缓存块,缓存多少等;
在mysql8 之后,查询缓存就被移除的,移除的原因主要有以下三点:
1.查询缓存的效果取决于缓存的命中率,只有命中缓存的查询效果才能有改善,因此无法预测其性能。
2.查询缓存的另一个大问题是它受到单个互斥锁的保护。在具有多个内核的服务器上,大量查询会导致大量的互斥锁争用。
3.研究表明,缓存越靠近客户端,获得的好处越大。
解析器
解析器(Parser)将客户端发送的SQL进行语法解析,生成"解析树"。预处理器根据一些MySQL
规则进一步检查“解析树”是否合法,例如这里将检查数据表和数据列是否存在,还会解析名字和别
名,看看它们是否有歧义,最后生成新的“解析树”。
查询优化器
查询优化器(Optimizer)根据“解析树”生成最优的执行计划。MySQL使用很多优化策略生成最
优的执行计划,可以分为两类:静态优化(编译时优化)、动态优化(运行时优化)。
- 等价变换策略
- 5=5 and a>5 改成 a > 5
- a < b and a=5 改成b>5 and a=5
- 基于联合索引,调整条件位置等
- 优化count、min、max等函数
- InnoDB引擎min函数只需要找索引最左边
- InnoDB引擎max函数只需要找索引最右边
- MyISAM引擎count(*),不需要计算,直接返回
- 提前终止查询
- 使用了limit查询,获取limit所需的数据,就不在继续遍历后面数据
- in的优化
- MySQL对in查询,会先进行排序,再采用二分法查找数据。比如where id in (2,1,3),变成 in (1,2,3)
查询执行引擎
查询执行引擎负责执行 SQL 语句,此时查询执行引擎会根据 SQL 语句中表的存储引擎类型,以及对应的API接口与底层存储引擎缓存或者物理文件的交互,得到查询结果并返回给客户端。若开启用查询缓存,这时会将SQL 语句和结果完整地保存到查询缓存(Cache&Buffer)中,以后若有相同的 SQL 语句执行则直接返回结果。如果开启了查询缓存,先将查询结果做缓存操作;如果返回结果过多,采用增量模式返回.
当执行一条查询的SQL的时候,大概发生以下步骤:
1.客户端发送查询语句给服务器;
2.服务器首先检查缓存中是否存在该查询,若存在,返回缓存中的结果,若不存在就进行下一步。(Mysql8 后没有这一步);
3.服务器进行SQL的解析、语法检测和预处理,再由优化器生成对应的执行计划;
4.Mysql 的执行器根据优化器生成的执行计划执行,调用存储引擎的接口进行查询;
5.服务器将查询的结果返回客户端;