我们思考一下这个问题:
观察以下代码,在运行的时候会崩溃
想一想为什么
#include<iostream>
using namespace std;
//栈类
typedef int DataType;
class Stack
{
public:
//默认构造:
Stack(size_t capacity = 3)
{
_array = (DataType*)malloc(sizeof(DataType) * capacity);
if (NULL == _array)
{
perror("malloc 申请空间失败!!!");
return;
}
_capacity = capacity;
_size = 0;
}
//压栈
void Push(DataType data)
{
//CheckCapacity();
_array[_size] = data;
_size++;
}
//析构
~Stack()
{
cout << "~Stack()" << endl;
free(_array);
_array = nullptr;
_size = _capacity = 0;
}
private:
DataType* _array;
int _capacity;
int _size;
};
void func1(Date d)
{
d.Print();
}
void func2(Stack s)
{
}
int main()
{
Stack s1;
func2(s1);
return 0;
}
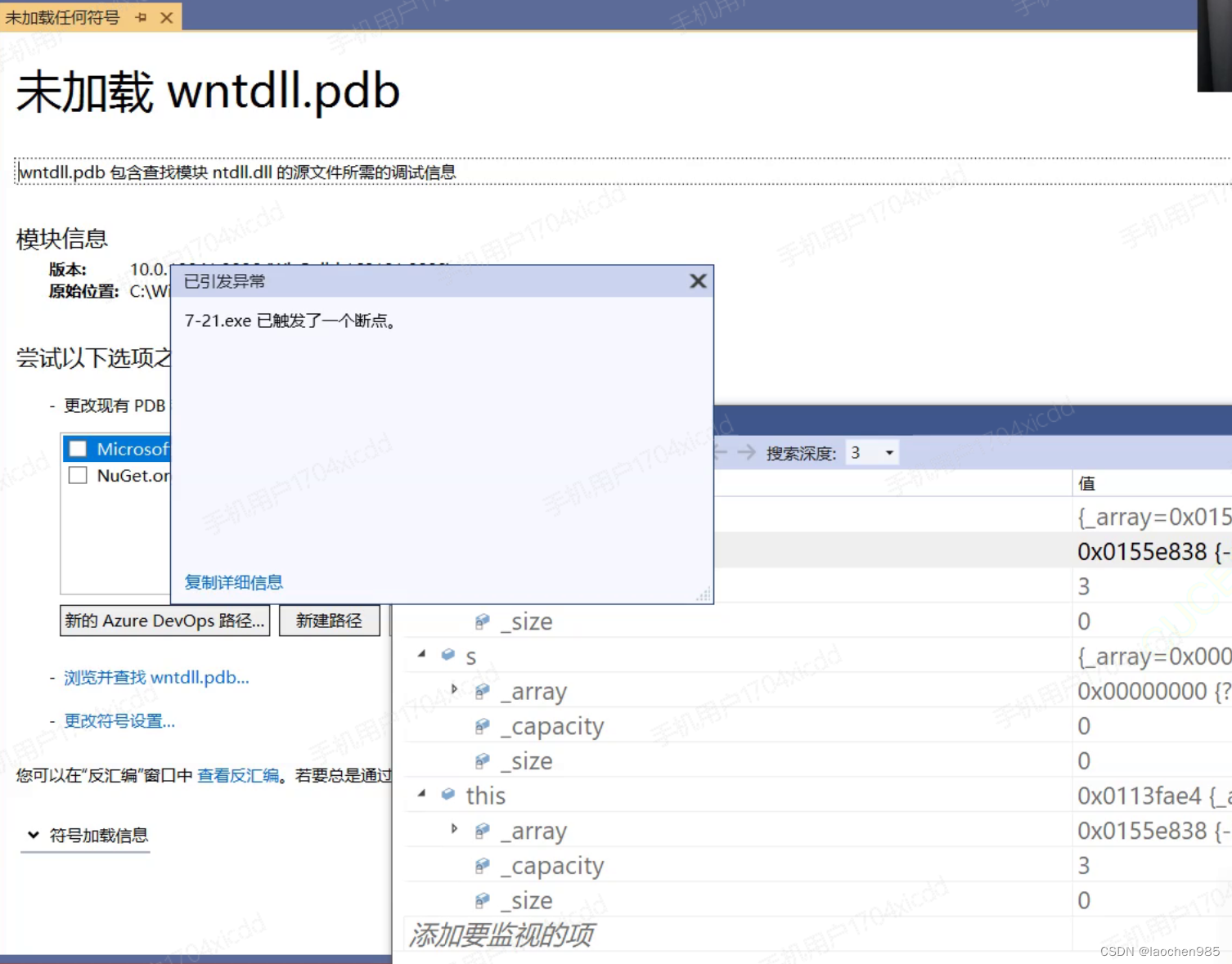
为什么这种情况下编译的时候会报错?
因为你这里有一个主函数,主函数里面有一个栈类型的变量s1,然后呢这个主函数中我们使用了一个名为func2的函数。这个时候编译器就又会去建立一个func2函数的栈帧。
这个时候要进行传参。
传值方式的传参是一种值的拷贝(或者叫做浅拷贝),意思就是把S1这个空间里的值直接拷贝到 func2这个函数栈帧中。
但是这个时候我们要注意。
我们在主函数的那个S1里面的成员变量_a是一个指针。指向了我们向内存申请的空间。如果我们把这个成员变量_a的值直接拷贝到func2函数中。那么func2函数中也会存取一份指针变量_a的所存的内容(即我们向内存所申请空间的地址)。
由于这是c++,当我们调用了func 2之后,在出这个函数的时候,它会自动调用析构函数。而析构函数会自动释放指针变量所指的那个空间。
于是乎_a所指向的那个空间被我们释放掉了,当我们回到主函数的时候,我们使用完s1结束的时候会再次调用析构函数,这样的话,会造成对同一个空间的再一次释放,所以程序会崩溃。
如何解决:
引用:& (引用其实就是对变量取别名)
void func2(Stack &s)
{
}
如果我希望s的改变不去影响s1那该怎么办
即:你希望s 只是 s1 的拷贝
这个时候用一个对象去拷贝另外一个对象的时候,C++定义了一个函数来解决这样一个问题。
这个函数叫做拷贝构造。
拷贝构造函数也是一个特殊的成员函数 其特征如下,
- 拷贝构造函数是构造函数的一个重载形式。
- 拷贝构造函数的参数只有一个,且必须是同类型对象 的引用,使用传值方式编译器直接报错,因为会引发无穷递归调用。(你如果不用引用的话,就会造成无穷递归)
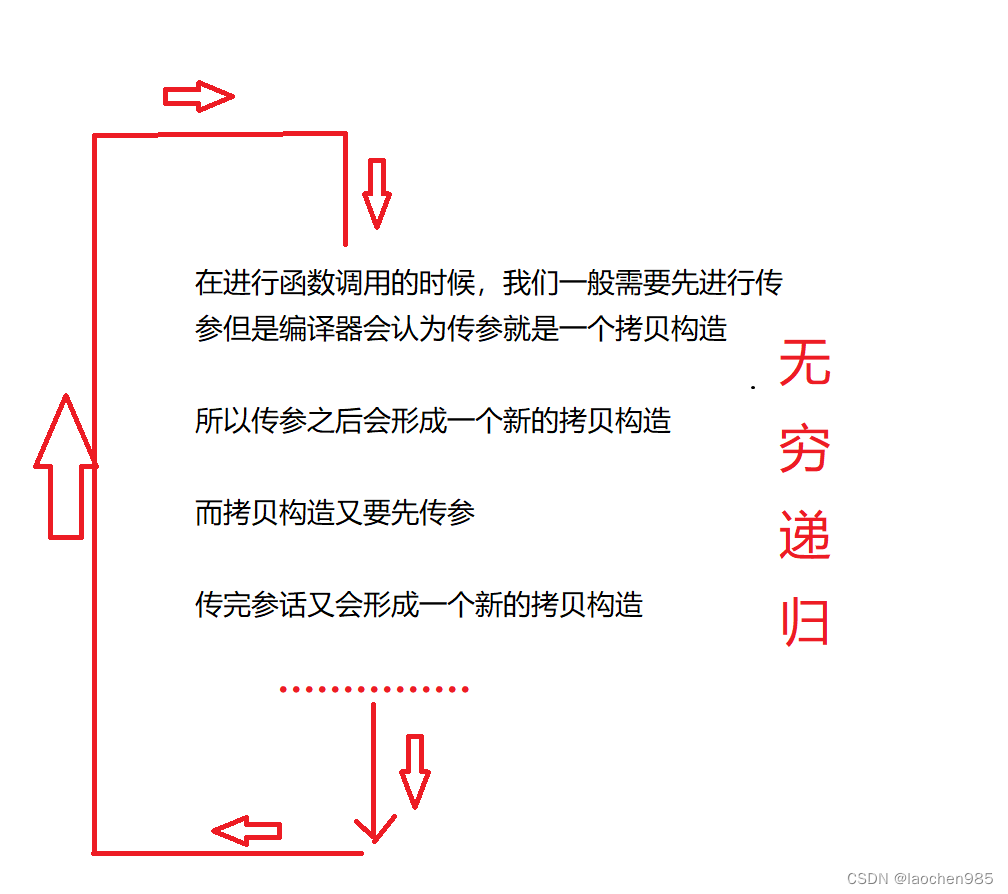
函数传参如果是内置类型,那就直接拷贝没问题
如果是自定义类型,则不能直接传,而是要调用一个函数来解决,这个函数就叫拷贝构造
为什么传值传参要调用拷贝构造函数?
为什么传值传参不能像c语言一样,结构体一样把相应的值依次的拷贝过去?
之前说了:像栈这样的类,如果你传值传参按浅拷贝的方式去拷贝的话,则会出现两次调用析构函数的情况,这会造成程序的崩溃。
所以这个时候我们必须要调用一个函数来解决这个问题,这个函数就是拷贝构造函数,他可以帮我们解决两次调用析构函数这个麻烦。这个拷贝构造函数可以完成深拷贝。
是不是有点懵,没关系,我们再来强调一下。
在c语言中,我们函数传值传参是直接拷贝的因为他不会出现一些问题
但是在c++中,如果我们直接拷贝的话,如果是栈这种类型对象的函数它会出现析构函数两次释放同一个空间的情况,
所以这个时候我们的拷贝就不能直接拷贝了,我们需要调用拷贝构造函数来进行拷贝。
我们使用拷贝构造函数来传参的话,那么函数它在传参的时候,它就不会直接传参,他会把参数先给拷贝构造函数,让拷贝构造函数处理完了之后再返回给函数,然后再进行函数中的内容。自定义类型传值传参必须调用拷贝构造。
就是在c++的逻辑中,任何传参都会先调用拷贝构造函数。
所以你会疑惑,为什么会造成深度递归呢?
因为当你使用函数的时候,拷贝构造函数和默认构造函数是构成函数重载的,那么当你调用这个函数的时候,你创建了一个d2嘛,那个d2面后面的括号里面写的是d1
那么他的这个形式是符合函数重载的形式的,这个时候他就会去调用拷贝构造函数,他调用拷贝构造函数的时候,(我们调用函数的时候,第一步先传参,C++的逻辑嘛,传参之前先要传给拷贝构造函数,当拷贝构造函数处理完成之后再传回给调用了的那个函数)那么它就会先把d1的内容传给拷贝构造函数,然后传给拷贝构造函数之后就要进行下一步了,但是当你传给拷贝构造函数之后,你会发现,拷贝后函数又会认为你的这个行为是一个传参的行为,所以他就又会传给拷贝构造函数,就这样一直循环了,死循环了,造成了一个深度的递归
与默认构造函数和析构函数的不同
拷贝构造函数和我们之前学的析构函数和默认构造函数的不同就是当我们不写它的时候,编译器默认生成的拷贝构造函数可以处理内置类型,它会对内置类型进行值拷贝 对自定义类型调用他相应的拷贝。
总结一下
日期类(Date)不需要我们实现拷贝构造,编译器默认生成的就可以直接用了。
但是栈这个类需要我们自己来写一个拷贝构造函数来实现深拷贝,因为编译器默认生成的会出现问题
注意:
//拷贝构造函数 用同类型的对象来初拷贝始化它,所以叫拷贝构造
Date(const Date& d)
{
cout << "Date(Date& d)" << endl;
_year = d._year;
_month = d._month;
_day = d._day;
}
我们为什么要加一个const?
因为在使用的时候,如果某一天你喝了酒,你把两个变量的位置写反了,这个时候你又没有察觉。那么就会造成一些错误的情况出现。
所以这个时候我们可以在前面加一个const限制一下。
加了const之后,他的权限就变小了,也符合引用的规则
进行引用的时候,权限是可以缩小的,但是是不能放大的