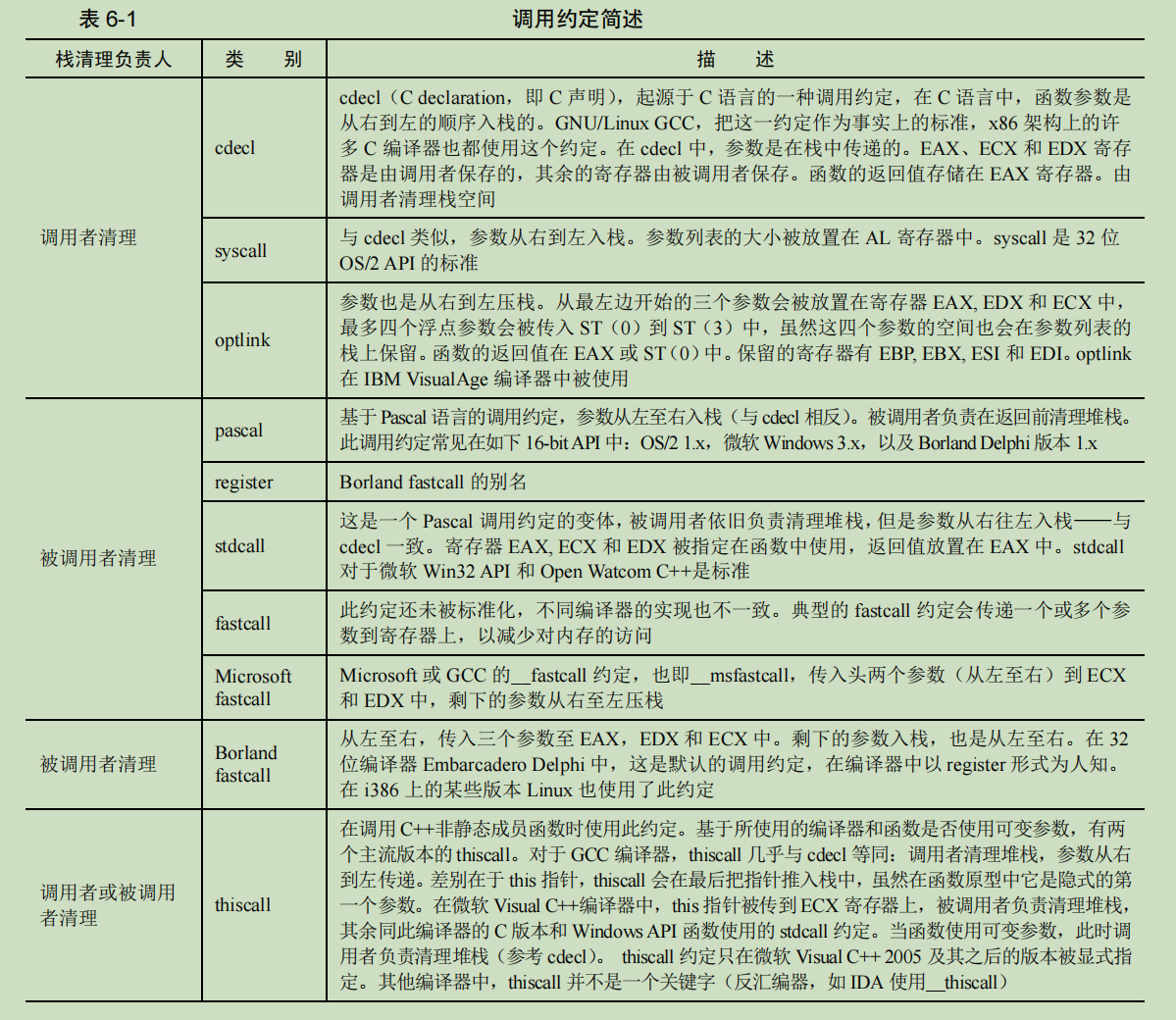
一.函数调用约定简介
调用约定,calling conventions,从字面上理解,它是调用函数时的一套约定,是被调用代码的接口,它体现在:
- 参数的传递方式,是放在寄存器中?栈中?还是两者混合?
- 参数的传递顺序,是从左到右传递?还是从右到左?
- 是调用者保存寄存器环境,还是被调用者保存?保存哪些寄存器呢?
二、 实现自己的打印函数
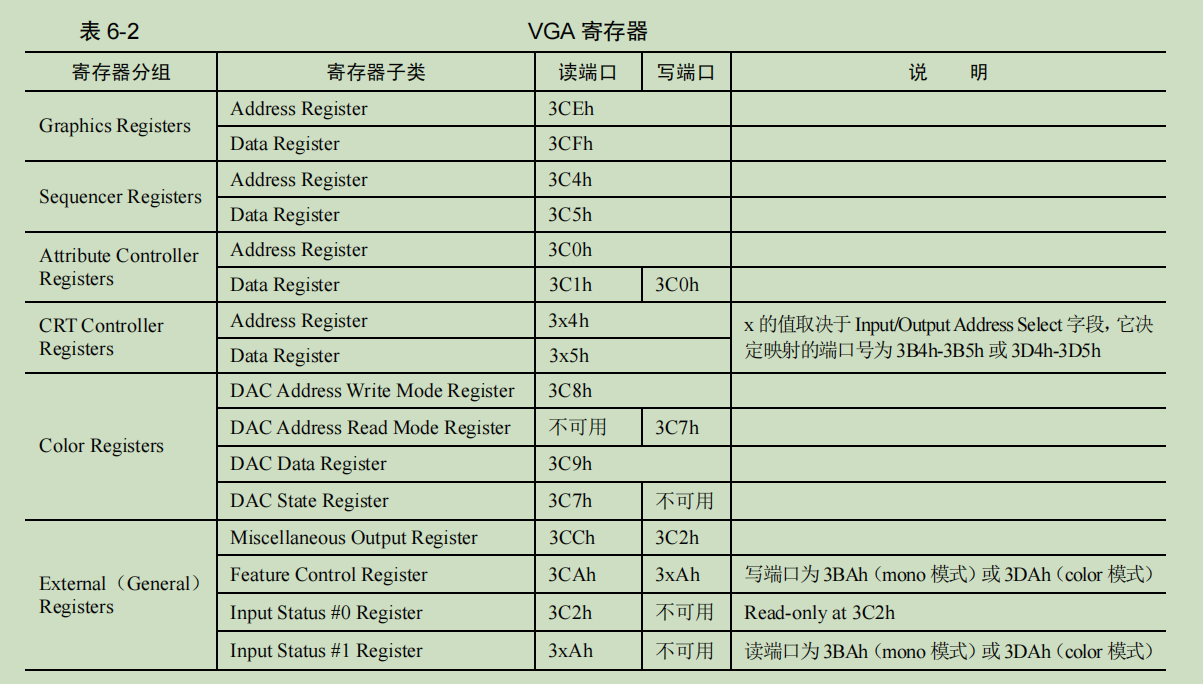
1. 显卡的端口控制
-
前四组寄存器属于分组,寄存器分组的原因是显卡上的寄存器太多,而系统端口有限。所以,对这类寄存器操作方法是先在Address Register中指定寄存器的索引值,用来确定所操作的寄存器是哪个,然后在Data Register 寄存器中对所索引的寄存器进行读写操作。
-
上面CRT Controller Registers 寄存器组中的 Address Register 和 Data Register 的端口地址有些特殊,它的端口地址并不固定,具体值取决于 Miscellaneous Output Register 寄存器中的 Input/Output Address Select 字段

-
I/OAS(Input/Output Address Select),此位用来选择 CRT controller 寄存器组的地址,这里是指 Address Register 和 Data Register 的地址。
-
当此位为 0 时:并且为了兼容 monochrome 适配器(显卡),Input Status #1 Register 寄存器的端口地址被设置为 0x3BA
-
当此位为 1 时:并且为了兼容 color/graphics 适配器(显卡),Input Status #1Register 寄存器的端口地址被设置为 0x3DA
Feature Control register 寄存器的写端口也是 3xAh 的形式,该端口地址取值以同样的方式受 I/OAS 位的影响。
- 如果 I/OAS 位为 0,写端口地址为 3BAh。
- 如果 I/OAS 位为 1,写端口地址为 3DAh。
默认情况下,Miscellaneous Output Register 寄存器的值为 0x67,其他字段不管,咱们只关注这最重要的 I/OAS 位,其值为 1。也就是说:
- CRT controller 寄存器组的 Address Register 的端口地址为 0x3D4,Data Register 的端口地址 0x3D5
- Input Status #1Register 寄存器的端口地址被设置为 0x3DA。
- Feature Control register 寄存器的写端口是 0x3DA。
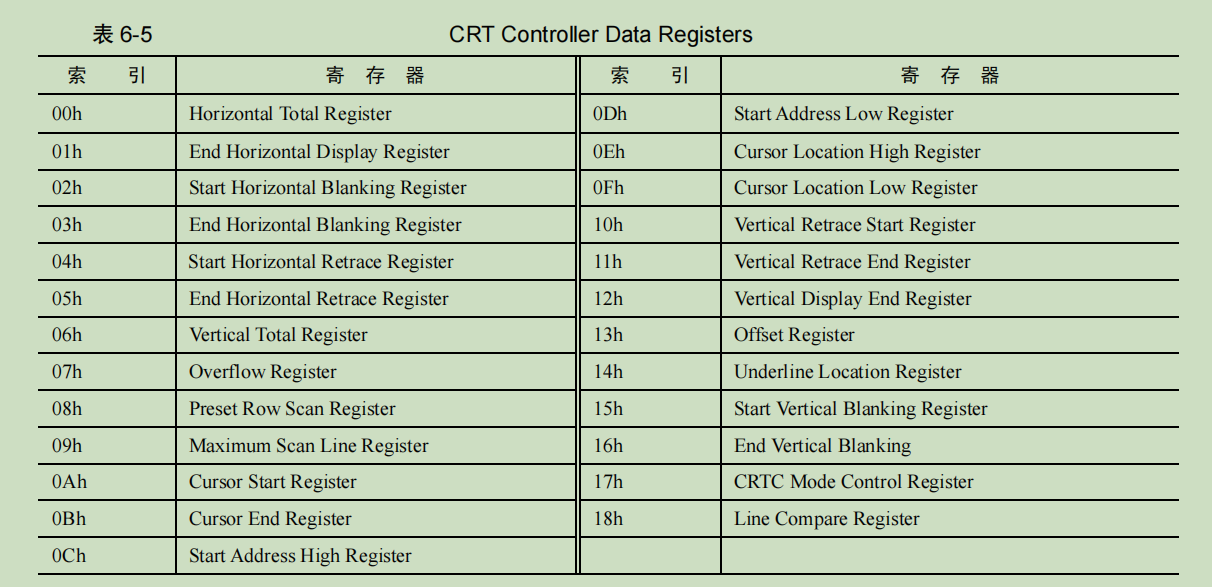
| 索引 | 寄存器名称 | 功能 |
|---|---|---|
| 00h | Horizontal Total Register | 水平总寄存器,定义了一个完整水平扫描线所需要的总像素数 |
| 01h | End Horizontal Display Register | 水平显示结束寄存器,定义了显示区的宽度,即一个水平扫描线上可见的像素数 |
| 02h | Start Horizontal Blanking Register | 水平消隐开始寄存器,定义了水平消隐的起始像素位置 |
| 03h | End Horizontal Blanking Register | 水平消隐结束寄存器,定义了水平消隐的结束像素位置 |
| 04h | Start Horizontal Retrace Register | 水平回扫开始寄存器,定义了水平回扫的起始像素位置 |
| 05h | End Horizontal Retrace Register | 水平回扫结束寄存器,定义了水平回扫的结束像素位置 |
| 06h | Vertical Total Register | 垂直总寄存器,定义了一个完整垂直扫描线所需的总行数 |
| 07h | Overflow Register | 溢出寄存器,定义了垂直回扫时,超出垂直总行数范围的行数 |
| 08h | Preset Row Scan Register | 预设行扫描寄存器,定义了显示器的初始扫描行 |
| 09h | Maximum Scan Line Register | 最大扫描行数寄存器,定义了每个水平扫描线上的最大行数 |
| 0Ah | Cursor Start Register | 光标开始寄存器,定义了光标显示的起始行 |
| 0Bh | Cursor End Register | 光标结束寄存器,定义了光标显示的结束行 |
| 0Ch | Start Address High Register | 起始地址高位寄存器,定义了显示区的起始地址的高8位 |
| 0Dh | Start Address Low Register | 起始地址低位寄存器,定义了显示区的起始地址的低8位 |
| 0Eh | Cursor Location High Register | 光标位置高位寄存器,定义了光标位置的高8位 |
| 0Fh | Cursor Location Low Register | 光标位置低位寄存器,定义了光标位置的低8位 |
| 10h | Vertical Retrace Start Register | 垂直回扫开始寄存器,定义了垂直回扫的起始行数 |
| 11h | Vertical Retrace End Register | 垂直回扫结束寄存器,定义了垂直回扫的结束行数 |
| 12h | Vertical Display End Register | 垂直显示结束寄存器,定义了垂直显示的结束行数 |
| 13h | Offset Register | 偏移寄存器,定义了每个字符在屏幕上占用的字节数 |
| 14h | Underline Location Register | 下划线位置寄存器,定义了下划线的位置 |
| 15h | Start Vertical Blanking Register | 垂直消隐开始寄存器 |
| 16h | End Vertical Blanking Register | 垂直消隐结束寄存器,定义了垂直消隐的结束行数 |
| 17h | CRTC Mode Control Register | CRTC模式控制寄存器,定义了CRTC控制器的模式和操作方式 |
| 18h | Line Compare Register | 行比较寄存器,定义了当CRT控制器扫描到一个特定行时发出的比较信号,可用于产生中断或其他操作 |
使用c语言实现自己的打印函数
先在Address Register中指定寄存器的索引值,用来确定所操作的寄存器是哪个,然后在Data Register 寄存器中对所索引的寄存器进行读写操作。
举例:
;;;;;;;;; 获取当前光标位置 ;;;;;;;;;
;先获得高8位
mov dx, 0x03d4 ;索引寄存器
mov al, 0x0e ;用于提供光标位置的高8位
out dx, al
mov dx, 0x03d5 ;通过读写数据端口0x3d5来获得或设置光标位置
in al, dx ;得到了光标位置的高8位
mov ah, al
;再获取低8位
mov dx, 0x03d4
mov al, 0x0f
out dx, al
mov dx, 0x03d5
in al, dx
屏幕每行 80 个字符,共 25 行,咱们的滚屏实现比较简单,现在说一下用此方案实现滚屏的步骤:
(1)将第 1~24 行的内容整块搬到第 0~23 行,也就是把第 0 行的数据覆盖。
(2)再将第 24 行,也就是最后一行的字符用空格覆盖,这样它看上去是一个新的空行。
(3)把光标移到第 24 行也就是最后一行行首。
经过这三步,屏幕就像向上滚动了一行
print.c
#include "print.h"
#include "io.h"
//设置光标位置
void set_cursor(unsigned short cursor_pos);
//往显存写入字符。参数:显存位置,写入的字符
void write_char(unsigned short video_memory_pos,char ch);
//向下滚动一行
void roll_screen();
void put_str(char* str)
{
while(*str != '\0')
{
put_char(*str);
str++;
}
}
void put_char(char ch)
{
//获取当前光标位置
unsigned short cursor_pos=0;
//高8位
unsigned char high_8=0;
outb(0x03d4,0x0e);
high_8 = inb(0x03d5);
//低8位
unsigned char low_8=0;
outb(0x03d4,0x0f);
low_8 = inb(0x03d5);
cursor_pos =(high_8<<8) + low_8;
//如果是换行键或者回车键
if(ch==0xd || ch==0xa )
{
cursor_pos=cursor_pos-(cursor_pos % 80)+80; //光标值减去除80的余数便是取整
if(cursor_pos<2000)
{
set_cursor(cursor_pos);
}
else
{
roll_screen(); //向下滚动一行
}
}
//如果是退格键
else if(ch==0x8)
{
//当为退格时,本质上只要将光标向前一个显存位置即可,后面再输入的字符自然会覆盖此字符
//但有可能在键入退格后不再键入新的字符,这时在光标已经向前移动到待删除的字符位置,但字符还在原处
//;这就显得好怪异,所以此处添加了空格或空字符0
cursor_pos--;
write_char(cursor_pos*2,0x20);
set_cursor(cursor_pos);
}
//普通字符
else
{
unsigned int video_memory_pos=cursor_pos*2;
write_char(video_memory_pos,ch);
cursor_pos++; //下一个光标值
if(cursor_pos<2000) //若光标值小于2000,表示未写到显存的最后,则去设置新的光标值
{
set_cursor(cursor_pos);
}
else
{
roll_screen(); //向下滚动一行
}
}
}
void put_int(unsigned int num)
{
unsigned char put_int_buffer[9] = {0};
char hex_digits[] = "0123456789ABCDEF";
//32位数字中,16进制数字的位数是8个
//遍历每一位16进制数字
int i;
for(i = 0; i<8; i++)
{
hex_str[i] = hex_digits[ (num>>i*4) & 0x0000000F ];
}
put_str(put_int_buffer);
}
void set_cursor(unsigned short cursor_pos)
{
//先设置高8位
outb(0x03d4,0x0e);
outb(0x03d5,(cursor_pos>>8));
//先设置低8位
outb(0x03d4,0x0f);
outb(0x03d5,(cursor_pos&0b0000000011111111));
}
//参数:显存位置,写入的字符
void write_char(unsigned short video_memory_pos,char ch)
{
asm volatile ("movb %b1, %%gs:(%%bx);\
inc %%bx; \
movb $0x7,%%gs:(%%bx); \
"::"b"(video_memory_pos),"a"(ch));
}
void roll_screen()
{
unsigned short cursor_pos;
//一共有2000-80=1920个字符要搬运,共1920*2=3840字节.一次搬4字节,共3840/4=960次
int *src = (int*)0xb80a0; //第1行行首
int *dest = (int*)0xb8000; //第0行行首
int i;
for(i = 0; i<960;i++)
{
*dest = *src;
src++;
dest++;
}
for(i = 3840; i<4000;i+=2)
{
write_char(i,0x20); //最后一行填充空格
}
cursor_pos=1920; //将光标值重置为1920,最后一行的首字符.
set_cursor(cursor_pos);
}
print.h
#ifndef __LIB_KERNEL_PRINT_H
#define __LIB_KERNEL_PRINT_H
void put_char(unsigned char ch);
void put_str(char* str);
void put_int(unsigned int num); // 以16进制打印
#endif
提前使用了下一节的内联汇编知识
io.h
/************** 机器模式 ***************
b -- 输出寄存器QImode名称,即寄存器中的最低8位:[a-d]l。
w -- 输出寄存器HImode名称,即寄存器中2个字节的部分,如[a-d]x。
HImode
“Half-Integer”模式,表示一个两字节的整数。
QImode
“Quarter-Integer”模式,表示一个一字节的整数。
*******************************************/
#ifndef __LIB_IO_H
#define __LIB_IO_H
/* 向端口port写入一个字节*/
static inline void outb(unsigned short port,unsigned char data) {
/*********************************************************
a表示用寄存器al或ax或eax,对端口指定N表示0~255, d表示用dx存储端口号,
%b0表示对应al,%w1表示对应dx */
asm volatile ( "outb %b0, %w1" : : "a" (data), "d" (port));
/******************************************************/
}
/* 将addr处起始的word_cnt个字写入端口port */
static inline void outsw(unsigned short port, void* addr,unsigned int word_cnt) {
/*********************************************************
+表示此限制即做输入又做输出.
outsw是把ds:esi处的16位的内容写入port端口, 我们在设置段描述符时,
已经将ds,es,ss段的选择子都设置为相同的值了,此时不用担心数据错乱。*/
asm volatile ("cld; rep outsw" : "+S" (addr), "+c" (word_cnt) : "d" (port));
/******************************************************/
}
/* 将从端口port读入的一个字节返回 */
static inline char inb(unsigned short port) {
char data;
asm volatile ("inb %w1, %b0" : "=a" (data) : "d" (port));
return data;
}
/* 将从端口port读入的word_cnt个字写入addr */
static inline void insw(unsigned short port, void* addr, unsigned int word_cnt) {
/******************************************************
insw是将从端口port处读入的16位内容写入es:edi指向的内存,
我们在设置段描述符时, 已经将ds,es,ss段的选择子都设置为相同的值了,
此时不用担心数据错乱。*/
asm volatile ("cld; rep insw" : "+D" (addr), "+c" (word_cnt) : "d" (port) : "memory");
/******************************************************/
}
#endif
main.c
#include "print.h"
#include "io.h"
void main(void)
{
put_str("hello world");
put_char('\n');
put_int(0x12345678);
put_char('\n');
put_int(0x123);
while(1);
}
编译链接
nasm -I /home/abc/Desktop/bochs/code/boot/ /home/abc/Desktop/bochs/code/boot/mbr.s -o /home/abc/Desktop/bochs/code/boot/mbr.bin
dd if=/home/abc/Desktop/bochs/code/boot/mbr.bin of=/home/abc/Desktop/bochs/hd60m.img bs=512 count=1 conv=notrunc
nasm -I /home/abc/Desktop/bochs/code/boot/ /home/abc/Desktop/bochs/code/boot/loader.s -o /home/abc/Desktop/bochs/code/boot/loader.bin
dd if=/home/abc/Desktop/bochs/code/boot/loader.bin of=/home/abc/Desktop/bochs/hd60m.img bs=512 count=4 seek=2 conv=notrunc
nasm -f elf32 ./code/lib/print.s -o ./code/lib/print.o
gcc -I ./code/lib/ -m32 -c ./code/kernel/main.c -o ./code/kernel/main.o
gcc -I ./code/lib/ -m32 -c ./code/kernel/test.c -o ./code/kernel/test.o
ld -m elf_i386 ./code/kernel/main.o ./code/lib/print.o ./code/kernel/test.o -Ttext 0xc0001500 -e main -o ./code/kernel/kernel.bin
dd if=./code/kernel/kernel.bin of=/home/abc/Desktop/bochs/hd60m.img bs=512 count=200 seek=9 conv=notrunc
bin/bochs -f bochs.disk
效果

什么是内联汇编
- 内联汇编称为inline assembly,GCC支持在C代码中直接嵌入汇编代码,所以称为GCC inline assembly。C语言不支持寄存器操作,汇编语言可以,所以自然就想到了再C语言中嵌入内联汇编提升“战斗力”的方式,通过内联汇编,C 程序员可以实现 C 语言无法表达的功能,这样使开发能力大为提升。
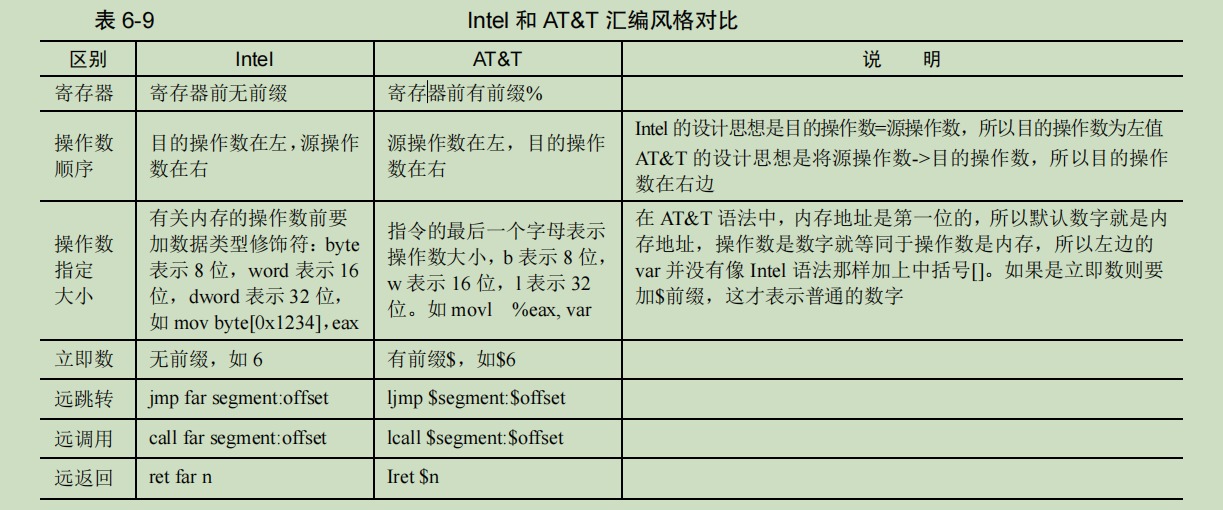
- 内联汇编按格式分为两大类,一类是最简单的基本内联汇编,另一类是复杂一些的扩展内联汇编,内联汇编中所用的汇编语言,其语法是 AT&T,并不是咱们熟悉的 Intel 汇编语法,GCC 只支持它,所以咱们还得了解下 AT&T。
基本内联汇编
基本内联汇编是最简单的内联形式,其格式为:
asm [volatile] ("assembly code")
-
asm:用于声明内联汇编表达式,这是内联汇编固定部分,不可少。asm和__asm__ 是一样的,是由gcc定义的宏:
#define __asm__ asm。 -
volatile:是可选项,它告诉gcc:“不要修改我写的汇编代码,请原样保留”。volatile 和__volatile__是一样的,是由gcc定义的宏:
#define __volatile__ volatile -
“assembly code” 是咱们所写的汇编代码,它必须位于圆括号中,而且必须用双引号括起来。规则如下:
- 指令必须用双引号引起来,无论双引号中是一条指令或多条指令
- 一对双引号不能跨行,如果跨行需要在结尾用反斜杠
\转义。 - 指令之间用分号
;换行符\n或换行符加制表符\n \t分隔。 - 当指令在多个双引号中时,除最后一个双引号外,其余双引号中的代码最后一定要有分隔符,如:
asm(“movl $9,%eax;””pushl %eax”) 正确 asm(“movl $9,%eax””pushl %eax”) 错误 - 寄存器前面加前缀%,立即数前面加前缀$,操作数由左到右的顺序。
扩展内联汇编
格式:
asm [volatile] (“assembly code”:output : input : clobber/modify)
-
output:用来指定汇编代码的数据如何输出给C代码使用。内嵌的汇编指令运行结束后,如果想将运行结果存储到C变量中,就用此项指定输出的位置。output中每个操作数的格式为:
“操作数修饰符约束名”(C 变量名),操作数修饰符通常为等号=。多个操作数之间用逗号,分隔。 -
input:用来指定C中数据如何输入给汇编使用。要向让汇编使用C中的变量作为参数,就要在此指定。input中每个操作数的格式为:
“[操作数修饰符] 约束名”(C 变量名),操作数修饰符为可选项。多个操作数之间用逗号,分隔。 -
clobber/modify:汇编代码执行后会破坏一些内存和寄存器资源,通过此项通知编译器,可能造成寄存器或内存数据破坏,这样gcc就知道哪些寄存器或内存需要提前保护前来。
- 格式:用双引号把寄存器名称引起来,多个寄存器之间用逗号
,分隔,寄存器不用再加两个%%,只要写名称即可,如:asm("movl %%eax, %0;movl %%eax,%%ebx":"=m" (ret_value)::"bx") - 如果我们的内联汇编代码修改了标志寄存器 eflags 中的标志位,同样需要在 clobber/modify 中用”cc”声明
- 如果我们修改了内存,我们需要在 clobber/modify 中”memory”声明。
- 如果我们在 output 中使用了内存约束,gcc 自然会得到哪块内存被修改。但如果被修改的内容并未在output 中,我们就需要用”memory”告诉 gcc 啦。
- 格式:用双引号把寄存器名称引起来,多个寄存器之间用逗号
- 约束的作用:约束的作用是让C代码的操作数变成汇编代码能使用的操作数,所有的约束形式其实都是给汇编用的。约束是C语言中的操作数与汇编语言中的操作数之间的映射,他告诉gcc,同一个操作数在两种环境下如何变换身份,如何对接沟通。编译过程中C代码是要先变成汇编代码的,内联汇编中的约束就相当于gcc让咱们指定C中数据的编译形式。
以下是各种约束的解释:
- 寄存器约束:寄存器约束就是要求gcc使用哪个寄存器,将input或output变量约束在某个寄存器中,常见的寄存器约束有:
a:表示寄存器 eax/ax/al
b:表示寄存器 ebx/bx/bl
c:表示寄存器 ecx/cx/cl
d:表示寄存器 edx/dx/dl
D:表示寄存器 edi/di
S:表示寄存器 esi/si
q:表示任意这 4 个通用寄存器之一:eax/ebx/ecx/edx
r:表示任意这 6 个通用寄存器之一:eax/ebx/ecx/edx/esi/edi
g:表示可以存放到任意地点(寄存器和内存)。相当于除了同 q 一样外,还可以让 gcc 安排在内存中
A:把 eax 和 edx 组合成 64 位整数
f:表示浮点寄存器
t:表示第 1 个浮点寄存器
u:表示第 2 个浮点寄存器
#include<stdio.h>
void main()
{
int in_a = 1, in_b = 2, out_sum;
asm("addl %%ebx, %%eax":"=a"(out_sum):"a"(in_a),"b"(in_b));
printf("sum is %d\n",out_sum);
}
-
内存约束:内存约束是要求gcc直接将位于input和output中的C变量内存地址作为内联汇编代码的操作数,不需要寄存器做中转,直接进行内存读写,也就是汇编代码的操作数是C变量的指针。
m:表示操作数可以使用任意一种内存形式
o:操作数为内存变量,但访问它是通过偏移量的形式访问,即包括offset_address的格式。 -
立即数约束:立即数即常数,此约束要求gcc在传值的时候不通过内存和寄存器,直接作为立即数传给汇编代码。由于立即数不是变量,只能作为右值,所以只能放在input中。
i:表示操作数为整数立即数
F:表示操作数为浮点数立即数
I:表示操作数为 0~31 之间的立即数
J:表示操作数为 0~63 之间的立即数
N:表示操作数为 0~255 之间的立即数
O:表示操作数为 0~32 之间的立即数
X:表示操作数为任何类型立即数 -
通用约束:
0~9:此约束只用在 input 部分,但表示可与 output 和 input 中第 n 个操作数用相同的寄存器或内存。
序号占位符
-
占位符:为了方便对操作数的引用,扩展内联汇编提供了占位符,他的作用是代表约束指定的操作数(寄存器、内存、立即数),我们更多的是在内联汇编中使用占位符来引用操作数。占位符分为序号占位符和名称占位符:
-
序号占位符:序号占位符是对在output和input中的操作数,按照它们从左到右的次序从0开始编号,一直到9,也就是说最多支持10个序号占位符,引用它的格式是%0~9。占位符所表示的操作数默认情况下为 32 位数据,在%和序号之间插入字符’h’来表示操作数为ah(第 8~15 位),或者插入字符’b’来表示操作数为 al(第 0~7 位)。
h –输出寄存器高位部分中的那一字节对应的寄存器名称,如 ah、bh、ch、dh。
b –输出寄存器中低部分 1 字节对应的名称,如 al、bl、cl、dl。
w –输出寄存器中大小为 2 个字节对应的部分,如 ax、bx、cx、dx。
k –输出寄存器的四字节部分,如 eax、ebx、ecx、edx。
如:
asm("addl %%ebx, %%eax":"=a"(out_sum):"a"(in_a),"b"(in_b));
等价于
asm("addl %2, %1":"=a"(out_sum):"a"(in_a),"b"(in_b));
其中:
“=a”(out_sum)序号为 0,%0 对应的是 eax。
“a”(in_a)序号为 1,%1 对应的是 eax。
“b”(in_b)序号为 2,%2 对应的是 ebx。 -
名称占位符:名称占位符与序号占位符不同,序号占位符靠本身出现在output和input中的位置就能被编译器识别出来。而名称占位符需要在output和input中把操作数显式地起个名字,它用这样的格式来标识操作数:
[名称]”约束名”(C 变量)。这样,该约束对应的汇编操作数便有了名字,在 assembly code 中引用操作数时,采用%[名称]的形式就可以了。
-
-
由于扩展内联汇编中的占位符要有前缀%,为了区别占位符和寄存器,只好在寄存器前用两个%做前缀啦,这就是本节前面解释在扩展内联汇编中寄存器前面要有两个%做前缀的原因。
-
在约束中还有操作数类型修饰符,用来修饰所约束的操作数:内存、寄存器,分别在ouput 和 input中有以下几种。
在output中:
=:表示操作数是只写,相当于为 output 括号中的 C 变量赋值,如=a(c_var),此修饰符相当于 c_var=eax。
+:表示操作数是可读写的,告诉 gcc 所约束的寄存器或内存先被读入,再被写入。
&:表示此 output 中的操作数要独占所约束(分配)的寄存器,只供 output 使用,任何 input 中所分配的寄存器不能与此相同。注意,当表达式中有多个修饰符时,&要与约束名挨着,不能分隔。
在input中:
%:input 中的输入可以和下一个 input 操作数互换 -
一般情况下,input 中的 C 变量是只读的,output 中的 C 变量是只写的。
-
修饰符’='只用在 output 中,表示 C 变量是只写的,功能相当于 output 中的 C 变量=约束的汇编操作数,如”=a”(c_var),相当于 c_var=eax 的值。
-
修饰符’+'也只用在 output 中,但它具备读、写的属性,也就是它既可作为输入,同时也可以作为输出,所以省去了在 input 中声明约束。
#include <stdio.h>
void main()
{
int in_a = 1, in_b = 2;
asm("addl %%ebx, %%eax;":"+a"(in_a):"b"(in_b));
printf("in_a is %d\n", in_a);
}
扩展内联汇编之机器模式简介
- 机器模式用来在机器层面上指定数据的大小及格式。
- 由于各种约束均不能确切地表达具体的操作数对象,所以引用了机器模式,用来从更细的粒度上描述数据对象的大小及其指定部分
寄存器按是否可单独使用,可分成几个部分,拿 eax 举例:
- 低部分的一字节:al
- 高部分的一字节:ah
- 两字节部分:ax
- 四字节部分:eax
h :输出寄存器高位部分中的那一字节对应的寄存器名称,如 ah、bh、ch、dh。
b :输出寄存器中低部分 1 字节对应的名称,如 al、bl、cl、dl。
w :输出寄存器中大小为 2 个字节对应的部分,如 ax、bx、cx、dx。
k :输出寄存器的四字节部分,如 eax、ebx、ecx、edx。
举例:
1 #include<stdio.h>
2 void main()
3 {
4 int in_a = 0x1234, in_b = 0;
5 asm("movw %1, %0":"=m"(in_b):"a"(in_a));
6 printf("in_b now is 0x%x\n", in_b);
}
这段代码目的是把in_a的低16位复制到in_b中,第五行中,变量in_a的约束是a,这表示由gcc把in_a的值分配给寄存器al、ax或eax,这很模糊,到底gcc把in_a的值分配给谁了呢?之后的movw指令也很模糊,我们只能这样理解:movw指令将al、ax或eax中的2个字节复制到in_b所在的内存中
修改后:
1 #include<stdio.h>
2 void main()
3 {
4 int in_a = 0x1234, in_b = 0;
5 asm("movw %w1, %0":"=m"(in_b):"a"(in_a));
6 printf("in_b now is 0x%x\n", in_b);
}
添加w前缀就可以确定源操作数为ax