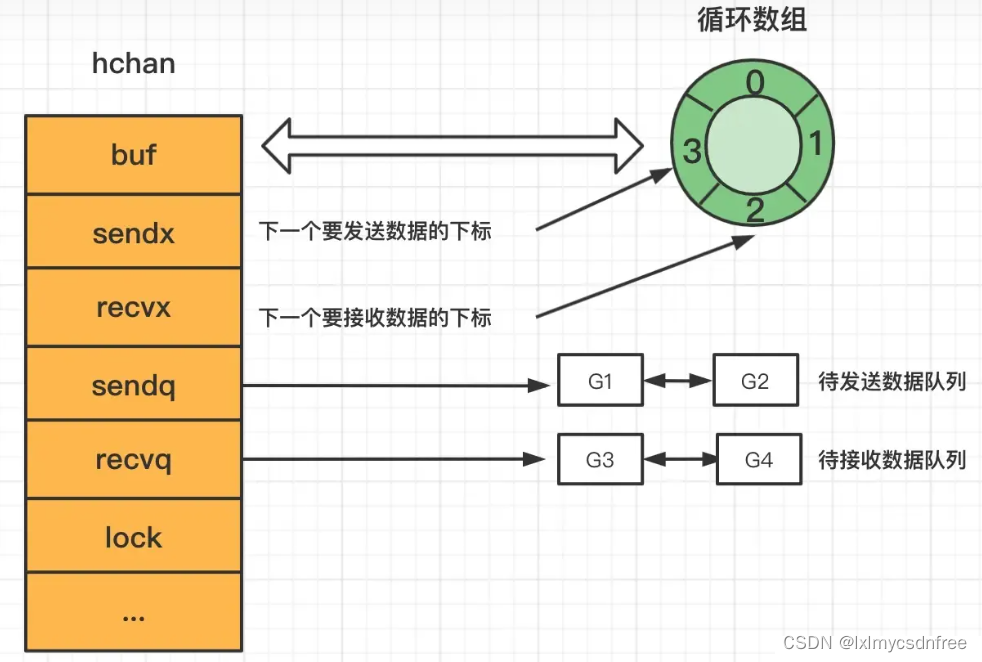







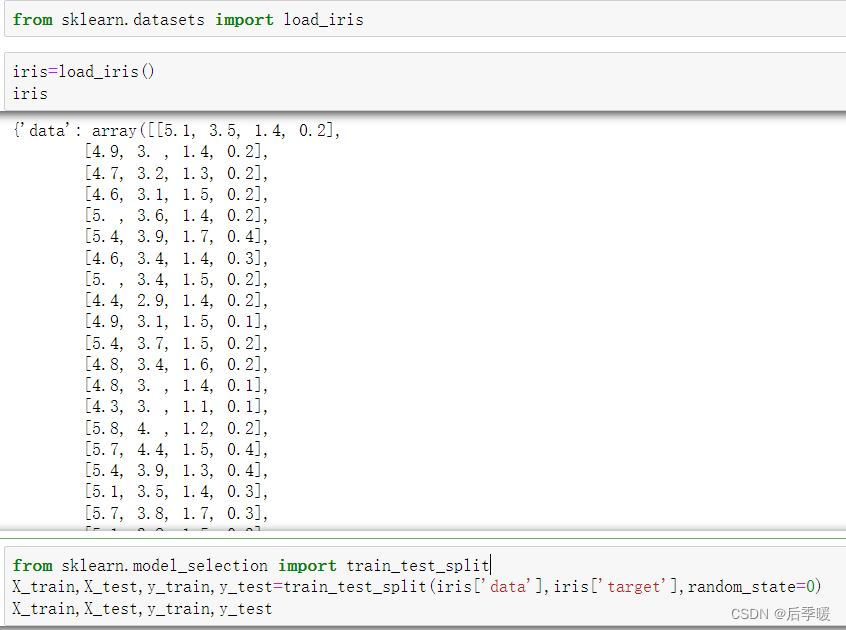
字典特征提取


第一列表示北京 第二列表示上海 第三列表示深圳 第四列表示温度
前面三列 是的话用1 不是的话用0
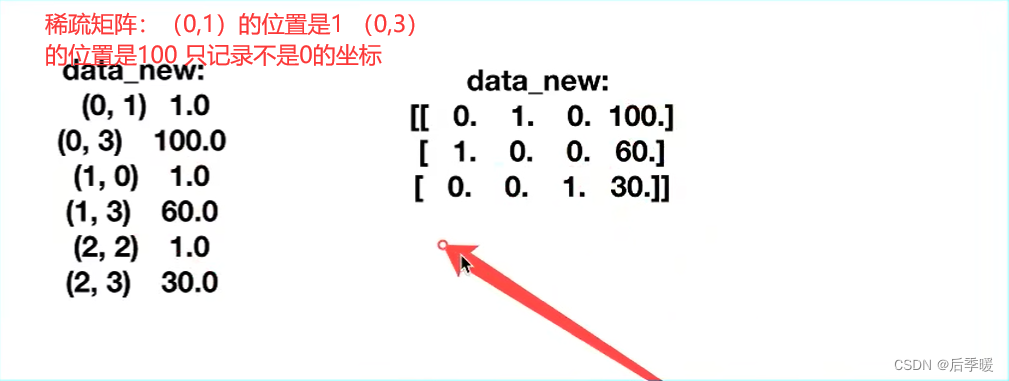
什么时候用稀疏矩阵:比如上面这种情况当你的城市很多的情况下 那这样就会出现大量的0 而系数矩阵只存储不是0的位置 可以节省大量空间
为什么采用这种表示方法呢?
首先我们来看 假如要分类:人是1 企鹅是2 章鱼是3

那么这样数字表示的就存在优先级 不如按这种办法来

pclass是一等舱二等舱三等舱这种
字典特征抽取的应用场景:

文本特征提取:自动抽取非字母的单词



对中文分词 它会把连在一起的词也就是短句当做特征 不符合我们想要的效果 于是我们可以用空格把句子分割 但是还是麻烦 于是:
首先先import jieba:![]()
.join是分割 join的参数是一个整体

输出


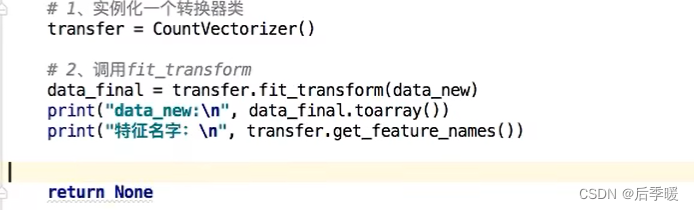
输出:

KMeans:


KMeans步骤:

这边的与原中心点一样代表着与上次的中心点还是一样 说明已经趋于极限值了 再改中心点意义已经不大了 已经是局部最优


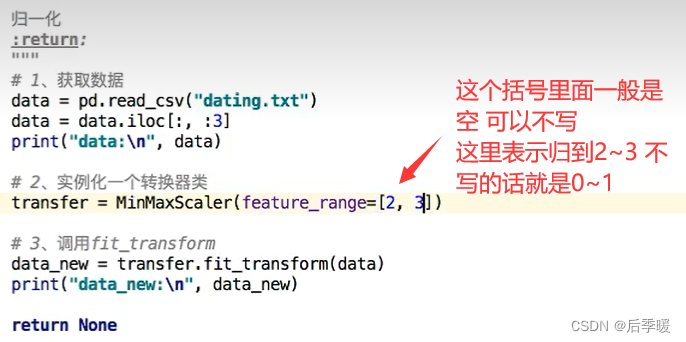
归一化:
![]()
前面导入的是线性归一化 后面导入的是标准差归一化

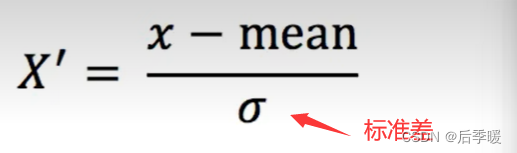


图就省略了
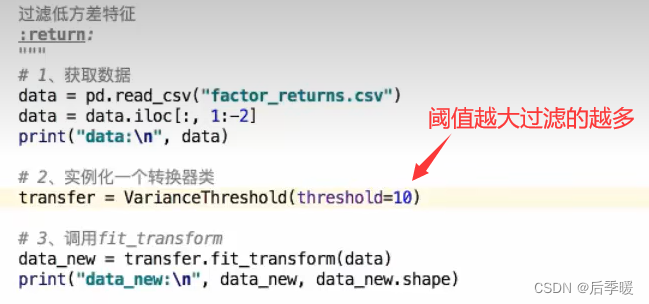
降维:
这里的降维可以理解为降低特征的个数 使得相关性较强的特征减少

![]()


![[kerberos] kerberos 认证详解](https://img-blog.csdnimg.cn/095d22a62987493ea28bbf69f87b3d88.png)



![[DT框架使用教程01]如何在DT框架中创建插件](https://img-blog.csdnimg.cn/img_convert/63c663510ab76ce2d33768885e686f5d.png)