1. Linux简介
1.1 什么是Linux

Linux,全称GNU/Linux,是一种免费使用和自由传播的类UNIX操作系统,其内核由Linus Torvalds于1991年10月5日首次发布,它主要受到Minix和Unix思想的启发,是一个基于POSIX的多用户、多任务、支持多线程和多CPU的操作系统
Linux 一般是指 Linux 内核、 Linux 系统、 Linux 发行版。严格意义上说 Linux 是指由 Linus Torvalds 维护的并发布的内核。它的代码只包括内核而不包括其它方面的应用。内核提供系统核心服务,如进程管理,进程的调度,虚拟文件系统,内存的管理等等。
1.2 Linux特点
-
免费开源
Linux是一款完全免费的操作系统,任何人都可以从网络上下载到它的源代码,并可以根据自己的需求进行定制化的开发,而且没有版权限制。
-
模块化程度高
Linux的内核设计分成进程管理、内存管理、进程间通信、虚拟文件系统、网络5部分,其采用的模块机制使得用户可以根据实际需要,在内核中插入或移走模块,这使得内核可以被高度的剪裁定制,以方便在不同的场景下使用。
-
广泛的硬件支持
得益于其免费开源的特点,有大批程序员不断地向Linux社区提供代码,使得Linux有着异常丰富的设备驱动资源,对主流硬件的支持极好,而且几乎能运行在所有流行的处理器上。
-
安全稳定
Linux采取了很多安全技术措施,包括读写权限控制、带保护的子系统、审计跟踪、核心授权等,这为网络环境中的用户提供了安全保障。实际上有很多运行Linux的服务器可以持续运行长达数年而无须重启,依然可以性能良好地提供服务,其安全稳定性已经在各个领域得到了广泛的证实。
-
多用户,多任务
多用户是指系统资源可以同时被不同的用户使用,每个用户对自己的资源有特定的权限,互不影响。多任务是现代化计算机的主要特点,指的是计算机能同时运行多个程序,且程序之间彼此独立,Linux内核负责调度每个进程,使之平等地访问处理器。由于CPU处理速度极快,从用户的角度来看所有的进程好像在并行运行。
-
良好的可移植性
Linux中95%以上的代码都是用C语言编写的,由于C语言是一种机器无关的高级语言,是可移植的,因此Linux系统也是可移植的。
1.3 Linux版本
内核版本
- 内核版本:免费的,它只是操作系统的核心,负责控制硬件、管理文件系统、程序进程等,并不给用户提供各种工具和应用软件;
网址:https://www.kernel.org/
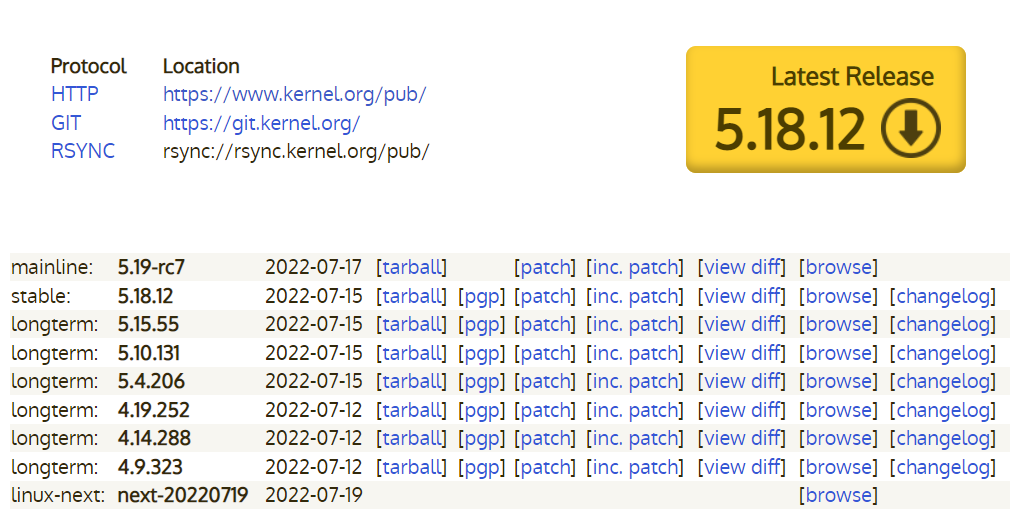
Linux内核版本号由3组数字组成:第一个组数字.第二组数字.第三组数字
- 第一个组数字:目前发布的内核主版本。
- 第二个组数字:偶数表示稳定版本;奇数表示开发中版本。
- 第三个组数字:错误修补的次数。
用命令uname -a查看内核版本号
[root@localhost ~]# uname -a
Linux bogon 3.10.0-1160.el7.x86_64 #1 SMP Mon Oct 19 16:18:59 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
- 第一个组数字:3, 主版本号
- 第二个组数字:10, 次版本号,当前为稳定版本
- 第三个组数字:0, 修订版本号
- 第四个组数字:0-1160,表示发行版本的补丁版本
- el7:则表示我正在使用的内核是 RedHat / CentOS 系列发行版专用内核
- x86_64:采用的是64位的CPU
发行版本
- 发行版本:以Linux内核为中心,再集成搭配各种各样的系统管理软件或应用工具软件组成一套完整的操作系统,如此的组合便称为Linux发行版。
Linux的发行版本可以大体分为两类:
- 一类是商业公司维护的发行版本:以著名的Redhat(REHL)为代表;
- 一类是社区组织维护的发行版本:以Debian为代表;
1) Red Hat Linux

Red Hat(红帽公司)创建于 1993 年,是目前世界上资深的 Linux 厂商,也是最获认可的 Linux 品牌。
Red Hat 公司的产品主要包括 RHEL(Red Hat Enterprise Linux,收费版本)和 CentOS(RHEL 的社区克隆版本,免费版本)、Fedora Core(由 Red Hat 桌面版发展而来,免费版本)。
CentOS:是基于 Red Hat Enterprise Linux 源代码重新编译、去除 Red Hat 商标的产物,各种操作使用和付费版本没有区别,且完全免费。缺点是不向用户提供技术支持,也不负任何商业责任。有实力的公司可以选择付费版本。
2) Ubuntu Linux

Ubuntu 基于知名的 Debian Linux 发展而来,界面友好,容易上手,对硬件的支持非常全面,是目前最适合做桌面系统的 Linux 发行版本,而且 Ubuntu 的所有发行版本都免费提供。
1.4 系统安装
发行版中不管是RedHat、CentOS还是Ubuntu,其内核都是来自Linux内核官网(www.kernel.org),不同发行版之间的差别在于软件管理的不同,所以不管使用哪一个发行版,只要理解其原理之后,各类发行版的区别其实不大。
这个理主要使用版本为7.9的CentOS
[root@localhost ~]# cat /etc/redhat-release
CentOS Linux release 7.9.2009 (Core)
1.4.1 下载IOS文件
下载地址:https://wiki.centos.org/Download
-
官网下载地址
CentOS Mirrors List
-
清华大学下载地址
Index of /centos/7.9.2009/isos/x86_64/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
-
阿里下载地址
centos-7-isos-x86_64安装包下载_开源镜像站-阿里云
以阿里下载举例说明
step1: 进入阿里云站点,选择 CentOS-7-x86_64-DVD-1804.iso下载
各个版本的ISO镜像文件说明:
CentOS-7-x86_64-DVD-1708.iso 标准安装版(推荐)
CentOS-7-x86_64-Everything-1708.iso 完整版,集成所有软件(以用来补充系统的软件或者填充本地镜像)
CentOS-7-x86_64-LiveGNOME-1708.iso GNOME桌面版
CentOS-7-x86_64-LiveKDE-1708.iso KDE桌面版
CentOS-7-x86_64-Minimal-1708.iso 精简版,自带的软件最少
CentOS-7-x86_64-NetInstall-1708.iso 网络安装版(从网络安装或者救援系统
1.4.2 创建虚拟机
1.4.3 典型类型的配置
1.4.4 安装客户端操作系统
1.4.5 命名虚拟机
根据自己喜欢命名
1.4.6 指定磁盘容量
一般20就差不多, 根据自己需求
1.4.7 开启此虚拟机
1.4.8 选择语言
1.4.9 等待安装完毕
设置root密码为:root,等待安装完毕
1.5 帮助命令(man、help、info)
Linux系统中的命令是非常多的,约2600个命令。我们不可能记住每个命令的使用方法,以及各个参数的功能。但好在Linux给我们提供了帮助手册,供我们查看命令的详细使用说明。
内部命令:
内部命令指的是集成在Shell里面的命令,属于Shell的一部分。只要Shell被执行,内部命令就自动载入内存,用户可以直接使用,比如cd命令等。
外部命令:
考虑到运行效率等原因,不可能把所有的命令都集成在Shell里面,更多的Linux命令是独立于Shell之外的,这些就叫做外部命令,比如cp、ls等命令。每个外部命令都对应系统中的一个可执行的二进制程序文件。
1.5.1 使用 help
help只能获取Shell内置命令的帮助
-
命令名称: help
-
英文原意: help
-
所在路径:
Shell内置命令 -
执行权限:所有用户
-
功能描述:显示Shell内置命令的帮助。可以使用type命令来区分内置命令与外部命令
shell是Linux的命令解释器
help <command> 只能用于内部命令,不能用于外部命令。
例如:help cd;<command> --help 用于外部命令。例如:ls --help。
使用type来查询命令属于外部的还是内部的
[root@localhost ~]# type cd
cd is a shell builtin # 得到这样的结果说明是内建命令,正如上文所说内建命令都是在 bash 源码中的 builtins 的.def中
[root@localhost ~]# type vim
vim is /usr/bin/vim # 得到这样的结果说明是外部命令,正如上文所说,外部命令在/usr/bin or /usr/sbin等等中
[root@localhost ~]# type ls
ls is aliased to `ls --color=auto'
[root@localhost ~]# # 若是得到alias的结果,说明该指令为命令别名所设定的名称
1.5.2 使用 man
man得到的内容比用help更多更详细,而且man没有内建与外部命令的区分,因为man工具是显示系统手册页中的内容,也就是一本电子版的字典,这些内容大多数都是对命令的解释信息,还有一些相关的描述。
[root@localhost ~]#man [选项] 命令
选项:
-f 查看命合拥有哪个级别的帮助
-k 查看和命合相关的所有帮助

使用上面这个命令时会发现最左上角显示“ LS (1)”,在这里,“ LS ”表示手册名称,而“(1)”表示该手册位于第一章节。
在man手册中一共有以下几个章节:
1 普通用户可以执行的系统命令和可执行文件的帮助
2 内核可以调用的函数和工具的帮助
3 C语言函数的帮助
4 设备和特殊文件的帮助
5 配置文件的帮助
6 游戏的帮助(个人版的Linux中是有游戏的)
7 杂项的帮助
8 超级用户可以执行的系统命令的帮助
9 内核的帮助
1 Standard commands (标准命令)
2 System calls (系统调用)
3 Library functions (库函数)
4 Special devices (设备说明)
5 File formats (文件格式)
6 Games and toys (游戏和娱乐)
7 Miscellaneous (杂项)
8 Administrative Commands (管理员命令)
9 其他(Linux特定的), 用来存放内核例行程序的文档。
1.5.3 使用 Info
得到的信息比 man 还要多,info 来自自由软件基金会的 GNU 项目,是 GNU 的超文本帮助系统,能够更完整的显示出 GNU 信息。所以得到的信息当然更多
man 和 info 就像两个集合,它们有一个交集部分,但与 man 相比,info 工具可显示更完整的 GNU 工具信息。若 man 页包含的某个工具的概要信息在 info 中也有介绍,那么 man 页中会有“请参考 info 页更详细内容”的字样。
2. Linux文件管理
2.1 文件目录的层级结构
为了方便管理文件和目录,Linux 系统将它们组织成一个以根目录 / 开始的倒置的树状结构。Linux 中的目录,和 Windows 系统中的文件夹类似,不同之处在于,Linux 系统中的目录也被当做文件看待。
在 Linux 操作系统中,所有的文件和目录都被组织成以一个根节点“/”开始的倒置的树状结构,如图所示:
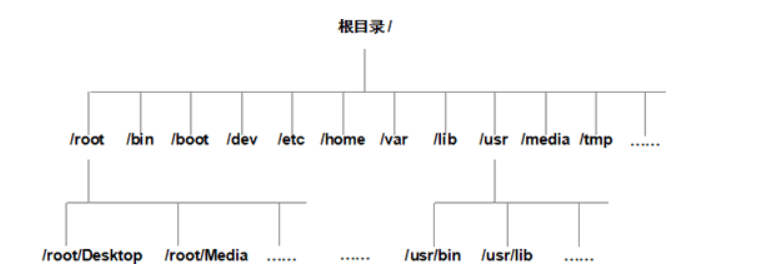
其中,目录就相当于 Windows 中的文件夹,目录中存放的既可以是文件,也可以是其他的子目录,而文件中存储的是真正的信息
为了方便管理和维护,Linux 系统采用了文件系统层次标准,也称为 FHS 标准,它规定了根目录下各个目录应该存在哪些类型的文件(或子目录)
[root@linux30 ~]# cd /
[root@linux30 /]# ls -l
总用量 24
lrwxrwxrwx. 1 root root 7 9月 6 15:40 bin -> usr/bin ## 常见的用户命令
dr-xr-xr-x. 5 root root 4096 11月 9 13:33 boot ## 内核和启动文件
drwxr-xr-x. 20 root root 3240 12月 20 16:15 dev ## 设备文件
drwxr-xr-x. 88 root root 8192 12月 20 16:15 etc ## 系统和服务的配置文件
drwxr-xr-x. 7 root root 77 12月 20 09:43 home ## 系统默认的普通用户的家目录
lrwxrwxrwx. 1 root root 7 9月 6 15:40 lib -> usr/lib ## 系统函数库目录
drwxr-xr-x. 2 root root 6 4月 11 2018 media ## 系统用来挂载光驱等临时文件系统的挂载点
drwxr-xr-x. 3 root root 18 11月 9 09:29 mnt ## 系统加载文件系统时常用的挂载点
drwxr-xr-x. 11 root root 162 11月 15 10:19 opt ## 第三方软件安装目录
dr-xr-xr-x. 138 root root 0 12月 20 16:14 proc ## 虚拟文件系统
dr-xr-x---. 13 root root 4096 12月 16 22:57 root ## root用户的家目录
lrwxrwxrwx. 1 root root 8 9月 6 15:40 sbin -> usr/sbin ## 存放系统管理命令
drwxrwxrwt. 16 root root 4096 12月 20 16:15 tmp ## 临时文件的存放目录
drwxr-xr-x. 13 root root 155 9月 6 15:40 usr ## 存放和用户直接相关的文件和目录
[root@linux30 /]#
2.2 绝对路径及相对路径
1)绝对路径
Linux系统采用了目录树的文件组织结构,在Linux下每个目录或文件都可以从根目录处开始寻找,比如:/usr/local/src目录。这种从根目录开始的全路径被称为“绝对路径”,绝对路径一定是以“/”开头的。
2)当前目录:pwd
[root@linux30 ~]# pwd
/root
[root@linux30 ~]#
3)特殊目录:(.)和(…)
在每个目录下,都会固定存在两个特殊目录,分别是一个点(.)和两个点(…)的目录。一个点(.)代表的是当前目录,两个点(…)代表的是当前目录的上层目录。在Linux下,所有以点开始的文件都是“隐藏文件”,对于这类文件,只使用命令ls -l是看不到的,必须要使用ls -la才可以看到
[root@linux30 ~]# ls -l
总用量 4
-rw-------. 1 root root 1440 9月 6 15:43 anaconda-ks.cfg
drwxr-xr-x. 5 root root 53 10月 21 17:49 logs
drwxr-xr-x. 4 root root 34 10月 25 15:47 nacos
[root@linux30 ~]# ls -la
总用量 76
dr-xr-x---. 13 root root 4096 12月 16 22:57 .
dr-xr-xr-x. 18 root root 236 9月 29 15:34 ..
-rw-------. 1 root root 1440 9月 6 15:43 anaconda-ks.cfg
drwxr-xr-x. 3 root root 32 10月 21 17:49 .arthas
-rw-------. 1 root root 17993 12月 20 16:14 .bash_history
...
[root@linux30 ~]#
4)相对路径
顾名思义,“相对路径”的关键在于当前在什么路径下
[root@linux30 ~]# cd /mnt/ ##现在进入/mnt目录
[root@linux30 mnt]# ls -la
总用量 0
drwxr-xr-x. 3 root root 18 11月 9 09:29 . ## 代表当前目录
dr-xr-xr-x. 18 root root 236 9月 29 15:34 .. ## 代表上层目录
drwxr-xr-x. 2 root root 6 11月 9 09:29 hgfs
[root@linux30 mnt]# cd . ## 进入当前目录
[root@linux30 mnt]# pwd ## 显示当前目录
/mnt
[root@linux30 mnt]# cd .. ## 进入当前目录的上层目录
[root@linux30 /]# pwd
/
[root@linux30 /]# ## 进入了上层目录,也就是/目录中
2.3 文件的相关操作
创建、删除、移动、重命名、查看文件,以及不同系统之间进行格式转换。
1)创建文件:touch
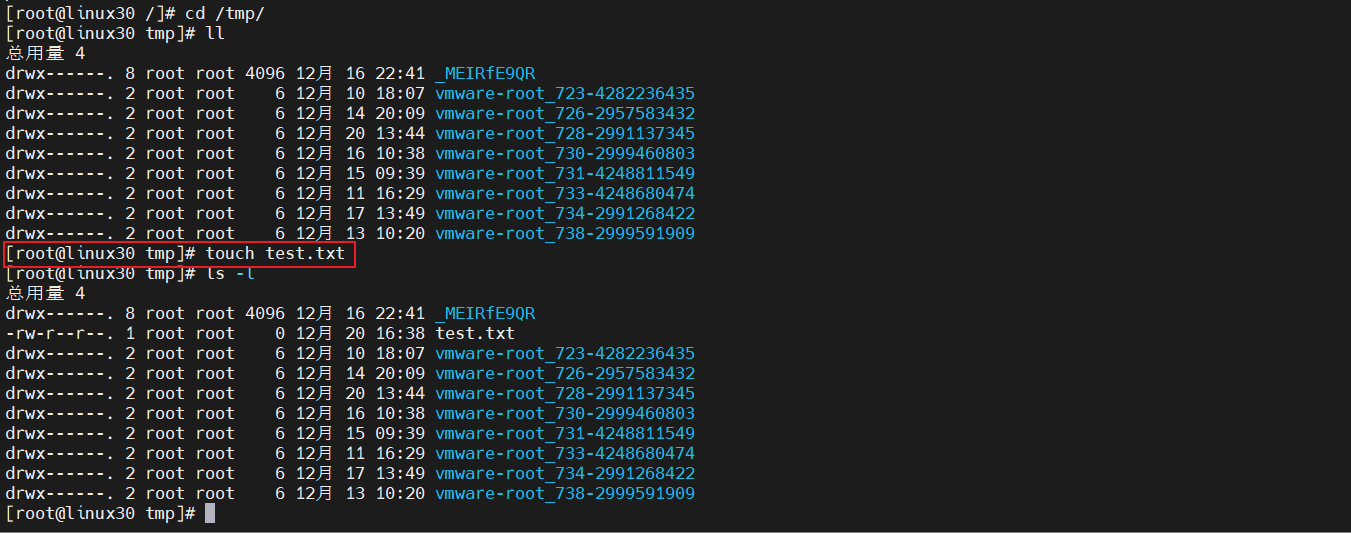
如果在使用touch命令创建文件的时候,当前目录中已经存在了这个文件,那么这个命令不会对当前的同名文件造成影响,因为它并不会修改文件的内容,虽然实际上touch确实对该文件做了“修改”—它会更新文件的创建时间属性。
2)删除文件:rm
[root@linux30 tmp]# rm test.txt
rm:是否删除普通空文件 "test.txt"?y
[root@linux30 tmp]#
3)移动或重命名文件:mv
[root@linux30 tmp]# mkdir src dest ## 创建src和dest目录
[root@linux30 tmp]# ll
总用量 4
drwxr-xr-x. 2 root root 6 12月 20 16:46 dest
drwxr-xr-x. 2 root root 6 12月 20 16:46 src
[root@linux30 tmp]# cd src/ ## 进入src目录
[root@linux30 src]# ll
总用量 0
[root@linux30 src]# touch test.txt ## 创建test.txt文件
[root@linux30 src]# ll
总用量 0
-rw-r--r--. 1 root root 0 12月 20 16:46 test.txt
[root@linux30 src]# mv test.txt ../dest/ ## 移动test.txt文件到dest目录
[root@linux30 src]# ll
总用量 0
[root@linux30 src]# cd ../dest/ ## 进入dest目录
[root@linux30 dest]# ll
总用量 0
-rw-r--r--. 1 root root 0 12月 20 16:46 test.txt
[root@linux30 dest]# mv test.txt test2.txt ## 重命名test.txt -> test2.txt
[root@linux30 dest]# ll
总用量 0
-rw-r--r--. 1 root root 0 12月 20 16:46 test2.txt
[root@linux30 dest]#
4)查看文件:cat
使用 -n 参数可以显示每行的行号
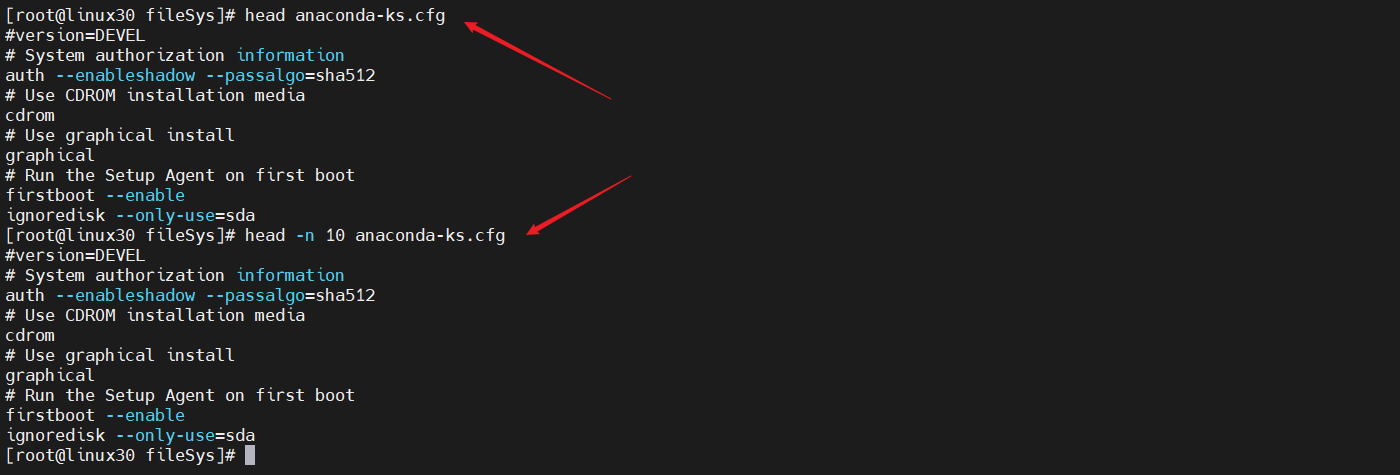
5)查看文件头:head
有时候文件非常大,使用cat命令显示出来的内容太多,而我们可能并不想查看所有内容,只是想看看文件开始部分的内容,这时候就可以使用head命令了,后面跟上需要查看的文件名就可以了。默认情况下,head将显示该文件前10行的内容。
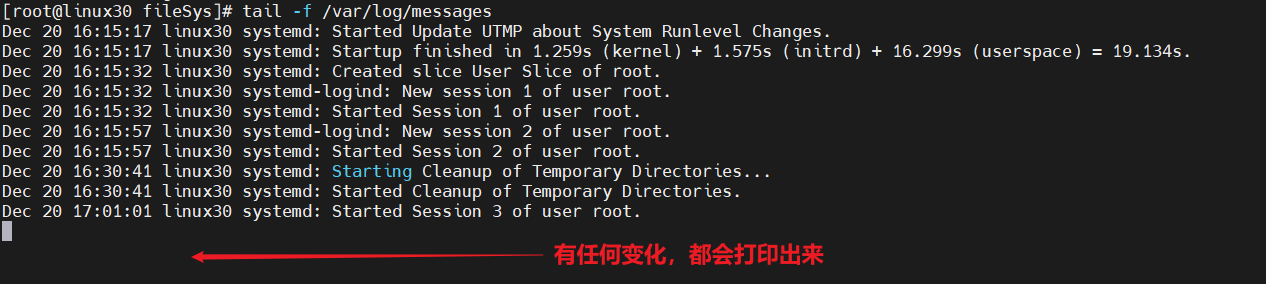
6)查看文件尾:tail
当文件很大时,可以使用该命令查看文件尾部的内容,默认情况下tail也是只显示文件的最后10行内容,同样可以使用-n参数指定显示的行数。
tail还有个更实用的功能,就是可以动态地查看文件尾。这对查看一些不断改变的文件来说非常有用。
查看末尾 tail -10 日志文件名称
动态查看日志 tail -f 日志文件名
2.4 目录相关操作
1)进入目录:cd
[root@linux30 fileSys]# cd ## 不带参数,进入到root目录
[root@linux30 ~]# pwd
/root
[root@linux30 ~]# cd linux-course/fileSys/ ## 进入/root/linux-course/fileSys目录
[root@linux30 fileSys]# pwd
/root/linux-course/fileSys
[root@linux30 fileSys]#
2)创建目录:mkdir
[root@localhost ~]# mkdir a
[root@localhost ~]# ll
total 4
drwxr-xr-x. 2 root root 6 Aug 3 08:30 a
-rw-------. 1 root root 1260 Aug 2 18:16 anaconda-ks.cfg
[root@localhost ~]# mkdir aa
[root@localhost ~]# ll
total 4
drwxr-xr-x. 2 root root 6 Aug 3 08:30 a
drwxr-xr-x. 2 root root 6 Aug 3 08:30 aa
-rw-------. 1 root root 1260 Aug 2 18:16 anaconda-ks.cfg
[root@localhost ~]# mkdir b bb
[root@localhost ~]# ll
total 4
drwxr-xr-x. 2 root root 6 Aug 3 08:30 a
drwxr-xr-x. 2 root root 6 Aug 3 08:30 aa
-rw-------. 1 root root 1260 Aug 2 18:16 anaconda-ks.cfg
drwxr-xr-x. 2 root root 6 Aug 3 08:30 b
drwxr-xr-x. 2 root root 6 Aug 3 08:30 bb
[root@localhost ~]#
批量创建目录
[root@localhost ~]# mkdir master{1..3}
[root@localhost ~]# ll
total 0
drwxr-xr-x. 2 root root 6 Aug 3 08:33 master1
drwxr-xr-x. 2 root root 6 Aug 3 08:33 master2
drwxr-xr-x. 2 root root 6 Aug 3 08:33 master3
[root@localhost ~]#
3)删除目录:rmdir和rm
该命令只能删除空目录,如果目录不为空(存在文件或者子目录),那么该命令将拒绝删除指定的目录。
可以使用rm -rf /dir1
[root@localhost ~]# rmdir aaa
rmdir: failed to remove ‘aaa’: Directory not empty
[root@localhost ~]# mkdir bbb
[root@localhost ~]# rmdir bbb
[root@localhost ~]# rm -rf aaa
4)文件和目录复制:cp
-i 覆盖已有文件前,提示用户确认,是否进行覆盖。
-r 递归复制目录,即复制目录下所有层级的子目录及文件。
-p 复制文件时,保持文件的所有者,权限信息,及时间属性。
-d 如果复制的源文件是符号链接,那么仅复制符号链接本身,而且保留符号链接所指向的目标文件或目录。
-a 等同于 -p,-d,-r三个参数选项的综合。
-t 默认情况下,命令格式为:cp 源文件 目标文件,当使用 -t 参数时,可以颠倒顺序。变为: cp -t 目标文件 源文件
[root@linux30 fileSys]# mkdir -p dir1/dir2/dir3/dir4
[root@linux30 fileSys]# cp anaconda-ks.cfg dir1/dir2/dir3/dir4 ## 文件的复制
[root@linux30 fileSys]# ll dir1/dir2/dir3/dir4
总用量 4
-rw-------. 1 root root 1440 12月 20 17:29 anaconda-ks.cfg
[root@linux30 fileSys]#
2.5 软/硬链接
ln 命令用于给文件创建链接,根据 Linux 系统存储文件的特点,链接的方式分为以下 2 种:
- 软链接:类似于 Windows 系统中给文件创建快捷方式,即产生一个特殊的文件,该文件用来指向另一个文件,此链接方式同样适用于目录。(
尽量使用绝对路径, 否则移动后无法找到文件) - 硬链接:文件的基本信息都存储在 inode 中,而硬链接指的就是给一个文件的 inode 分配多个文件名,通过任何一个文件名,都可以找到此文件的 inode,从而读取该文件的数据信息。(
别名)
ln 命令的基本格式如下:
[root@localhost ~]# ln [选项] 源文件 目标文件
选项:
- -s:建立软链接文件。如果不加 “-s” 选项,则建立硬链接文件;
- -f:强制。如果目标文件已经存在,则删除目标文件后再建立链接文件;
【例 1】创建硬链接:
[root@localhost ~]# touch cangls
[root@localhost ~]# ln /root/cangls /tmp
建立硬链接文件,目标文件没有写文件名,会和原名一致 #也就是/tmp/cangls 是硬链接文件
【例 2】创建软链接:
[root@localhost ~]# touch bols
[root@localhost ~]# In -s /root/bols /tmp
建立软链接文件
这里需要注意的是,软链接文件的源文件必须写成绝对路径,而不能写成相对路径(硬链接没有这样的要求);否则软链接文件会报错
硬链接
硬链接(hard link):可以将它理解为一个“指向原始文件inode的指针”,系统不为它分配独立的inode和文件。所以,硬链接文件与原始文件其实是同一个文件,只是名字不同。我们每添加一个硬链接,该文件的inode连接数就会增加1;而且只有当该文件的inode连接数为0时,才算彻底将它删除。换言之,由于硬链接实际上是指向原文件inode的指针,因此即便原始文件被删除,依然可以通过硬链接文件来访问。需要注意的是,由于技术的局限性,我们不能跨分区对目录文件进行链接。
- 不允许给目录创建硬链接;
- 只有在同一文件系统中的文件之间才能创建链接,即不同分区上的两个文件之间不能够建立硬链接。

源文件的关联数,在文件创建之初该值为1,该文件每增加一个硬链接该值将增1,当此数为0的时候该文件才能真正被文件系统删除。
软链接
软链接(也称为符号链接[symbolic link]):仅仅包含所链接文件的路径名,因此能链接目录文件,也可以跨越文件系统进行链接。但是,当原始文件被删除后,链接文件也将失效,从这一点上来说与Windows系统中的“快捷方式”具有一样的性质。

软链接的inode和源文件的inode不一样,这说明软链接本身就是一个文件。
删除软链接的源文件,然后可以在终端中看到对应的软链接将会以闪烁的方式标记其已是一个断链。
3.Vim文本编辑器
Linux 系统中“一切皆文件”,因此当在命令行下更改文件内容时,不可避免地要用到文本编辑器。
Vi 编辑器是 Unix 系统最初的编辑器。它使用控制台图形模式来模拟文本编辑窗口,允许查看文件中的行、在文件中移动、插入、编辑和替换文本。
在 GNU 项目中,在将 Vi 编辑器移植到开源世界的同时,决定对其作一些改进。由于改进后的 Vi 不再是以前 Unix 中的那个原始的 Vi 编辑器了,开发人员也就将它重命名为“Vi improved”,也就是 Vim。
因此可以这样说,Vim 是由 Vi 发展演变过程的文本编辑器,因其具有语法高亮显示、多视窗编辑、代码折叠、支持插件等功能,已成为众多 Linux 发行版本的标配
Vim的命令安装

主要是因为默认安装的是vi,vim命令并没有安装完全,输入rpm -qa|grep vim命令,发现CentOS上只装了vim的最小化安装
安装命令
yum -y install vim*
Vim三种工作模式
使用 Vim 编辑文件时,存在 3 种工作模式,分别是命令模式、输入模式和末行指令模式,这 3 种工作模式可随意切换,如图所示:
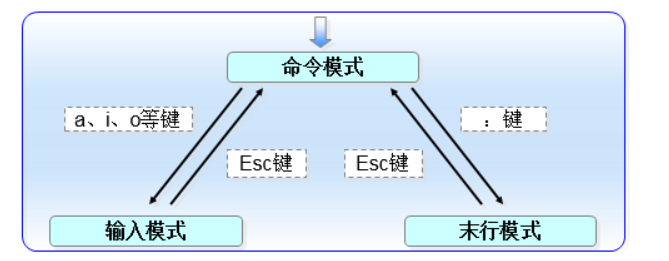
Vim的命令模式
使用 Vim 编辑文件时,默认处于命令模式。此模式下,可使用方向键(上、下、左、右键)或 k、j、h、i 移动光标的位置,还可以对文件内容进行复制、粘贴、替换、删除等操作。
Vim的输入模式
在输入模式下,Vim 可以对文件执行写操作,类似于在 Windows 系统的文档中输入内容。
使 Vim 进行输入模式的方式是在命令模式状态下输入 i、I、a、A、o、O 等插入命令(各指令的具体功能如表 所示),当编辑文件完成后按 Esc 键即可返回命令模式
Vim 的末行指令模式
编辑模式用于对文件中的指定内容执行保存、查找或替换等操作。
Vim基本操作
使用 Vim 进行编辑
同样,Vim 提供了大量的编辑快捷键,主要可分为以下几类。
Vim 插入文本
从命令模式进入输入模式进行编辑,可以按下 I、i、O、o、A、a 等键来完成,使用不同的键,光标所处的位置不同,如表所示。
| 快捷键 | 功能描述 |
|---|---|
| i | 在当前光标所在位置插入随后输入的文本,光标后的文本相应向右移动 |
| I | 在光标所在行的行首插入随后输入的文本,行首是该行的第一个非空白字符,相当于光标移动到行首执行 i 命令 |
| o | 在光标所在行的下面插入新的一行。光标停在空行首,等待输入文本 |
| O(大写) | 在光标所在行的上面插入新的一行。光标停在空行的行首,等待输入文本 |
| a | 在当前光标所在位置之后插入随后输入的文本 |
| A | 在光标所在行的行尾插入随后输入的文本,相当于光标移动到行尾再执行 a 命令 |
Vim 查找文本
| 快捷键 | 功能描述 |
|---|---|
| /abc | 从光标所在位置向前查找字符串 abc |
| /^abc | 查找以 abc 为行首的行 |
| /abc$ | 查找以 abc 为行尾的行 |
| ?abc | 从光标所在为主向后查找字符串 abc |
| n | 向同一方向重复上次的查找指令 |
| N | 向相反方向重复上次的查找指定 |
Vim 替换文本
| 快捷键 | 功能描述 |
|---|---|
| r | 替换光标所在位置的字符 |
| R | 从光标所在位置开始替换字符,其输入内容会覆盖掉后面等长的文本内容,按“Esc”可以结束 |
| : s/a1/a2/g | 将当前光标所在行中的所有 a1 用 a2 替换 |
| :n1,n2s/a1/a2/g | 将文件中 n1 到 n2 行中所有 a1 都用 a2 替换 |
| :g/a1/a2/g | 将文件中所有的 a1 都用 a2 替换 |
Vim删除文本
| 快捷键 | 功能描述 |
|---|---|
| x | 删除光标所在位置的字符 |
| dd | 删除光标所在行 |
| ndd | 删除当前行(包括此行)后 n 行文本 |
| dG | 删除光标所在行一直到文件末尾的所有内容 |
| D | 删除光标位置到行尾的内容 |
| :a1,a2d | 函数从 a1 行到 a2 行的文本内容 |
注意,被删除的内容并没有真正删除,都放在了剪贴板中。将光标移动到指定位置处,按下 “p” 键,就可以将刚才删除的内容又粘贴到此处
Vim复制和粘贴文本
| 快捷键 | 功能描述 |
|---|---|
| p | 将剪贴板中的内容粘贴到光标后 |
| P(大写) | 将剪贴板中的内容粘贴到光标前 |
| y | 复制已选中的文本到剪贴板 |
| yy | 将光标所在行复制到剪贴板,此命令前可以加数字 n,可复制多行 |
| yw | 将光标位置的单词复制到剪贴板 |
Vim 保存退出文本
Vim 的保存和退出是在编辑模式中进行的,其常用命令如下表所示。
| 命令 | 功能描述 |
|---|---|
| :wq | 保存并退出 Vim 编辑器 |
| :wq! | 保存并强制退出 Vim 编辑器 |
| :q | 不保存就退出 Vim 编辑器 |
| :q! | 不保存,且强制退出 Vim 编辑器 |
| :w | 保存但是不退出 Vim 编辑器 |
| :w! | 强制保存文本 |
| :w filename | 另存到 filename 文件 |
| x! | 保存文本,并退出 Vim 编辑器,更通用的一个 vim 命令 |
| ZZ | 直接退出 Vim 编辑器 |
需要注意的是,“w!” 和 “wq!” 等类似的指令,通常用于对文件没有写权限的时候,但如果你是文件的所有者或者 root 用户,就可以强制执行。
Vim 可视化模式及其用法
Vim可视化模式
在 Vim 中,如果想选中目标文本,就需要调整 Vim 进入可视化模式,如下所示,通过在 Vim 命令模式下键入不同的键,可以进入不同的可视化模式。

vim 命令模式下编辑文本的很多命令,在可视化模式下仍然可以使用

多文件编辑
不管是vi还是vim都可以同时打开并编辑多个文件,如同在Windows中使用Office同时打开多个文件一样。但是由于vim拥有多行编辑的功能,因此使用它在多个文件之间切换编辑的时候更加方便。
[root@linux30 charPro]# vim vim_file1 vim_file2
同时打开vim_file1和vim_file2后,默认会打开第一个文件,也就是vim_file1,输入一些内容后,我们把光标定位到第二行,并按V键,这时进入多行选中模式,选中第二行和第三行,并进行复制操作(按y键)。这时刚刚选中的两行被复制到了缓冲区中,输入:n并按回车键,会切换至vim_file2,这时按p键,刚刚复制的内容将会粘贴到当前文件vim_file2中。
要想从文件vim_file2的界面回到vim_file1,只需要输入:N并按回车键即可。要想查看当前一共打开了几个文件,可以输入:files查看
4. Linux 文本处理(grep、sed、awk)
连接合并文件内容(cat命令)
cat 命令可以用来显示文本文件的内容,也可以把几个文件内容附加到另一个文件中,即连接合并文件。
cat 命令的基本格式如下:
[root@localhost ~]# cat [选项] 文件名
或者
[root@localhost ~]# cat 文件1 文件2 > 文件3
注意,cat 命令用于查看文件内容时,不论文件内容有多少,都会一次性显示。如果文件非常大,那么文件开头的内容就看不到了。不过 Linux 可以使用PgUp+上箭头组合键向上翻页,但是这种翻页是有极限的,如果文件足够长,那么还是无法看全文件的内容。
【例 】将文件 file1.txt 和 file2.txt 的内容合并后输出到文件 file3.txt 中。
[root@localhost base]# ls
file1.txt file2.txt
[root@localhost base]# cat file1.txt
[root@localhost base]# cat file2.txt
[root@localhost base]# cat file1.txt file2.txt > file3.txt
[root@localhost base]# more file3.txt
[root@localhost base]# ls
file1.txt file2.txt file3.txt
分屏显示文件内容(more命令)
在看cat 命令时,有个疑问,即当使用 cat 命令查看文件内容时,如果文件过大,以至使用PgUp+上箭头组合键向上翻页也无法看全文件中的内容,该怎么办呢?这就需要使用 more 命令。
more 命令可以分页显示文本文件的内容,使用者可以逐页或者逐行阅读文件中内容,此命令的基本格式如下:
[root@localhost ~]# more [选项] 文件名
| 选项 | 含义 |
|---|---|
| -f | 计算行数时,以实际的行数,而不是自动换行过后的行数。 |
| -p | 不以卷动的方式显示每一页,而是先清除屏幕后再显示内容。 |
| -c | 跟 -p 选项相似,不同的是先显示内容再清除其他旧资料。 |
| -s | 当遇到有连续两行以上的空白行时,就替换为一行的空白行。 |
| -u | 不显示下引号(根据环境变量 TERM 指定的终端而有所不同)。 |
| +n | 从第 n 行开始显示文件内容,n 代表数字。 |
| -n | 一次显示的行数,n 代表数字。。 |
常用操作
- Enter 向下n行,可自定义。默认为1行
- Ctrl+F 向下滚动一屏
- 空格键 向下滚动一屏
- Ctrl+B 返回上一屏
- = 输出当前行的行号
- :f 输出文件名和当前行的行号
- V 调用vi编辑器
- ! 命令, 调用Shell,并执行命令
- q 退出more
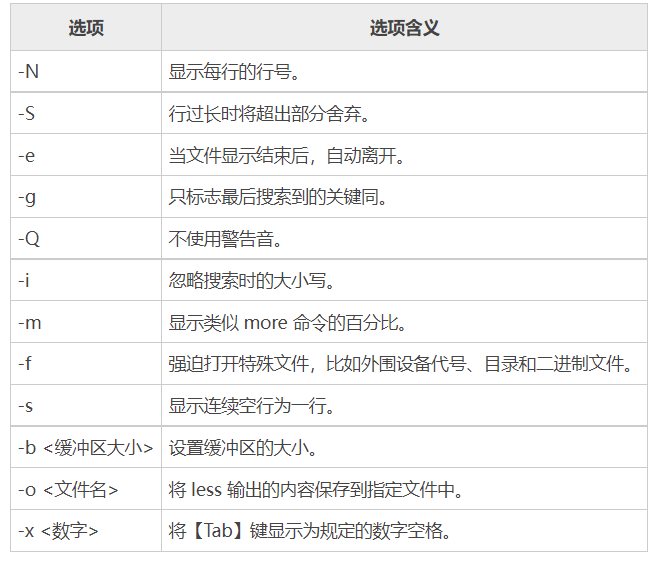
查看文件内容(less命令)
less 命令的作用和 more 十分类似,都用来浏览文本文件中的内容
less 命令的基本格式如下:
[root@localhost ~]# less [选项] 文件名
显示文件开头的内容(head命令)
head 命令可以显示指定文件前若干行的文件内容,其基本格式如下:
[root@localhost ~]# head [选项] 文件名
该命令常用选项以及各自的含义,如表 1 所示。
| 选项 | 含义 |
|---|---|
| -n K | 这里的 K 表示行数,该选项用来显示文件前 K 行的内容;如果使用 “-K” 作为参数,则表示除了文件最后 K 行外,显示剩余的全部内容。 |
| -c K | 这里的 K 表示字节数,该选项用来显示文件前 K 个字节的内容;如果使用 “-K”,则表示除了文件最后 K 字节的内容,显示剩余全部内容。 |
| -v | 显示文件名; |
注意,如不设置显示的具体行数,则默认显示 10 行的文本数据。
【例 1】基本用法。
[root@localhost ~]# head anaconda-ks.cfg
head 命令默认显示文件的开头 10 行内容。如果想显示指定的行数,则只需使用 “-n” 选项即可,例如:
[root@localhost ~]# head -n 20 anaconda-ks.cfg
这是显示文件的开头 20 行内容,也可以直接写 “-行数”,例如:
[root@localhost ~]# head -20 anaconda-ks.cfg
显示文件结尾的内容(tail命令)
tail 命令和 head 命令正好相反,它用来查看文件末尾的数据,其基本格式如下:
[root@localhost ~]# tail [选项] 文件名

管道
在Linux中存在着管道,它是一个固定大小的缓冲区,该缓冲区的大小为1页,即4K字节。管道是一种使用非常频繁的通信机制,我们可以用管道符“|”来连接进程,由管道连接起来的进程可以自动运行,如同有一个数据流一样,所以管道表现为输入输出重定向的一种方法,它可以把一个命令的输出内容当作下一个命令的输入内容,两个命令之间只需要使用管道符连接即可。
将两个或者多个命令(程序或者进程)连接到一起,把一个命令的输出作为下一个命令的输入,以这种方式连接的两个或者多个命令就形成了管道(pipe)。
Linux 管道使用竖线|连接多个命令,这被shadow称为管道符。Linux 管道的具体语法格式如下:
command1 | command2
command1 | command2 [ | commandN... ]
当在两个命令之间设置管道时,管道符|左边命令的输出就变成了右边命令的输入
为什么使用管道?
使用 mysqldump(一个数据库备份程序)来备份一个叫做 wiki 的数据库:
mysqldump -u root -p '123456' wiki > /tmp/wikidb.backup
gzip -9 /tmp/wikidb.backup
scp /tmp/wikidb.backup username@remote_ip:/backup/mysql/
上述这组命令主要做了如下任务:
- mysqldump 命令用于将名为 wike 的数据库备份到文件 /tmp/wikidb.backup;其中
-u和-p选项分别指出数据库的用户名和密码。 - gzip 命令用于压缩较大的数据库文件以节省磁盘空间;其中
-9表示最慢的压缩速度最好的压缩效果。 - scp 命令(secure copy,安全拷贝)用于将数据库备份文件复制到 IP 地址为 remote_ip 的备份服务器的 /backup/mysql/ 目录下。其中
username是登录远程服务器的用户名,命令执行后需要输入密码。
上述三个命令依次执行。然而,如果使用管道的话,你就可以将 mysqldump、gzip、ssh 命令相连接,这样就避免了创建临时文件 /tmp/wikidb.backup,而且可以同时执行这些命令并达到相同的效果。
使用管道后的命令如下所示:
mysqldump -u root -p '123456' wiki | gzip -9 | ssh username@remote_ip "cat > /backup/wikidb.gz"
这些使用了管道的命令有如下特点:
- 命令的语法紧凑并且使用简单。
- 通过使用管道,将三个命令串联到一起就完成了远程 mysql 备份的复杂任务。
- 从管道输出的标准错误会混合到一起。
grep(Linux三剑客之一)
很多时候,我们并不需要列出文件的全部内容,而是从文件中找到包含指定信息的那些行,要实现这个目的,可以使用 grep 命令
grep 命令的全称:global regular expressions print (全局正则表达式打印)
grep命令能够在一个或多个文件中,搜索某一特定的字符模式(也就是正则表达式),此模式可以是单一的字符、字符串、单词或句子。
grep 命令的基本格式如下:
[root@localhost ~]# grep [选项] 模式 文件名
这里的模式,要么是字符(串),要么是正则表达式。而此命令常用的选项以及各自的含义如表所示。
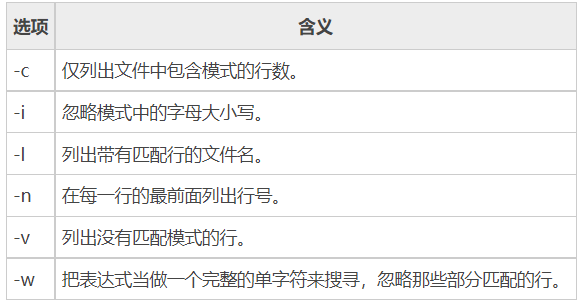
注意,如果是搜索多个文件,grep 命令的搜索结果只显示文件中发现匹配模式的文件名;而如果搜索单个文件,grep 命令的结果将显示每一个包含匹配模式的行。
【例 1】假设有一份 emp.data 员工清单,现在要搜索此文件,找出职位为 CLERK 的所有员工,则执行命令如下:
[root@localhost ~]# grep CLERK emp.data
#忽略输出内容
而在此基础上,如果只想知道职位为 CLERK 的员工的人数,可以使用“-c”选项,执行命令如下:
[root@localhost ~]# grep -c CLERK emp.data
#忽略输出内容
【例 2】搜索 emp.data 文件,使用正则表达式找出以 78 开头的数据行,执行命令如下:
[root@localhost ~]# grep ^78 emp.data
#忽略输出内容
grep 命令支持如表所示的这几种正则表达式的元字符:
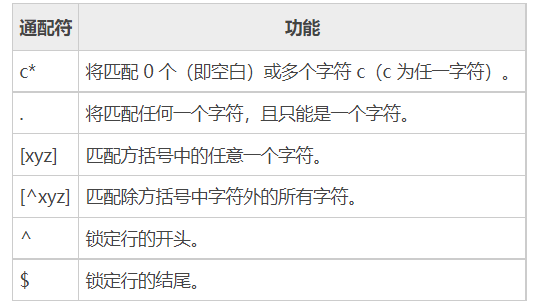
sed (Linux三剑客之一)
Vim 采用的是交互式文本编辑模式,你可以用键盘命令来交互性地插入、删除或替换数据中的文本。但sed 命令不同,它采用的是流编辑模式,最明显的特点是,在 sed 处理数据之前,需要预先提供一组规则,sed 会按照此规则来编辑数据。
sed 会根据脚本命令来处理文本文件中的数据,这些命令要么从命令行中输入,要么存储在一个文本文件中,此命令执行数据的顺序如下:
- 每次仅读取一行内容;
- 根据提供的规则命令匹配并修改数据。注意,sed 默认不会直接修改源文件数据,而是会将数据复制到缓冲区中,修改也仅限于缓冲区中的数据;
- 将执行结果输出。
当一行数据匹配完成后,它会继续读取下一行数据,并重复这个过程,直到将文件中所有数据处理完毕。
语法
sed [-hnV][-e<script>][-f<script文件>][文本文件]
参数说明:
- -e或–expression= 以选项中指定的script来处理输入的文本文件。
- -f<script文件>或–file=<script文件> 以选项中指定的script文件来处理输入的文本文件。
- -h或–help 显示帮助。
- -n或–quiet或–silent 仅显示script处理后的结果。
- -V或–version 显示版本信息。
动作说明:
- a :新增, a 的后面可以接字串,而这些字串会在新的一行出现(目前的下一行)~
- c :取代, c 的后面可以接字串,这些字串可以取代 n1,n2 之间的行!
- d :删除,因为是删除,所以 d 后面通常不接任何东东;
- i :插入, i 的后面可以接字串,而这些字串会在新的一行出现(目前的上一行);
- p :打印,亦即将某个选择的数据印出。通常 p 会与参数 sed -n 一起运行~
- s :取代,可以直接进行取代的工作哩!通常这个 s 的动作可以搭配正规表示法!例如 1,20s/old/new/g
实例
先创建一个 testfile 文件,内容如下:
$ cat testfile #查看testfile 中的内容
HELLO LINUX!
Linux is a free unix-type opterating system.
This is a linux testfile!
Linux test
Google
Taobao
Runoob
Tesetfile
Wiki
添加
在 testfile 文件的第四行后添加一行,并将结果输出到标准输出,在命令行提示符下输入如下命令:
sed -e 4a\\newLine testfile
使用 sed 命令后,输出结果如下:
$ sed -e 4a\\newLine testfile
HELLO LINUX!
Linux is a free unix-type opterating system.
This is a linux testfile!
Linux test
newLine
Google
Taobao
Runoob
Tesetfile
Wiki
以行为单位的新增/删除
将 testfile 的内容列出并且列印行号,同时,请将第 2~5 行删除!
$ nl testfile | sed '2,5d'
1 HELLO LINUX!
6 Taobao
7 Runoob
8 Tesetfile
9 Wiki
sed 的动作为 2,5d,那个 d 是删除的意思,因为删除了 2-5 行,所以显示的数据就没有 2-5 行了, 另外,原本应该是要下达 sed -e 才对,但没有 -e 也是可以的,同时也要注意的是, sed 后面接的动作,请务必以 ‘…’ 两个单引号括住!
只要删除第 2 行:
$ nl testfile | sed '2d'
1 HELLO LINUX!
3 This is a linux testfile!
4 Linux test
5 Google
6 Taobaos
7 Runoob
8 Tesetfile
9 Wiki
要删除第 3 到最后一行:
$ nl testfile | sed '3,$d'
1 HELLO LINUX!
2 Linux is a free unix-type opterating system.
以行为单位的替换与显示
将第 2-5 行的内容取代成为 No 2-5 number
$ nl testfile | sed '2,5c No 2-5 number'
1 HELLO LINUX!
No 2-5 number
6 Taobao
7 Runoob
8 Tesetfile
9 Wiki
透过这个方法我们就能够将数据整行取代了。
数据的搜寻并显示
搜索 testfile 有 oo 关键字的行:
$ nl testfile | sed -n '/oo/p'
5 Google
7 Runoob
如果 root 找到,除了输出所有行,还会输出匹配行。
直接修改文件内容(危险动作)
sed 可以直接修改文件的内容,不必使用管道命令或数据流重导向! 不过,由于这个动作会直接修改到原始的文件
regular_express.txt 文件内容如下:
$ cat regular_express.txt
runoob.
google.
taobao.
facebook.
zhihu-
weibo-
利用 sed 将 regular_express.txt 内每一行结尾若为 . 则插入 !
$ sed -i 's/\\.$/\\!/g' regular_express.txt
$ cat regular_express.txt
runoob!
google!
taobao!
facebook!
zhihu-
weibo-
:q:q
利用 sed 直接在 regular_express.txt 最后一行加入 # This is a test:
$ sed -i '$a # This is a test' regular_express.txt
$ cat regular_express.txt
runoob!
google!
taobao!
facebook!
zhihu-
weibo-
# This is a test
由於 $ 代表的是最后一行,而 a 的动作是新增,因此该文件最后新增 # This is a test!
sed 的 -i 选项可以直接修改文件内容,这功能非常有帮助!举例来说,如果你有一个 100 万行的文件,你要在第 100 行加某些文字,此时使用 vim 可能会疯掉!因为文件太大了!就利用 sed !透过 sed 直接修改/取代的功能,你甚至不需要使用 vim 去修订
awk(Linux三剑客之一)
awk是专门为文本处理设计的编程语言,是一门数据驱动的编程语言,与sed类似都是以数据驱动的行处理软件,主要用于数据扫描、过滤、统计汇总工作,数据可以来自标准输入、管道或者文件。
awk是基于列的文本处理工具,它的工作方式是按行读取文本并视为一条记录,每条记录以字段分割成若干字段,然后输出各字段的值。
之所以叫 AWK 是因为其取了三位创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
语法格式:
awk [选项] ‘条件{动作} 条件{动作} ... ...’ 文件名
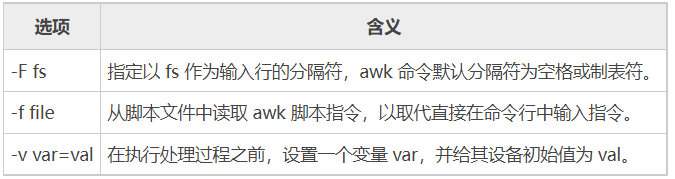
awk语法由一系列条件和动作组成,在花括号内可以有多个动作,多个动作之间用分号分隔,在多个条件和动作之间可以有若干空格,也可以没有。
如果没有指定条件则匹配所有数据,如果没有指定动作则默认为print打印。
例子:
[root@localhost ~]# awk '/^$/ {print "Blank line"}' test.txt
在此命令中,/^$/ 是一个正则表达式,功能是匹配文本中的空白行,同时可以看到,执行命令使用的是 print 命令,此命令经常会使用,它的作用很简单,就是将指定的文本进行输出。因此,整个命令的功能是,如果 test.txt 有 N 个空白行,那么执行此命令会输出 N 个 Blank line。
awk 使用数据字段变量
awk 的主要特性之一是其处理文本文件中数据的能力,它会自动给一行中的每个数据元素分配一个变量。
默认情况下,awk 会将如下变量分配给它在文本行中发现的数据字段:
- $0 代表整个文本行;
- $1 代表文本行中的第 1 个数据字段;
- $2 代表文本行中的第 2 个数据字段;
- $n 代表文本行中的第 n 个数据字段。
前面说过,在 awk 中,默认的字段分隔符是任意的空白字符(例如空格或制表符)。 在文本行中,每个数据字段都是通过字段分隔符划分的。awk 在读取一行文本时,会用预定义的字段分隔符划分每个数据字段。

awk 程序读取文本文件,只显示第 1 个数据字段的值:
[root@localhost ~]# cat data2.txt
One line of test text.
Two lines of test text.
Three lines of test text.
[root@localhost ~]# awk '{print $1}' data2.txt
One
Two
Three
该程序用 $1 字段变量来表示“仅显示每行文本的第 1 个数据字段”。当然,如果你要读取采用了其他字段分隔符的文件,可以用 -F 选项手动指定。
awk 脚本命令使用多个命令
awk 允许将多条命令组合成一个正常的程序。要在命令行上的程序脚本中使用多条命令,只要在命令之间放个分号即可,例如:
[root@localhost ~]# echo "My name is Rich" | awk '{$4="Christine"; print $0}'
My name is Christine
第一条命令会给字段变量 $4 赋值。第二条命令会打印整个数据字段。可以看到,awk 程序在输出中已经将原文本中的第四个数据字段替换成了新值。
awk BEGIN关键字
awk 中还可以指定脚本命令的运行时机。默认情况下,awk 会从输入中读取一行文本,然后针对该行的数据执行程序脚本,但有时可能需要在处理数据前运行一些脚本命令,这就需要使用 BEGIN 关键字。
BEGIN 会强制 awk 在读取数据前执行该关键字后指定的脚本命令,例如:
[root@localhost ~]# cat data3.txt
Line 1
Line 2
Line 3
[root@localhost ~]# awk 'BEGIN {print "The data3 File Contents:"} {print $0}' data3.txt
The data3 File Contents:
Line 1
Line 2
Line 3
可以看到,这里的脚本命令中分为 2 部分,BEGIN 部分的脚本指令会在 awk 命令处理数据前运行,而真正用来处理数据的是第二段脚本命令。
awk END关键字
和 BEGIN 关键字相对应,END 关键字允许我们指定一些脚本命令,awk 会在读完数据后执行它们,例如:
[root@localhost ~]# awk 'BEGIN {print "The data3 File Contents:"} {print $0} END {print "End of File"}' data3.txt
The data3 File Contents:
Line 1
Line 2
Line 3
End of File
5. Linux用户管理
用户 & 用户组
用户:
Linux 是多用户多任务操作系统,换句话说,Linux 系统支持多个用户在同一时间内登陆,不同用户可以执行不同的任务,并且互不影响。
不同用户具有不问的权限,毎个用户在权限允许的范围内完成不间的任务,Linux 正是通过这种权限的划分与管理,实现了多用户多任务的运行机制。
通过建立不同属性的用户,一方面可以合理地利用和控制系统资源,另一方面也可以帮助用户组织文件,提供对用户文件的安全性保护。
每个用户都有唯一的用户名和密码。
用户组:
用户组是具有相同特征用户的逻辑集合。简单的理解,有时我们需要让多个用户具有相同的权限,比如查看、修改某一个文件的权限,一种方法是分别对多个用户进行文件访问授权,如果有 10 个用户的话,就需要授权 10 次,那如果有 100、1000 甚至更多的用户呢?
显然,这种方法不太合理。最好的方式是建立一个组,让这个组具有查看、修改此文件的权限,然后将所有需要访问此文件的用户放入这个组中。那么,所有用户就具有了和组一样的权限,这就是用户组。
将用户分组是 Linux 系统中对用户进行管理及控制访问权限的一种手段,通过定义用户组,很多程序上简化了对用户的管理工作。
UID & GID
1)User ID,简称UID,是用来区分不同用户的数字,系统会自动记录“用户名”和UID的对应关系。
注:登陆 Linux 系统时,虽然输入的是自己的用户名和密码,但其实 Linux 并不认识你的用户名称,它只认识用户名对应的 ID 号(也就是一串数字)
Linux系统中的用户分为3类,即:
-
普通用户
指所有使用Linux系统的真实用户,这类用户可以使用用户名及密码登录系统。Linux有着极为详细的权限设置,所以一般来说普通用户只能在其家目录、系统临时目录或其他经过授权的目录中操作,以及操作属于该用户的文件。通常普通用户的UID大于500,因为在添加普通用户时,系统默认用户ID从500开始编号。
使用 id 命令可以查看当前用户的uid以及gid:
[user1@linux30 ~]$ id uid=1003(user1) gid=1003(user1) 组=1003(user1) 环境=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 [user1@linux30 ~]$ -
根用户
也就是root用户,它的ID是0,也被称为超级用户,root账户拥有对系统的完全控制权:可以修改、删除任何文件,运行任何命令。所以root用户也是系统里面最具危险性的用户,root用户甚至可以在系统正常运行时删除所有文件系统,造成无法挽回的灾难。所以一般情况下,使用root用户登录系统时需要十分小心。
[root@linux30 ~]# id uid=0(root) gid=0(root) 组=0(root) 环境=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 [root@linux30 ~]# -
系统用户
系统运行时必须有的用户,但并不是指真实的使用者。比如在RedHat或CentOS下运行网站服务时,需要使用系统用户apache来运行httpd进程,而运行MySQL数据库服务时,需要使用系统用户mysql来运行mysqld进程。在RedHat或CentOS下,系统用户的ID范围是1~499。
[root@linux30 ~]# ps aux | grep apache apache 2944 0.0 0.0 230440 3004 ? S 11:16 0:00 /usr/sbin/httpd -DFOREGROUND apache 2945 0.0 0.0 230440 3004 ? S 11:16 0:00 /usr/sbin/httpd -DFOREGROUND apache 2946 0.0 0.0 230440 3004 ? S 11:16 0:00 /usr/sbin/httpd -DFOREGROUND apache 2947 0.0 0.0 230440 3004 ? S 11:16 0:00 /usr/sbin/httpd -DFOREGROUND apache 2948 0.0 0.0 230440 3004 ? S 11:16 0:00 /usr/sbin/httpd -DFOREGROUND root 2952 0.0 0.0 112824 984 pts/0 S+ 11:17 0:00 grep --color=auto apache
2)Group ID,简称GID,是用于区分不同用户组的ID。
使用ls -l查看文件时,第三列和第四列显示的是这个文件的所有者是用户root,所有组是root组,如果加上了-n参数,第三列和第四列则是用UID和GID来显示的,这里分别是0和0。
[root@linux30 ~]# ls -l
总用量 4
-rw-------. 1 root root 1440 9月 6 15:43 anaconda-ks.cfg
drwxr-xr-x. 5 root root 53 10月 21 17:49 logs
drwxr-xr-x. 4 root root 34 10月 25 15:47 nacos
[root@linux30 ~]# ls -ln
总用量 4
-rw-------. 1 0 0 1440 9月 6 15:43 anaconda-ks.cfg
drwxr-xr-x. 5 0 0 53 10月 21 17:49 logs
drwxr-xr-x. 4 0 0 34 10月 25 15:47 nacos
[root@linux30 ~]#
在Linux下每个用户都至少属于一个组。
想获取自己的UID:
[root@linux30 ~]# id
uid=0(root) gid=0(root) 组=0(root) 环境=unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023
[root@linux30 ~]#
想获取自己所属的组:
[root@linux30 ~]# groups
root
[root@linux30 ~]#
/etc/passwd
Linux 系统中的 /etc/passwd 文件,是系统用户配置文件,存储了系统中所有用户的基本信息,并且所有用户都可以对此文件执行读操作。
[root@localhost ~]# vi /etc/passwd
#查看一下文件内容
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
...省略部分输出...
可以看到,/etc/passwd 文件中的内容非常规律,每行记录对应一个用户。
疑问:Linux 系统中默认怎么会有这么多的用户?
这些用户中的绝大多数是系统或服务正常运行所必需的用户,这种用户通常称为系统用户或伪用户。系统用户无法用来登录系统,但也不能删除,因为一旦删除,依赖这些用户运行的服务或程序就不能正常执行,会导致系统问题。
不仅如此,每行用户信息都以 “:” 作为分隔符,划分为 7 个字段,每个字段所表示的含义如下:
用户名:密码:UID(用户ID):GID(组ID):描述性信息:主目录:默认Shell
-
用户名:
用户名,就是一串代表用户身份的字符串。
-
密码:
“x” 表示此用户设有密码,但不是真正的密码,真正的密码保存在 /etc/shadow 文件中(为了保证密码安全)
-
UID: UID,也就是用户 ID。每个用户都有唯一的一个 UID,Linux 系统通过 UID 来识别不同的用户,实际上,UID 就是一个 0~65535 之间的数,不同范围的数字表示不同的用户身份,具体如表所示

-
GID:
全称“Group ID”,简称“组ID”,表示用户初始组的组 ID 号
-
描述性信息:
这个字段并没有什么重要的用途,只是用来解释这个用户的意义而已。
-
主目录
也就是用户登录后有操作权限的访问目录,通常称为用户的主目录。
-
默认Shell:
Shell 就是 Linux 的命令解释器,是用户和 Linux 内核之间沟通的桥梁。
我们知道,用户登陆 Linux 系统后,通过使用 Linux 命令完成操作任务,但系统只认识类似 0101 的机器语言,这里就需要使用命令解释器。也就是说,Shell 命令解释器的功能就是将用户输入的命令转换成系统可以识别的机器语言。
通常情况下,Linux 系统默认使用的命令解释器是 bash(/bin/bash),当然还有其他命令解释器,例如 sh、csh 等。
在 /etc/passwd 文件中,可以把这个字段理解为用户登录之后所拥有的权限。如果这里使用的是 bash 命令解释器,就代表这个用户拥有权限范围内的所有权限。例如:
[root@localhost ~]# vi /etc/passwd
lamp:x:502:502::/home/lamp:/bin/bash
手工添加了 lamp 用户,它使用的是 bash 命令解释器,那么这个用户就可以使用普通用户的所有权限。
如果我把 lamp 用户的 Shell 命令解释器修改为 /sbin/nologin,那么,这个用户就不能登录了,例如:
[root@localhost ~]# vi /etc/passwd
lamp:x:502:502::/home/lamp:/sbin/nologin
因为 /sbin/nologin 就是禁止登录的 Shell。同样,如果我在这里放入的系统命令,如 /usr/bin/passwd,例如:
[root@localhost ~]#vi /etc/passwds
lamp:x:502:502::/home/lamp:/usr/bin/passwd
那么这个用户可以登录,但登录之后就只能修改自己的密码。但是,这里不能随便写入和登陆没有关系的命令(如 ls),系统不会识别这些命令,同时也就意味着这个用户不能登录。
/etc/shadow
/etc/shadow 文件,用于存储 Linux 系统中用户的密码信息,又称为“影子文件”。
前面介绍了 /etc/passwd 文件,由于该文件允许所有用户读取,易导致用户密码泄露,因此 Linux 系统将用户的密码信息从 /etc/passwd 文件中分离出来,并单独放到了此文件中。
/etc/shadow 文件只有 root 用户拥有读权限,其他用户没有任何权限,这样就保证了用户密码的安全性。
[root@localhost ~]#vim /etc/shadow
root: $6$9w5Td6lg
$bgpsy3olsq9WwWvS5Sst2W3ZiJpuCGDY.4w4MRk3ob/i85fl38RH15wzVoom ff9isV1 PzdcXmixzhnMVhMxbvO:15775:0:99999:7:::
bin:*:15513:0:99999:7:::
daemon:*:15513:0:99999:7:::
…省略部分输出…
同 /etc/passwd 文件一样,文件中每行代表一个用户,同样使用 “:” 作为分隔符,不同之处在于,每行用户信息被划分为 9 个字段。每个字段的含义如下:
用户名:加密密码:最后一次修改时间:最小修改时间间隔:密码有效期:密码需要变更前的警告天数:密码过期后的宽限时间:账号失效时间:保留字段
忘记密码
对于普通账户的密码遗失,可以通过 root 账户解决,它会重新给你配置好指定账户的密码,而不需知道你原有的密码(利用 root 的身份使用 passwd 命令即可)。
如果 root 账号的密码遗失,则需要重新启动进入单用户模式,系统会提供 root 权限的 bash 接口,此时可以用 passwd 命令修改账户密码;也可以通过挂载根目录,修改 /etc/shadow,将账户的 root 密码清空的方法,此方式可使用 root 无法密码即可登陆,建议登陆后使用 passwd 命令配置 root 密码。
添加新用户
Linux 系统中,可以使用 useradd 命令新建用户,此命令的基本格式如下:
[root@localhost ~]#useradd [选项] 用户名
该命令常用的选项及各自的含义,如表所示。

其实,系统已经帮我们规定了非常多的默认值,在没有特殊要求下,无需使用任何选项即可成功创建用户。例如:
[root@localhost ~]# useradd lamp
不要小看这条简单的命令,它会完成以下几项操作:
-
在 /etc/passwd 文件中创建一行与 lamp 用户相关的数据:
[root@localhost ~]# grep "lamp" /etc/passwd lamp:x:500:500::/home/lamp:/bin/bash可以看到,用户的 UID 是从 500 开始计算的。同时默认指定了用户的家目录为 /home/lamp/,用户的登录 Shell 为 /bin/bash。
-
在 /etc/shadow 文件中新增了一行与 lamp 用户密码相关的数据:
[root@localhost ~]# grep "lamp" /etc/shadow lamp:!!:15710:0:99999:7:::当然,这个用户还没有设置密码,所以密码字段是 “!!”,代表这个用户没有合理密码,不能正常登录。同时会按照默认值设定时间字段,例如密码有效期有 99999 天,距离密码过期 7 天系统会提示用户“密码即将过期”等。
-
在 /etc/group 文件中创建一行与用户名一模一样的群组:
[root@localhost ~]# grep "lamp" /etc/group lamp:x:500:该群组会作为新建用户的初始组。
-
在 /etc/gshadow 文件中新增一行与新增群组相关的密码信息:
[root@localhost ~]# grep "lamp" /etc/gshadow lamp:!::当然,我们没有设定组密码,所以这里没有密码,也没有组管理员。
-
默认创建用户的主目录和邮箱:
[root@localhost ~]#ll -d /home/lamp/ drwx------ 3 lamp lamp 4096 1月6 00:19 /home/lamp/ [root@localhost ~]#ll /var/spod/mail/lamp -rw-rw---- 1 lamp mail 0 1月6 00:19 /var/spool/mail/lamp注意这两个文件的权限,都要让 lamp 用户拥有相应的权限。
-
将 /etc/skel 目录中的配置文件复制到新用户的主目录中
备注:useradd 命令在添加用户时参考的默认值文件主要有两个,分别是 /etc/default/useradd 和 /etc/login.defs
流程 useradd 命令创建用户的过程是这样的,系统首先读取 /etc/login.defs 和 /etc/default/useradd,根据这两个配置文件中定义的规则添加用户,也就是向 /etc/passwd、/etc/group、/etc/shadow、/etc/gshadow 文件中添加用户数据,接着系统会自动在 /etc/default/useradd 文件设定的目录下建立用户主目录,最后复制 /etc/skel 目录中的所有文件到此主目录中,由此,一个新的用户就创建完成了。
修改用户密码
创建用户后,该用户实际上还没有登录系统的权限,因为在不设置密码的情况下,在/etc/shadow中该用户记录中以冒号分隔的第二列将显示为两个感叹号“!!”,这说明不允许该用户登录系统。
[root@localhost ~]#passwd [选项] 用户名
选项:
- -S:查询用户密码的状态,也就是 /etc/shadow 文件中此用户密码的内容。仅 root 用户可用;
- -l:暂时锁定用户,该选项会在 /etc/shadow 文件中指定用户的加密密码串前添加 “!”,使密码失效。仅 root 用户可用;
- -u:解锁用户,和 -l 选项相对应,也是只能 root 用户使用;
- –stdin:可以将通过管道符输出的数据作为用户的密码。主要在批量添加用户时使用;
- -n 天数:设置该用户修改密码后,多长时间不能再次修改密码,也就是修改 /etc/shadow 文件中各行密码的第 4 个字段;
- -x 天数:设置该用户的密码有效期,对应 /etc/shadow 文件中各行密码的第 5 个字段;
- -w 天数:设置用户密码过期前的警告天数,对于 /etc/shadow 文件中各行密码的第 6 个字段;
- -i 日期:设置用户密码失效日期,对应 /etc/shadow 文件中各行密码的第 7 个字段。
例如,我们使用 root 账户修改 lamp 普通用户的密码,可以使用如下命令:
[root@localhost ~]#passwd lamp
Changing password for user lamp.
New password: <==直接输入新的口令,但屏幕不会有任何反应
BAD PASSWORD: it is WAY too short <==口令太简单或过短的错误!这里只是警告信息,输入的密码依旧能用
Retype new password: <==再次验证输入的密码,再输入一次即可
passwd: all authentication tokens updated successfully. <==提示修改密码成功
当然,也可以使用 passwd 命令修改当前系统已登录用户的密码,但要注意的是,需省略掉 “选项” 和 “用户名”。例如,我们登陆 lamp 用户,并使用 passwd 命令修改 lamp 的登陆密码,执行过程如下:
[root@localhost ~]#passwd
#passwd直接回车代表修改当前用户的密码
Changing password for user vbird2.
Changing password for vbird2
(current) UNIX password: <==这里输入『原有的旧口令』
New password: <==这里输入新口令
BAD PASSWORD: it is WAY too short <==口令检验不通过,请再想个新口令
New password: <==这里再想个来输入吧
Retype new password: <==通过口令验证!所以重复这个口令的输入
passwd: all authentication tokens updated successfully. <==成功修改用户密码
注意,普通用户只能使用 passwd 命令修改自己的密码,而不能修改其他用户的密码。
可以看到,与使用 root 账户修改普通用户的密码不同,普通用户修改自己的密码需要先输入自己的旧密码,只有旧密码输入正确才能输入新密码。不仅如此,此种修改方式对密码的复杂度有严格的要求,新密码太短、太简单,都会被系统检测出来并禁止用户使用。
很多Linux 发行版为了系统安装,都使用了 PAM 模块进行密码的检验,设置密码太短、与用户名相同、是常见字符串等,都会被 PAM 模块检查出来,从而禁止用户使用此类密码。
删除用户
userdel 命令功能很简单,就是删除用户的相关数据。此命令只有 root 用户才能使用。
通过前面的学习我们知道,用户的相关数据包含如下几项:
- 用户基本信息:存储在 /etc/passwd 文件中;
- 用户密码信息:存储在 /etc/shadow 文件中;
- 用户群组基本信息:存储在 /etc/group 文件中;
- 用户群组信息信息:存储在 /etc/gshadow 文件中;
- 用户个人文件:主目录默认位于 /home/用户名,邮箱位于 /var/spool/mail/用户名。
其实,userdel 命令的作用就是从以上文件中,删除与指定用户有关的数据信息。
userdel 命令的语法很简单,基本格式如下:
[root@localhost ~]# userdel -r 用户名
-r 选项表示在删除用户的同时删除用户的家目录。
注意,在删除用户的同时如果不删除用户的家目录,那么家目录就会变成没有属主和属组的目录,也就是垃圾文件。
例如,删除前面章节中创建的 lamp 用户,只需执行如下命令:
[root@localhost ~]# userdel -r lamp
切换用户
su
在使用Linux的过程中,很多时候由于实际需要可能要在不同的用户之间切换,比如,原本是使用普通用户登录的,但是在操作的过程中由于权限原因必须使用root用户来做一些操作,这时就需要临时切换成root用户;操作完成后,再退出切换成普通用户。
su 是最简单的用户切换命令,通过该命令可以实现任何身份的切换,包括从普通用户切换为 root 用户、从 root 用户切换为普通用户以及普通用户之间的切换。
普通用户之间切换以及普通用户切换至 root 用户,都需要知晓对方的密码,只有正确输入密码,才能实现切换;从 root 用户切换至其他用户,无需知晓对方密码,直接可切换成功。
su 命令的基本格式如下:
[root@localhost ~]# su [选项] 用户名
选项:
- -:当前用户不仅切换为指定用户的身份,同时所用的工作环境也切换为此用户的环境(包括 PATH 变量、MAIL 变量等),使用 - 选项可省略用户名,默认会切换为 root 用户
- -l:同 - 的使用类似,也就是在切换用户身份的同时,完整切换工作环境,但后面需要添加欲切换的使用者账号。
- -p:表示切换为指定用户的身份,但不改变当前的工作环境(不使用切换用户的配置文件)。
- -m:和 -p 一样;
- -c 命令:仅切换用户执行一次命令,执行后自动切换回来,该选项后通常会带有要执行的命令
su 对比 su-
su 命令时,有 - 和没有 - 是完全不同的,- 选项表示在切换用户身份的同时,连当前使用的环境变量也切换成指定用户的。我们知道,环境变量是用来定义操作系统环境的,因此如果系统环境没有随用户身份切换,很多命令无法正确执行。
通俗的理解:即有 - 选项,切换用户身份更彻底;反之,只切换了一部分,这会导致某些命令运行出现问题或错误(例如无法使用 service 命令)。
[lamp@localhost ~]$ su
Password:
[root@localhost lamp]# pwd
/home/lamp
[root@localhost lamp]# echo $PATH
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/usr/local/java/jdk1.8.0_321/bin:/usr/local/java/jdk1.8.0_321/jre/bin:/home/lamp/.local/bin:/home/lamp/bin
[root@localhost lamp]# echo $PATH
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/usr/local/java/jdk1.8.0_321/bin:/usr/local/java/jdk1.8.0_321/jre/bin:/home/lamp/.local/bin:/home/lamp/bin
[root@localhost lamp]# su - root
Last login: Wed Jul 20 06:36:48 EDT 2022 on pts/0
[root@localhost ~]# pwd
/root
[root@localhost ~]# echo $PATH
/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/usr/local/java/jdk1.8.0_321/bin:/usr/local/java/jdk1.8.0_321/jre/bin:/root/bin
[root@localhost ~]#
sudo
sudo并不是真的切换了用户,而是使用其他用户的身份和权限执行了命令。
使用root的身份修改user2的密码
[user1@linux30 root]$ sudo passwd user2
我们信任您已经从系统管理员那里了解了日常注意事项。
总结起来无外乎这三点:
#1) 尊重别人的隐私。
#2) 输入前要先考虑(后果和风险)。
#3) 权力越大,责任越大。
[sudo] user1 的密码:
user1 不在 sudoers 文件中。此事将被报告。
[user1@linux30 root]$
运行该命令时,系统首先检查/etc/sudoers,判断该用户是否有执行sudo的权限,在确定有执行权限后,系统要求用户输自己的密码,如果密码输入正确,则会以root用户的身份运行passwd user2命令。
在演示sudo命令之前,首先需要设置/etc/sudoers这个配置文件。当然,可以使用一些常见的编辑器来编辑这个文件,比如vi或者vim编辑器等,但是考虑到这个配置文件的重要性,Linux提供了专门编辑这个文件的方式,就是使用命令visudo来编辑这个文件,它的好处是可以在编辑后保存退出时自动检查语法设置,以防止不小心配置错误而造成无法使用sudo命令。该命令如下所示:
[root@linux30 ~]# visudo
...省略...
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
user1 ALL=(ALL) ALL ## 复制上一行的内容
...省略...
修改完成后,使用用户user1登录,然后再尝试使用sudo给别的用户修改密码,系统首先要求输入用户user1的密码,验证通过后,就可以设置其他用户的密码了
[user1@linux30 root]$ sudo passwd user2
[sudo] user1 的密码:
更改用户 user2 的密码 。
新的 密码:
无效的密码: 密码未通过字典检查 - 过于简单化/系统化
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
[user1@linux30 root]$
user1这个用户可以从任何地方登录后执行任何人的任何命令。还可以定义某一个组的sudo权限,比如“%user1 ALL=(ALL) ALL”可以让所有属于user1用户组的用户从任何地方登录后执行任何人的任何命令。这样方便多了。但是每次都需要输入一遍密码也是比较麻烦的事情,想要实现不需要输入密码就可以执行命令,可以在最后一个ALL前添加“NOPASSWD:”
user1 ALL=(ALL) NOPASSWD:ALL ## 复制上一行的内容
[root@linux30 ~]# su - user1
上一次登录:一 12月 20 14:14:19 CST 2021pts/0 上
[user1@linux30 ~]$ sudo passwd user2
更改用户 user2 的密码 。
新的 密码:
无效的密码: 密码未通过字典检查 - 过于简单化/系统化
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
[user1@linux30 ~]$
6. Linux权限控制
Linux系统之所以更安全,是因为对文件权限有着非常严格的控制。
3.2.1 查看文件或目录的权限:ls-al
[root@bogon linux]# ls -lih
total 112K
1451 -rw-r--r--. 1 root root 74 Jul 26 03:57 data2.txt
1448 -rw-r--r--. 1 root root 37 Jul 26 03:35 emp.data
1445 -rw-r--r--. 1 root root 101 Jul 26 03:22 file1
50592733 -rw-r--r--. 2 root root 92K Jul 26 02:59 redis2.conf
1450 -rw-r--r--. 1 root root 55 Jul 26 03:51 regular_express.txt
1449 -rw-r--r--. 1 root root 134 Jul 26 03:44 testfile

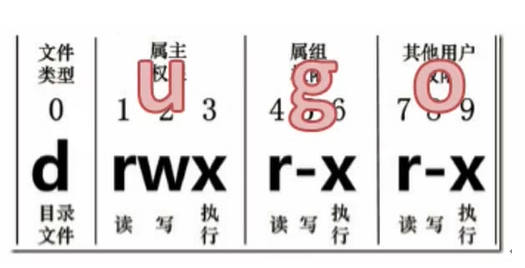
每个文件针对每类访问者定义了三种主要权限。其中,第一位:代表文件类型,后面每3位代表一组权限,分别是:所有者、所属组和其他人。

文件权限分别为:读( read ),写( write ),执行( execute),简写即为(r,w,x),也可以可用数字来(4,2,1)表示,-即无权限。
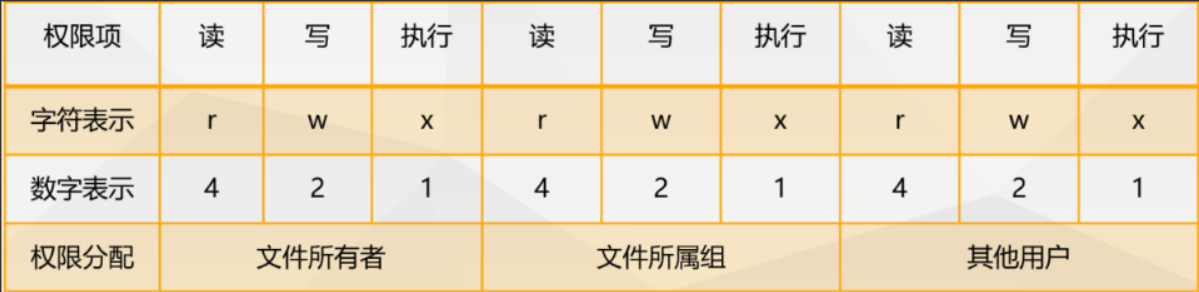
注意 :
- root账户不受文件权限的读写限制,执行权限受限制
- 用户获取文件权限的顺序:先看是否为所有者,如果是,则后面权限不看;再看是否为所属组,如果是,则后面权限不看
- 缺省创建的文件不可授予可执行的权限,基于最基本的安全机制,防止病毒等
对于文件和目录来说,r、w、x有着不同的作用和含义
针对文件 :

针对目录 :目录本质可看做是存放文件列表、节点号等内容的文件

3.2.3 改变文件权限:chmod
[root@localhost ~]# **chmod** [选项] 模式 文件名
参数说明:
-
选项:-R 表示递归
-
模式:权限 字母 表示法 :[ugoa] [±=] [rwx] 权限 数字 表示法 :[mode=421]
-
权限数字:r-4,w-2,x-1,无权限 - 0
-
常用组合:777最高权限,644普通文件权限,755执行权限
-
修改权限格式1:
用户表示符+/-=权限字符:
+:向权限范围增加权限代号所表示的权限
-:向权限范围取消权限代号所表示的权限
=:向权限范围赋予权限代号所表示的权限
用户符号:
u:拥有者
g:拥有者同组用
o:其它用户
a:所有用户
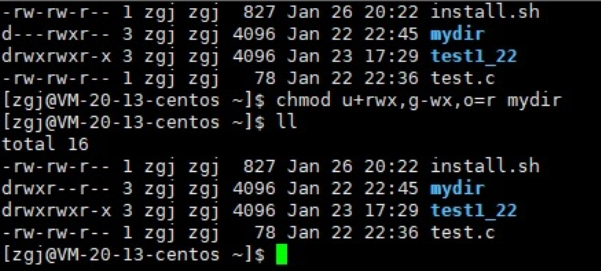
-
chmod 三位10进制数字
[root@localhost ~]# chmod 755 test.txt
3.2.4 改变文件的拥有者:chown
该命令用来更改文件的拥有者,同时它也具备更改文件拥有组的功能。默认情况下,使用什么用户登录系统,那么该用户新创建的文件和目录的拥有者就是这个用户
要是想改变该文件的拥有者和文件的用户组,则
[root@linux30 fileSys]# ls -l
-rw-r--r--. 1 root root 0 12月 21 09:13 chown_file
[root@linux30 fileSys]# chown user1:user2 chown_file
[root@linux30 fileSys]# ls -l
-rw-r--r--. 1 user1 user2 0 12月 21 09:13 chown_file
[root@linux30 fileSys]#
如果需要修改的不是一个文件而是一个目录,以及该目录下所有的文件、子目录、子目录下所有的文件和目录,则需要使用-R参数。
3.2.5 改变文件的拥有组:chgrp
该命令用来更改文件的拥有组
[root@linux30 fileSys]# ls -l
-rw-r--r--. 1 user1 user2 0 12月 21 09:13 chown_file
[root@linux30 fileSys]# chgrp user1 chown_file
[root@linux30 fileSys]# ls -l
-rw-r--r--. 1 user1 user1 0 12月 21 09:13 chown_file
[root@linux30 fileSys]#
3.2.7 默认权限和umask
所有的文件在创建时就都是有权限的了,也就是当我们创建文件的时候,系统套用默认权限来设置了文件。
[root@linux30 fileSys]# touch root_file1 root_file2
[root@linux30 fileSys]# mkdir root_dir1 root_dir2
[root@linux30 fileSys]# ls -ld root_*
drwxr-xr-x. 2 root root 6 12月 21 09:58 root_dir1
drwxr-xr-x. 2 root root 6 12月 21 09:58 root_dir2
-rw-r--r--. 1 root root 0 12月 21 09:58 root_file1
-rw-r--r--. 1 root root 0 12月 21 09:58 root_file2
注意,创建的root_file1、root_file2文件的权限都是644;创建的root_dir1、root_dir2目录的权限都是755。到这里似乎可以得出一个结论:文件的权限默认是644,目录的默认权限是755。
[user1@linux30 fileSys]$ su - user1 ## 切换为user1用户
密码:
上一次登录:二 12月 21 10:01:27 CST 2021pts/0 上
[user1@linux30 ~]$ ll
总用量 0
[user1@linux30 ~]$ touch u1_file1 u1_file2 ## 创建两个文件
[user1@linux30 ~]$ mkdir u1_dir1 u1_dir2 ## 创建两个目录
[user1@linux30 ~]$ ls -ld u1_* ## 显示user1创建的文件和目录权限
drwxrwxr-x. 2 user1 user1 6 12月 21 10:04 u1_dir1
drwxrwxr-x. 2 user1 user1 6 12月 21 10:04 u1_dir2
-rw-rw-r--. 1 user1 user1 0 12月 21 10:04 u1_file1
-rw-rw-r--. 1 user1 user1 0 12月 21 10:04 u1_file2
[user1@linux30 ~]$
这里创建的u1_file1、u1_file2文件的权限都是664;创建的u1_dir1、u1_dir2目录的权限都是775
**可以给出一个结论:**对于root用户,文件的默认权限是644,目录的默认权限是755;对于普通用户,文件的默认权限是664,目录的默认权限是775
这个默认权限是从哪里来的呢?为什么root用户和普通用户的默认权限不同呢?
要想回答上面的问题,就需要引入umask概念,中文翻译为:遮罩。在Linux下,定义目录创建的默认权限的值是“umask遮罩777后的权限”,定义文件创建的默认权限是“umask遮罩666后的权限”。
系统在/etc/profile文件中,设置了不同用户的遮罩值。
# By default, we want umask to get set. This sets it for login shell
# Current threshold for system reserved uid/gids is 200
# You could check uidgid reservation validity in
# /usr/share/doc/setup-*/uidgid file
if [ $UID -gt 199 ] && [ "`/usr/bin/id -gn`" = "`/usr/bin/id -un`" ]; then
umask 002
else
umask 022
fi
从上面的代码中可以看出,UID大于199的用户设置了umask为002,否则为022。所以umask值对于root用户是022,对于普通用户是002,这也就造成了上面我们看到的root用户和普通用户创建出来的文件和目录默认权限不一样,那么如何使用遮罩计算权限呢?
777用字符串表示为:rwxrwxrwx,如果遮罩值是022,用字符串表示为:----w–w-,那么前者第五位和第八位的w被遮罩掉,权限变为rwxr-xr-x,用数字表示就是755。如果遮罩值是002,用字符串表示为:-------w-,那么第八位的w被遮罩掉,权限变为rwxrwxr-x,用数字表示就是775。666用字符串表示为:rw-rw-rw-,如果遮罩值是022,用字符串表示为:----w–w-,那么前者第五位和第八位的w被遮罩掉,权限变为rw-r–r–,用数字表示就是644。如果遮罩值是002,用字符串表示为:-------w-,那么第八位的w被遮罩掉,权限变为rw-rw-r–,用数字表示就是664。
7. 进程管理
进程是Linux系统中一个非常重要的概念,但是,这并不意味着我们需要太过接近底层地去了解这些进程是如何运行的、内核是如何管理调度的、时间片是如何轮转分配的等问题,我们所需要关心的是如何控制这些进程,包括查看、启动、关闭、设置优先级等
7.1 什么是进程
进程是正在执行的一个程序或命令,每个进程都是一个运行的实体,都有自己的地址空间,并占用一定的系统资源。程序是人使用计算机语言编写的可以实现特定目标或解决特定问题的代码集合。
这么讲很难理解,那我们换一种说法。程序是人使用计算机语言编写的,可以实现一定功能,并且可以执行的代码集合。而进程是正在执行中的程序。当程序被执行时,执行人的权限和属性,以及程序的代码都会被加载入内存,操作系统给这个进程分配一个 ID,称为 PID(进程 ID)。
也就是说,在操作系统中,所有可以执行的程序与命令都会产生进程。只是有些程序和命令非常简单,如 ls 命令、touch 命令等,它们在执行完后就会结束,相应的进程也就会终结,所以我们很难捕捉到这些进程。但是还有一些程和命令,比如 httpd 进程,启动之后就会一直驻留在系统当中,我们把这样的进程称作常驻内存进程。
7.2 进程管理的作用
- 判断服务器的健康状态
- 查看系统中所有的进程
- 杀死进程
7.3 进程的观察:ps、top
ps
如果想要查看进程,了解当前进程的情况就需要用到相关命令了。其中,ps命令就是一款非常强大的进程查看工具。
- “ps aux” 可以查看系统中所有的进程;
- “ps -le” 可以查看系统中所有的进程,而且还能看到进程的父进程的 PID 和进程优先级;
- “ps -l” 只能看到当前 Shell 产生的进程;

[root@linux30 charPro]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 193692 6852 ? Ss 09:39 0:01 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
root 2 0.0 0.0 0 0 ? S 09:39 0:00 [kthreadd]
root 3 0.0 0.0 0 0 ? S 09:39 0:03 [kworker/0:0]
root 4 0.0 0.0 0 0 ? S< 09:39 0:00 [kworker/0:0H]
root 6 0.0 0.0 0 0 ? S 09:39 0:00 [ksoftirqd/0]
root 7 0.0 0.0 0 0 ? S 09:39 0:00 [migration/0]
root 8 0.0 0.0 0 0 ? S 09:39 0:00 [rcu_bh]
root 9 0.0 0.0 0 0 ? S 09:39 0:01 [rcu_sched]
root 10 0.0 0.0 0 0 ? S< 09:39 0:00 [lru-add-drain]
root 11 0.0 0.0 0 0 ? S 09:39 0:00 [watchdog/0]
root 12 0.0 0.0 0 0 ? S 09:39 0:00 [watchdog/1]
root 13 0.0 0.0 0 0 ? S 09:39 0:00 [migration/1]
root 14 0.0 0.0 0 0 ? S 09:39 0:00 [ksoftirqd/1]
root 16 0.0 0.0 0 0 ? S< 09:39 0:00 [kworker/1:0H]
root 17 0.0 0.0 0 0 ? S 09:39 0:00 [watchdog/2]
root 18 0.0 0.0 0 0 ? S 09:39 0:00 [migration/2]
root 19 0.0 0.0 0 0 ? S 09:39 0:00 [ksoftirqd/2]
root 21 0.0 0.0 0 0 ? S< 09:39 0:00 [kworker/2:0H]
root 22 0.0 0.0 0 0 ? S 09:39 0:00 [watchdog/3]
top
命令ps输出的只是当前查询状态下进程瞬间的状态信息,如果要想及时动态地查看进程就需要使用top命令了。top命令提供了实时的系统状态监控,可以按照CPU使用、内存使用、执行时间等指标对进程进行排序。

我们解释一下命令的输出。top 命令的输出内容是动态的,默认每隔 3 秒刷新一次。命令的输出主要分为两部分:
- 第一部分是前五行,显示的是整个系统的资源使用状况,我们就是通过这些输出来判断服务器的资源使用状态的;
- 第二部分从第六行开始,显示的是系统中进程的信息;
我们先来说明第一部分的作用。
-
第一行为任务队列信息,具体内容如表 1 所示。
内 容 说 明 12:26:46 系统当前时间 up 1 day, 13:32 系统的运行时间.本机己经运行 1 天 13 小时 32 分钟 2 users 当前登录了两个用户 load average: 0.00,0.00,0.00 系统在之前 1 分钟、5 分钟、15 分钟的平均负载。如果 CPU 是单核的,则这个数值超过 1 就是高负载:如果 CPU 是四核的,则这个数值超过 4 就是高负载 (这个平均负载完全是依据个人经验来进行判断的,一般认为不应该超过服务器 CPU 的核数) -
第二行为进程信息
内 容 说 明 Tasks: 95 total 系统中的进程总数 1 running 正在运行的进程数 94 sleeping 睡眠的进程数 0 stopped 正在停止的进程数 0 zombie 僵尸进程数。如果不是 0,则需要手工检查僵尸进程 -
第三行为 CPU 信息
内 容 说 明 Cpu(s): 0.1 %us 用户模式占用的 CPU 百分比 0.1%sy 系统模式占用的 CPU 百分比 0.0%ni 改变过优先级的用户进程占用的 CPU 百分比 99.7%id 空闲 CPU 占用的 CPU 百分比 0.1%wa 等待输入/输出的进程占用的 CPU 百分比 0.0%hi 硬中断请求服务占用的 CPU 百分比 0.1%si 软中断请求服务占用的 CPU 百分比 0.0%st st(steal time)意为虚拟时间百分比,就是当有虚拟机时,虚拟 CPU 等待实际 CPU 的时间百分比 -
第四行为物理内存信息
内 容 说 明 Mem: 625344k total 物理内存的总量,单位为KB 571504k used 己经使用的物理内存数量 53840k&ee 空闲的物理内存数量。我们使用的是虚拟机,共分配了 628MB内存,所以只有53MB的空闲内存 65800k buffers 作为缓冲的内存数量 -
第五行为交换分区(swap)信息
内 容 说 明 Swap: 524280k total 交换分区(虚拟内存)的总大小 Ok used 已经使用的交换分区的大小 524280k free 空闲交换分区的大小 409280k cached 作为缓存的交换分区的大小
我们通过 top 命令的第一部分就可以判断服务器的健康状态。如果 1 分钟、5 分钟、15 分钟的平均负载高于 1,则证明系统压力较大。如果 CPU 的使用率过高或空闲率过低,则证明系统压力较大。如果物理内存的空闲内存过小,则也证明系统压力较大。
这时,我们就应该判断是什么进程占用了系统资源。如果是不必要的进程,就应该结束这些进程;如果是必需进程,那么我们该増加服务器资源(比如増加虚拟机内存),或者建立集群服务器。
我们还要解释一下缓冲(buffer)和缓存(cache)的区别:
- 缓存(cache)是在读取硬盘中的数据时,把最常用的数据保存在内存的缓存区中,再次读取该数据时,就不去硬盘中读取了,而在缓存中读取。
- 缓冲(buffer)是在向硬盘写入数据时,先把数据放入缓冲区,然后再一起向硬盘写入,把分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道,从而提高系统性能。
简单来说,缓存(cache)是用来加速数据从硬盘中"读取"的,而缓冲(buffer)是用来加速数据"写入"硬盘的。
再来看 top 命令的第二部分输出,主要是系统进程信息,各个字段的含义如下:
- PID:进程的 ID。
- USER:该进程所属的用户。
- PR:优先级,数值越小优先级越高。
- NI:优先级,数值越小、优先级越高。
- VIRT:该进程使用的虚拟内存的大小,单位为 KB。
- RES:该进程使用的物理内存的大小,单位为 KB。
- SHR:共享内存大小,单位为 KB。
- S:进程状态。
- %CPU:该进程占用 CPU 的百分比。
- %MEM:该进程占用内存的百分比。
- TIME+:该进程共占用的 CPU 时间。
- COMMAND:进程的命令名。
7.4 进程的终止:kill、killall
kill 从字面来看,就是用来杀死进程的命令,但事实上,这个或多或少带有一定的误导性。从本质上讲,kill 命令只是用来向进程发送一个信号,至于这个信号是什么,是用户指定的。
也就是说,kill 命令的执行原理是这样的,kill 命令会向操作系统内核发送一个信号(多是终止信号)和目标进程的 PID,然后系统内核根据收到的信号类型,对指定进程进行相应的操作。
kill 命令的基本格式如下:
[root@localhost ~]# kill [信号] PID
kill 命令是按照 PID 来确定进程的,所以 kill 命令只能识别 PID,而不能识别进程名。Linux 定义了几十种不同类型的信号,读者可以使用 kill -l 命令查看所有信号及其编号,这里仅列出几个常用的信号,如表 1 所示。
| 信号编号 | 信号名 | 含义 |
|---|---|---|
| 0 | EXIT | 程序退出时收到该信息。 |
| 1 | HUP | 挂掉电话线或终端连接的挂起信号,这个信号也会造成某些进程在没有终止的情况下重新初始化。 |
| 2 | INT | 表示结束进程,但并不是强制性的,常用的 “Ctrl+C” 组合键发出就是一个 kill -2 的信号。 |
| 3 | QUIT | 退出。 |
| 9 | KILL | 杀死进程,即强制结束进程。 |
| 11 | SEGV | 段错误。 |
| 15 | TERM | 正常结束进程,是 kill 命令的默认信号。 |
KillAll
killall 也是用于关闭进程的一个命令,但和 kill 不同的是,killall 命令不再依靠 PID 来杀死单个进程,而是通过程序的进程名来杀死一类进程,也正是由于这一点,该命令常与 ps等命令配合使用。
killall 命令的基本格式如下:
[root@localhost ~]# killall [选项] [信号] 进程名
注意,此命令的信号类型同 kill 命令一样