一、常用存储引擎分类
1.1 ReplacingMergeTree
这个引擎是在 MergeTree 的基础上,添加了”处理重复数据”的功能,该引擎和MergeTree的不同之处在于它会删除具有相同主键的重复项。
特点:
1使用ORDERBY排序键作为判断重复的唯一键
2.数据的去重只会在合并的过程中触发
3.以数据分区为单位删除重复数据,不同分区的的重复数据不会被删除
4找到重复数据的方式依赖数据已经ORDER BY排好序了
5.如果没有ver版本号,则保留重复数据的最后一行
6.如果设置了ver版本号,则保留重复数据中ver版本号最大的数据
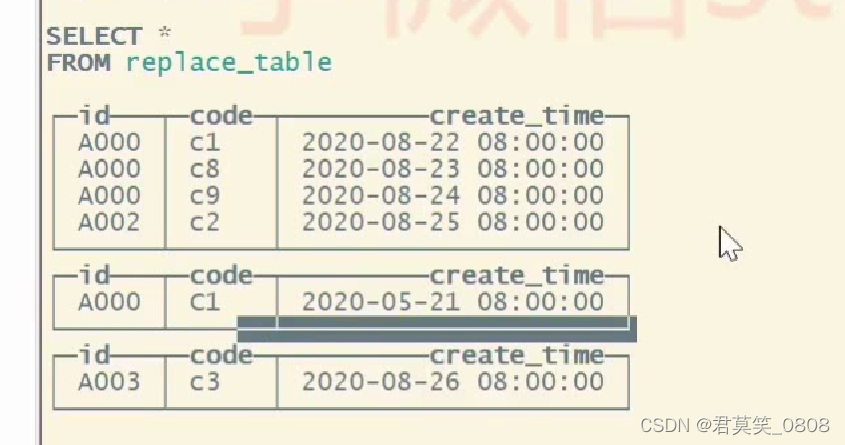
1.2 建表语句示例
create table replace_table(
id string,
code String,
create_time DateTime
)ENGINE=RepTacingMergeTree() PARTITION BY toYYYYMM(create_time)ORDER BY (id,code) PRIMARY KEY id;
order by 数据做主键,进行数据去重,但是不同分区数据不会去重
1.2 SummingMergeTree
该引擎继承自 MergeTree。区别在于,当合并 SummingMergeTree 表的数据片段时,ClickHouse 会把所有有相同聚合数据的条件Key的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值。如果聚合数据的条件Key的组合方式使得单个键值对应于大量的行,则可以显著的减少存储空间并加快数据查询的速度,对于不可加的列,会取一个最先出现的值。
特征:
1用DRDERBY排序键作为聚合数据的条件Key
2合并分区的时候触发汇总逻辑
3.以数据分区为单位聚合数据,不同分区的数据不会被汇总
4如果在定义引擎时指定了Columns汇总列(非主键)则SUM汇总这些字段
5.如果没有指定,则汇总所有非主键的数值类型字段
6.SUM汇总相同的聚合Key的数据,依赖ORDER BY排序
7.同一分区的SUM汇总过程中,非汇总字段的数据保留第一行取值8.支持嵌套结构,但列字段名称必须以Map后缀结束。
1.3 AggregateMergeTree
说明: 逻辑。 clickHouse 会将相同主键的所有行(在一个数据片该引擎继承自 MergeTree,并改变了数据片段的合并段内)替换为单个存储一系列聚合函数状态的行。
可以使用AggregatingMergeTree 表来做增量数据计聚合,包括物化视图的数据聚合引擎需使用AggregateFunction 类型来处理所有列
如果要按一组规则来合并减少行数,则使用AggregaingMergeTree 是合适的对于AggregatingMergeTree不能直接使用insert来查询写入数据。一般是用insert select。但更常用的是创建物化视图。
提前聚合数据,形成数据立方体,数据提前预处理聚合。
1.3.1 先创建一个MergeTree引擎的基表

1.3.2 创建一个AggregatingMergeTree的物化视图

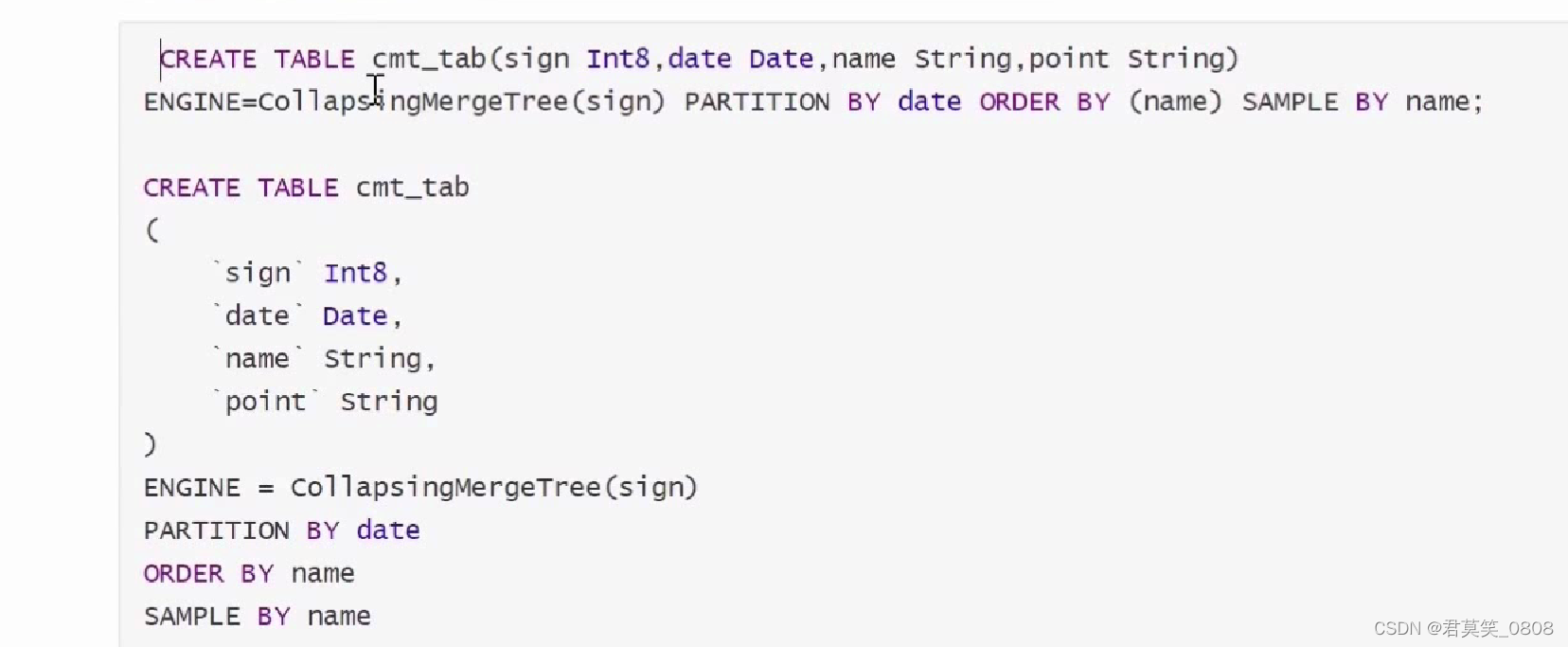
1.4 CollapsingMergeTree
以增代删
yandex官方给出的介绍是CollapsingMergeTree 会异步的除(折叠)这些除了特定列 ign有1和-1的值外,其余所有字段的值都相等的成对的行。没有成对的行会被保留。该引擎可以显著的降低存储量并提高 SELEC查询效率。
CollapsingMergeTree引擎有个状态列sign,这个值1为”状态”行,1为”取消”行,对于数据只关心状态列为状的数据,不关心状态列为取消的数据。
1.5 VersionedCollapsingMergeTree
这个引擎和collapsingMergeTree差不多,只是对collapsingMergeTree引擎加了一个版本,比如可以适于非实时用户在线统计,统计每个节点用户在在线业务
CREATE TABLE [IF NOT EXISTS] [db,jtable_name [ON CLUSTER cluster]
name1 [type1][DEFAULTIMATERIALIZEDIALIAS expr1].name2 [type2][DEFAULTIMATERIALIZEDALIAS expr2]
ENGINE = VersionedCollapsingMergeTree(sign, version)IPARTITION BY expr)
[ORDER BY expr][SAMPLE BY expr]
[SETTINGS name=value, ...]
二、clickhouse 连接其他存储引擎
2.1 连接mysql
mysql建表语句

2.2 连接kafka
Kafka SETTINGS
kafka_broker_list = 'localhost:9092',
kafka_topic_list ='topic1,topic2',
kafka_group_name ='group1',
kafka format = 'JSONEachRow',
kafka_row_delimiter = '\n'
kafka_schema = '',
kafka num_consumers = 2
kafka引擎表写入后会删除,需要建一个物化视图
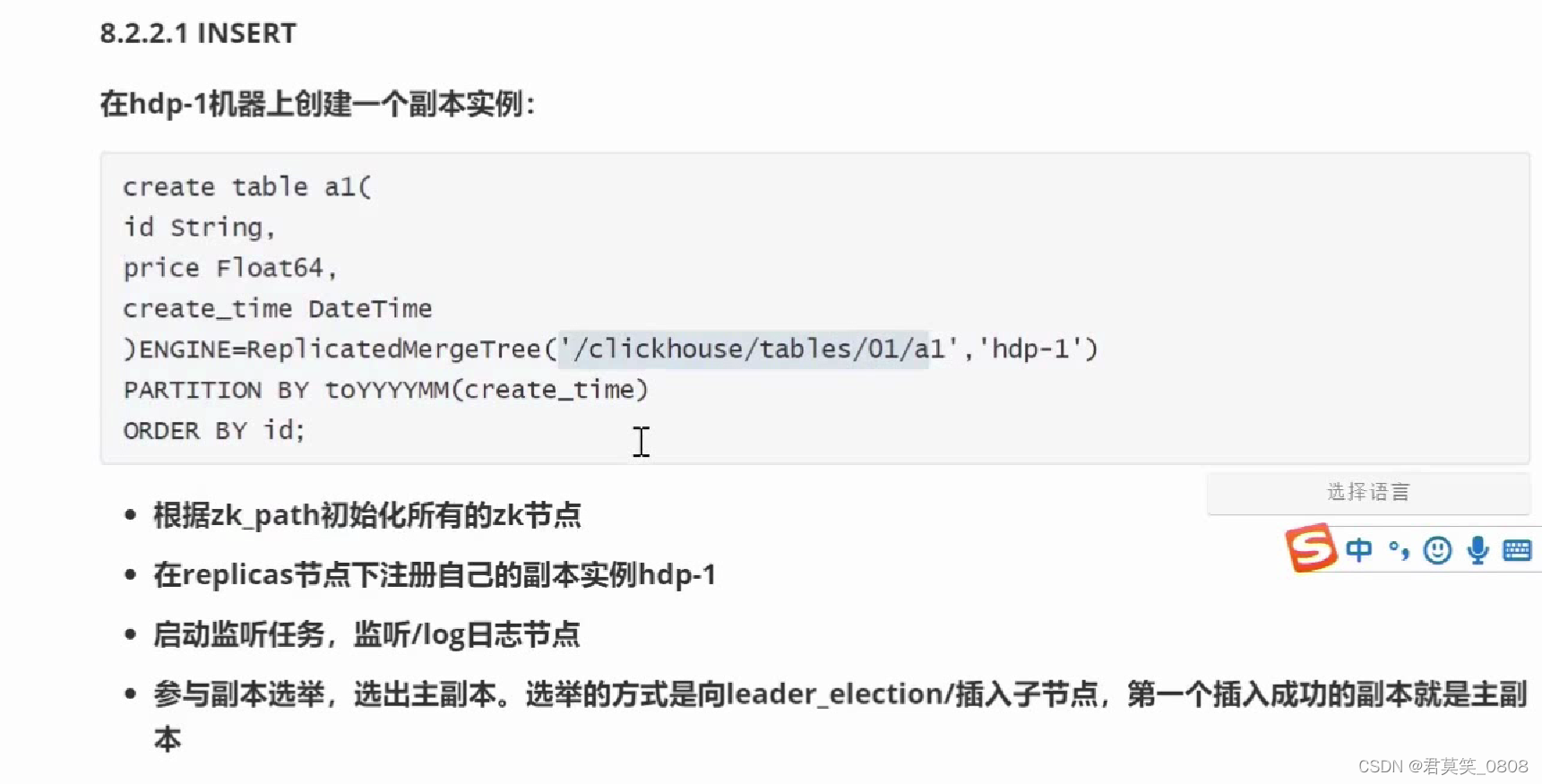
三、数据备份
分区写入数据后,写入数据记录到zk节点,被其他副本消费

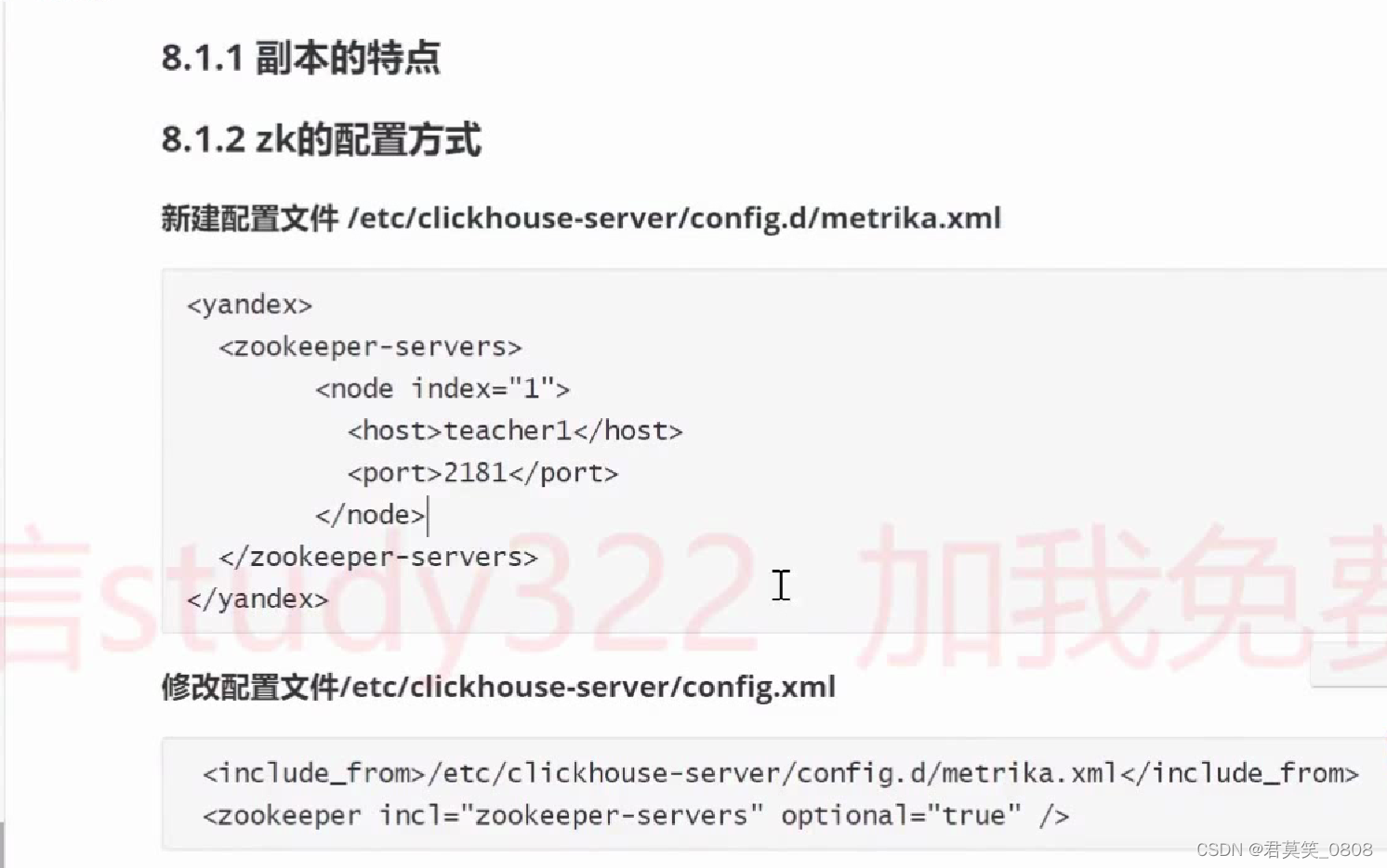

zk节点信息





四、分布式表










![[疑难杂症2023-007]multiprocessing.Process使用时遇到的几个棘手问题](https://img-blog.csdnimg.cn/0efc5d98bff942a3893457eaa5cf50a8.png)



