本文由Markdown编辑器编辑完成。
1. 背景
近日,为了解决自己负责的一个组件,在处理大量数据时,由于内存释放不及时,而导致整个组件占用了较高的内存。
这主要是因为目前我们在使用python的一个采用多进程的框架——Celery.
关于Celery的基本用法,我会在后面专门写一篇文章介绍。
由于Celery,是在设置了总的并发量的基础上,动态的创建和回收进程。有一个参数是:worker_max_tasks_per_child, 是为了设置子进程每运行多少个任务,这个子进程就会被系统回收,释放它所占的内存资源,然后再重新perfork出一个新的子进程,来继续处理任务。
当这个参数设置为1时,其实就是每执行一个任务,就回收进程,释放内存。
我所遇到的应用场景时,部分数据需要立刻释放,部分数据,可以相对将这个参数worker_max_tasks_per_child,设置得大一些。
因此,我想到了,那还不如,直接使用multiprocessing.Process(), 来解决这个问题。
因此,线上运行的基本代码,类似:
from multiprocessing import Process
......
if conditionA:
Process(target=funcA, args=(m,n)).start()
else:
Celery_task.apply_async()
这样,就可以根据实际的情况,如果是想让程序每跑一个任务,就回收进程和释放内存,就可以走第一个if分支;如果是可以允许多运行一些任务,不要那么频繁的回收和创建子进程,就可以走else分支。
本来以为,这是一个很简单的改动,但当真正测试时,却发现了很多意想不到的问题。
问题如下:
同样的一个任务,如果运用celery的子进程跑,就可以顺利运行完毕。但是用Process().start()运行,任务在运行过程中就会中止。而且,并不会发生任何的报错。即可加try…except块包起来,也没有任何的异常抛出。
2. 解决方案
为了解决Process()内部的进程,执行任务时中断的问题,开始进行逐行debug。后来在debug的过程中,发现了几个问题,同时也向chatgpt寻求帮助,得到了一些回复。这里记录一下。
2.1 importlib的调用位置
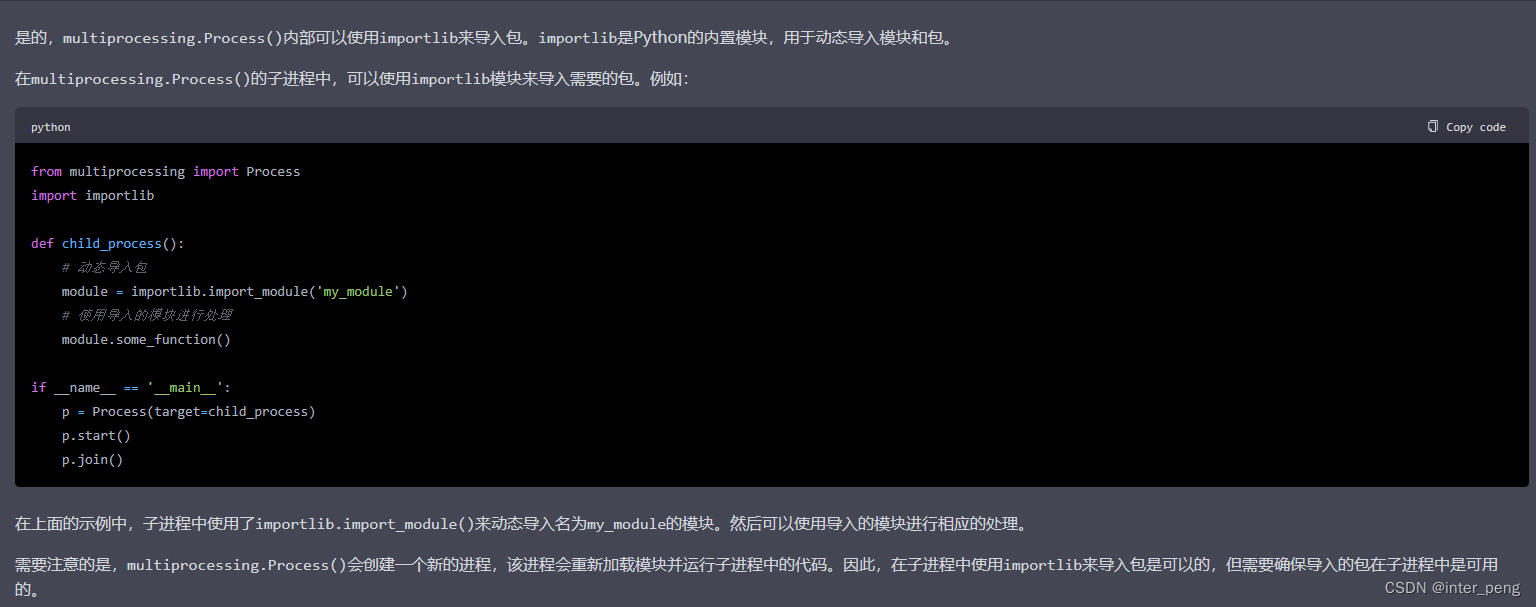
首先发现的问题是,多进程从celery切换到Process()时,importlib的使用,会导致程序处理被中断。
importlib, 主要是为了能够动态地导入一些包。因为需要导入的包的名称,可能需要根据函数传入的参数来决定。
debug过程中发现,如果是在Process()的外部,导入相应的包时,可能导致处理中断。而,如果是在Process()的target函数内部,再import相应的模块,则可以正常的工作。
2.2 与pytorch的兼容问题
使用Process(), 还有可能在使用到pytorch的地方卡住。
因为,有时候为了调用深度学习模型的一些算法,会将算法封装成一个package,来供子进程的任务调用。
通过一些查询,chatgpt给出的一些解释如下:
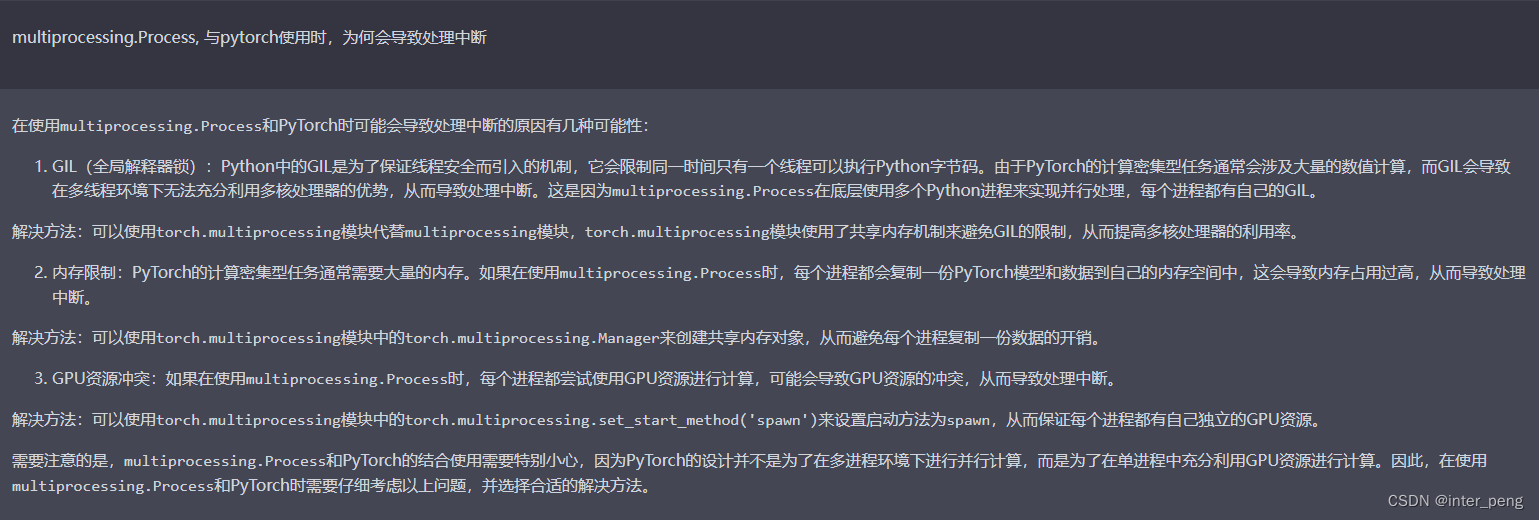
对于以上提到的,与pytorch的兼容问题,前两个推荐的解决方案,是将引入multiprocessing.Process()的地方,修改为引入:
torch.multiprocessing来代替。因为这个torch中的multiprocessing, 通过共享内存的方式,已经解决了:python的GIL锁,和不同进程各自复制一份数据时,内存占用过大的问题;
第3个方案,则是在启用多进程的时候,设置一下调用的方法:
torch.multiprocessing.set_start_method('spawn')
这样可以保证每个进程,都会拥有独立的GPU资源。
以上,是这段时间,因为想当然的使用多进程中的Process()时,与原来的代码的一些兼容问题。
为了定位和解决这些问题,也耗费了挺长的时间。
看来,为了如果对于某些东西,一知半解时,最好不要贸然使用。否则,有可能处理它引发的问题的时间,都大于了它带来的收益。因此,必须知己知彼,方能百战不殆。