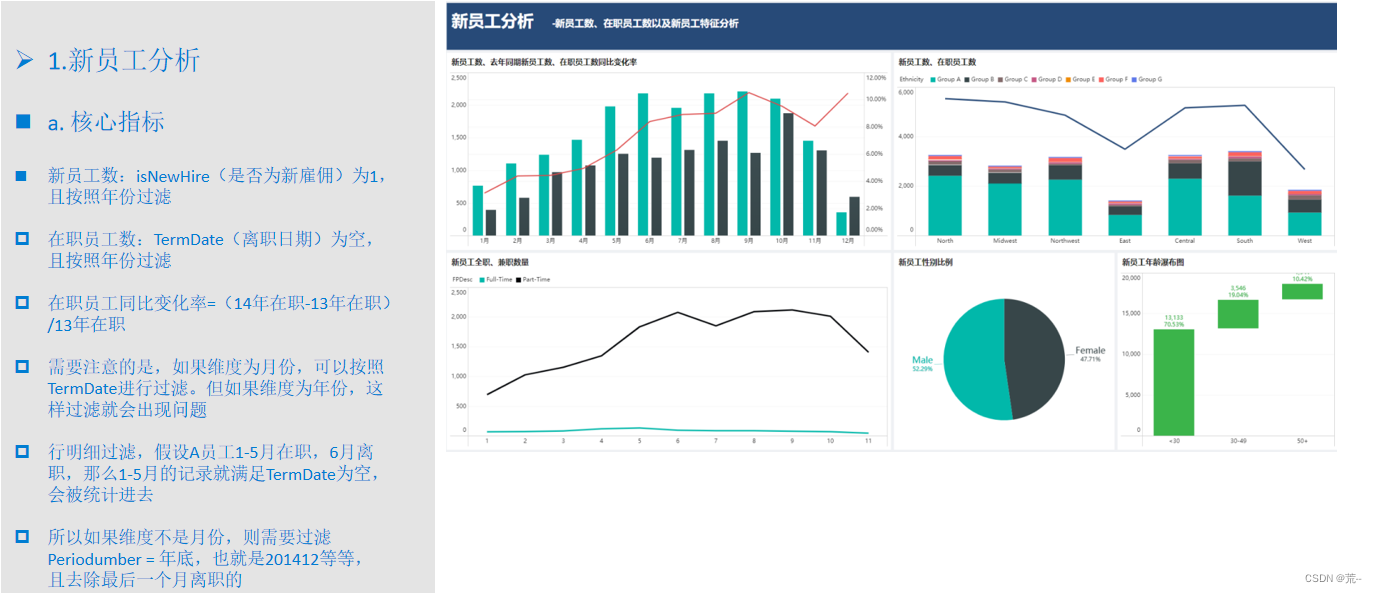
一、Scrapy框架简介
Scrapy 是一个开源的 Python 库和框架,用于从网站上提取数据。它为自从网站爬取数据而设计,也可以用于数据挖掘和信息处理。Scrapy 可以从互联网上自动爬取数据,并将其存储在本地或在 Internet 上进行处理。Scrapy 的目标是提供更简单、更快速、更强大的方式来从网站上提取数据。

二、Scrapy的基本构成
Scrapy 框架由以下五个主要组件构成:
1. Spiders:它是 Scrapy 框架的核心部分,主要用于定义从网站上提取数据的方式。Spider 是一个 Python 类,它定义了如何从特定的网站抓取数据。
2. Items:它用于定义爬取的数据结构,Scrapy 将在爬取过程中自动创建 Item 对象,它们将被进一步处理,例如存储到数据库中。
3. Item Pipeline:它是 Scrapy 框架用于处理 Item 对象的机制。它可以执行诸如数据清洗、验证和存储等操作。
4. Downloader:它是 Scrapy 框架用于下载页面的组件之一。它正在处理网络请求,从互联网上下载页面并将其回传到 Spider 中。
5. Middleware:它是 Scrapy 框架用于处理 Spider、Downloader 和 Item Pipeline 之间交互的组件之一。中间件在这个架构中扮演了一个交换件角色,可以添加、修改或删除请求、响应和 Item 对象。
三、Scrapy框架的运行流程
Scrapy 的运行流程可以分为以下几步:
1. 下载调度器:Scrapy 框架接收 URL 并将其传递给下载调度器。下载调度器负责队列管理和针对每个 URL 的下载请求的优先级。它还可以控制并发请求的总数,从而避免对服务器的过度负载。
2. 下载器:下载器使用 HTTP 请求从互联网上下载 HTML 或其他类型的页面内容。下载器可以通过中间件拦截处理、修改或过滤请求和响应。下载器还可以将下载的数据逐步传递到爬虫中。
3. 爬虫:Spider 接收下载器提供的页面数据,并从中提取有用的信息。Spider 可以通过规则来定义如何从页面中提取数据。Spider 可以将提取的数据传递给 Item Pipeline 进行处理。
4. Item Pipeline:Item Pipeline 进行数据的清洗、验证和存储等操作。它还可以将数据存储到数据库、JSON 或 CSV 文件中。
5. 输出:Scrapy 可以输出爬取的数据到命令行、文件或 JSON 格式。输出可以用于生成各种类型的报告或分析。
四、Scrapy框架的使用
下面我们将介绍如何使用 Scrapy 框架。
1. 安装 Scrapy
Scrapy 框架可以通过 pip 安装。使用以下命令安装 Scrapy:
pip install scrapy
2. 创建 Scrapy 项目
使用以下命令创建 Scrapy 项目:
scrapy startproject project_name
其中,project_name 是项目的名称。
3. 创建 Spider
使用以下命令创建 Spider:
scrapy genspider spider_name domain_name其中,spider_name 是 Spider 的名称,domain_name 是要爬取的域名。
在 Spider 中,我们可以定义如何从网站上提取数据。下面是一个简单的 Spider 的示例:
import scrapy
class MySpider(scrapy.Spider):
name = 'myspider'
start_urls = ['http://www.example.com']
def parse(self, response):
# 提取数据的代码
pass在这个示例中,我们定义了一个 Spider,并指定了它的名称和要爬取的 URL。我们还实现了一个 parse 方法,用于提取页面上的数据。
4. 创建 Item
在 Scrapy 中,我们可以定义自己的数据结构,称为 Item。我们可以使用 Item 类来定义数据结构。下面是一个 Item 的示例:
import scrapy
class MyItem(scrapy.Item):
title = scrapy.Field()
author = scrapy.Field()
content = scrapy.Field()在这个示例中,我们定义了一个 Item,并定义了三个字段:title、author 和 content。
5. 创建 Item Pipeline
在 Scrapy 中,我们可以定义 Item Pipeline 来处理 Item 对象。Item Pipeline 可以执行以下操作:
- 清洗 Item 数据
- 验证 Item 数据
- 存储 Item 数据
下面是一个简单的 Item Pipeline 的示例:
class MyItemPipeline(object):
def process_item(self, item, spider):
# 处理 Item 的代码
return item
在这个示例中,我们定义了一个 Item Pipeline,并实现了 process_item 方法。
6. 配置 Scrapy
Scrapy 有几个重要的配置选项。其中,最常见的是 settings.py 文件中的选项。下面是一个 settings.py 文件的示例:
BOT_NAME = 'mybot'
SPIDER_MODULES = ['mybot.spiders']
NEWSPIDER_MODULE = 'mybot.spiders'
ROBOTSTXT_OBEY = True
DOWNLOADER_MIDDLEWARES = {
'mybot.middlewares.MyCustomDownloaderMiddleware': 543,
}
ITEM_PIPELINES = {
'mybot.pipelines.MyCustomItemPipeline': 300,
}
在这个示例中,我们定义了一些重要的选项,包括 BOT_NAME、SPIDER_MODULES、NEWSPIDER_MODULE、ROBOTSTXT_OBEY、DOWNLOADER_MIDDLEWARES 和 ITEM_PIPELINES。
7. 运行 Scrapy
使用以下命令运行 Scrapy:
scrapy crawl spider_name
其中,spider_name 是要运行的 Spider 的名称。
五、Scrapy框架的案例
下面我们来实现一个简单的 Scrapy 框架的案例。
1. 创建 Scrapy 项目
使用以下命令创建 Scrapy 项目:
scrapy startproject quotes我们将项目名称设置为 quotes。
2. 创建 Spider
使用以下命令创建 Spider:
scrapy genspider quotes_spider quotes.toscrape.com其中,quotes_spider 是 Spider 的名称,quotes.toscrape.com 是要爬取的域名。
在 Spider 中,我们定义如何从网站上提取数据。下面是一个 quotes_spider.py 文件的示例:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('span small::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
next_page = response.css('li.next a::attr(href)').get()
if next_page is not None:
yield response.follow(next_page, self.parse)在这个示例中,我们定义了一个 Spider,并指定了它的名称。我们还实现了 start_requests 方法,用于定义要爬取的 URL。我们还实现了一个 parse 方法,用于提取页面上的所有引用。我们使用 response.css 方法选择要提取的元素,并使用 yield 语句返回一个字典对象。
3. 运行 Spider
使用以下命令运行 Spider:
scrapy crawl quotes这个示例将下载 quotes.toscrape.com 网站上的页面,并从中提取所有引用。它将引用的文本、作者和标签存储到 MongoDB 数据库中。
六、总结
Scrapy 是一个功能强大的 Python 库和框架,用于从网站上提取数据。它为自从网站爬取数据而设计,也可以用于数据挖掘和信息处理。Scrapy 的目标是提供更简单、更快速、更强大的方式来从网站上提取数据。Scrapy 框架由 Spiders、Items、Item Pipeline、Downloader 和 Middleware 等组件构成,并具有可定制和可扩展性强的特性。使用 Scrapy 框架可以大大减少开发人员在网络爬虫开发中的时间和精力,是一个非常优秀的爬虫框架。



![[Docker实现测试部署CI/CD----构建成功后钉钉告警(7)]](https://img-blog.csdnimg.cn/2bf429bc95e34e34b7d4a7eee2ff5844.png)