一、ChatYuan-large-v2
ChatYuan-large-v2是一个开源的支持中英双语的功能型对话语言大模型,与其他 LLM 不同的是模型十分轻量化,并且在轻量化的同时效果相对还不错,仅仅通过0.7B参数量就可以实现10B模型的基础效果,正是其如此的轻量级,使其可以在普通显卡、 CPU、甚至手机上进行推理,而且 INT4 量化后的最低只需 400M 。
v2 版本相对于以前的 v1 版本,是使用了相同的技术方案,但在指令微调、人类反馈强化学习、思维链等方面进行了优化。
在本专栏前面文章介绍了 ChatYuan-large-v2 和 langchain 相结合的使用,地址如下:
LangChain 本地化方案 - 使用 ChatYuan-large-v2 作为 LLM 大语言模型
本篇文章以 ChatYuan-large-v2 模型为基础 Fine-tuning 广告生成 任务。
二、数据集处理
数据集这里使用 ChatGLM 官方在 Fine-tuning 中使用到的 广告生成 数据集。
下载地址如下:
https://drive.google.com/file/d/13_vf0xRTQsyneRKdD1bZIr93vBGOczrk/view
数据已 JSON 的形式存放,分为了 train 和 dev 两种类型:

数据格式如下所示:
{
"content":"类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤",
"summary":"宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"
}
{
"content":"类型#裤*版型#宽松*风格#性感*图案#线条*裤型#阔腿裤",
"summary":"宽松的阔腿裤这两年真的吸粉不少,明星时尚达人的心头爱。毕竟好穿时尚,谁都能穿出腿长2米的效果宽松的裤腿,当然是遮肉小能手啊。上身随性自然不拘束,面料亲肤舒适贴身体验感棒棒哒。系带部分增加设计看点,还让单品的设计感更强。腿部线条若隐若现的,性感撩人。颜色敲温柔的,与裤子本身所呈现的风格有点反差萌。"
}
{
"content":"类型#裙*风格#简约*图案#条纹*图案#线条*图案#撞色*裙型#鱼尾裙*裙袖长#无袖",
"summary":"圆形领口修饰脖颈线条,适合各种脸型,耐看有气质。无袖设计,尤显清凉,简约横条纹装饰,使得整身人鱼造型更为生动立体。加之撞色的鱼尾下摆,深邃富有诗意。收腰包臀,修饰女性身体曲线,结合别出心裁的鱼尾裙摆设计,勾勒出自然流畅的身体轮廓,展现了婀娜多姿的迷人姿态。"
}
{
"content":"类型#上衣*版型#宽松*颜色#粉红色*图案#字母*图案#文字*图案#线条*衣样式#卫衣*衣款式#不规则",
"summary":"宽松的卫衣版型包裹着整个身材,宽大的衣身与身材形成鲜明的对比描绘出纤瘦的身形。下摆与袖口的不规则剪裁设计,彰显出时尚前卫的形态。被剪裁过的样式呈现出布条状自然地垂坠下来,别具有一番设计感。线条分明的字母样式有着花式的外观,棱角分明加上具有少女元气的枣红色十分有年轻活力感。粉红色的衣身把肌肤衬托得很白嫩又健康。"
}
{
"content":"类型#裙*版型#宽松*材质#雪纺*风格#清新*裙型#a字*裙长#连衣裙",
"summary":"踩着轻盈的步伐享受在午后的和煦风中,让放松与惬意感为你免去一身的压力与束缚,仿佛要将灵魂也寄托在随风摇曳的雪纺连衣裙上,吐露出<UNK>微妙而又浪漫的清新之意。宽松的a字版型除了能够带来足够的空间,也能以上窄下宽的方式强化立体层次,携带出自然优雅的曼妙体验。"
}
{
"content":"类型#上衣*材质#棉*颜色#蓝色*风格#潮*衣样式#polo*衣领型#polo领*衣袖长#短袖*衣款式#拼接",
"summary":"想要在人群中脱颖而出吗?那么最适合您的莫过于这款polo衫短袖,采用了经典的polo领口和柔软纯棉面料,让您紧跟时尚潮流。再配合上潮流的蓝色拼接设计,使您的风格更加出众。就算单从选料上来说,这款polo衫的颜色沉稳经典,是这个季度十分受大众喜爱的风格了,而且兼具舒适感和时尚感。"
}
其中任务的方式为根据输入(content)生成一段广告词(summary)。
train.json 共有 114599 条记录,这里为了演示效果取前 50000 条数据进行训练、5000 条数据进行验证:
import os
# 将训练集进行提取
def doHandle(json_path, train_size, val_size, out_json_path):
train_count = 0
val_count = 0
train_f = open(os.path.join(out_json_path, "train.json"), "a", encoding='utf-8')
val_f = open(os.path.join(out_json_path, "val.json"), "a", encoding='utf-8')
with open(json_path, "r", encoding='utf-8') as f:
for line in f:
if train_count < train_size:
train_f.writelines(line)
train_count = train_count + 1
elif val_count < val_size:
val_f.writelines(line)
val_count = val_count + 1
else:
break
print("数据处理完毕!")
train_f.close()
val_f.close()
if __name__ == '__main__':
json_path = "./data/AdvertiseGen/train.json"
out_json_path = "./data/"
train_size = 50000
val_size = 5000
doHandle(json_path, train_size, val_size, out_json_path)
处理之后可以看到两个生成的文件:

下面基于上面的数据格式构建 Dataset :
from torch.utils.data import Dataset, DataLoader, RandomSampler, SequentialSampler
import torch
import json
class SummaryDataSet(Dataset):
def __init__(self, json_path: str, tokenizer, max_length=300):
self.tokenizer = tokenizer
self.max_length = max_length
self.content_data = []
self.summary_data = []
with open(json_path, "r", encoding='utf-8') as f:
for line in f:
if not line or line == "":
continue
json_line = json.loads(line)
content = json_line["content"]
summary = json_line["summary"]
self.content_data.append(content)
self.summary_data.append(summary)
print("data load , size:", len(self.content_data))
def __len__(self):
return len(self.content_data)
def __getitem__(self, index):
source_text = str(self.content_data[index])
target_text = str(self.summary_data[index])
source = self.tokenizer.batch_encode_plus(
[source_text],
max_length=self.max_length,
pad_to_max_length=True,
truncation=True,
padding="max_length",
return_tensors="pt",
)
target = self.tokenizer.batch_encode_plus(
[target_text],
max_length=self.max_length,
pad_to_max_length=True,
truncation=True,
padding="max_length",
return_tensors="pt",
)
source_ids = source["input_ids"].squeeze()
source_mask = source["attention_mask"].squeeze()
target_ids = target["input_ids"].squeeze()
target_mask = target["attention_mask"].squeeze()
return {
"source_ids": source_ids.to(dtype=torch.long),
"source_mask": source_mask.to(dtype=torch.long),
"target_ids": target_ids.to(dtype=torch.long),
"target_ids_y": target_ids.to(dtype=torch.long),
}
三、模型训练
下载 ChatYuan-large-v2 模型:
https://huggingface.co/ClueAI/ChatYuan-large-v2/tree/main
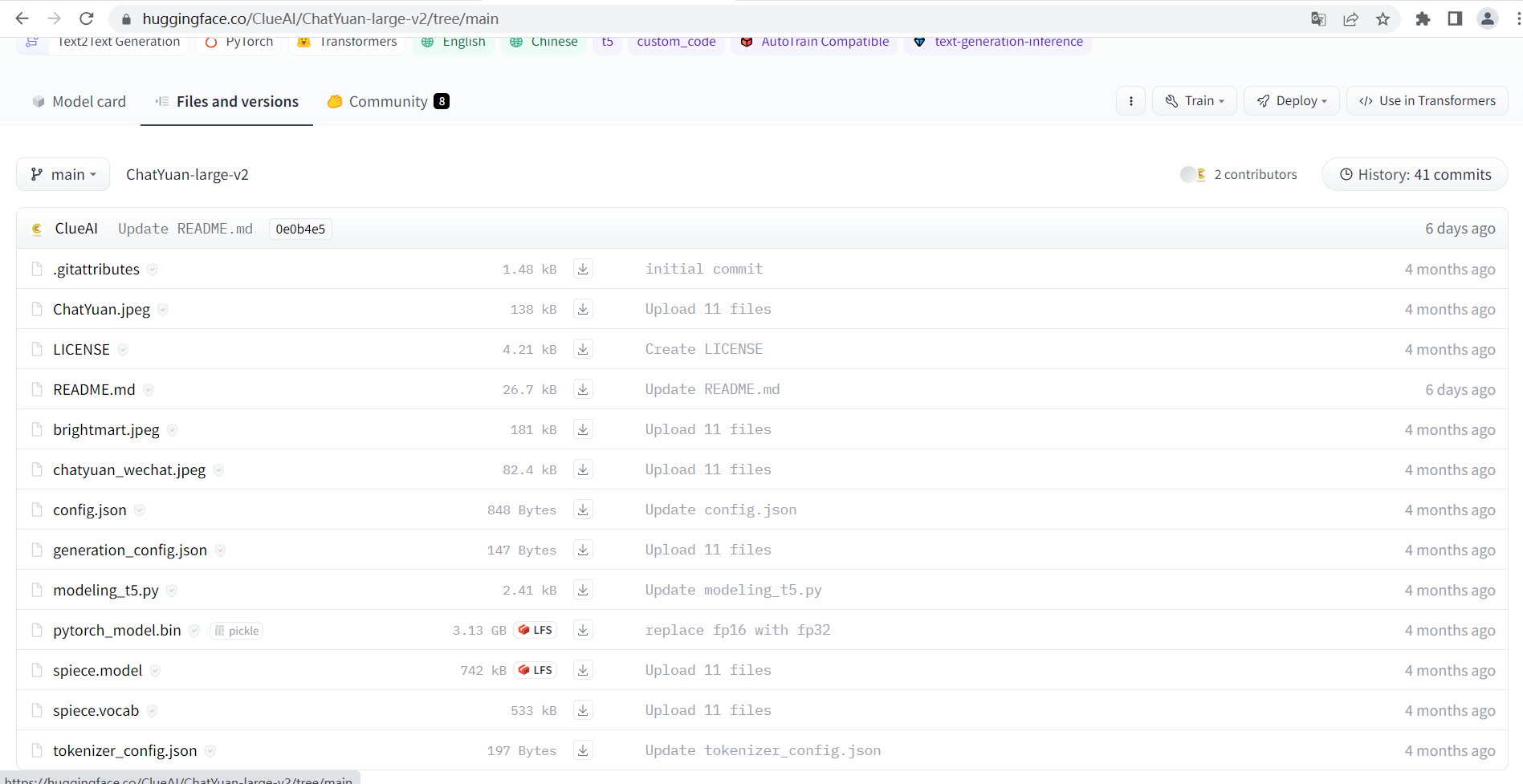
下面基于 ChatYuan-large-v2 进行训练:
import pandas as pd
import torch
from torch.utils.data import DataLoader
import os, time
from transformers import T5Tokenizer, T5ForConditionalGeneration
from gen_dataset import SummaryDataSet
def train(epoch, tokenizer, model, device, loader, optimizer):
model.train()
time1 = time.time()
for _, data in enumerate(loader, 0):
y = data["target_ids"].to(device, dtype=torch.long)
y_ids = y[:, :-1].contiguous()
lm_labels = y[:, 1:].clone().detach()
lm_labels[y[:, 1:] == tokenizer.pad_token_id] = -100
ids = data["source_ids"].to(device, dtype=torch.long)
mask = data["source_mask"].to(device, dtype=torch.long)
outputs = model(
input_ids=ids,
attention_mask=mask,
decoder_input_ids=y_ids,
labels=lm_labels,
)
loss = outputs[0]
# 每100步打印日志
if _ % 100 == 0 and _ != 0:
time2 = time.time()
print(_, "epoch:" + str(epoch) + "-loss:" + str(loss) + ";each step's time spent:" + str(
float(time2 - time1) / float(_ + 0.0001)))
optimizer.zero_grad()
loss.backward()
optimizer.step()
def validate(epoch, tokenizer, model, device, loader, max_length):
model.eval()
predictions = []
actuals = []
with torch.no_grad():
for _, data in enumerate(loader, 0):
y = data['target_ids'].to(device, dtype=torch.long)
ids = data['source_ids'].to(device, dtype=torch.long)
mask = data['source_mask'].to(device, dtype=torch.long)
generated_ids = model.generate(
input_ids=ids,
attention_mask=mask,
max_length=max_length,
num_beams=2,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
preds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g in
generated_ids]
target = [tokenizer.decode(t, skip_special_tokens=True, clean_up_tokenization_spaces=True) for t in y]
if _ % 1000 == 0:
print(f'Completed {_}')
predictions.extend(preds)
actuals.extend(target)
return predictions, actuals
def T5Trainer(train_json_path, val_json_path, model_dir, batch_size, epochs, output_dir, max_length=300):
tokenizer = T5Tokenizer.from_pretrained(model_dir)
model = T5ForConditionalGeneration.from_pretrained(model_dir)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device)
train_params = {
"batch_size": batch_size,
"shuffle": True,
"num_workers": 0,
}
training_set = SummaryDataSet(train_json_path, tokenizer, max_length=max_length)
training_loader = DataLoader(training_set, **train_params)
val_params = {
"batch_size": batch_size,
"shuffle": False,
"num_workers": 0,
}
val_set = SummaryDataSet(val_json_path, tokenizer, max_length=max_length)
val_loader = DataLoader(val_set, **val_params)
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-4)
for epoch in range(epochs):
train(epoch, tokenizer, model, device, training_loader, optimizer)
print("保存模型")
model.save_pretrained(output_dir)
tokenizer.save_pretrained(output_dir)
# 验证
with torch.no_grad():
predictions, actuals = validate(epoch, tokenizer, model, device, val_loader, max_length)
# 验证结果存储
final_df = pd.DataFrame({"Generated Text": predictions, "Actual Text": actuals})
final_df.to_csv(os.path.join(output_dir, "predictions.csv"))
if __name__ == '__main__':
train_json_path = "./data/train.json"
val_json_path = "./data/val.json"
# 下载模型目录位置
model_dir = "chatyuan_large_v2"
batch_size = 5
epochs = 1
max_length = 300
output_dir = "./model"
# 开始训练
T5Trainer(
train_json_path,
val_json_path,
model_dir,
batch_size,
epochs,
output_dir,
max_length
)
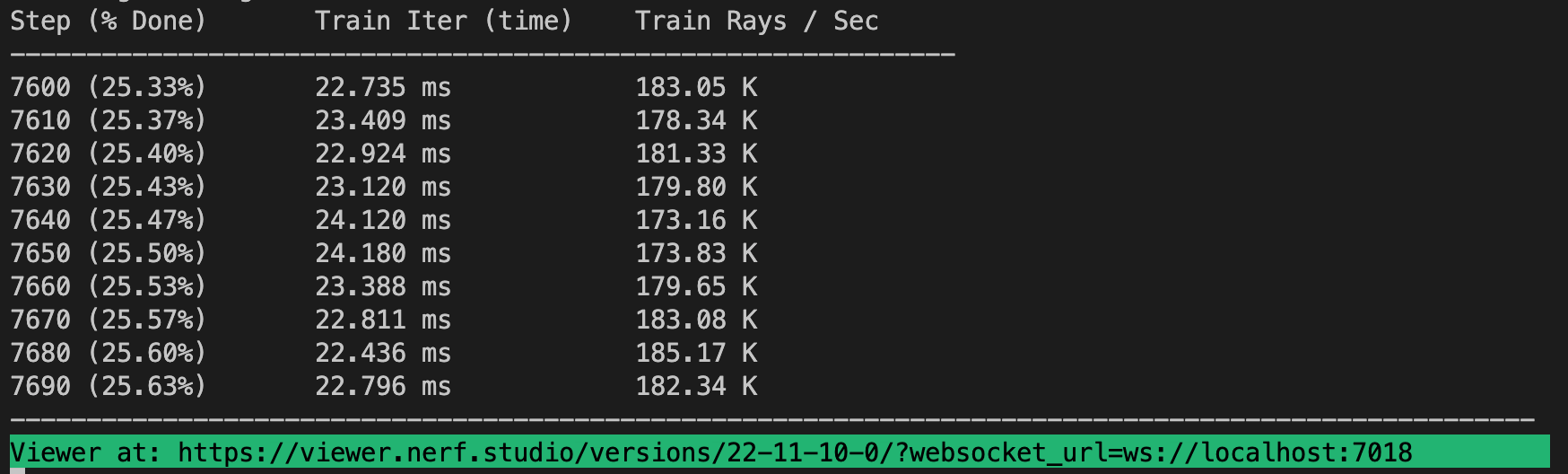
运行后可以看到如下日志打印,训练大概占用 33G 的显存,如果显存不够可以调低些 batch_size 的大小:

等待训练结束后:
可以在 model 下看到保存的模型:
这里可以先看下 predictions.csv 验证集的效果:

可以看到模型生成的结果有点不太好,这里仅对前 50000 条进行了训练,并且就训练了一个 epoch ,后面可以增加数据集大小和增加 epoch 应该能达到更好的效果,下面通过调用模型测试一下生成的文本效果。
四、模型测试
# -*- coding: utf-8 -*-
from transformers import T5Tokenizer, T5ForConditionalGeneration
import torch
# 这里是模型下载的位置
model_dir = './model'
tokenizer = T5Tokenizer.from_pretrained(model_dir)
model = T5ForConditionalGeneration.from_pretrained(model_dir)
while True:
text = input("请输入内容: \n ")
if not text or text == "":
continue
if text == "q":
break
encoded_input = tokenizer(text, padding="max_length", truncation=True, max_length=300)
input_ids = torch.tensor([encoded_input['input_ids']])
attention_mask = torch.tensor([encoded_input['attention_mask']])
generated_ids = model.generate(
input_ids=input_ids,
attention_mask=attention_mask,
max_length=300,
num_beams=2,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
reds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g in
generated_ids]
print(reds)
效果测试: