中文摘要
本文以学术研究为目的,针对新闻行业迫切需求和全文搜索引擎技术的优越性,设计并实现了一个针对新闻领域的全文搜索引擎。该搜索引擎通过Scrapy网络爬虫工具获取新闻页面,将新闻内容存储在分布式存储系统HBase中,并利用倒排索引及轮排索引等索引技术对新闻内容进行索引,实现了常用的新闻搜索功能,如短语查询、布尔查询、通配符查询等。同时为了获得更快的检索速度,该系统使用了B+树来构建索引树;为了提升用户浏览体验,引入了事件图谱可视化技术,帮助用户直观易懂地浏览相关新闻事件;为顺应搜索引擎个性化、智能化的发展趋势和给用户提供更符合其口味的新闻资讯, 实现了个性化新闻推荐功能。
关键词:HBase,B+树,事件图谱,个性化新闻推荐
目录
一、 绪论
(一) 研究背景
(二) 研究意义
(三) 主要研究内容
(四) 研究创新点
二、 关键技术与理论基础
(一) 全文搜索引擎的工作原理
(二) 网络爬虫技术
(三) 搜索引擎索引技术
(四) 分布式存储技术
(五) 分布式计算技术
(六) 分布式消息系统
(七) 事件图谱
(八) 推荐算法
三、 系统需求分析
(一) 功能性需求
(二) 特殊需求
四、 系统设计
(一) 系统功能模块设计
(二) 新闻检索功能设计
(三) 新闻推荐功能设计
五、 系统实现
(一) 开发环境及工具
(二) 搭建大数据平台
(三) 数据采集模块的实现
(四) 索引模块的实现
(五) 检索模块的实现
(六) 新闻事件图谱模块的实现
(七) 新闻特征学习模块的实现
(八) 用户行为日志收集模块的实现
(九) 新闻推荐模块的实现
(十) Web服务的实现
六、 系统测试
(一) 功能测试
(二) 性能测试
七、 总结与展望
参考文献
一、 绪论
(一) 研究背景
在当今数字化时代,人们获取新闻的方式已经发生了巨大变化,越来越多的人选择在网络上获取新闻信息。而对于新闻行业来说,如何快速、准确地将信息传达给读者,满足读者的信息需求,实现信息的有效发布和传播,已经成为了一个十分重要的问题。传统的新闻报道方式已经无法满足当今追求即时性和互动性的需求。并且,一些传统的新闻门户网站如新浪、中国新闻网等,由于信息量过于庞大,会给网民们带来寻找他们需要的信息的困难。此外,不同新闻网站对于某些事件的评价也各有不同,因此如果只看一个或两个网站的话,容易产生以偏概全的问题,随着网站数量不断增加,这种问题也日益突出。
在此背景下,新闻搜索引擎应运而生。通过搜索引擎的特性,不同网站对于相同内容的新闻报道可以被搜集整理后再呈现在网友的面前,为他们提供了便利的获取资讯的条件。新闻搜索引擎还可以成为记者的攻坚利器,为记者的采访提供大量的线索,为报道的成功提供坚实的基础,让记者们更好地挖掘事件背后的真相。
因此,新闻搜索引擎的开发背景是建立在解决这些问题和需求的基础之上的。除此之外,新闻搜索引擎的研究还涉及信息检索、自然语言处理、机器学习等多个领域,其发展也可以促进这些相关领域的发展。
(二) 研究意义
随着互联网的飞速发展,人们获取信息的途径也日益增多。而在这些途径中,全文搜索引擎被认为是最为广泛和方便的信息获取方式之一。而新闻行业对信息处理和获取的需求日益迫切,而全文搜索引擎提供了高效、精准的信息检索服务,是满足新闻行业需求的重要方式之一。因此,通过开发一个新闻搜索引擎,可以将搜索引擎技术应用到新闻行业中,推动新闻行业的信息化进程。
同时,搜索引擎相关技术也是应用广泛、前沿性强的技术之一,包括各种优化检索效果和用户体验的算法和数据结构,以及人工智能等前沿技术。因此,开发一个新闻搜索引擎不仅能够深入了解搜索引擎技术,还可以提升自身的技术水平。
本文选题就是出于以上两点,以学术研究为目的,选取新闻领域作为研究对象,旨在探究如何将搜索引擎技术应用到新闻行业中并且优化用户体验。
(三) 主要研究内容
本文主要完成了基于Java的新闻全文搜索引擎的系统设计和开发工作,主要包括以下几点内容:
(1)基于Linux系统的分布式生产环境的搭建,包括Hadoop、Spark、HBase、Kafka、Zookeeper等大数据开源软件的部署和配置。
(2)使用Scrapy实现新闻网页的抓取,通过XPath精准获取新闻网页的各个字段,构建结构化的新闻语料库,写入分布式数据库HBase。
(3)利用倒排索引及轮排索引等索引技术对新闻语料库里的新闻内容文本进行索引,实现了常用的新闻检索功能,如短语查询、布尔查询、通配符查询等。同时为了获得更快的检索速度,使用了 B+树来构建索引树。
(4)引入了事件图谱可视化技术,为新闻语料库中的每一篇新闻文本都构造了事件图谱,将得到的新闻事件图谱的JSON数据存储到HBase中,由Web应用根据用户的选择以图谱化的形式渲染出来。
(5)对新闻语料库里的新闻内容文本进行清洗、预处理。使用Spark对新闻内容文本进行挖掘,使用LDA主题模型获取新闻的主题分布向量作为新闻的特征表示。
(6)在前台使用JavaScript脚本监控用户的浏览行为,将用户的点击行为日志收集到系统后台后,使用Spark Streaming实时分析用户点击行为日志,对用户兴趣进行建模,得到用户对新闻的偏好特征。
(7)对于待推荐新闻集合中的每一条新闻,结合新闻特征和用户偏好特征使用余弦距离来计算它们的推荐评分。然后按照推荐评分对可能引起用户兴趣的新闻进行排序,并推荐给用户。
(8)为用户提供Web服务:包括搜索主页、登录注册页面、新闻推荐页面、新闻事件图谱可视化页面。
(四) 研究创新点
本系统的创新点在于引入了事件图谱技术,提升了用户的浏览体验。事件图谱通常被应用于情报分析、社交媒体分析和金融市场分析等领域。在搜索引擎中,事件图谱通常被用于提高搜索结果和推荐结果的精确度。这可以帮助用户更快地找到他们想要的信息,获得更好的检索结果。然而,在检索结果的可视化方面,该技术的使用却并不是很多。因此,本系统引入了事件图谱可视化技术,将新闻中的各关键点以及关键点之间的关联都展现在图谱中,以此提供图谱化的浏览方式。引入了事件图谱可视化技术的新闻搜索引擎具有以下优点: (1)多维度展示:通过将与新闻事件相关联的不同信息以图谱的形式展示,用户可以一目了然地了解事件关系的多个维度。 (2)直观易懂:事件图谱可视化可以帮助用户更好地理解和快速浏览相关新闻事件。
二、 关键技术与理论基础
(一) 全文搜索引擎的工作原理
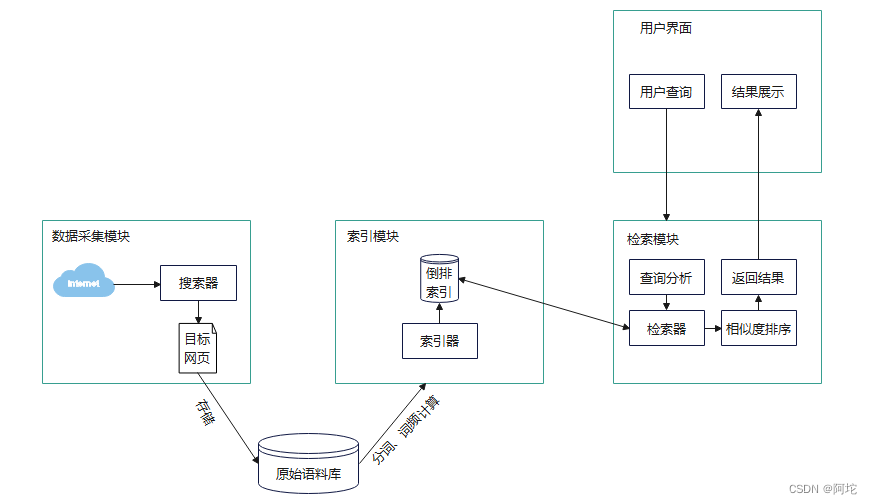
由上图可知,全文搜索引擎程序可以化分为数据采集模块、索引模块、检索模块以及用户界面。全文搜索引擎程序的组成结构具体如下:
| 组成结构 | 功能 |
|---|---|
| 数据采集模块 | 即网络爬虫程序,它的主要任务是从因特网上搜集各式各样的信息资源,并存到原始语料库里,为日后的用户检索做准备。 |
| 索引模块 | 把原始语料库里的信息提取出来,进行分析和建立索引,并进行简单的排列,把结果放在存储系统里,生成倒排索引文件。 |
| 检索模块 | 当用户进行检索的时候,检索模块会通过判断用户输入的请求,在倒排索引文件中进行查找,将查找到的结果,根据匹配度、优先度等指标进行最终排序,以提供给用户最优质的结果。 |
| 用户界面 | 是用户与搜索引擎进行人机交互的界面,不仅可用于输入用户的需求,也可用于返回搜索结果供用户选择。 |
(二) 网络爬虫技术
网络爬虫技术是一种信息自动采集程序,主要用于高效下载网页信息并采集数据,以提高搜索引擎的效率。在众多开源爬虫技术中,Apache软件基金会提供的Nutch分布式爬虫框架和基于Python语言的Scrapy爬虫框架等最为流行。其中,Nutch包含爬虫 crawler 和查询 searcher 两个组成部分,前者负责抓取网页和建立索引,后者用这些索引产生查找结果。同时,Nutch还支持分布式抓取,运行在Hadoop平台上,并具有强大的插件机制。但是定制插件并不能修改爬虫的遍历算法、去重算法和爬取流程,因而 Nutch的灵活性不高。
Scrapy 是一个基于 Python 语言的应用框架,专注于提供网站数据爬取和结构化数据提取功能。它便于实现网页内容和图片的抓取,用户只需定制开发几个相应的方法即可达成目的。这个框架在爬虫领域中用途非常广泛,可以帮助用户高效地采集所需数据。Scrapy是异步的,可同时在不同网页上爬行,并灵活调整并发量;在持久化存储方面,通过管道的方式存入数据库,可保存为多种形式。Scrapy本身不支持分布式爬虫,但Scrapy具有较强的扩展性,可通过扩展插件的方式实现分布式爬虫。
综上所述,Scrapy与Nutch两方面的对比如下:

(三) 搜索引擎索引技术
搜索引擎索引技术负责收集、解析和存储数据,以便于快速准确地检索信息。全文搜索引擎在设计之初一般都会对互联网中存在的所有文本文档创建全文索引。全文索引一般分为两种,正向索引与倒排索引。正向索引通过存储每个文档的单词列表构成索引结构,如下所示:
文档 ID:(单词 1,单词 2,…)。
正向索引在搜索引擎进行搜索时才会根据查询关键词在索引文档中逐次查找。这种索引结构虽然前期准备工作十分简单,但占用的搜索时间较长所以这种索引方式基本不被使用。倒排索引和正向索引相反,根据单词来索引文档编号,如下所示:
单词:(文档2,文档6,文档9,文档8,…)。
这种普通倒排索引结构只存储了词项和词项对应的文档ID列表之间的索引信息,因此它只可以实现判断词项是否存在于特定文档中的精确查询和完成多个查询词之前的布尔查询功能外,无法对词项检索出来的文档列表进行相关度排序,为了让检索出来的文档列表实现相关度排序,本文在倒排索引设计时会附加反映词项在文档中的词汇频率和文档集合中的出现频率的信息,如下所示:
单词,总词频,文档集合中出现该单词的文档数:(文档2→该单词在文档2的词频,文档6…)。
同时考虑到,用户向搜索引擎提交查询时,可能会对输入词项的拼写形式没有绝对把握,或者是想找包含查询词以及其相关变体形式的文档的现实情况,本文对以上倒排索引中的词典部分再进行了一层索引——轮排索引以实现通配符查询的功能。轮排索引是倒排索引的一种特殊形式,它在字符集中引入了一种新的符号,以标识词项的结束,并为每个旋转结构构造了一个指针。这些指针指向词项的不同旋转版本,形成了一个集合。轮排索引的一部分的结构图如图2所示。构建轮排索引可以让用户输入诸如X*Y、*X、X*、*X*等查询语句进行通配符查询,比如如果要进行通配符查询m*n, 可以将查询语句m*n进行旋转让*号出现在字符串末尾,即得到n$m*。下一步,在轮排索引中查找该字符串。
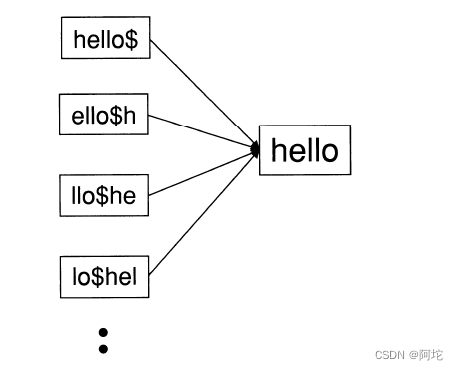
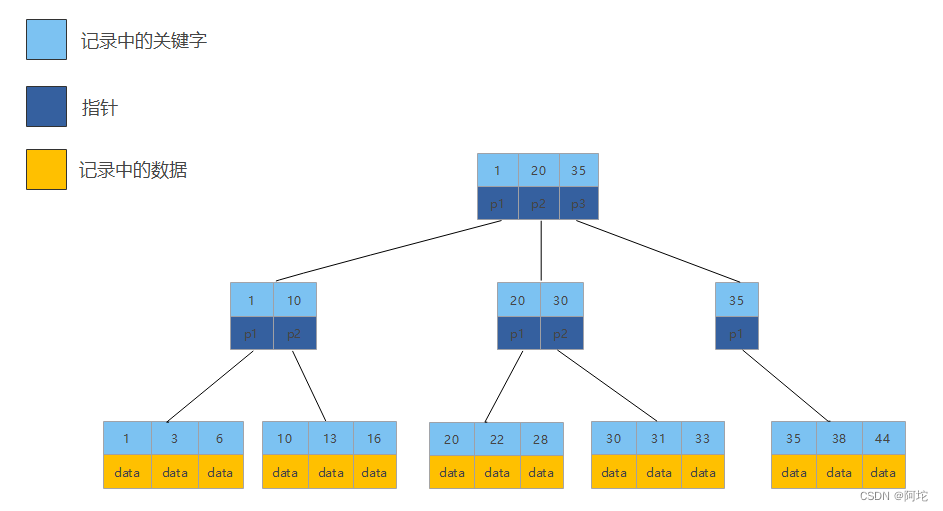
轮排索引保存了每个词项的所有旋转结果,这样会造成词表非常大,为了实现我们能在一张大词表中快速定位到我们想要查找的词项,本文借鉴了MySQL中所使用的B+树索引结构,用B+树来存储轮排索引,用于实现通配符查询快速定位。
B+树是一种平衡查找树,与红黑树、二叉树和B-树相比,B+树具有更低的高度,因此基于此构建的索引结构可以获得更快的查找性能。在B+树中,只有叶子节点存储数据,非叶节点则起到索引的作用。所有叶子节点按键值顺序存放,并通过指针相连接形成一个链表,这样有利于区间查找和遍历。B+树的数据结构图如图所示。
(四) 分布式存储技术
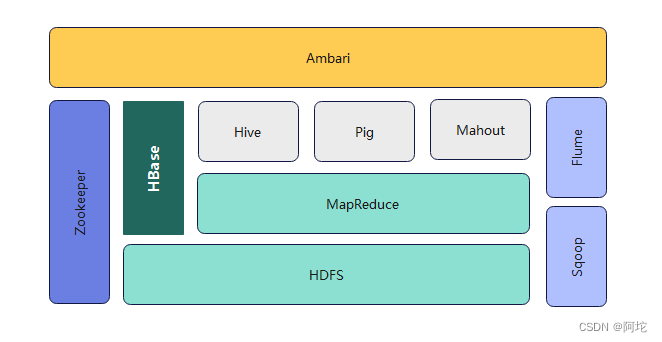
Hadoop 是基于 Apache 的开源分布式计算平台,可以将大量的普通计算机整合在一起,形成一个计算机集群,用于解决大规模数据的计算和存储问题。它的核心是分布式文件系统 HDFS 和分布式计算框架 MapReduce。经过多年的发展,Hadoop 已经成为一个生态系统,包括HDFS、HBase、Hive、Zookeeper、Mahout 等多个组成部分。
1. HDFS
HDFS是Hadoop体系中数据存储管理的基础,主要负责大规模数据计算下的数据存储和管理,运行在大量普通计算机上。它的特点是高可靠性、高容错性、高扩展性和高吞吐量,可以稳定可靠的存储超大规模数据,并且方便海量数据的处理。
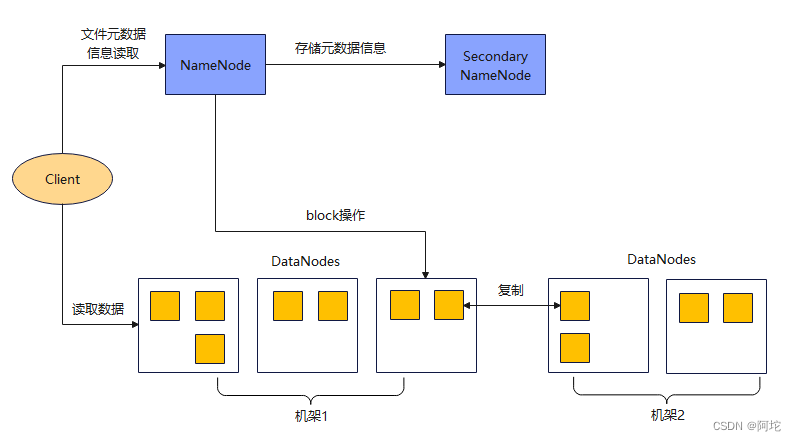
HDFS采用主从结构模型,包含一个NameNode和多个DataNode。NameNode是主节点,负责管理HDFS的命名空间和客户端访问操作;DataNode是从节点,负责存储分配到的数据。HDFS将文件按一定的大小切块(默认设置是128MB),然后把每个块以多个副本的形式保存在不同的DataNode上。通常每个块会保存3个副本,多个副本可以保证在少量节点出现问题时数据不会丢失,同时也能提高数据读取的速度。在HDFS中,文件的元数据,包括文件路径、大小、创建日期、所有者,以及分块情况和每块所在的数据节点编号等,会保存在NameNode上,名字节点全局只有一台,同时还可以配置一个SecondaryNameNode来同步这些元数据,充当NameNode的备份。一旦NameNode出现故障,就可以很快地从SecondaryNameNode恢复所有的元数据。
2. HBase
HBase是Google Bigtable的开源实现,而 Google 公司开发Bigtable是为了它的搜索引擎应用。HBase是一个运行在Hadoop集群上的高可靠性、高实时性、可扩展的分布式数据库,很容易进行横向扩展。HBase的实现以HDFS为基础,每个表的每个列族都会对应HDFS上的一个或多个文件。数据使用者可以通过HBase将数据存储在HDFS中,或使用HBase随机访问HDFS中的数据。HBase允许存储各种类型的、动态的、灵活的数据,它利用行键、列族、列限定符和时间戳建立索引。HBase 数据库的存储结构如图所示:
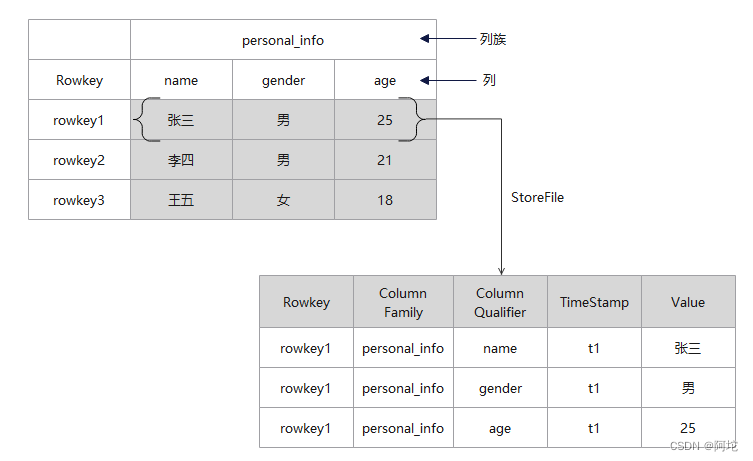
HBase 数据库主要有如下六部分构成:
(1)表:HBase 用表来存储数据。
(2)行键:在每个表中,数据按行存储,行由行键作为唯一标示,可以用来保证数据的唯一性。
(3)列族:HBase 基于列族划分数据的物理存储,一个列族可以包含包意多个列限定符,一般同一类的列限定符会放在一个列族中。
(4)列限定符:列族里的数据用列限定符来定位。
(5)单元格:由行键、列族和列限定符共同确定,存储在其中的数据即为单元值,单元值的数据类型通常被当作字节数组byte[],也就是说HBase中的数据是以字节数组形式存储的。
(6)时间戳:通过设置时间戳(默认使用当前时间戳),HBase表中一个单元格可以并列存储多个版本的数据。
HBase与传统的关系型数据库的区别主要体现在以下几个方面:
(1)数据索引:关系型数据库一般能够根据不同的列建立多种复杂索引,以提升信息查询的精度。而HBase仅针对行键构建索引,以便增加存取信息的效率。
(2)数据维护:在关系型数据库中,更新操作会导致旧值被覆盖。而HBase执行更新操作时,并不会删除旧值,而是生成一个新值。
(3)可伸缩性:关系型数据库难以实现横向扩展,纵向扩展的空间也受到限制。与此形成对比,HBase旨在实现可灵活扩展的横向扩展,并能轻松地增加或减少集群中的硬件数量,从而实现性能的伸缩性。
HBase极强的横向扩展性,使HBase能够支持对网络爬虫提交的海量数据的存储。同时HBase简单的数据索引设计使其不需要考虑存储和访问海量数据时因为索引导致的性能瓶颈,所以HBase非常适合用来配合搜索引擎,根据搜索结果实时获取数据。所以相对于传统的关系型数据库,用HBase来配合搜索引擎的构建,更具有得天独厚的优势。
(五) 分布式计算技术
在大数据处理中,Hadoop的MapReduce因延迟过高,无法适用于实时和快速计算的需求,因此只适用于离线批处理的应用场景。为了弥补Hadoop在数据处理和计算方面的不足,出现了基于内存计算的大数据并行计算框架Spark。Spark专注于处理和分析数据,提供了内存计算框架,支持SQL即席查询、实时流式计算、机器学习和图计算等。Spark形成了一套完整的生态系统,并与Hadoop生态系统兼容,因此可以轻易地将现有的Hadoop应用程序迁移到Spark系统中。
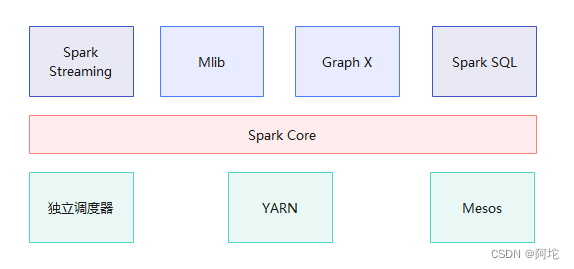
Spark生态系统包括Spark Core、Spark SQL、Spark Streaming、MLlib等组件。各个组件的具体功能如下:
(1)Spark Core:Spark Core是Spark的基础,它建立在抽象RDD之上,能够适用于不同场景的大数据处理。RDD是弹性的分布式数据集,本质上是一个只读的分区记录集合,每个RDD都可分为多个分区,每个分区就是数据集的一个部分,不同分区可保存在集群中不同的节点上,因而可以在集群中的不同节点上进行并行计算。
(2)Spark SQL:Spark SQL支持常见的SQL查询操作和结构化数据连接到Spark的底层引擎,满足高级数据处理需求。
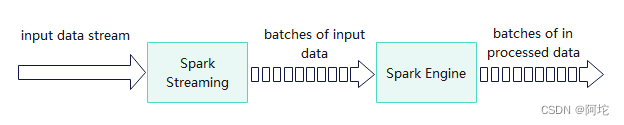
(3)Spark Streaming:Spark Streaming是建立在Spark上的实时计算框架,它扩展了Spark处理大规模流式数据的能力。Spark Streaming支持多种数据输入源,并以时间片为单位切分实时输入数据流进行处理。执行流程如下图所示:
(4)Spark MLlib:Spark MLlib是Spark的机器学习库,提供了常用的机器学习算法,包括聚类、分类、回归、协同过滤等,让开发人员更方便快捷地进行机器学习实践。
(六) 分布式消息系统
Kafka是分布式消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用,允许用户发布或者订阅流数据。Kafka 旨在构建可靠的、实时的数据流通道,以便在不同系统或应用之间传递数据,Kafka 是可以在单台或多台服务器上以集群方式运行的。Kafka的系统总体架构如图所示:
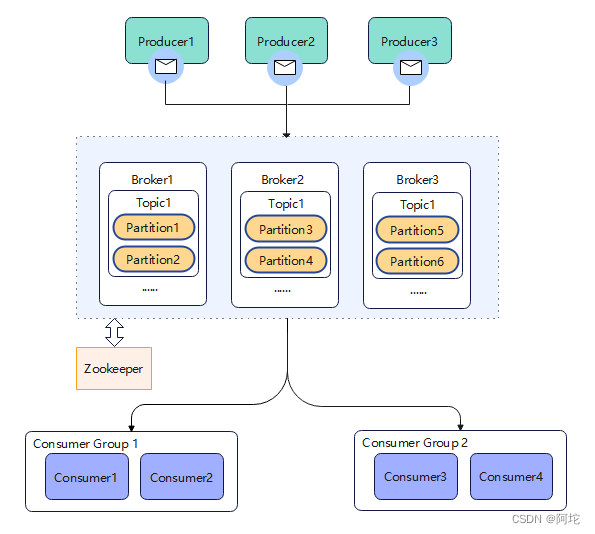
一个基本的Kafka体系结构包括:若干个Producer,它们是消息的生产者;若干个Broker,作为Kafka集群的节点服务器;若干个Comsumer,它们是消息的消费者,负责消息的消费。 除此之外,在Kafka架构中,还有几个重要概念。
(1)Topics:Kafka集群中存储的消息按照不同的分类称为不同的Topic。这本质上是一个逻辑的概念。Topic主要针对的是Comsumer和Producer。在Producer中,只需要关注将消息push到哪一个Topic,在Comsumer中, 只需关注订阅了哪些Topic。
(2)Partitions:每个Topic都可以被分割成多个Partition以提高并发性和消除大小的限制。就存储而言,每个Partition实际上是一个日志文件,每当消息发布到该Partition时,都会以追加的方式写入文件末尾。
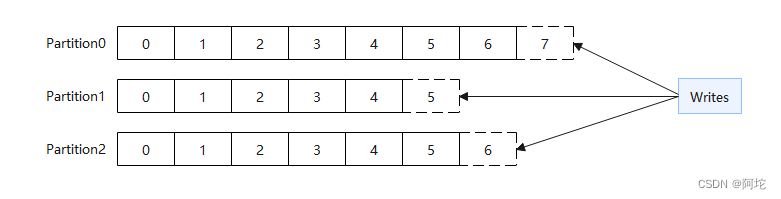
(3)Offsets:为了方便读取消息,每个消息在Partition中都有一个唯一的编号,称为偏移量。偏移量用于标识消息的位置和顺序,如图所示。
(4)Consumer Groups:多个Comsumer可以组成一个Comsumer Group,共享一个Topic的数据。每个Comsumer Group内的Comsumer只能消费一个Partition的数据,以避免重复(队列模式)。不同Comsumer Group之间可以独立地消费同一个主题的数据(发布-订阅模式)。
(七) 事件图谱
事件图谱是一种基于知识图谱的技术,其主要功能是将新闻中的实体、事件以及它们之间的关系提取出来,形成结构化化的事件图谱。要构建事件图谱,最重要的两个方面是实体识别和关系抽取。
实体识别是从文本中识别出各种实体类型(如人名、地名、组织机构等),并将它们转化为计算机可处理的形式。它是事件图谱构建的第一个主要步骤。为了实现有效的实体识别,NLP(自然语言处理)技术被广泛应用,其中包括分词、词性标注、命名实体识别等
关系抽取是指从文本中识别和抽取出实体之间的关系,例如:是、在、发生于、属于等。关系抽取是事件图谱构建的第二个主要步骤。事件图谱中的关系抽取往往依靠基于规则的方法。其中,基于词性标注的规则和基于句法分析的规则等规则模型是#较为常用的。
(八) 推荐算法
搜索引擎的推荐系统是评价搜索引擎综合性能的一个重要因素,目前国内外学术界和科技界常见的推荐算法有:
(1)基于内容的推荐算法:以物品的内容描述信息以及用户对内容的偏好为基础,通过对物品和用户自身特征的分析和建模来实现的,它根据建模后的用户偏好和物品特征进行计算,使用余弦相似度、欧氏距离等方法求两者的相似度来预测用户对物品的偏好,以得出推荐结果。
(2)协同过滤的推荐算法:协同过滤算法有基于用户(UserCF)和基于物品(ItemCF)两种,基于用户与商品之间的交互,前者是推荐与用户有相似行为的其他用户喜欢的商品;后者是推荐与用户当前喜欢的商品类似的其他商品。协同过滤算法能够为用户推荐出多样性、新颖的商品,能很多得挖掘用户的潜在需求,但协同过滤算法依赖于海量的用户商品交互记录,会存在冷启动问题(难以为新用户推荐商品、难以向用户推荐新商品)和数据稀疏问题(用户和商品的数量大,但用户对商品的行为数据很少,导致构建出来的用户-物品矩阵很稀疏,难以计算相似度和推荐结果)。
(3)基于知识的推荐算法:根据专家的知识或领域规则,推荐符合用户需求的商品,假设找不到满足用户需求的商品,用户必须改动需求,为此系统必须向用户维护一个会话窗口用于用户修改需求,对系统交互性要求高。
对于强内容属性的新闻领域来说,基于内容的推荐算法更能在新闻检索系统中发挥优势,且由于本系统并非上线系统,用户数量较少,因此难以利用基于大量用户数据的协同过滤算法进行推荐。相比之下,基于内容的推荐算法可避免新闻的冷启动问题。因此,在本系统中,我们选择了基于内容的推荐算法来实现新闻推荐。
三、系统需求分析
(一) 功能性需求
系统总体用例图如下图所示:
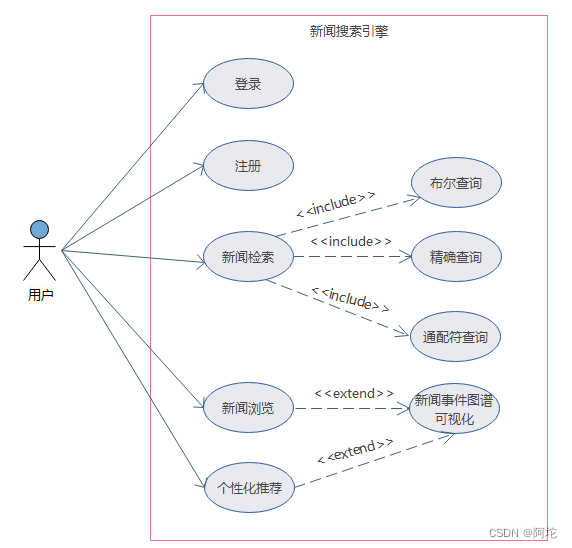
该系统主要包含四大功能:用户登录注册功能、新闻检索功能、个性化推荐新闻功能、新闻浏览功能。
(1)用户登录注册功能
本系统要求实现用户登录注册功能,这有利于收集用户搜索行为数据,从而更好地为用户推荐其感兴趣的新闻。
(2)新闻检索功能
本系统会显示新闻检索页面,用户可以在该页面中输入关键词、通配符和布尔运算符进行检索,并得到经相关度排序后的新闻列表集合。
(3)新闻浏览功能
在新闻检索或个性化推荐页面中,用户不仅可以查看具体新闻正文内容,也可以查看与该新闻相关的事件图谱,以便更好地了解新闻关联的事件、人物等知识。
(4)个性化推荐新闻功能
用户可以选择进入个性化推荐页面,从而得到根据其浏览记录生成的新闻推荐。
(二) 特殊需求
(1)海量数据存储:随着互联网数据的爆炸式增长,面对海量数据的存储和处理已经成为业界的一个大问题。搜索引擎需要解决海量数据的存储和管理问题,以便快速、高效地响应用户的搜索请求。
(2)可扩展性:在互联网时代下,用户数量、请求量以及数据量都在不断增长,搜索引擎必须具备快速扩展的能力,以便能够支持大量用户的同时保证搜索速度和质量。
(3)准确挖掘用户兴趣:准确挖掘用户兴趣能够提高搜索结果的精准度和个性化程度,从而增强用户黏性和满意度。通过对搜索引擎用户行为的研究,发现虽然用户的主体兴趣不容易发生变化,但用户对于某一类型的新闻兴趣会随时间的推移而逐渐衰减。如何处理时间因素对用户兴趣的影响是提高推荐系统精确度的关键。
四、系统设计
(一) 系统功能模块设计
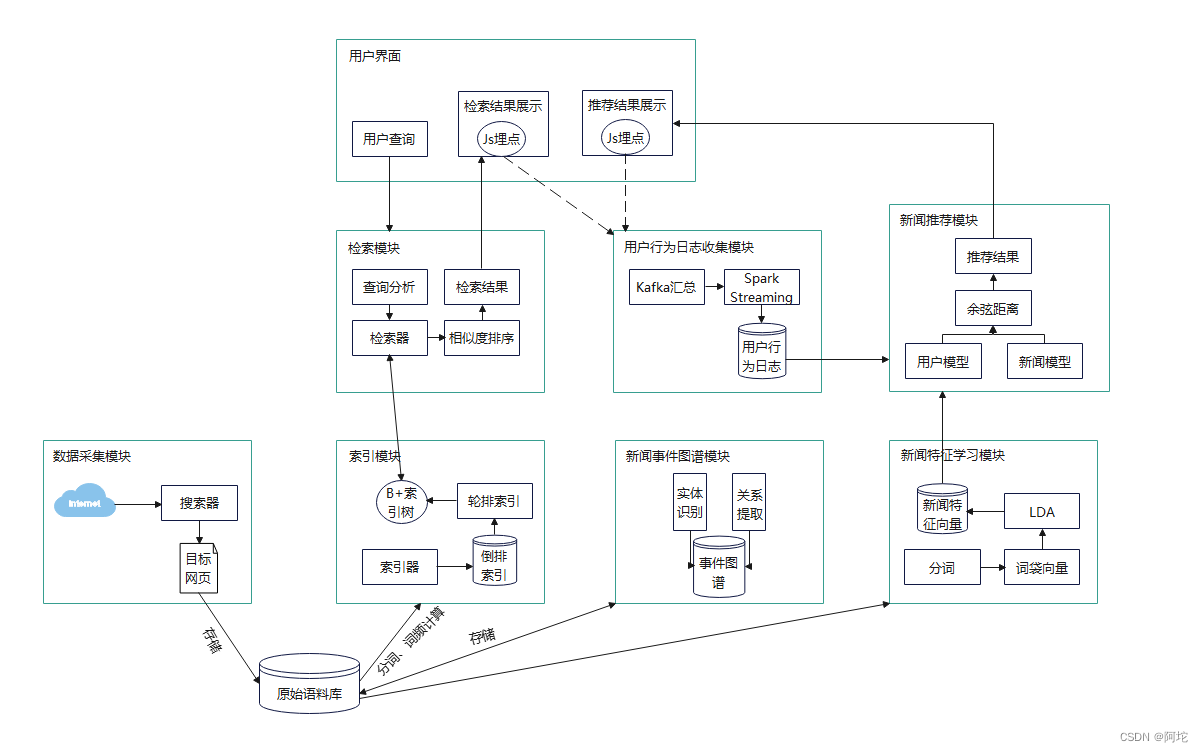
本系统的功能模块图如上图所示,可基于上述需求分析把该系统各部分按照功能进行模块划分,主要包括数据采集模块、索引模块、检索模块、新闻事件图谱模块、新闻特征学习模块、用户行为日志收集模块、新闻推荐模块。
(二) 新闻检索功能设计
1. 索引模块设计
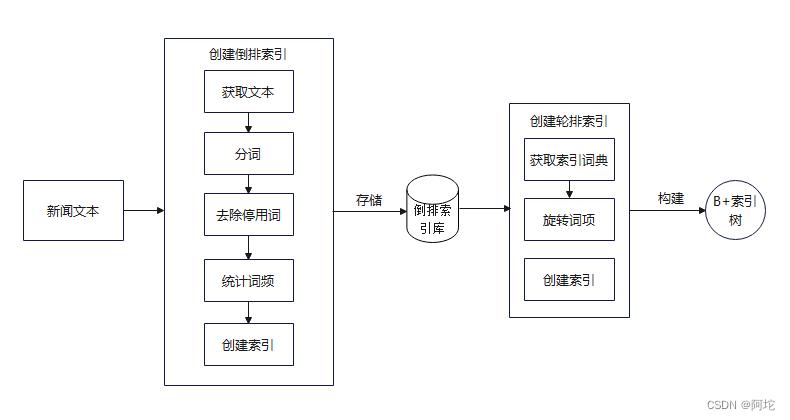
该模块负责将采集到的新闻数据进行构建倒排索引,以便后续的检索。索引模块流程图如上图所示。各个处理步骤如下:
(1)分词:将文档集合中的每个文档分成一个个独立的单元,称为词项等,成为构建倒排索引的最小单位。对于中文可以使用开源中文分词工具进行分词。
(2)去除停用词:在文档中出现频率较高但又没有特殊含义和价值的词,称为停用词。通过过滤停用词,可以降低索引的存储空间、提高检索效率。常用的中文停用词库为Stopwords-zh。
(3)统计词频:统计每个词项在文档集合中和每个文档中出现的次数。
(4)构建倒排索引:基于词项生成倒排索引,即词项到原始文档的映射。文档列表包括文档ID,以及每个词项在此文档中的出现次数等信息。通过这个倒排索引,可以实现复杂的布尔查询、处理短语进行精确查询等操作。
(5)构建轮排索引:将倒排索引文件中的词典部分提取出来,对于词典中的每个词项,构建旋转结构,生成轮排索引。
(6)构建B+索引树:读取轮排索引中的词项,将其添加到B+索引树中,首先建立根节点,然后将单词按照字典序逐个插入到B+树中。
2. 检索模块设计
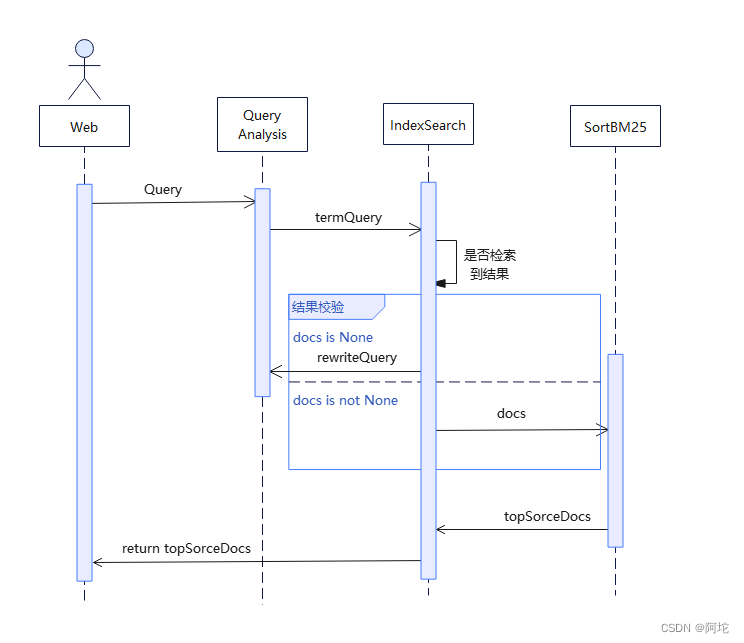
检索模块时序图如上图所示。该检索模块处理用户检索的流程如下:
(1)用户查询:用户在搜索界面输入要查询的Query语句。
(2)Query语句切分:检索模块对用户输入的Query语句进行切分处理,并将Query语句分为三类:短语、带通配符的短语和布尔运算符。根据切分后的Query语句类别,判断查询的逻辑方式,确定是精准查询还是范围查询。
(3)执行检索 :根据查询逻辑方式,检索模块从后台调用对应的查询API,对索引模块构建的B+索引树进行查询。
(4)检索召回相关网页:通过查询API调用,检索模块从索引库中检索召回初步相关网页,即与用户查询的关键词项相关的新闻网页等。
(5)BM25排序:将召回的初步相关网页与用户查询的关键词项一起带入BM25算法计算,计算每个关键词的词项与该新闻的得分,将计算出的得分按照高低顺序排列,返回给用户并在搜索界面中显示相关网页结果列表。
(三) 新闻推荐功能设计
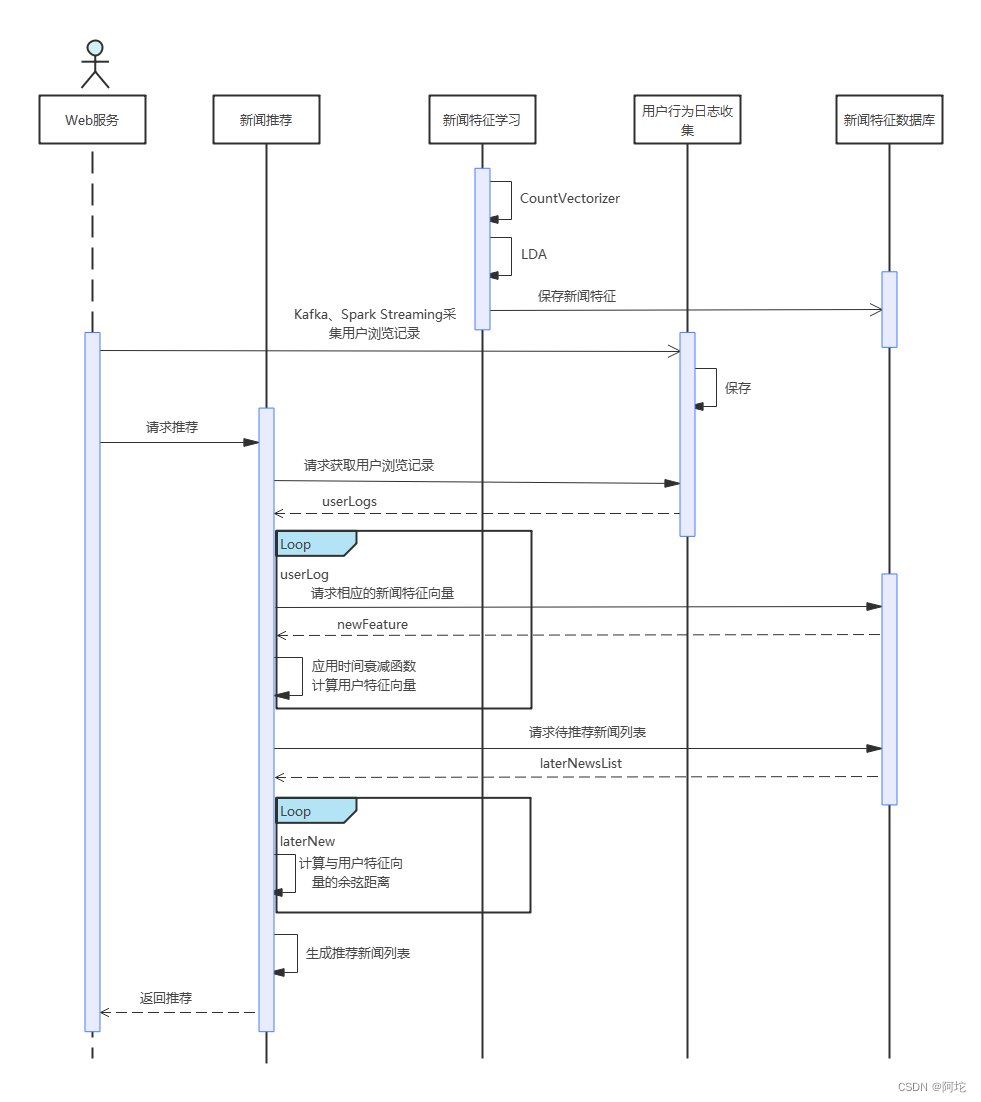
新闻推荐功能时序图如上图所示。本系统采用的基于内容的推荐算法,需要表示新闻的特征,还需要对用户的偏好特征(即用户对新闻的兴趣)进行建模。
对于新闻推荐功能的设计,本系统运用了CountVectorizer 和 LDA 模型相结合的方式来构建新闻模型。此外,本系统通过使用 Kafka 和 Spark Streaming,实时获取用户点击新闻的行为日志,并计算用户对主题的偏好,以建立用户模型。同时,对于用户对新闻兴趣会随时间的推移而逐渐衰减的现象,运用了牛顿冷却定律建立了一个时间权值衰减函数,以应对这一现象并对用户模型进行调节。在得到了用户模型和新闻模型的前提下,通过余弦距离的比较来做出推荐。
下面先介绍本系统使用到的两种向量空间模型CountVectorizer和LDA主题分布模型,再介绍由牛顿冷却定律建立的时间衰减函数以及余弦距离。
1. CountVectorizer
CountVectorizer是一种文本特征提取工具,它将文本中单词的出现次数计算出来作为特征,并忽略文本的顺序和语法,将文本转换为数值矩阵,其生成的数值矩阵可以传递给其他算法进行处理。CountVectorizer可以用于文本分类、聚类、信息检索、情感分析等自然语言处理任务。
2. LDA
LDA(Latent Dirichlet Allocation)是一种主题模型。它可以对文档集进行分析,对于每篇文档中的主题,按照一定的概率分布进行归纳。实质上,LDA 模型是一个三层贝叶斯概率模型,包括文本、主题和词三层结构。每个文档可以被视为主题集合的概率分布,每个主题则可以被视为单词集合的概率分布。总而言之,LDA模型的三层结构为我们提供了一种分层的思路,可以用来解决文本聚类,主题提取等问题。这一模型的应用非常广泛,例如在新闻分类、推荐系统和情感分析等领域都有相应的应用。
当我们有一个文档集合,需要去判定其中每一篇文档的主题集合的概率分布时,LDA模型的工作流程伪代码如下:
// docs为一个包含N个文档,每个文档都是一个长度为M的单词列表
// alpha为超参数
// beta为超参数
// K为topic的个数
// iteration是迭代次数
// 随机初始化每篇文档中每个单词的topic
for each doc in docs:
for each word in doc:
assign a random topic to word
//迭代优化每篇文档中每个单词的topic
for i in range(iteration):
for each doc in docs:
for each word in doc:
// 计算每个主题下这个单词出现的概率
topic_word_prob = (count(word in topic) + beta) / (count(topic) + beta * vocab_size)
// 计算该doc内出现各个topic的概率
doc_topic_prob = (count(topic in doc) + alpha) / (count(doc) + alpha * num_topics)
// 根据上面两个概率值更新单词的topic
p = topic_word_prob * doc_topic_prob
new_topic = sample(p) //从概率分布中采样
// 将单词的主题分配为新的topic
assign new_topic to word
3. 牛顿冷却定律在挖掘用户兴趣上的应用
牛顿冷却定律来自于物理学领域,其原始含义是:物体冷却速度,与其当前温度与周围环境温度之差成正比。公式如下:
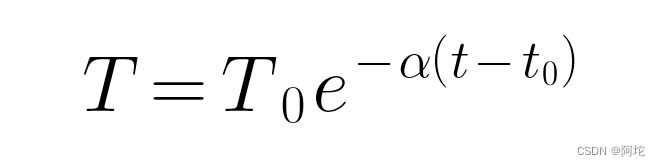
公式中变量含义为:T:当前温度;T0原始温度;α:衰减因子;t:当前时间;t0:初始时间。牛顿冷却定律给我们提供了一种指数衰减的思路,这种思路同样是可以应用到用户兴趣的建模上。假设当前用户对点击过的所有新闻主题分布向量为{v1,v2,…vn},每条新闻的点击时间为t1,t2,…tn,当前时间为t,我们对当前用户偏好建模计算公式如下:
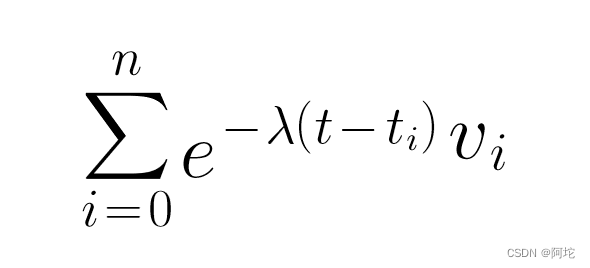
其中λ为衰减因子,通常我们用半衰期的概念计算λ。对于新闻,半衰期较短,假设12小时,即0.5天后,热度衰减一半,我们把相关的数字代入上式计算,得到λ=1.386。
4. 余弦距离
余弦距离 (Cosine Distance),又称余弦相似度,是一种计算两个向量之间相似度的方法。它是基于向量空间模型的概念而来的。在计算两个向量之间的余弦距离时,我们首先将这两个向量看作是在多维空间中的两个向量,然后计算它们之间的夹角的余弦值来衡量它们之间的相似程度。在n 维空间中的余弦距离计算公式为:
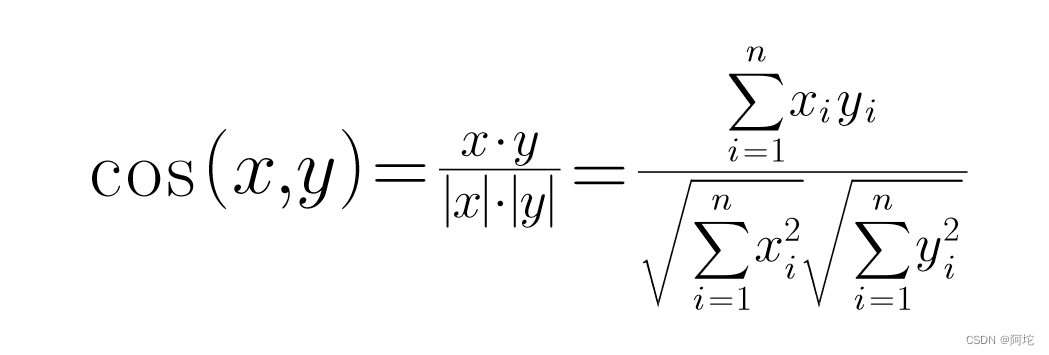
余弦距离的取值范围是[-1, 1],其中-1表示两个向量完全相反,0表示两个向量没有相似性,1表示两个向量完全相同。
五、 系统实现
(一) 开发环境及工具
本系统所采用的开发环境和工具为:
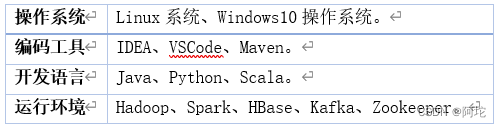
本系统根据不同语言的性质选用不同的语言开发模块,然后通过网络通信(如Socket通信)、模块调用等方式,把模块协同起来提供服务。这样做有以下好处:
(1)扩展性:如果只使用一种编程语言去实现所有功能,可能会受到语言的局限性而无法实现一些细节或性能上的优化。使用多种编程语言,可以让项目更加可扩展,更容易添加新的功能或更改现有的功能。
(2)技术适配性:不同的编程语言适用于不同的技术场景,使用多种编程语言去实现不同的功能,可以更好地发挥每种编程语言的优势,提高项目的效率。例如Java具有优秀的性能和内存管理能力,可以在处理大量数据时保持高效率,本系统用于开发索引模块和检索模块;Scala适合大数据处理和复杂计算,与大数据处理与分析框架如Spark和Kafka紧密结合,本系统用于实现新闻特征学习模块和用户行为日志收集模块;Python拥有简洁的语法特性和丰富的第三方库,对于数据采集、数据分析、科学计算以及构建轻量级的Web应用方面有着较好的支持,本系统用于开发数据采集模块、新闻事件图谱模块以及构建Web服务。
(二) 搭建大数据平台
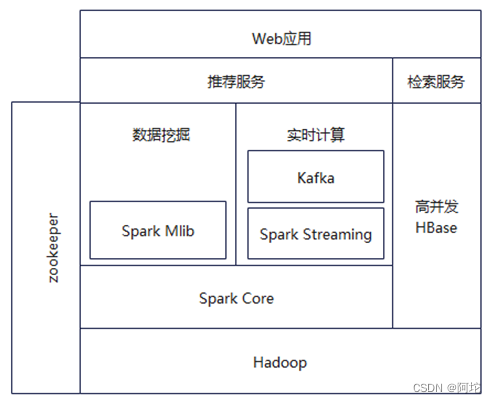 大数据平台的集群架构如上图所示。首先需要完成Hadoop集群的搭建,然后再在集群上配置安装ZooKeeper、HBase、Spark和Kafka,完成整个实验环境搭建。
大数据平台的集群架构如上图所示。首先需要完成Hadoop集群的搭建,然后再在集群上配置安装ZooKeeper、HBase、Spark和Kafka,完成整个实验环境搭建。
本文利用服务器虚拟机搭建了本实验集群,在该服务器上创建了 3个节点,其中1个主节点Master,2个从节点 Slave,将各个节点连入同一局域网,保证节点可以相互ping通。各个节点软硬件情况如下表所示:

具体的 Hadgeoop大数据平台搭建过程如下:
(1)在各个节点上都安装好 CentOS 6.4 系统。
(2)首先需要修改虚拟机的网络配置并为主机名与 IP 地址之间建立映射。可以通过运行 “vim /etc/hosts” 命令来打开系统的 hosts 文件,然后在文件的末尾添加各个节点的 IP 地址和对应的主机名,每行一个。
(3)为了避免在 Hadoop 启动过程中频繁输入密码验证,我们需要配置 SSH 免密码登录。具体做法为在主节点 Master 上使用 “ssh-keygen -t rsa” 命令生成公钥,然后使用 scp 命令将公钥发送给所有从节点 Slave,最终在从节点上为该公钥授权即可。
(4)在所有节点上安装 JDK-1.8,并为 JAVA_HOME 环境变量进行配置。
(5)为了将各节点组成一个 Hadoop 集群,需要在每个节点上安装并配置 Hadoop。首先在主节点 Master 上下载并解压 Hadoop 文件夹,然后配置 Path 变量。接着需要修改 Hadoop 的配置文件,包括 slaves、core-site.xml 和 hdfs-site.xml。其中,slaves 文件需要写入所有从节点的主机名,每行一个。在 core-site.xml 文件中,需要在 fs.defaultFS 标签中设置默认文件系统名称,并在 hadoop.tmp.dir 标签中设置 HDFS 的临时文件目录。在 hdfs-site.xml 文件中,需要在 dfs.namenode.secondary. http-address 标签中设置备份名称节点的 http 协议访问地址与端口,并在 dfs.replication 标签中设置 Slave 数量(本集群为 2)。最后,需要将修改好配置文件的 Hadoop 文件夹发送到所有从节点上。
(6)在各个节点上安装 Zookeeper。首先需要下载并解压 Zookeeper 文件夹,然后配置 PATH 变量。接下来,将 conf 目录下的 zoo_sample.cfg 文件名改为 zoo.cfg,并根据 Hadoop 集群的配置,在其中添加所有主从节点的信息。最后,为了使 Zookeeper 在 Hadoop 集群中运行,需要在各个节点上创建 myid 文件,并在其中写入该节点的 id。这样Zookeeper就被安装到了Hadoop集群中。
(7)在各个节点上安装HBase 。先在主节点Master上下载并解压HBase文件夹;然后配置PATH变量;接下来,修改HBase 的配置文件:在hbase-site.xml中,修改hbase.cluster.distributed字段为true,指定HBase是以分布式形式运行,修改hbase.rootdir字段,指定HBase的数据文件在HDFS文件系统中的位置,修改hbase.zookeeper.quorum字段,指定zookeeper集群各个主机的位置;在regionservers文件中,写入节点名,一行一个。主节点把修改好配置文件的HBase文件夹发送到其他两个从节点,这样就完成了HBase的集群搭建。
(8)在各个节点上安装Spark 。先在主节点Master上下载并解压Spark文件夹;然后配置PATH变量;接下来,修改HBase 的配置文件:添加从节点的主机名或IP地址到slaves中;在spark-env.sh中(设置Worker节点),设置SPARK_DIST_CLASSPATH为"${HADOOP_HOME}/bin/hadoop classpath",这样Spark就可以把数据存储到Hadoop的HDFS中,设置HADOOP_CONF_DIR为Hadoop的配置文件夹所在的文件路径,设置SPARK_MASTER_IP 为Spark 集群 Master 节点的 IP 地址;主节点把修改好配置文件的Spark文件夹发送到其他两个从节点,这样就完成了Spark的集群搭建。
(9)在各个节点上按照Kafka。先在主节点Master上下载并解压Kafka文件夹;然后配置PATH变量;接下来,修改Kafka的配置文件:在server.properties中,设置broker.id为一整数,设置Kafka的端口号port,设置log.dir为日志文件存放的文件路径,设置zookeeper.connect为Zookeeper各节点的主机名和端口号。主节点把修改好配置文件的Kafka文件夹发送到其他两个从节点,并在各个从节点下修改broker.id为全局唯一的其他整数,这样就完成了Kafka的集群搭建。
(三) 数据采集模块的实现
该模块负责从互联网各个站点抓取新闻数据。实现该模块时需考虑抓取速度、数据格式等问题。本系统使用Scrapy实现新闻网页的抓取,利用XPath解析、提取网页中用户感兴趣的内容,将半结构化的网页数据转化为结构化的网页数据,并将结构化网页数据存储至HBase中,作为新闻原始语料库,供后续新闻特征学习、生成新闻事件图谱和新闻检索使用。
Scrapy作为网页数据采集的工具,由调度器(Scheduler)、下载器(Downloader)、爬虫(Spiders)、管道(Item Pipeline)和Scrapy引擎(Scrapy Engine)五个部分组成,其连接关系以及数据的流通方向如图所示:
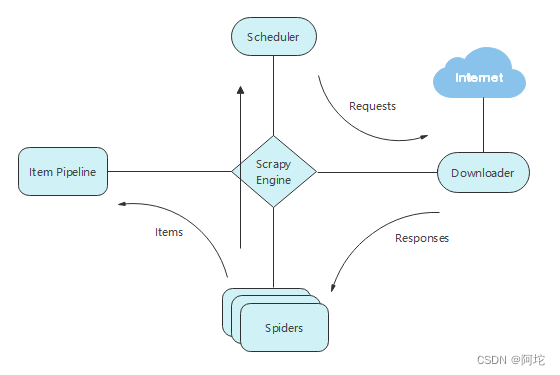
Scrapy运行流程如下:
(1)Scrapy引擎从Spiders获取链接url,并把链接url封装成Requests传给调度器 。
(2)调度器将Requests调度后经引擎交给下载器,下载器把资源下载下来,封装成Responses再次经过引擎交给Spiders。
(3)Spiders处理Responses返回数据items给Item Pipeline,或者把新的Requests发送给调度器等待调度,开启新一轮的爬取,直到调度器中没有Requests。
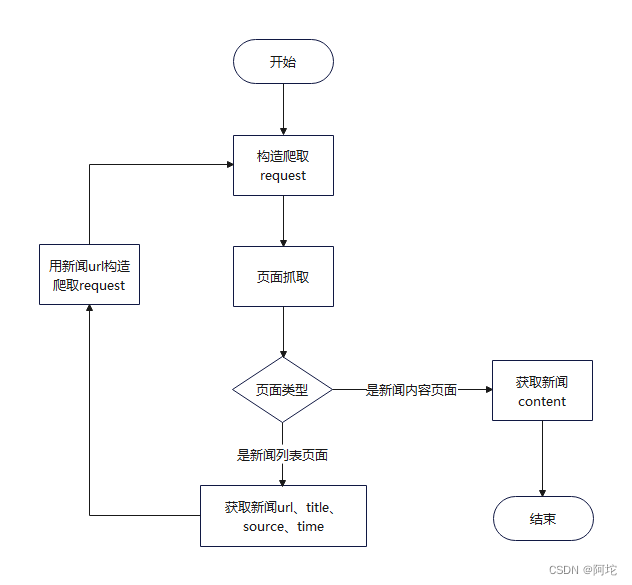
在Scrapy自有框架的基础下,本文根据实际需要对新浪新闻、中国新闻网的新闻数据进行爬取,新闻爬虫代码流程图如图所示:
该爬虫的运行过程如图所示:
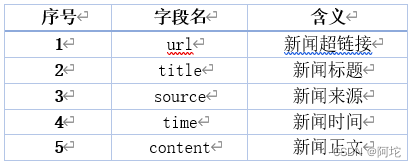
通过新闻爬虫获取到的新闻字段信息如表5所示. 爬取到的新闻信息将会存储到HBase数据库中,作为新闻原始语料库。
(四) 索引模块的实现
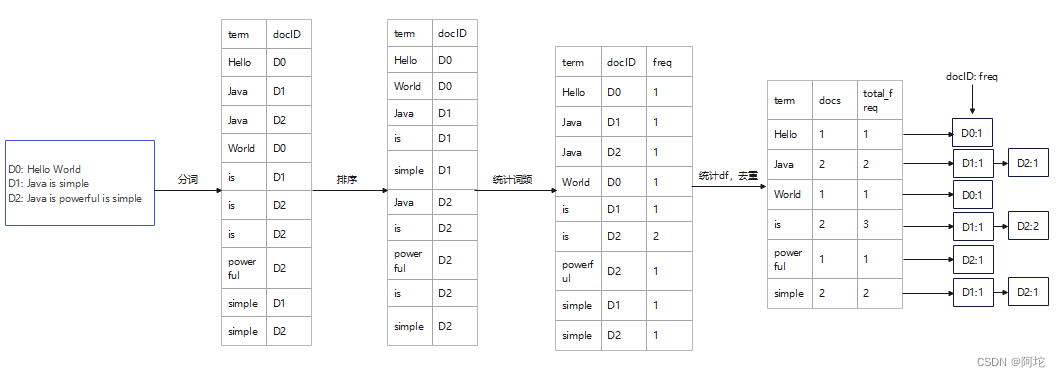
倒排索引的构建过程如图所示,实现流程如下:
(1)获取文本:获取存储在HBase中的新闻原始语料库中的content字段的文本用来建立倒排索引。
(2)分词:选用中文分词工具来对选取的各个文本信息进行分词,生成item(term,docID),并记录各个文本信息的长度。其中Item类的定义如下:
import java.text.Collator;
import java.util.Comparator;
import java.util.Locale;
import java.lang.String;
public class Item implements Comparable<Item> {
public String term;
public Integer freq;
public String strdocId;
//以下略
}
(3)排序:对提取的所有 items进行排序。
(4)统计词频:统计在每个文档中出现的每个item(term,docID)的词频tf,形成item(term,docID,freq)。
(5)统计df并去重:计算出现每个词语的文档个数df,将具有同个term的item(term,docID,freq)进行合并处理,形成itemIndex(term,docs,total_freq,ori_item_list)。其中ItemIndex类的定义如下:
import java.util.LinkedList;
public class ItemIndex {
public String term;
public Integer docs;
public Integer freq_total;
public LinkedList<Item> ori_item_list;
//以下略
}
(6)基于itemIndex(term,docs,total_freq,ori_item_list)建立倒排索引结构(包含Dictionary结构和PostingList结构),生成索引文件。倒排索引结构如图所示。
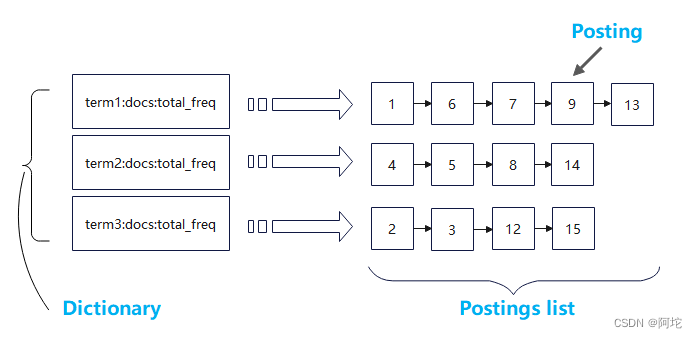
构建好轮排索引之后还需将倒排索引文件中的词典部分提取出来,对于词典中的每个词项,构建旋转结构,生成轮排索引。然后将轮排索引中每个词项的旋转结构添加到B+索引树中。实现流程如下:
(1)读取倒排索引文件,反序列化形成倒排索引结构,把倒排索引结构里Dictionary结构里的每一项term形成轮排索引。以hello举例,hello可以被转换成hello$, ello$h, llo$he, lo$hel, o$hell。$代表中hello的结束,现在查询hello等于查询hello$,查询hel*等于查询hel*$,查询*hel等于查询hel$*,查询hel*o等于查询o$hel*。引入轮排的索引方法,可以支持通配符的模糊查询方式
(2)在形成轮排索引的基础上构建B+索引树,首先建立根节点,然后将单词按照字典序逐个插入到B+树中,B+索引树构建好后常驻在内存中,以加快检索速度。核心代码如下:
public static BPlusTree createRotateIndex(LinkedList dictionary){
long startTime = System.currentTimeMillis(); //获取开始时间
//每个节点可放4个关键字,5个子节点指针
int order = 4;
BPlusTree bPlusTree = new BPlusTree(order);
Iterator<ItemIndex> iterator = dictionary.iterator();
while (iterator.hasNext()) {
ItemIndex item = iterator.next();
String cur_term = item.term + "$";
for (int i = 0; i < cur_term.length() - 1; i++) {
bPlusTree.insertOrUpdate(cur_term, item);
cur_term = cur_term.substring(1) + cur_term.charAt(0);
}
}
构建好的B+索引树的一部分如下图所示:

(五) 检索模块的实现
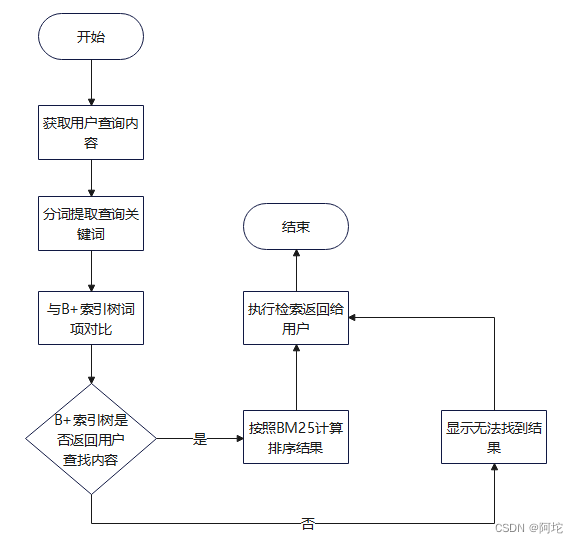
检索过程流程图如图所示:检索模块的实现流程如下:
(1)获取用户的查询内容并进行切分,切分后用户的查询内容可划分为三个组成部分(也可以只有其中一个组成部分或两个):短语、带通配符的短语、布尔运算符,据此判断出要用哪种查询方式,短语使用精确查询,带通配符的短语使用范围查询,如查询内容还含有布尔运算符,则需要根据相应的布尔运算符把精确查询和范围查询(或精确查询和精确查询、范围查询和范围查询)两者得到的结果进行布尔查询,筛选出初步的相关新闻docID列表。该新闻检索子系统支持如下形式的查询语句:
单个查询:
X
XY或X或X或X*
多个查询相结合:
XY或X或X或X或X AND XY或X或X或X或X
XY或X或X或X或X OR XY或X或X或X或X
XY或X或X或X或X ANDNOT XY或X或X或X或X …
XY或X或X或X或X AND XY或X或X或X或X OR…
…
(2)把初步的相关新闻docID列表和用户查询的关键词项一起带入BM25算法,计算出关键词的词项与该新闻的相关度得分,按照相关度得分高低的顺序排列返回最终的相关新闻docID列表。BM25是目前信息索引领域最主流的计算用户查询与召回文档相似度得分的算法。BM25算法公式如下所示:
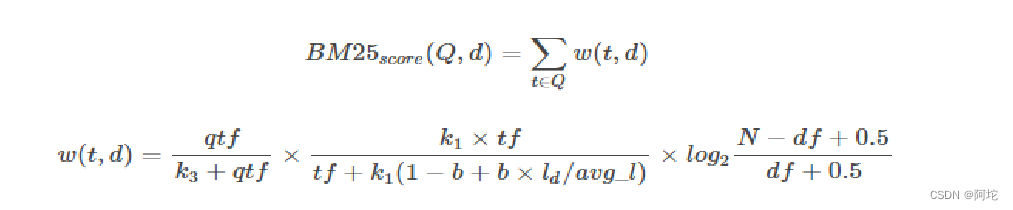
公式中变量含义为:qtf:查询关键词的词频;tf:文档中的词频;ld:文档长度;avg_1:平均文档长度;N:文档数量;df:文档频率;b、k1、k3:可调参数。
(3)根据最终的相关新闻docID列表,从对应的HBase数据库存储中得到详细的新闻内容信息返回给前端。
本系统采取HBase数据库存储和索引文件相结合的方式检索数据,HBase数据库中存储新闻网页内容的详细信息,索引文件存储了新闻网页的索引信息。HBase数据库存储的作用是减轻索引存储的容量负担,且当索引文件崩溃或损坏时,还可以用HBase数据库存储的信息作为源,重新生成索引文件,从而提高系统的安全性。
(六) 新闻事件图谱模块的实现
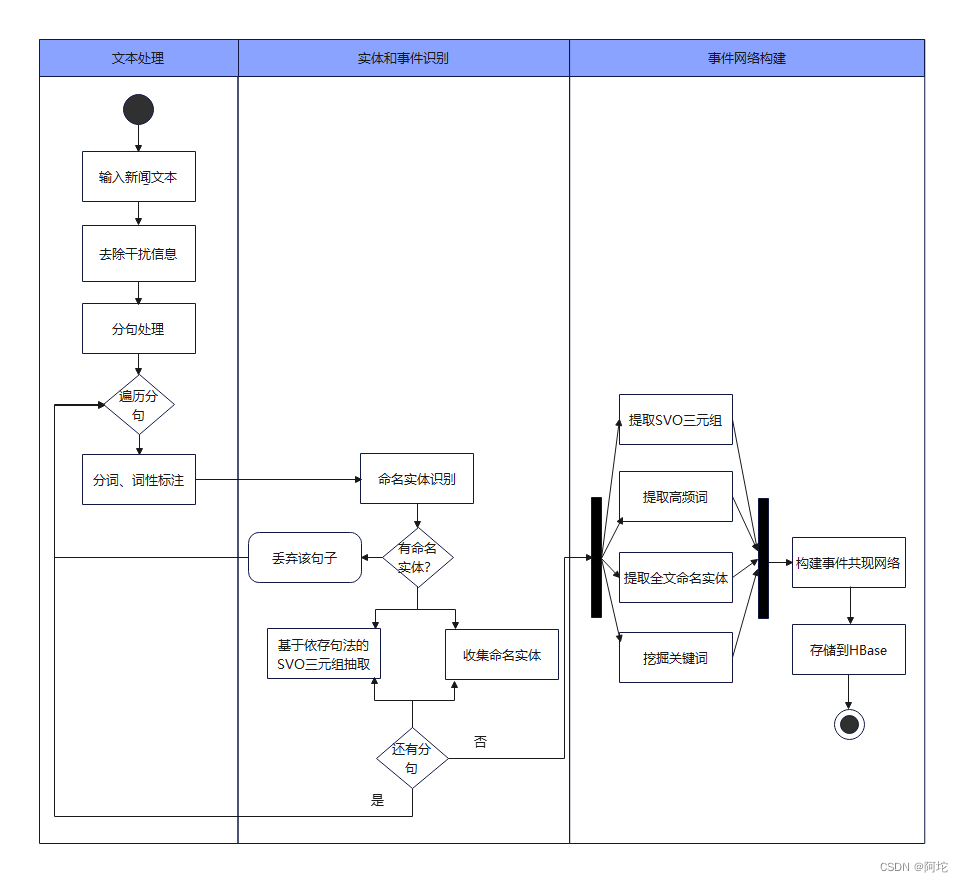
新闻事件图谱模块的活动图如上图所示。它主要的功能是对新闻语料库中的每一篇新闻文本进行文本处理、实体和事件识别和构建事件网络。
1. 文本处理
文本处理的步骤如下:
(1)输入新闻文本。
(2)去除干扰信息:对输入的新闻文本移除括号内的内容。
(3)分词、词性标注:对新闻文本进行分句,遍历每个分句,对分句进行分词和词性标注,得到分词结果words和词性标注结果postags。
以上步骤涉及到的处理结果words和postags的示例如下表所示:

2. 实体和事件识别
实体和事件识别的步骤如下:
(1)命名实体识别:遍历words和postags列表,当词性为命名实体(人名、地名、机构名)时,将该词和词性标注按照“词/词性”格式拼接成一个字符串收集起来。
(2)对每一个具有命名实体的分句提取出SVO(主谓宾)三元组等信息:对words和postags列表进行句法分析,返回句法分析结果tuples和句法分析树的结构child_dict_list。接着,遍历tuples,对于SBV关系(表示主语与谓语的关系),抽取出主语、谓语,并根据谓语在child_dict_list中找到宾语,形成SVO三元组,最后将SVO三元组依次放入svo列表中。
以上步骤涉及到的处理结果tuples、child_dict_list和svo的示例如下:

3. 事件网络构建
事件网络构建的步骤如下:
(1)提取高频词:计算每个词的出现频率,并排除了长度小于等于 1 的词汇。接着选取出现频率最高的前 10 个词汇,将这些词汇的类别定义为“高频词”,并将这些词汇的名称和类别存储在 events 列表中。
(2)挖掘关键词:基于TextRank算法挖掘关键词,将这些关键词按权重从大到小排序,并返回前10个关键词,然后将这些词汇的类别定义为“关键词”,并将这些词汇的名称和类别存储在 events 列表中。
(3)提取SVO三元组:把全文经过实体和事件识别得到的并且含有关键词的SVO三元组收集起来,存储在 events 列表中。
(4)提取全文命名实体:把全文经过实体和事件识别得到的所有命名实体收集起来,存储在 events 列表中。
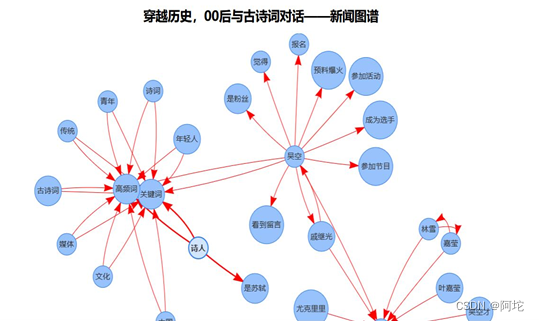
(5)构建事件共现网络:首先获取命名实体共现对以及关键词与命名实体的共现对。获取命名实体共现对:对分句进行遍历,将分句中的命名实体两两组合作为共现对,遍历分句结束后,将所有的共现对存储在events 列表中;获取关键词与命名实体的共现对:对分句进行遍历,将分句中的关键词和命名实体两两组合作为共现对,遍历分句结束后,将所有的共现对存储在events 列表中。最后将events列表转化为共现网络的节点和边,最终将所有的节点和边打包成JSON格式的数据。事件共现网络JSON数据如下图所示。

(6)存储到HBase:把得到的新闻事件共现网络JSON数据存储到HBase中,由Web应用根据用户的选择以图谱化的形式渲染出来。
(七) 新闻特征学习模块的实现
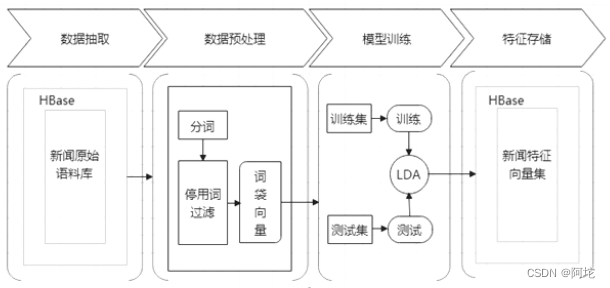
新闻特征学习模块的流程如上图所示。新闻特征学习模块主要完成对新闻的特征表示,本系统使用向量空间模型表示新闻特征,即每条新闻数据以向量的形式表示。首先使用Spark Mlib库对存储在HBase数据库的新闻原始语料库进行训练,先采用CountVectorizer模型得到新闻的词袋向量,再将词袋向量作为LDA模型的输入,使用LDA模型训练新闻的主题分布向量。具体实现过程如下。
(1)首先,使用SparkConf提供的newAPIHadoopRDD接口从HBase数据库中导入content字段的新闻正文文本
(2)对选取的新闻正文文本进行分词并去除停用词,过滤掉经分词和去除停用词后词项列表为空的新闻,防止后续训练过程中出现空指针异常。经过数据预处理后的数据为RDD格式,需要基于StructType类型建立schema,与需要转换的RDD相匹配建立DataFrame,才可以进行进一步处理。使用CountVectorizer模型将文本分词后的词项集合转换为词袋向量。
(3)数据预处理完毕后,可以进行模型训练。将得到的词袋向量转递给LDA模型。设置LDA模型的超参数主题Topics数量K=20,最大迭代次数MaxIter=20进行训练。训练完毕后,每条新闻得到一个topicDistribution类型作为输出,表示新闻的主题分布向量,也是新闻特征学习的最终输出结果。
(4)调用自定义的hbaseSave方法,将训练结果保存到HBase数据库。每条新闻内容对应的词项集合、经CountVectorizer模型训练得到的词袋向量以及经LDA模型训练得到的主题分布向量如下图所示

(八) 用户行为日志收集模块的实现
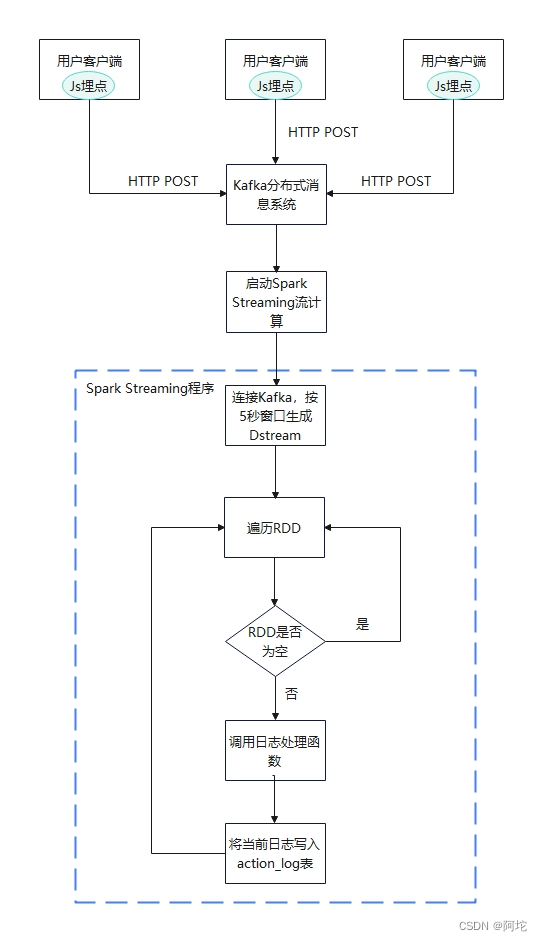
用户行为日志收集模块的流程图如上图所示。用户行为日志收集模块主要利用Javascript、Kafka、Spark Streaming等技术实时处理用户日志。具体实现过程如下。
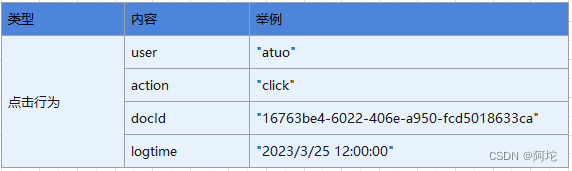
(1)在用户使用我们提供的Web应用的基础上,使用Javascript埋点技术收集用户的点击行为,收集的数据包括用户id或名字,用户点击的新闻docId,点击时间等。然后将用户行为数据封装为JSON格式,使用AJAX技术将JSON数据发送到后台。收集用户点击行为的方法为自定义的postClick函数。收集的用户行为日志格式如下表所示。
(2)postClick函数将用户行为日志发送到后台的"/get_action"接口,该接口再将数据转发到Kafka上汇总,最后由Kafka交给Spark Streaming处理。
(3)Spark Streaming程序的流程:使用StreamingContext类配置Spark Streaming的数据接收间隔为5秒,即5秒接收的数据组成一个RDD。每5秒产生一个RDD组成DStream类型的数据,DStream类型的数据实际是一个RDD序列。获取Kafka中的数据后,使用Spark Streaming提供的foreachRDD功能遍历所有的RDD窗口,并调用foreachPartition方法枚举每一个分片进行处理,处理的核心逻辑为迭代遍历日志数据,使用JSON解析器将String类型的日志数据为Map[String,String]对象,使用UUID创建随机的RowKey,并将日志数据存储到HBase的action_log表中。
(九) 新闻推荐模块的实现
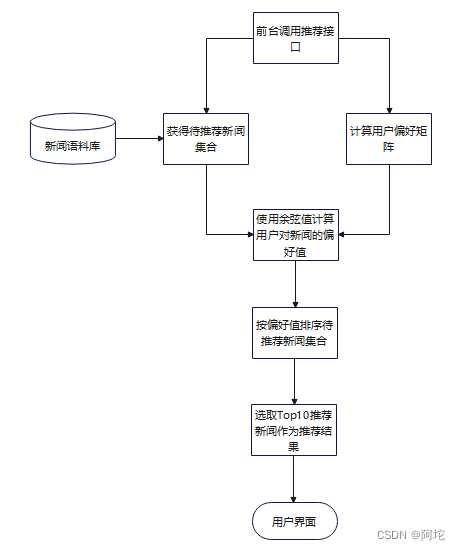
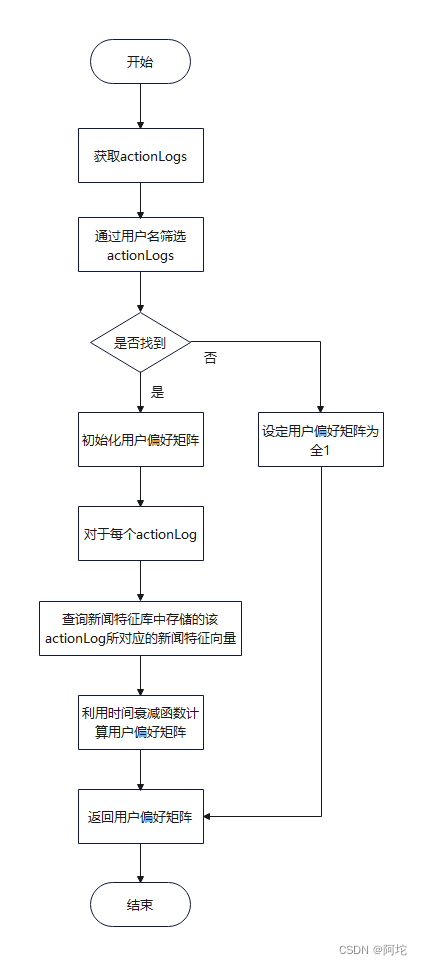
新闻推荐模块的流程图如上图所示。具体实现如下:通过新闻发布时间过滤出待推荐新闻集合,对于待推荐新闻集合里的每一篇新闻,获取其特征向量new_vec,并计算用户偏好矩阵user_vec(计算用户偏好矩阵的流程图如下图所示),然后计算new_vec和user_vec的余弦相似度simscore,之后按照simscore的大小进行排序,按照排序结果返回前10篇新闻作为推荐结果。
(十) Web服务的实现
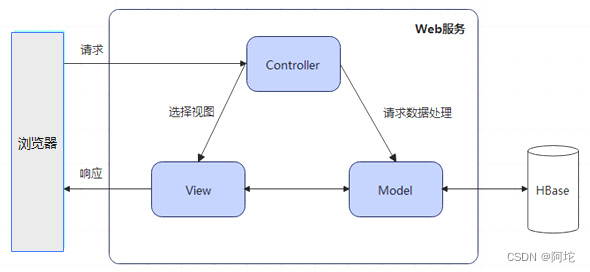
本系统采用Flask框架实现Web服务。Flask 是一种采用 Python 编写的轻量级 Web 应用框架,与其他同类框架相比,它相对更加灵活、轻便和安全性更高,且易于入门。Flask的设计理念上是基于 MVC(Model-View-Controller) 架构的,可以与MVC模式很好地结合进行开发。MVC架构图如下所示。
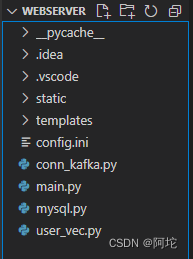
在 VSCode中创建Web服务的项目结构如下图所示。项目结构包含:存放html模板的文件夹(templates)、存放静态文件资源的文件夹(static)、项目配置文件(config.ini)、项目程序文件(main.py)、连接MySQL的程序文件(mysql.py)、连接Kafka的程序文件(conn_kafka.py)、计算用户特征的程序文件(user_vec.py)。
1. 新闻检索接口设计
Web服务提供搜索引擎主页,可将接收到的用户查询内容与提供核心搜索服务的数据检索服务进行交互,获取相关新闻的docID列表,并从对应的HBase数据库存储中得到详细的新闻内容信息返回给用户。为此,Web服务需要提供新闻检索接口以供与用户进行检索交互。新闻检索接口说明表如下表所示。

2. 新闻推荐接口设计
系统获得新闻特征向量和用户特征向量后,可开发新闻推荐接口供Web服务使用。该接口根据用户ID或名字调用用户特征计算方法计算出当前用户的特征向量,再调用新闻过滤方法获得当前待推荐新闻集合,然后枚举推荐新闻集合,计算当前用户对每一条新闻的推荐评分值。最终将待推荐新闻按照推荐评分值从大到小排序后返回。新闻推荐接口说明表如下表所示。
3. 新闻事件图谱可视化接口设计
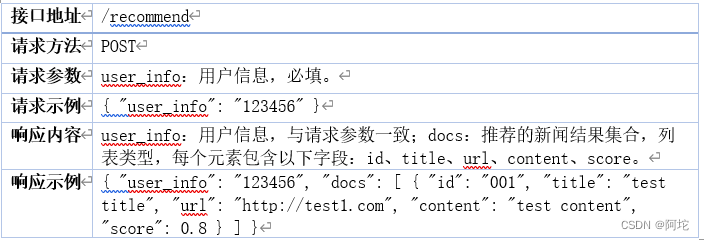
用户可选择浏览新闻检索服务或新闻推荐服务返回的新闻列表中的任何一条新闻的事件图谱。为此,Web服务提供了一个可视化访问新闻事件图谱的接口。该接口会根据新闻的docID从对应的HBase数据库中读取新闻事件图谱JSON数据,供前端渲染成图谱化的形式返回给用户。新闻事件图谱可视化接口说明表如表11所示。

4. 用户界面设计
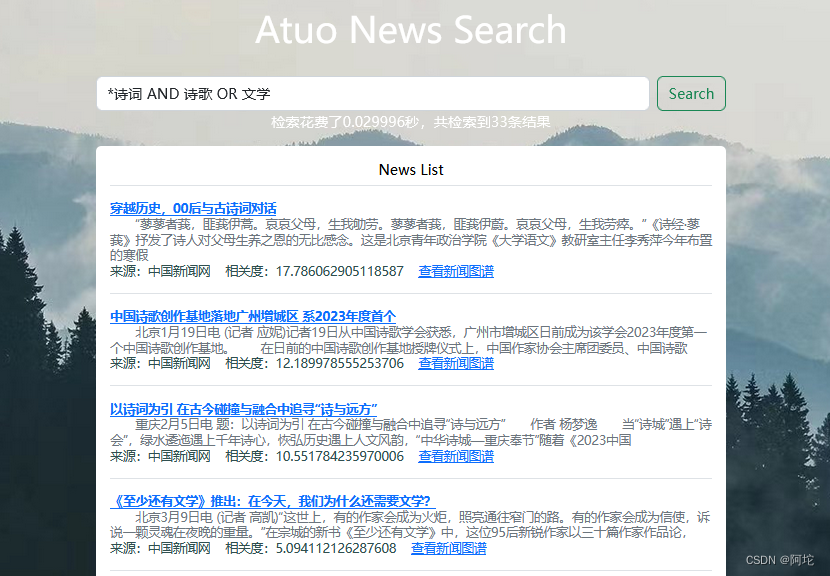
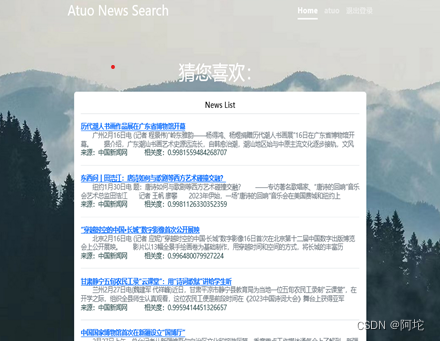
界面设计主要在templates文件夹下,为了实现更好的用户体验,需要设计web界面。这个搜索引擎目前需要五个页面,一个是搜索主页页面,用户可输入查询内容检索新闻,并且可查看按查询内容检索和经BM25算法计算相关度排序的新闻列表;两个是登录注册页面,用户可进行登录注册;一个是新闻推荐页面,用户可获取个性化的新闻推荐服务;一个是新闻事件图谱可视化页面,用户可浏览相应的新闻事件图谱。

六、 系统测试
系统测试是软件测试的重要阶段,它主要是测试整个系统是否满足用户需求,并且系统的性能是否正常运行。该系统进行了系统测试,主要分为功能测试和性能测试两个部分。其中,功能测试涵盖用户登录注册、新闻检索、新闻浏览和新闻推荐四个方面的测试。而性能测试则包括倒排索引构建时间和检索响应时间两个方面的测试。综合上述测试,可以对该系统的功能和性能进行全面的评估和优化。
(一)功能测试
1. 用户登录注册测试
该测试主要检验用户登录注册功能是否正常运作。测试要点包括用户注册、登录、退出登录等功能是否正常。
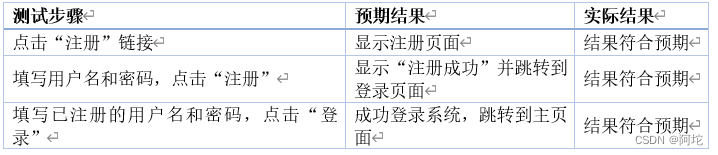
2. 新闻检索测试
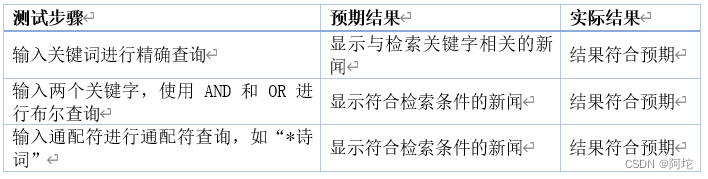
该测试主要检验用户能否通过检索功能准确查找到所需的新闻。测试要点包括是否能够对新闻进行精确查询、布尔查询和通配符查询。
3. 新闻浏览测试
该测试主要检验新闻浏览功能是否正常运行,并且显示信息是否符合要求。测试要点包括新闻列表页面的信息展示是否完整、新闻详情页面是否能正常跳转、新闻的事件图谱是否能正常显示、检索结果页面跳转是否正常等。

4. 新闻推荐测试
该测试主要检验系统能否成功根据用户的新闻浏览记录推荐相关新闻。测试要点包括推荐结果是否能正常显示、推荐结果是否与用户的浏览兴趣相关等。

(二) 性能测试
1. 倒排索引构建时间测试
该测试主要检验系统在倒排索引构建时所需的时间,以确定系统的性能和用户体验。

上表显示了为28353条新闻(字数为9582976)构建倒排索引时各步骤的运行耗时,各步骤的运行耗时均在合理的范围内,此结果达到了预期。
2. 检索响应时间测试
该测试主要检验系统的检索响应时间,以确定系统的性能和用户体验。为了确保准确获取系统的检索响应时间,采用了以下测试步骤:在精确查询、布尔查询和通配符查询方面,手动输入关键词进行单次检索,记录了每种查询方式的5组系统响应时间,最后取每种查询方式的5组响应时间的平均值。

从上表可以看到,系统的检索响应时间在可接受范围内。此结果达到了预期,可以满足用户对新闻检索的普通需求。
七、总结与展望
本文针对搜索引擎的广阔应用前景以及搜索引擎系统的基本原理设计一种应用于新闻领域的全文搜索引擎,在对项目工程进行分析之后,确定了一系列有针对性的技术解决方案:
(1)使用个性化定制的网络爬虫工具Scrapy爬取新闻页面,对爬取到的新闻页面进行精准解析,从而获取用户感兴趣的新闻信息。
(2)结合时下应用比较广泛的分布式存储技术存储原始的新闻语料库,供后续的生成索引文件、配合新闻检索使用,满足了海量新闻内容的存储需求,同时保证了存储可靠性。
(3)实现了新闻的常用搜索功能。用户可输入短语、带通配符的短语以及布尔运算符查询感兴趣的新闻内容。
(4)根据用户偏好向量和新闻主题分布向量,设计和实现了新闻推荐算法,并提供了接口供前台Web服务调用。
(5)引入了事件图谱可视化技术,将新闻中的各个关键点以及关键点之间的关联都展现在图谱中,提升了用户浏览新闻时的用户体验。
本文研究仅研究了搜索引擎的基本理论和典型框架,实际上搜索引擎系统的真正内涵非常丰富,它所涉及的技术正在向多元化、纵深化发展。现在的搜索引擎不仅能搜文字内容,还能搜索图片、音乐等,并且更加注重智能化和个性化。我将继续努力学习,不断提高自己在这个领域的知识和技能。另外,虽然本系统已经拥有了部分功能,但仍存在一些不完善的地方以及需要进一步开发的进阶功能,可以在如下方面进行改进:
(1)可以考虑引入拼写检查功能,这是市面上成熟的搜索引擎所拥有的。
(2)利用先进的自然语言处理技术挖掘用户检索行为日志,对用户检索语句进行分析和改写,从而召回更多、更优质的搜索结果。
参考文献
[1] (美)曼宁,(美)拉哈万,(德)舒策. 信息检索导论[M]. 北京: 人民邮电出版社, 2010.
[2] Spark快速大数据分析[M]. 卡劳;;肯维尼斯科;;温德尔;;扎哈里亚.人民邮电出版社.2015
[3] 推荐系统实践[M]. 项亮, 编著.人民邮电出版社.2012
[4]时亚南,张太红,陈燕红,郭斌.大规模非结构化数据的索引技术研究[J].计算机技术与发展,2014,24(12):109-113.
[5]耿庆田,狄婧,常亮,赵宏伟.基于B+树的数据索引存储[J].吉林大学学报(理学版),2013,51(06):1133-1136.
[6]韩志强. 基于Hadoop的分布式藏文新闻网站垂直搜索引擎设计与实现[D].中央民族大学,2016.
[7]崔博. 基于Spark Streaming的实时新闻推荐平台的设计与实现[D]. 山东大学, 2018.
[8]李钊. 基于大数据的热点医疗新闻系统的研究与实现[D]. 西北大学, 2018.
[9]张翼. 基于分布式的新闻爬取和推荐系统的设计与实现_张翼[D]. 山东大学, 2018.
[10]李鑫克. 基于爬虫技术的小型垂直搜索引擎的设计与实现_李鑫克[D]. 首都经济贸易大学,2020.
[11]吴小飞. 分布式环境下动态实时新闻推荐技术研究[D].北京工业大学,2018.
[12]陈铭权. 基于主题模型的用户兴趣建模及在新闻推荐中的应用[D].华南理工大学,2015.
[13]丁正祁,彭余辉,孙刚.基于改进LDA主题模型的个性化新闻推荐算法[J].赤峰学院学报(自然科学版),2021,37(06):28-32.DOI:10.13398/j.cnki.issn1673-260x.2021.06.006.
[14]查云杰. 基于网络新闻的知识图谱构建与研究[D].武汉邮电科学研究院,2020.DOI:10.27386/d.cnki.gwyky.2020.000064.
[15]黄恒琪,于娟,廖晓等.知识图谱研究综述[J].计算机系统应用,2019,28(06):1-12.DOI:10.15888/j.cnki.csa.006915.




![[oeasy]python0081_[趣味拓展]ESC键进化历史_键盘演化过程_ANSI_控制序列_转义序列_CSI](https://img-blog.csdnimg.cn/img_convert/0da0d2cb3169bebeb6f832748890de1c.png)