Apache Arrow流执行引擎
对于许多复杂的计算,在内存或计算时间内,连续的计算函数的直接调用都是不可行的。为了更加有效的提高资源使用率、促进多批数据的消费,Arrow提供了一套流式执行引擎,称为Acero。
目前支持算子有:Source、Sink、HashJoin、Project、Filter、Sort、 Agg。
如果自己要在Arrow里面实现一个新算子,如物化、MergeJoin等算子,我们需要如何实现?
本节将以最复杂的HashJoin算子为例,拆解其实现原理,便于快速上手。
1.Acero Plan
以两表join为例,假设Student、Score表,其列字段分别如下:
Student表
Column | Type | Collation | Nullable | Default
---------+---------+-----------+----------+---------
id | integer | | |
stu_id | integer | | |
subject | text | | |
score | integer | | |Score表
Column | Type | Collation | Nullable | Default
--------+---------+-----------+----------+---------
id | integer | | |
name | text | | |
age | integer | | |SQL语句
select subject, name, score from student st join score s on st.id = s.stu_id and st.name != s.subject;我们大概可以得到类似的Plan:
-> Hash Join
Hash Cond: (student.id = score.stu_id)
Join Filter: (student.name <> score.subject)
-> Seq Scan on student
-> Hash (cost=431.00..431.00 rows=1 width=8)
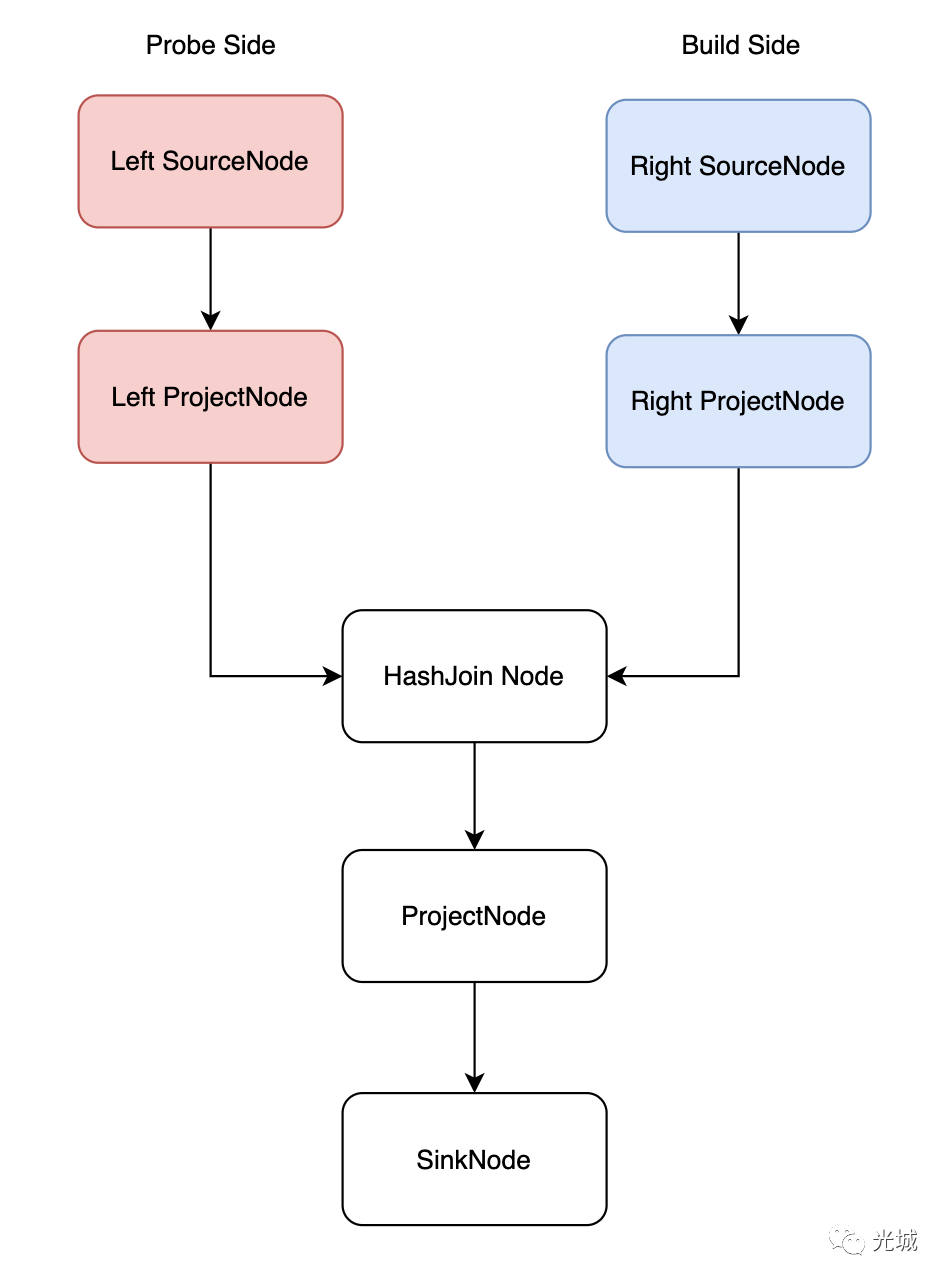
-> Seq Scan on score对于这样的Plan我们可以构建一个Acero计划,如下图所示:
2.拓扑排序
对于一个Plan,我们可以把它想象成算法中的图,使用拓扑排序便可以得到节点执行的顺序。
在Acero中,便是这么做的,通过拓扑排序算法,得到先后顺序,对于上面的图我们可以得到拓扑排序的结果为:
Left SourceNode->Left ProjectNode->HashJoinNode(probe 端)->Right SourceNode->Right ProjectNode->HashJoinNode(build 端)->ProjectNode->SinkNode。
注意:对于HashjoinNode其实是一个节点,在节点内部去分叉build/probe。
当得到这么一个执行顺序节点之后,我们需要关注几个问题?
如何初始化这些节点?
如何停止/结束、什么时候发送数据/接受数据?
对于多条路径,像Hashjoin这种既有build/probe端,如何识别哪一端?
如何管理Schema?特别是Filter、Output这些的列如何与Input的Schema关联起来?
如何使用Filter过滤数据?
除了这些问题,还有特别多,例如:
多线程调度
任务调度
异步处理
BloomFilter细节
SwissJoin细节
等等。
涉及的内容非常庞杂,可以说把HashjoinNode实现出来,对于Arrow的整个框架基本可以覆盖了(当然还有ipc/kernel等)。
我们先来熟悉一下,整个Acero的模型是怎样的,这很重要,因为一不小心,写出来的Plan就没法停了,死循环了就尴尬了。
还是以上述两个表Join为例,在得到节点的拓扑排序后,plan会对收集好的节点进行倒序遍历,这样做的目的是初始化节点、收集节点异步future。
倒序的逻辑涉及两点:
StartProducing
开始生产数据,对于像Project、Sink之类的节点,基本是不做事的,完成当前节点的初始化工作,所有节点最重要的初始化便是执行完成的标记。
finished()
返回什么时候当前异步任务可以结束工作,在节点倒序遍历过程中会把每个节点finished()返回的Future对象收集起来,最后统一等待所有任务完成。
目前有两种方式来判断是否已经完成当前节点:
第一种是:通过Future对象控制
finished_.MarkFinished(status);另外一种是:任务组
task_group_.End();3.执行框架
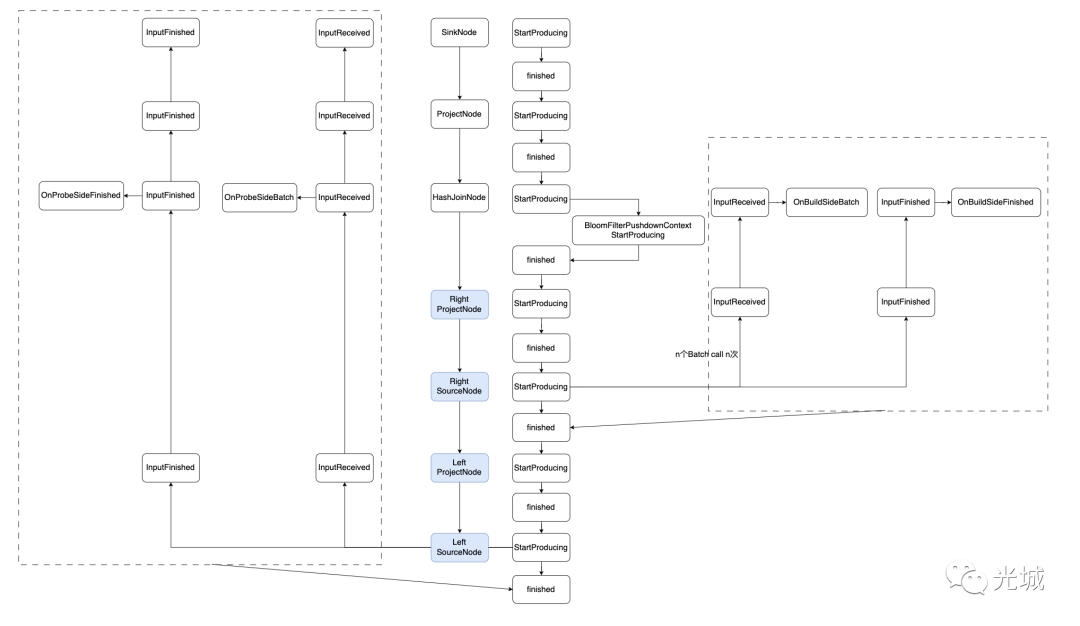
以上述的Plan为例子,我们可以得到如下执行流程。
图中蓝色这条线我们称之为倒序遍历初始化各个节点,左虚线框我们称之为probe端,右侧虚线框我们称之为build端。
1)第一个执行的节点是SinkNode,然后按照StartProducing、finished流程执行,没啥好说的,没什么特殊逻辑。
2)第二个执行的节点是ProjectNode,同上。
3)第三个执行的节点是HashJoinNode,HashJoin支持BloomFilter,所以在内部有一个Context去StartProducing、finished。
4)第四个执行的节点是Build端的Right ProjectNode,同上。
5)第五个执行的节点是Build端的Right SourceNode,这里到了精彩的部分,此时的StartProducing会真正的干活,对于Source节点是数据的来源,那么它会负责把数据Push下去,那么就会依次调用各个节点的InputReceived、InputFinished接口。
InputReceived
每个输入的节点必须要实现的接口,当然SourceNode是不需要实现的,因为它是没有输入的,如果当前节点实现了InputReceived接口,那么数据便会从上游Push下来,然后当前节点处理即可。
InputFinished
当处理完当前节点的任务后,我们需要停止,这个节点可太重要了,因为没它,你的plan就死循环了。因为在最外面一直在等当前节点处理完,可以没处理完,就死循环了,不过arrow的Future有超时控制。InputeFinished需要做两件事情:
第一:通知下游节点你可以结束了。当前节点处理了一堆事情之后,会产生Batch,产生多少个,那么当前节点完成的话,下游节点也得拿到这些完成的数据去做处理,就得一层层的InputeFinished掉。
第二:当前节点结束设置finished()接口的标志,例如:
finished_.MarkFinished(status);
或者
task_group_.End();6)第六个执行的节点是Probe端的Left ProjectNode,不做什么事情,StartProducing、finished。
7)第七个执行的节点是Probe端的Left SourceNode,跟前面的Build端SourceNode类似,负责Probe表的数据输入,注意两者在HashJoinNode节点内部处理的区别,分别会调用各自的逻辑。
4.Schema管理
HashJoin的Schema管理是一门艺术,设计的非常优雅。
首先来讨论一下为什么要Schema管理呢?
假设输入了两个表的schema,left schema、right schema,这个我们称之为INPUT schema,对于下面这样的query,引出几个问题。
select subject, name, score from student st join score s on st.id = s.stu_id and st.name != s.subject;PayLoad部分需要?如果需要,如何与输入的Schema进行关联?
Filter时,我可能只需要Left+Right的部分列,怎么快速获取?
如何快速判断Hash Key中是否含有Filter列?或者PayLoad是否含有Filter列?
对于第三个问题,HashJoin在Probe阶段会得到一些匹配的行、不匹配的行,对于Filter来说需要Batch数据,而这个Batch是由n列组合而来,那么可能一部分列来自于PayLoad、一部分来自于Key。
对于前面两个问题比较常见了,就是我扫描的时候记下用了Left/Right哪些列即可。
于是,我猜测,为了这些目标,arrow实现了一套schema管理机制,在HashJoin里面分为几类:
INPUT
OUTPUT
KEY
PAYLOAD
FILTER
分别是输入、输出、等值条件Key、不进行输出的列、进行过滤的列。
其实现原理比较好理解,记录两个mapping,一个是正向、另一个是反向。
正向:用来记录其他类型在INPUT中是否存在,具体的位置是哪里。
反向:用来记录INPUT类型在其他类型是否存在,具体的位置是哪里。
不存在用-1来标记。
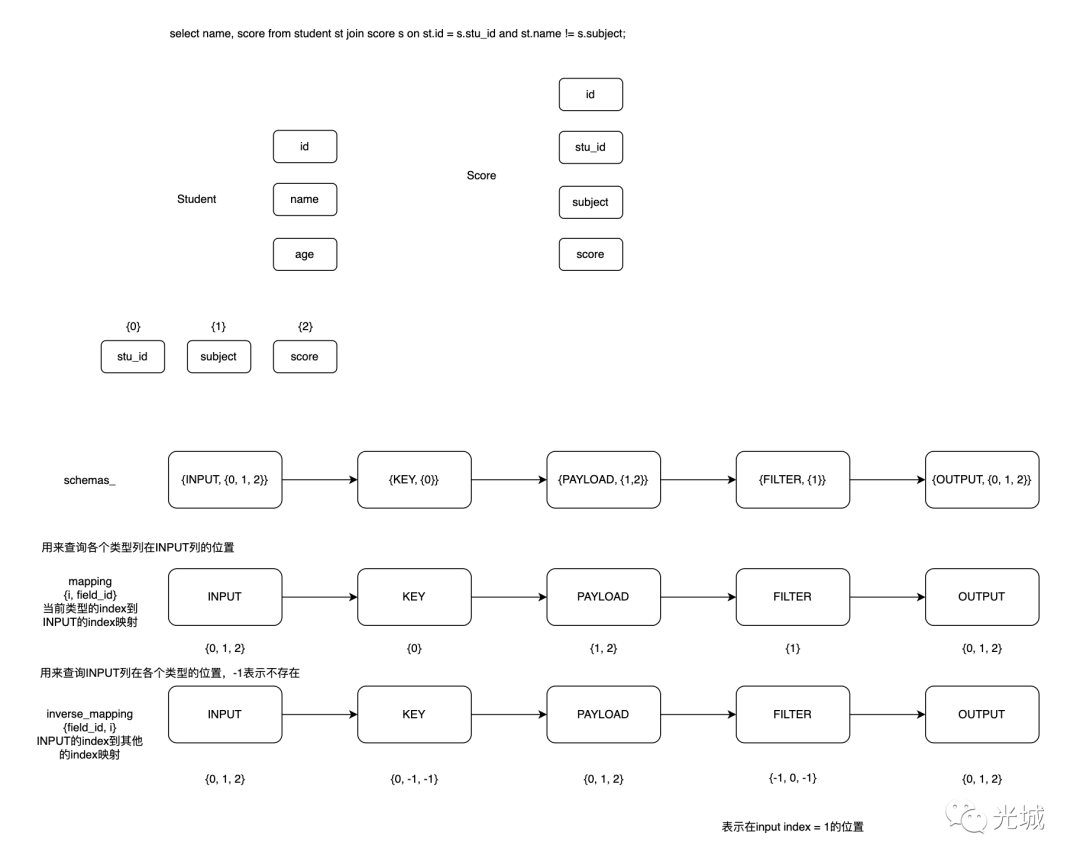
于是我们便可以通过map来得到任意两者之间的关系,例如:
查询filter类型在input类型的位置
查询input类型在filter类型的位置
查询filter类型在payload类型的位置

以上便是本节的内容,欢迎大家转发~
更多硬核内容,欢迎订阅知识星球~