文章目录
- 1. Docker安装
- 2. 拉镜象
- 2.1 ElastciSearch
- 2.2 Kibana
- 2.3 logstash
- 3. 数据展示
1. Docker安装
看之前的文章
docker ubuntu完全卸载docker及再次安装
Ubuntu安装 Docker
此外,Docker偶尔会出现这种问题dial tcp: lookup registry-1.docker.io on 192.168.1.1:53: no such host
参考Docker----执行docker pull 下载镜像时报dial tcp: lookup registry-1.docker.io on 192.168.1.1:53: no such host错误的解决办法
- 修改“/etc/resolv.conf”, 增加几个nameserver
nameserver 8.8.8.8
nameserver 8.8.4.4
- 再执行如下两条命令即可
systemctl daemon-reload
systemctl restart docker
2. 拉镜象
参考https://blog.csdn.net/at1358/article/details/114921506
#下载ELK使用的镜像
docker pull elasticsearch:7.8.0
docker pull kibana:7.8.0
docker pull logstash:7.8.0
docker pull mobz/elasticsearch‐head:5
2.1 ElastciSearch
#安装elasticsearch,创建一个elk文件夹, 后面的elk日志采集系统的配置文件都放在这里面
#创建elk使用配置文件的目录
mkdir -p /data/elk
#创建es使用的目录
mkdir /data/elk/conf -p
#配置es的配置文件
cat >/data/elk/conf/elasticsearch.yml<<'EOF'
cluster.name: "docker-cluster"
network.host: 0.0.0.0
# 访问ID限定,0.0.0.0为不限制,生产环境请设置为固定IP
transport.host: 0.0.0.0
# elasticsearch节点名称
node.name: node-1
# elasticsearch节点信息
cluster.initial_master_nodes: ["node-1"]
# 下面的配置是关闭跨域验证可以实现浏览器查看es的数据
http.cors.enabled: true
http.cors.allow-origin: "*"
EOF
#创建es使用的存储卷把数据映射出来
[root@centos7 ~]# docker volume create elasticsearch
elasticsearch
#创建并启动elasticsearch容器
docker run -di -p 9200:9200 -p 9300:9300 --name=elasticsearch -v /data/elk/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml --mount src=elasticsearch,dst=/usr/share/elasticsearch elasticsearch:7.6.0
#把宿主机的配置文件映射到es作为配置文件
/data/elk/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
#把es的容器安装目录映射到宿主机
--mount src=elasticsearch,dst=/usr/share/elasticsearch
#创建成功
[root@centos7 elasticsearch]# docker run -di -p 9200:9200 -p 9300:9300 --name=elasticsearch -v /data/elk/elasticsearch/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml --mount src=elasticsearch,dst=/usr/share/elasticsearch elasticsearch:7.6.0
317d2a274ec64500c44a7c8c0bea60175c2183a66e8e6e8a5554bc223e836e58
#对存储卷创建软连接实现快速访问
/data/docker/volumes/elasticsearch/_data/
ln -s /data/docker/volumes/elasticsearch/_data/ /data/elk/es
Elasticsearch使用9200端口作为HTTP REST API的默认端口,用于与客户端进行通信。而9300端口是Elasticsearch节点之间进行通信的默认端口,用于集群内部的节点间通信。
接下来测试安装是否完成。注意:下面的命令有可能有问题,curl瞬间docker就炸了
#测试是否安装成功
[root@centos7 es]# curl 127.0.0.1:9200
{
"name" : "node-1",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "CK6xnBvaTciqRtWhjZf7WA",
"version" : {
"number" : "7.6.0",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "7f634e9f44834fbc12724506cc1da681b0c3b1e3",
"build_date" : "2020-02-06T00:09:00.449973Z",
"build_snapshot" : false,
"lucene_version" : "8.4.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
注意:如果需要添加插件时,需要将容器的插件目录映射到实际的路径中或者通过命令
(如安装ik分词器:docker cp ik elasticsearch:/usr/share/elasticsearch/plugins/)将其拷贝到容器中
解决方案参考docker启动es(解决9200端口访问不到)
- 检查docker启动的log
docker logs -f 容器id - 发现虚拟内存开的太小了
- 修改虚拟内存参数
# 查看参数大小
cat /proc/sys/vm/max_map_count
# 设置参数
sysctl -w vm.max_map_count=262144
由于暴露端口可能导致信息泄露或者遭受攻击
(你的Elasticsearch在“裸奔”吗?),因此建议不要暴露端口
2.2 Kibana
#安装kibana
#kibana主要用于对elasticsearch的数据进行分析查看。注意选择的版本必须和elasticsearch的版本相同或者低,建议和elasticsearch的版本相同,否则会无法将无法使用kibana。
#创建配置文件
cat >/data/elk/conf/kibana.yml<<'EOF'
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://127.0.0.1:9200"]
# 操作界面语言设置为中文
i18n.locale: "zh-CN"
EOF
#创建kibana使用的容器卷
docker volume create kibana
#创建并启动kibana容器
docker run -di --name kibana -p 5601:5601 -v /data/elk/conf/kibana.yml:/usr/share/kibana/config/kibana.yml --mount src=kibana,dst=/usr/share/kibana kibana:7.8.0
#把宿主机的kibana配置文件映射到容器内部
# -v /data/elk/conf/kibana.yml:/usr/share/kibana/config/kibana.yml
#把容器内的kibana的安装目录映射到宿主机的容器卷方便管理
# --mount src=kibana,dst=/usr/share/kibana
#创建kibana容器卷的软连接方便管理
ln -s /data/docker/volumes/kibana/_data/ /data/elk/kibana
此时直接curl 127.0.0.1:5601,有可能遇到问题Kibana server is not ready yet,解决方法参考kibana解决Kibana server is not ready yet问题
20230807更新:本质问题是如何在docker中访问别的容器,参考我新的博客让ELK在同一个docker网络下通过名字直接访问
方法1(对我有效)
将配置文件kibana.yml中的elasticsearch.url改为正确的链接,默认为: http://elasticsearch:9200 或者 http://127.0.0.1:9200 ,改为http://自己的IP地址 或者 docker的地址:9200
至于为什么有效,是因为这里的localhost是容器内的localhost,如果es在另一个容器中就访问不到了。
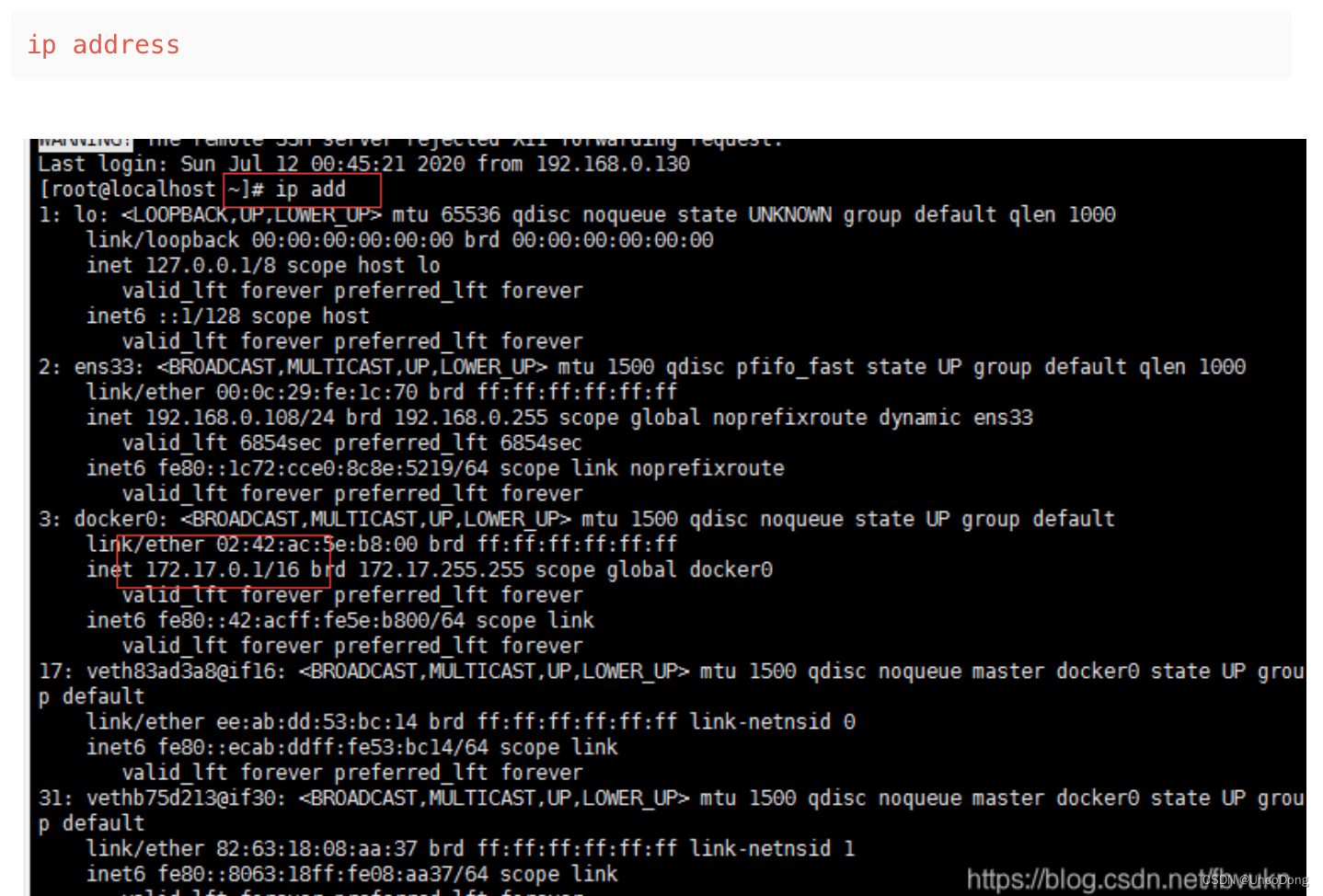
docker0 是 Docker 引擎创建的默认网络桥接接口。当你在 Docker 中创建容器时,默认情况下,Docker 会为每个容器分配一个虚拟网络接口,并将其连接到 docker0 网桥上。
docker0 网桥充当了 Docker 主机和容器之间的网络桥梁。它的主要作用是实现容器与 Docker 主机以及其他容器之间的通信。通过 docker0 网桥,Docker 主机可以与容器进行网络通信,并提供容器之间的网络互连性。
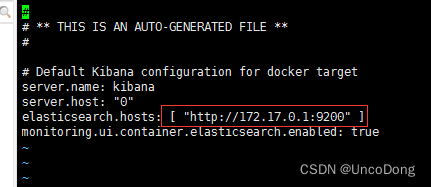
我也是给改成了docker的地址变好了
方法2 关闭防火墙
# 关闭之后再查看防火墙状态
systemctl stop firewalld.service
systemctl status firewalld.service
# 永久关闭防火墙,重启系统也不会开启防火墙
systemctl disable firewalld.service
kibana配置密码
参考https://blog.csdn.net/IT_road_qxc/article/details/121858843
直接在yml配置即可
# 此处设置elastic的用户名和密码
elasticsearch.username: miima
elasticsearch.password: miima
2.3 logstash
logstash的配置比较复杂
1. 首先启动容器,获取配置文件
# 启动容器
docker run -d --name=logstash logstash:7.2.0
# 查看日志
docker logs -f logstash
直到最后有successfully字段即可
2. 创建所需要的挂载文件,并拷贝配置
# 创建文件夹,用于保存同步用的conf文件
mkdir -p /opt/docker/logstash/config/conf.d
# 拷贝配置
docker cp logstash:/usr/share/logstash/config /opt/docker/logstash/
docker cp logstash:/usr/share/logstash/data /opt/docker/logstash/
docker cp logstash:/usr/share/logstash/pipeline/opt/docker/logstash/
修改配置logstash.yml
http.host: "0.0.0.0"
xpack.monitoring.elasticsearch.hosts: [ "http://127.0.0.1:9200" ] # 如果在docker中,则使用docker的ip address或者服务器IP(需要保证服务器公网可以访问)
#path.config: /usr/share/logstash/config/conf.d/*.conf
path.logs: /usr/share/logstash/logs
递归为文件夹赋予权限
chmod -R 777 logstash/
3. 命令行启动
删除之前的容器,重新启动一个新的容器
docker run \
--name logstash \
--restart=always \
-p 5044:5044 \
-p 9600:9600 \
-e ES_JAVA_OPTS="-Duser.timezone=Asia/Shanghai" \
-v /opt/docker/logstash/config:/usr/share/logstash/config \
-v /opt/docker/logstash/data:/usr/share/logstash/data \
-v /opt/docker/logstash/pipeline:/usr/share/logstash/pipeline \
-d logstash:7.8.0
4. 配置mysql自动同步
首先确认是否有 logstash-input-jdbc插件,一般7.x版本都默认有。
# 进入容器
docker exec -it logstash bash
# 查询是否有 logstash-input-jdbc
./bin/logstash-plugin list --verbose
# 如果没有就安装插件(一般默认安装)
./bin/logstash-plugin install logstash-input-jdbc
# 退出容器
exit
在conf路径下创建jdbc.conf文件,格式如下
input{
jdbc{
# 连接数据库
jdbc_connection_string => "jdbc:mysql://47.108.13.175:3306/edu?serverTimezone=Asia/Shanghai&characterEncoding=utf8&useSSL=false"
jdbc_user => "root"
jdbc_password => "HBcloud.1024"
# 连接数据库的驱动包
jdbc_driver_library => "/usr/share/logstash/config/jars/mysql-connector-java-8.0.20.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
codec => plain { charset => "UTF-8" }
# 数据追踪
# 追踪的字段
# 在配置中,tracking_column 参数的值应该是你的数据库表中的一个列名,该列的值会随着数据的插入而递增或变化。jdbc 输入插件将使用这个列的值来确定从数据库中检索哪些新的数据。
tracking_column => "update_time"
# 上次追踪的元数据存放位置
last_run_metadata_path => "/usr/share/logstash/config/lastrun/logstash_jdbc_last_run"
# 设置时区
jdbc_default_timezone => "Asia/Shanghai"
# sql 文件地址
# statement_filepath => ""
# sql 注意:一定需要sql_last_value
# 这里的SQL语言需要保证和mysql中一致,比如用了MySQL的关键字定义的列名,那就需要`{列名}`的方式进行搜索
statement => "SELECT g.merchant_id AS id,g.nickname AS nickname,g.avatar_name AS avatarName,g.`desc` AS `desc`,g.contacts AS contacts,g.province AS province,g.city AS city,g.district AS district,g.address AS address, ST_AsText(g.coordinate) AS coordinate FROM wbc_merchant g WHERE g.update_time > :sql_last_value"
# 是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run =>false
# 这是控制定时的,重复执行导入任务的时间间隔,第一位是分钟 不设置就是1分钟执行一次
schedule => "* * * * *"
}
}
output{
elasticsearch{
# 要导入到的Elasticsearch所在的主机
hosts => "132.232.41.245:9200"
# 要导入到的Elasticsearch的索引的名称
index => "merchant_index"
# 类型名称(类似数据库表名)
document_type => "merchanteso"
# 主键名称(类似数据库表名),必须是唯一ID
# 如果想要保证你的数据库不出现重复的数值,那就要好好设置他
# 我的方案是和tracking_column一致,但这样可能会导致无法插入新数据,因此document_id必须得是唯一的
document_id => "%{id}"
}
stdout{
# JSON 格式输出
codec => json_lines
}
}
需要注意的是这里需要下载jar文件,可以参考这片博客不同版本mysql-connector-java的jar包下载地址。下载后将压缩包解压到本机(非docker)/opt/docker/logstash/config的路径下,并提取出jar文件。
此外,elasticsearch的hosts和yaml文件中的保持一致即可。
3. 数据展示
1. 加入索引
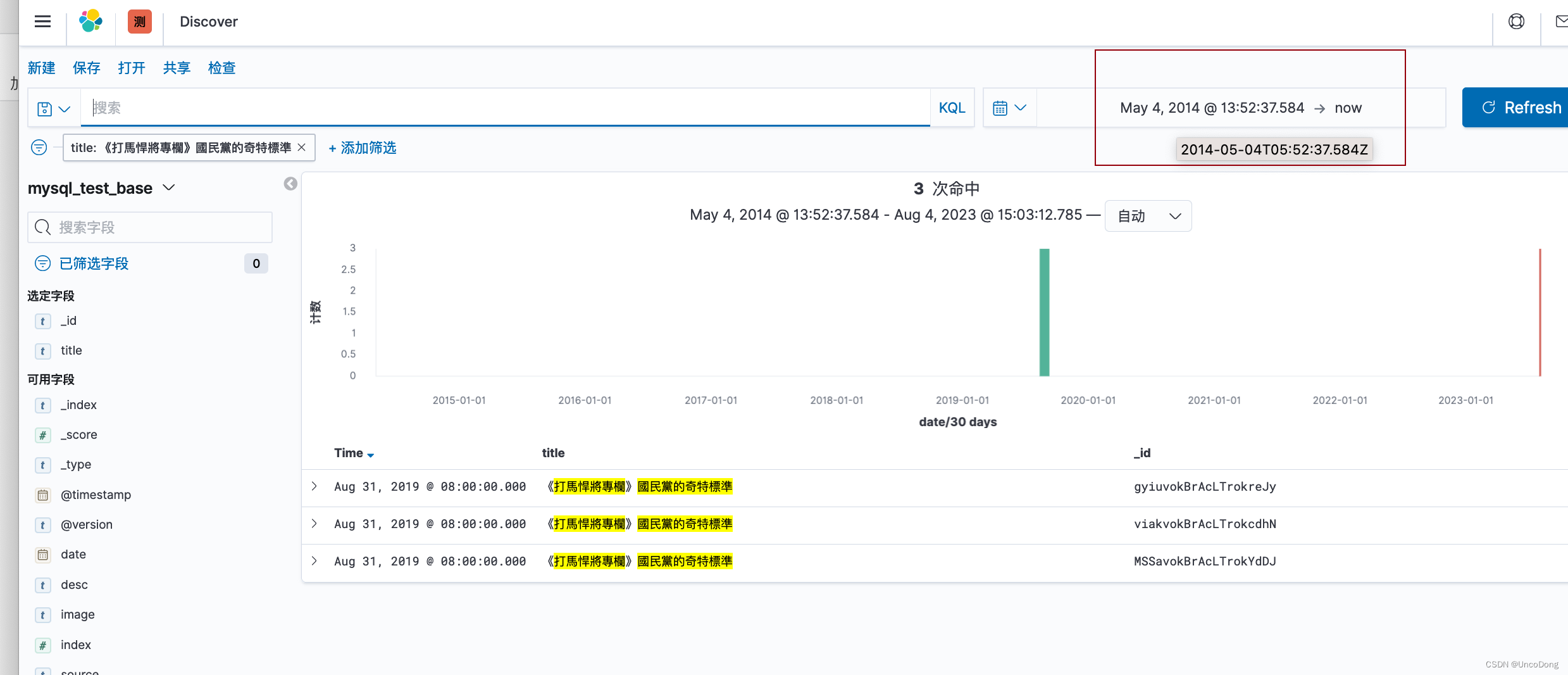
根据{IP}:5601访问kibana,对于刚刚插入数据库的数据进行检索。
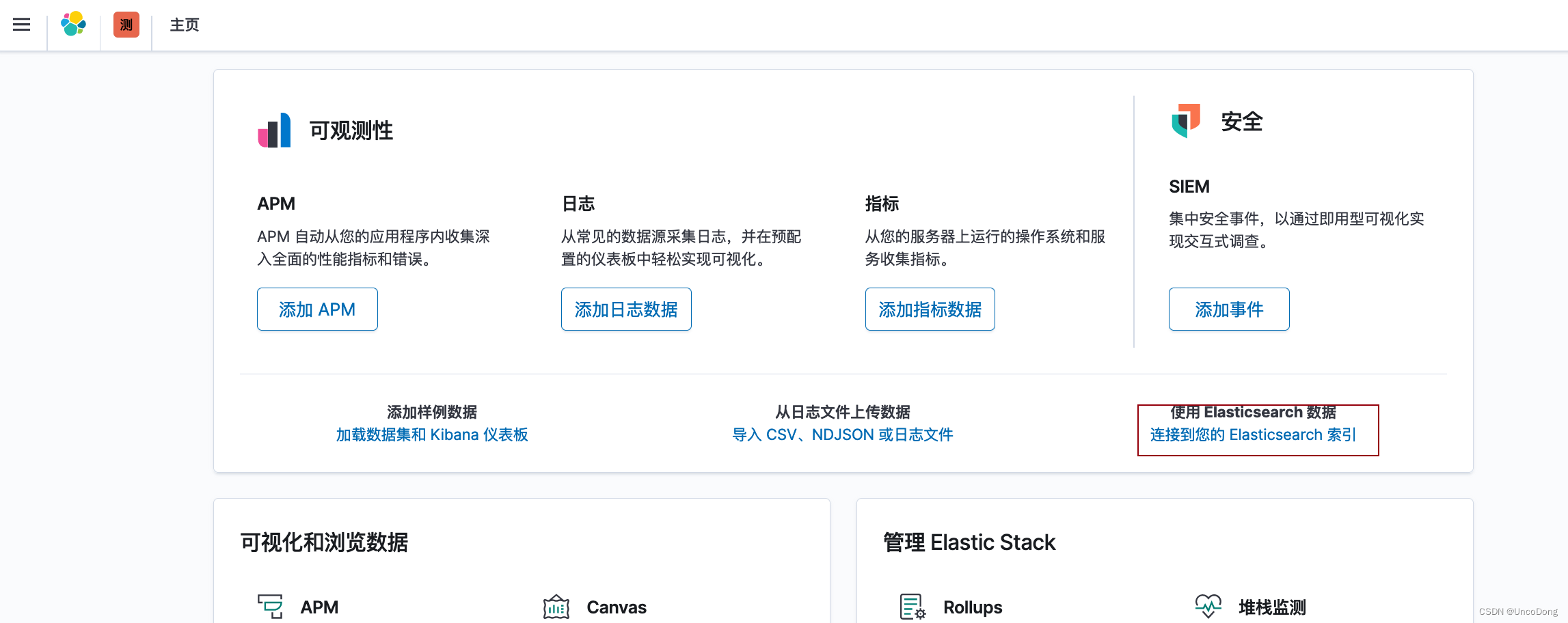
输入索引,并选择时间字段。
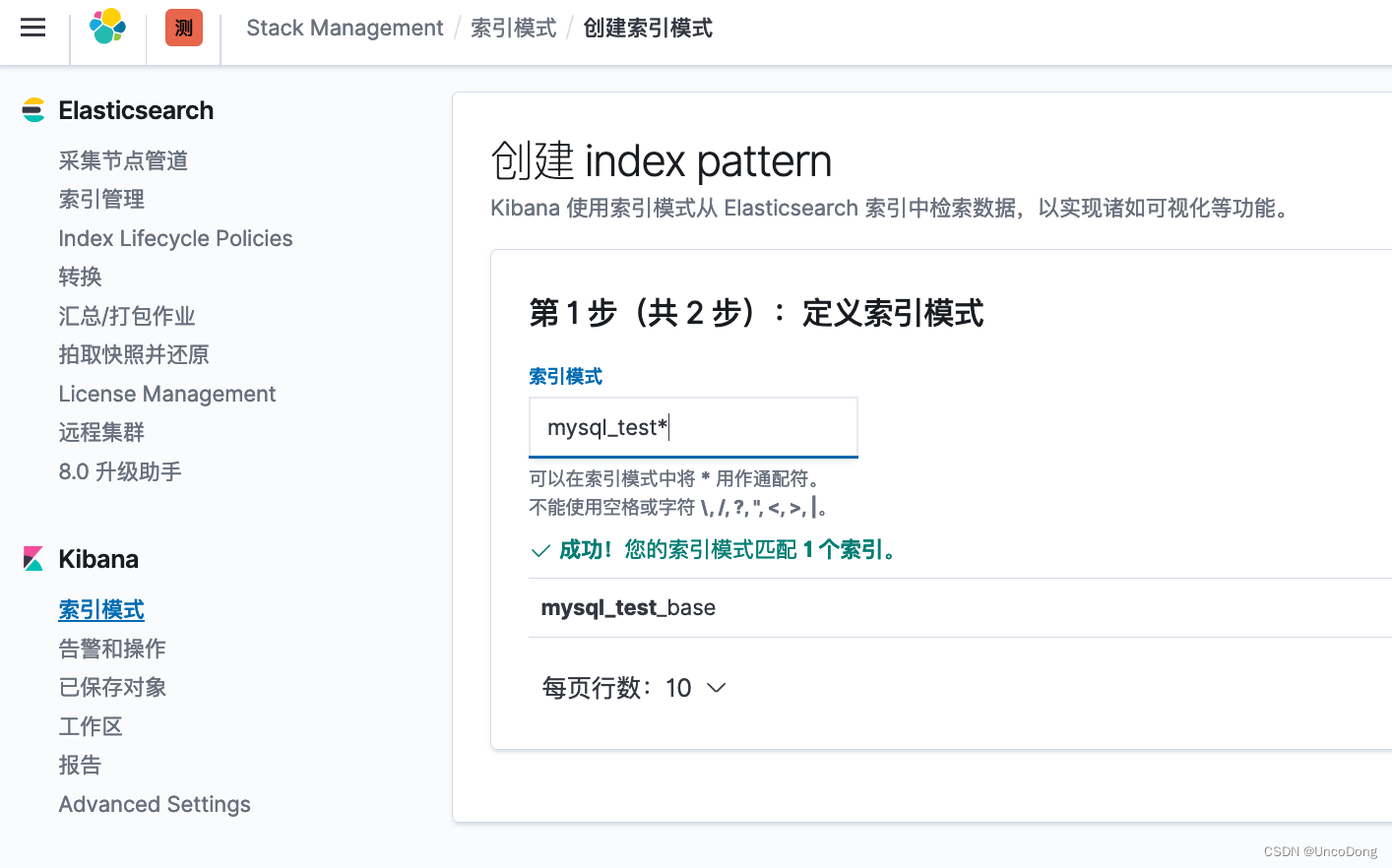
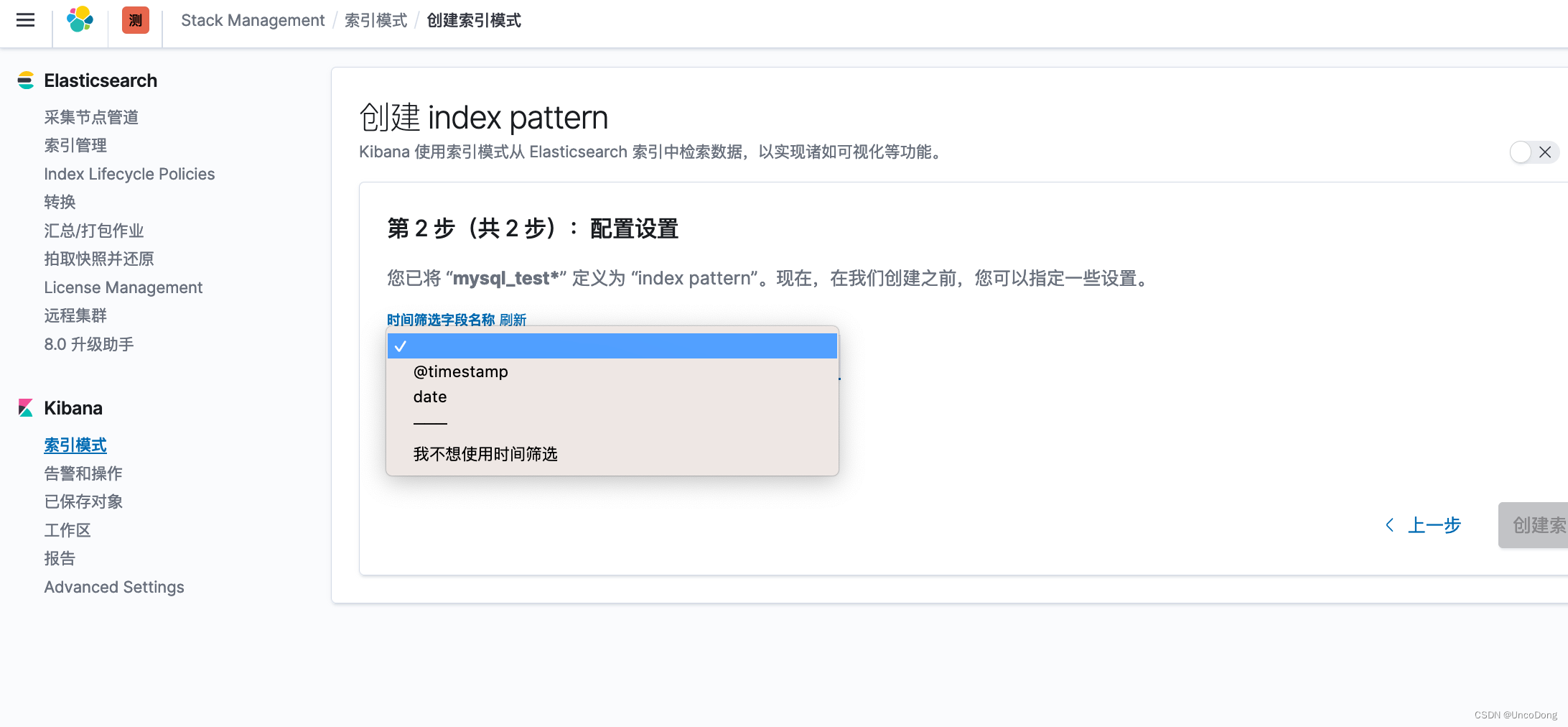
完成上面一步就ok了
2. 展示数据
进入discover展示数据
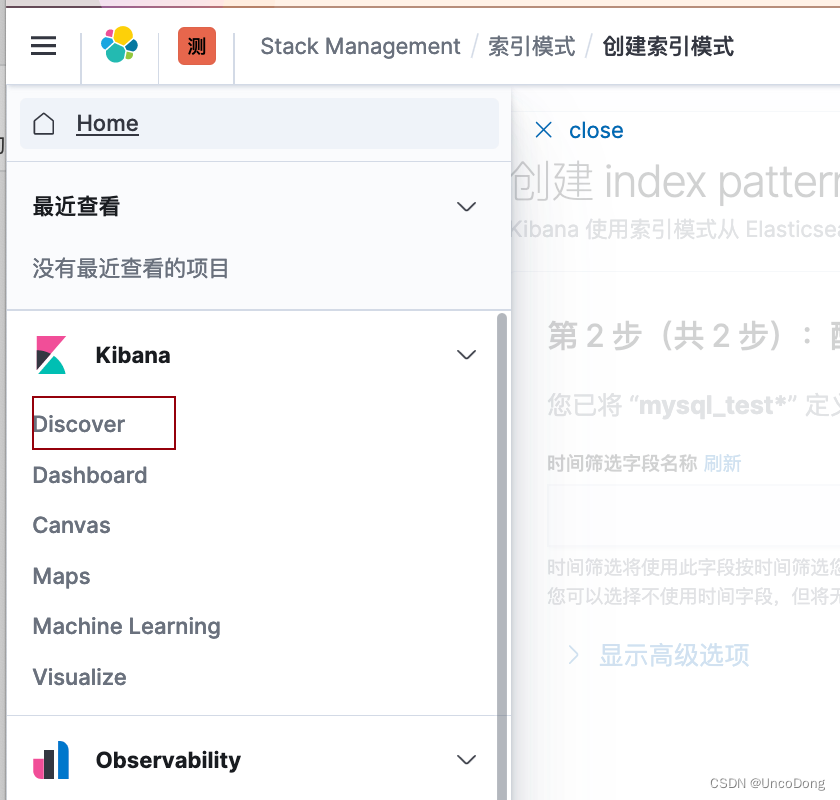
注意:如果时间字段用的过去的时间,而不是插入数据库的时间,需要在搜索的时候需要格外注意时间设置,比如我用的是新闻发布的时间作为时间字段