一、说明
由于OpenAI的ChatGPT的巨大成功引发了大语言模型的繁荣,许多人预见到大图像模型的下一个突破。在这个领域,可以提示视觉模型分析甚至生成图像和视频,其方式类似于我们目前提示 ChatGPT 的方式。
用于大型图像模型的最新深度学习方法已经分支到两个主要方向:基于卷积神经网络(CNN)的方法和基于变压器的方法。本文将重点介绍 CNN 端,并提供这些改进的 CNN 内核结构的高级概述。
二. 可变形卷积网络 (DCN)
2.1 关于感受野
传统上,CNN内核已应用于每层中的固定位置,导致所有激活单元具有相同的感受野。
如下图所示,要对输入特征映射 x 执行卷积,每个输出位置 p0 的值计算为核权重 w 和 x 上的滑动窗口之间的逐元素乘法和求和。 滑动窗口由网格 R 定义,它也是 p0 的感受野。 R 的大小在同一 y 层内的所有位置上保持不变。

使用 3x3 内核进行常规卷积操作。
每个输出值的计算方法如下:
![]()
从纸张开始的常规卷积操作函数。
其中 pn 枚举滑动窗口(网格 R)中的位置。
RoI(感兴趣区域)池化操作也在每层中具有固定大小的箱上运行。对于包含 nij 像素的 (i, j)-th bin,其池化结果计算如下:
![]()
来自纸张的常规平均 RoI 池函数。
同样,每层箱的形状和大小都相同。

使用 3x3 箱的常规平均 RoI 池操作。
因此,对于编码语义的高级层(例如,具有不同比例的对象)来说,这两种操作都变得特别成问题。
DCN提出了可变形卷积和可变形池化,它们更灵活地对这些几何结构进行建模。两者都在 2D 空间域上运行,即在整个通道维度上的操作保持不变。
2.2 可变形卷积

具有 3x3 内核的可变形卷积操作。
给定输入特征映射 x,对于输出特征映射 y 中的每个位置 p 0,DCN 在枚举常规网格 R 中的每个位置 p n 时添加 2D 偏移量 △pn。
![]()
纸的可变形卷积函数。
这些偏移是从前面的特征图中学习的,通过特征图上的附加卷积层获得。由于这些偏移通常是分数,因此它们通过双线性插值实现。
2.3 可变形的投资回报池
与卷积操作类似,池化偏移量 △pij 被添加到原始分档位置。
![]()
论文 可变形RoI池化功能。
如下图所示,这些偏移是在原始池化结果之后通过全连接 (FC) 层学习的。

可变形平均 RoI 池化操作,带 3x3 箱。
2.4 可变形位置感知 (PS) 投资回报率池化
如下图所示,当将可变形操作应用于PS RoI池化(Dai等人,n.d.)时,偏移量应用于每个分数图而不是输入特征图。这些偏移是通过卷积层而不是 FC 层学习的。
位置敏感 RoI 池化(Dai 等人,N.D.):传统的 RoI 池化会丢失有关每个区域代表哪个对象部分的信息。PS RoI池化通过将输入特征图转换为每个对象类的k²分数图来保留此信息,其中每个得分图代表一个特定的空间部分。因此,对于 C 对象类,存在总 k² (C+1) 分数图。

3x3 可变形 PS RoI 池化图示 |来源于纸张。
三、 DCNv2
尽管DCN允许对感受野进行更灵活的建模,但它假设每个感受野内的像素对响应的贡献相等,但事实往往并非如此。为了更好地理解贡献行为,作者使用三种方法来可视化空间支持:
- 有效感受野:节点响应相对于每个图像像素的强度扰动的梯度
- 有效采样/箱位置:网络节点相对于采样/箱位置的梯度
- 误差边界显著区域:逐步屏蔽图像的各个部分,以找到产生与整个图像相同的响应的最小图像区域
为了将可学习的特征幅度分配给感受野内的位置,DCNv2引入了调制的可变形模块:
![]()
DCNv2卷积函数来自纸张,修改符号以匹配DCN论文中的符号。
对于位置 p0,偏移量 △pn 及其振幅 △mn 可通过应用于同一输入特征图的单独卷积层来学习。
DCNv2 通过为每个 (i,j) 个箱添加可学习幅度 △mij 来类似地修改可变形 RoI 池。
![]()
DCNv2 从论文文章汇集功能,修改符号以匹配 DCN 纸张中的符号。
DCNv2 还扩展了可变形卷积层的使用,以取代 ResNet-3 中 conv5 中的常规卷积层到 conv50 阶段。
四、 DCNv3
为了降低DCNv2的参数大小和内存复杂度,DCNv3对内核结构进行了以下调整。
- 灵感来自深度可分卷积(Chollet,2017)
深度可分离卷积将传统卷积解耦为:1.深度卷积:输入特征的每个通道分别用滤波器卷积;2. 逐点卷积:跨通道应用的 1x1 卷积。
作者建议将特征振幅m作为深度部分,并将格网中位置之间共享的投影权重w作为逐点部分。
2. 受群卷积启发(Krizhevsky, Sutskever and Hinton, 2012)
组卷积:将输入通道和输出通道拆分为组,并对每个组应用单独的卷积。
DCNv3(Wang 等人,2023 年)建议将卷积分成 G 组,每个组具有单独的偏移量 △p gn 和特征振幅 △mgn。
因此,DCNv3的表述为:

DCNv3卷积函数来自纸张,修改符号以匹配DCN论文中的符号。
其中 G 是卷积群的总数,wg 是位置无关紧要的,△mgn 由 softmax 函数归一化,因此网格 R 上的和为 1。
五、性能
到目前为止,基于 DCNv3 的 InternImage 在检测和分割等多个下游任务中表现出卓越的性能,如下表所示,以及带有代码的论文的排行榜。有关更详细的比较,请参阅原始论文。

COCO val2017 上的对象检测和实例分段性能。FLOP 使用 1280×800 个输入进行测量。AP' 和 AP' 分别表示框 AP 和掩码 AP。“MS”是指多尺度培训。来源于纸张。
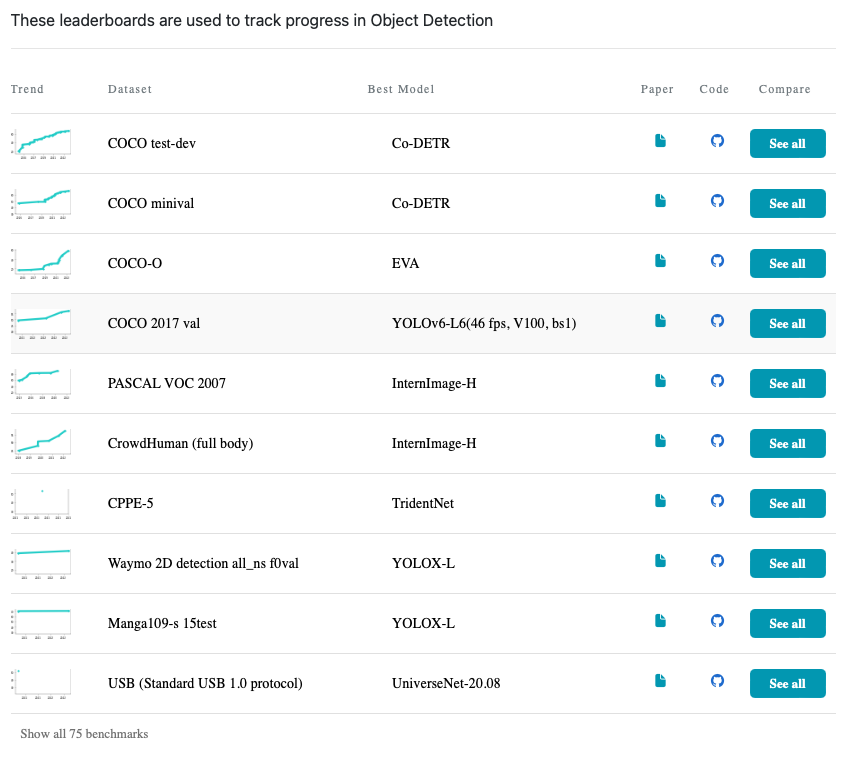
来自 paperswithcode.com 的对象检测的排行榜屏幕截图。
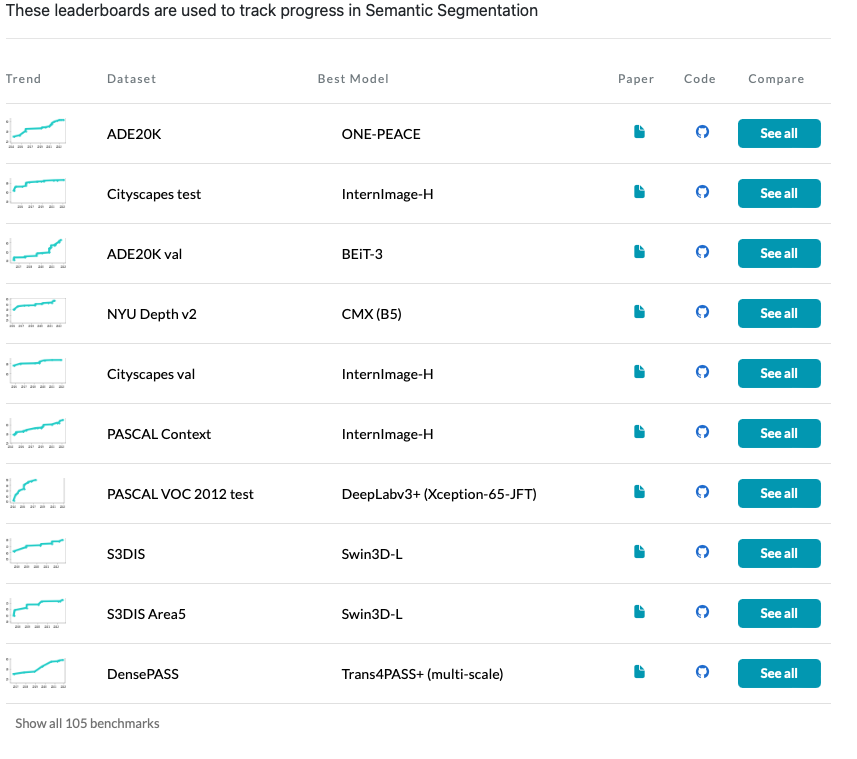
paperswithcode.com 语义分割的排行榜屏幕截图。
六、总结
在本文中,我们回顾了常规卷积网络的核结构,以及它们的最新改进,包括可变形卷积网络(DCN)和两个较新版本:DCNv2和DCNv3。我们讨论了传统结构的局限性,并强调了基于先前版本的创新进步。要更深入地了解这些模型,请参阅参考文献部分中的论文。