如果源码不编译,是无法实现自动跳转的,
Redis在win上编译有点麻烦,我是使用的CentOS环境,Clion编译
编译完就可以直接通过shell连接Redis server了
server.c 中放的是就是主类 :6000多行左右是入口main()函数位置
Redis的使用:
通过redis.conf 文件的如下位置 配置 Redis有多少个数据库:

select 0 select 1对应就是数据库的序号,16个数据库对应0-15下标
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
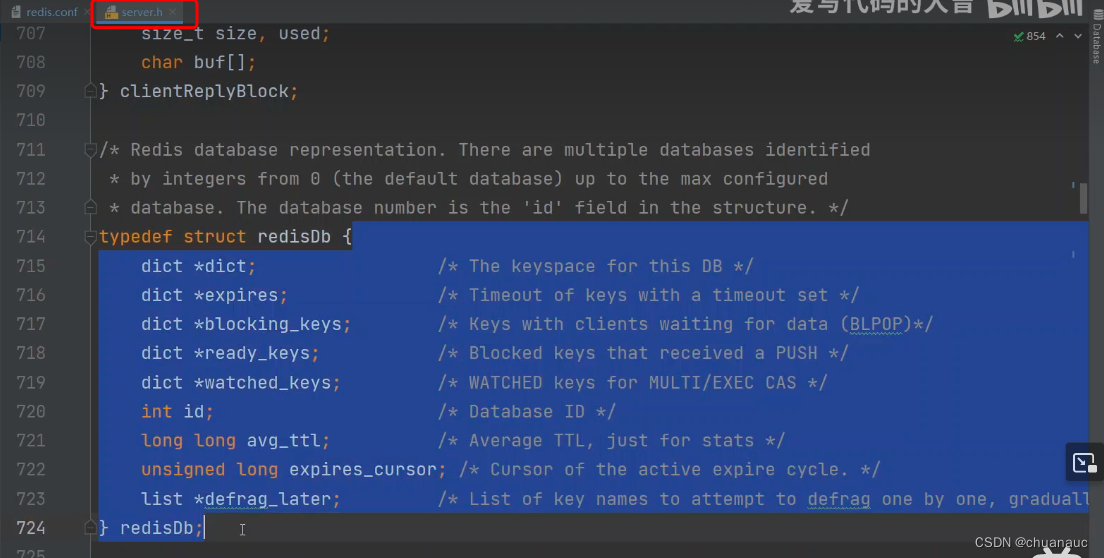
下图就是数据库的结构:
其中最重要的一项就是存放该数据库key-value对的:715行 dict 类型的 *dict指针
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
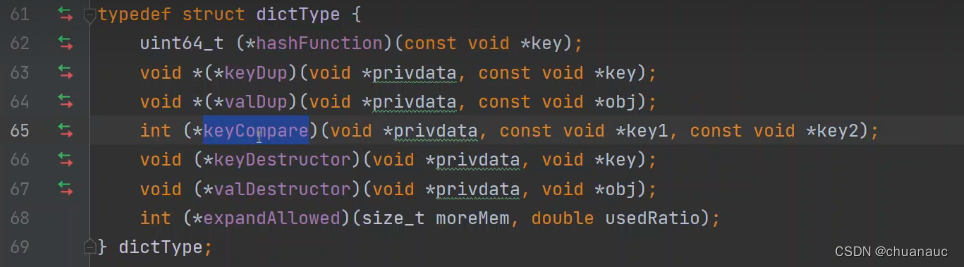
dict 数据类型如下定义:
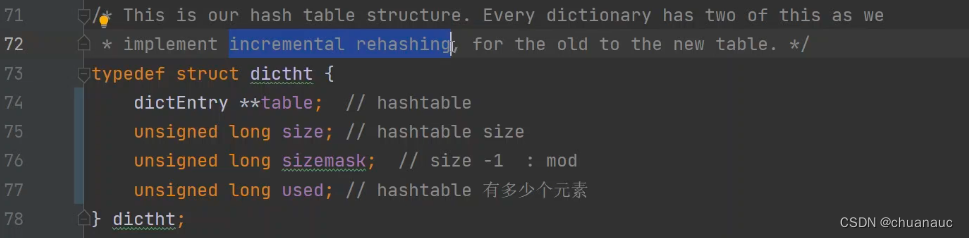
83行有两个dictht 类型的数组:就是对应存放 老HashTable 和 新扩容的HashTable

。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
62:hashFunction() 给出 key 求对应的哈希值
65:keyCompare() 比较两个Key是否一致,是否出现冲突,一致的话执行后续逻辑操作
。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。。
HashTable的数据结构
Redis 底层设计方式,Redis底层 如何 管理数据:
Redis通过 HashTable 来 存放数据:
我们知道 Redis 维护的是一个个 key-value 的项entry,而组织存放这些entry的数据结构是 HashTable,HashTable是一个数组:
通过对 entry 中 key 的 hash() 处理,并且按照HashTable大小取模,这样,把key对应到为一个int 值。该 int 值作为下标,HashTable[i] 中就存放 该entry 的 value 内容的地址,即,存放的是指向value值存放空间的指针(注意,HashTable中存的是地址,不是把entry直接存进去了)
由于hash函数会导致哈希冲突,即,不同的key可能会哈希到同一个值:Redis 通过拉链法,即,在HashTable的值指向一个个 结构体:结构体内容包括:key值,value的地址,和 next指针(用于指向下一个哈希到相同位置的entry条目),同时每次出现哈希冲突,新的entry对应的结构体以头插法的方式插入到链表头部,新头插的entry可能会在最近被访问的概率大
而哈希冲突越来越频繁的时候,拉链越来越长,找到一个对应的entry时间也越来越长,此时,HashTable就会考虑扩容:HashTable扩容的条件是:若出现一条拉链链表的长度>HashTable的长度,那么,HashTable扩容。
HashTable扩容的方式:成倍扩容:原来HashTable长度是 8 ,扩容后会开辟一个新的大小为8*2=16的空间,放置扩容的HashTable。
而后将旧的HashTable中的拉链上的各个entry结构体重新执行哈希函数,插入到扩容后的HashTable中。这个操作就被称为 rehash
主动渐进式将entry移动到新的HashTable中,操作是:不管get set 等任何访问HashTable的操作,只要访问了HashTable,就按顺序移动一个hash槽(一个哈希槽对应所有被哈希函数处理后对应到该位置的entry)内的所有内容。这么做是由于,我们使用Redis就是为了加速,而大批量新旧HashTable的数据转移会影响Redis正常功能,因此要渐进式移动数据。
在渐进式移动HashTable时,调用get()要求获得某个数据的value:执行顺序 :先去旧HashTable寻找,找不到再去新的HashTable寻找
调用set()时,直接向新的HashTable中插入(这就是为啥访问get时,会出现key找不到,是因为get的value是新set的数据,已经被插入到新的HashTable中了)
Redis 的 key 数据类型:
Redis 在使用时,key可以是 整形、浮点、字符串 、音频视频等,但实际上,Redis服务器端会将无论是什么数据类型的key都转换成 String对象
SDS数据类型:
【SDS相较于char[] 做了哪些优化】
(一)减少len这个属性占的空间:
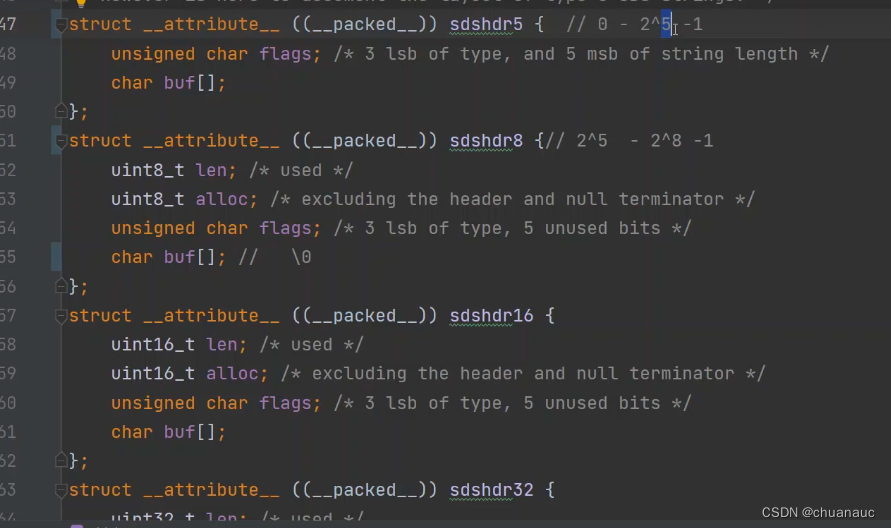
3.2和3.2版本之前SDS 数据结构用 int 来描述SDS的buf[]长度:
int占4个字节,但是buf[]长度可能只有10个,造成SDS实例空间浪费
结局方案是:Redis6版本提出了SDS 新的数据类型实现:sdshdr5
结构中包括:char类型的 flag,和 存放内容的buf[]
char占8字节,前3位用于表明这是个SDS的数据类型,后5位用来指示buf[]的长度
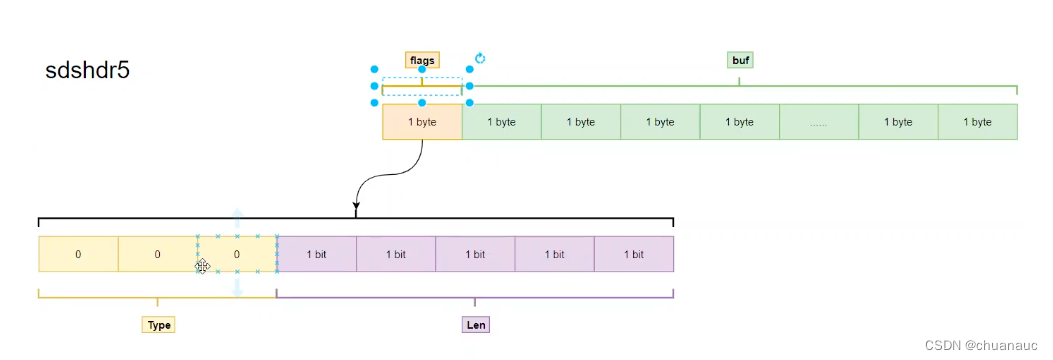
啥叫SDS数据类型:因为SDS为了不同长度的buf定义了多种不同的 sdshdrX 数据类型,有sdshdr5 , sdshdr8 等等:
(二)预分配、懒回收:
定义字符串 ss = "lalala"时,系统会自动 malloc出6个char大小存放
此时我们想在后面加一个字符,就得重新malloc(),malloc()函数调用要很长的时间,因此,每次出现扩容需求的时候,若扩容内容<1M : 倍增原来的buf数组长度,若>1M,则满足新的buf数组的长度后在追加1M的大小
SDS的free变量(在6版本的Redis中改了个名字 叫 alloc,还是一个意思一个用法)就是记录这个每次与分配后,还剩余的空间(free也因为buf的长度不同 优化为了 uint8_t 或者 uint16_t)
(三)Redis 赋值buf[]时,也会 以 `\0`结尾,为了兼容C语言,其实就是为了少写点函数,用用C语言的函数
(四)二进制安全,即使buf[]中出现 `\0`也没关系,不会被处理为内容结束