1. TensorBoard介绍
TensorBoard是TensorFlow推出的可视化工具,可以可视化模型结构、跟踪并以表格形式显示模型指标。
TensorBoard的使用包括两个步骤:
- 在代码中设置TensorBoard,在训练的过程中将会根据设置产生日志文件
- 在浏览器中可视化该日志文件,查看网络结构、loss的变化情况等
下面以 LeNet-5 为例,介绍如何在TensorFlow和PyTorch中配置TensorBoard。
2. 代码中设置TensorBoard
2.1 TensorFlow中设置
2.1.1 使用说明
在TensorFlow通过两个简单步骤即可使用TensorBoard(更多的功能可参考官方文档)。
-
tensorboard_callback = keras.callbacks.TensorBoard(log_dir='logs/tf'):初始化日志文件。其中,log_dir是日志文件的存放位置 -
model.fit(callbacks=[tensorboard_callback]):设置回调函数,在模型训练期间将会调用tensorboard_callback从而向日志文件中写入数据注意:
日志文件的绝对路径中不能包含中文!
2.1.2 代码实现
LeNet-5 的搭建可参考[TensorFlow搭建神经网络]https://blog.csdn.net/qq_41100617/article/details/132122966)
import time
import tensorflow as tf
from keras import datasets
from keras import layers
from tensorflow import keras
def my_model(input_shape):
# 首先,创建一个输入节点
inputs = keras.Input(input_shape)
# 搭建神经网络
x = layers.Conv2D(filters=6, kernel_size=(5, 5), strides=(1, 1), activation='relu')(inputs)
x = layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2))(x)
x = layers.Conv2D(filters=16, kernel_size=(5, 5), strides=(1, 1), activation='relu')(x)
x = layers.AveragePooling2D(pool_size=(2, 2), strides=(2, 2))(x)
x = layers.Flatten()(x)
x = layers.Dense(units=16 * 4 * 4, activation='relu')(x)
x = layers.Dense(units=120, activation='relu')(x)
# 输出层
outputs = layers.Dense(units=10, activation='softmax')(x)
model = keras.Model(inputs=inputs, outputs=outputs)
return model
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
train_images = tf.reshape(train_images, (train_images.shape[0], train_images.shape[1], train_images.shape[2], 1))
train_images = tf.cast(train_images, tf.float32)
test_images = tf.reshape(test_images, (test_images.shape[0], test_images.shape[1], test_images.shape[2], 1))
test_images = tf.cast(test_images, tf.float32)
model = my_model(train_images.shape[1:])
loss = keras.losses.SparseCategoricalCrossentropy()
optimizer = keras.optimizers.SGD(0.0001)
model.compile(loss=loss, optimizer=keras.optimizers.SGD(0.00001))
# 初始化日志文件
tensorboard_callback = keras.callbacks.TensorBoard(
log_dir='logs/tf/' + time.strftime('%m-%d-%H-%M', time.localtime(time.time())))
# 在训练过程中设置回调
model.fit(train_images, train_labels, validation_split=0.3, epochs=1000, batch_size=20,
callbacks=[tensorboard_callback])
pre_labels = model.predict(test_images)
2.2 PyTorch中设置
2.2.1 使用说明
PyTorch1.1之后添加了TensorBoard,在PyTorch中使用TensorBoard主要有3个步骤(具体信息可查看其官方文档):
SummaryWriter:创建一个日志文件,主要有以下两个参数:log_dir:保存日志文件的目录,默认值为runs/当前日期时间(存放的路径中不能包含中文!)comment:log_dir取默认值时添加到log_dir后面的后缀,当设置了log_dir时,该值无效
add_XXX: 向创建好的日志文件里面添加数据,常用的有:add_graph:添加GRAPHS,其中存放了网络结构。有以下两个常用参数:model:模型input_to_model:模型的输入数据
add_scalar: 添加SCALARS,其中可以存放折线图数据用于显示训练过程中的损失值变化情况。有以下三个常用参数:tag:折线图的标签。指定tag时,加入/分割,可将多个折线图放在一个tag下,如 :tag=train/loss, tag=train/map,此时train下面会有loss和map两个折线图scalar_value:折线图纵轴的值,一般是loss、准确率等数据global_step:折线图的横轴,一般是epoch
add_scalars:在一张折线图中同时绘制多个数据,有以下三个常用参数:main_tag,:与add_scalar中的tag用法一样tag_scalar_dict:纵轴的值,因为是多个数据,需要以字典形式传入(具体看下面代码实现)global_step:与add_scalar中的global_setp用法一样
close:结束log写入,一般用在训练结束后
类似于操作文件,SummaryWriter 也可以和 with 一起使用,此时可以不需显示调用 close ,如:
writer = SummaryWriter()
# 写入数据……
writer.close()
#上面的代码等价于下面
with SummaryWriter() as w:
# 写入数据……
2.2.2 代码实现
LeNet-5 的搭建可参考PyTorch搭建神经网络
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from sklearn.metrics import classification_report
from torch import optim
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
from tqdm import tqdm
class LeNet(nn.Module):
def __init__(self, in_channels):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=6, kernel_size=5, stride=1)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5, stride=1)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.fc1 = nn.Linear(in_features=16 * 4 * 4, out_features=120)
self.fc2 = nn.Linear(in_features=120, out_features=84)
self.fc3 = nn.Linear(in_features=84, out_features=10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.pool2(x)
x = x.reshape(x.shape[0], -1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
return x
def main():
batch_size = 8
num_epochs = 10
train_dataset = torchvision.datasets.MNIST(root="data/", train=True, transform=transforms.ToTensor(),
download=True)
val_dataset = torchvision.datasets.MNIST(root="data/", train=False, transform=transforms.ToTensor(), download=True)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size,
shuffle=True)
val_loader = DataLoader(dataset=val_dataset, batch_size=batch_size, shuffle=True)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = LeNet(1).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
writer = SummaryWriter(
'logs/pt/' + time.strftime('%m-%d-%H-%M', time.localtime(time.time()))) # 设置了存放位置,此时即使设置了 comment 也不起作用
writer.add_graph(model, torch.randn(1, 1, 28, 28)) # 先写入模型结构
for epoch in tqdm(range(num_epochs)):
train_loss = 0
val_loss = 0
accuracy = 0
macro_avg_f1 = 0
weighted_avg_f1 = 0
# 训练模型
for batch_idx, (data, label) in enumerate(train_loader):
data = data.to(device=device)
label = label.to(device=device)
pre = model(data)
loss = criterion(pre, label)
train_loss = (train_loss * batch_idx + loss) / (batch_idx + 1)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 评估模型
with torch.no_grad():
model.eval()
for batch_idx, (data, label) in enumerate(val_loader):
data = data.to(device=device)
label = label.to(device=device)
pre = model(data)
loss = criterion(pre, label).item()
val_loss = (val_loss * batch_idx + loss) / (batch_idx + 1)
pre = torch.argmax(pre, dim=1)
score = classification_report(pre, label, output_dict=True)
accuracy = (accuracy * batch_idx + score['accuracy']) / (batch_idx + 1)
macro_avg_f1 = (macro_avg_f1 * batch_idx + score['macro avg']['f1-score']) / (batch_idx + 1)
weighted_avg_f1 = (weighted_avg_f1 * batch_idx + score['weighted avg']['f1-score']) / (batch_idx + 1)
model.train()
writer.add_scalar('val/accuracy', accuracy, epoch) # 在一个 tag 下面添加多个折线图
writer.add_scalar('val/macro avg-f1', macro_avg_f1, epoch)
writer.add_scalar('val/weighted avg-f1', weighted_avg_f1, epoch)
writer.add_scalars('loss', {'train_loss': train_loss, 'val_loss': val_loss}, epoch) # 一个折线图里面显示多个数据
writer.close() # 训练结束,不再写入数据,关闭writer
if __name__ == '__main__':
main()
3. 可视化
注意,这里如果直接输入tensorboard使用的是系统python环境里面的tensorboard,因此,务必确保系统python环境中已安装了tensorboard。
打开 log 所在的文件夹,在该文件夹下打开命令行窗口(1.在路径显示框中输入 cmd 然后回车即可打开 或者 2. 在文件夹中按住 Shift 键同时右击鼠标然后选择‘在此处打开Powershell窗口’),输入:
tensorboard --logdir=.\logs --port=6007
其中:
- –logdir:存放日志文件的文件夹
- –port:端口号,默认是6006
若正常,将显示以下信息:

打开浏览器,在地址栏中输入:localhost:6007(端口号要和上面保持一致)。即可看到可视化的效果,点击不同的标签可查看不同数据
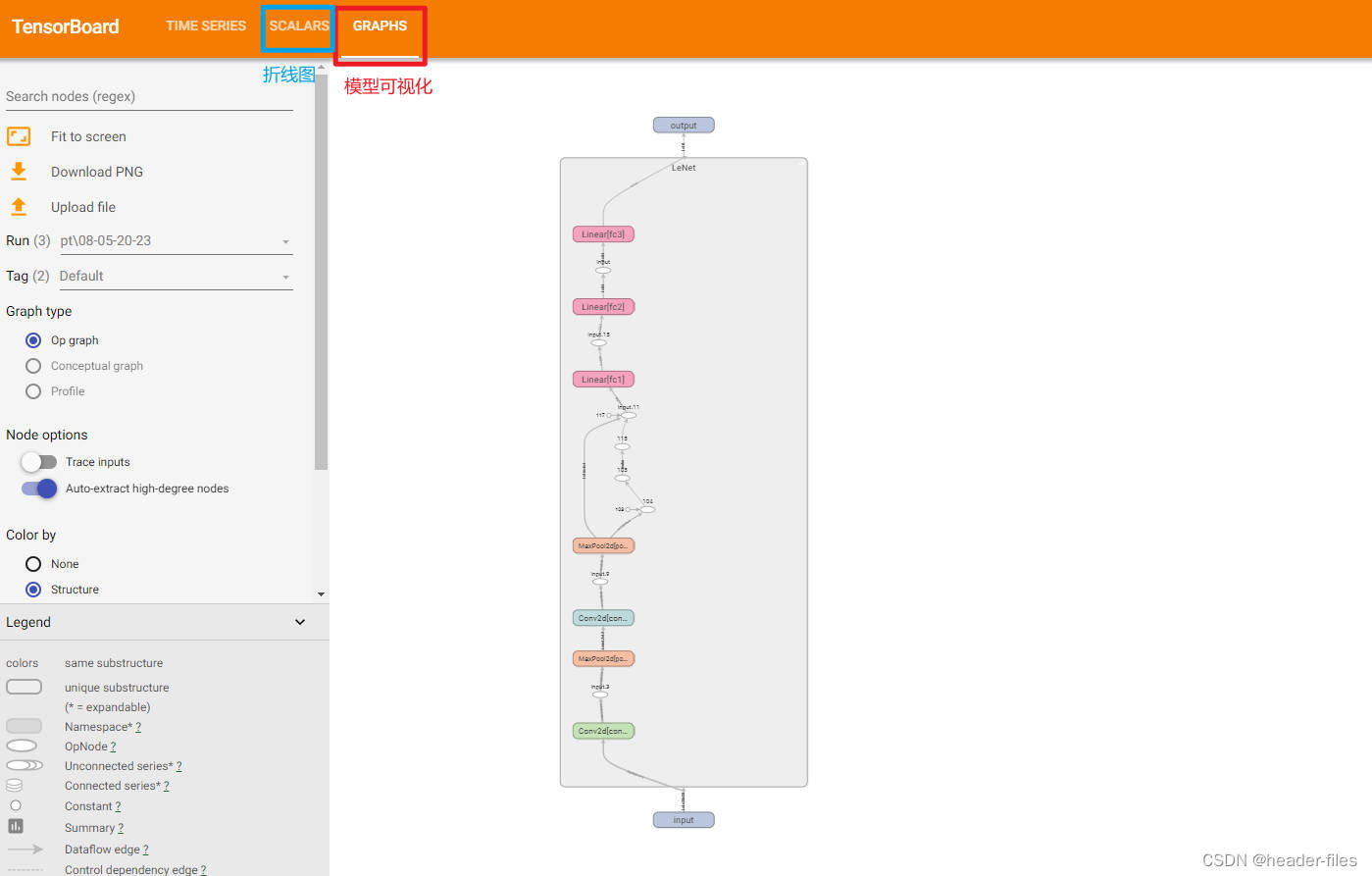
4. 配合远程服务器使用
上面的代码和浏览器都在同一个电脑上,有时需要在服务器上跑代码,这时候要想在自己的电脑浏览器上可视化TensorBoard,可以按照下面的方式:
4.1 端口转发
在电脑命令行窗口输入:
ssh -L 6008:127.0.0.1:6007 服务器用户名@服务器IP地址 -p 22
这将在连接服务器的同时将服务器上的 6007 端口转发到本地的 6008 端口。
成功连接服务器后,按照上面讲的可视化的方法在服务器对应的目录下输入:
tensorboard --logdir=日志文件的存放路径 --port=6007
成功启动后,在电脑的浏览器中输入:localhost:6008 。这里用到了两个端口号,一个是服务器上tensorboard使用的端口号 6007 ,一个是本地转发以及浏览器使用的端口号 6008 ,注意区分。
4.2 Xshell建立隧道
在Xshell中选择需要设置的会话,然后右键选择属性,进行如下设置
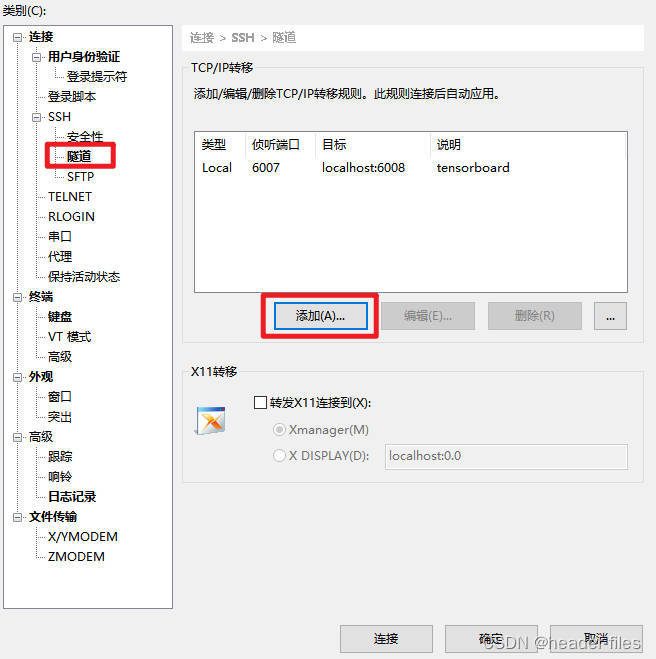
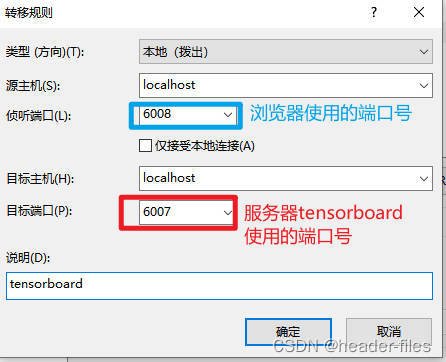
设置完之后连接服务器,在服务器对应的目录下输入:
tensorboard --logdir=日志文件的存放路径 --port=6007
成功启动后,在电脑的浏览器中输入:localhost:6008 。这里用到了两个端口号,一个是服务器上tensorboard使用的端口号 6007 ,一个是浏览器使用的端口号 6008 ,注意区分。