项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域):汇总有意义的项目设计集合,助力新人快速实战掌握技能,助力用户更好利用 CSDN 平台,自主完成项目设计升级,提升自身的硬实力。

-
专栏订阅:项目大全提升自身的硬实力
-
[专栏详细介绍:项目设计集合(人工智能方向):助力新人快速实战掌握技能、自主完成项目设计升级,提升自身的硬实力(不仅限NLP、知识图谱、计算机视觉等领域)
ChatGenTitle:使用百万arXiv论文信息在LLaMA模型上进行微调的论文题目生成模型

- 相关信息
- 1.训练数据集在Cornell-University/arxiv,可以直接使用;
- 2.正式发布LLaMa-Lora-7B-3 和 LLaMa-Lora-7B-3-new 版本的LoRA模型权重,允许本地部署使用;
-
- 完成了基于alpaca-lora 上进行的
LLaMa-Lora-7B-3和LLaMa-Lora-13B-3模型微调;
- 完成了基于alpaca-lora 上进行的
-
- 开始了一项长期进行在
arXiv上定时爬取cs.AI 、cs.CV 、cs.LG 论文的任务,目的是为了支持 CS 相关方向的研究;
- 开始了一项长期进行在
- 5.整理了
220W+篇arXiv论文的元信息,这些元信息包括:title和abstract,更多的有:id、submitter、authors、comments、journal-ref、doi、categories、versions;
1.项目背景
科研论文写作中,生成一个有吸引力的、准确的论文标题需要综合考虑多个因素,这是论文作者面临的一个重要挑战。生成一个论文标题的难点有:
- 简洁但准确:一个好的论文标题应该简洁、精炼,但同时又能准确地反映出论文研究的重点和核心所在,这对于作者来说是一个巨大的挑战。
- 独特但易于理解:论文题目应该是独特的,能够吸引读者的兴趣,但同时也要易于理解,避免过于笼统或过于繁琐深奥的词汇。
- 体现研究的贡献:好的论文题目应该能够明确体现出研究的贡献,突出研究创新点,使读者对该研究的贡献显而易见。
- 避免使用口头禅:一些常用的词汇、短语等可能被过多的使用,这样会使得论文的题目显得陈旧、无创新性,甚至会让人感到毫无意义。
最近,以ChatGPT、GPT-4等为代表的大语言模型(Large Language Model, LLM)掀起了新一轮自然语言处理领域的研究浪潮,展现出了类通用人工智能(AGI)的能力,受到业界广泛关注。在这些工作以外,许多学者开始关注以低成本实现个人"ChatGPT"的方案,如:stanford_alpaca[1]、alpaca-lora[2],这些方案聚焦于大模型微调,然而我们更期望探索大模型在下游任务的落地。
为此,我们关注到论文题目生成领域,ArXiv(全称为:The arXiv.org e-Print archive)是一个由康奈尔大学创建和维护的一个免费、开放的学术预印本社区,它于1991年创立。ArXiv是全球数学、物理学等学科的电子预印本和会议论文库,包含了众多的高质量学术论文和研究报告,覆盖面日益增广。arXiv中包含了众多高质量的论文元信息。通过arXiv上开放的论文信息,我们构建了一个包含220万篇论文元信息的数据库。这些数据通过数据清洗等被构建成了可以用于大模型微调的数据对。
将这些论文元信息引入大模型微调,它可以对生成论文题目涉及的难点产生积极影响,它可以从以下几个方面提供帮助:
- 提供更准确、广泛的语言模型:大模型通常使用了大量数据进行训练,因此其语言模型可以更准确地解释自然语言,能够应对更多的语言场景,提升论文题目的语言表达能力。
- 提供更加精准的语义理解:大模型采用了深度学习的技术手段,能够构建语言的高维向量表示,从而提供更准确的语义理解能力,帮助生成更精确、准确的论文题目。
- 增强创造性和创新性:大模型使用了大量的训练数据,并能够从数据中提取规律,从而提供更多的词汇或句子组合方式,增强了生成论文题目的创造性和创新性。
- 提高效率:相比传统的手动方式,使用大模型来生成论文题目可以极大地提高效率,不仅减少了需要写出标题的时间,同时也不容易产生显著的错误,提高了输出的质量。
总之,引入大模型可以提供更好的帮助来解决生成论文题目的难点,有望提升分析、抽象、创新等能力。
2.arXiv数据集介绍
我们所搜集的论文元信息包含全部的学科分类,如:
- 计算机科学(Computer Science)
- 数学(Mathematics)
- 物理学(Physics)
- 统计学(Statistics)
- 电气工程和系统科学(Electrical Engineering and Systems Science)
- 经济学(Economics)
- 量子物理(Quantum Physics)
- 材料科学(Materials Science)
- 生物学(Biology)
- 量化金融(Quantitative Finance)
- 信息科学(Information Science)
- 交叉学科(Interdisciplinary)。
每个大类下面还有很多具体的子类,如计算机科学大类下又包括计算机视觉、机器学习、人工智能、计算机网络等子类。如果您想找到特定领域的论文,可以根据这些分类进行选择。
每一篇论文都包含如下字段的元信息:
{
"id":string"0704.0001",
"submitter":string"Pavel Nadolsky",
"authors":string"C. Bal\'azs, E. L. Berger, P. M. Nadolsky, C.-P. Yuan",
"title":string"Calculation of prompt diphoton production cross sections at Tevatron and LHC energies",
"comments":string"37 pages, 15 figures; published version",
"journal-ref":string"Phys.Rev.D76:013009,2007",
"doi":string"10.1103/PhysRevD.76.013009",
"report-no":string"ANL-HEP-PR-07-12",
"categories":string"hep-ph",
"license":NULL,
"abstract":string" A fully differential calculation in perturbative quantum chromodynamics is presented for the production of massive photon pairs at hadron colliders. All next-to-leading order perturbative contributions from quark-antiquark, gluon-(anti)quark, and gluon-gluon subprocesses are included, as well as all-orders resummation of initial-state gluon radiation valid at next-to-next-to-leading logarithmic accuracy. The region of phase space is specified in which the calculation is most reliable. Good agreement is demonstrated with data from the Fermilab Tevatron, and predictions are made for more detailed tests with CDF and DO data. Predictions are shown for distributions of diphoton pairs produced at the energy of the Large Hadron Collider (LHC). Distributions of the diphoton pairs from the decay of a Higgs boson are contrasted with those produced from QCD processes at the LHC, showing that enhanced sensitivity to the signal can be obtained with judicious selection of events. ",
"versions":
}
- id: ArXiv ID (can be used to access the paper, see below)
- submitter: Who submitted the paper
- authors: Authors of the paper
- title: Title of the paper
- comments: Additional info, such as number of pages and figures
- journal-ref: Information about the journal the paper was published in
- doi: [https://www.doi.org](Digital Object Identifier)
- abstract: The abstract of the paper
- categories: Categories / tags in the ArXiv system
- versions: A version history
3.LLMs微调
ChatGenTitle基于Meta的LLaMA模型进行微调,微调主流的方法有:Instruct微调和LoRa微调。
Instruct微调和LoRa微调是两种不同的技术。Instruct微调是指在深度神经网络训练过程中调整模型参数的过程,以优化模型的性能。在微调过程中,使用一个预先训练好的模型作为基础模型,然后在新的数据集上对该模型进行微调。Instruct微调是一种通过更新预训练模型的所有参数来完成的微调方法,通过微调使其适用于多个下游应用。LoRa微调则是指对低功耗广域网(LoRaWAN)中的LoRa节点参数进行微调的过程,以提高节点的传输效率。在LoRa微调中,需要了解节点的硬件和网络部署情况,并通过对节点参数进行微小调整来优化传输效率。与Instruct微调相比,LoRA在每个Transformer块中注入可训练层,因为不需要为大多数模型权重计算梯度,大大减少了需要训练参数的数量并且降低了GPU内存的要求。 研究发现,使用LoRA进行的微调质量与全模型微调相当,速度更快并且需要更少的计算。因此,如果有低延迟和低内存需求的情况,建议使用LoRA微调。
因此我们选择使用LoRA微调构建整个ChatGenTitle。
#下载项目
git clone https://github.com/tloen/alpaca-lora.git
#安装依赖
pip install -r requirements.txt
#转化模型
python src/transformers/models/llama/convert_llama_weights_to_hf.py \
--input_dir ../model/ \
--model_size 7B \
--output_dir ../model/7B-hf
#单机单卡训练模型
python finetune.py \
--base_model '../model/7B-hf' \
--data_path '../train.json' \
--output_dir '../alpaca-lora-output'
#单机多卡(4*A100)训练模型
WORLD_SIZE=4 CUDA_VISIBLE_DEVICES=0,1,2,3 torchrun --nproc_per_node=4 --master_port=3192 finetune.py \
--base_model '../model/7B-hf' \
--data_path '../train.json' \
--output_dir '../alpaca-lora-output' \
--batch_size 1024 \
--micro_batch_size 128 \
--num_epochs 3
- 在线访问
在开始部署使用之前,我们需要知道两个模型的定义。整个项目会有LLaMA和LoRA两种模型,LoRA模型是我们微调产生保存的权重,LLaMA 权重则是由Meta公司开源的大模型预训练权重。我们可以将生成的LoRA权重认为是一个原来LLaMA模型的补丁权重。因此我们要同时加载两种不同模型。目前我们已经提供的LoRA模型有:
| 模型名称 | 微调数据 | 微调基准模型 | 模型大小 | 微调时长 |
|---|---|---|---|---|
| LLaMa-Lora-7B-3 | arXiv-50-all | LLaMa-7B | 148.1MB | 9 hours |
| LLaMa-Lora-7B-3-new | arXiv-50-all | LLaMa-7B | 586MB | 12.5 hours |
| LLaMa-Lora-13B-3 | arXiv-100-all | LLaMa-13B | 230.05MB | 26 hours |
更多模型将会很快发布!
准备好需要的两种权重,就可以开启使用:
#推理
python generate.py \
--load_8bit \
--base_model '../model/7B-hf' \
--lora_weights '../alpaca-lora-output'
当模型运行以后,访问127.0.0.1:7860即可。

然后在Instruction中输入:
If you are an expert in writing papers, please generate a good paper title for this paper based on other authors' descriptions of their abstracts.
在Input中输入:
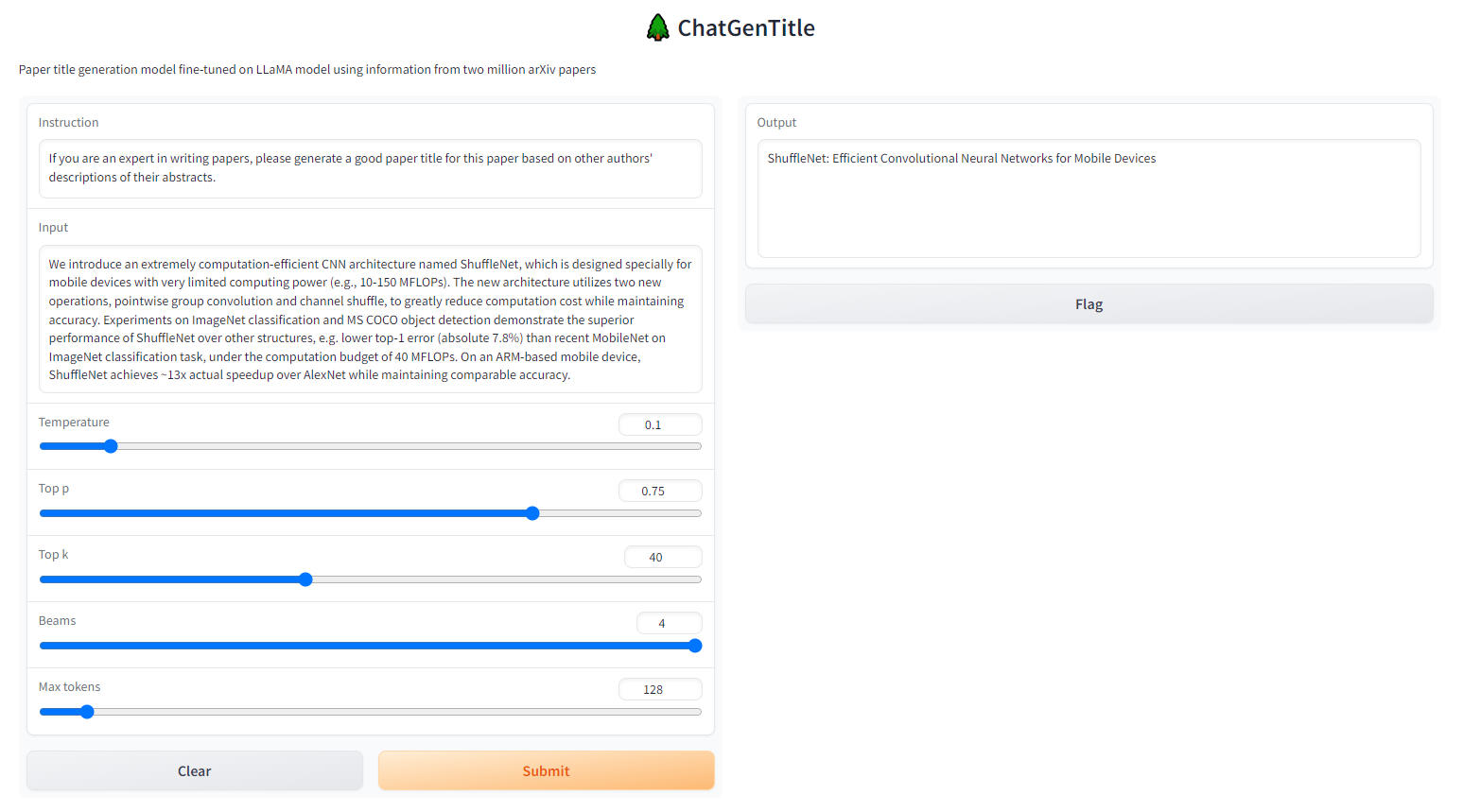
<你论文的摘要>:Waste pollution is one of the most important environmental problems in the modern world. With the continuous improvement of the living standard of the population and the increasing richness of the consumption structure, the amount of domestic waste generated has increased dramatically and there is an urgent need for further waste treatment of waste. The rapid development of artificial intelligence provides an effective solution for automated waste classification. However, the large computational power and high complexity of algorithms make convolutional neural networks (CNNs) unsuitable for real-time embedded applications. In this paper, we propose a lightweight network architecture, Focus-RCNet, designed with reference to the sandglass structure of MobileNetV2, which uses deeply separable convolution to extract features from images. The Focus module is introduced into the field of recyclable waste image classification to reduce the dimensionality of features while retaining relevant information. In order to make the model focus more on waste image features while keeping the amount of parameters computationally small, we introduce the SimAM attention mechanism. Additionally, knowledge distillation is used to further compress the number of parameters in the model. By training and testing on the TrashNet dataset, the Focus-RCNet model not only achieves an accuracy of 92%, but also has high mobility of deployment.
点击Submit等待即可!

Output输出即为ChatGenTitle为你生成的论文题目。
4.模型效果展示
Note:Meta发布的LLaMA模型禁止商用,因此这里我们开源的是LoRA模型,LoRA模型必须搭配对应版本的LLaMA模型使用才可以
| 模型名称 | 微调数据 | 微调基准模型 | 模型大小 | 微调时长 | 微调效果 |
|---|---|---|---|---|---|
| ✅LLaMa-Lora-7B-3 | arXiv-50-all | LLaMa-7B | -MB | 9 hours |  |
|✅LLaMa-Lora-7B-3-new |arXiv-50-all|LLaMa-7B|-MB|12.5 hours| |
|
|✅LLaMa-Lora-7B-cs-3-new |arXiv-cs |LLaMa-7B|-MB|20.5 hours|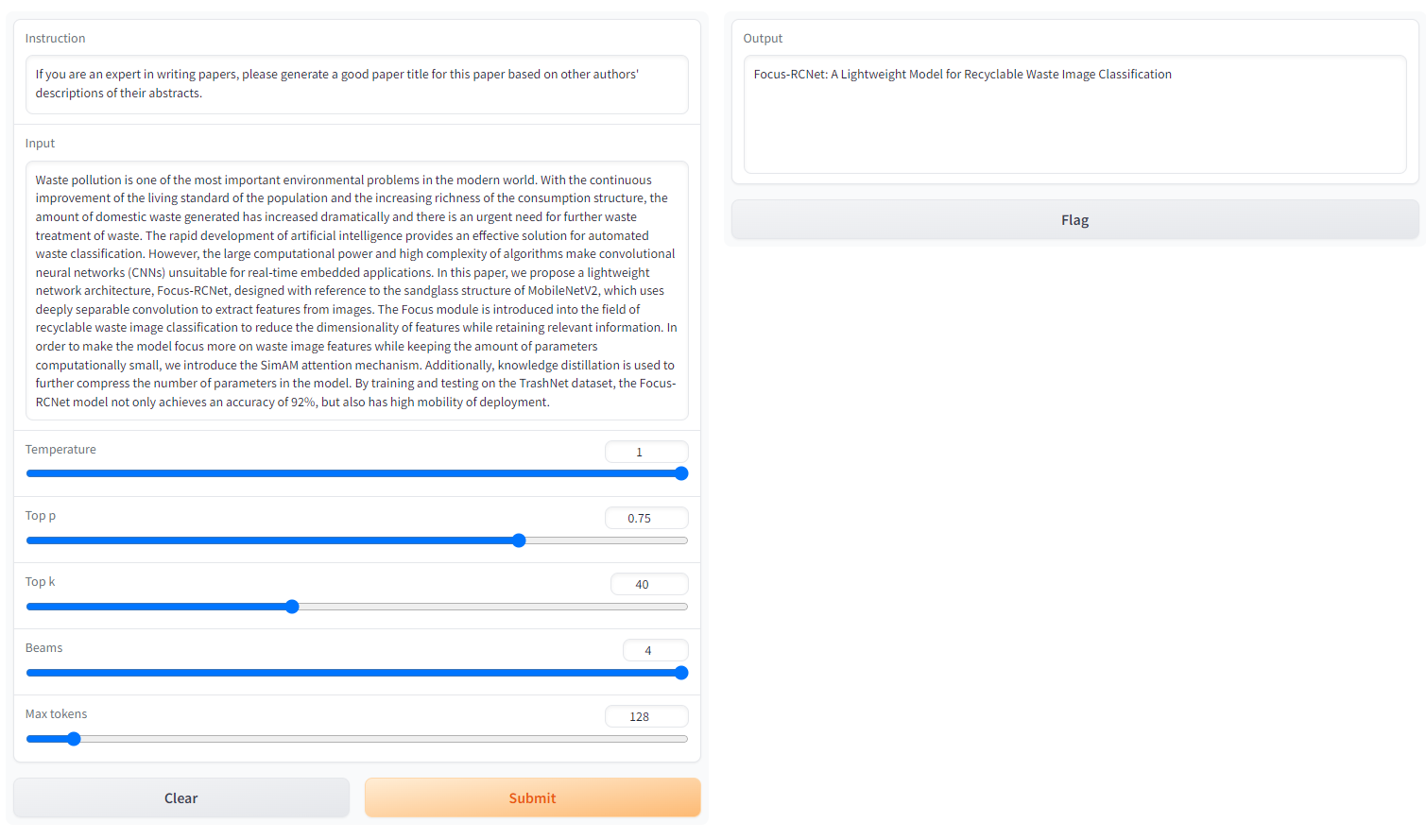 |
|
|✅LLaMa-Lora-7B-cs-6-new |arXiv-cs|LLaMa-7B|-MB|34 hours| |
|
|✅LLaMa-Lora-13B-3 |arXiv-100-all|LLaMa-13B|-MB|26 hours| |
|
- 训练设置:实验在A100 (4卡, 80GB)上进行
5.LLM效果对比
| 提示词 | 摘要 | 原始论文题目 | ChatGenTitle | ChatGPT(GPT3.5) | GPT4 | ChatGLM(130B) |
|---|---|---|---|---|---|---|
| 提示词① | 摘要① | Focus-RCNet: A lightweight recyclable waste classification algorithm based on Focus and knowledge distillation | Focus-RCNet: A Lightweight Convolutional Neural Network for Recyclable Waste Image Classification | Focus-RCNet: A lightweight deep learning model for automated waste classification with enhanced recyclable waste image feature recognition | Efficient Waste Classification with Focus-RCNet: A Lightweight Deep Learning Architecture Employing Sandglass Structure, SimAM Attention Mechanism, and Knowledge Distillation for Real-Time Embedded Applications | 超过Token长度 |
| 提示词② | 摘要② | ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices | ShuffleNet: Efficient Convolutional Neural Networks for Mobile Devices | ShuffleNet: A Computation-Efficient CNN Architecture for Mobile Devices with Superior Performance in Object Detection and ImageNet Classification while Maintaining Accuracy | ShuffleNet: A Computationally Efficient CNN Architecture for Mobile Devices with Enhanced Performance in ImageNet Classification and MS COCO Object Detection | ShuffleNet: An Extremely Computation-Efficient CNN Architecture for Mobile Devices |
| 提示词③ | 摘要③ | Segment Anything | Segment Anything | Segment Anything: Introducing a New Task, Model, and Dataset for Promptable Image Segmentation with Superior Zero-Shot Performance | Exploring the Segment Anything Project: A Promptable Image Segmentation Model and Extensive Dataset with Impressive Zero-Shot Performance | Segment Anything (SA) Project: A New Task, Model, and Dataset for Image Segmentation |
5.1.提示词①和摘要①
- 提示词①:If you are an expert in writing papers, please generate a good paper title for this paper based on other authors’ descriptions of their abstracts.
- 摘要①:Waste pollution is one of the most important environmental problems in the modern world. With the continuous improvement of the living standard of the population and the increasing richness of the consumption structure, the amount of domestic waste generated has increased dramatically and there is an urgent need for further waste treatment of waste. The rapid development of artificial intelligence provides an effective solution for automated waste classification. However, the large computational power and high complexity of algorithms make convolutional neural networks (CNNs) unsuitable for real-time embedded applications. In this paper, we propose a lightweight network architecture, Focus-RCNet, designed with reference to the sandglass structure of MobileNetV2, which uses deeply separable convolution to extract features from images. The Focus module is introduced into the field of recyclable waste image classification to reduce the dimensionality of features while retaining relevant information. In order to make the model focus more on waste image features while keeping the amount of parameters computationally small, we introduce the SimAM attention mechanism. Additionally, knowledge distillation is used to further compress the number of parameters in the model. By training and testing on the TrashNet dataset, the Focus-RCNet model not only achieves an accuracy of 92%, but also has high mobility of deployment.
5.2 提示词②和摘要②
- 提示词②:If you are an expert in writing papers, please generate a good paper title for this paper based on other authors’ descriptions of their abstracts.
- 摘要②:We introduce an extremely computation-efficient CNN architecture named ShuffleNet, which is designed specially for mobile devices with very limited computing power (e.g., 10-150 MFLOPs). The new architecture utilizes two new operations, pointwise group convolution and channel shuffle, to greatly reduce computation cost while maintaining accuracy. Experiments on ImageNet classification and MS COCO object detection demonstrate the superior performance of ShuffleNet over other structures, e.g. lower top-1 error (absolute 7.8%) than recent MobileNet on ImageNet classification task, under the computation budget of 40 MFLOPs. On an ARM-based mobile device, ShuffleNet achieves ~13x actual speedup over AlexNet while maintaining comparable accuracy.
5.3 提示词③和摘要③
- 提示词③:If you are an expert in writing papers, please generate a good paper title for this paper based on other authors’ descriptions of their abstracts.
- 摘要③:We introduce the Segment Anything (SA) project: a new task, model, and dataset for image segmentation. Using our efficient model in a data collection loop, we built the largest segmentation dataset to date (by far), with over 1 billion masks on 11M licensed and privacy respecting images. The model is designed and trained to be promptable, so it can transfer zero-shot to new image distributions and tasks. We evaluate its capabilities on numerous tasks and find that its zero-shot performance is impressive – often competitive with or even superior to prior fully supervised results. We are releasing the Segment Anything Model (SAM) and corresponding dataset (SA-1B) of 1B masks and 11M images.
6.QA
- 关于Instruct微调和LoRa微调
Instruct微调和LoRa微调是两种不同的技术。
Instruct微调是指在深度神经网络训练过程中调整模型参数的过程,以优化模型的性能。在微调过程中,使用一个预先训练好的模型作为基础模型,然后在新的数据集上对该模型进行微调。Instruct微调是一种通过更新预训练模型的所有参数来完成的微调方法,通过微调使其适用于多个下游应用。
LoRa微调则是指对低功耗广域网(LoRaWAN)中的LoRa节点参数进行微调的过程,以提高节点的传输效率。在LoRa微调中,需要了解节点的硬件和网络部署情况,并通过对节点参数进行微小调整来优化传输效率。与Instruct微调相比,LoRA在每个Transformer块中注入可训练层,因为不需要为大多数模型权重计算梯度,大大减少了需要训练参数的数量并且降低了GPU内存的要求。
研究发现,使用LoRA进行的微调质量与全模型微调相当,速度更快并且需要更少的计算。因此,如果有低延迟和低内存需求的情况,建议使用LoRA微调。
- 为什么会有LLaMA模型和LoRA两种模型?
如1所述,模型的微调方式有很多种,基于LoRA的微调产生保存了新的权重,我们可以将生成的LoRA权重认为是一个原来LLaMA模型的补丁权重 。至于LLaMA 权重,它则是由Mean公司开源的大模型预训练权重。
- 关于词表扩充
加入词表是有一定破坏性的, 一是破坏原有分词体系,二是增加了未训练的权重。所以如果不能进行充分训练的话,可能会有比较大的问题。个人觉得如果不是特别专的领域(比如生物医学等涉及很多专业词汇的领域)没有太大必要去扩充英文词表。 Chinese-LLaMA-Alpaca/issues/16
参考文献
- stanford_alpaca
- alpaca-lora
- ChatDoctor
- Chinese-alpaca-lora
- cabrita
- japanese-alpaca-lora
- Chinese-LLaMA-Alpaca
- FastChat
- LLaMA-Adapter
- LMFlow
- 中文科学文献数据集
项目码源下载
https://download.csdn.net/download/sinat_39620217/88010022