目录
- 1.HTML编码概述
- 2.实体编码
- 3.URLcode编码
- 4.unicode编码
- 5.解码实例
1.HTML编码概述
通常一个网页中可解析的总共有三种编码,每种编码都能用来代替表示字符,按解析顺序依次是“html实体编码”“urlcode码”“Unicode码”,在执行过程中会在HTML环境下先解析“html实体编码”和“urlcode码”,然后查看有无js环境并解析其中的Unicode编码,对于三者的理解都有助于我们绕过限制正则,实行渗透。
2.实体编码
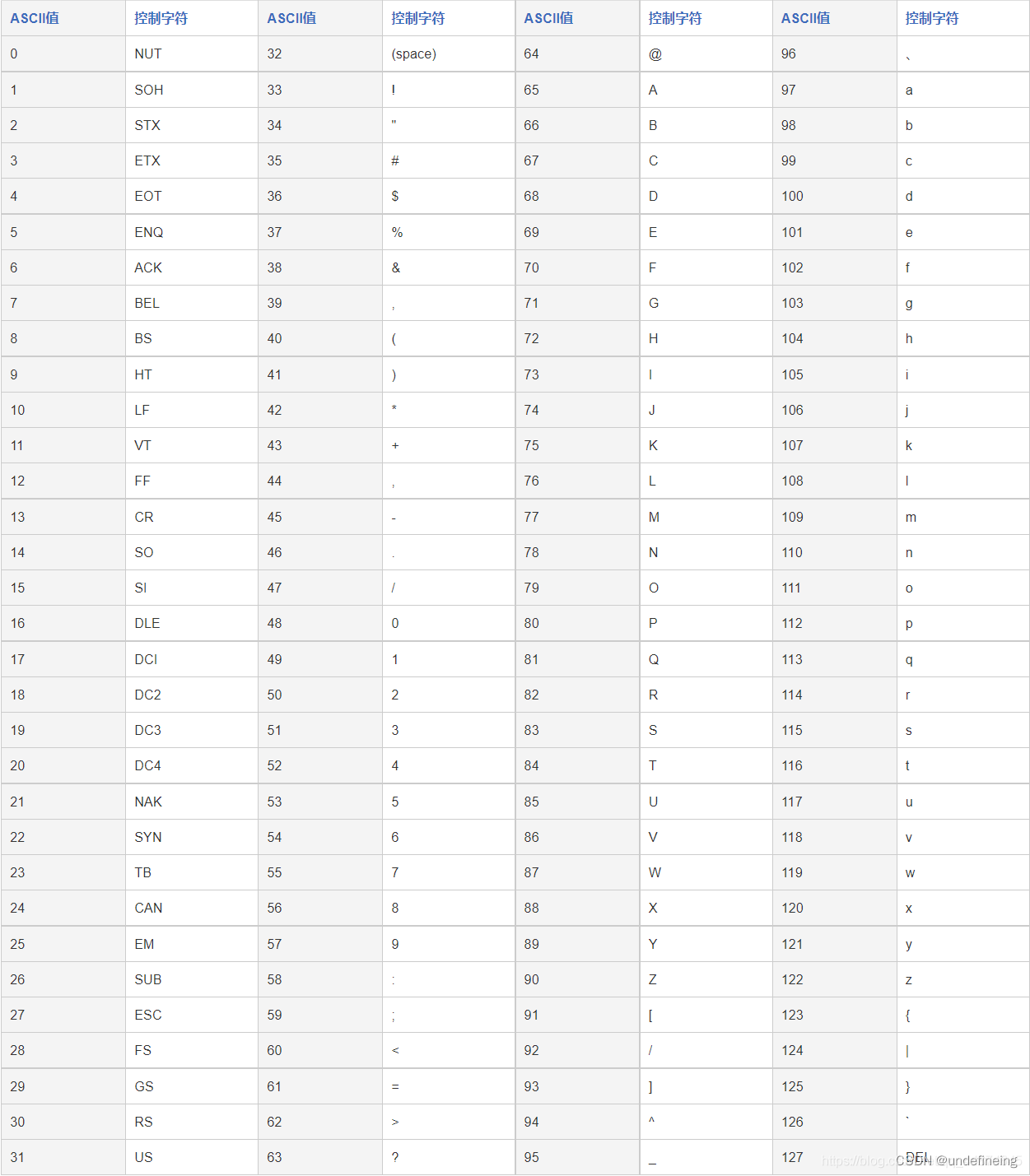
HTML 实体是一段以’&#‘开头、加上ASCII码居中、以分号‘;’结尾的文本,如:“ ;”,实体常常用于显示保留字符,和不可见的字符,作为HTML环境第一次解析的编码,这些字符可能还会进一步被解析为 urlcode、js 代码,以下是ASCII码对照表:
以下是几个举例格式
| 显示结果 | 描述 | 实体名称 | 实体编号 |
|---|---|---|---|
| 空格 | |   | |
| < | 小于号 | < | < |
| > | 大于号 | > | > |
| & | 和号 | & | & |
| " | 引号 | " | " |
| ’ | 撇号 | ' (IE不支持) | ' |
编码可用10进制表示,也可使用16进制表示如:1和1均表示1;
需要提一下的是<和>使用中不会将其内部的数据当做标签处理,解析后会直接当做字符。
3.URLcode编码
URLcode编码同样是对ASCII码的运用,但使用的ASCII码为16进制,且格式为‘%’+ASCII码的形式。同时它也是URL中使用的解析编码,如此处的%27就在URL中表示单引号

4.unicode编码
Unicode码是指万国码,几乎涵盖了所有的文字与字符,utf-8也是其中一种,特指可变长的Unicode编码,它的前127位与ASCII码完全相同,其编码规则如下:
| Unicode十六进制码点范围 | UTF-8二进制 |
|---|---|
| 00000000 - 0000 007F | 0xxxxxxx |
| 0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000 - 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
第一个字节的第一位是 0 ,则说明这个字节对应一个字符;如果一个字节的第一位1,那么连续有多少个 1,就表示该字符占用多少个字节。
“汉”的 Unicode 码点是 0x6c49(110 1100 0100 1001),对照表可知0x0000 6c49 表示字节为3,也就是第三行的 1110xxxx 10xxxxxx 10xxxxxx格式,从“汉”的二进制数最后一位开始,从后向前依次填充对应格式中的 x,多出的 x 则补0,,“汉”的编码可得为 11100110 10110001 10001001,转换成十六进制就是 0xE6 0xB7 0x89。
在网页中只有JavaScript环境才能识别Unicode编码,且格式为\u+16进制码,如\u0061就表示a
值得注意的是尽管Unicode能表示几乎所有字符,但在JavaScript环境下并不能解码任何符号和数字
5.解码实例
以下是一段简单的a标签,其中存在一段html实体编码
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)">测试</a>
按执行流程会先将其解码为:
<a href="javascript:%5c%75%30%30%36%31%5c%75%30%30%36%63%5c%75%30%30%36%35%5c%75%30%30%37%32%5c%75%30%30%37%34(15)">测试</a>
接着它会继续扫描是否存在URLcode码,然后继续解析,得到:
<a href="javascript:\u0061\u006c\u0065\u0072\u0074(15)">测试</a>
再然后进入JavaScript环境继续解析为:
<a href="javascript:alert(15)">测试</a>

]](https://img-blog.csdnimg.cn/71e802c244ee4701956e8be45e6056e8.png)
![[每周一更]-(第57期):用Docker、Docker-compose部署一个完整的前后端go+vue分离项目](https://img-blog.csdnimg.cn/90f5bca6c1e94333b3ba2547fa98c70b.png#pic_center)