2022 CCF BDCI 数字安全公开赛
赛题「Web攻击检测与分类识别」
地址:http://go.datafountain.cn/4Zj
@机器学习战队
获奖方案
团队简介
我们团队由五名成员组成,对机器学习都非常感兴趣,同时在机器学习领域有着丰富的实战经验,对结构化数据,nlp、cv任务都有丰富的经验。在工作和比赛中,都曾获得过一些优异的成绩。
队长:吴绍武,中山大学 网络空间安全专业 在读博士;
队员:冯楠坪、齐福晓、闫利帅来自中企网络通信技术有限公司;
队员:张琦华,加州大学圣塔巴巴拉分校 数学专业。

摘要
本文描述了我们团队针对2022 CCF BDCI Web攻击检测与分类识别这一赛题的解决方案及算法。我们团队的方案是观察数据特点,对数据进行数据统计后进行可视化分析,然后基于针对TF-IDF维度特征的特征工程,包括特征提取、特征融合、特征选择等,使用了Lightgbm建模,利用概率加权对结果进行提升,最终初赛成绩0.96922604,线上排名第四。
关键词
Web攻击日志、TF-IDF、数据增强
赛题与方案思路
1.1 赛题背景
某业务平台平均每月捕获到Web攻击数量超过2亿,涉及常见注入攻击,代码执行等类型。传统威胁检测手段通过分析已知攻击特征进行规则匹配,无法检测未知漏洞或攻击手法。如何快速准确地识别未知威胁攻击并且将不同攻击正确分类,对提升Web攻击检测能力至关重要。利用机器学习和深度学习技术对攻击报文进行识别和分类已经成为解决该问题的创新思路,有利于推动AI技术在威胁检测分析场景的研究与应用。
1.2 任务解读
NLP文本多分类任务,通过对训练集进行机器学习建模学习,提升模型精确率和召回率,然后在测试集上检验模型效果。
1.3 方案思路
数据集共包含6类攻击类型,观察数据集发现不同的攻击类型中包含的文本有明显的差异,比如高频词、中英文、长度、文本结构、特殊字符等,所以选择TF-IDF会是一个非常棒的研究方向。对数据进行统计分析后,进行可视化,分析关键因素。构造特征后,选择使用Lightgbm进行建模,在模型训练过程中,模型参数的选择尤其重要,通过不断的训练,对模型参数进行调整,提升模型效果。
方案架构
2.1 方案流程
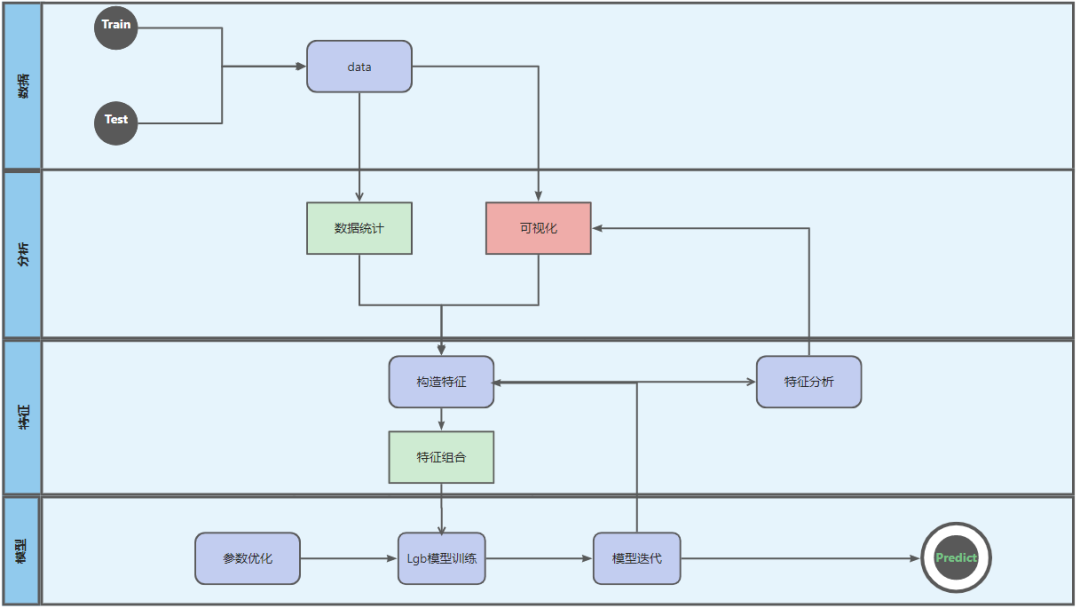
2.2 数据探究
观察各类别数据的基础特征,发现具有鲜明的特征,比如中文文本只在目录遍历中出现;sql注入有非常明显的sql关键词;远程代码执行有非常高频的系统命令词;XSS跨站脚本有明显的http特征,白的文本长度普遍较低。鉴于各类别的数据有明显的文本特征,选择TF-IDF是一个非常好的选择,可以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度,字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。

各类别数据样本量严重不平衡,模型选择Lightgbm,对于处理样本不均衡的数据集效果也很好,所以在此次任务中,没有进行单独的采样处理。
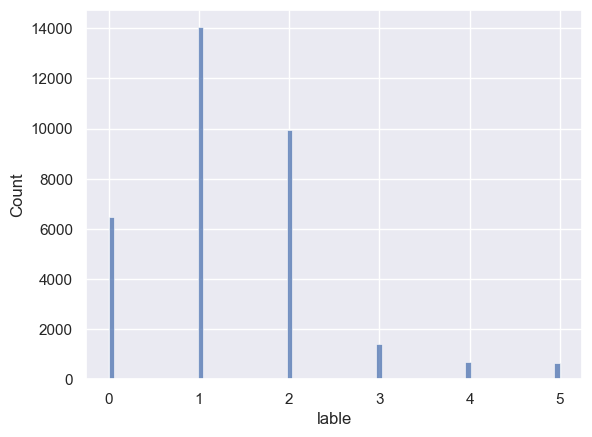
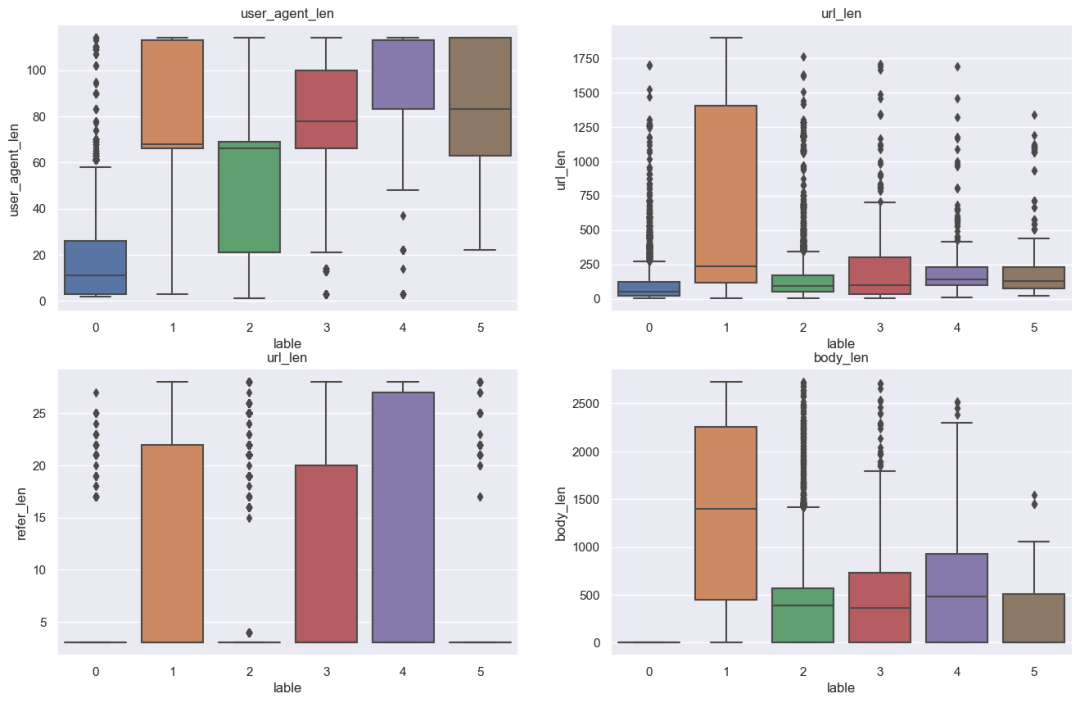
文本长度也是有明显的区别
2.3 特征工程
Method字段是明显的类别特征,所以要针对此字段处理,转成int类型,除{'GET': 0, 'POST': 1, 'PUT': 2, 'HEAD': 3}以外,还有极个别样本为其他类型,也做了异常值的处理。对于user_agent、'url', 'refer', 'body'则提取词频特征;
在提取完词频特征以后,模型效果还是不够理想,继续分析文本特征,值得一提的是,不同的列类别中字符也是明显的不同,如XSS跨站脚本中,因为包含url信息,所以有非常多是“%”等;目录遍历列表中有非常多的“:”,所以提取特殊字符的词频特征也是非常有必要的。同时也需要考虑到特殊字符的顺序组合,比如文件路径。
方案亮点
1. 关键词:通过观察文本,发现不同的分类在关键词特征上非常明显,使用TF-IDF的思想构造词频特征有明显的效果,而且提取词频特征在计算方面也有速度优势。
2. 特殊字符:不同的攻击类别,在日志中包含的特殊字符也是有明显的不一样,在特征中增加特殊字符特征,对模型效果也有明显提升。
3. 特征组合:在原始特征提取的基础上,增加组合特征,丰富特征维度。
4. 通用性:对于文本多分类任务,采用TF-IDF+Lightgbm建模的方式,其思想可以迁移至其他业务场景。
5. 模型参数调优:在特征无法提升的时候,对模型的参数进行调整,进一步增强模型效果。
模型效果
在本地电脑使用CPU进行训练,Train+Predict总时长201.74秒;单样本的预测耗时仅需0.000077秒;在训练结束后,模型的只有13Mb;而模型取得的F1值为0. 96922604。
致谢
感谢DataFountain提供优质比赛平台,感谢中国计算机学会 、大数据协同安全技术国家工程研究中心 、清华大学网络研究院-北京奇虎科技有限公司网络空间测绘联合研究中心、 360信息安全中心。在此次比赛中取得的优异成绩离不开团队成员的通力合作,对于问题多思考,提出来非常好的模型优化建议。此外,也向此次大赛的官方组织者表示由衷的感谢。
参考
[1] Guolin Ke,Qi Meng,LightGBM:A Highly Efficient Grandient Boosting Decision Tree,NIPS 2017。
[2] Search Engines: Information Retrieval in Practice 。





![OJ:C++ | [vector] — 力扣](https://img-blog.csdnimg.cn/50598d9ac0c641e9819d189ee0f65383.png#pic_center)