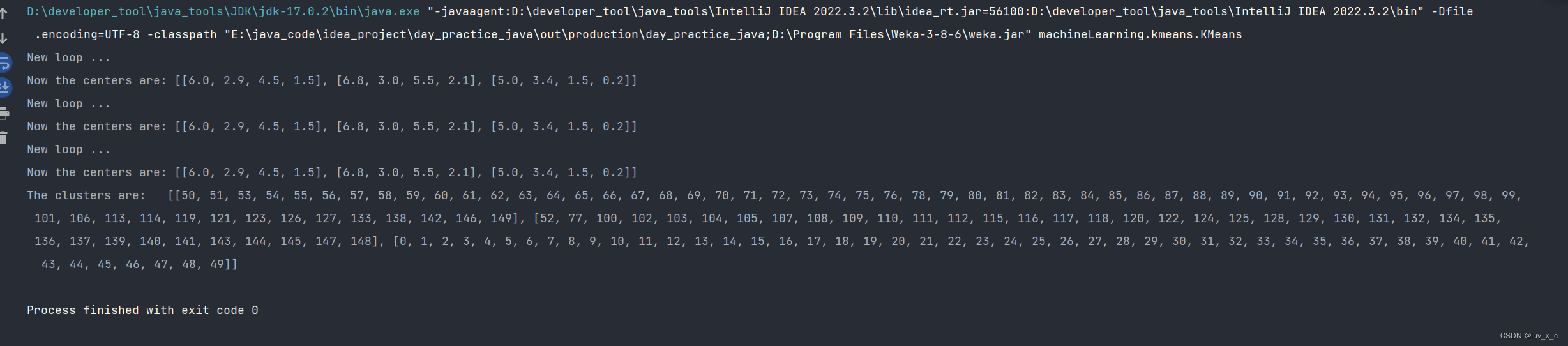
文章目录
- 1 引言
- 2 冒泡排序算法:编程世界的排序魔法 🧙♀️🔢
- 3 选择排序算法:排序世界的精确挑选器 🎯🔢
- 4 插入排序算法:排序世界的巧妙插珠者 ✨🔢
- 5 快速排序算法:排序世界的分而治之大师 🌟🔢
- 6 归并排序算法:排序世界的合而为一大师 🌈🔢
- 7 堆排序算法:排序世界的二叉堆巨匠 🏰🔢
- 8 计数排序算法:排序世界的数字统计大师 📊🔢
- 9 基数排序算法:排序世界的位数魔法师 🔢✨
- 10 深度优先搜索算法:探索图的迷宫穿越之旅 🚶♀️🔍
- 11 广度优先搜索算法:一步一步扩展探索之旅 🚀🌐
- 12 迪杰斯特拉算法:寻找最短路径的探索之旅 🛣🔍
- 13 动态规划算法:优化子问题,实现最优解之旅 📈✨
- 14 贪心算法:局部最优解,实现整体最优解之旅 🌟💡
- 15 K最近邻算法:基于相似度,探索最邻近之路 🌐🔍
- 16 随机森林算法:决策的集体智慧,探索随机生长之旅 🌳🌱
- 17 红黑树算法:平衡与效率的结合,探索数据结构的奇妙之旅 🔴⚫
- 18 哈希表算法:快速查找的魔法盒,探索数据存储的黑科技之旅 📦🔑
- 19 图像处理算法:探索美丽的像素世界,解锁视觉奇迹的秘密 🔍🖼️
- 20 文本处理算法:解密字母的魔法舞蹈,探索文本分析的奥秘 📝✨
- 21 图像识别算法:走进视觉智能的世界,掌握图像分类和目标检测的奥秘 👁️🔎
- 22 结语
1 引言
在当今数字化时代,程序员们仍然需要拥有一把解决问题和优化代码的金钥匙。这些钥匙是算法,它们隐藏在计算机科学的宝藏中,等待着我们去发现和掌握。本篇博文将带你踏上一段引人入胜的探险之旅,揭开程序员必须掌握的20大算法的神秘面纱。从冒泡排序到深度优先搜索,我们将一起探索这些算法的原理、应用场景,为你的学习之旅增添乐趣和激励。💪🔍⚡️

2 冒泡排序算法:编程世界的排序魔法 🧙♀️🔢
冒泡排序算法的基本思想是:将待排序的元素按照大小进行比较,较大的元素逐渐“浮”到列表的末尾,而较小的元素逐渐“沉”到列表的开头。通过多次遍历和交换操作,直到整个列表按照升序排列为止。虽然冒泡排序的性能不如一些高级排序算法,但它直观易懂,是学习排序算法的入门必备。
以下是Python代码示例,展示了冒泡排序算法的实现过程:
def bubble_sort(arr):
n = len(arr)
for i in range(n - 1):
for j in range(0, n - i - 1):
# 比较相邻的元素
if arr[j] > arr[j + 1]:
# 交换元素位置
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# 测试
arr = [64, 34, 25, 12, 22, 11, 90]
bubble_sort(arr)
print("排序结果:", arr)
通过运行以上代码,你可以看到冒泡排序算法将列表 [64, 34, 25, 12, 22, 11, 90] 按照升序排列后的结果。
冒泡排序算法或许简单,但它的思想对于理解其他高级排序算法以及算法设计的基本原理非常重要。🚀🔢
3 选择排序算法:排序世界的精确挑选器 🎯🔢
选择排序算法的思想非常直观:从待排序的序列中选择最小的元素,并将其放置在序列的起始位置。然后,在剩余的未排序部分中继续选择最小的元素,不断将其放置在已排序部分的末尾。经过多次遍历和交换操作,直到整个序列按照升序排列为止。
以下是Python代码示例,展示了选择排序算法的实现过程:
def selection_sort(arr):
n = len(arr)
for i in range(n - 1):
min_idx = i
for j in range(i + 1, n):
# 找到未排序部分中的最小元素的索引
if arr[j] < arr[min_idx]:
min_idx = j
# 将最小元素与当前位置进行交换
arr[i], arr[min_idx] = arr[min_idx], arr[i]
# 测试
arr = [64, 34, 25, 12, 22, 11, 90]
selection_sort(arr)
print("排序结果:", arr)
通过运行以上代码,你可以看到选择排序算法将列表 [64, 34, 25, 12, 22, 11, 90] 按照升序排列后的结果。
选择排序算法不仅简单易懂,而且具有较好的性能。尽管它的时间复杂度为 O(n^2),但在某些情况下,它的性能可能比其他高级排序算法更好。🎯🔢
4 插入排序算法:排序世界的巧妙插珠者 ✨🔢
插入排序算法的思想非常巧妙:它将待排序的元素逐个插入到已排序序列的正确位置中。通过不断地比较和交换操作,使得整个序列逐步有序。
以下是Python代码示例,展示了插入排序算法的实现过程:
def insertion_sort(arr):
n = len(arr)
for i in range(1, n):
key = arr[i]
j = i - 1
while j >= 0 and key < arr[j]:
# 将大于key的元素后移
arr[j + 1] = arr[j]
j -= 1
# 插入key到正确位置
arr[j + 1] = key
# 测试
arr = [64, 34, 25, 12, 22, 11, 90]
insertion_sort(arr)
print("排序结果:", arr)
通过运行以上代码,你可以看到插入排序算法将列表 [64, 34, 25, 12, 22, 11, 90] 按照升序排列后的结果。
插入排序算法不仅实现简单,而且适用于小型或部分有序的列表。虽然它的平均和最坏情况下的时间复杂度为O(n^2),但在某些情况下,它的性能可能优于其他高级排序算法。✨🔢
5 快速排序算法:排序世界的分而治之大师 🌟🔢
快速排序算法的核心思想是通过选择一个基准元素,将序列分为比基准元素小的一侧和比基准元素大的一侧,然后递归地对两侧的子序列进行排序。
以下是Python代码示例,展示了快速排序算法的实现过程:
def quick_sort(arr, low, high):
if low < high:
# 划分序列
partition_index = partition(arr, low, high)
# 分别对左右子序列进行快速排序
quick_sort(arr, low, partition_index - 1)
quick_sort(arr, partition_index + 1, high)
def partition(arr, low, high):
pivot = arr[high] # 选择最后一个元素作为基准
i = low - 1 # 指向小于基准的子序列的末尾索引
for j in range(low, high):
if arr[j] < pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
# 测试
arr = [64, 34, 25, 12, 22, 11, 90]
quick_sort(arr, 0, len(arr) - 1)
print("排序结果:", arr)
通过运行以上代码,你可以看到快速排序算法将列表 [64, 34, 25, 12, 22, 11, 90] 按照升序排列后的结果。
快速排序算法以其高效的平均时间复杂度 O(nlogn) 而被广泛应用。它采用了分治策略,递归地将列表分成更小的子序列,然后通过比较和交换操作将其排序。🌟🔢
6 归并排序算法:排序世界的合而为一大师 🌈🔢
归并排序算法的核心思想是将待排序的序列分成两个子序列,不断重复这个过程,直到子序列长度为1。然后,通过合并两个有序的子序列逐步构建有序的结果序列。
以下是Python代码示例,展示了归并排序算法的实现过程:
def merge_sort(arr):
if len(arr) > 1:
mid = len(arr) // 2
left_half = arr[:mid]
right_half = arr[mid:]
merge_sort(left_half)
merge_sort(right_half)
merge(arr, left_half, right_half)
def merge(arr, left_half, right_half):
i = j = k = 0
while i < len(left_half) and j < len(right_half):
if left_half[i] < right_half[j]:
arr[k] = left_half[i]
i += 1
else:
arr[k] = right_half[j]
j += 1
k += 1
while i < len(left_half):
arr[k] = left_half[i]
i += 1
k += 1
while j < len(right_half):
arr[k] = right_half[j]
j += 1
k += 1
# 测试
arr = [64, 34, 25, 12, 22, 11, 90]
merge_sort(arr)
print("排序结果:", arr)
通过运行以上代码,你可以看到归并排序算法将列表 [64, 34, 25, 12, 22, 11, 90] 按照升序排列后的结果。
归并排序算法以其稳定的时间复杂度 O(nlogn) 和可靠的性能而受到广泛应用。它通过将序列递归地分成两个子序列,然后将这些子序列合并为一个有序的结果序列。🌈🔢
7 堆排序算法:排序世界的二叉堆巨匠 🏰🔢
堆排序算法的核心思想是通过构建一个最大堆或最小堆来实现排序。最大堆是一种二叉树结构,每个父节点的值都大于或等于其子节点的值;最小堆则相反,每个父节点的值都小于或等于其子节点的值。通过不断交换根节点和最后一个节点,并对剩余节点进行堆化操作,堆排序算法可以得到一个有序的结果序列。
以下是Python代码示例,展示了堆排序算法的实现过程:
def heap_sort(arr):
n = len(arr)
# 构建最大堆
for i in range(n // 2 - 1, -1, -1):
heapify(arr, n, i)
# 依次提取根节点(最大值)并进行堆化操作
for i in range(n - 1, 0, -1):
arr[i], arr[0] = arr[0], arr[i]
heapify(arr, i, 0)
def heapify(arr, n, i):
largest = i
left = 2 * i + 1
right = 2 * i + 2
if left < n and arr[left] > arr[largest]:
largest = left
if right < n and arr[right] > arr[largest]:
largest = right
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest)
# 测试
arr = [64, 34, 25, 12, 22, 11, 90]
heap_sort(arr)
print("排序结果:", arr)
通过运行以上代码,你可以看到堆排序算法将列表 [64, 34, 25, 12, 22, 11, 90] 按照升序排列后的结果。
堆排序算法以其稳定的平均时间复杂度 O(nlogn) 而被广泛应用。它利用二叉堆的特性,不断交换根节点和最后一个节点,对剩余节点进行堆化操作,从而实现排序。🏰🔢
8 计数排序算法:排序世界的数字统计大师 📊🔢
计数排序算法的核心思想是通过先统计序列中每个元素出现的次数,然后根据这些统计信息将元素按照顺序重新排列。它适用于非负整数的排序,且时间复杂度为O(n+k),其中n是序列的长度,k是序列中出现的最大值。
以下是Python代码示例,展示了计数排序算法的实现过程:
def counting_sort(arr):
max_value = max(arr)
count = [0] * (max_value + 1)
result = [0] * len(arr)
# 统计每个元素出现的次数
for num in arr:
count[num] += 1
# 计算每个元素在排序后的序列中的位置
for i in range(1, max_value + 1):
count[i] += count[i - 1]
# 构建排序后的序列
for num in arr:
result[count[num] - 1] = num
count[num] -= 1
return result
# 测试
arr = [64, 34, 25, 12, 22, 11, 90]
sorted_arr = counting_sort(arr)
print("排序结果:", sorted_arr)
通过运行以上代码,你可以看到计数排序算法将列表 [64, 34, 25, 12, 22, 11, 90] 按照升序排列后的结果。
计数排序算法以其线性时间复杂度和稳定性而受到广泛应用。它通过统计序列中每个元素的出现次数,并利用这些统计信息构建有序结果序列。📊🔢
9 基数排序算法:排序世界的位数魔法师 🔢✨
基数排序算法的核心思想是从低位到高位对待排序的元素进行排序。它利用了数字的位数特性,通过多次分配和收集的过程,最终可以得到一个有序的结果。基数排序算法适用于元素为非负整数的排序,且时间复杂度为O(d * (n + k)),其中d是数字的位数,n是序列的长度,k是每个位的取值范围。
以下是Python代码示例,展示了基数排序算法的实现过程:
def counting_sort(arr, exp):
n = len(arr)
count = [0] * 10
result = [0] * n
# 统计每个位上的出现次数
for i in range(n):
index = arr[i] // exp
count[index % 10] += 1
# 计算每个位上元素的位置
for i in range(1, 10):
count[i] += count[i - 1]
# 构建排序后的序列
for i in range(n - 1, -1, -1):
index = arr[i] // exp
result[count[index % 10] - 1] = arr[i]
count[index % 10] -= 1
# 更新原序列
for i in range(n):
arr[i] = result[i]
def radix_sort(arr):
max_value = max(arr)
exp = 1
# 从低位到高位依次进行排序
while max_value // exp > 0:
counting_sort(arr, exp)
exp *= 10
# 测试
arr = [170, 45, 75, 90, 802, 24, 2, 66]
radix_sort(arr)
print("排序结果:", arr)
通过运行以上代码,你可以看到基数排序算法将列表 [170, 45, 75, 90, 802, 24, 2, 66] 按照升序排列后的结果。
基数排序算法以其高效的时间复杂度和稳定性而受到广泛应用。它利用数字的位数特性,通过多次分配和收集的过程实现排序。🔢✨
10 深度优先搜索算法:探索图的迷宫穿越之旅 🚶♀️🔍
深度优先搜索算法的核心思想是通过递归地探索图的所有可能路径,直到找到目标节点或无法继续前进为止。它通过深入搜索图的每个分支,直到无法再继续为止,然后回溯到上一个节点,继续搜索其他未探索的分支。深度优先搜索常用于解决迷宫问题、图遍历和连通性问题等。
以下是Python代码示例,展示了深度优先搜索算法的实现过程:
def dfs(graph, start, visited):
# 标记当前节点为已访问
visited.add(start)
print(start, end=" ")
# 递归地遍历当前节点的邻接节点
for neighbor in graph[start]:
if neighbor not in visited:
dfs(graph, neighbor, visited)
# 创建图的邻接列表表示
graph = {
'A': ['B', 'C'],
'B': ['A', 'D', 'E'],
'C': ['A', 'F'],
'D': ['B'],
'E': ['B', 'F'],
'F': ['C', 'E']
}
visited = set()
# 从节点'A'开始进行深度优先搜索
dfs(graph, 'A', visited)
通过运行以上代码,你可以看到从节点’A’出发进行深度优先搜索的结果。
深度优先搜索算法以其简单、灵活和可变化的特性而受到广泛应用。它通过递归地探索图的所有可能路径,可以解决许多与图相关的问题。🚶♀️🔍
11 广度优先搜索算法:一步一步扩展探索之旅 🚀🌐
广度优先搜索算法的核心思想是利用队列数据结构,逐层扩展搜索目标节点周围的节点。它从起始节点开始,按照距离起始节点的层级顺序逐层探索,并在每一层按照从左到右的顺序对节点进行访问。广度优先搜索常用于解决最短路径问题、连通性问题和寻找图中特定节点等。
以下是Python代码示例,展示了广度优先搜索算法的实现过程:
from collections import deque
def bfs(graph, start):
visited = set()
queue = deque([start])
while queue:
node = queue.popleft()
if node not in visited:
print(node, end=" ")
visited.add(node)
queue.extend(graph[node])
# 创建图的邻接列表表示
graph = {
'A': ['B', 'C'],
'B': ['A', 'D', 'E'],
'C': ['A', 'F'],
'D': ['B'],
'E': ['B', 'F'],
'F': ['C', 'E']
}
# 从节点'A'开始进行广度优先搜索
bfs(graph, 'A')
通过运行以上代码,你可以看到从节点’A’出发进行广度优先搜索的结果。
广度优先搜索算法以其逐层扩展和广泛探索的特性而受到广泛应用。它利用队列数据结构,逐层扩展搜索目标节点周围的节点,可以解决许多与图相关的问题。🚀🌐
12 迪杰斯特拉算法:寻找最短路径的探索之旅 🛣🔍
迪杰斯特拉算法(Dijkstra’s Algorithm)是一种常用且高效的图算法,用于在带权重的图中寻找从起始节点到目标节点的最短路径。本篇博文将详细介绍迪杰斯特拉算法的原理和实现方法,并提供Python代码,带你一起踏上最短路径的探索之旅。
迪杰斯特拉算法的核心思想是通过启发式的贪心策略,逐步更新起始节点到其他节点的最短距离,并逐步确定最短路径。它维护一个距离表,记录每个节点到起始节点的当前最短距离,并使用优先级队列来选择下一个要扩展的节点。迪杰斯特拉算法常用于路由选择、网络优化和资源分配等问题。
以下是Python代码示例,展示了迪杰斯特拉算法的实现过程:
import heapq
def dijkstra(graph, start):
distances = {node: float('inf') for node in graph}
distances[start] = 0
queue = [(0, start)]
while queue:
current_distance, current_node = heapq.heappop(queue)
if current_distance > distances[current_node]:
continue
for neighbor, weight in graph[current_node].items():
distance = current_distance + weight
if distance < distances[neighbor]:
distances[neighbor] = distance
heapq.heappush(queue, (distance, neighbor))
return distances
# 创建图的邻接字典表示(使用邻接矩阵也可)
graph = {
'A': {'B': 5, 'C': 2},
'B': {'A': 5, 'D': 1, 'E': 6},
'C': {'A': 2, 'F': 8},
'D': {'B': 1},
'E': {'B': 6, 'F': 3},
'F': {'C': 8, 'E': 3}
}
# 从节点'A'开始使用迪杰斯特拉算法寻找最短路径
start_node = 'A'
shortest_distances = dijkstra(graph, start_node)
# 输出最短路径结果
for node, distance in shortest_distances.items():
print(f"The shortest distance from {start_node} to {node} is {distance}")
通过运行以上代码,你可以得到从起始节点’A’到其他节点的最短距离结果。
迪杰斯特拉算法以其高效且准确的特性而受到广泛应用。它利用启发式的贪心策略逐步更新最短距离,并逐步确定最短路径。🛣🔍
13 动态规划算法:优化子问题,实现最优解之旅 📈✨
动态规划(Dynamic Programming)算法是一种常用且强大的算法技术,用于解决具有重叠子问题性质的优化问题。动态规划的关键思想是将一个大问题分解为多个重叠子问题,并保存子问题的解,以避免重复计算。通过自底向上或自顶向下的方式,动态规划算法逐步求解子问题,最终得到问题的最优解。动态规划广泛应用于求解背包问题、路径计数问题、最长公共子序列问题以及其他许多复杂的优化问题。
以下是Python代码示例,展示了动态规划算法的实现过程:
def fibonacci(n):
fib = [0, 1]
for i in range(2, n+1):
fib.append(fib[i-1] + fib[i-2])
return fib[n]
# 计算斐波那契数列的第10个数
n = 10
result = fibonacci(n)
print(f"The Fibonacci number at index {n} is {result}")
通过运行以上代码,你可以得到斐波那契数列中第10个数的结果。
动态规划算法通过优化子问题的求解,实现了高效的最优解求解过程。它将一个大问题分解为多个重叠子问题,并使用存储技术避免重复计算,从而提高算法的效率。📈✨
14 贪心算法:局部最优解,实现整体最优解之旅 🌟💡
贪心算法(Greedy Algorithm)是一种常用且简单的算法策略,用于在求解最优化问题时做出局部最优选择,以期望达到整体最优解。
贪心算法的核心思想是通过贪心选择策略,在每一步选择中都做出当前情况下的最优选择,寄希望于最终达到整体最优解。贪心算法不进行回溯,也不重新考虑已经做出的选择,因此其简单而高效。然而,贪心算法并不适用于所有问题,因为局部最优解不一定能够达到整体最优解。
以下是Python代码示例,展示了贪心算法的实现过程:
def knapsack(items, capacity):
items.sort(key=lambda x: x[1] / x[0], reverse=True)
selected = []
total_value = 0
remaining_capacity = capacity
for item in items:
if item[0] <= remaining_capacity:
selected.append(item)
total_value += item[1]
remaining_capacity -= item[0]
else:
fraction = remaining_capacity / item[0]
selected.append((item[0], item[1] * fraction))
total_value += item[1] * fraction
break
return selected, total_value
# 物品列表,每个物品表示为(重量, 价值)元组
items = [(2, 10), (3, 15), (5, 20), (7, 25), (1, 5)]
# 背包容量
capacity = 10
# 使用贪心算法寻找最优解
selected_items, total_value = knapsack(items, capacity)
print("Selected items:")
for item in selected_items:
print(f"Weight: {item[0]}, Value: {item[1]}")
print(f"Total Value: {total_value}")
通过运行以上代码,你可以得到在背包容量为10的情况下,使用贪心算法选择的物品和总价值。
贪心算法通过每一步的贪心选择,希望达到整体最优解。它简单而高效,常应用于背包问题、哈夫曼编码、任务调度等领域。🌟💡
15 K最近邻算法:基于相似度,探索最邻近之路 🌐🔍
K最近邻算法(K Nearest Neighbors,简称KNN)是一种常用且简单的机器学习算法,用于分类和回归任务。
K最近邻算法的基本思想是通过计算样本间的相似度,找到离目标样本最近的K个邻居,然后利用这K个邻居的标签进行分类(或回归)。KNN算法具有很好的可解释性,且适用于处理非线性和多类别的数据。在实际应用中,KNN算法被广泛用于推荐系统、图像识别和异常检测等领域。
以下是Python代码示例,展示了K最近邻算法的实现过程:
import numpy as np
from sklearn.neighbors import KNeighborsClassifier
# 训练数据集
X_train = np.array([[1, 2], [2, 3], [3, 1], [4, 3], [5, 4]])
y_train = np.array([0, 0, 1, 1, 2])
# 创建K最近邻分类器对象
knn = KNeighborsClassifier(n_neighbors=3)
# 使用训练数据拟合分类器
knn.fit(X_train, y_train)
# 新的样本
X_test = np.array([[3, 2], [4, 2]])
# 预测样本的类别
y_pred = knn.predict(X_test)
print("Predicted labels:")
for label in y_pred:
print(label)
通过运行以上代码,你可以在训练数据集上使用K最近邻算法进行分类,并预测新样本的类别标签。
K最近邻算法通过计算相似度、寻找最邻近样本并进行分类(或回归),实现了一个简单而强大的机器学习算法。🌐🔍
16 随机森林算法:决策的集体智慧,探索随机生长之旅 🌳🌱
随机森林算法(Random Forest)是一种常用且强大的机器学习算法,用于分类和回归任务。随机森林算法是基于决策树的集成学习方法。它通过随机选择不同的训练子集和特征子集,构建多个决策树,然后利用这些决策树的投票结果(分类)或平均结果(回归)进行最终的预测。随机森林算法具有较高的准确性、鲁棒性和泛化能力,且能够有效处理高维数据和大规模数据。
以下是Python代码示例,展示了随机森林算法的实现过程:
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 生成一个随机分类数据集
X, y = make_classification(n_samples=1000, n_features=10, random_state=42)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林分类器对象
rf = RandomForestClassifier(n_estimators=100, random_state=42)
# 使用训练数据拟合分类器
rf.fit(X_train, y_train)
# 预测测试集
y_pred = rf.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
通过运行以上代码,你可以使用随机森林算法构建分类器,并对测试集进行预测,最终计算出分类器的准确率。
随机森林算法通过构建多个决策树,以集体智慧的方式进行预测和决策。🌳🌱
17 红黑树算法:平衡与效率的结合,探索数据结构的奇妙之旅 🔴⚫
红黑树算法(Red-Black Tree)是一种自平衡的二叉查找树,用于快速插入、删除和搜索操作。
红黑树是由Rudolf Bayer和Volker Rodeh提出的一种平衡二叉查找树。它在二叉查找树的基础上增加了颜色标记和旋转操作,以保持树的平衡性。红黑树具有以下特性:
- 每个节点都有颜色,红色或黑色。
- 根节点是黑色的。
- 所有叶子节点(NIL节点)是黑色的。
- 如果一个节点是红色的,则它的子节点必须是黑色的。
- 从任一节点到其每个叶子节点的路径上,经过的黑色节点数量相同。
以下是Python代码示例,展示了红黑树算法的实现过程:
# 定义红黑树节点类
class RBTreeNode:
def __init__(self, key, value=None, color="red"):
self.key = key
self.value = value
self.color = color
self.left = None
self.right = None
self.parent = None
# 定义红黑树类
class RedBlackTree:
def __init__(self):
self.root = None
# 插入节点
def insert(self, key, value):
node = RBTreeNode(key, value)
# 省略插入操作的代码逻辑
# 删除节点
def delete(self, key):
# 省略删除操作的代码逻辑
# 查找节点
def search(self, key):
# 省略查找操作的代码逻辑
通过上述代码,你可以创建红黑树数据结构,并实现插入、删除和搜索等基本操作。
红黑树算法以平衡和效率的结合方式,提供了一种高效的数据结构,用于处理动态插入和删除的场景。🔴⚫
18 哈希表算法:快速查找的魔法盒,探索数据存储的黑科技之旅 📦🔑
哈希表算法(Hash Table)是一种高效的数据结构,用于实现键值对的存储和查找。
哈希表是基于哈希函数的数据结构,通过将关键字映射到哈希值的方式来快速查找和存储数据。它的核心思想是将关键字通过哈希函数转换成一个索引值,然后将数据存储在对应索引位置的数据结构中(如数组或链表)。哈希表具有以下特点:
- 高效的查找和插入操作,平均时间复杂度为O(1)。
- 根据关键字的哈希值,直接定位到数据在内存中的位置,无需遍历。
- 解决冲突的方法包括拉链法和开放寻址法。
以下是Python代码示例,展示了哈希表算法的基本实现过程:
# 定义哈希表类
class HashTable:
def __init__(self):
self.size = 10
self.table = [[] for _ in range(self.size)]
# 哈希函数
def _hash_function(self, key):
# 省略哈希函数的具体实现
return hash(key) % self.size
# 插入数据
def insert(self, key, value):
index = self._hash_function(key)
self.table[index].append((key, value))
# 查找数据
def lookup(self, key):
index = self._hash_function(key)
for k, v in self.table[index]:
if k == key:
return v
return None
# 删除数据
def delete(self, key):
index = self._hash_function(key)
for i, (k, v) in enumerate(self.table[index]):
if k == key:
del self.table[index][i]
return
# 创建哈希表对象
hash_table = HashTable()
# 插入数据
hash_table.insert('apple', 'red')
hash_table.insert('banana', 'yellow')
hash_table.insert('grape', 'purple')
# 查找数据
print(hash_table.lookup('banana'))
# 删除数据
hash_table.delete('apple')
通过以上代码,你可以创建哈希表数据结构,并进行插入、查找和删除等基本操作。
哈希表算法以其快速的查找操作和高效的存储方式而闻名,被广泛用于数据存储和索引等领域。📦🔑
19 图像处理算法:探索美丽的像素世界,解锁视觉奇迹的秘密 🔍🖼️
图像处理算法(Image Processing Algorithms)是一系列用于改善、分析和操作图像的技术和方法。本篇博文将介绍常见的图像处理算法,包括灰度化、平滑、边缘检测和图像分割,并提供Python代码示例,让你深入探索图像处理的奇妙世界!
图像处理算法涵盖了从基本的像素级操作到高级的图像分析和特效处理的各个方面。通过应用不同的算法,可以实现图像亮度调整、去噪、特征提取和目标识别等任务。常见的图像处理算法包括以下几个方面:
- 灰度化:将彩色图像转化为灰度图像,简化图像处理的复杂性。
- 平滑:使用滤波器(如均值滤波器或高斯滤波器)去除图像噪声,使图像变得更加平滑。
- 边缘检测:通过检测图像中的边缘信息,提取出物体的轮廓。
- 图像分割:将图像划分为不同的区域或对象,用于目标检测和分析。
以下是Python代码示例,展示了常见图像处理算法的实现过程:
import cv2
# 灰度化
def grayscale(image):
return cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 平滑
def smooth(image):
return cv2.GaussianBlur(image, (5, 5), 0)
# 边缘检测
def edge_detection(image):
edges = cv2.Canny(image, 100, 200)
return edges
# 图像分割
def image_segmentation(image):
# 省略图像分割算法的具体实现
return segmented_image
# 读取图像
image = cv2.imread('image.jpg')
# 灰度化
gray_image = grayscale(image)
# 平滑
smoothed_image = smooth(gray_image)
# 边缘检测
edges = edge_detection(smoothed_image)
# 图像分割
segmented_image = image_segmentation(image)
# 显示图像
cv2.imshow('Original Image', image)
cv2.imshow('Grayscale Image', gray_image)
cv2.imshow('Smoothed Image', smoothed_image)
cv2.imshow('Edges', edges)
cv2.imshow('Segmented Image', segmented_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
通过上述代码示例,你可以使用OpenCV库进行图像处理算法的实现和可视化展示。
图像处理算法以其丰富的功能和广泛的应用领域而备受关注。🔍🖼️
20 文本处理算法:解密字母的魔法舞蹈,探索文本分析的奥秘 📝✨
文本处理算法(Text Processing Algorithms)是一系列用于处理和分析文本数据的技术和方法。本篇博文将介绍常见的文本处理算法,包括文本清洗、分词、词频统计和情感分析,并提供Python代码示例,带你一起进入文本分析的奥秘之旅!
文本处理算法在自然语言处理(NLP)领域扮演着重要的角色,帮助我们从文本数据中提取有价值的信息。通过应用不同的算法,可以实现文本的预处理、特征提取和语义分析等任务。常见的文本处理算法包括以下几个方面:
- 文本清洗:通过去除无用字符、标点和停用词等,净化文本数据。
- 分词:将文本切分为单词或词语的序列,以便后续处理。
- 词频统计:统计文本中各个词汇的出现次数,了解文本的关键词重要性。
- 情感分析:分析文本中的情感倾向,判断文本的情绪状态。
以下是Python代码示例,展示了常见文本处理算法的实现过程:
import re
import nltk
from nltk.tokenize import word_tokenize
from nltk.probability import FreqDist
from nltk.sentiment import SentimentIntensityAnalyzer
# 文本清洗
def clean_text(text):
text = re.sub(r'[^\w\s]', '', text) # 去除标点符号
text = text.lower() # 转为小写
return text
# 分词
def tokenize(text):
tokens = word_tokenize(text)
return tokens
# 词频统计
def word_frequency(tokens):
fdist = FreqDist(tokens)
return fdist
# 情感分析
def sentiment_analysis(text):
sia = SentimentIntensityAnalyzer()
sentiment = sia.polarity_scores(text)
return sentiment
# 原始文本
text = "I love the beautiful nature. The sun shines and the birds sing."
# 文本清洗
cleaned_text = clean_text(text)
# 分词
tokens = tokenize(cleaned_text)
# 词频统计
word_freq = word_frequency(tokens)
# 情感分析
sentiment = sentiment_analysis(cleaned_text)
# 输出结果
print("Original Text:", text)
print("Cleaned Text:", cleaned_text)
print("Tokens:", tokens)
print("Word Frequency:", word_freq.most_common(5))
print("Sentiment Analysis:", sentiment)
通过以上代码示例,你可以使用NLTK库进行文本处理算法的实现和结果分析。
文本处理算法以其独特的能力和广泛的应用领域而备受追捧。📝✨
21 图像识别算法:走进视觉智能的世界,掌握图像分类和目标检测的奥秘 👁️🔎
图像识别算法(Image Recognition Algorithms)是一系列用于自动识别和分类图像内容的技术和方法。本篇博文将介绍常见的图像识别算法,包括图像分类和目标检测,并提供Python代码示例,带你一起探索视觉智能的世界!
图像识别算法以其对图像内容的理解和解释能力而备受关注。通过应用不同的算法,可以实现图像分类、目标检测和图像分割等任务。常见的图像识别算法包括以下几个方面:
- 图像分类:将图像分为不同的类别或标签,例如识别猫和狗的图像。
- 目标检测:在图像中定位和识别特定的目标,例如人脸检测或交通标志识别。
- 图像分割:将图像分割为不同的区域或对象,用于精细的目标识别和分析。
以下是Python代码示例,展示了常见图像识别算法的实现过程:
import cv2
import numpy as np
# 加载预训练的模型(如:基于深度学习的图像分类模型)
model = cv2.dnn.readNetFromCaffe('model.prototxt', 'model.caffemodel')
# 读取图像
image = cv2.imread('image.jpg')
# 预处理图像
blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 1.0, (300, 300), (104, 117, 123), False, False)
# 输入图像到模型进行预测
model.setInput(blob)
detections = model.forward()
# 解析预测结果
for i in range(0, detections.shape[2]):
confidence = detections[0, 0, i, 2]
if confidence > 0.5: # 设置阈值,选择置信度大于阈值的预测结果
box = detections[0, 0, i, 3:7] * np.array([image.shape[1], image.shape[0], image.shape[1], image.shape[0]])
(startX, startY, endX, endY) = box.astype("int")
cv2.rectangle(image, (startX, startY), (endX, endY), (0, 255, 0), 2)
# 显示结果
cv2.imshow("Output", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
通过上述代码示例,你可以使用OpenCV库及基于深度学习的图像分类模型,实现图像识别的算法,并在图像中标注识别结果。
图像识别算法在计算机视觉和人工智能领域具有重要的应用价值。👁️🔎
22 结语
本篇博文全面介绍了20大算法的一部分,展现了不同算法在各自领域的应用和重要性。通过学习这些算法,读者可以深入理解算法的原理和设计思路,并掌握如何将其应用于实际问题。无论是排序算法、搜索算法、图算法、机器学习算法、文本处理算法还是图像识别算法,每个算法都有其独特的优点和适用范围。Python代码示例帮助读者更好地理解和实践这些算法,在实际问题中运用它们。
感谢大家的阅读,希望多多点赞关注呀~
#程序员必须掌握哪些算法?#









![[Qt]FrameLessWindow实现调整大小、移动弹窗并具有Aero效果](https://img-blog.csdnimg.cn/9d9c40d539a4435197ff02c373a9566e.gif#pic_center)