1、JAVA BIO、NIO、AIO的区别
BIO (Blocking I/O):同步阻塞I/O模式。当有其他线程进行数据读写时阻塞等待。当用户线程发出IO请求之后,内核会去查看数据是否就绪,如果没有就绪就会等待,用户线程就会处于阻塞状态交出CPU。当数据就绪之后,操作系统就会将数据从主内存拷贝到线程工作内存,并返回结果给用户线程,才解除阻塞状态。(类似重量级锁)
NIO(nonblocking I/O):同步非阻塞I/O。当用户线程发起一个read操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个error时(数据未准备就绪),它就知道数据还没有准备好,于是它可以再次发送read操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。所以事实上,在非阻塞IO模型中,用户线程需要不断地询问主内存数据是否就绪,也就说非阻塞IO不会交出CPU,而会一直占用CPU。(类似CAS)
AIO(Asynchronous I/O) 异步非阻塞I/O。当用户线程发起了个I/O操作后立即返回,执行该线程的其他任务。当I/O操作真正完成之后,会通知用户线程,用户线程只需要处理读取的数据即可,不需要实际的I/O操作,真正的I/O读写已经由内核完成了。
2、JAVA NIO
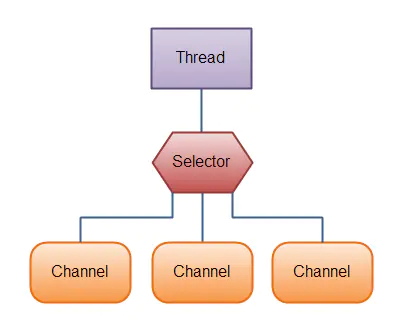
NIO主要有三大核心部分:Channel、Buffer、Selector。
传统IO基于字节流和字符流,而NIO基于Channel和Buffer进行操作,数据总是从通道读取到缓冲区,或者从缓冲区写入到通道中。Selector用于监听多个通道的事件(连接打开,数据到达等)。
NIO的buffer(缓冲区):普通的I/O面向流意味着每次从流中读取一个或者多个字节,直到读取完所有字节,没有缓存在任何地方。NIO将数据读取到一个缓冲区,需要时可以在缓冲区中前后移动,这增加了处理的灵活性。但是需要检查缓冲区中是否包含需要的数据,还要保证读取更多数据时不会覆盖尚未处理的数据。
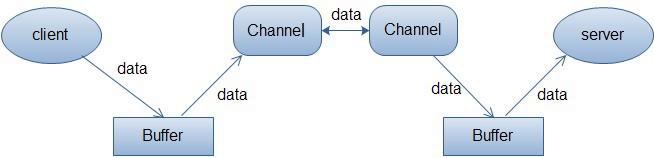
上述图描述了客户端向服务器端发送数据,然后被服务器端接收的过程。通道之间可以进行数据的交换,而客户端和服务器端发送和接收数据都必须经过Buffer。
channel:stream流是单向的,而Channel是双向的,既可以用来读操作,也可以进行写操作。分别有FileChannel、DatagramChannel、SocketChannel、ServerSocketChannel,对应文件I/O、UDP和TCP
selector:Selector能够检测多个注册的通道上是否有事件发生,如果有事件发生,便获取事件然后针对每个事件进行相应的响应处理。这样一来,只是用一个单线程就可以管理多个通道,也就是管理多个连接,避免了为每一个连接都创建一个线程增加开销。
3、以下几种情况不会出发类的初始化
- 通过子类引用父类的静态字段,只会触发父类的初始化,而不会触发子类的初始化。
- 定义对象数组,不会触发该类的初始化。
- 常量在编译期间会存入调用类的常量池中,本质上没有直接引用定义常量的类,不会触发定义常量所在的类。
- 通过类名获取Class对象,不会触发类的初始化。
- 通过Class.forName加载指定类时,如果指定参数initialize为false时,也不会触发类初始化,其实这个参数是告诉虚拟机,是否要对类进行初始化。
- 通过ClassLoader默认的loadClass方法,也不会触发初始化动作。
4、线程池的种类
Java里面线程池的顶级接口是Executor,但是严格意义上讲Executor并不是一个线程池,而只是一个执行线程的工具。真正的线程池接口是ExecutorService。
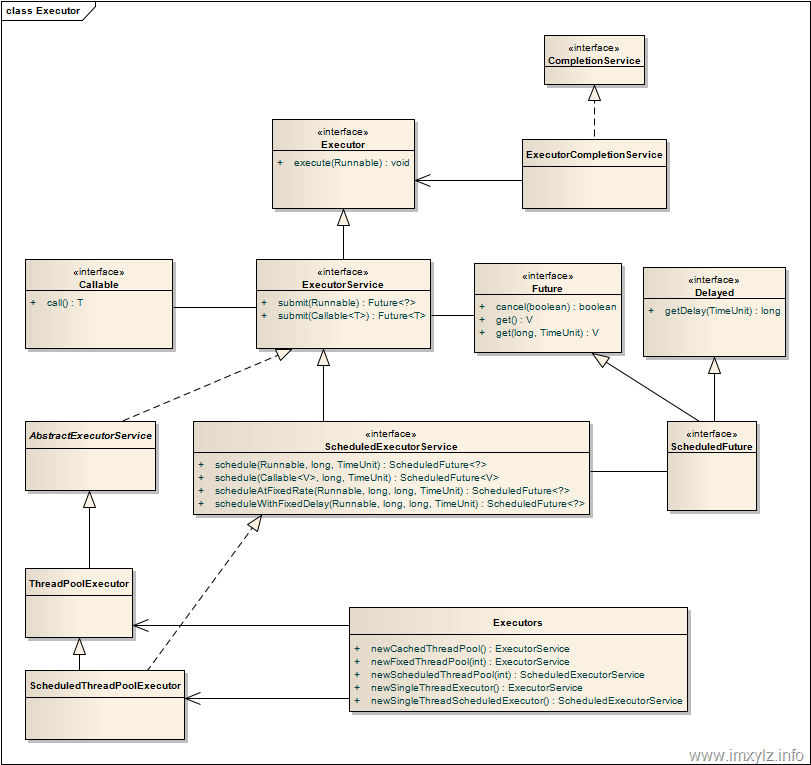
Executors可以创建四种线程池,分别是:
Executors.newCachedThreadPool:如果有可用的线程调用execute时会重用,没有可用的将创建一个新的线程加入池中。会终止并移除60秒未被使用的线程。
Executors.newFixedThreadPool:创建固定数量线程的线程池,如果所有线程都不可用,新的任务将在队列中等待可用线程。线程没有被显示关闭则一直在线程池中。
Executors.newScheduledThreadPool:创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
ScheduledExecutorService scheduledThreadPool= Executors.newScheduledThreadPool(3);
scheduledThreadPool.schedule(new Runnable(){
@Override public void run() {
System.out.println("延迟三秒");
}
}, 3, TimeUnit.SECONDS);
scheduledThreadPool.scheduleAtFixedRate(newRunnable(){
@Override public void run() {
System.out.println("延迟1秒后每三秒执行一次");
}
},1,3,TimeUnit.SECONDS);
Executors.newSingleThreadExecutor:线程池只有一个线程,可以在线程死后(或发生异常时)重新启动一个线程来替代原来的线程继续执行下去!
使用线程池的好处:
线程复用,控制并发度,线程同一管理。
5、如何进行锁优化
减少锁持有时间:只用在有线程安全要求的程序上加锁
减小锁粒度:将大对象(这个对象可能会被很多线程访问),拆成小对象,大大增加并行度,降低锁竞争。降低了锁的竞争,偏向锁,轻量级锁成功率才会提高。最最典型的减小锁粒度的案例就是ConcurrentHashMap。
锁分离:最常见的锁分离就是读写锁ReadWriteLock,根据功能进行分离成读锁和写锁,这样读读不互斥,读写互斥,写写互斥,即保证了线程安全,又提高了性能。
锁粗化:通常情况下,为了保证多线程间的有效并发,会要求每个线程持有锁的时间尽量短。但是,凡事都有一个度,如果对同一个锁不停的进行请求、同步和释放,其本身也会消耗系统宝贵的资源,反而不利于性能的优化,此时粗化反而会提升性能。
锁消除 :锁消除是在编译器级别的事情。在即时编译器时,如果发现不可能被共享的对象,则可以消除这些对象的锁操作,多数是因为程序员编码不规范引起。
6、java中的阻塞队列
阻塞队列的原理:
- 当队列中没有数据的情况下,消费者端的所有线程都会被自动阻塞(挂起),直到有数据放入队列。
- 当队列中填满数据的情况下,生产者端的所有线程都会被自动阻塞(挂起),直到队列中有空的位置,线程被自动唤醒。
阻塞队列的主要方法
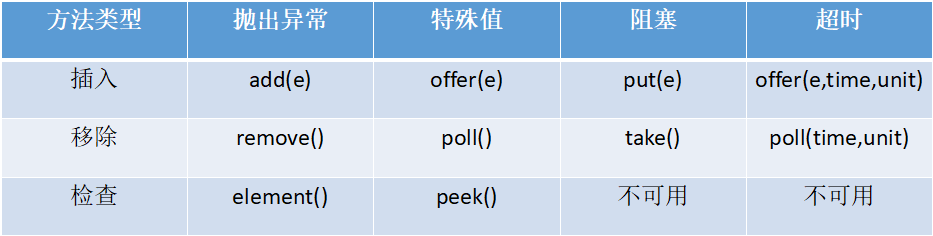
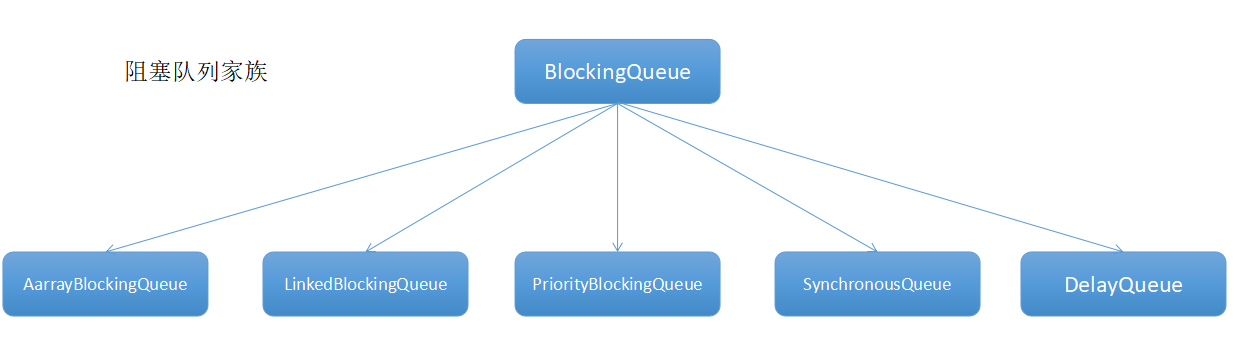
ArrayBlockingQueue(公平、非公平):用数组实现的有界阻塞队列。按照先进先出(FIFO)的原则对元素进行排序。默认情况下不保证访问者公平的访问队列。
LinkedBlockingQueue(两个独立锁提高并发):基于链表的阻塞队列,先进先出(FIFO),对于生产者端和消费者端分别采用了独立的锁来控制数据同步,生产者和消费者可以并发,从而提升性能。
PriorityBlockingQueue(compareTo排序实现优先):可以自定义排序,需要注意的是不能保证同优先级元素的顺序。
DelayQueue(缓存失效、定时任务 ):队列使用PriorityQueue来实现。队列中的元素必须实现Delayed接口,在创建元素时可以指定时间,只有在延迟期满时才能从队列中提取元素。
SynchronousQueue(不存储数据、可用于传递数据):一个不存储元素的阻塞队列。每一个put操作必须等待一个take操作,否则不能继续添加元素。非常适合于传递性场景,吞吐量高于LinkedBlockingQueue 和ArrayBlockingQueue。
7、进程的调度算法
先来先服务调度算法(FCFS):作业调度按照线程的启动顺序进行分配资源。公平。
短作业优先算法:从就绪队列中选择估计运行时间最短的进行分配资源。
高优先权优先调度算法:1.抢占式优先权算法:执行期间只要出现优先权更高的进程,就把处理机重新分配给高优先权的进程 2.非抢占式优先权算法:等当前进程执行完后,选择优先权高的进程分配资源 3:高响应比优先调度算法,通过比较响应比进行进程的调度。
时间片轮换算法:将就绪的进程按照给定的时间片依次运行,当前进程执行完时间片后就排到就绪队列的队尾。
多级反馈队列调度算法:设置多个就绪队列,每个队列的时间片大小不同(依次增大),当上层队列中的时间片用完时,进程进入下一层就绪队列中进行等待,上层队列中空闲时后再调度下层就绪队列中的进程。
8、java中常见的运行时异常和非运行时异常
运行时异常:在编译期不会发现,通常是逻辑错误导致的异常。如NullPointerException,ClassCastException
非运行时异常:在编译阶段,java编译器就会强制去捕获此类异常,否则编译不通过。例如:IOException、SQLException
9、Spring的特点
轻量级:体积小,开销小。
控制反转:对象的创建和使用通过Spring框架来完成,降低了代码的耦合性。
面向切面:使用动态代理的技术,将应用业务逻辑和系统服务分开。
容器:Spring是一种容器,包含并管理对象的配置和生命周期。
框架:提供了很多开箱即用的功能(事务管理,数据库连接等),只把逻辑的开发留给开发者。
10、spring依赖注入的四种方式
构造器注入:
/*带参数,方便利用构造器进行注入*/
public CatDaoImpl(String message){
this. message = message;
}
<bean id="CatDaoImpl" class="com.CatDaoImpl">
<constructor-arg value=" message "></constructor-arg>
</bean>
setter方法注入:
public class Id {
private int id;
public int getId() { return id; }
public void setId(int id) { this.id = id; }
}
<bean id="id" class="com.id "> <property name="id" value="123"></property> </bean>
静态工厂注入:
public class DaoFactory { //静态工厂
public static final FactoryDao getStaticFactoryDaoImpl(){
return new StaticFacotryDaoImpl();
}
}
public class SpringAction {
private FactoryDao staticFactoryDao; //注入对象
//注入对象的set方法
public void setStaticFactoryDao(FactoryDao staticFactoryDao) {
this.staticFactoryDao = staticFactoryDao;
}
}
//factory-method="getStaticFactoryDaoImpl"指定调用哪个工厂方法
<bean name="springAction" class=" SpringAction" >
<!--使用静态工厂的方法注入对象,对应下面的配置文件-->
<property name="staticFactoryDao" ref="staticFactoryDao"></property>
</bean>
<!--此处获取对象的方式是从工厂类中获取静态方法-->
<bean name="staticFactoryDao" class="DaoFactory"
factory-method="getStaticFactoryDaoImpl"></bean>
通过实例工厂注入:
public class DaoFactory { //实例工厂
public FactoryDao getFactoryDaoImpl(){
return new FactoryDaoImpl();
}
}
public class SpringAction {
private FactoryDao factoryDao; //注入对象
public void setFactoryDao(FactoryDao factoryDao) {
this.factoryDao = factoryDao;
}
}
<bean name="springAction" class="SpringAction">
<!--使用实例工厂的方法注入对象,对应下面的配置文件-->
<property name="factoryDao" ref="factoryDao"></property>
</bean>
<!--此处获取对象的方式是从工厂类中获取实例方法-->
<bean name="daoFactory" class="com.DaoFactory"></bean>
<bean name="factoryDao" factory-bean="daoFactory"
factory-method="getFactoryDaoImpl"></bean>
11、网络的OSI七层架构
物理层:等一了物理接口标准以及电气特性。数据为比特。
数据链路层:将物理层接收的数据进行MAC地址封装/解封装。工作设备为交换机,数据为帧。
网络层:将接收到的数据进行IP地址的封装和解封装,以及进行路由选择。工作设备为路由器,数据为数据包
传输层:定义了一些传输协议(TCP/UDP)和端口号。将下层接收到的数据进行分段传输。数据为段
会话层:通过传输层建立数据传输的通路,在设备之间发起会话或者接收会话请求。
表示层:主要是进行对接收的数据进行解释、加密与解密、压缩与解压缩等,(也就是把计算机能够识别的东西转换成人能够能识别的东西(如图片、声音等))
应用层:主要是一些终端的应用。
12、TCP/IP参考模型
TCP/IP由四个层次组成:网络接口层、网络层、传输层、应用层。
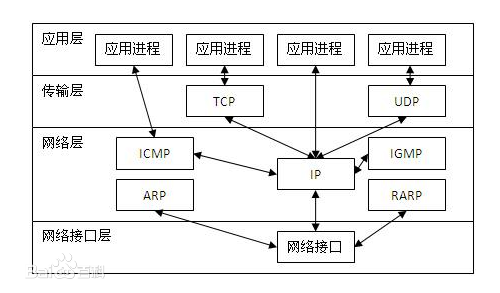
网络接口层:指出主机必须使用某种协议与网络相连。
网络层:分组转发,这些分组可以通过不同的网络,到达的顺序和发送的顺序也可能不同,高层如果需要顺序收发,那么就必须自行处理对分组的排序。
传输层:在这一层定义了两个端到端的协议:传输控制协议(TCP,Transmission Control Protocol)和用户数据报协议(UDP,User Datagram Protocol)。
应用层:文件传输协议(FTP)、电子邮件传输协议(SMTP)、域名服务(DNS)、和超文本传送协议(HTTP)等。
13、三次握手和四次挥手
TCP建立连接需要三次握手:
首先服务器端创建一个传输控制块,进入listen状态。
第一次握手:
然后客户端创建一个传输控制块,开始发送一个连接请求报文:
SYN=1,seq=x,进入syn_sent状态
第二次握手:
服务器端收到客户端的请求之后,同意与它连接,并发送一个同意请求连接的报文:
SYN=1,ACK=1,seq=y,ack=x+1(客户端的序列号+1),进入syn_recieve状态
第三次握手:
客户端收到服务器的确认连接后,再次发送一个确认收到对方确认的报文:
SYN=1,ACK=1,seq=x+1(等于对方的确认号),ack=y+1,进入连接状态
服务器端收到客户端的确认之后,进入连接状态。
TCP断开连接的四次挥手:(由于TCP的连接是全双工的,所以关闭时需要两个方向上都单独进行关闭)
第一次挥手:
首先客户端这边主动发送一个请求断开连接的报文:
FIN=1,seq=x;进入终止等待1.
第二次挥手:
服务器端收到断开请求后,发送一个同意断开的报文:
ACK=1,ack=x+1,seq=y;进入关闭等待1
第三次挥手:
服务器准备好断开后,发送一个请求断开的报文:
FIN=1,seq=z;进入最后等待阶段。
第四次挥手:
客户端收到服务器端的断开请求后,发送一个同意断开的报文:
ACK=1,ack=z+1,seq=h;客户端正式进入终止等待2。
服务器接收到客户端的确认之后,立即进入close状态。
客户端等待2MSL(报文最大生命)后,也进入close状态。(原因:为了防止最后一个ACK报文服务器没有收到,它要继续给服务器端发送ACK报文。)
14、HTTP原理
HTTP是一个无状态协议,意味着客户端(web浏览器)服务器之间不需要建立持久的连接。当客户端发起请求,然后服务器端返回应答,连接就被关闭了,服务器端不保留连接有关的信息。所有HTTP连接都被构造成一套请求和应答。(默认80端口)
传输的流程:
1.地址解析:根据域名到DNS服务器上解析出主机的IP地址
2.封装HTTP数据包:把域名解析到的数据和客户端自己的信息封装成一个HTTP请求包。
3.封装成TCP包并建立连接(三次握手)
4.建立连接后,浏览器发送一个请求给服务器
5.服务器接收到请求之后,基于相应的响应信息。
6.服务器关闭TCP连接:一般情况下,一旦Web服务器向浏览器发送了请求数据,它就要关闭TCP连接,然后如果浏览器或者服务器在其头信息加入了这行代码Connection:keep-alive,TCP连接在发送后将仍然保持打开状态,节省了网络带宽。
15、HTTPS
HTTPS,是以安全为目标的HTTP通道,简单讲是HTTP+SSL层。(默认端口号443)
HTTPS的整体过程分为证书验证和数据传输阶段,具体的交互过程如下:
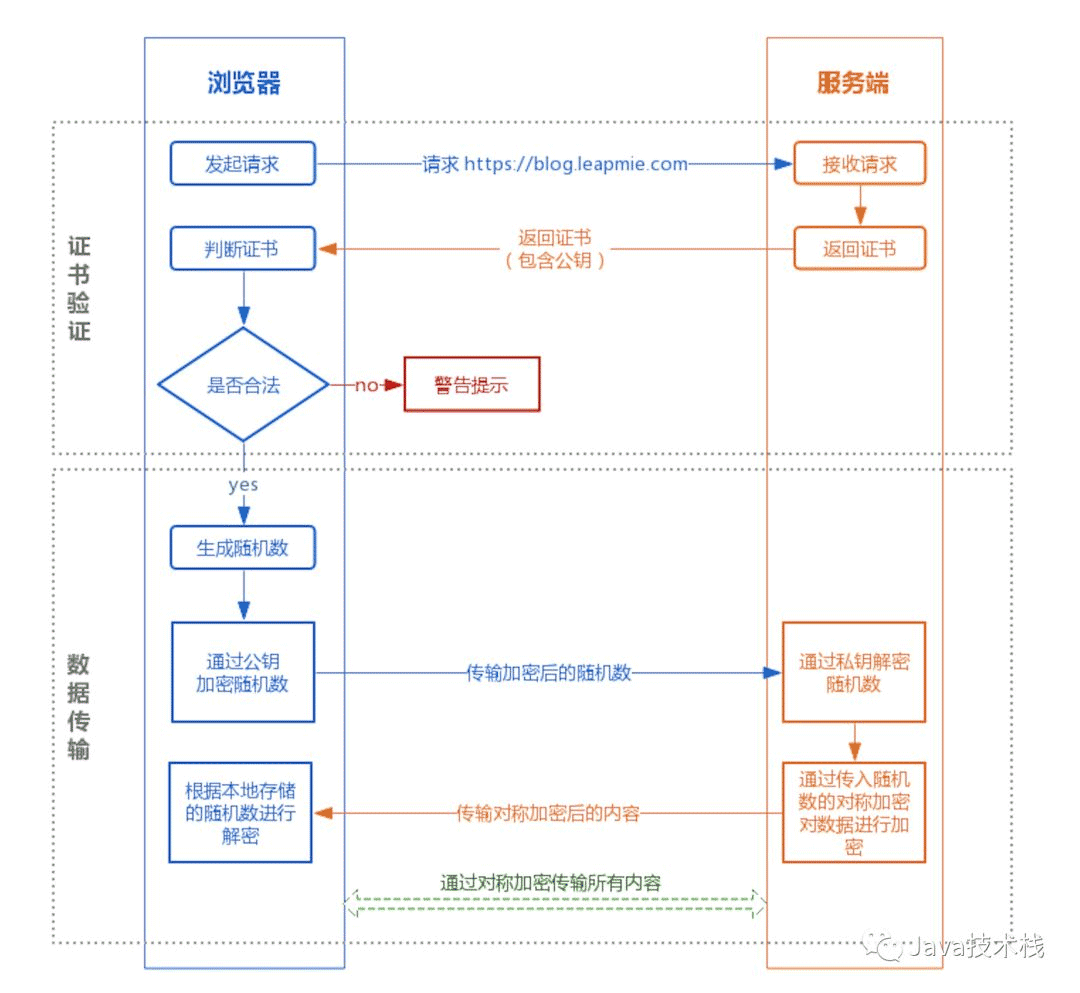
① 证书验证阶段
1.浏览器发起 HTTPS 请求
2.服务端返回 包含公钥HTTPS 证书。客户端验证证书是否合法,如果不合法则提示告警
② 数据传输阶段
1.当证书验证合法后,在本地生成随机数
2.通过公钥加密随机数,并把加密后的随机数传输到服务端
3.服务端通过私钥对随机数进行解密
4.服务端通过客户端传入的随机数构造对称加密算法,之后双方通过该随机数秘钥进行加密通话。
对称秘钥加密:双方通过同一把秘钥进行数据的加密和解密。
非对称秘钥加密:一方通过公钥进行加密,一方通过另一把私钥进行解密。
16、关系型数据库和非关系型数据库的区别
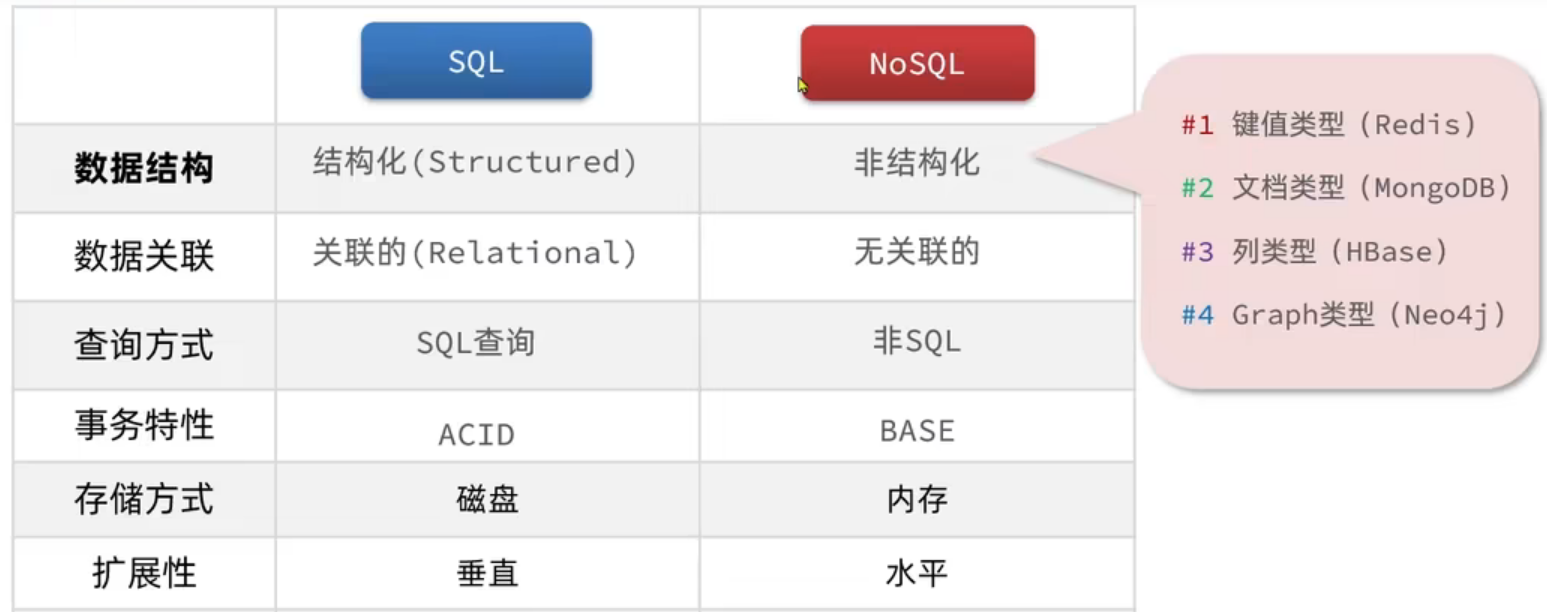
1、数据存储方式不同
- 关系型数据库天然就是表格式的,数据表可以彼此关联存储,也很容易提取数据。
- 而非关系型数据库是以key-value的形式存储的
2、事务的支持不同
- 关系型数据库汇总有事务的概念
- 非关系型数据库中没有事务,它的每一个数据集都是原子级别的
3、扩展方式不同
- 关系型数据库容易纵向扩展,但是想要横向扩展就必须改变表结构
- 非关系型数据库天然是分布式的,很灵活,容易横向扩展