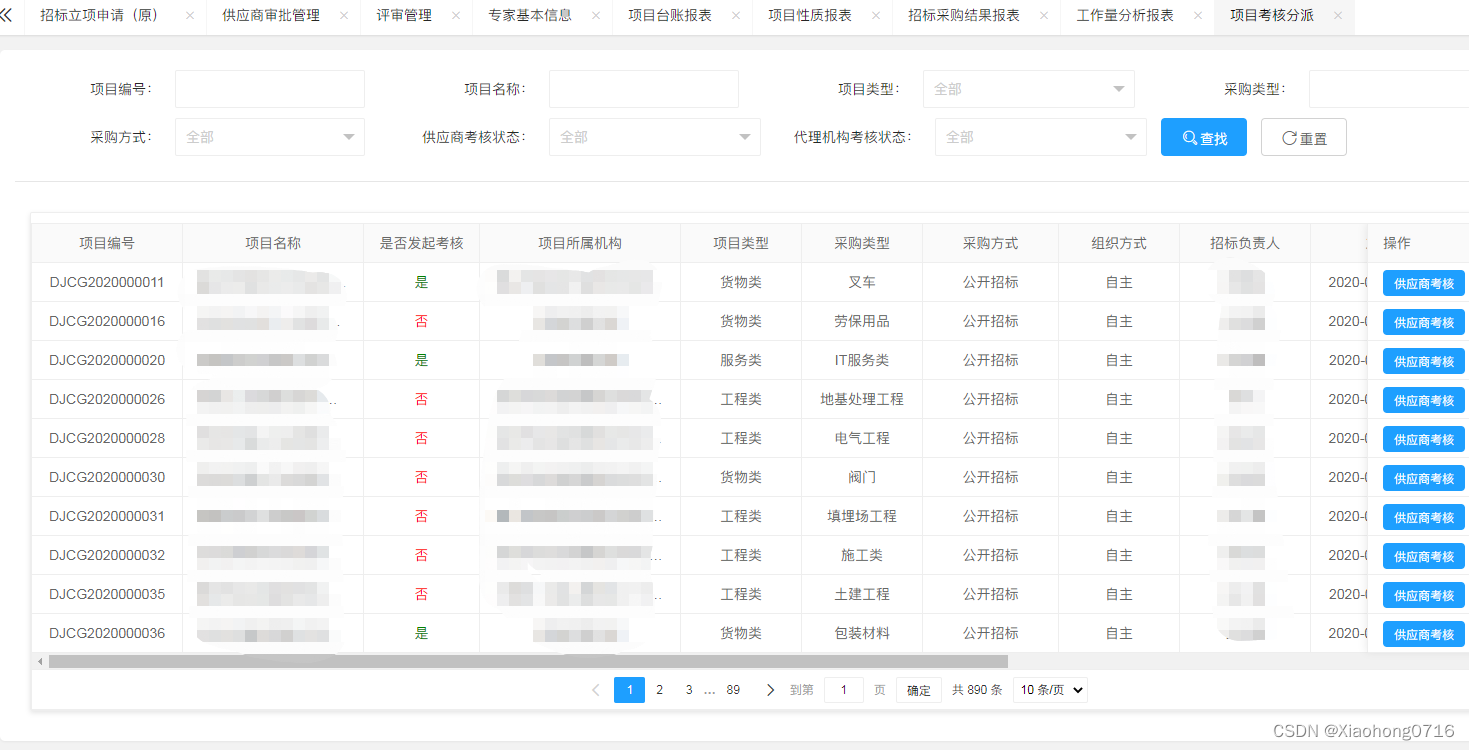
编译型语言 VS 解释型语言
计算机高级语言按程序执行方式分为编译型和解释型
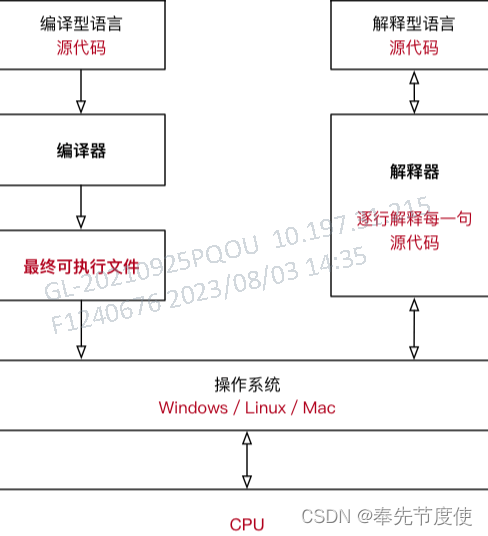
编译型语言
- 所有源代码一次性通过编译器转换成二进制指令,即生成一个可执行程序(如Windows下的.exe),可执行程序包含的就是机器码;且无需重新编译,实现一次编译,无限次运行
- 运行可执行程序时,不再需要源代码和编译器,因此编译型语言可以脱离开发环境运行
- 编译型语言一般不能跨平台,因为编译型语言与平台联系比较紧密(操作系统都是用编译型语言编写的),不同平台(操作系统)可能有其特定的编写规则,即不能在不同的操作系统之间随意切换
- 编译型语言包括诸如C、C++、Golang、Pascal(Delphi)、汇编等编程语言
编译器的类型
- 前端编译器:编译器的分析阶段也称为前端,它将程序划分为基本的组成部分,检查代码的语法、语义和语法,然后生成中间代码。分析阶段包括词法分析、语义分析和语法分析
- 后端编译器:编译器的合成阶段也称为后端,优化中间代码,生成目标代码。合成阶段包括代码优化器和代码生成器
解释型语言
- 每次执行程序都需要通过解释器一边执行一边转换,需要哪些源代码就转换哪些源代码,不生成可执行程序
- 每次执行程序都需要重新转换源代码,所以无法脱离开发环境,所以解释型语言的执行效率天生就低于编译型语言,甚至存在数量级的差距
- 解释型语言能跨平台,即实现“一次编写,到处运行”
- 解释型语言包括诸如Python、JavaScript、PHP、Shell、MATLAB等编程语言
半编译半解释型语言(结合编译和解释)
- 源代码需要先通过前端编译器转换成中间文件(字节码文件),然后再将中间文件加载虚拟机中解释和编译执行,由于每个平台对应一个虚拟机,因此是源代码是可跨平台的,即实现“一次编写,到处运行”
- 既使用解释器也使用编译器
- 半解释和半编译语言包括诸如Java和C#等编程语言
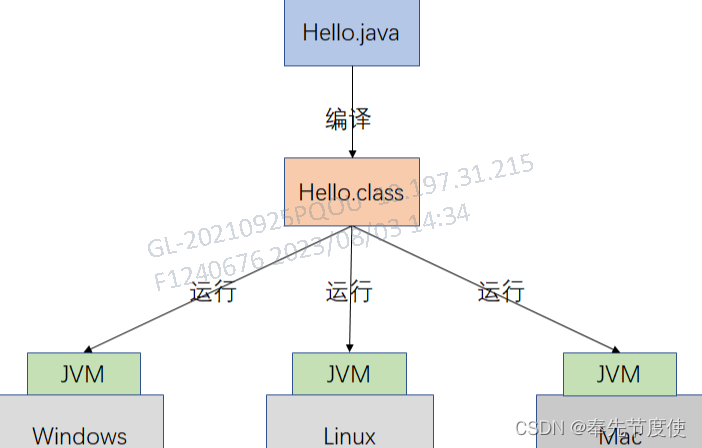
比如Java源代码执行流程
编译和解释型语言对比

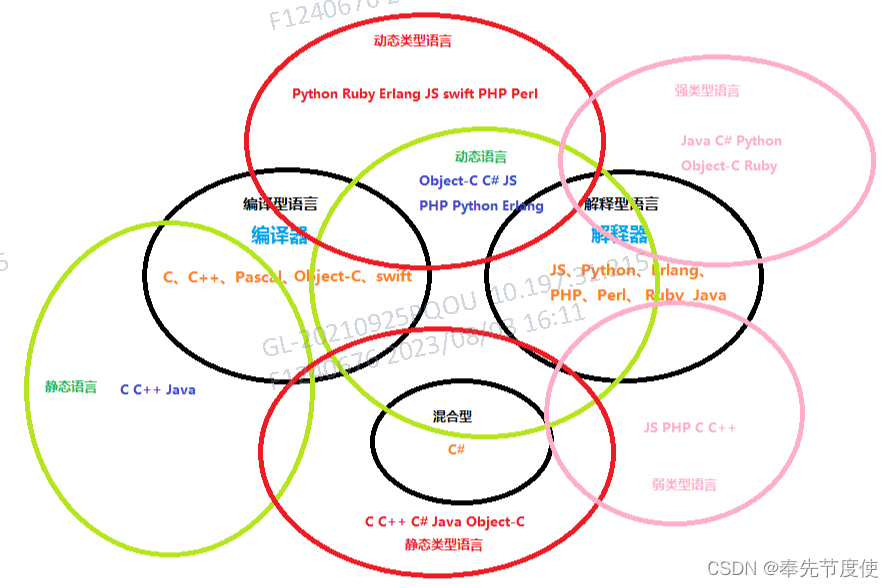
动态 VS 静态 & 强类型VS弱类型
概述
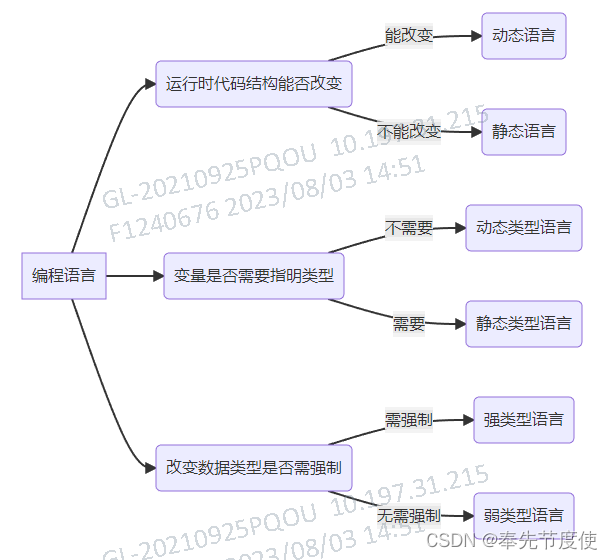
详情
| 名称 | 定义 | 举例 | 优势 | 劣势 | 编程语言 | |
|---|---|---|---|---|---|---|
| 动态语言 | 类在运行时可以改变其结构的语言。(强调改变代码结构) | 例如新的函数、对象、甚至代码可以被引进,已有的函数可以被删除或是其他结构上的变化。 | / | / | Object-C、C#、JavaScript、PHP、Ruby、Python、Erlang。 | |
| 静态语言 | 与动态语言相对应的,运行时结构不可变的语言就是静态语言。(强调改变代码结构) | / | / | / | Java、C、C++。 | |
| 动态类型语言 | 在运行时,确认数据类型的语言,变量在使用之前无需申明类型,通常变量的值是被赋值的那个值的类型。(强调检查数据类型) | 伪代码:
| 1.思维不受束缚,可以任意发挥,把更多的精力放在产品本身。 2.集中思考业务逻辑实现,思考过程即实现过程。 | 代码运行期间有可能会发生与类型相关的错误。 | PHP、ASP、JavaScript、Python、Perl、SQL、Ruby、ABAP、Unix Shell等。 | |
| 静态类型语言 | 在编译时,变量的数据类型就可以确定的语言。 多数静态类型语言要求在使用变量之前必须声明数据类型。(强调检查数据类型) | 伪代码:
| 1.由于类型的强制声明,IDE(集成开发环境)有很强的代码感知能力,因此,在实现复杂的业务逻辑,开发大型商业系统,以及那些生命周期很长的应用中,依托IDE对系统的开发很有保障。 2.由于静态类型语言相对比较封闭,使得第三方开发包对代码的侵害性可以降到最低 | 1.开发代码的时候,需要格外注意变量的类型。 2.过多的类型声明会增加更多的代码 | C、C++、Java、Delphi、C#等。 | |
| 强类型语言 | 强制数据类型定义的语言。 一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型。(强调转换数据类型) | 例如,不能把一个整形变量当成一个字符串来处理。 | 强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。 | Java、C#、Python、Object-C、Ruby | ||
| 弱类型语言 | 数据类型可以被忽略,一个变量可以赋不同数据类型的值。(强调转换数据类型) | 一个变量可以赋不同数据类型的值。 | / | JavaScript、PHP、C、C++(C 和 C++ 有争议,但是确实可以给一个字符变量赋整形值,可能初衷是强类型,形态上接近弱类型) |