尚硅谷Python爬虫教程小白零基础速通(含python基础+爬虫案例)
内容包括:Python基础、Urllib、解析(xpath、jsonpath、beautiful)、requests、selenium、Scrapy框架
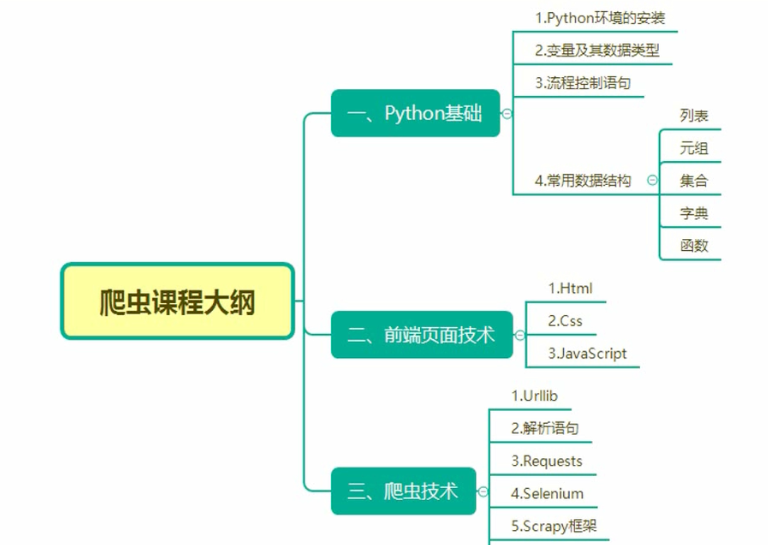
python基础 + 进阶(字符串 列表 元组 字典 文件 异常)
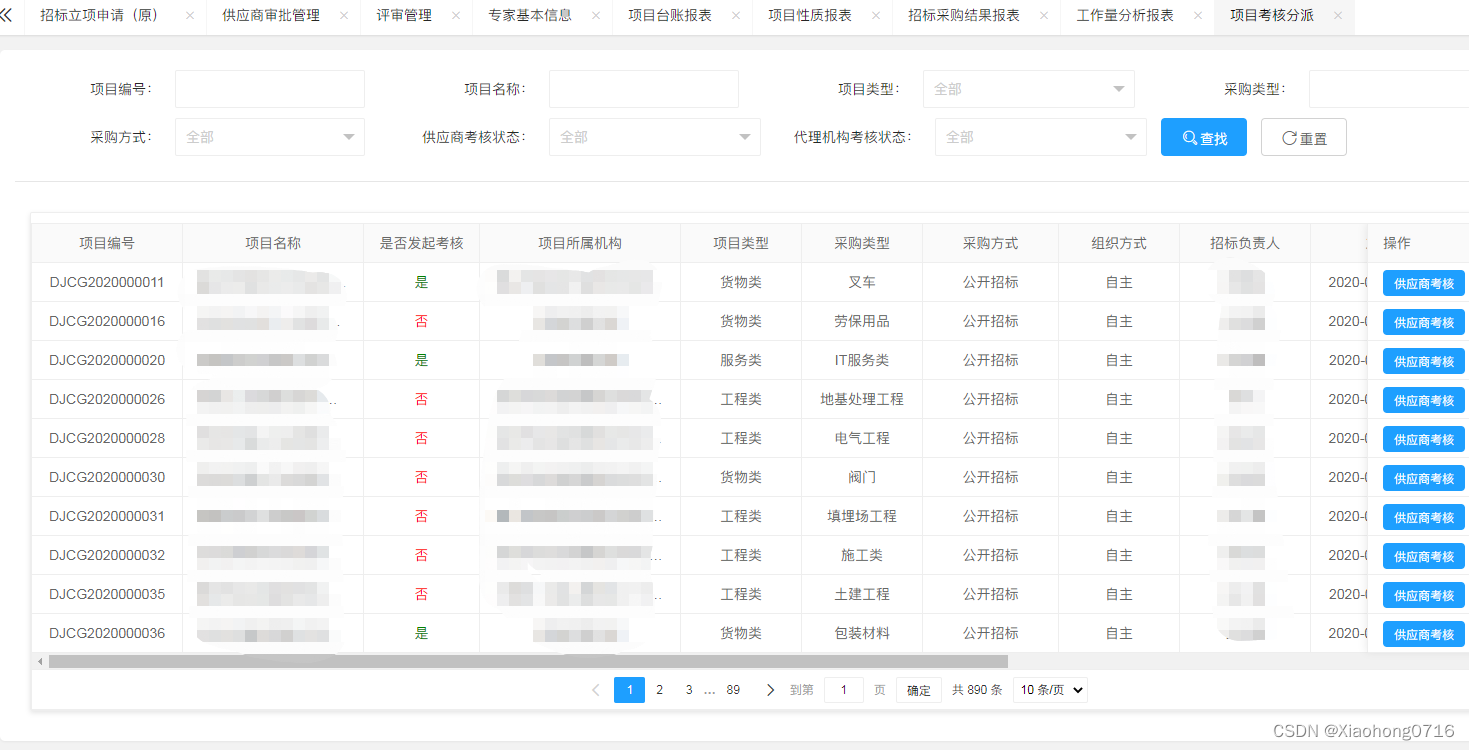
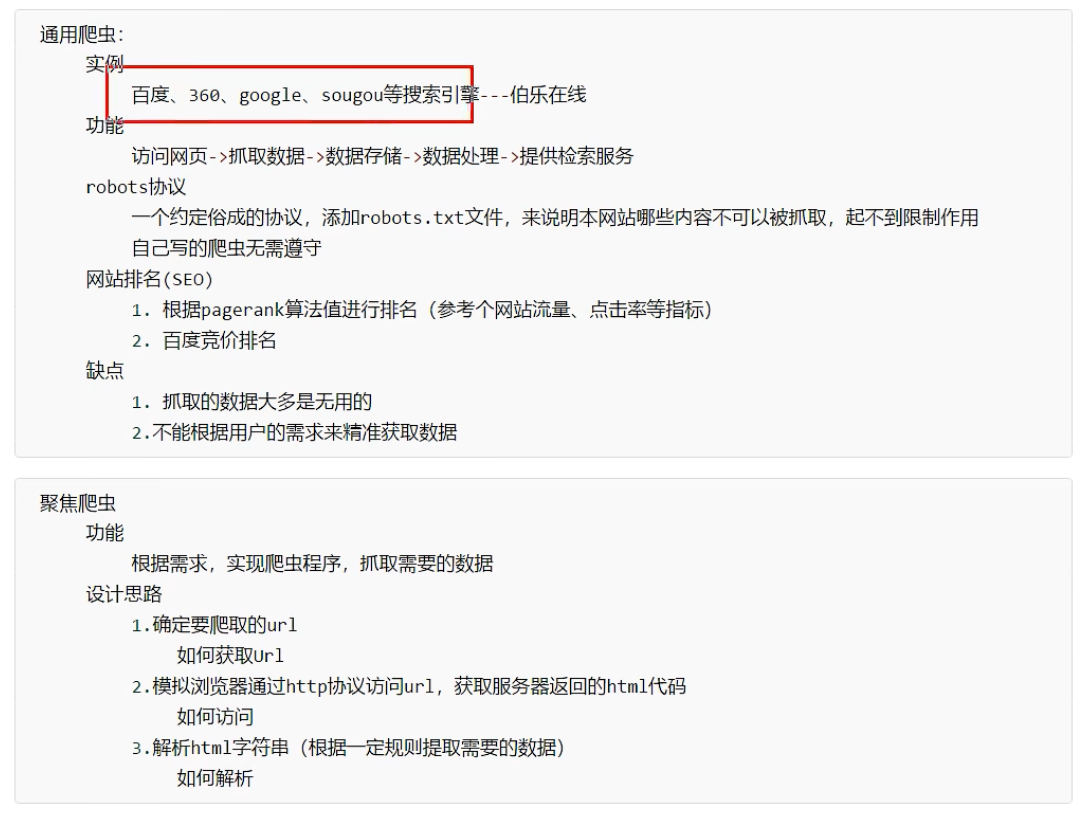
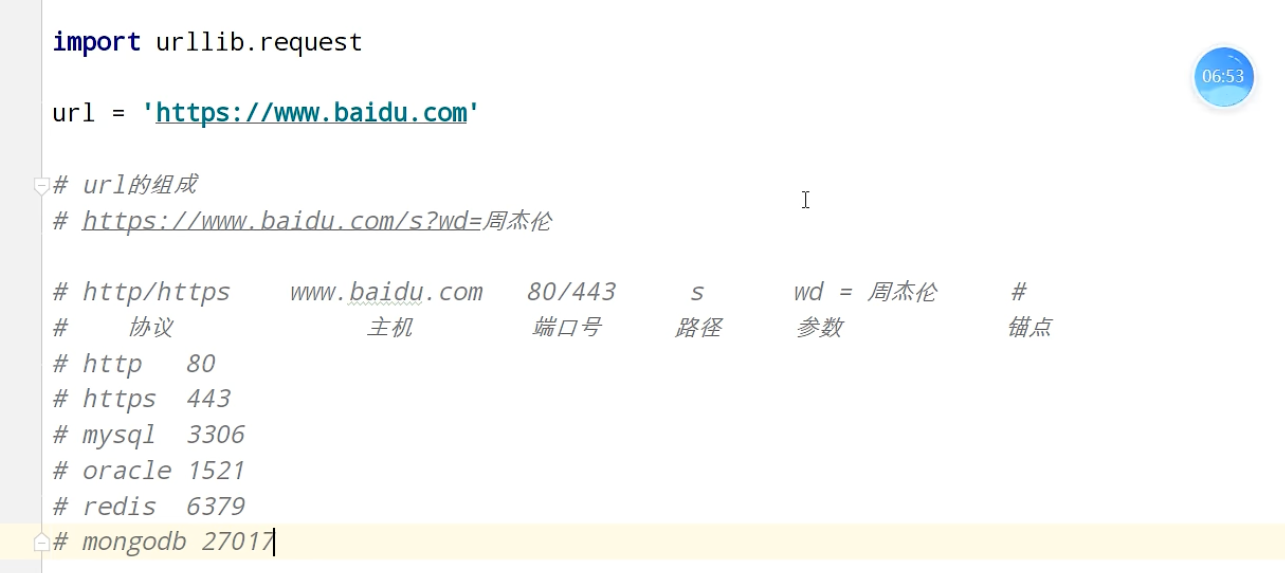
页面结构
爬虫



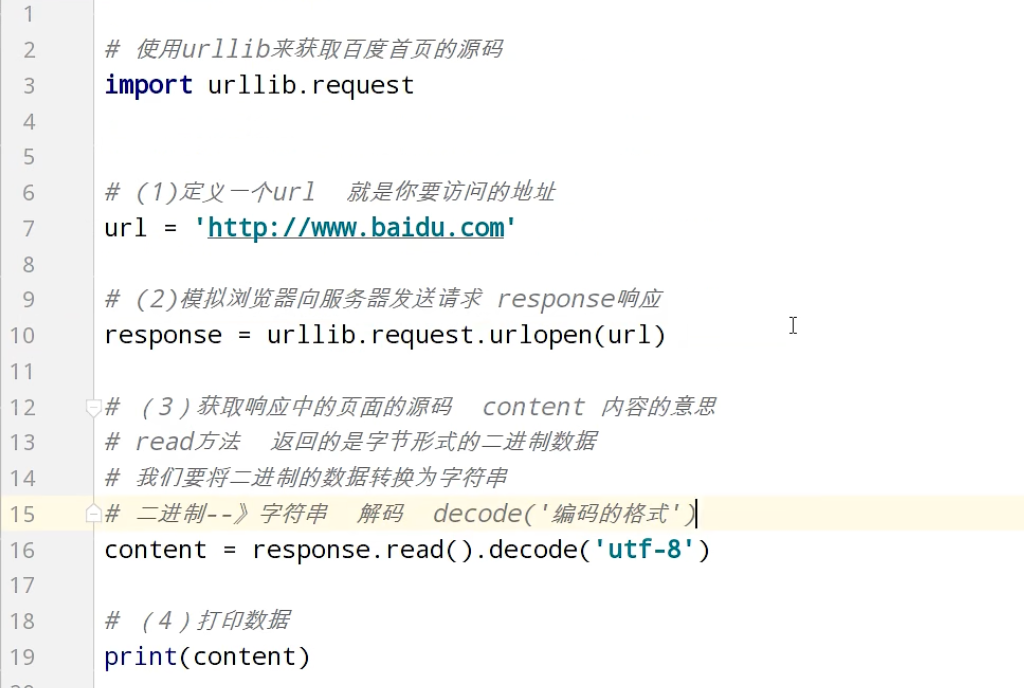
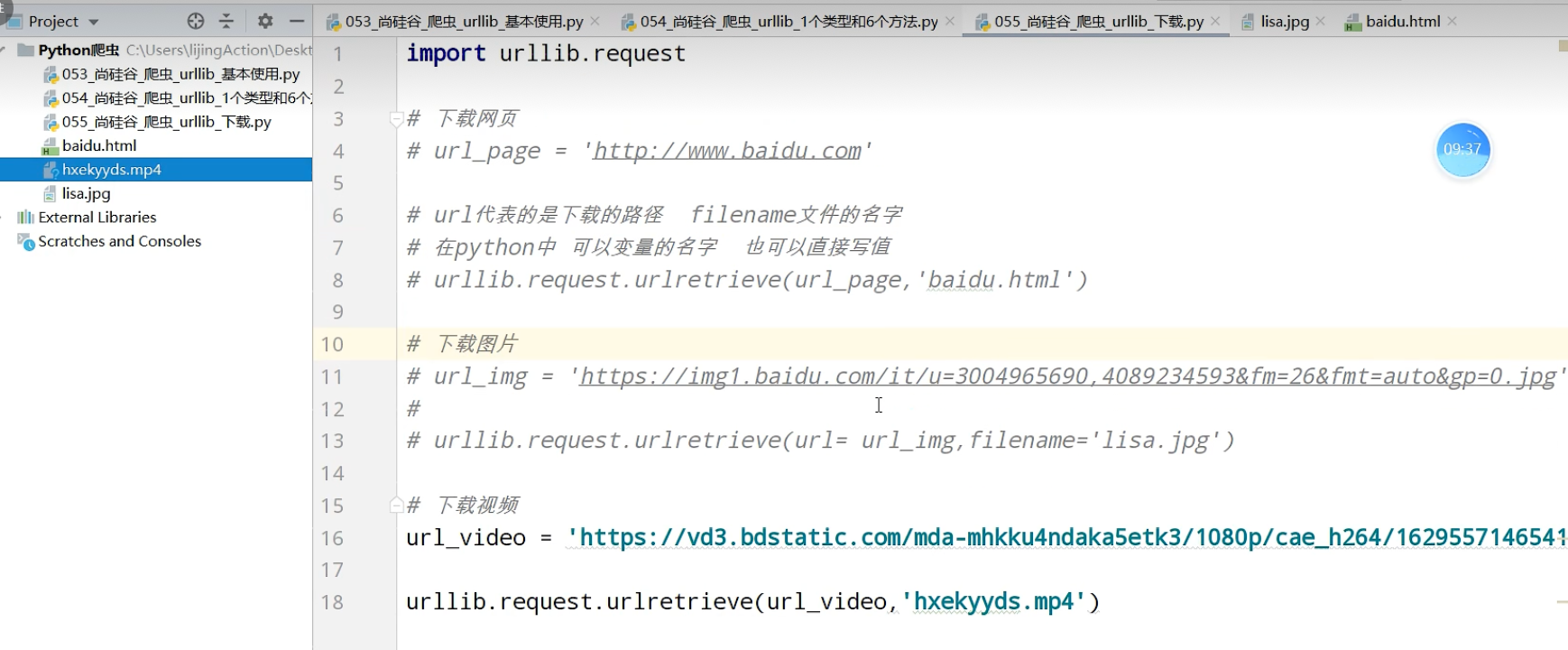
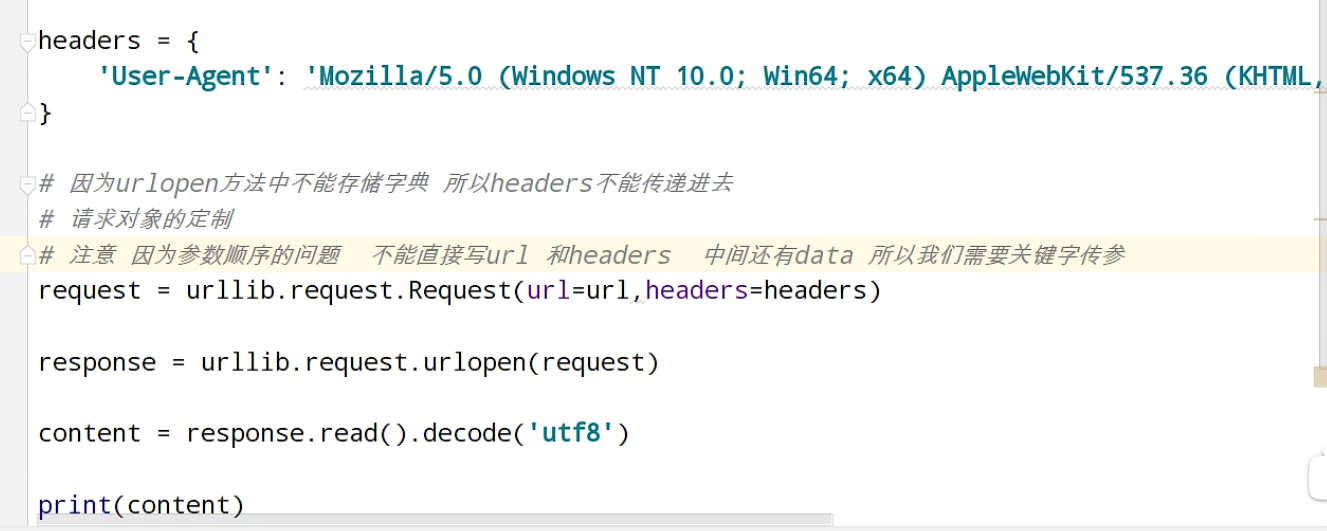
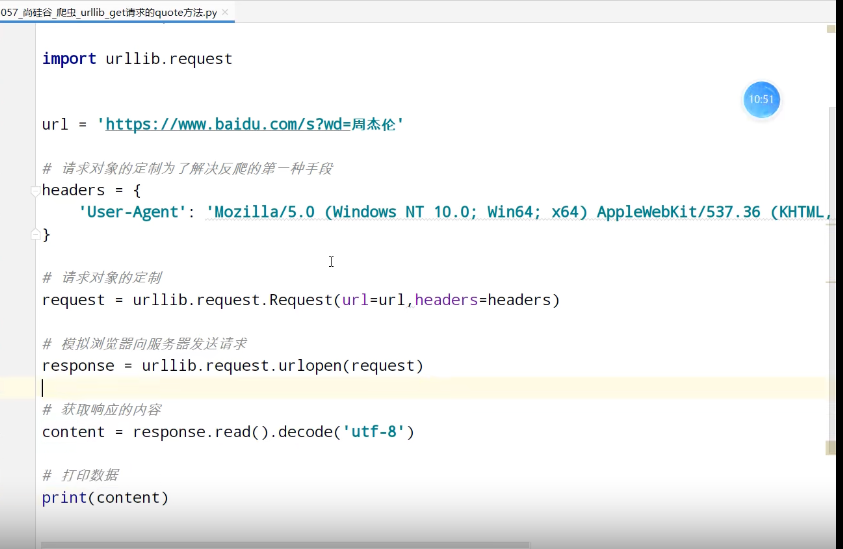
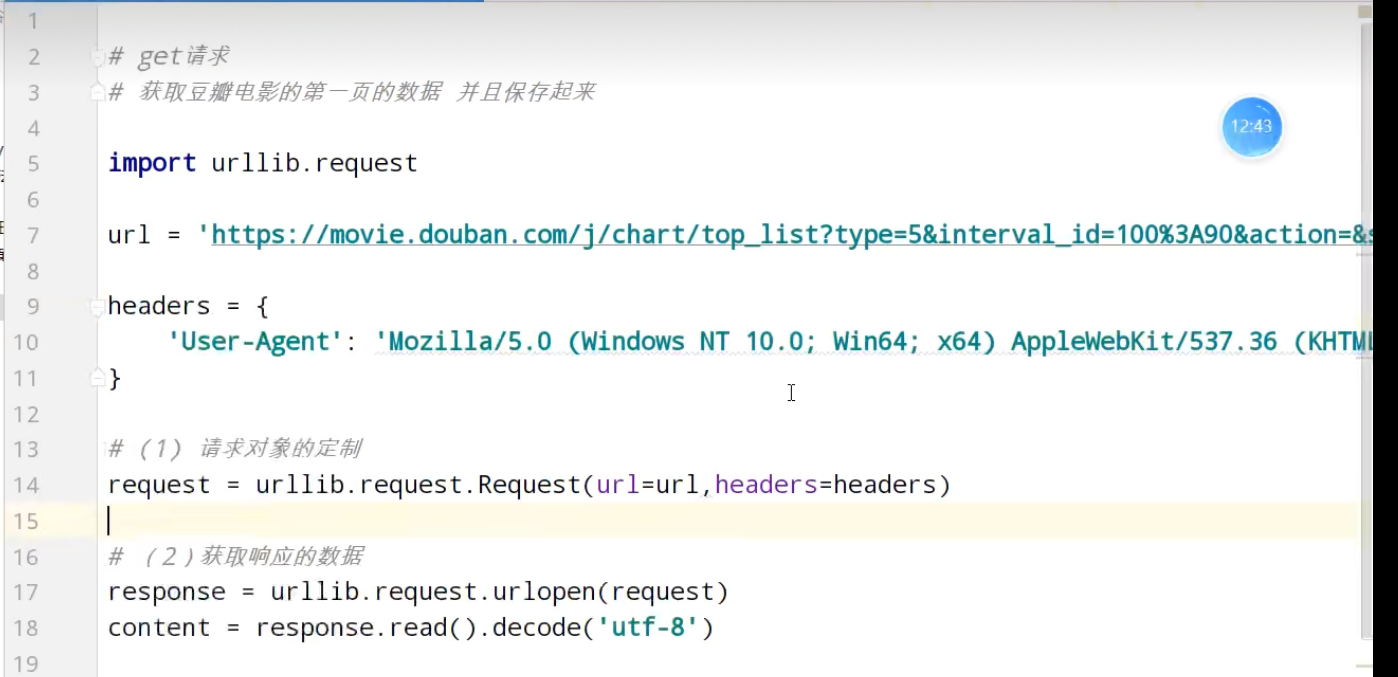
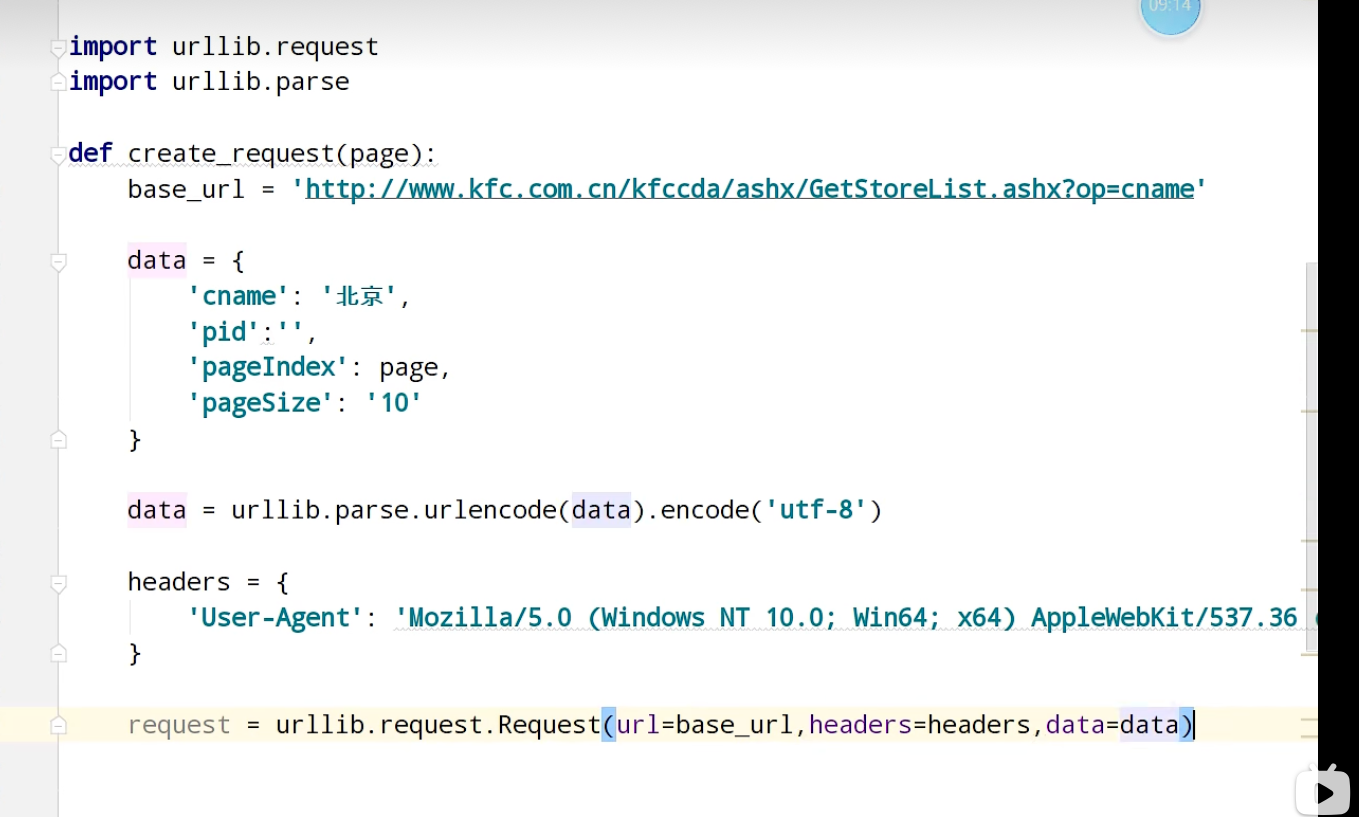
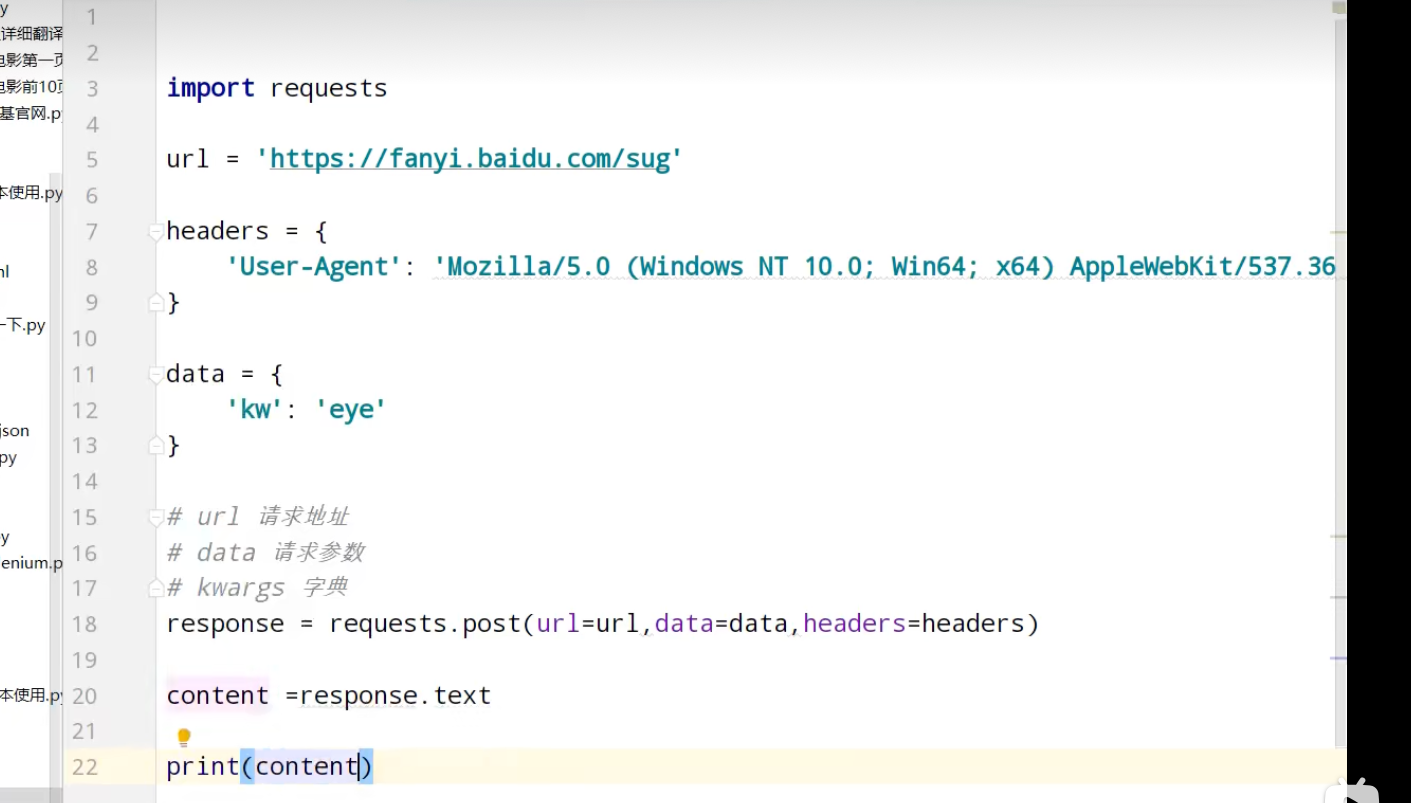
urllib_get请求的quote方法
编码集的演变
由于计算机是美国人发明的,因此,最早只有127个字符被编码到计算机里,也就是大小写英文字母、数字和一些符号,
这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母z的编码是122。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,
所以,中国制定了GB2312编码,用来把中文编进去。
你可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,
各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。
现代操作系统和大多数编程语言都直接支持Unicode。

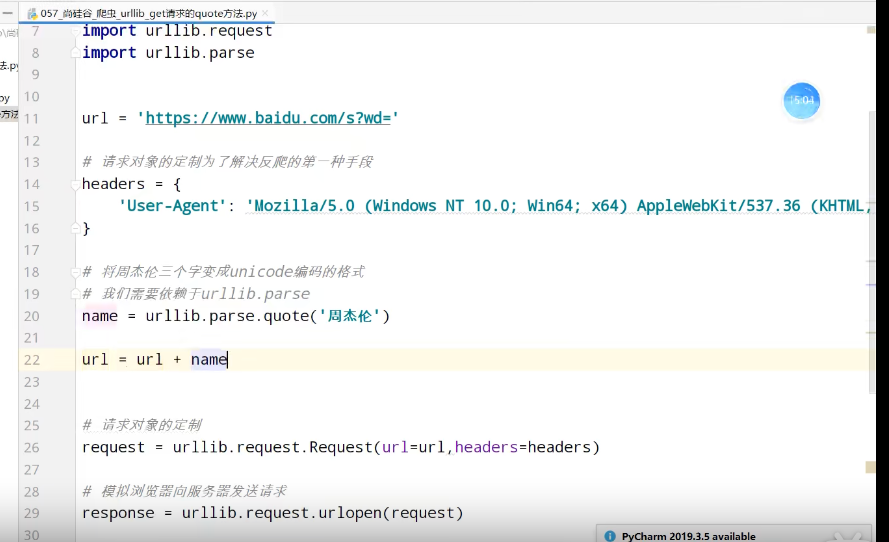
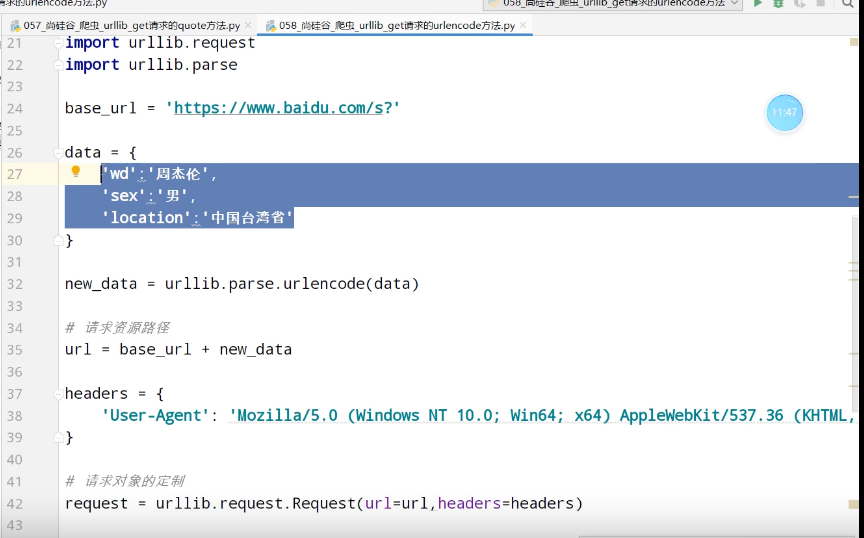
urllib_get请求的urlencode方法
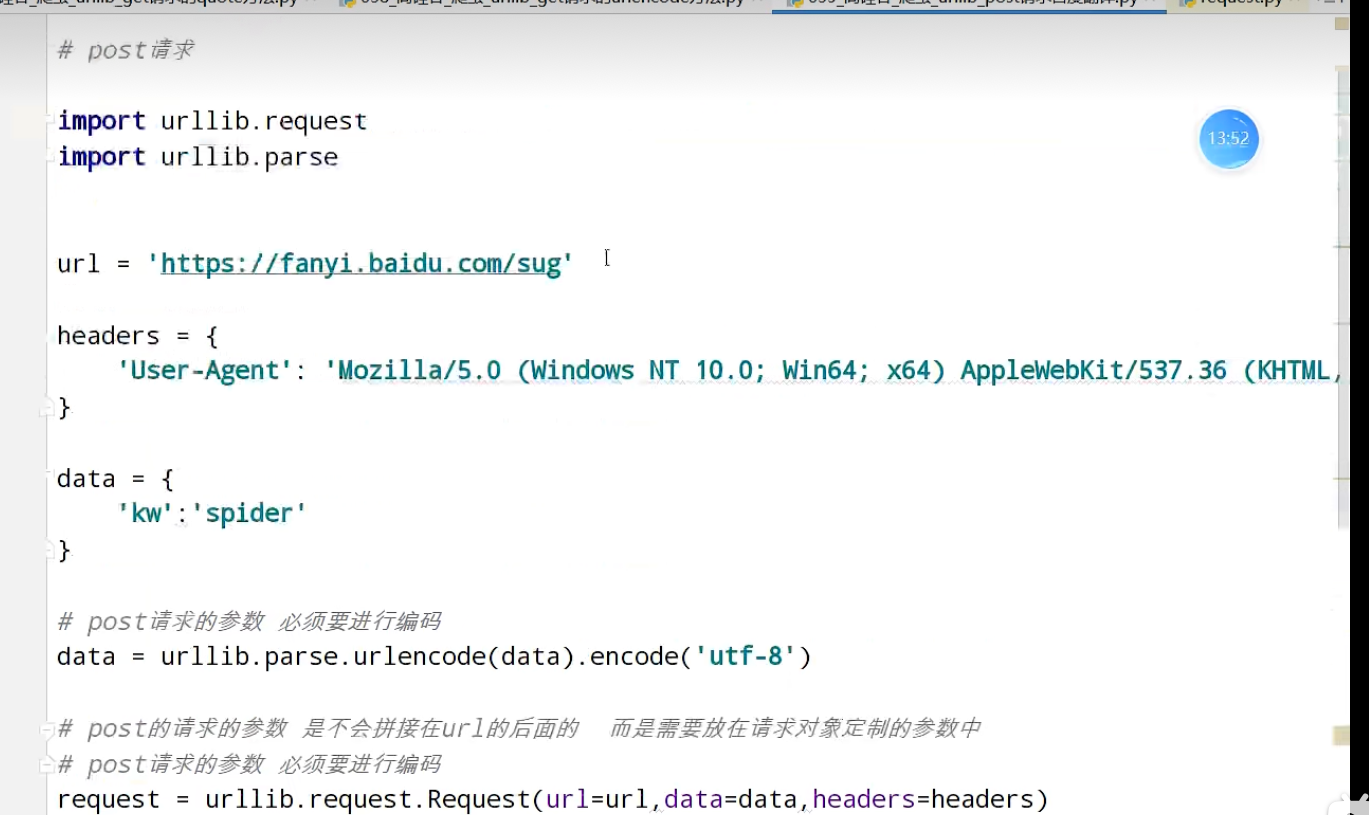
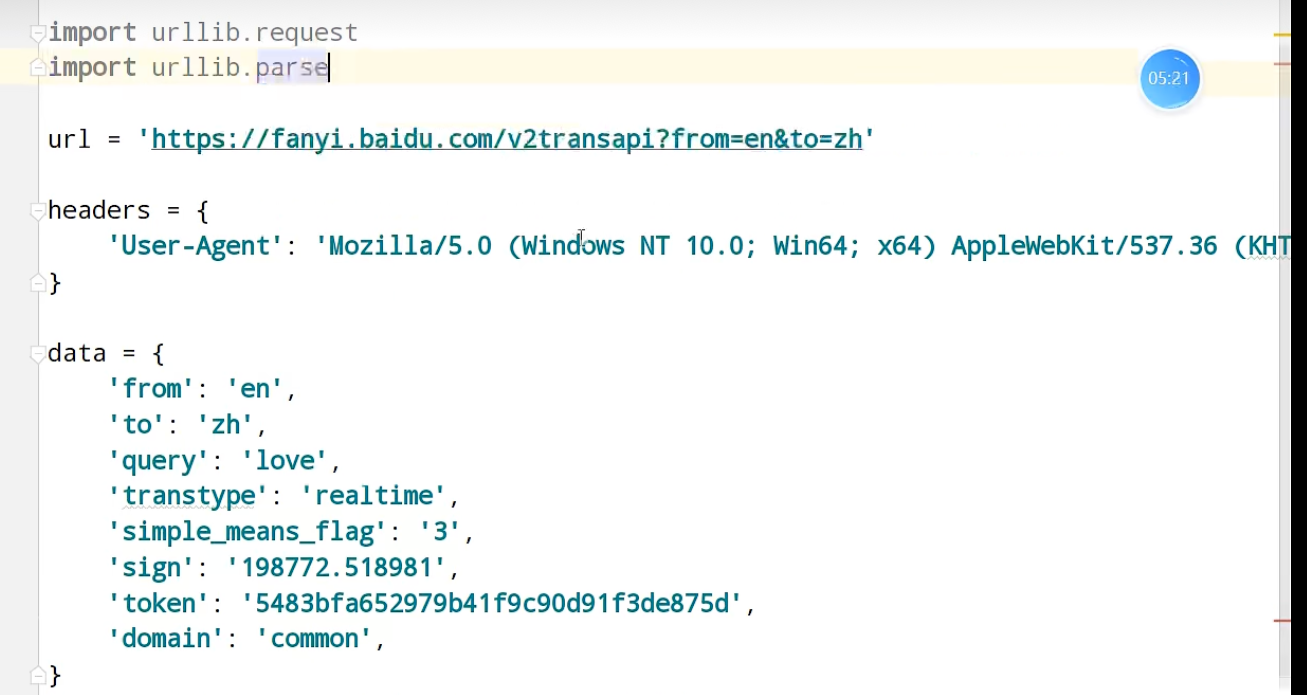
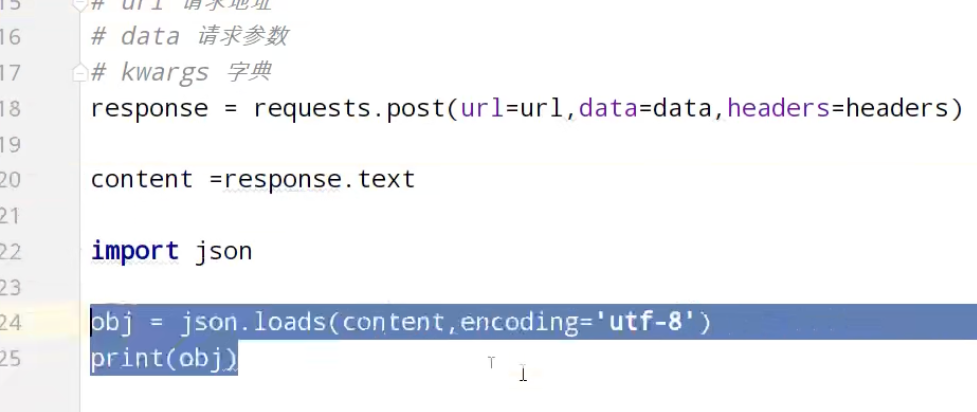
urllib_post

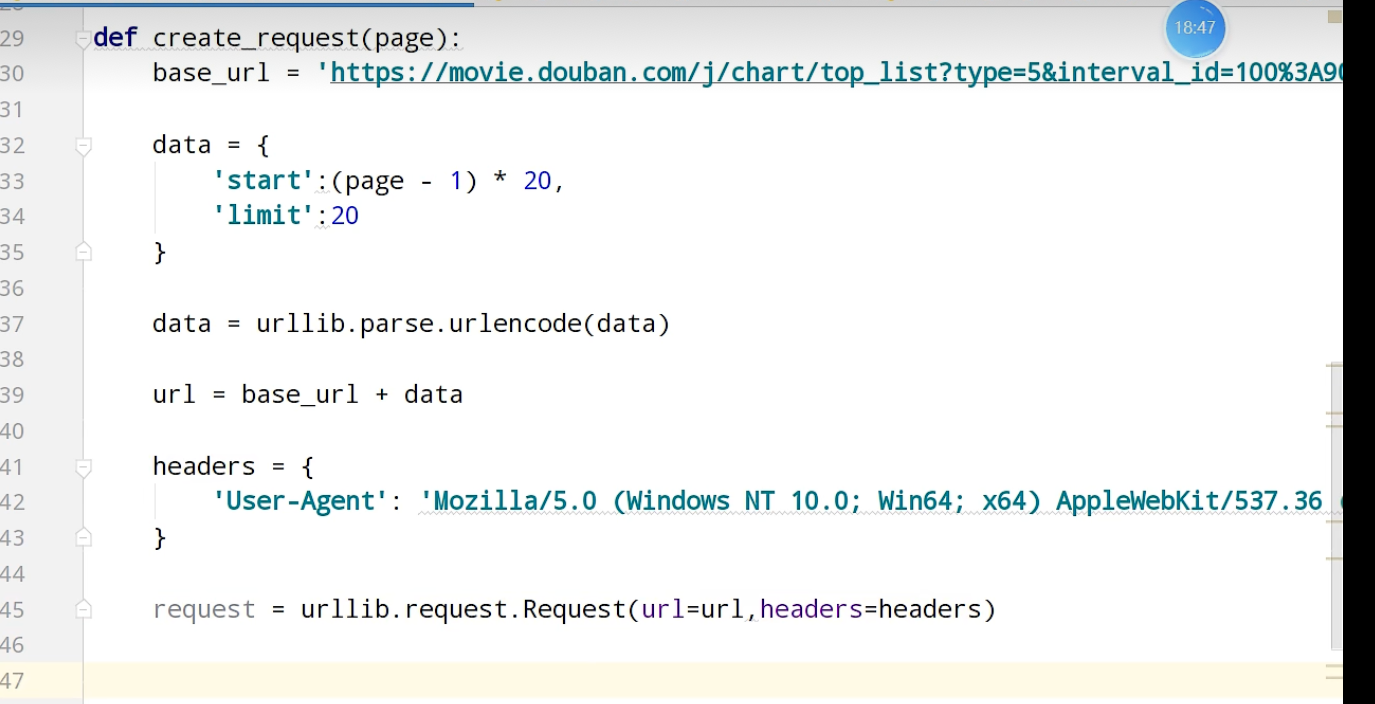
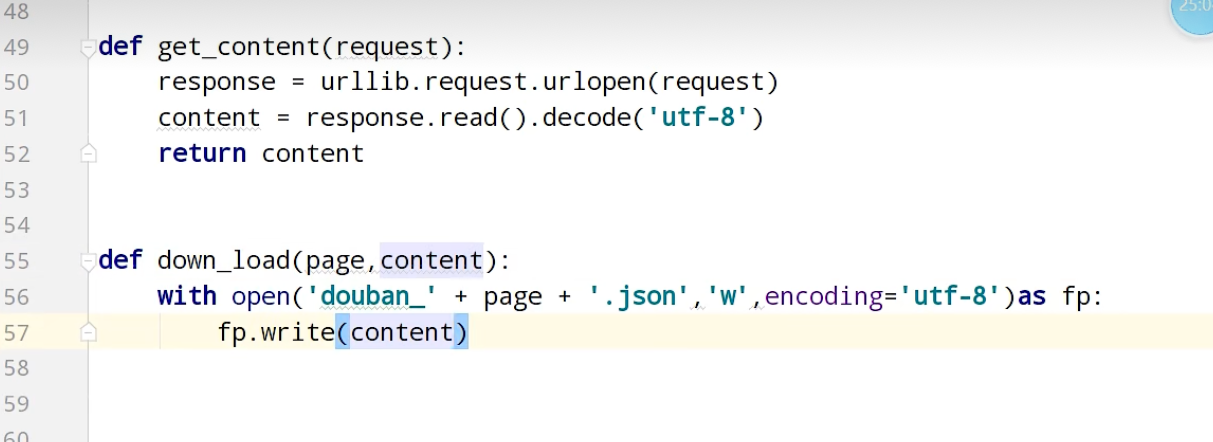
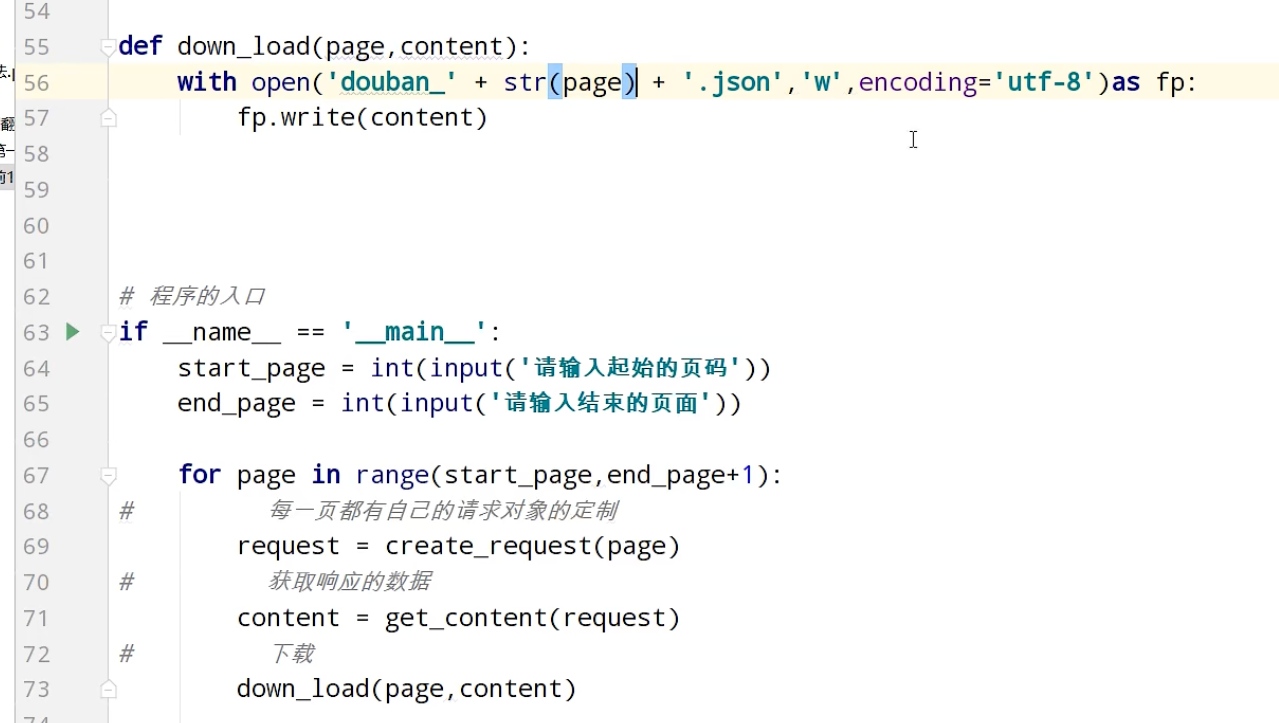
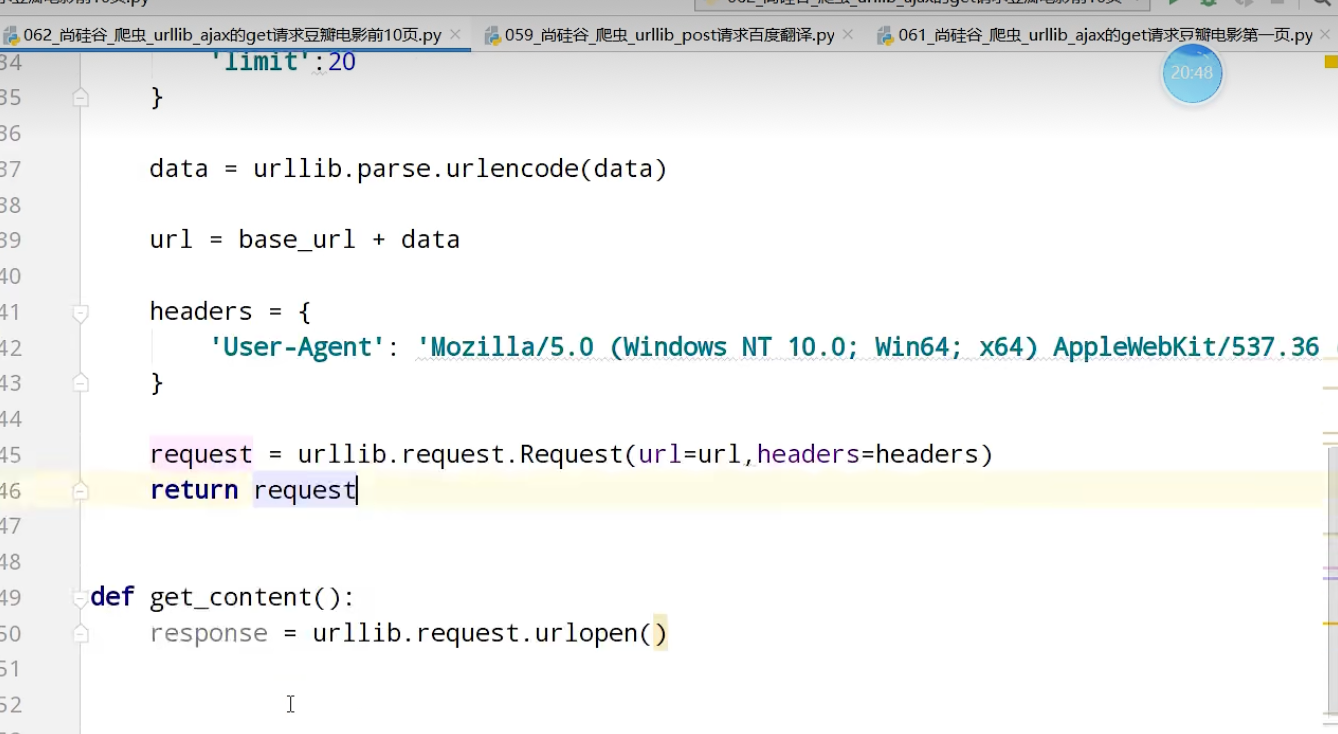
ajax的get请求
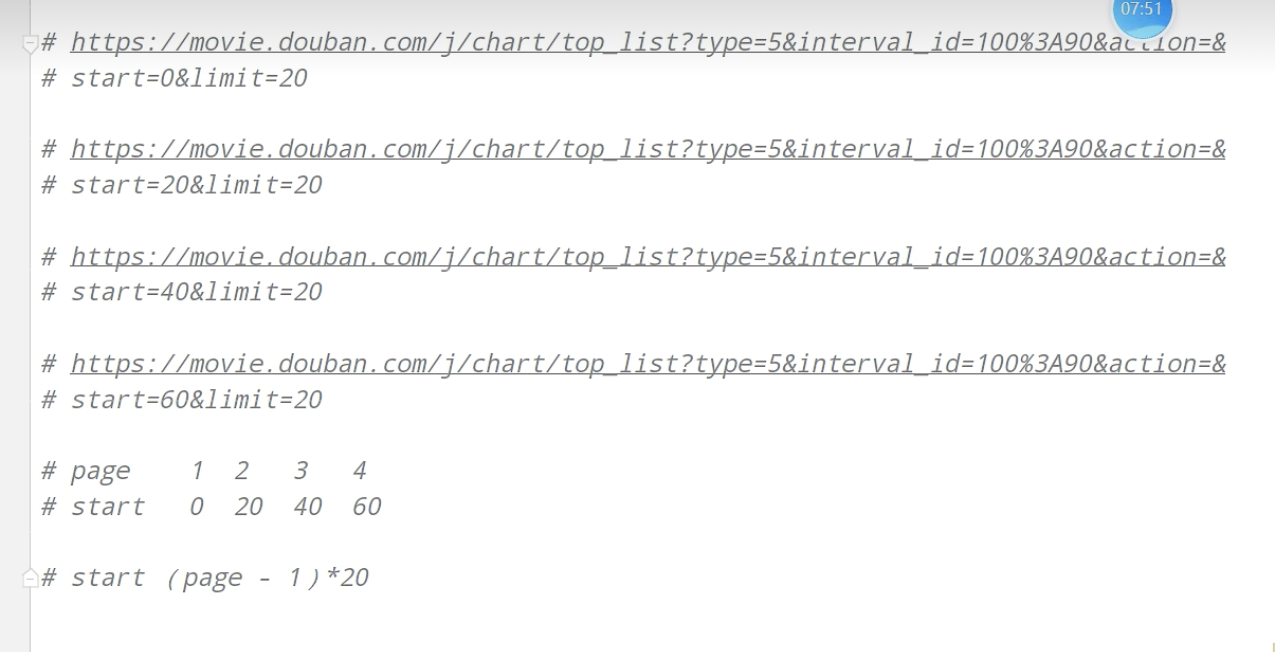
豆瓣电影前十页
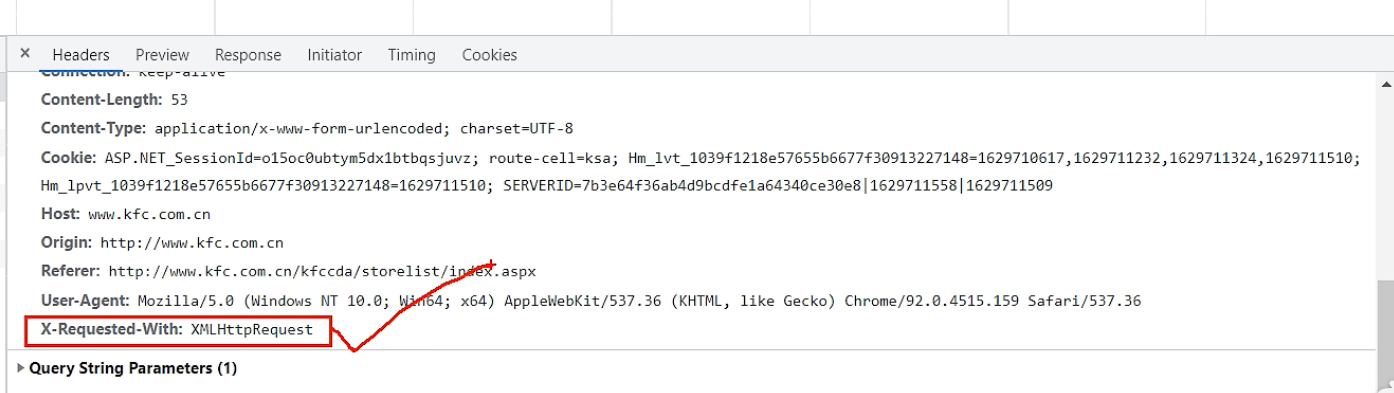
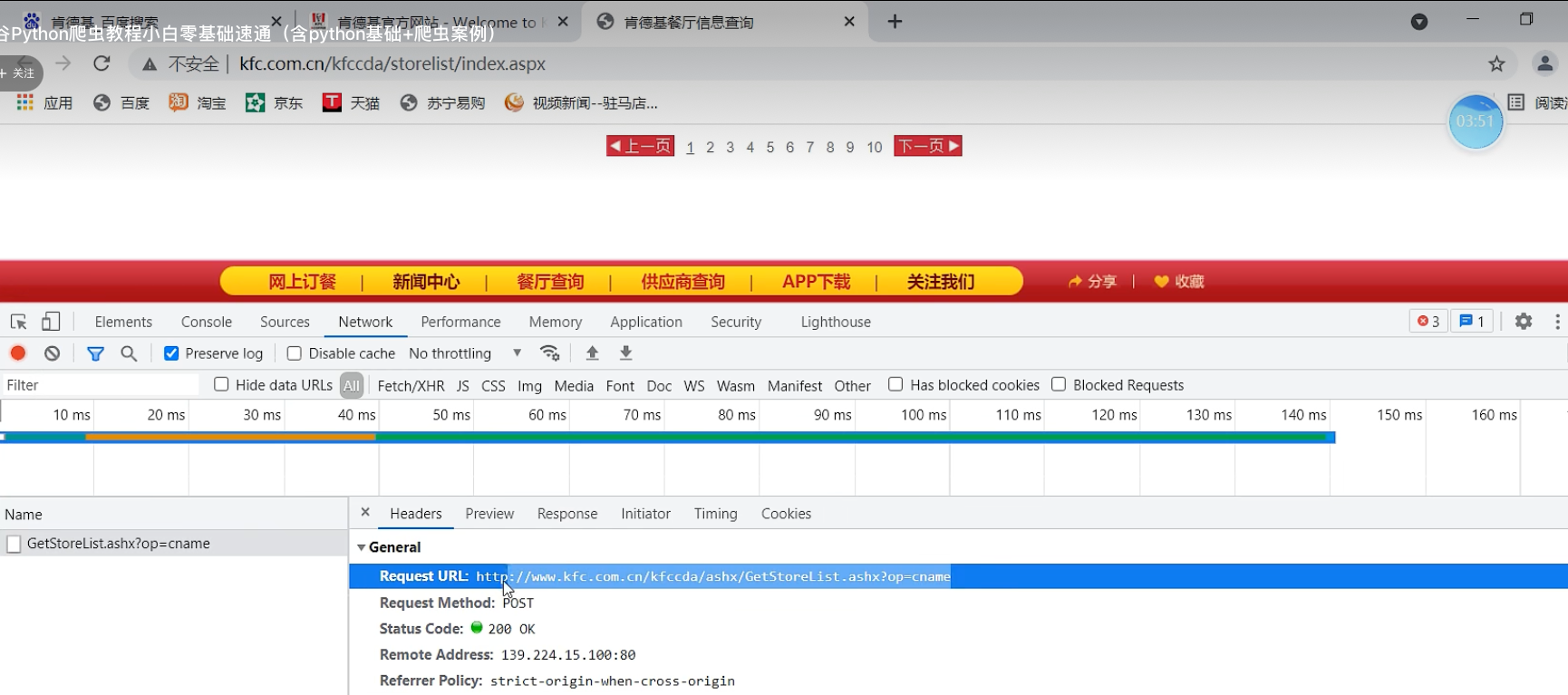
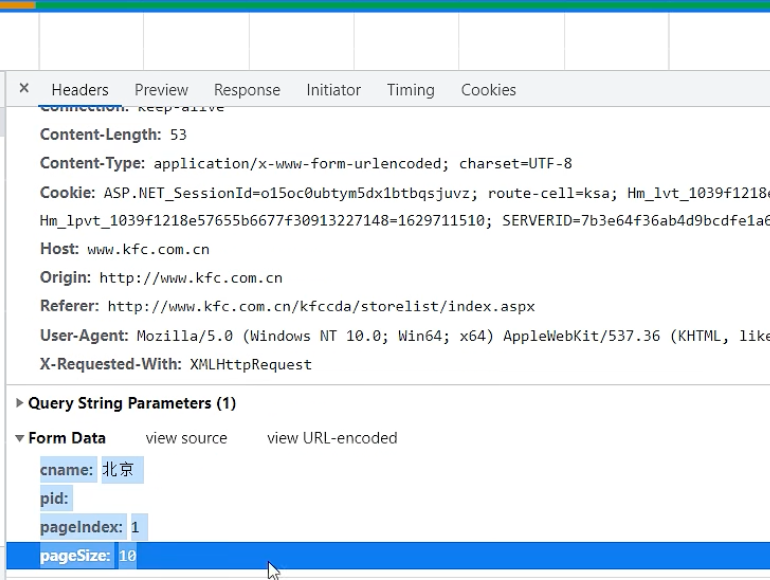
ajax的post请求
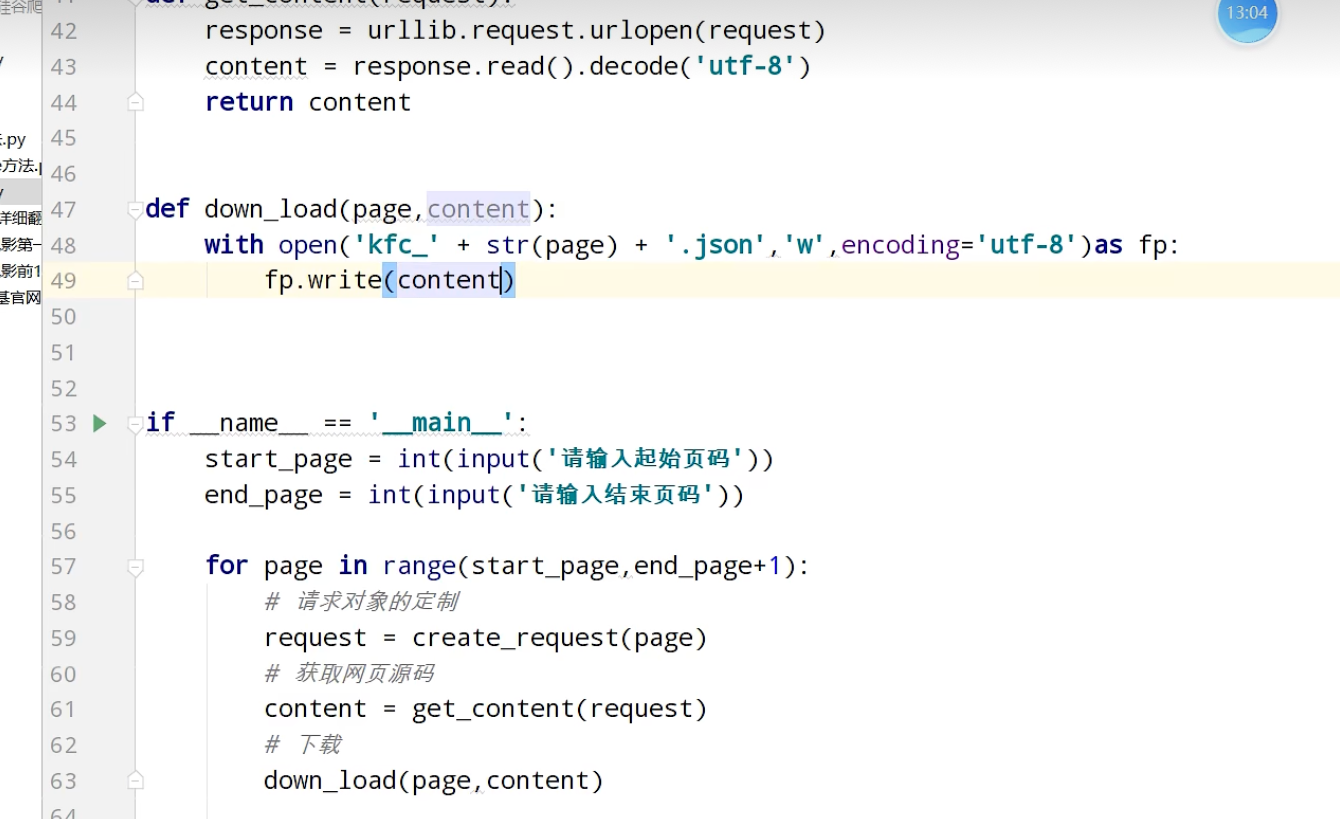
肯德基的餐厅信息
判断ajax请求

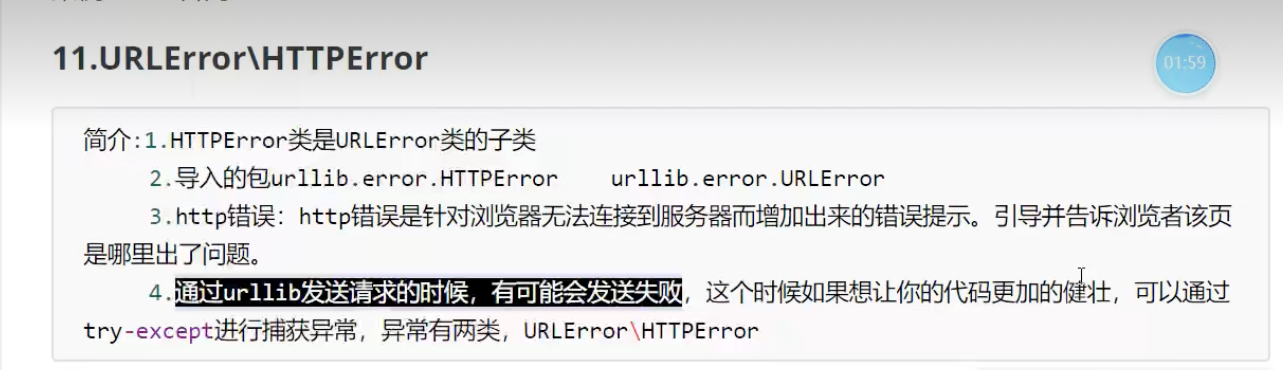
异常
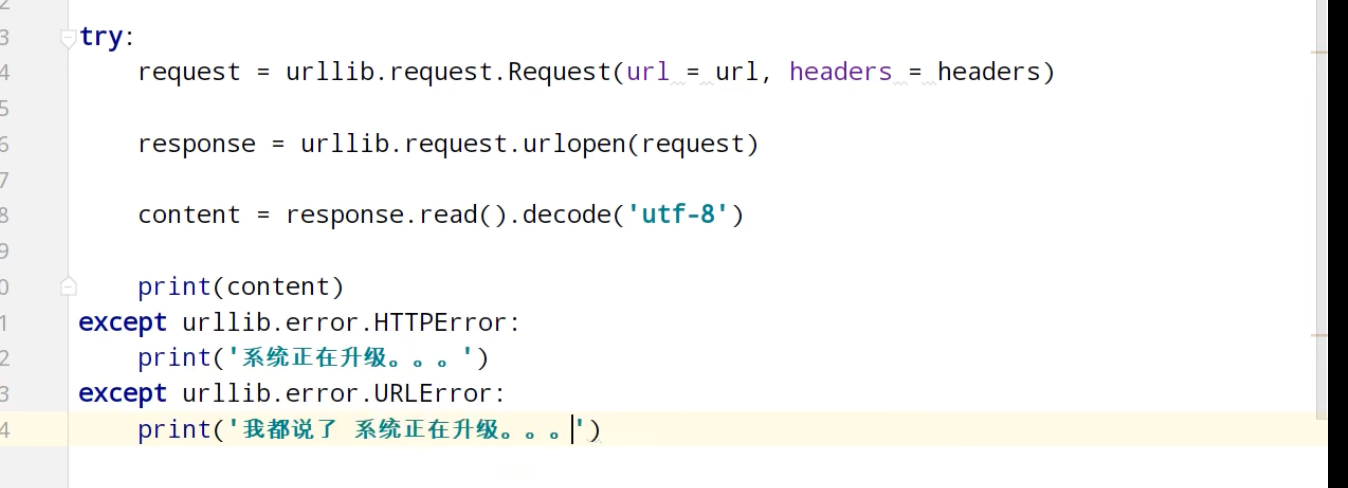
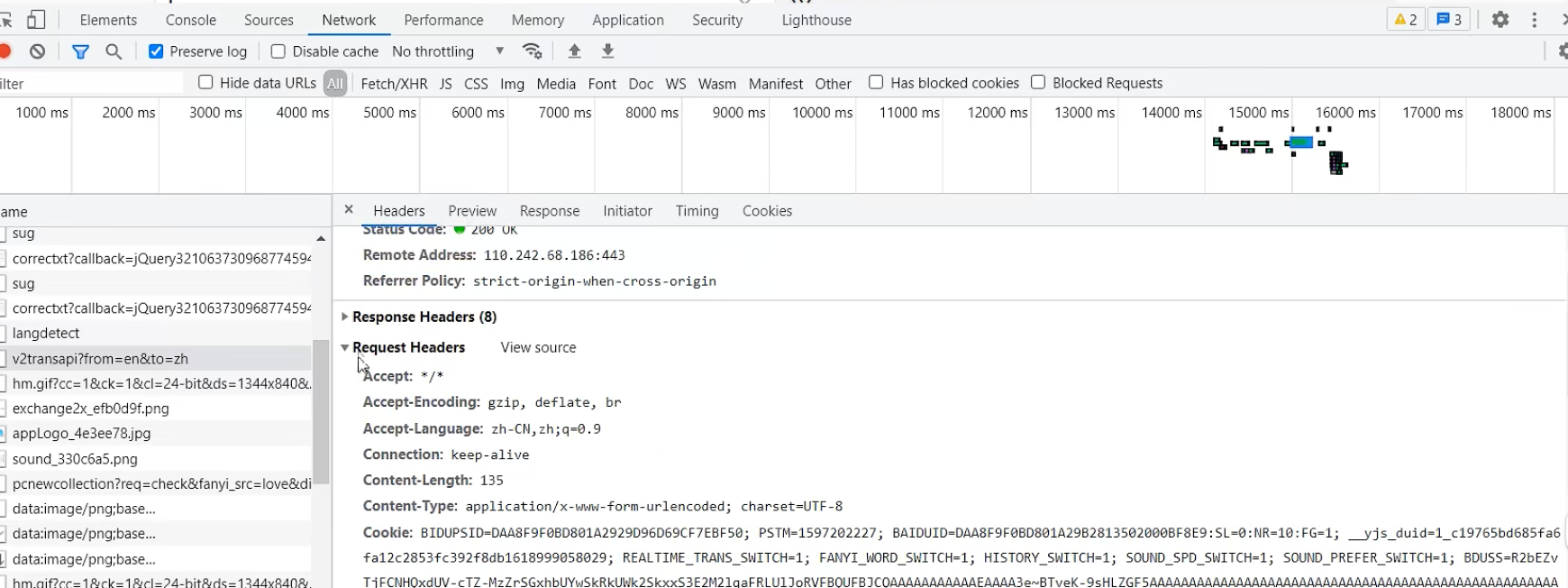
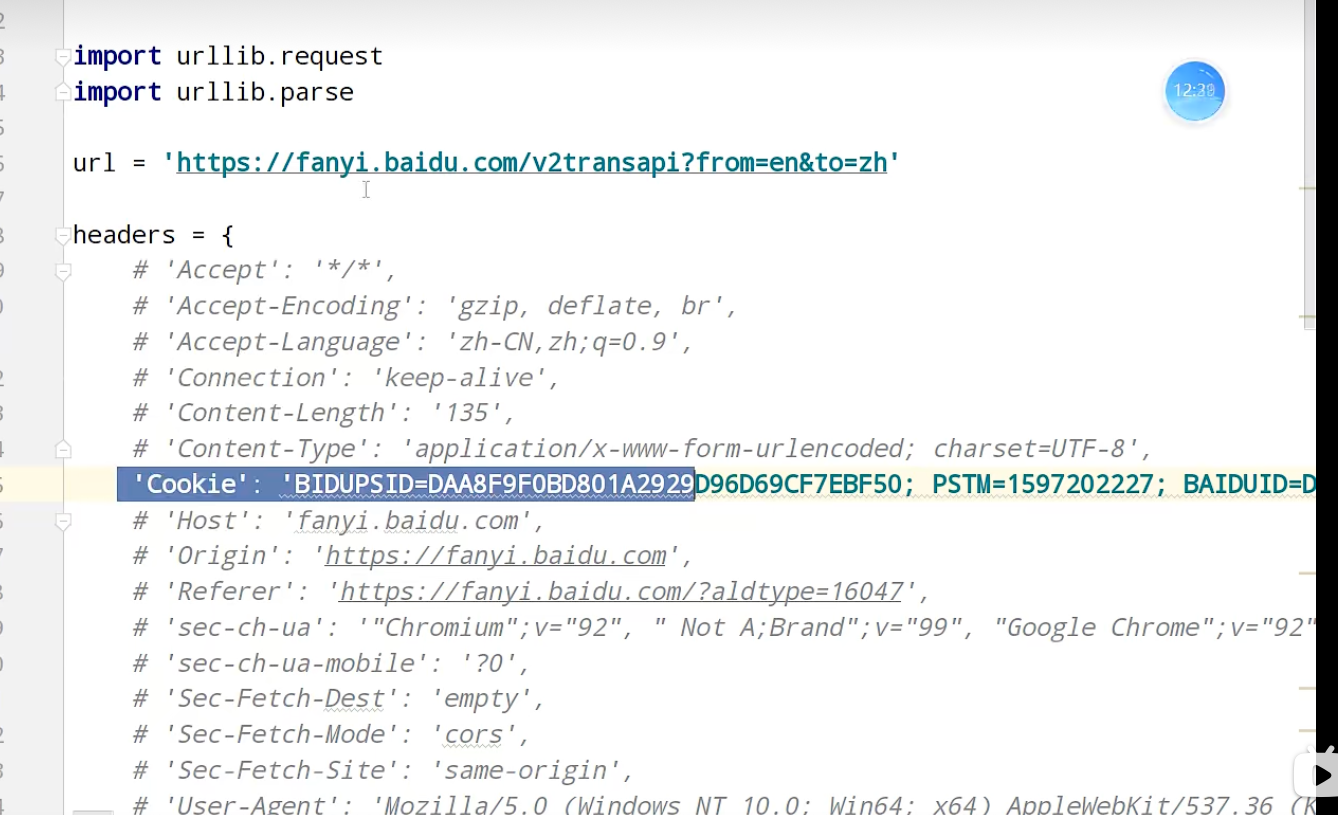
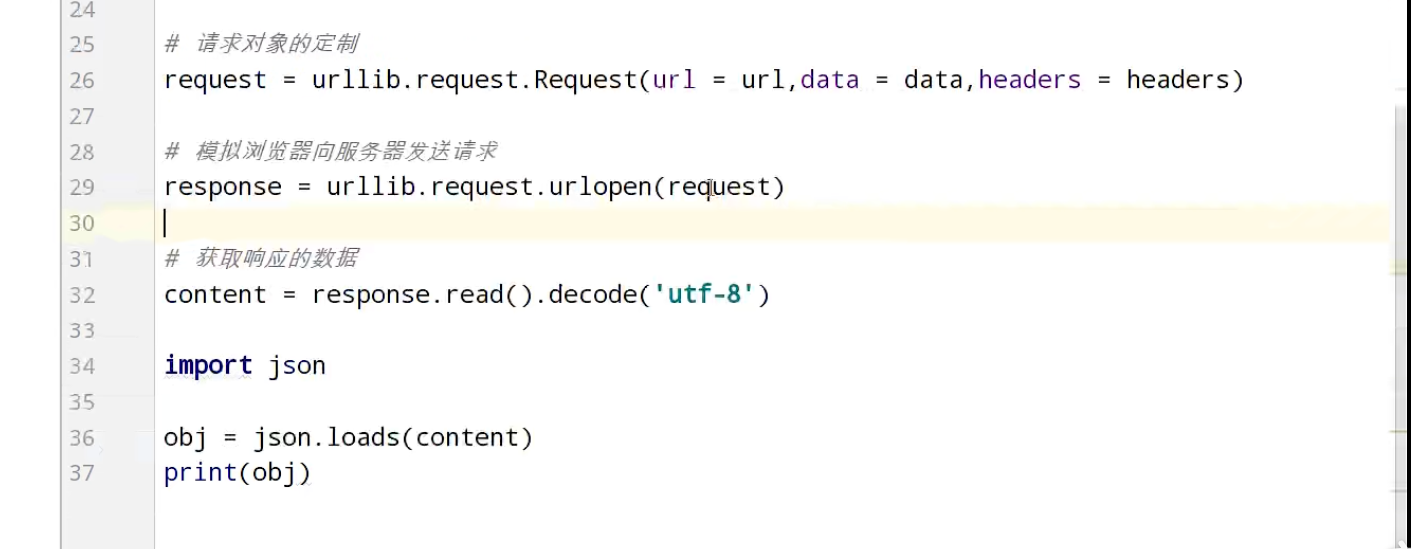
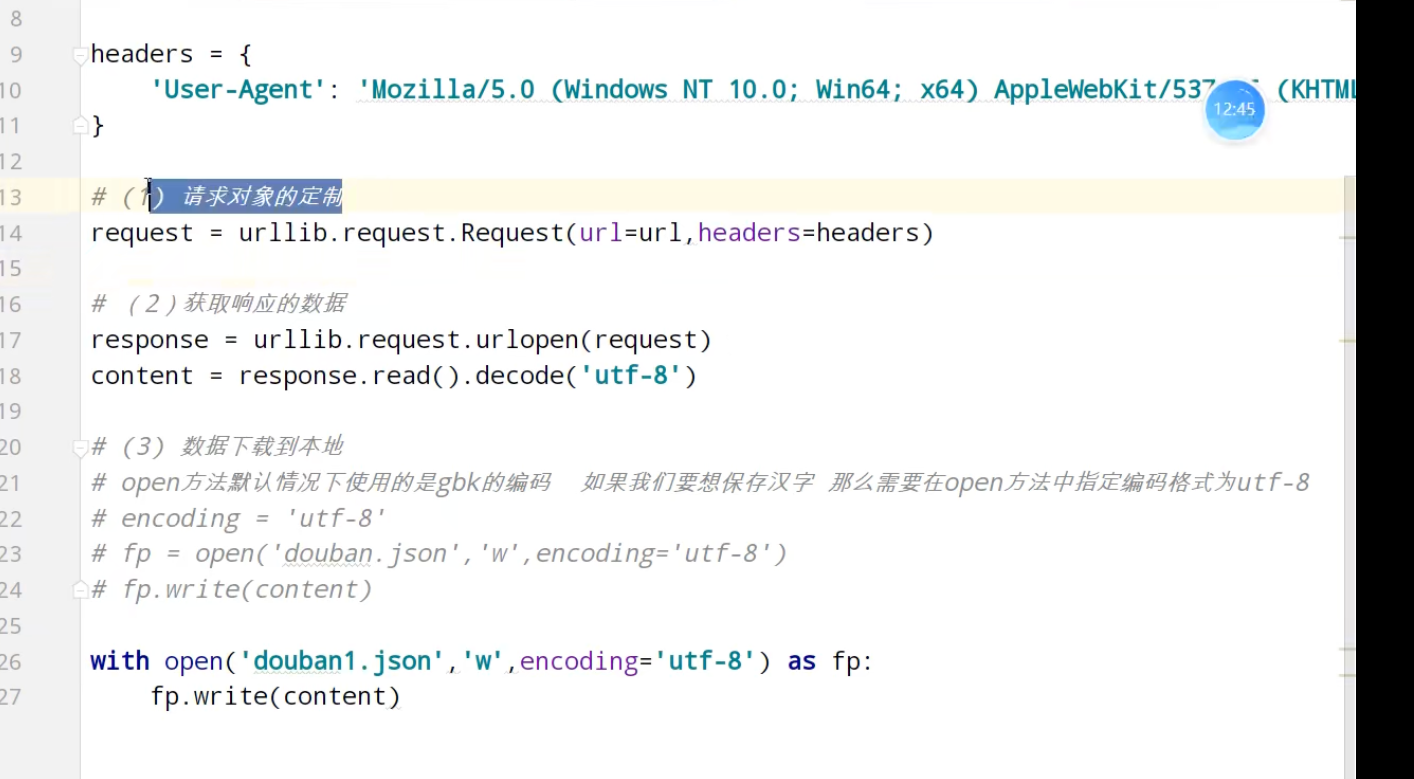
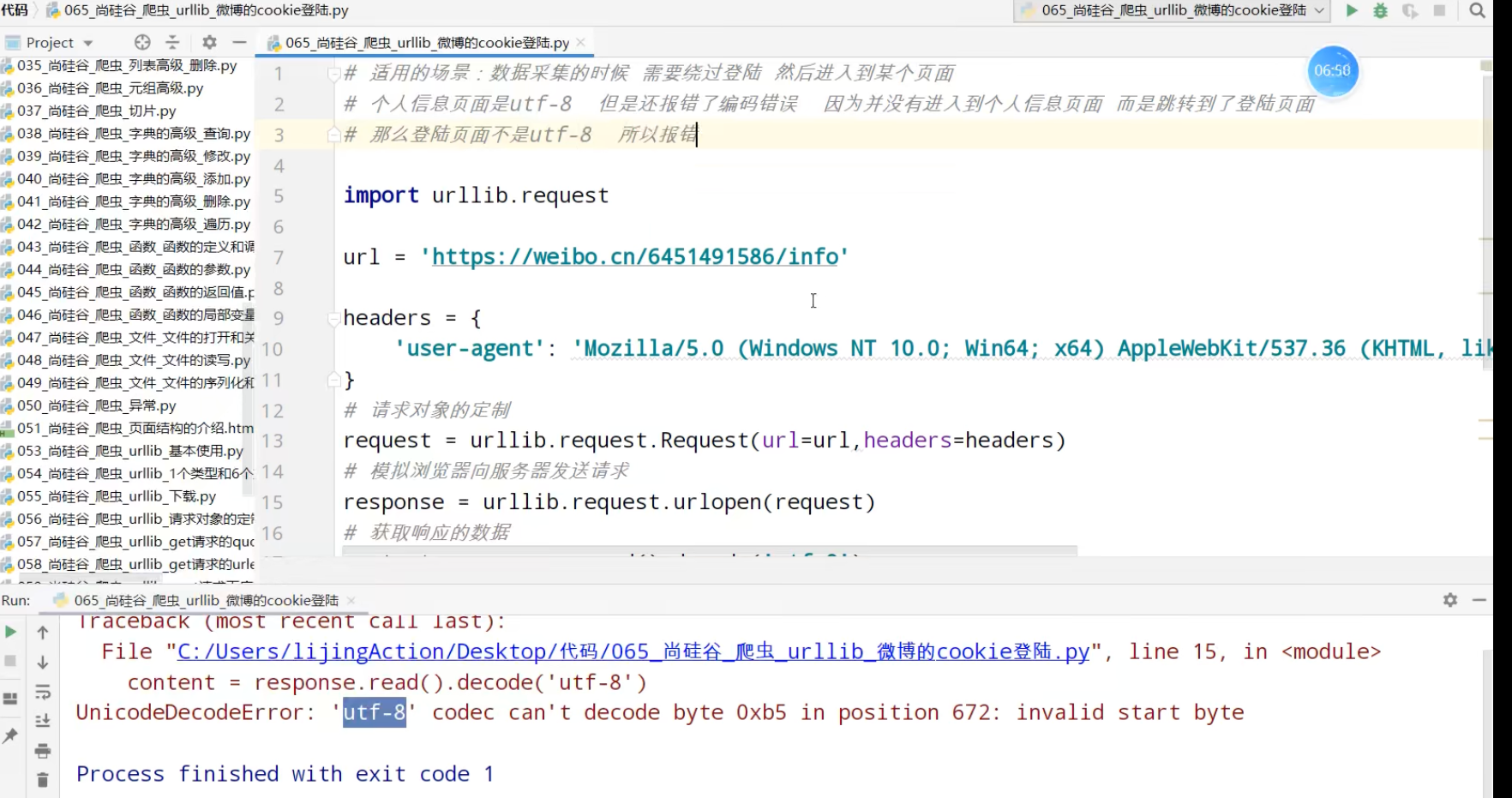
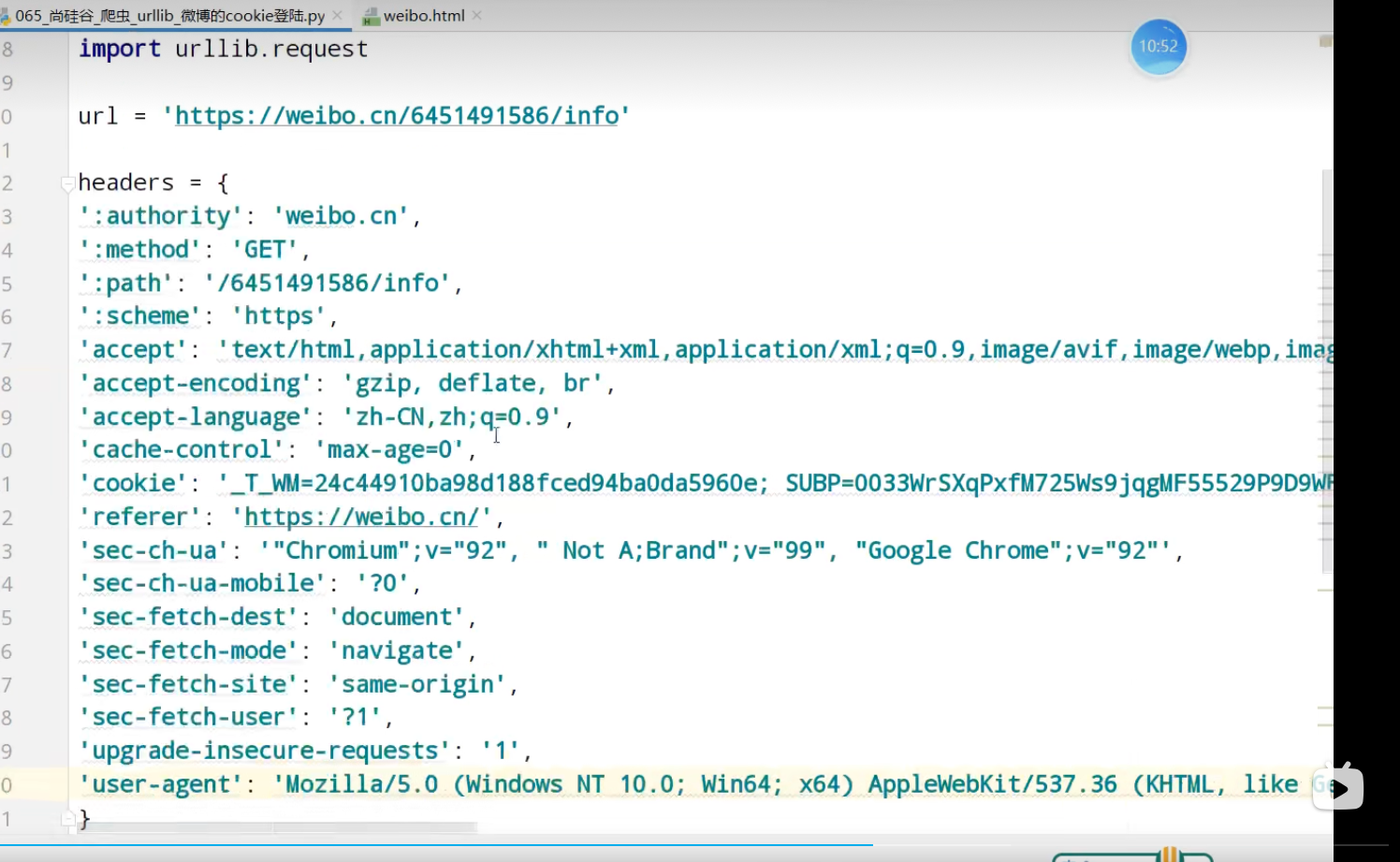
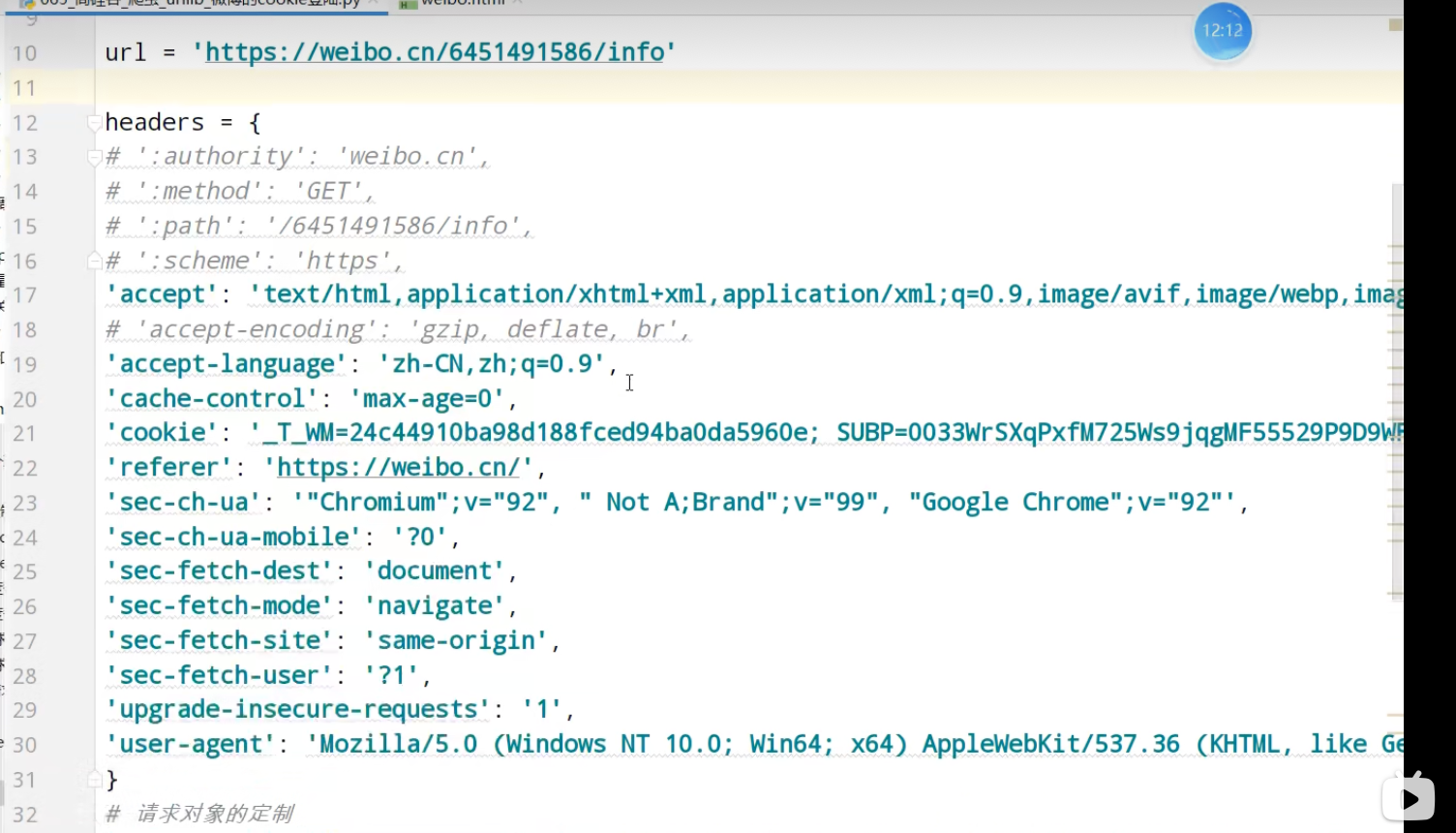
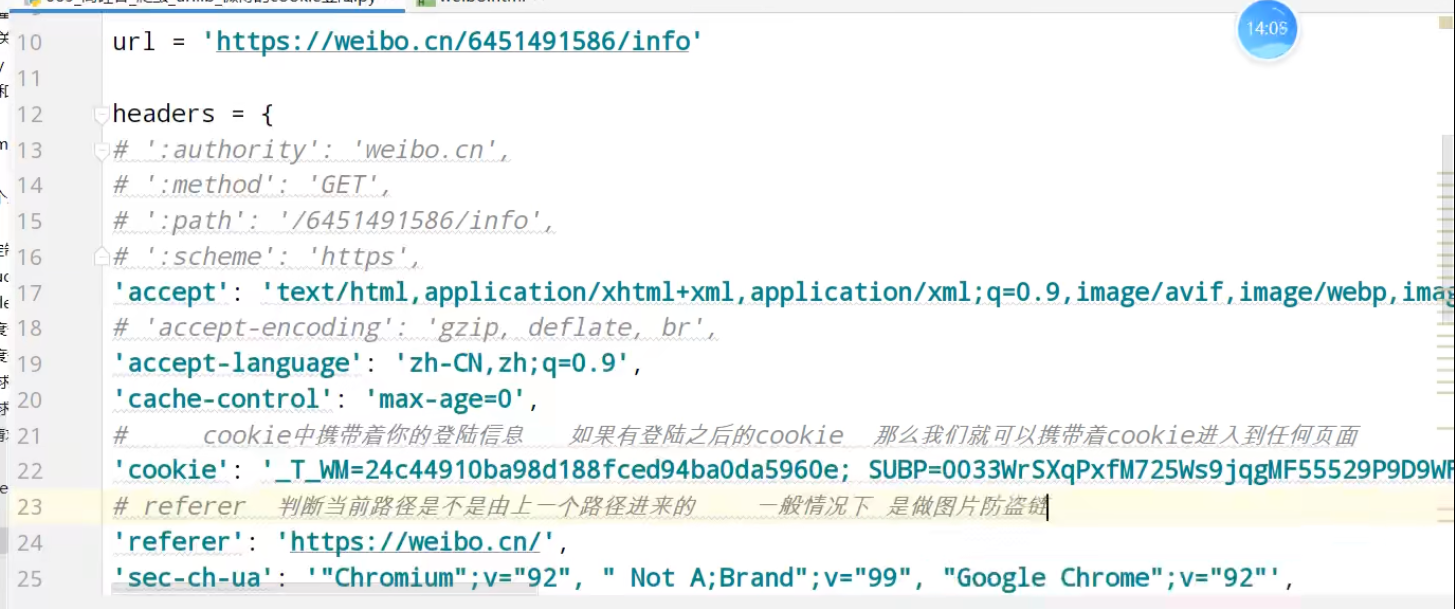
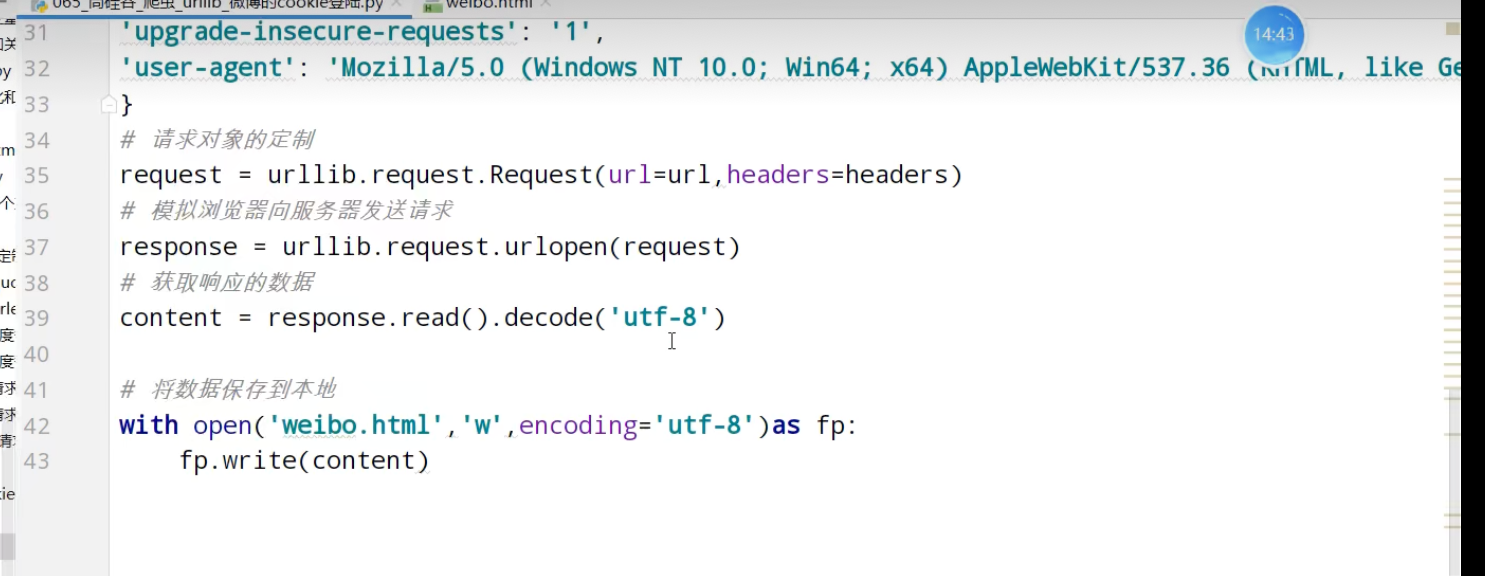
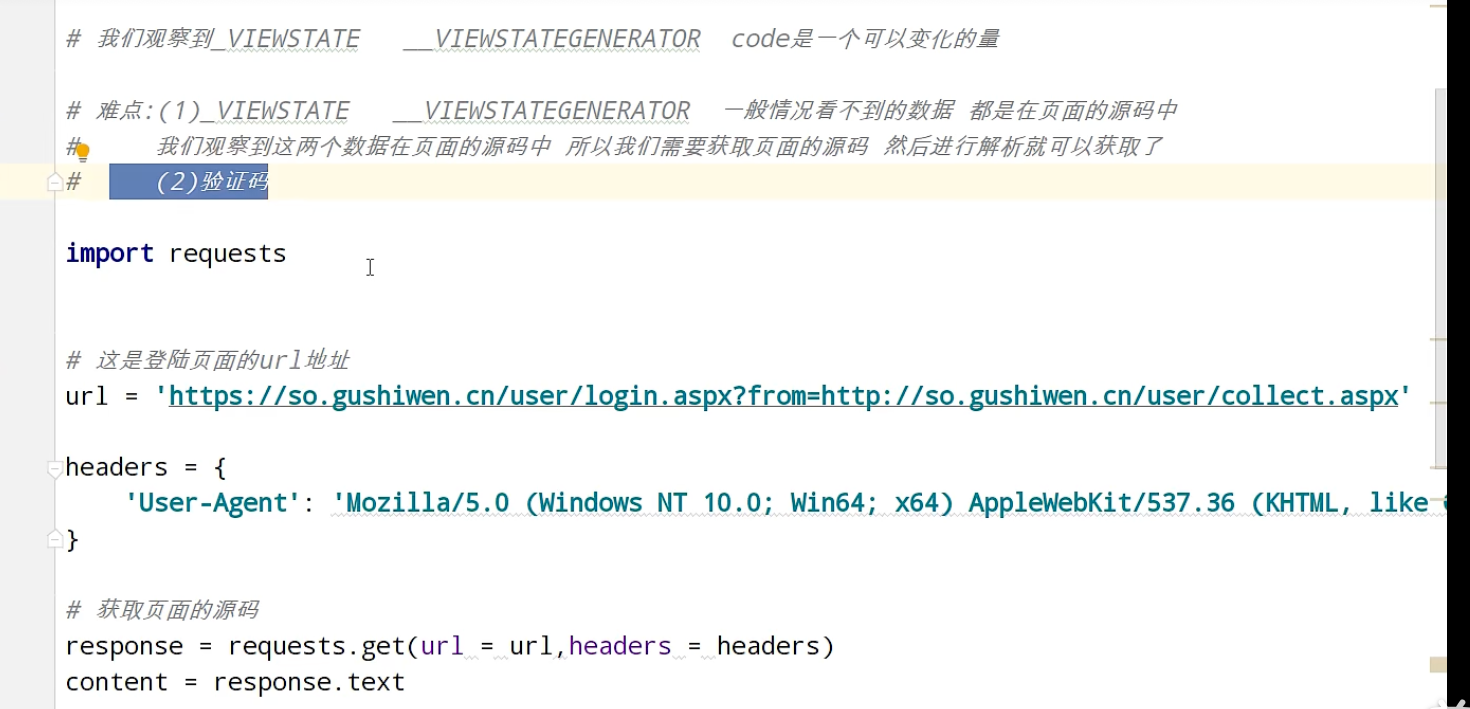
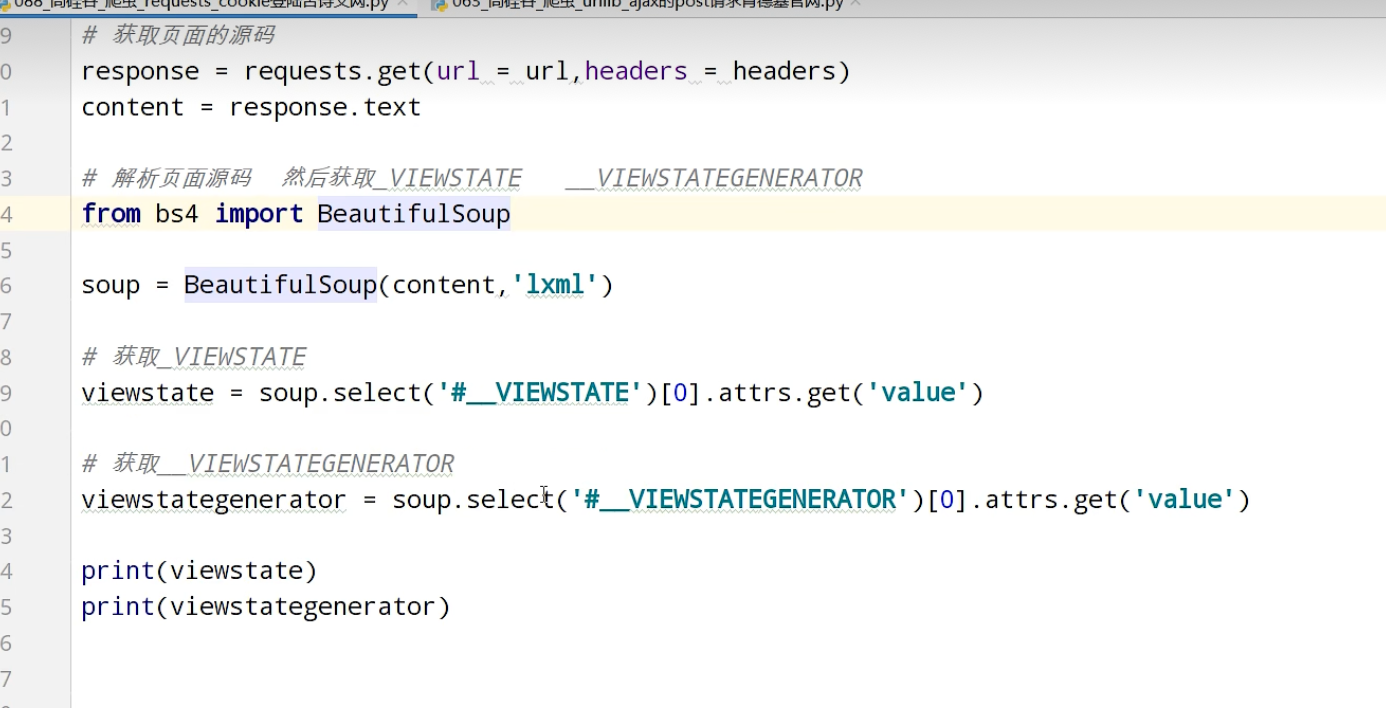
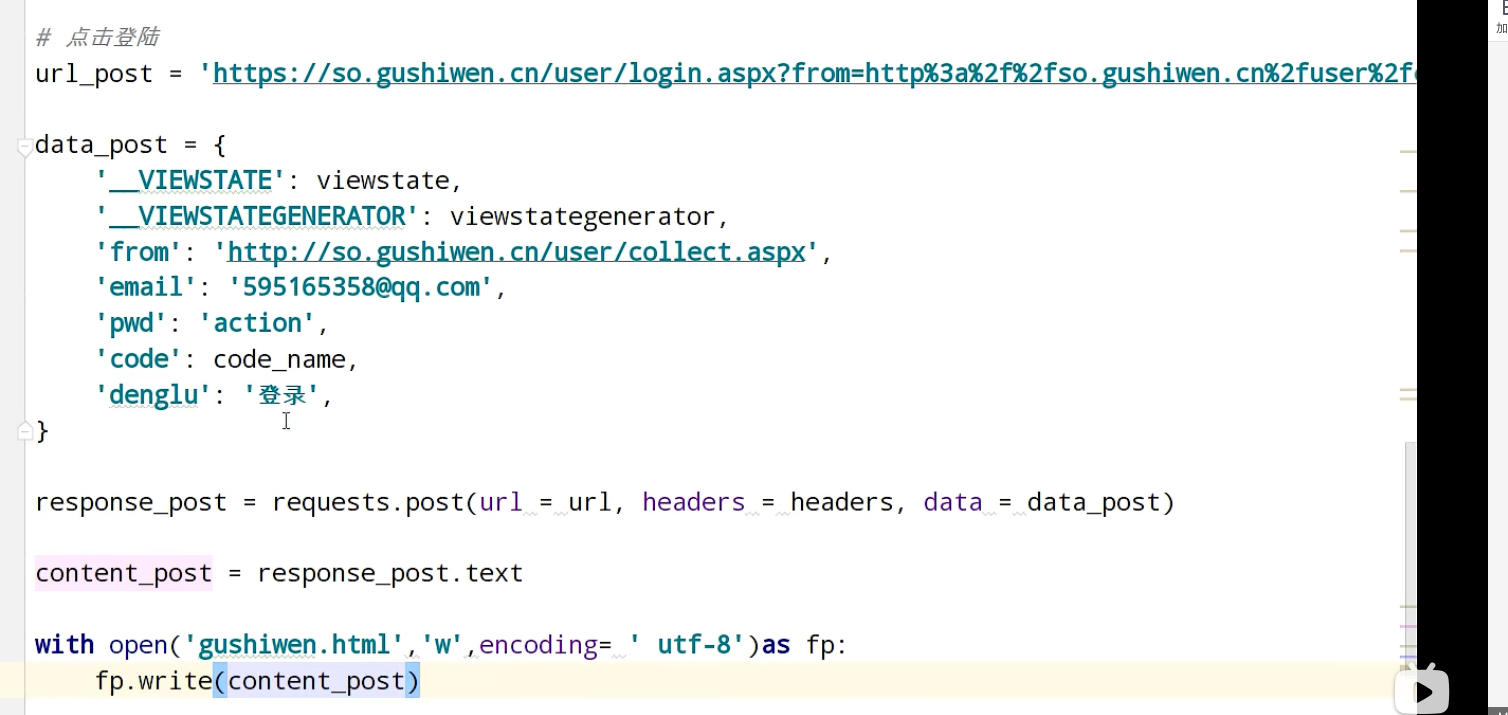
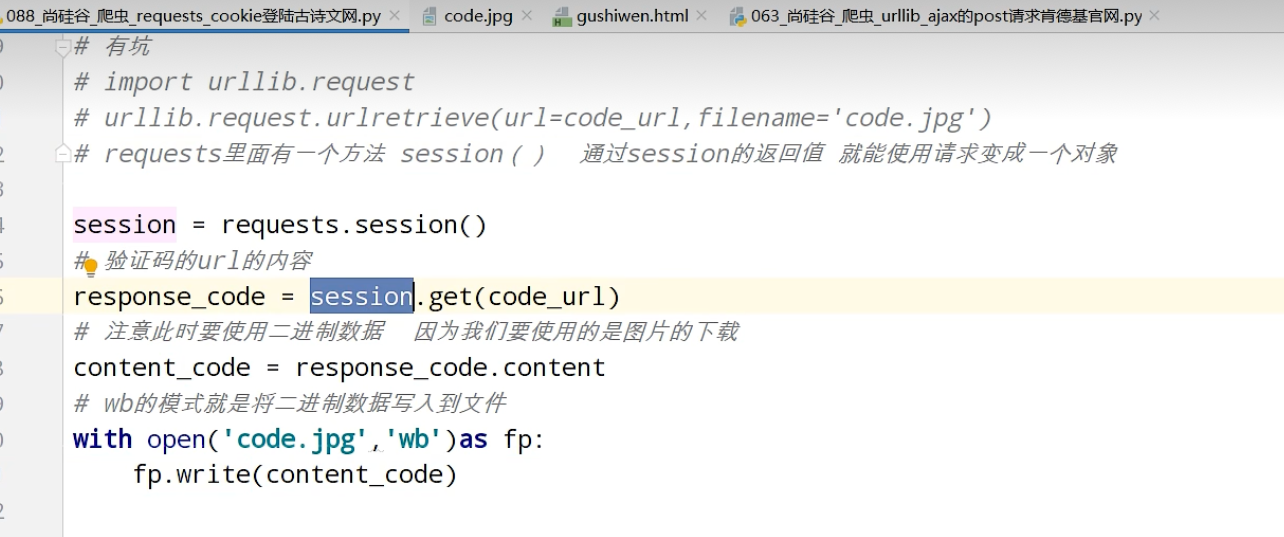
urllib_cookie登录
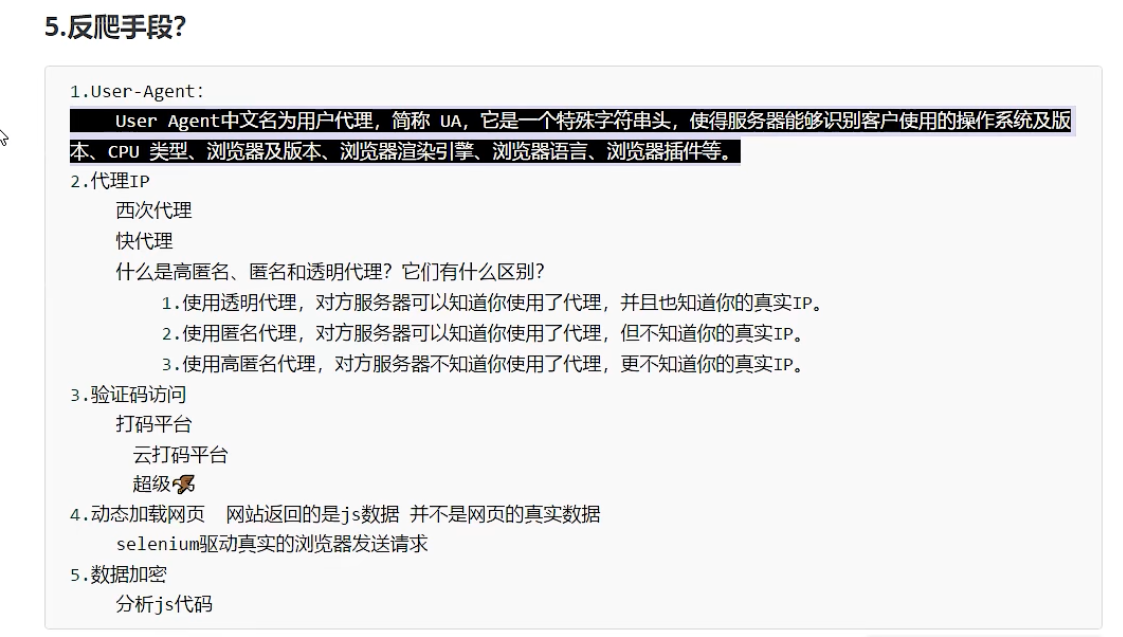
数据采集的时候需要绕过登录,进入某个页面

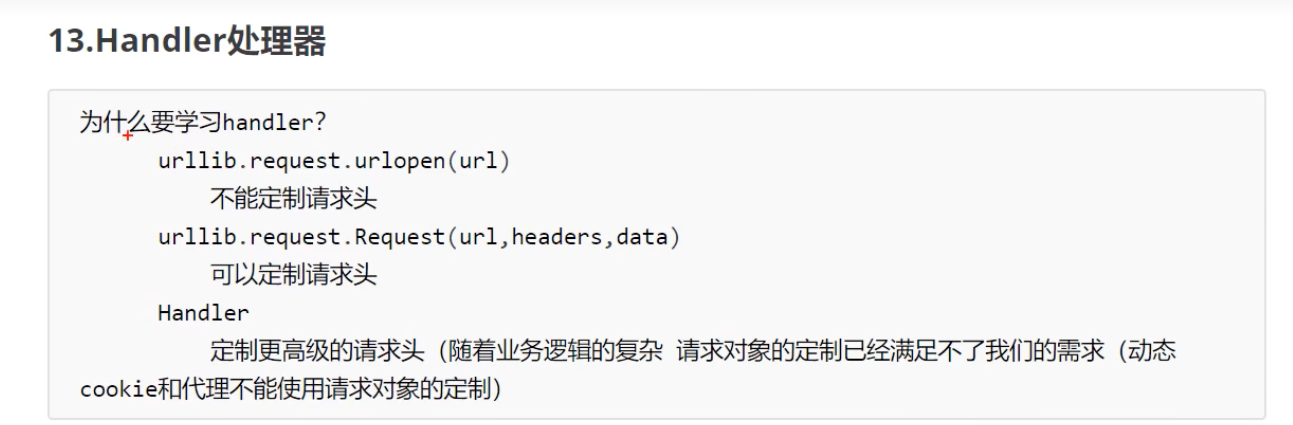
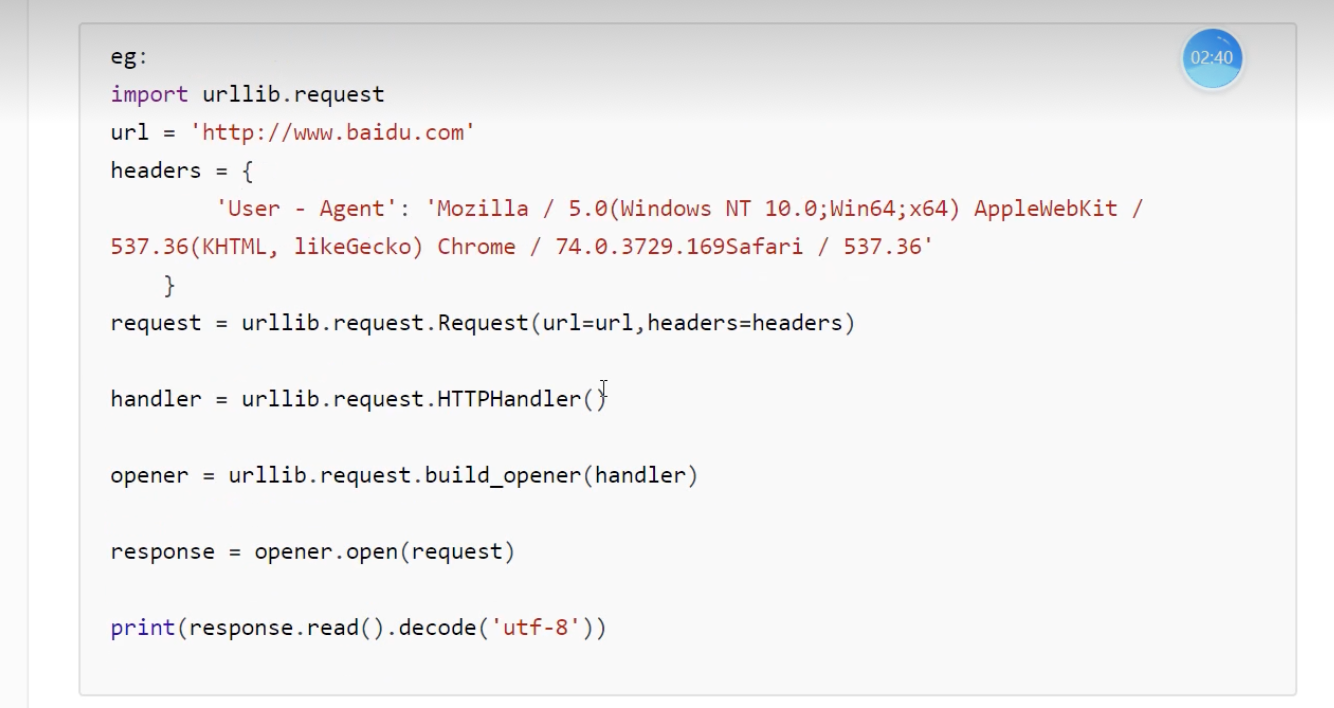
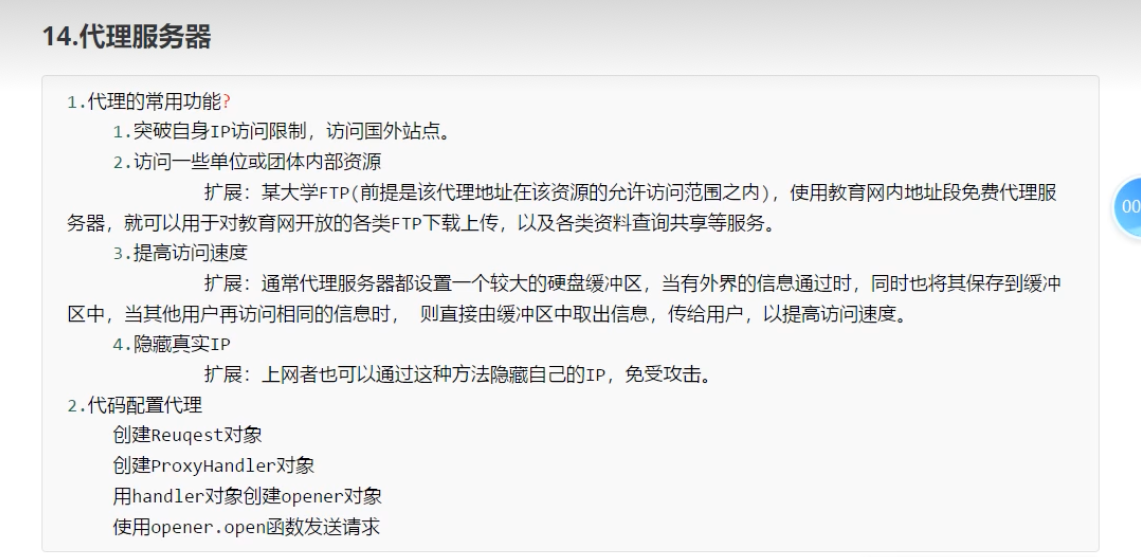
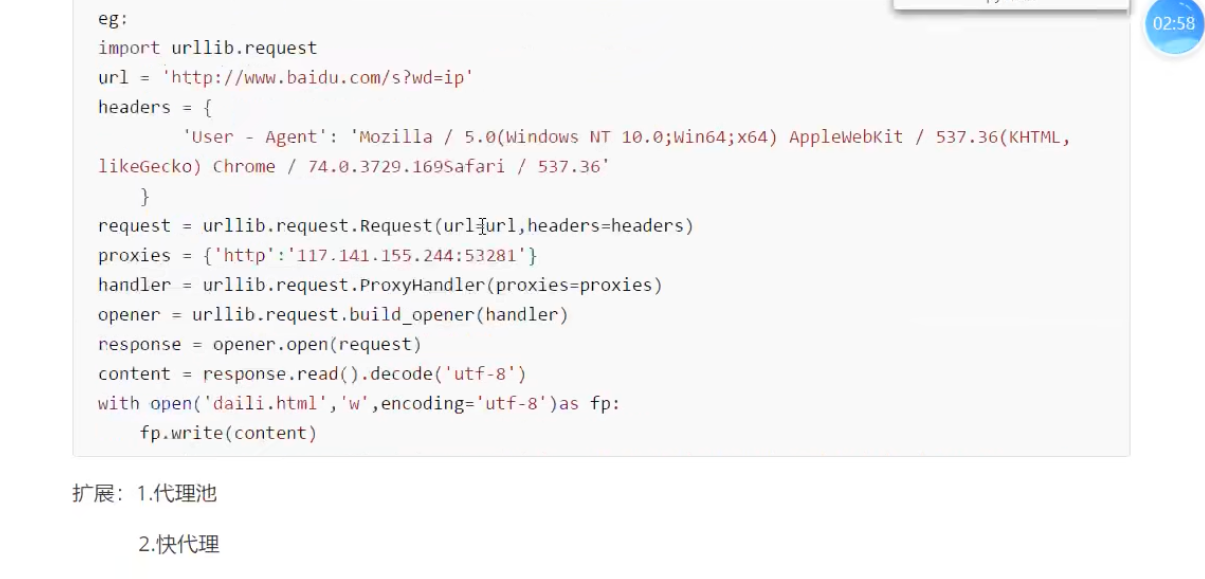
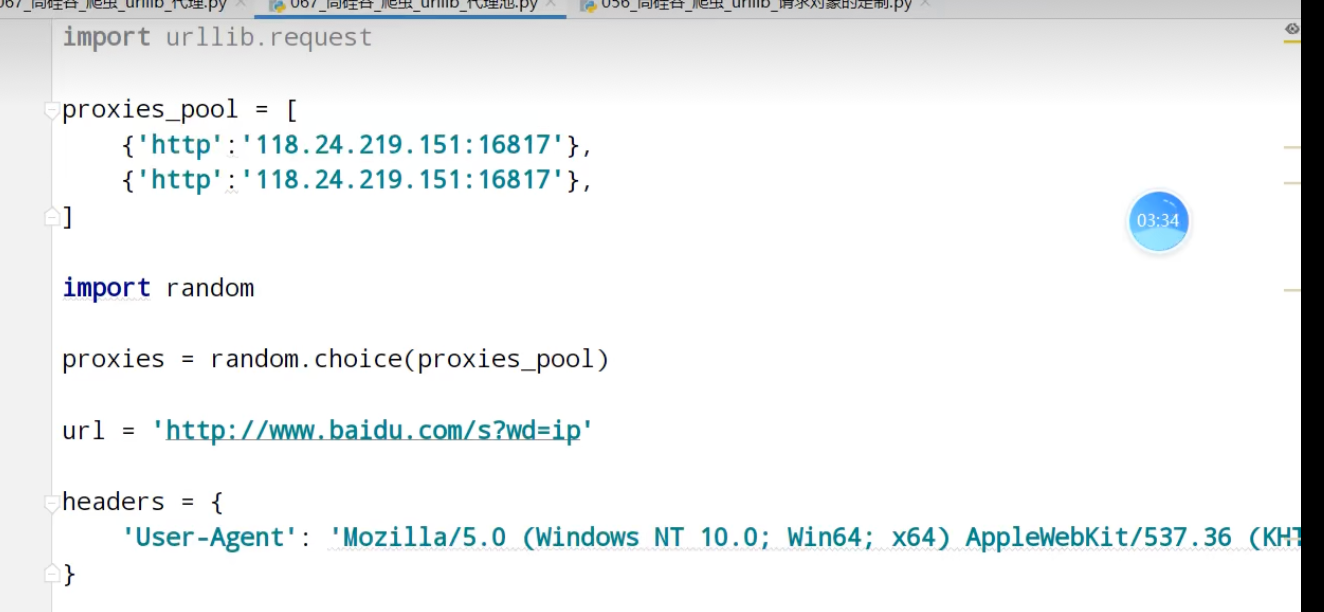
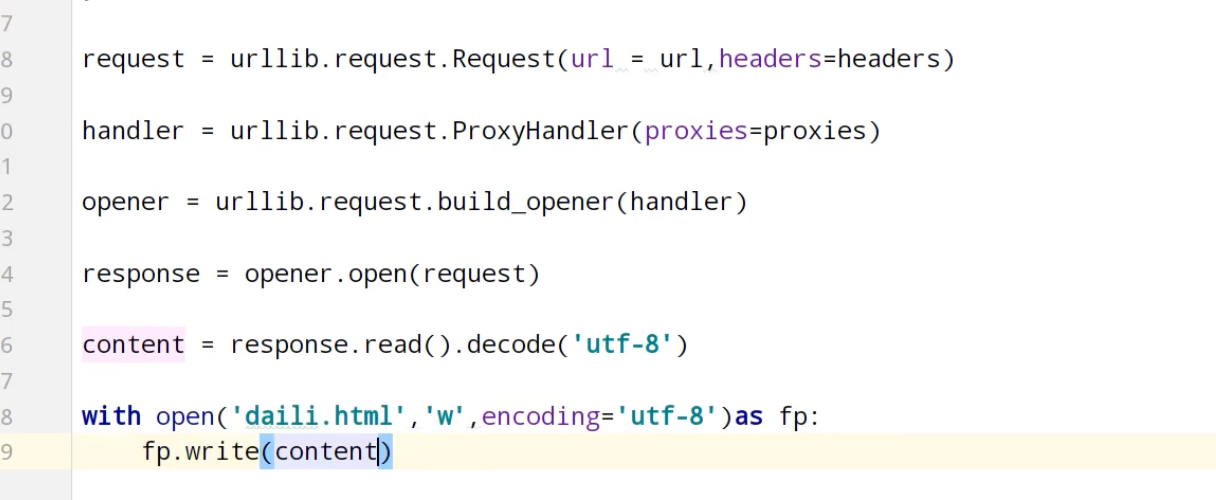
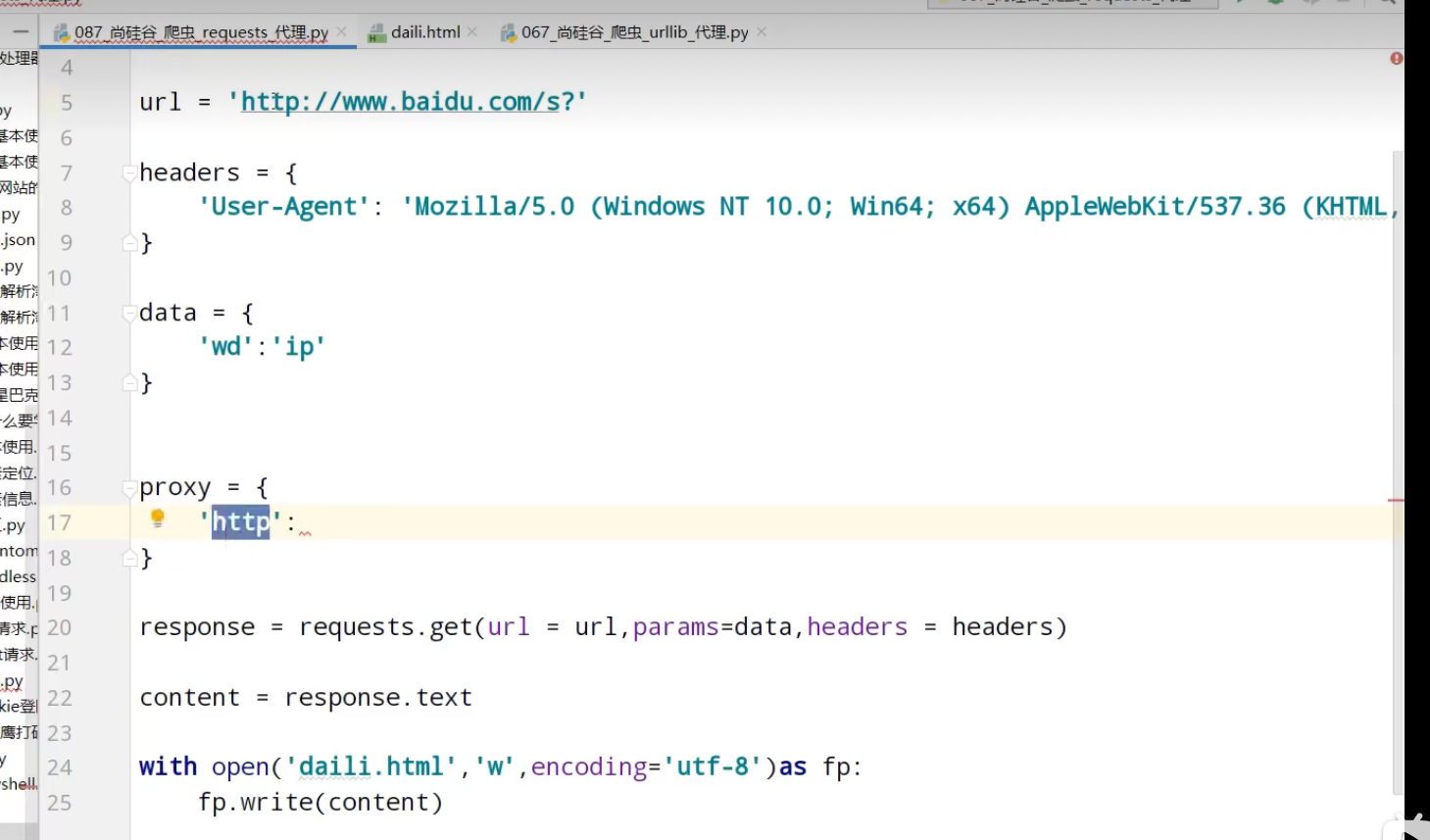
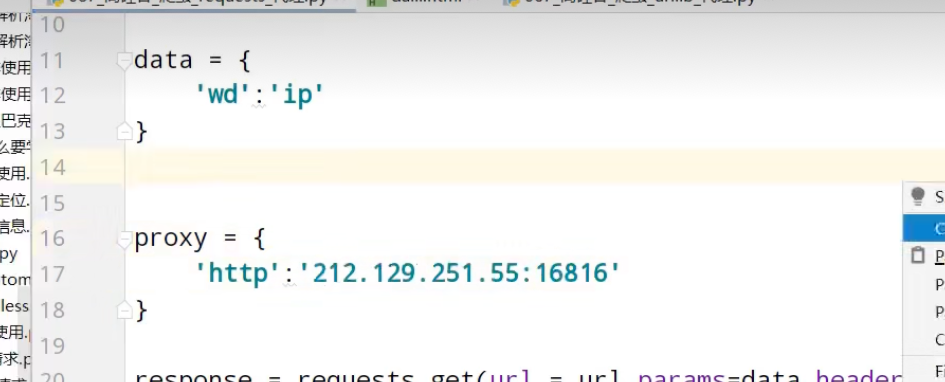
代理池
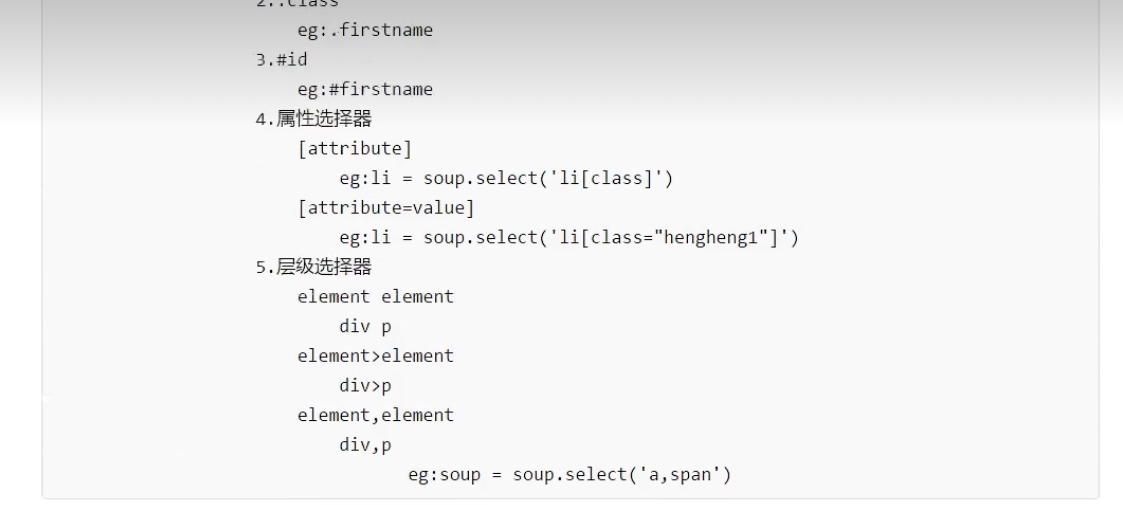
解析
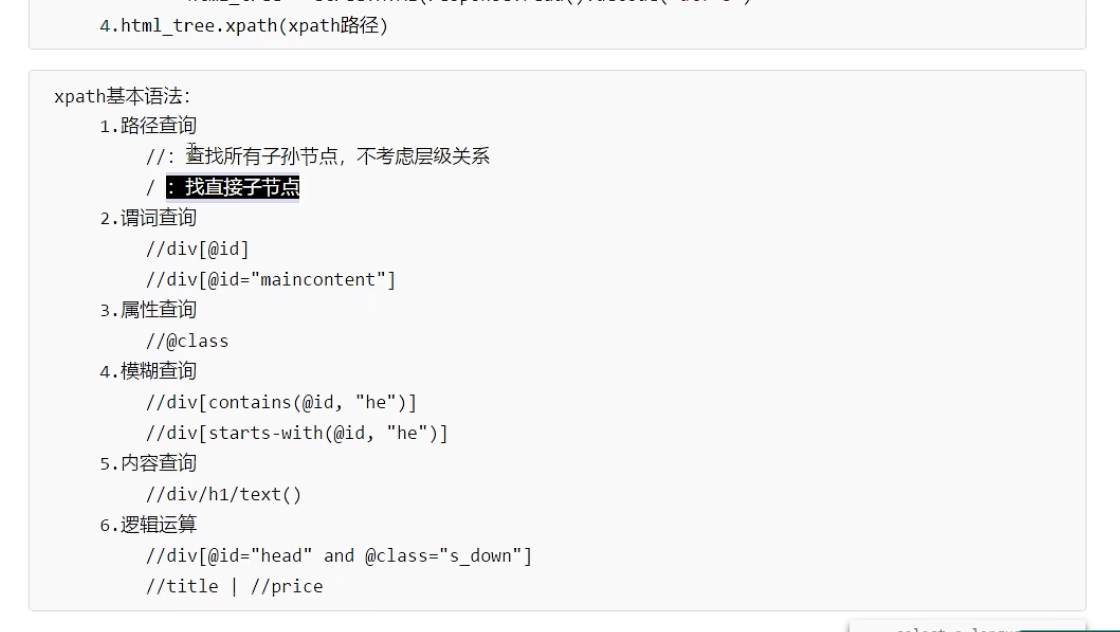
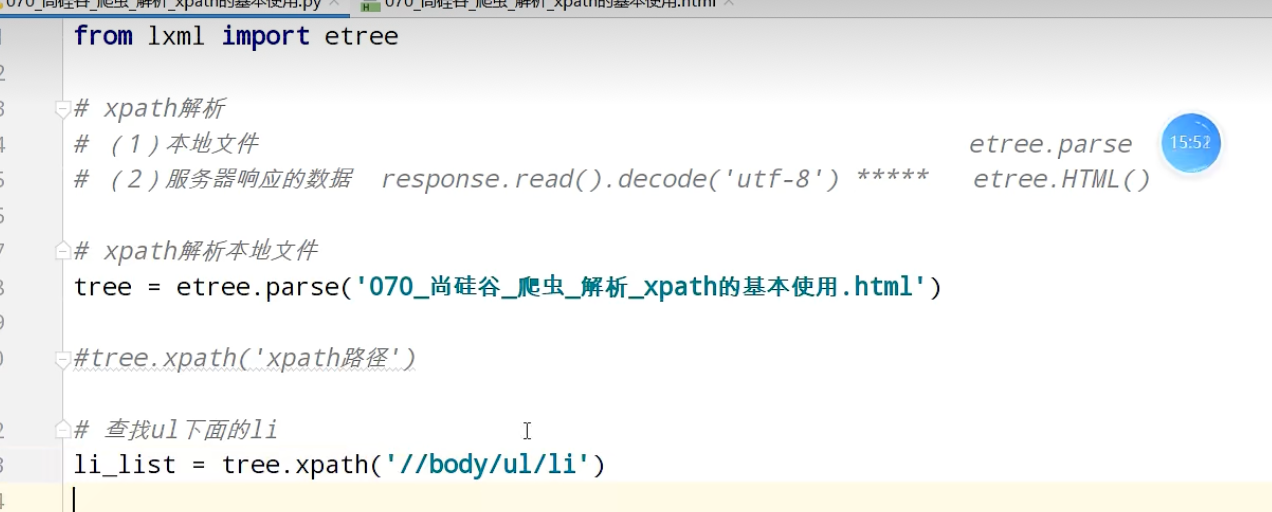
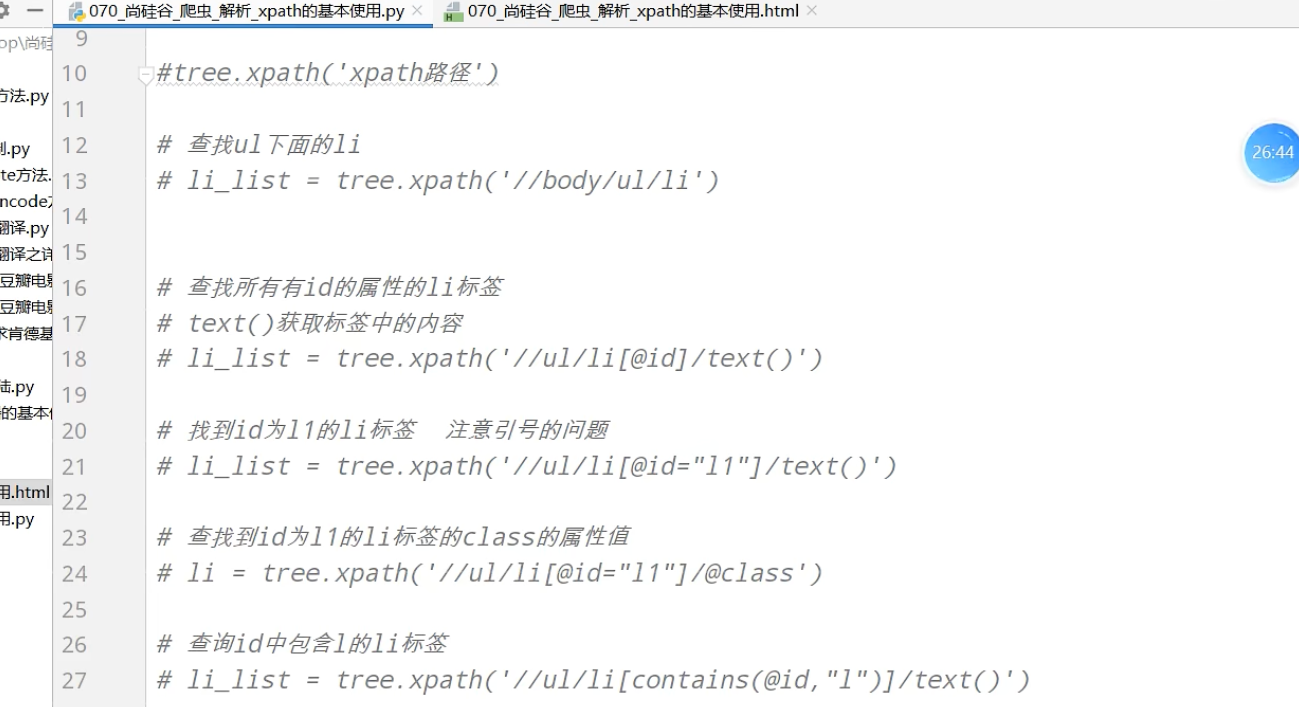
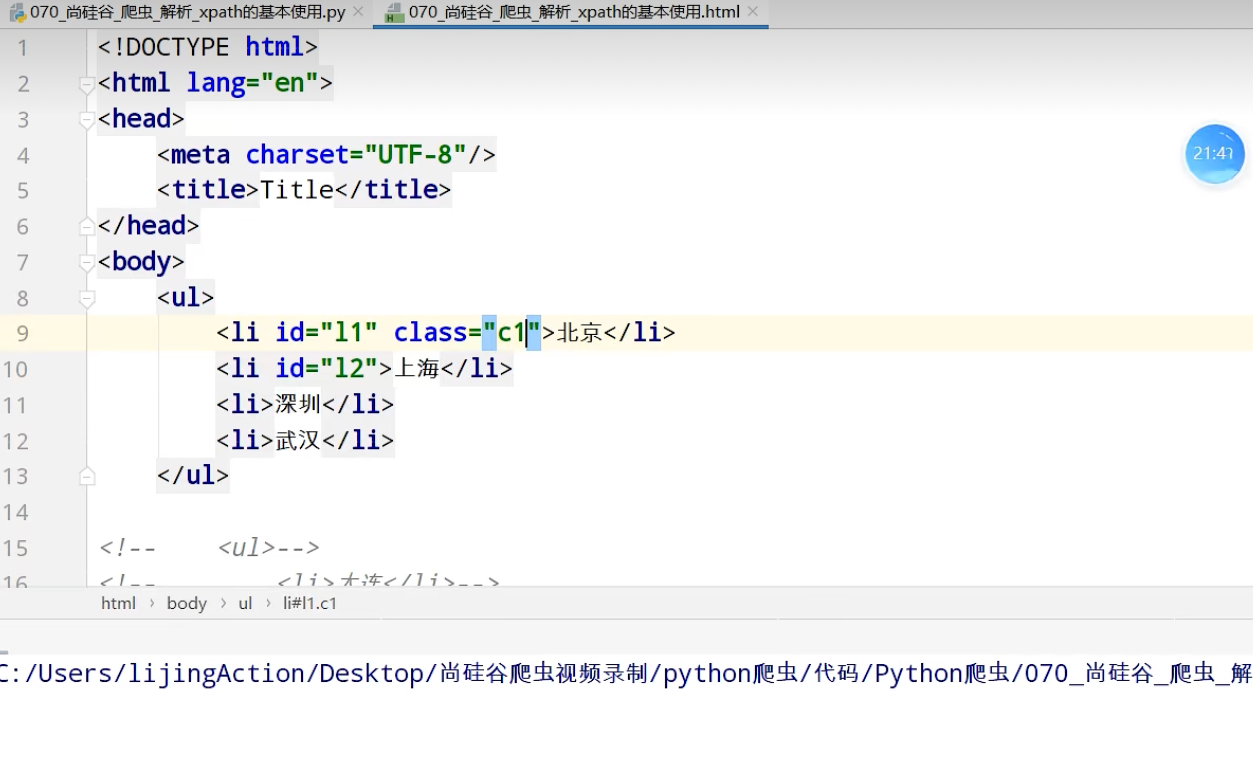
xpath

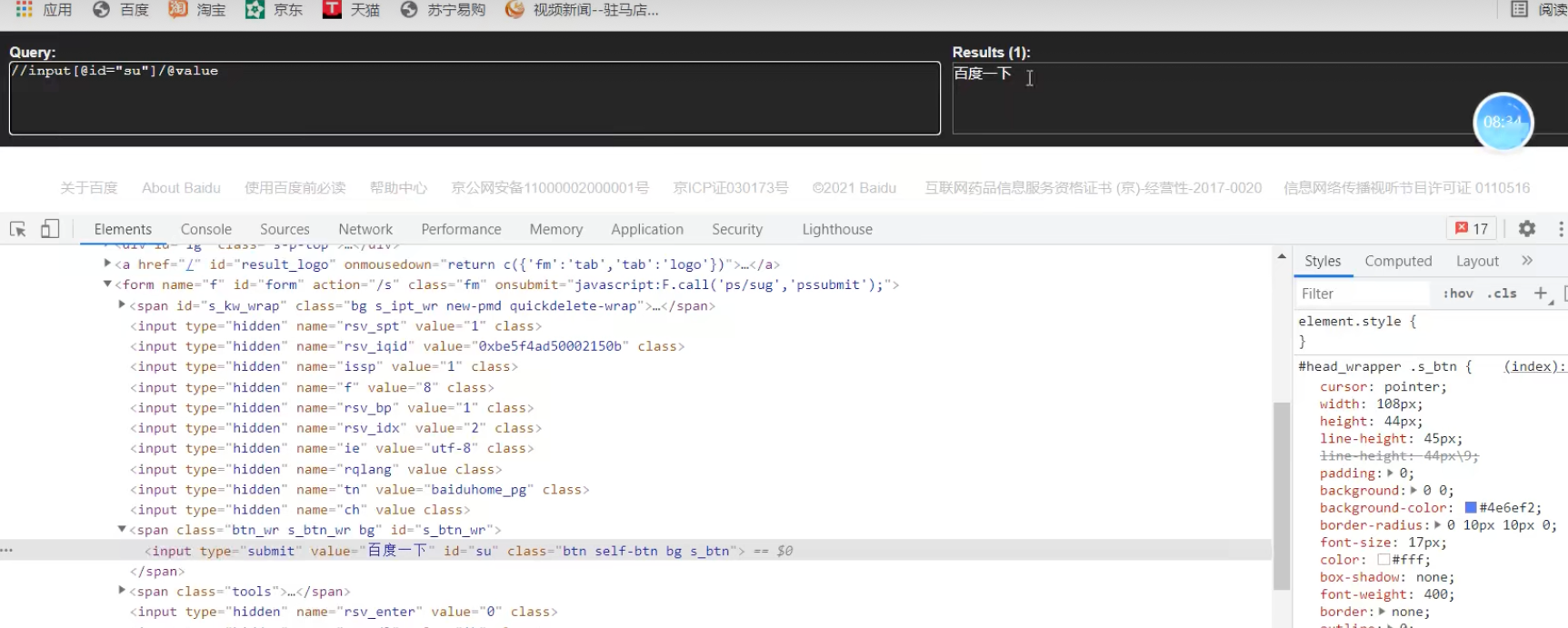
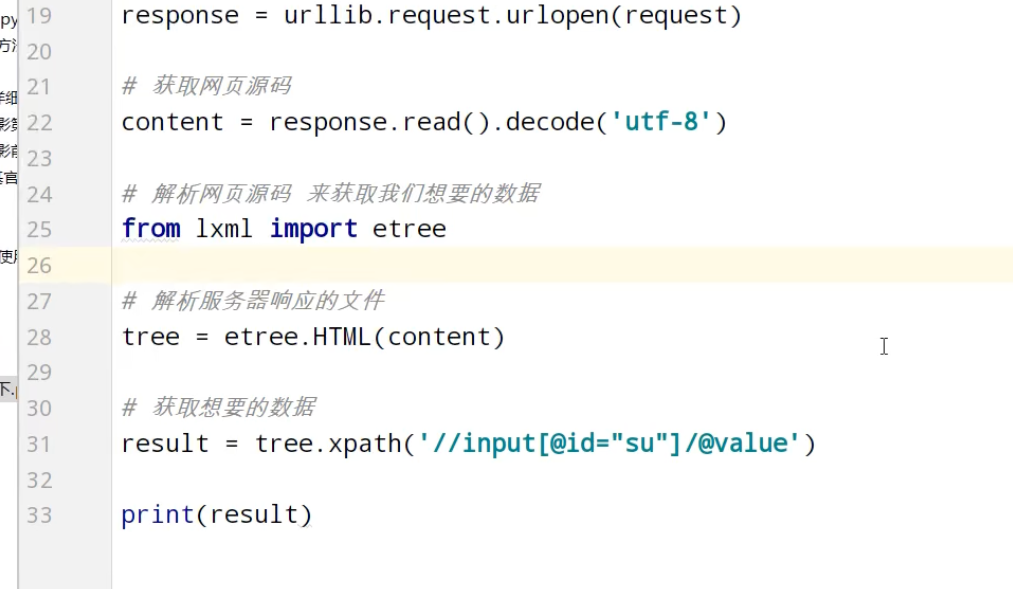
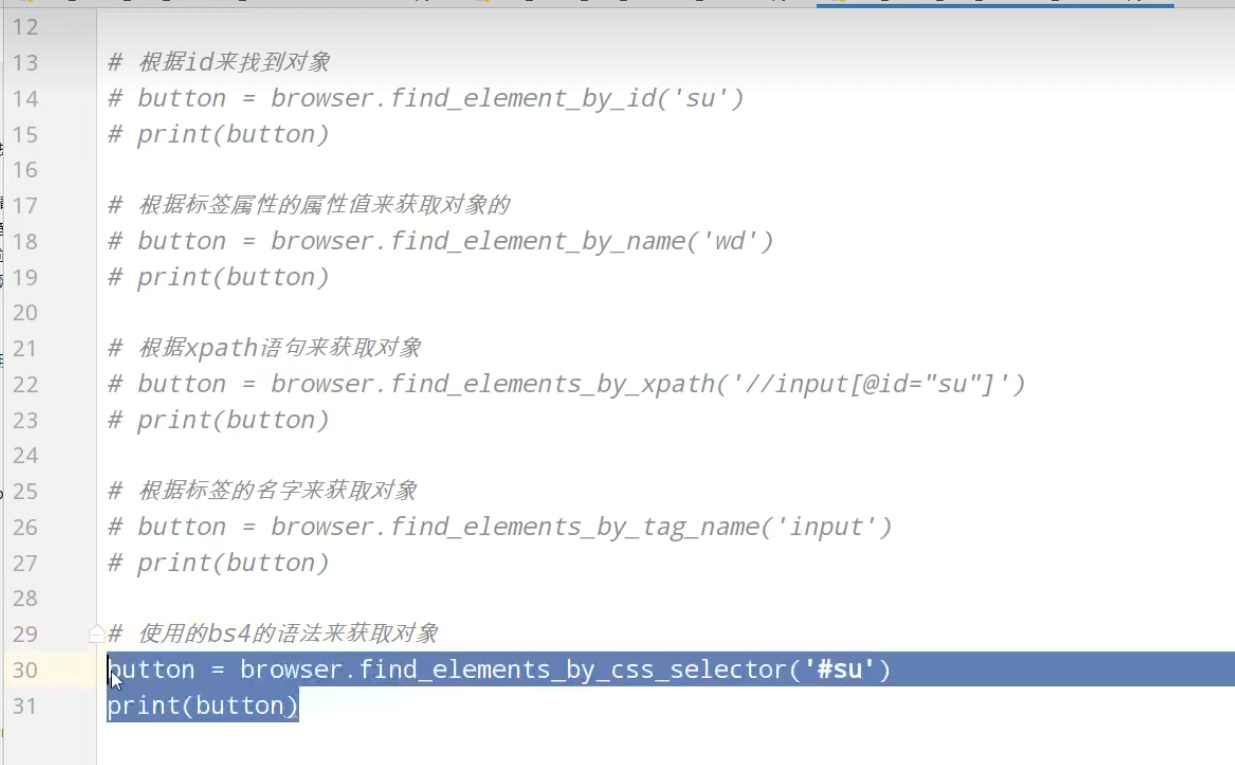
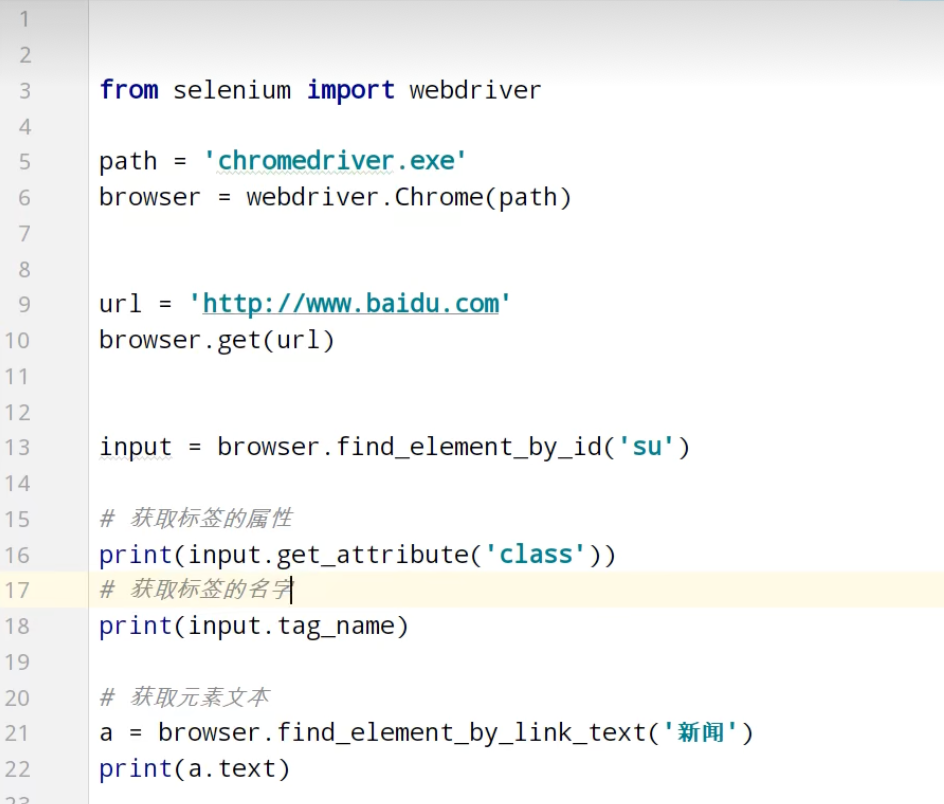
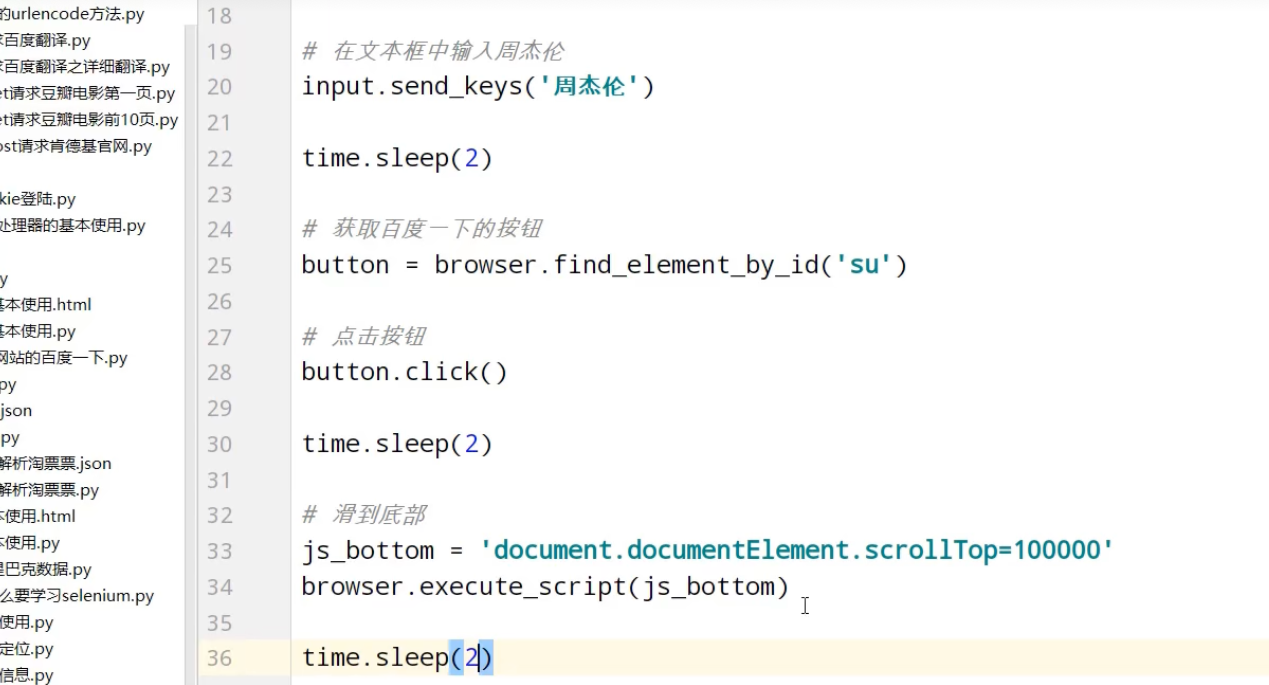
获取百度网页百度一下

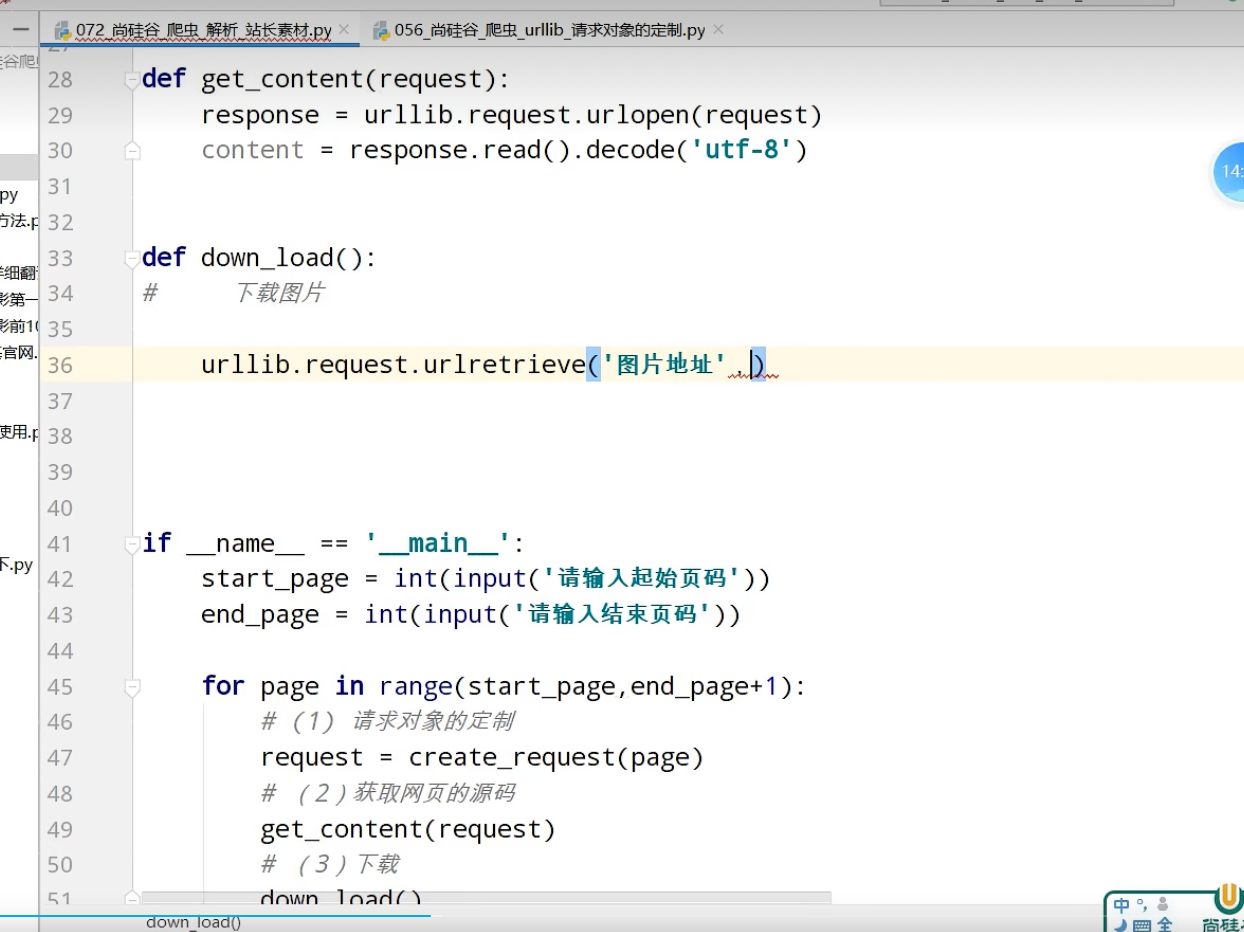
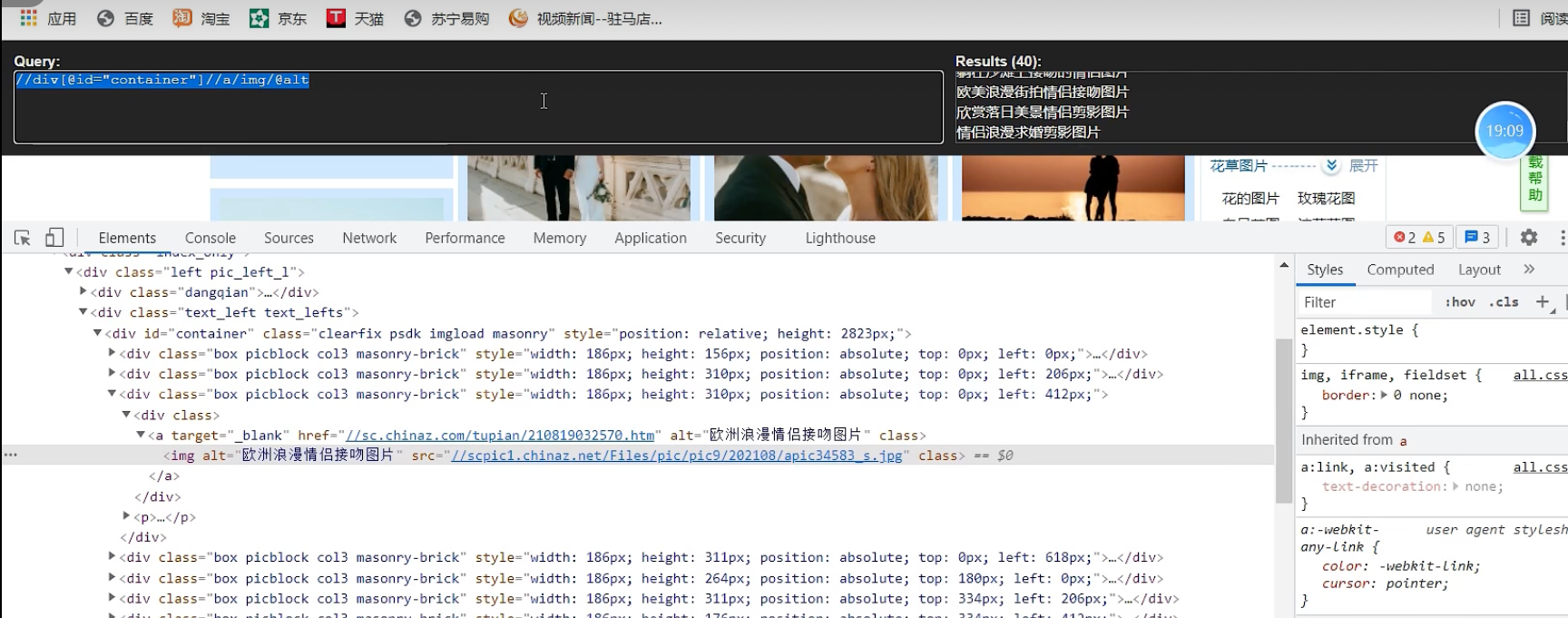
站长素材

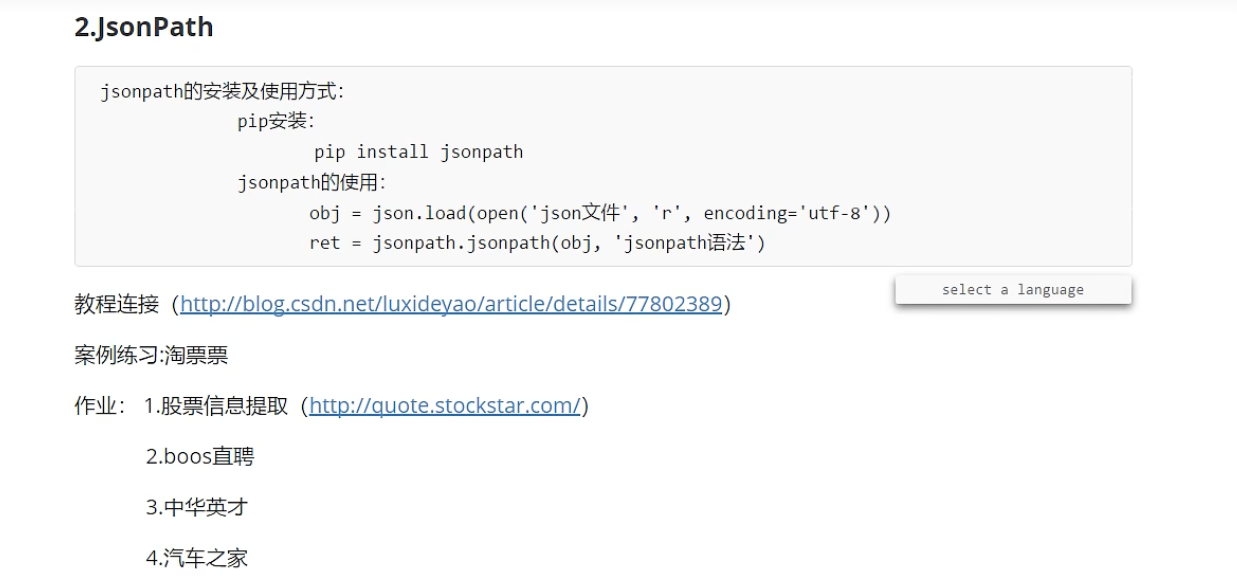
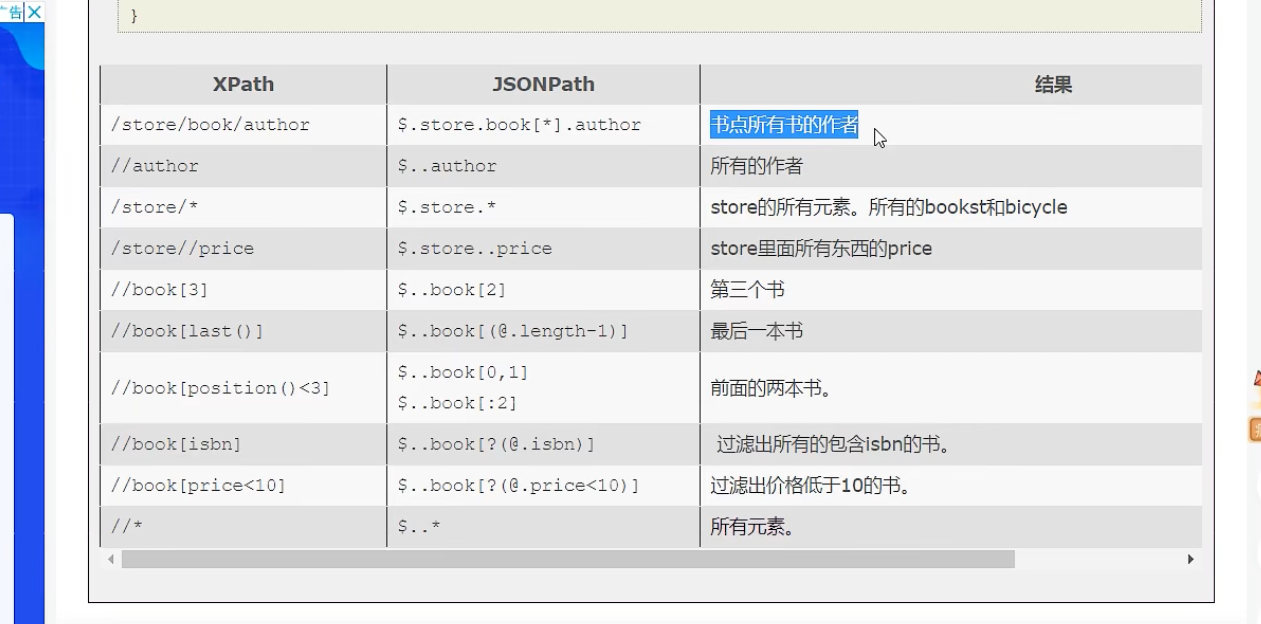
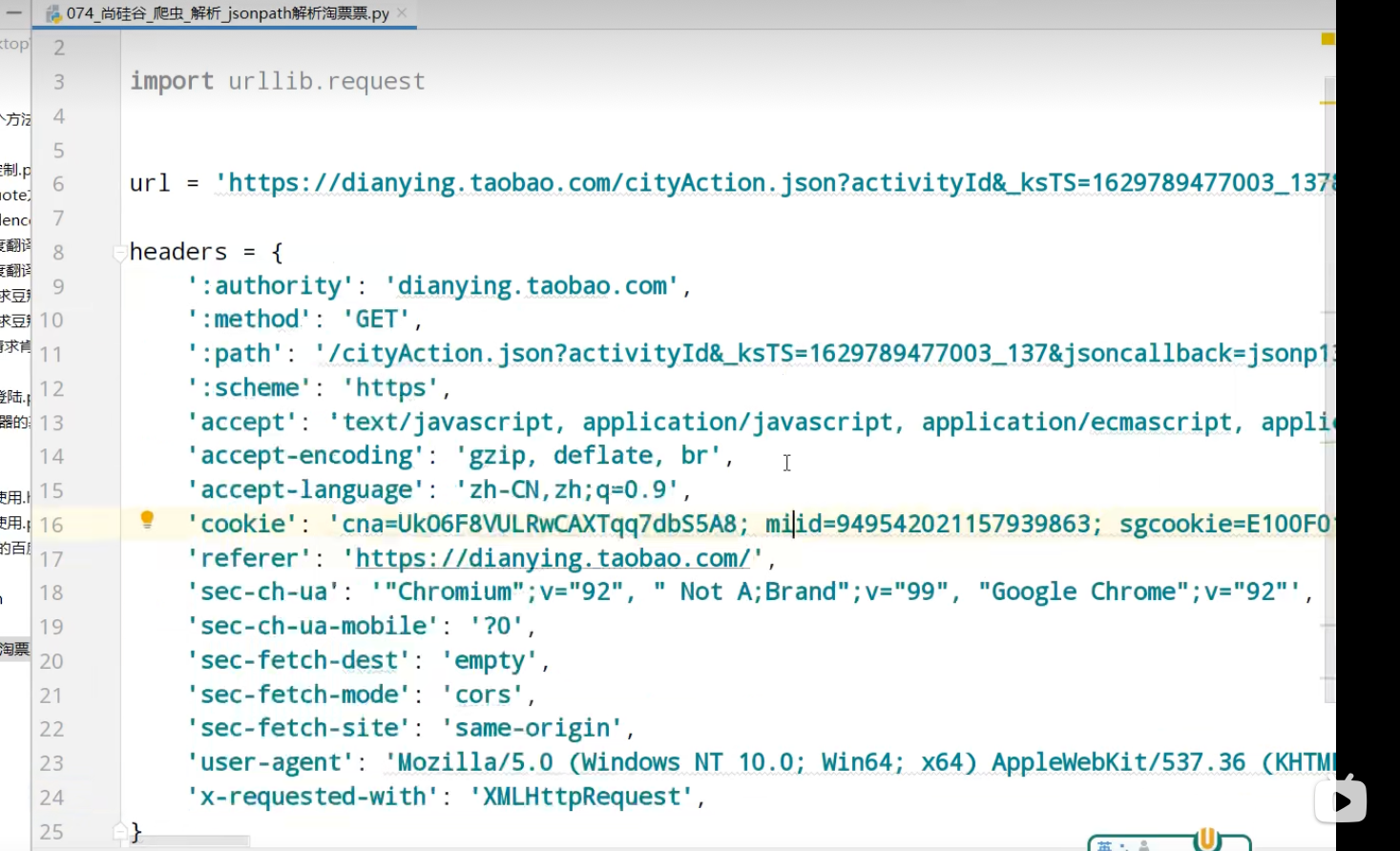
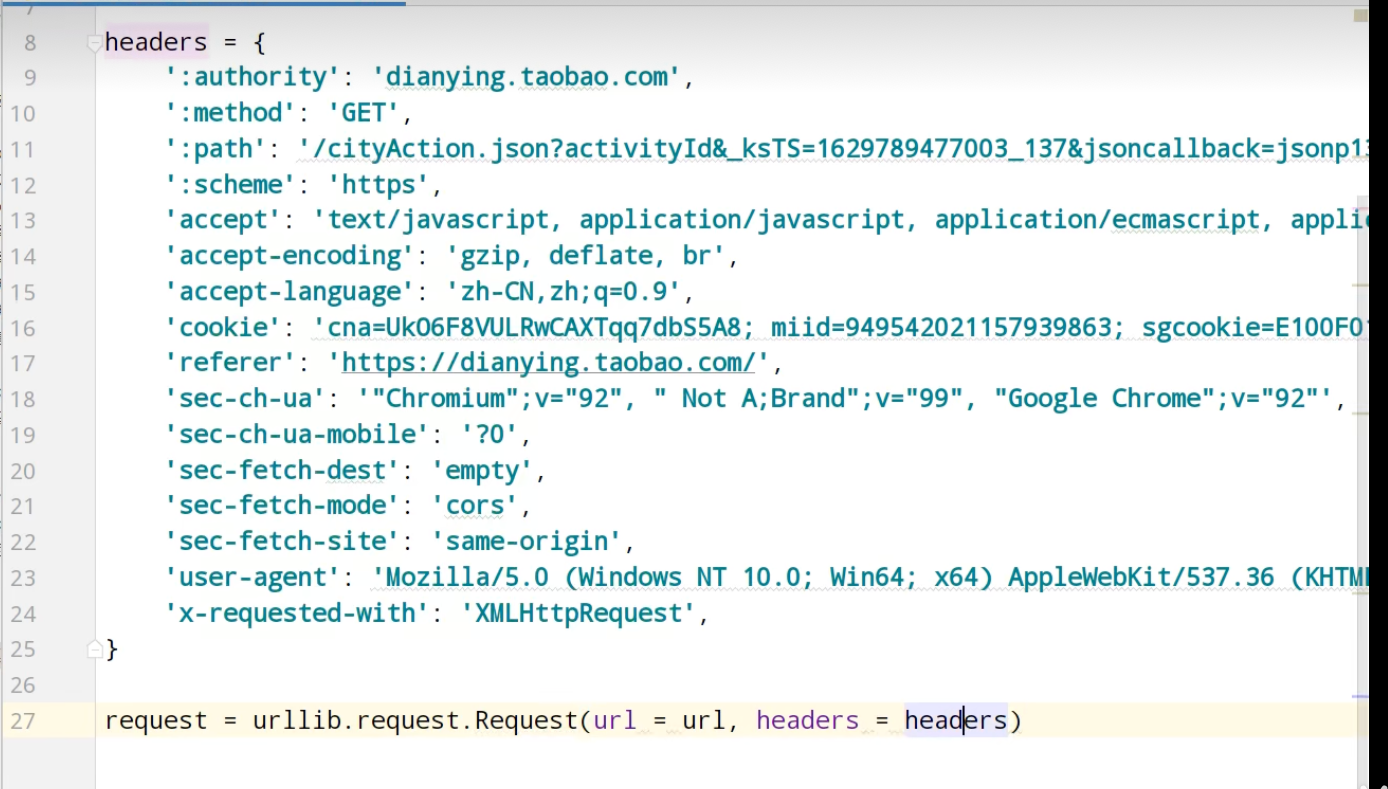
JsonPath


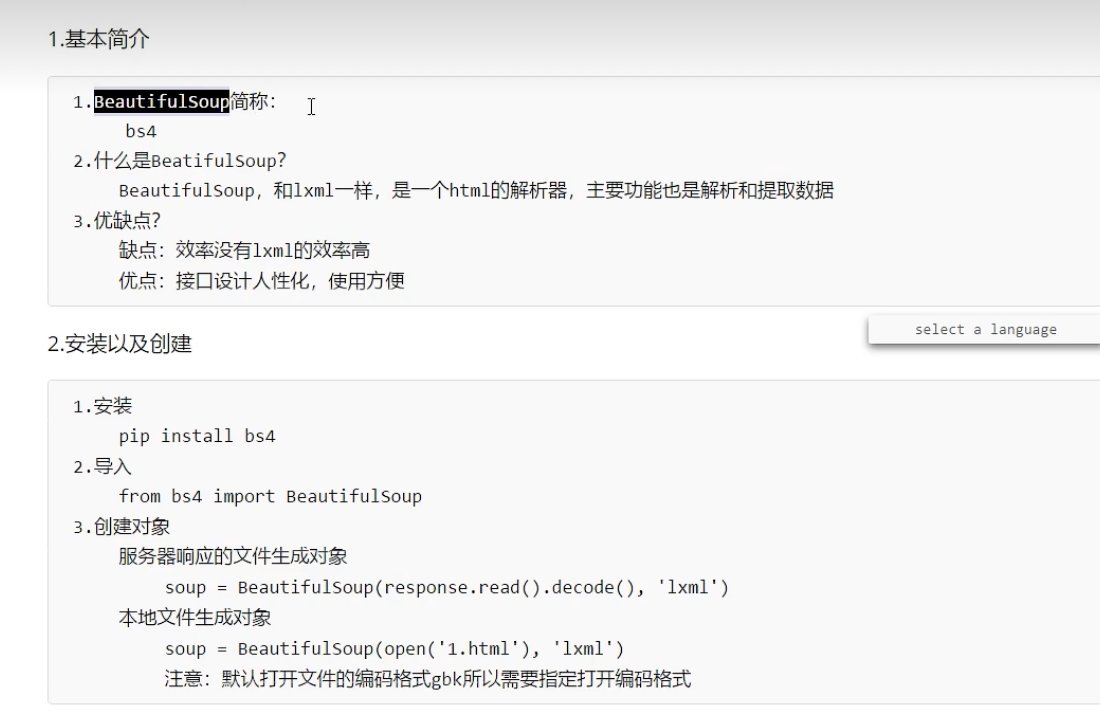
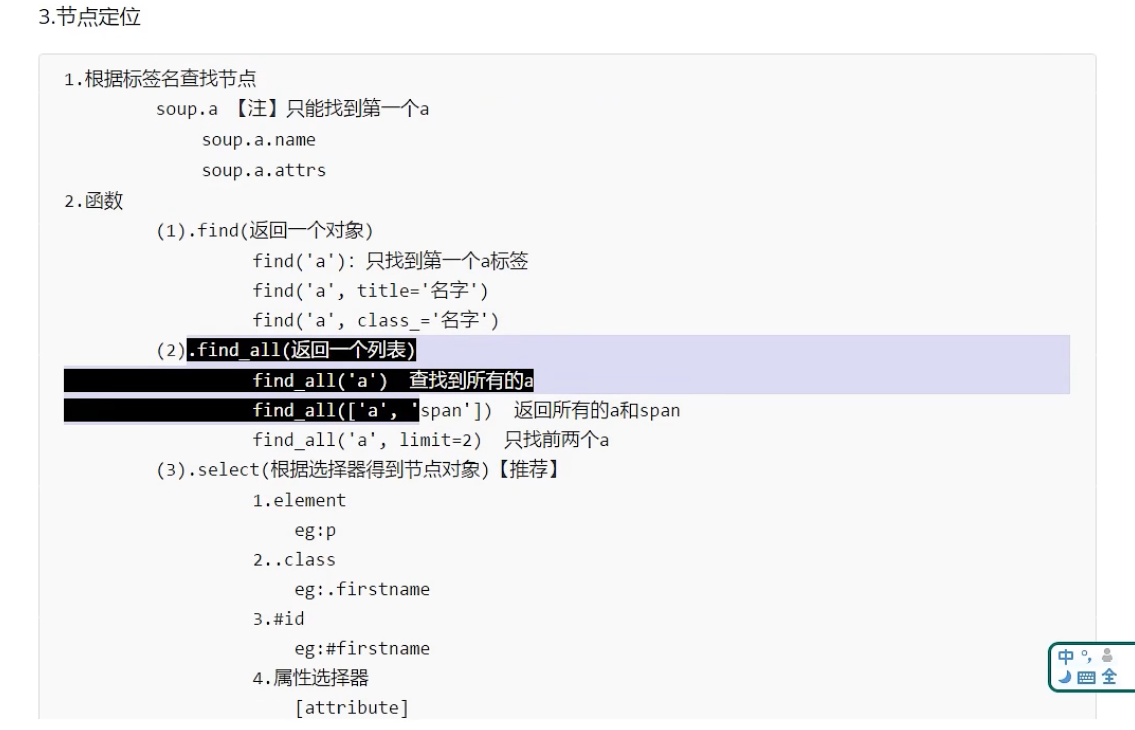
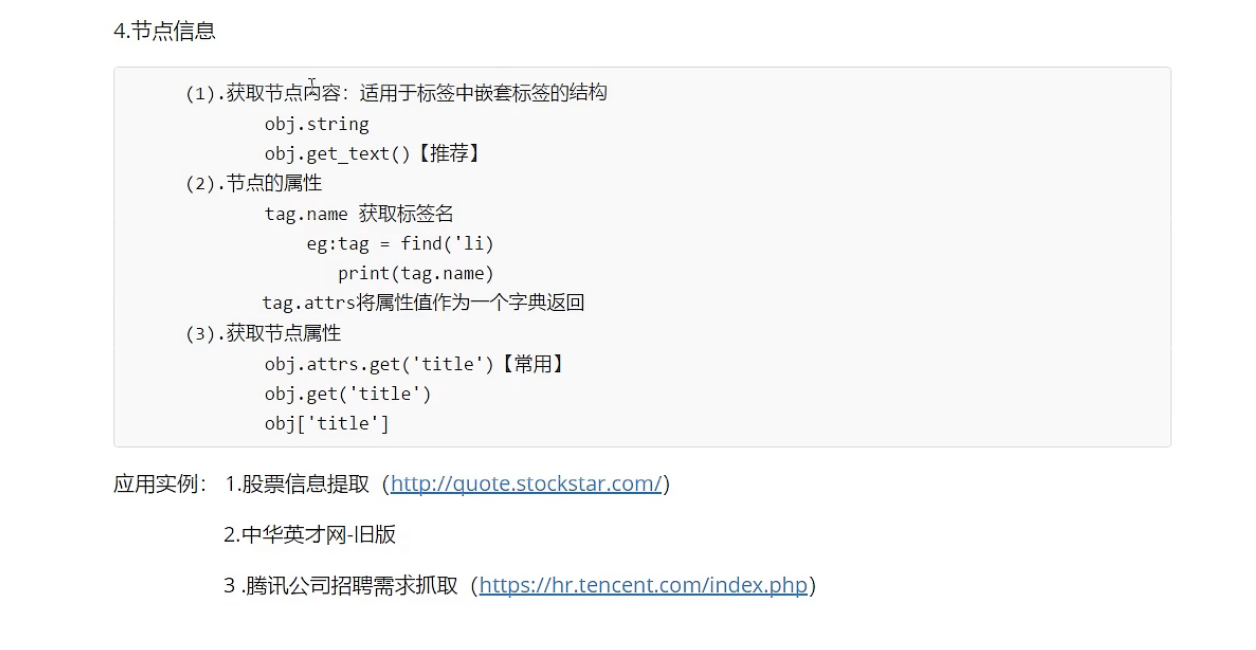
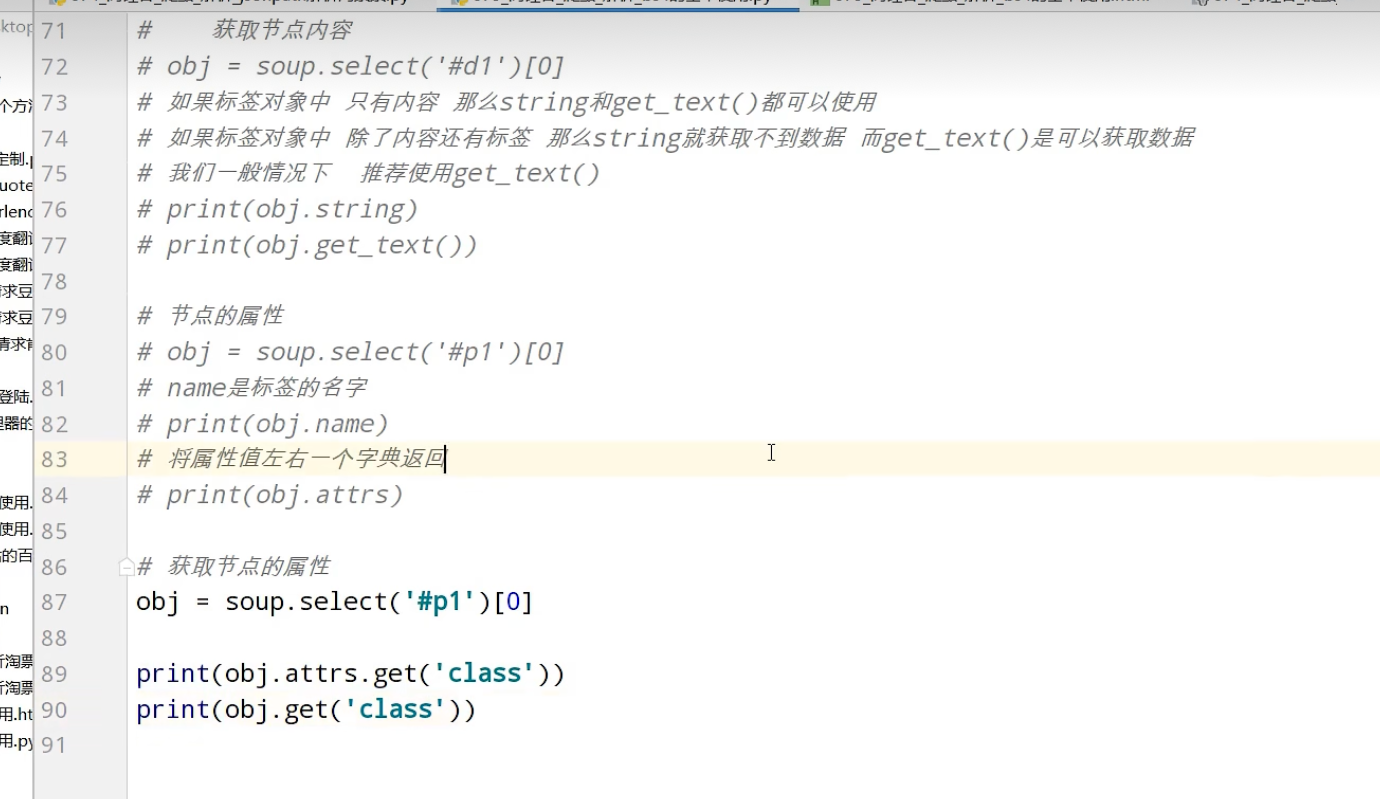
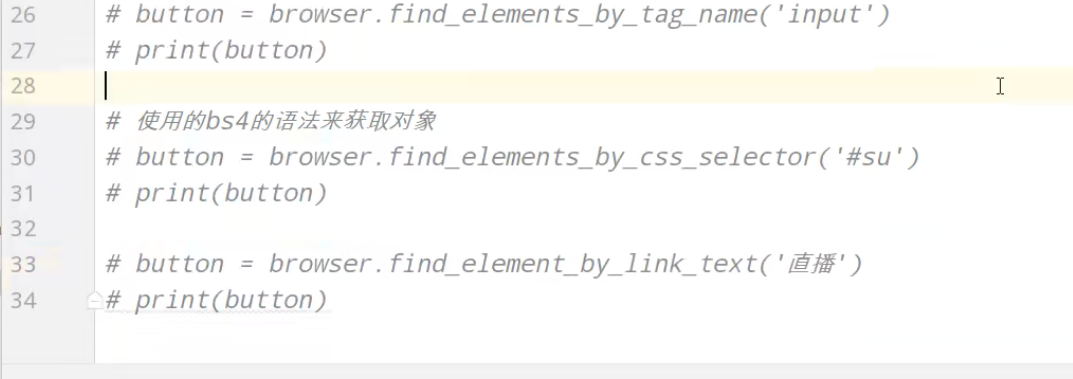
BeautifulSoup





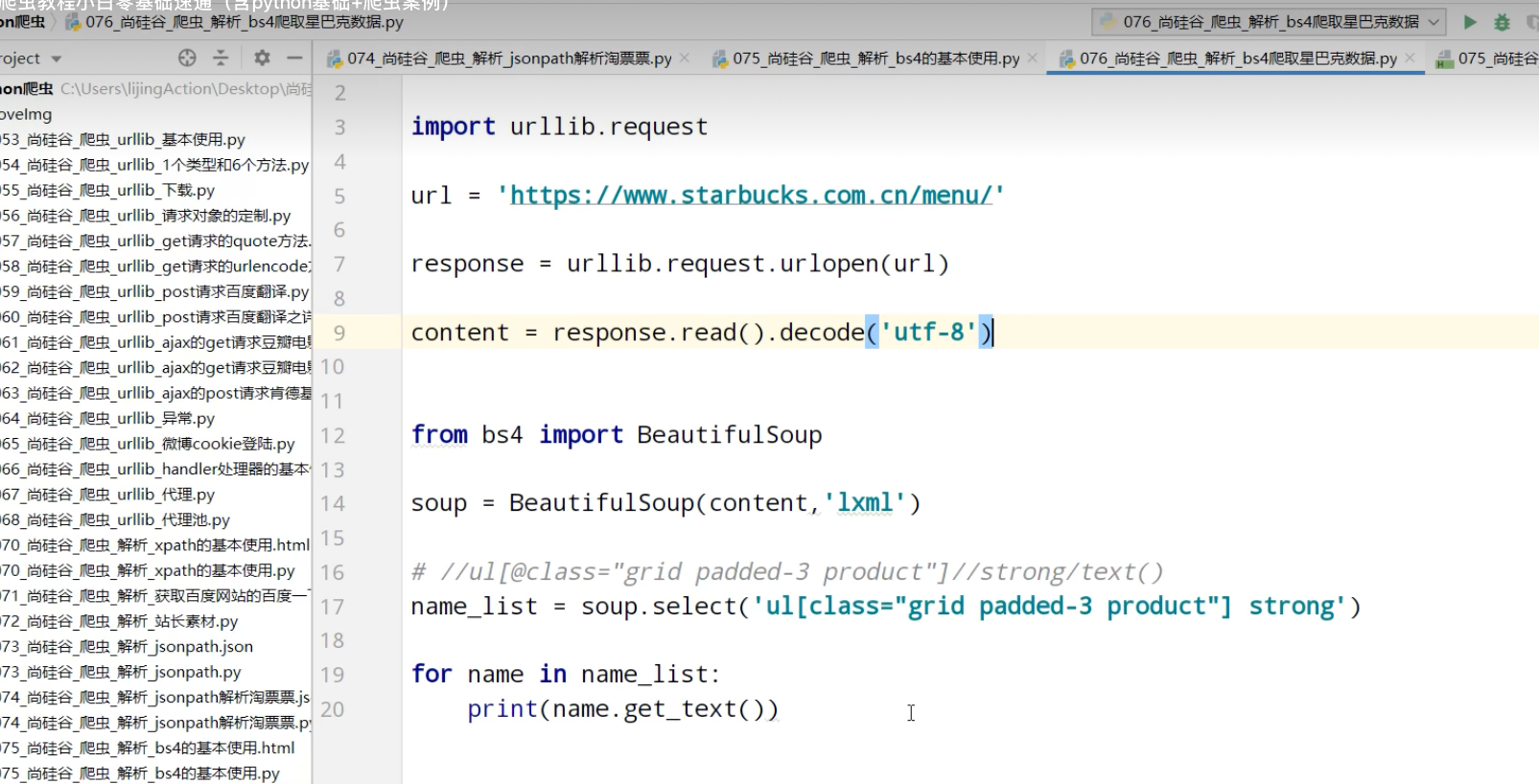
爬取星巴克数据
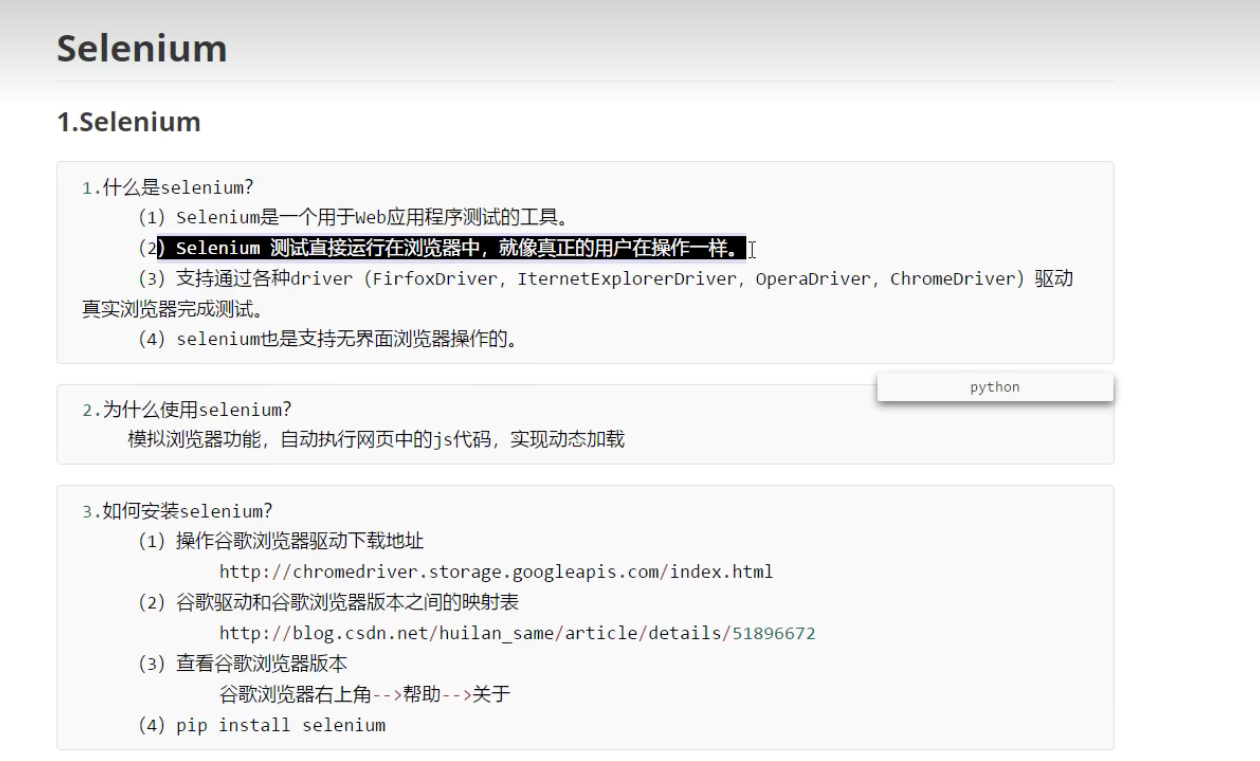
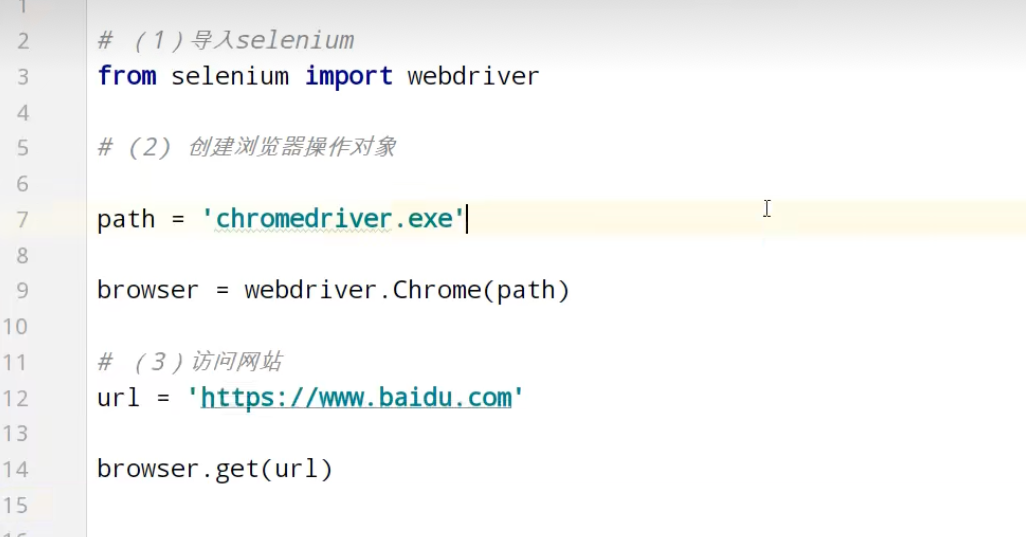
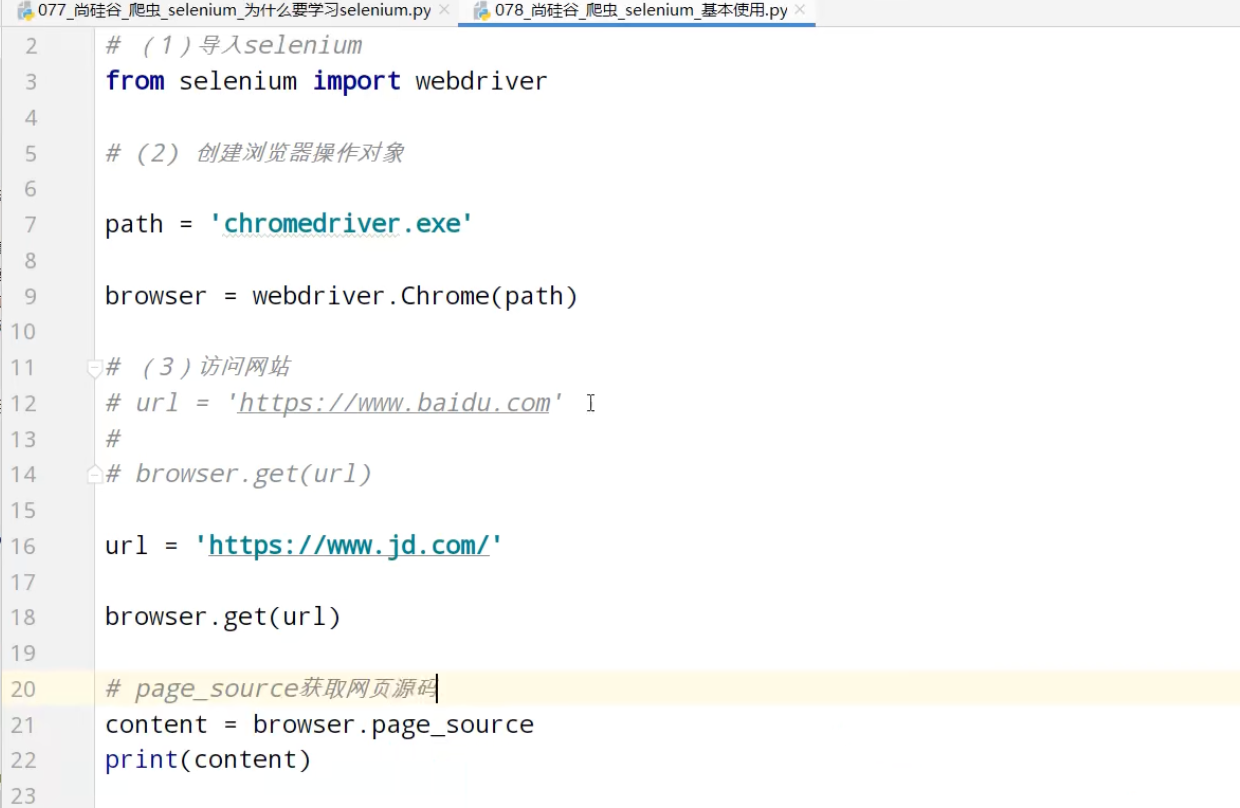
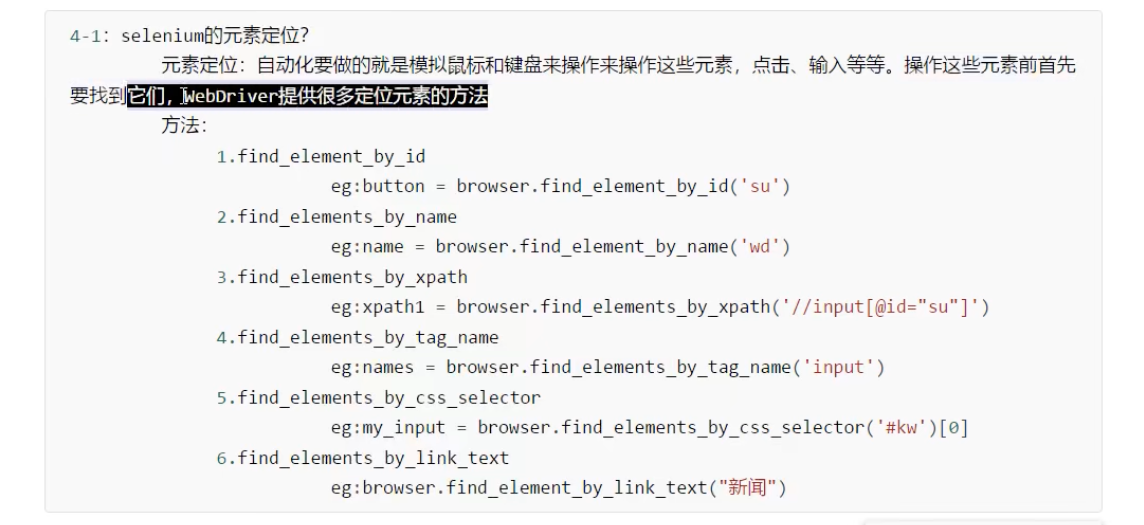
Selenium
Selenium
驱动下载后,解压,放在项目目录下


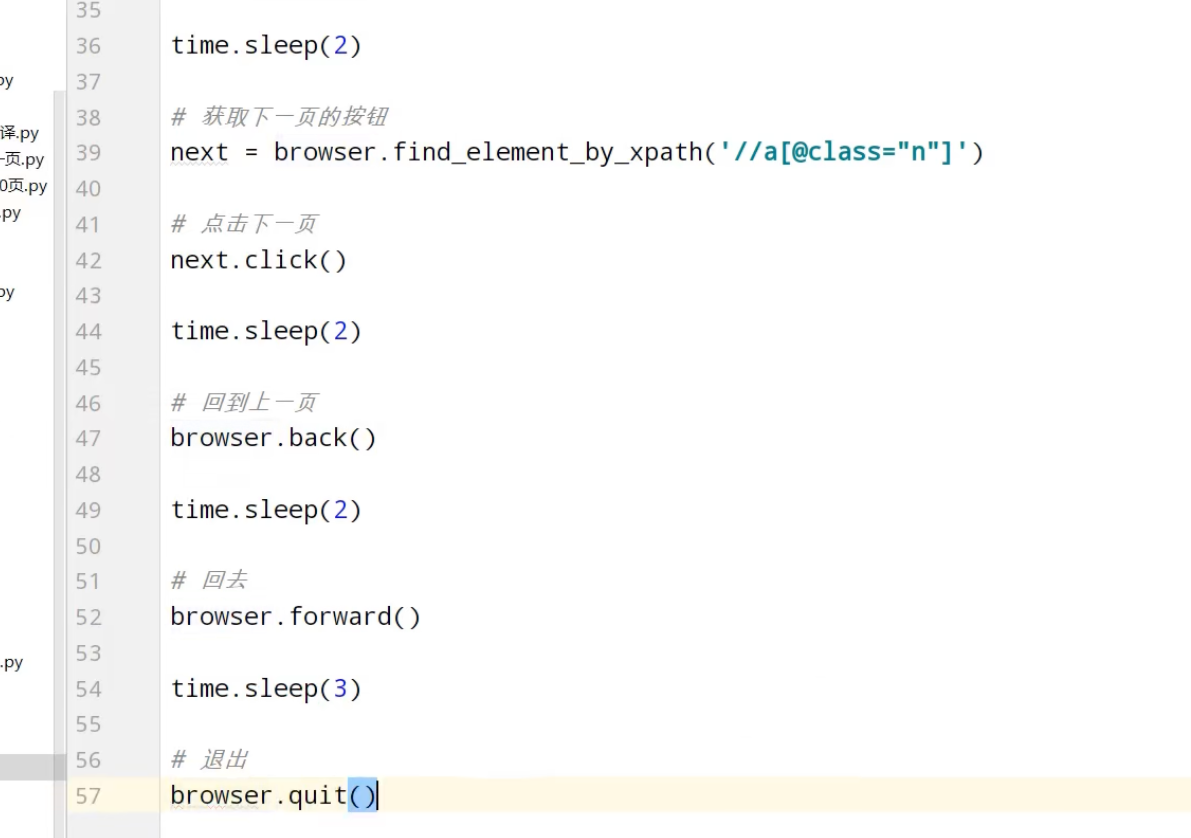
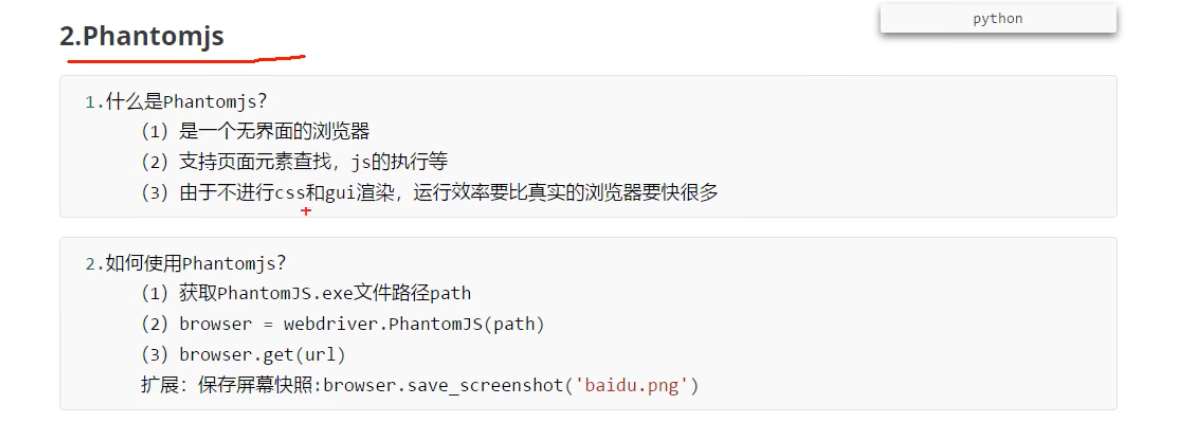
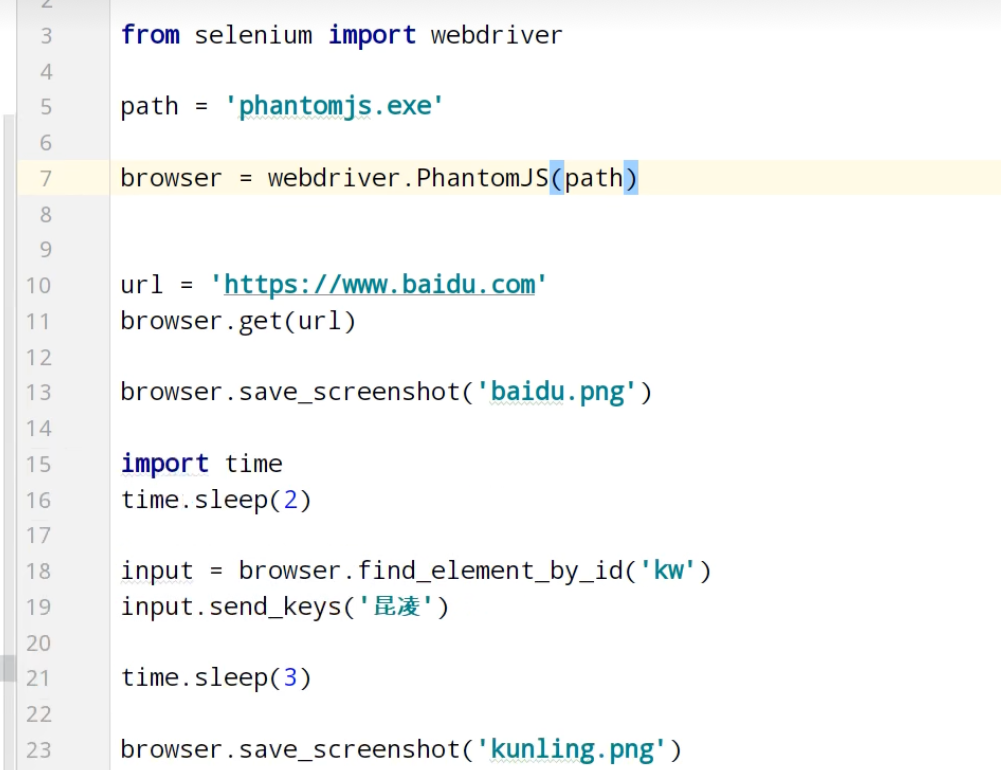
Phantomjs(基本被淘汰)
驱动下载后,解压,放在项目目录下
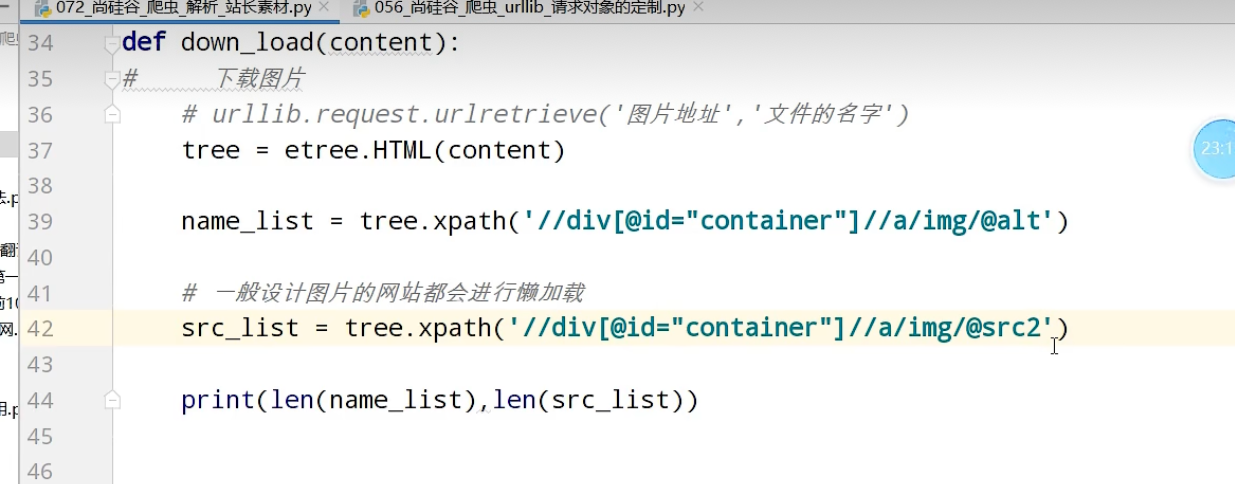
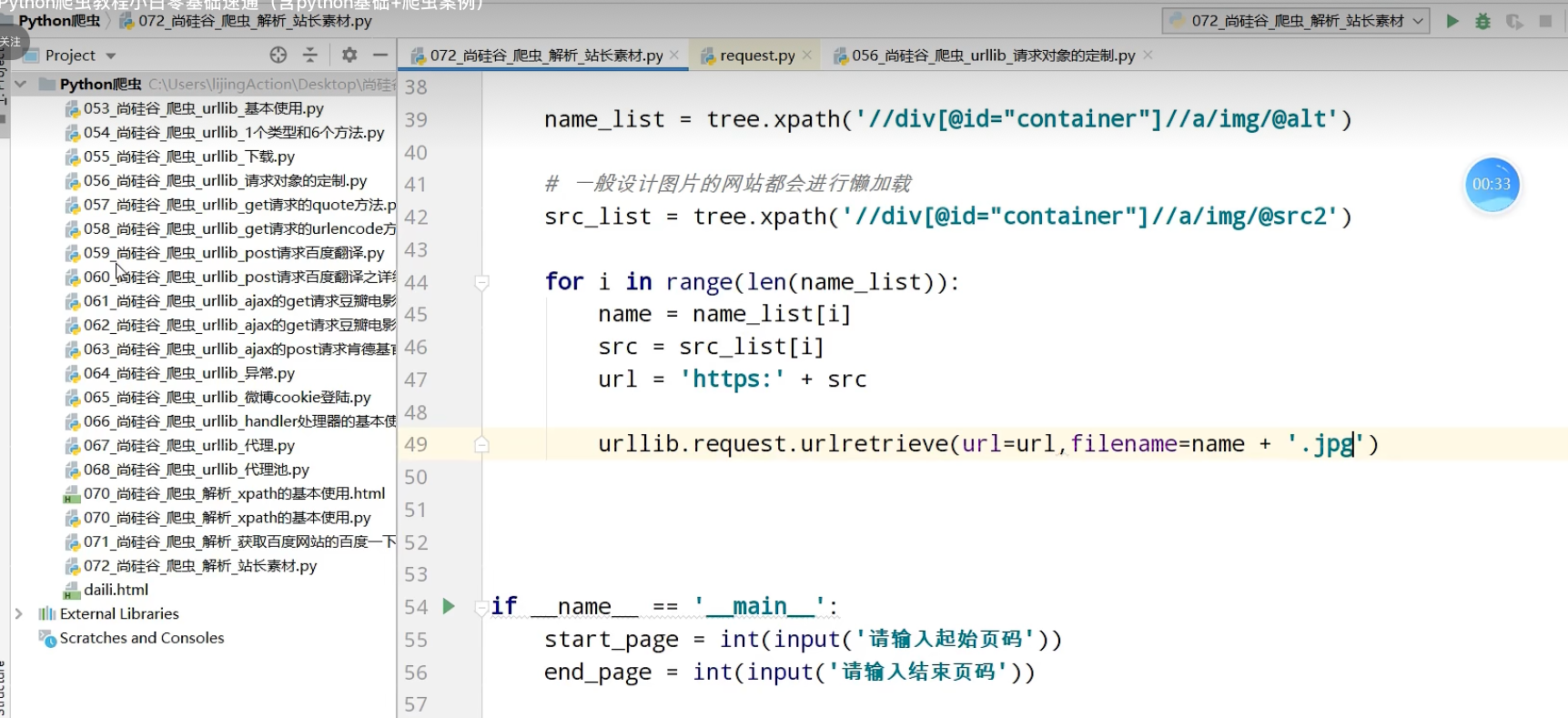
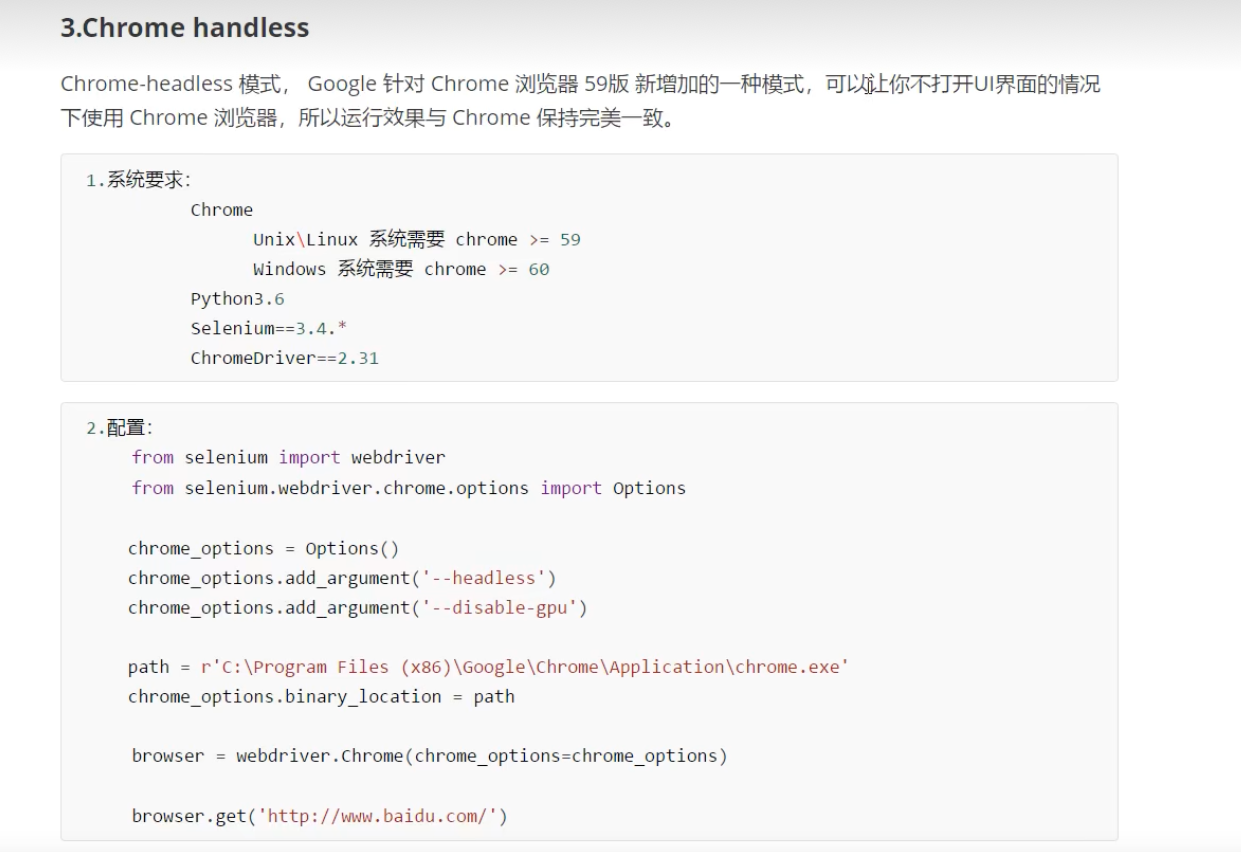
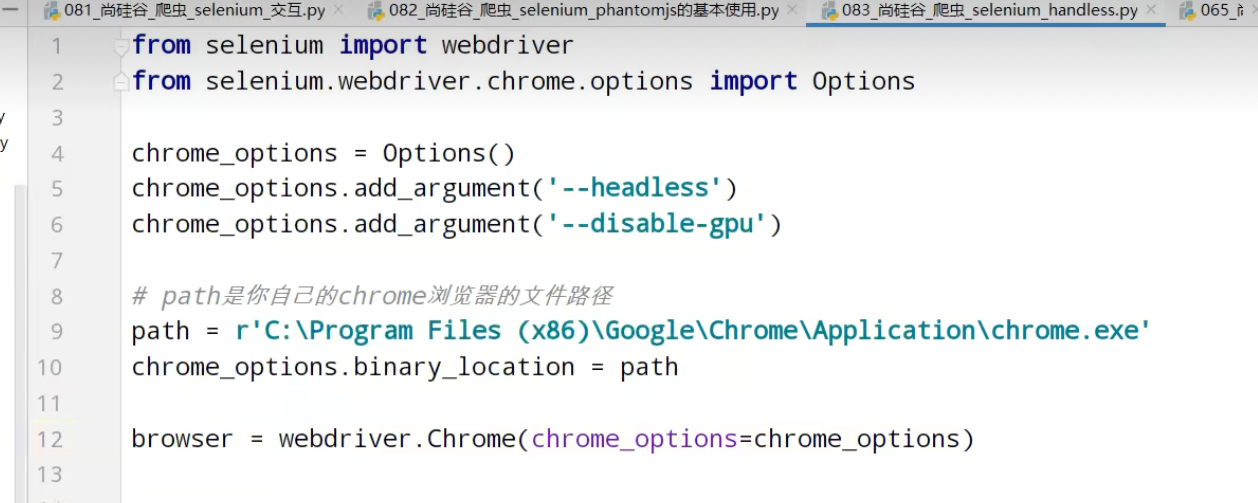
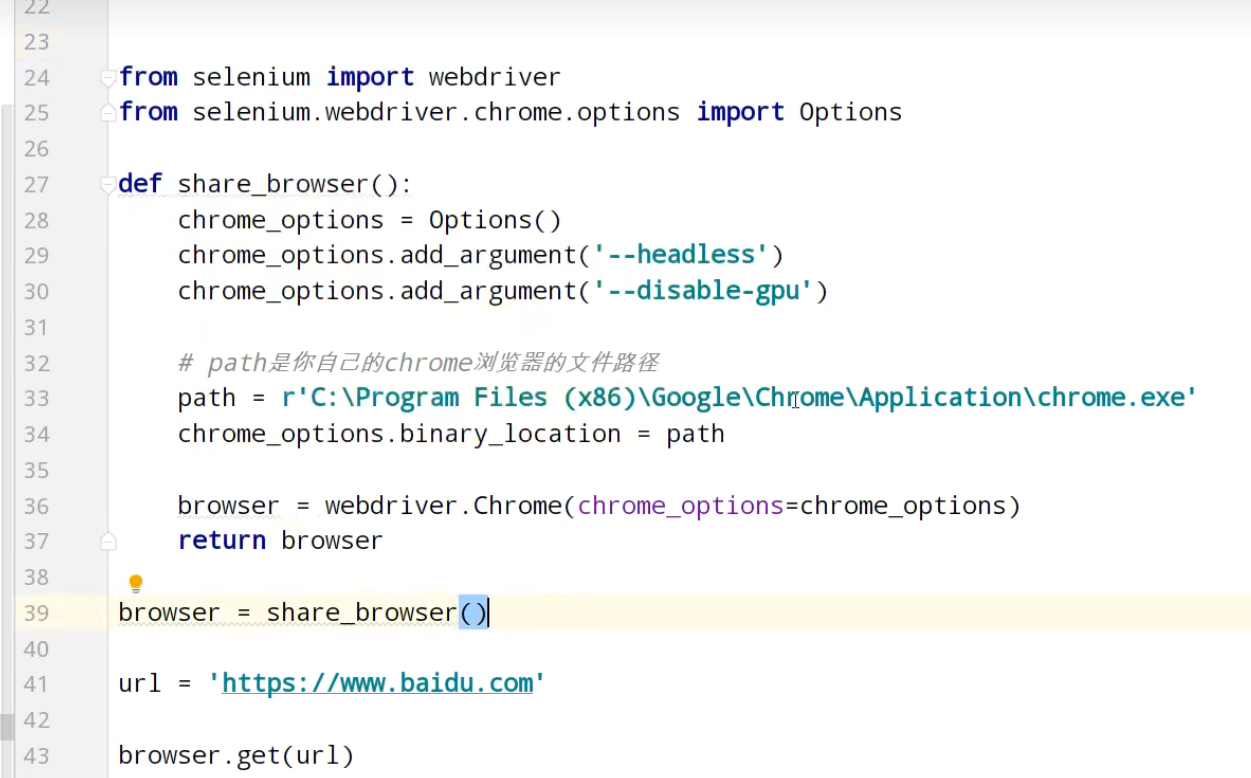
Chrome handless

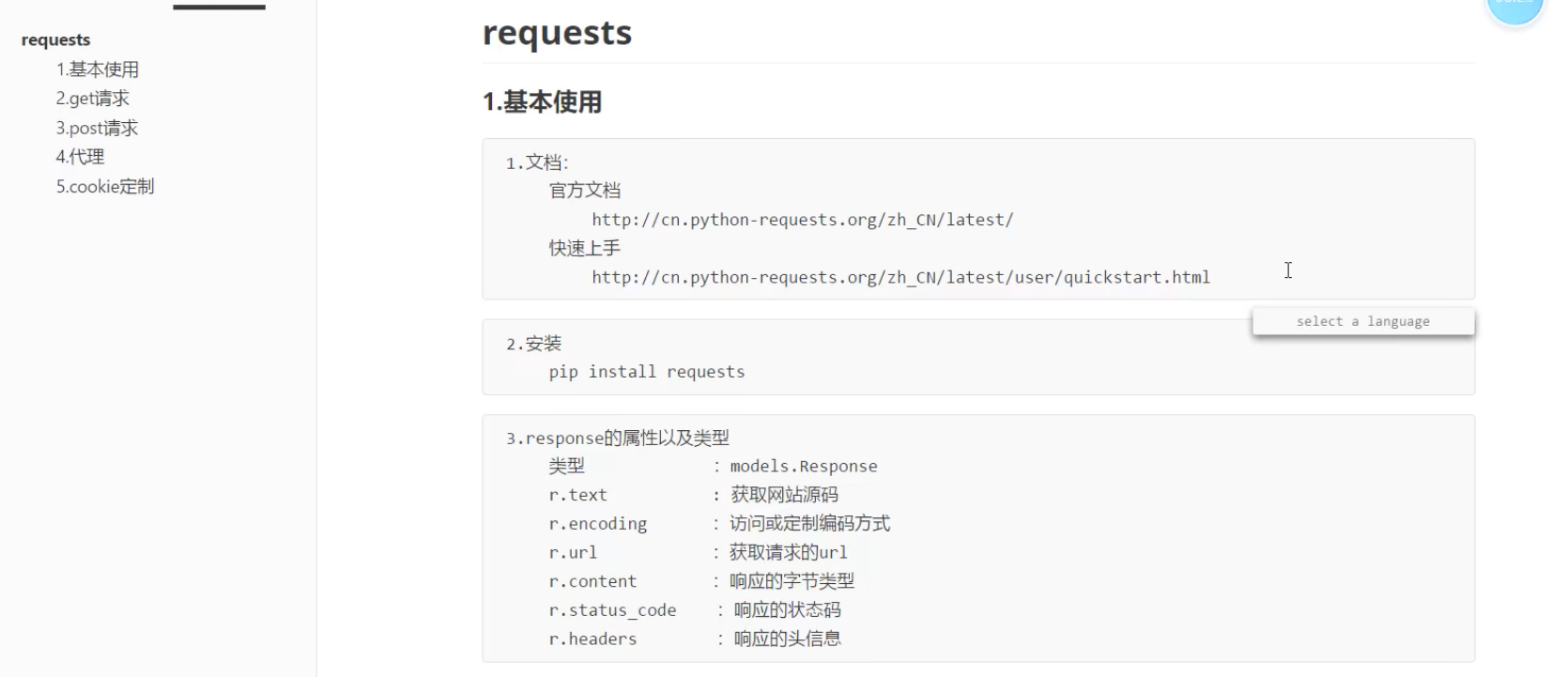
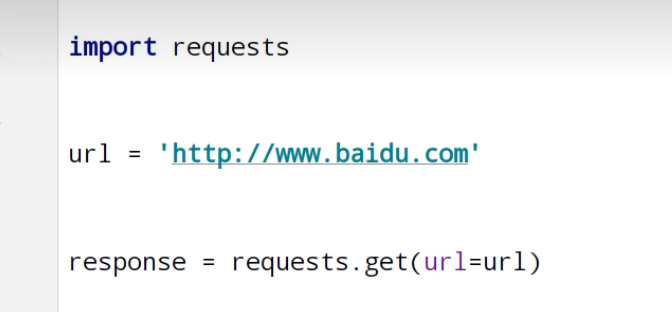
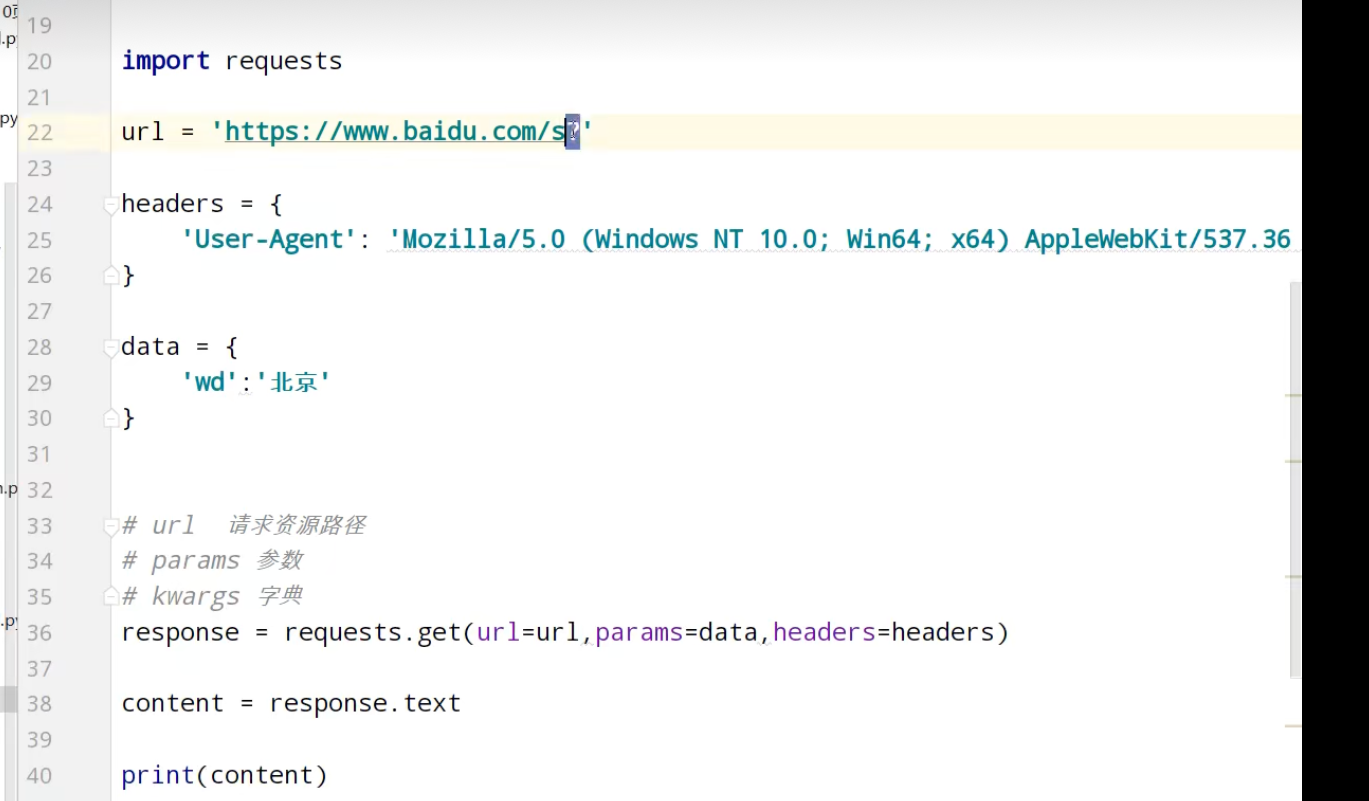
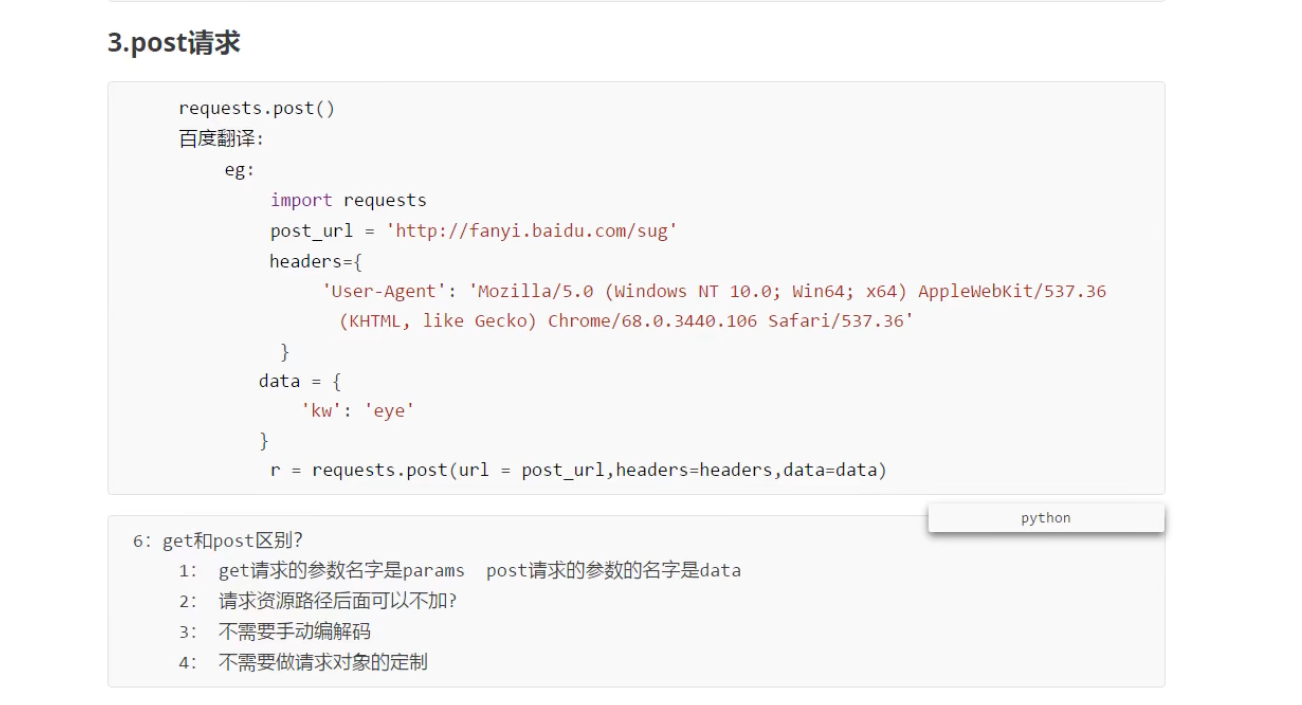
requests



超级鹰平台,能够识别验证码图片
scrapy
- scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖
掘,信息处理或存储历史数据等一系列的程序中。
# (1) pip install scrapy
# (2)错1: building 'twisted.test.raiser' extension
#error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft
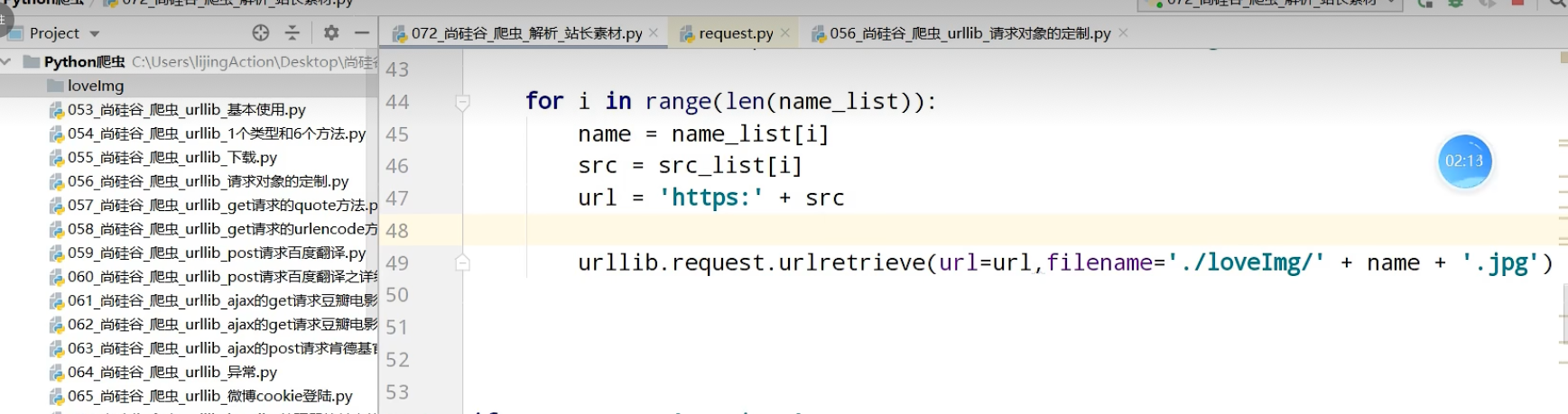
#Build Tools": http://landinghub.visualstudio.com/visual-cpp-build-too
#解决1
#http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
#Twisted-20.3.0-cp37-cp37m-win_amd64.whl
#cp是你的python版本
#amd是你的操作系统的版本
#下载完成之后使用pip install twistec的路径安装
#切记安装完twisted再次安装scrapy
# (3)报错2 示python -m pip install --upgrade pip
#解决2 运行python -m pip install --upgrade pip
# (4)报错3 win32的错误
#解决3 pip install pypiwin32
# (5) anaconda
1. scrapy项目的创建以及运行
1.创建scrapy项目:
终端输入 scrapy startproject 项目名称(不能数字开头,不能有汉字)
项目组成:
spiders
_init_.py 自定义的爬虫文件.py --》由我们自己创建,是实现爬虫核心功能的文件 init_.py
items.py ---》定义数据结构的地方,是一个继承自scrapy.Item的类
middlewares. py ---》中间件代理
pipelines.py ---》管道文件,里面只有一个类,用于处理下载数据的后续处理默认是300优先级,值越小优先级越高(1-1000)
settings.py -》配置文件比如:是否遵守robots协议,User-Agent定义等
2.创建爬虫文件
要在spiders文件夹中去创建爬虫文件
cd项目的名字\项目名字\spiders
cd scrapy_baidu_091\scrapy_baidu_091\spiders创建爬虫文件
scrapy genspider 爬虫文件的名字 要爬取网页
eg:scrapy genspider baidu www.baidu.com
一般情况下不需要添加http协议 因为start_urls的值是根据allowed_domains修改的所以添加了http的话那么start_urls就需要我们手动去修改了
生成的baidu.py
import scrapy
class BaiduSpider(scrapy. Spider):
#爬虫的名字用于运行爬虫的时候使用的值
name 'baidu'
#允许访问的域名
allowed_domains =['http://www.baidu.com']
#起始的url地址指的是第一次要访问的域名
# start_urls 在allowed_domains前面添加一个http://
#在 allowed_domains的后面添加一个/ start_urls ['http: //http: //www. baidu. com/']
#是执行了start_urls之后执行的方法
方法中的response就是回的那个对象
# 相当 response = urllib.request.urlopen()
# response requests. get()
def parse(self, response):
#字符串
# content = response. text
#二进制数据
# content = response. body
# print('
# print(content)
span response. xpath('//div[@id="filter"]/div[@class="tabs"]/a/span')[0]
print()
print(span. extract()
# response的属性和方法
# response.text
# 获取的是响应的字符串
# response.body
# 获取的是二进制数据
# response.xpath 可以直接是xpath方法来解析response中的内容 response. extract(
# 提取seletor对象的data属性值
# response.extract_first()提取的seletor列表的第一个数据
3.运行爬虫代码
scrapy crawl 爬虫名字
eg:scrapy crawl baidu
4. settings.py-ROBOTTXT_OBEY=TRUE注释掉
2. scrapy架构组成
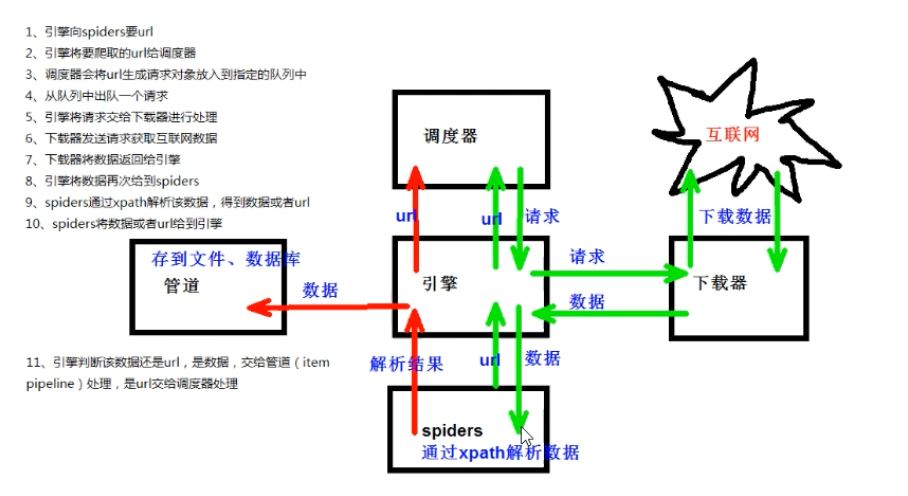
(1)引擎-–》自动运行,无需关注,会自动组织所有的请求对象,分发给下载器
(2)下载器--》从引擎处获取到请求对象后,请求数据
(3)spiders-–》Spider类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。换句话说, Spider就是您定义爬取的动作及分析某个网页(或者是有些网页)的地方。
(4)调度器--》有自己的调度规则,无需关注
(5)管道(Item pipeline)—》最终处理数据的管道,会预留接口供我们处理数据
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。
每个item pipeline组件(有时称之为“Item Pipeline")是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。
以下是item pipeline的一些典型应用:
1.清理HTML数据
2.验证爬取的数据(检查item包含某些字段)
3.查重(并丢弃)
4.将爬取结果保存到数据库中
class CarSpider(scrapy. Spider):
name ='car'
allowed_domains ['https: //car. autohome. com. cn/price/brand-15. html']
#注意如果你的请求的接口是html为结尾的那么是不需要加/的
start_urls ['https: //car, autohome. com. cn/price/brand-15. html']
def parse(self, response):
name_list response. xpath('//div[@class="main-title"]/a/text()')
price_list response. xpath('//div[@class="main-lever"]//span/span/text)'
for i in range(len(name_list)):
name = name_list[i].extract()
price = price_list[i].extract()
print(name, price)
3. scrapy工作原理
2. scrapy shell
1.什么是scrpy shell?
Scrapy终端,是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。其本意是用来测试提取
数据的代码,不过您可以将其作为正常的Python终端,在上面测试任何的Python代码。
该终端是用来测试XPath或CSS表达式,查看他们的工作方式及从爬取的网页中提取的数据。在编写您的spider时,该
终端提供了交互性测试您的表达式代码的功能,免去了每次修改后运行spider的麻烦。
一旦熟悉了Scrapy终端后,您会发现其在开发和调试spider时发挥的巨大作用。
2.安装ipython
安装:pip install ipython
简介:如果您安装了 IPython,Scrapy终端将使用 IPython(替代标准Python终端)。 IPython 终端与其他
相比更为强大,提供智能的自动补全,高亮输出,及其他特性。
直接在终端输入 scrapy shell www.baidu.com
3. yield
1.带有yield的函数不再是一个普通函数,而是一个生成器generator,可用于迭代
2.yield是一个类似 return的关键字,迭代一次遇到yield时就返回yield后面(右边)的值。重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行
3.简要理解:yield就是return返回一个值,并且记住这个返回的位置,下次迭代就从这个位置后(下一行)开始案例:1.当当网
(1)yield(2).管道封装(3).多条管道下载(4)多页数据下载
import scrapy
class ScrapyDangdang095Item(scrapy.Item):
# 定义下载的数据都有什么
src = scrapy.Field()
name = scrapy.Field()
price = scrapy.Field()
import scrapy
from scrapy_dangdang_095.items import ScrapyDangdang095Item
class DangSpider(scrapy. Spider):
name ='dang'
allowed_domains = ['http: //category.dangdang.com/cp01.01.02.00.00.00.html']
start_urls = ['http: //category.dangdang.com/cp01.01.02.00.00.00.html']
def parse(self, response):
#pipelines
#items
#定义数据结构的
#src =//ul[@id="component_59"]/li//img/@src
#alt = //ul[@id="component_59"]/li//img/@alt
#price = //ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()
#所有的seletor的对象都可以再次调用xpath方法
li_list response. xpath('//ul[@id="component_59"]/1i')
for li in li list:
src = li. xpath('.//img/@data-original').extract_first()
if src:
src = src
else
src = li. xpath('.//img/@src').extract_first()
name = li. xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
book = ScrapyDangdang095Item(src=src,name=name,price=price)
# 获取一个book就将book交给pipelines
yield book
settings中开启管道,以下代码注释解开
ITEM_PIPELINES = {
#管道可以有很多个
‘scrapy_dangdang_095.pipelines.ScrapyDangdang095Pipeline’: 300,
}
class ScrapyDangdang095Pipeline:
#在爬虫文件开始的之前就执行的一个方法
def open_spider(self, spider):
self. fp open('book. json', 'w', encoding='utf-8')
# item就是yield后面的book对象
def process_item(self, item, spider):
#以下这种模式不推荐因为每传递过来一个对象那么就打开一次文件对文件的操作过于频繁
##(1)write方法必须要写一个字符串而不能是其他的对象
##(2)w模式会每一个对象都打开一次文件覆盖之前的内容
# with open('book.json','a',encoding='utf-8')as fp: #
fp. write(str(item))
self. fp. write(str(item))
return item
#在爬虫文件执行完之后执行的方法
def close_spider(self, spider):
self. fp. close()
#多条管道开启
#(1)定义管道类
#(2)在settings中开启管道
class DangDangDownloadPipeline:
def process_item(self, item, spider):
url item. get('src')
filename ='./books/' item. get( 'name')+'. jpg'
urllib. request. urlretrieve(url ur1, filename= filename)
return item
ITEM _PIPELINES ={
#管道可以有很多个那么管道是有优先级的优先级的范围是1到1000值越小优先级越高
'scrapy_dangdang_095.pipelines.ScrapyDangdang095Pipeline': 300,
'scrapy_dangdang_095. pipelines. DangDangDownloadPipeline': 301
}
- 多页数据下载
import scrapy
from scrapy_dangdang_095.items import ScrapyDangdang095Item
class DangSpider(scrapy. Spider):
name ='dang'
#allowed_domains = ['http: //category.dangdang.com/cp01.01.02.00.00.00.html']
#如果是多页下载,要调整allowed_domains的范围,一般只写域名
allowed_domains = ['category.dangdang.com']
start_urls = ['http: //category.dangdang.com/cp01.01.02.00.00.00.html']
base_url = 'http://category.dangdang.com/pg'
page =1
def parse(self, response):
#pipelines
#items
#定义数据结构的
#src =//ul[@id="component_59"]/li//img/@src
#alt = //ul[@id="component_59"]/li//img/@alt
#price = //ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()
#所有的seletor的对象都可以再次调用xpath方法
li_list response. xpath('//ul[@id="component_59"]/1i')
for li in li list:
src = li. xpath('.//img/@data-original').extract_first()
if src:
src = src
else
src = li. xpath('.//img/@src').extract_first()
name = li. xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()
book = ScrapyDangdang095Item(src=src,name=name,price=price)
# 获取一个book就将book交给pipelines
yield book
#每一页的爬取的业务逻辑全都是一样的,所以我们只需要将执行的那个页的请求再次调用parse方法就可以了
#http: //category. dangdang. com/pg2-cp01. 01. 02.00.00.00. html
#http://category.dangdang.com/pg3-cp01.01.02.00.00.00.html
#http: //category. dangdang. com/pg4-cp01. 01. 02. 00. 00. 00. html
if self. page < 100:
self. page self. page 1
url = self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html'
#怎么去调用parse方法
#scrapy.Request就是scrpay的get请求
#url就是请求地址
#callback是你要执行的那个函数注意需要加
yield scrapy. Request(url=ur1, callback=self. parse)
2.电影天堂
(1)一个item包含多级页面的数据
import Scrapy
from scrapy movie 099. items import ScrapyMovie099Item
class MvSpider(scrapy. Spider):
name ='mv'
allowed_domains = ['https: //www. dytt8. net/html/gndy/china/index. html']
start_urls = ['https: //www. dytt8. net/html/gndy/china/index. html']
def parse(self, response):
#要第一个的名字和第二页的图片
a_list= response. xpath('//div[@class="co_content8"]//td[2]//a[2]')
for a in a list:
#获取第一页name和要点击接
name = a.xpath('./text()'). extract_first()
href = a.xpath('./@href').extract_first()
#对第二页的链接发起访问
yield scrapy. Request(url=ur1, callback=self. parse_second, meta=('name': name)
def parse_second(self, response):
#注意如果拿不到数据的情况下一定检查你的xpath语法是否正确
src response. xpath('//div[@id="Zoom"]//img/@src').extract_first()
#接受到请求的那个meta参数的值
name = response. meta[ 'name']
movie ScrapyMovie099Item(src=src, name=name)
yield movie
class ScrapyMovie099Pipeline:
def open_spider(self, spider):
self. fp open('movie. json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self. fp. write(str(item))
return item
def close_spider(self, spider):
self. fp. close()
-
Mysql
(1)下载(https:/dev.mysql.com/downloads/windows/installer/5.7.html
(2)安装 (https: //jingyan.baidu.com/album/d7130635f1c77d13fdf475df.html) -
pymysql的使用步骤
1.pip install pymysql
2.pymysql. connect(host, port, user, password, db, charset)
3.conn. cursor()
4.cursor.execute() -
CrawlSpider
1.继承自scrapy.Spider
2.独门秘笈
CrawlSpider可以定义规则,再解析html内容的时候,可以根据链接规则提取出指定的链接,然后再向这些链接发送请求
所以,如果有需要跟进链接的需求,意思就是爬取了网页之后,需要提取链接再次爬取,使用CrawlSpider是非常合适的
3.提取链接
链接提取器,在这里就可以写规则提取指定链接
scrapy. linkextractors. LinkExtractor(
allow =()#正则表达式提取符合正则的链接
deny = (),#(不用)正则表达式不提取符合正则的链接
allow domains =()#(不用)允许的域名
deny_domains =()#(不用)不允许的域名
restrict xpaths =()),xpath,提取符合xpath规则的链接
restrict css =(#提取符合选择器规则的链接)
4.模拟使用
正则用法: links1 = LinkExtractor(allow=r’list_23_\d+.html’)
xpath用法: links2 = LinkExtractor(restrict_xpaths=r’//div[@class=“x”]‘) css用法: links3 = LinkExtractor(restrict css=’.x’)
5.提取连接
link. extract_links(response)
6.注意事项
【注1】callback只能写函数名字符串,callback=‘parse item’
【注2】在基本的spider中,如果重新发送请求,那里的callback写的是
callback=self.parse_item 【稍后看】follow=true是否进就是取规则进行取 -
CrawlSpider案例
需求:读书网数据入库
1.创建项目: scrapy startproject dushuproject
2.跳转到spiders路径 cd\dushuproject\dushuproject\spiders
3.创建爬虫类: scrapy genspider -t crawl read www.dushu.com
4.items
5.spiders
6.settings
7.pipelines
数据保存到本地
数据保存到mysq1数据库
import scrapy
from scrapy. linkextractors import LinkExtractor
from scrapy. spiders import CrawlSpider, Rule
from scrapy_readbook_101. items import ScrapyReadbook101Item
class ReadSpider(CrawlSpider )
name 'read'
allowed_domains ['www. dushu. com']
start_urls ['https: //www. dushu. com/book/1188_1. html']
rules =
Rule(LinkExtractor(allow=r'/book/1188_\d+\. html'),
callback='parse_item',
follow=False),
)
def parse_item(self, response):
img_list response. xpath('//div[@class="bookslist"]//img') for img in img_list:
name img. xpath('. /@data-original'). extract_first()
src img. xpath('./@alt'). extract_first()
book ScrapyReadbook101Item(name=name, src=src) yield book
return item
开启管道,写管道同之前
- 数据入库
settings.py
DB HOST = '192.168.231.130'#端口号是一个整数
DB PORT 3306
DB USER ='root'
DB PASSWROD ='1234'
DB_NAME ='spider01
DB CHARSET ='utf8
pipelines.py
class ScrapyReadbook101Pipeline:
def open_spider(self, spider):
self. fp open('book. json', 'w', encoding='utf-8')
def process_item(self, item, spider):
self. fp. write(str(item))
return item
def close_spider(self, spider):
self. fp. close()
from scrapy. utils. project import get_project_settings
class MysqlPipeline:
def open_spider(self, spider):
settings get_project_settings()
self. host settings 'DB_HOST']
self. port =settings 'DB_PORT']
self. user =settings 'DB_USER']
self. password =settings 'DB_PASSWROD']
self. name =settings 'DB_NAME']
self. charset =settings 'DB_CHARSET']
self. connect()
def connect(self):
self. conn pymysql. connect(
host=self. host,
port=self. port,
user=self. user,
password=self. password,
db=self. name,
charset=self. charset
self. corsor self. conn. cursor()
def process_item(self, item, spider):
sql 'insert into book(name, src) values("{}", "{}")' format(item['name'], item#执行sql语句
self. cursor. execute(sql)
#提交
self. conn. commit()
return item
def close_spider(self, spider):
self. cursor. close()
self. conn. close()
- 日志信息和日志等级
(1)日志级别:
CRITICAL:严重错误
ERROR:
一般错误
I WARNING:警告
INFO:
一般信息
DEBUG:调试信息
默认的日志等级是DEBUG
只要出现了DEBUG或者DEBUG以上等级的日志
那么这些日志将会打印
(2)settings.py文件设置:
默认的级别为DEBUG,会显示上面所有的信息
在配置文件中 settings.py
LOG_FILE:将屏幕显示的信息部记录到文件中,屏幕不再显示,注意文件后缀一定是.logLOG LEVEL:设置日志显示的等级,就是显示哪些,不显示哪些 - Request和response总结
- scrapy的post请求
import scrapy
import json
class TestpostSpider(scrapy. Spider):
name ='testpost'
allowed_domains ['https: //fanyi. baidu. com/sug']# post请求如果没有参数那么这个请求将没有任何意义
#start_urls
#parse方法也没有用了
# start_urls 'https: //fanyi. baidu. com/sug/'] #
# def parse(self, response):
# pass
def start_requests(self):
url ='https: //fanyi. baidu. com/sug'
data={'kw': 'final'}
yield scrapy. FormRequest(url=ur1, formdata=data, callback=self.parse_second)
def parse_second(self, response):
content =response. text
obj =json. loads(content, encoding='utf-8')
print(obj)
- 代理