1.什么是作业调度
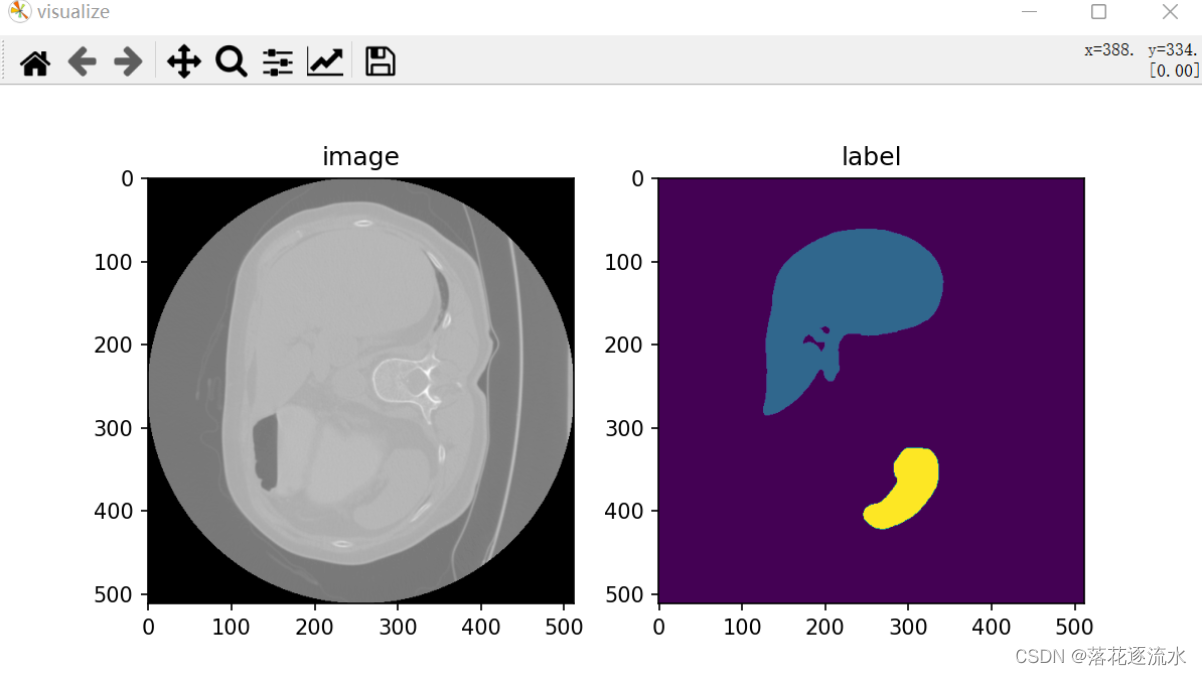
Flink 通过 Task Slots 来定义执行资源。每个 TaskManager 有一到多个 task slot,每个 task slot 可以运行一条由多个并行 task 组成的流水线。 这样一条流水线由多个连续的 task 组成,比如并行度为 n 的 MapFunction 和 并行度为 n 的 ReduceFunction。
例如:一个由数据源、MapFunction 和 ReduceFunction 组成的 Flink 作业,其中数据源和 MapFunction 的并行度为 4 ,ReduceFunction 的并行度为 3 。流水线由一系列的 Source - Map - Reduce 组成,运行在 2 个 TaskManager 组成的集群上,每个 TaskManager 包含 3 个 slot,整个作业的运行如下图所示。

2.作业调度的9种状态
当创建一个Flink任务后,该任务可能会经历多种状态。目前Flink给任务共定义了9种状态,包括:
- Created
- Running
- Finished
- Cancelling
- Canceled
- Restarting
- Failing
- Failed
- Suspended
具体状态流转如下图所示:
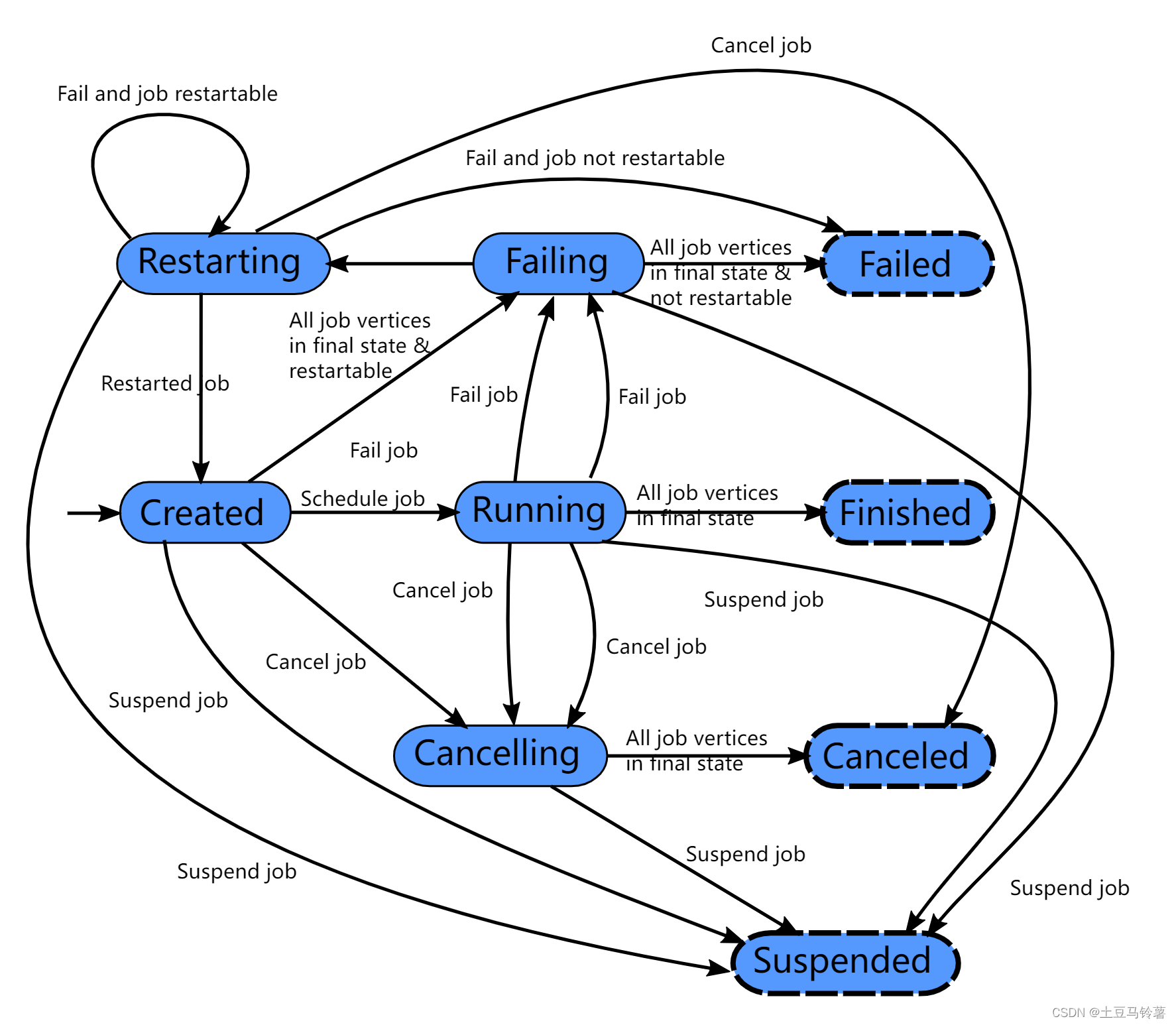
具体流程分成以下几个场景:
- 正常流程: Flink 作业正常启动处于 created 状态,启动成功后切换到 running 状态,当所有任务都执行完之后会切换到 finished 状态。
- 作业失败:如果遇到失败的话,作业首先切换到 failing 状态以便取消所有正在运行的 task。如果所有 job 节点都到达最终状态并且 job 无法重启, 那么 job 进入 failed 状态。
- 作业重试:如果配置了失败重试次数,任务会自动尝试重启,如果重启成功,那么任务会从Restarting 状态变更为 Created 继而再处于 Running 状态,如果重启失败且已无法恢复,那么任务会等所有tasks都进入到最终状态后变更为Failed状态。
- 作业取消:如果用户取消了 job 话,它会进入到 cancelling 状态,并取消所有正在运行的 task。当所有正在运行的 task 进入到最终状态的时候,job 进入 cancelled 状态。
Finished、canceled 和 failed 会导致全局的终结状态,并且触发作业的清理。跟这些状态不同,suspended 状态只是一个局部的终结。局部的终结意味着作业的执行已经被对应的 JobManager 终结,但是集群中另外的 JobManager 依然可以从高可用存储里获取作业信息并重启。因此一个处于 suspended 状态的作业不会被彻底清理掉。
3.Task状态转换
在整个 ExecutionGraph 执行期间,每个并行 task 都会经历多个阶段,从 created 状态到 finished 或 failed。下图展示了各种状态以及他们之间的转换关系。由于一个 task 可能会被执行多次(比如在异常恢复时),ExecutionVertex 的执行是由 Execution 来跟踪的,每个 ExecutionVertex 会记录当前的执行,以及之前的执行。
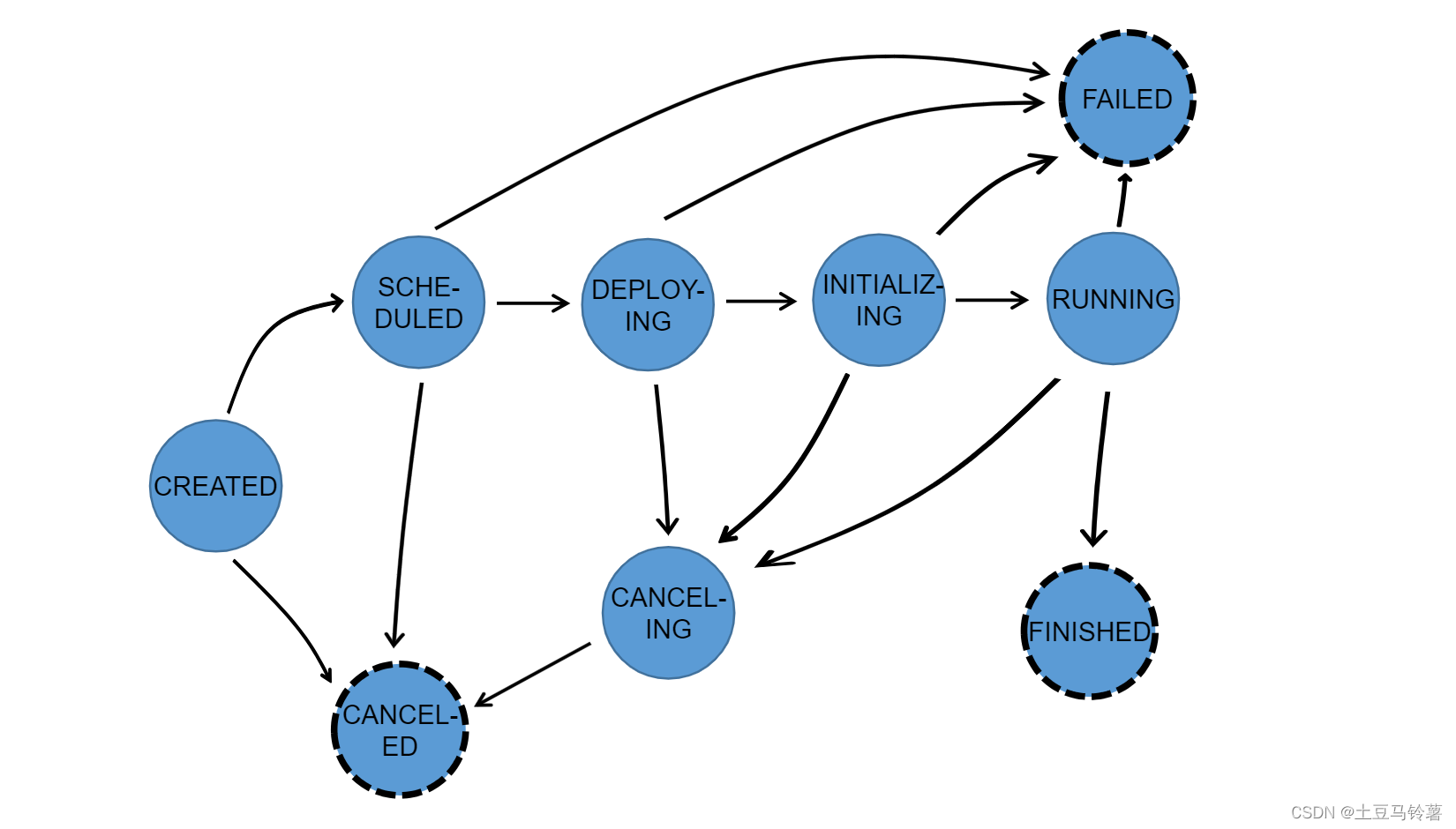
根据任务的不同状态,我们可以通过一些监控策略对任务的状态提前进行监控和预警,从而保证任务平稳运行。