文章目录
- 题目
- 标题和出处
- 难度
- 题目描述
- 要求
- 示例
- 数据范围
- 解法一
- 思路和算法
- 代码
- 复杂度分析
- 解法二
- 思路和算法
- 代码
- 复杂度分析
题目
标题和出处
标题:叶子相似的树
出处:872. 叶子相似的树
难度
3 级
题目描述
要求
考虑一个二叉树上所有的叶子,这些叶子的值按从左到右的顺序排列形成一个叶值序列。
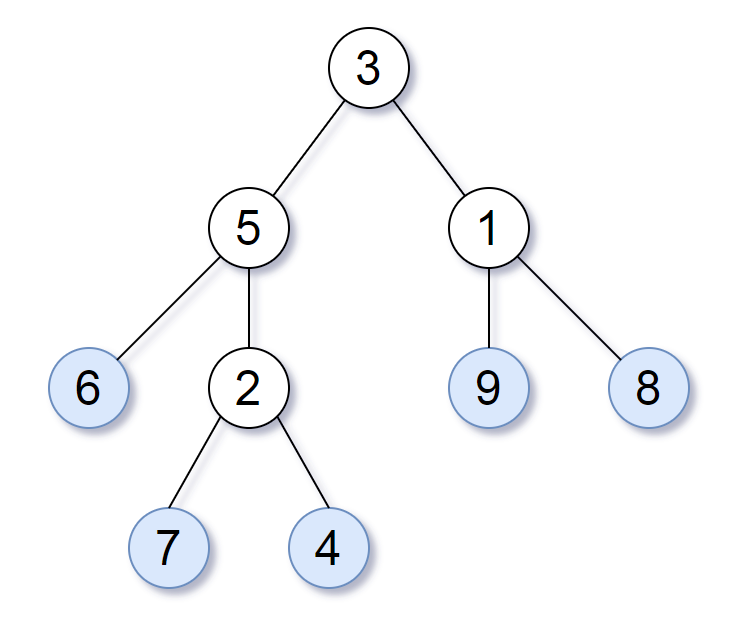
例如,上图给定的树的叶值序列为 (6, 7, 4, 9, 8) \texttt{(6, 7, 4, 9, 8)} (6, 7, 4, 9, 8)。
如果有两个二叉树的叶值序列相同,那么它们是叶相似的。
当且仅当给定的两个根结点分别为 root1 \texttt{root1} root1 和 root2 \texttt{root2} root2 的树是叶相似的情况下,返回 true \texttt{true} true。
示例
示例 1:
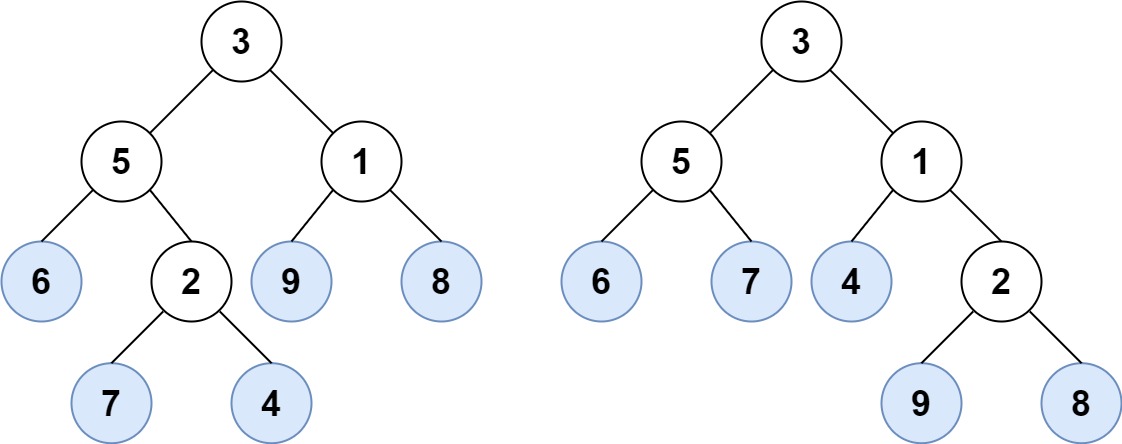
输入:
root1
=
[3,5,1,6,2,9,8,null,null,7,4],
root2
=
[3,5,1,6,7,4,2,null,null,null,null,null,null,9,8]
\texttt{root1 = [3,5,1,6,2,9,8,null,null,7,4], root2 = [3,5,1,6,7,4,2,null,null,null,null,null,null,9,8]}
root1 = [3,5,1,6,2,9,8,null,null,7,4], root2 = [3,5,1,6,7,4,2,null,null,null,null,null,null,9,8]
输出:
true
\texttt{true}
true
示例 2:

输入:
root1
=
[1,2,3],
root2
=
[1,3,2]
\texttt{root1 = [1,2,3], root2 = [1,3,2]}
root1 = [1,2,3], root2 = [1,3,2]
输出:
false
\texttt{false}
false
数据范围
- 每个树中结点数目在范围 [1, 200] \texttt{[1, 200]} [1, 200] 内
- 每个树中结点值在范围 [0, 200] \texttt{[0, 200]} [0, 200] 内
解法一
思路和算法
二叉树的叶值序列为所有叶结点值按照从左到右的顺序组成的序列。规定深度优先搜索的顺序为先遍历左子树再遍历右子树,则二叉树的叶值序列即为深度优先搜索遍历所有叶结点的顺序。
对于每个二叉树,从根结点开始深度优先搜索,访问根结点之后依次遍历左子树和右子树,并对左子树和右子树递归地遍历,访问到叶结点时将叶结点值加到叶值序列,遍历结束时即可得到二叉树的叶值序列。
两个二叉树都遍历结束之后,比较两个二叉树的叶值序列是否相等即可。
代码
class Solution {
public boolean leafSimilar(TreeNode root1, TreeNode root2) {
List<Integer> sequence1 = new ArrayList<Integer>();
List<Integer> sequence2 = new ArrayList<Integer>();
getLeafValueSequence(root1, sequence1);
getLeafValueSequence(root2, sequence2);
return sequence1.equals(sequence2);
}
public void getLeafValueSequence(TreeNode node, List<Integer> sequence) {
if (node.left == null && node.right == null) {
sequence.add(node.val);
} else {
if (node.left != null) {
getLeafValueSequence(node.left, sequence);
}
if (node.right != null) {
getLeafValueSequence(node.right, sequence);
}
}
}
}
复杂度分析
-
时间复杂度: O ( m + n ) O(m + n) O(m+n),其中 m m m 和 n n n 分别是两个二叉树的结点数。对两个二叉树深度优先搜索,每个结点都被访问一次。
-
空间复杂度: O ( m + n ) O(m + n) O(m+n),其中 m m m 和 n n n 分别是两个二叉树的结点数。空间复杂度主要是递归调用的栈空间和两个二叉树的叶值序列空间。
解法二
思路和算法
也可以使用迭代实现深度优先搜索,需要使用栈存储结点。
从根结点开始遍历。每次访问一个结点之后,将当前结点入栈然后将当前结点移动到其左子结点,直到当前结点为空。然后将一个结点出栈,将当前结点设为出栈结点的右子结点。当所有结点都访问过时,遍历结束。
遍历过程中,访问到叶结点时将叶结点值加到叶值序列。两个二叉树都遍历结束之后,比较两个二叉树的叶值序列是否相等即可。
代码
class Solution {
public boolean leafSimilar(TreeNode root1, TreeNode root2) {
List<Integer> sequence1 = getLeafValueSequence(root1);
List<Integer> sequence2 = getLeafValueSequence(root2);
return sequence1.equals(sequence2);
}
public List<Integer> getLeafValueSequence(TreeNode root) {
List<Integer> sequence = new ArrayList<Integer>();
Deque<TreeNode> stack = new ArrayDeque<TreeNode>();
TreeNode node = root;
while (!stack.isEmpty() || node != null) {
while (node != null) {
if (node.left == null && node.right == null) {
sequence.add(node.val);
}
stack.push(node);
node = node.left;
}
node = stack.pop().right;
}
return sequence;
}
}
复杂度分析
-
时间复杂度: O ( m + n ) O(m + n) O(m+n),其中 m m m 和 n n n 分别是两个二叉树的结点数。对两个二叉树深度优先搜索,每个结点都被访问一次。
-
空间复杂度: O ( m + n ) O(m + n) O(m+n),其中 m m m 和 n n n 分别是两个二叉树的结点数。空间复杂度主要是栈空间和两个二叉树的叶值序列空间。