计算机网络(3) --- 网络套接字TCP_哈里沃克的博客-CSDN博客![]() https://blog.csdn.net/m0_63488627/article/details/132035757?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_63488627/article/details/132035757?spm=1001.2014.3001.5501
目录
1. 协议的基础知识
TCP协议通讯流程
编辑
2.协议
1.介绍
2.手写协议
1.内容
2.接口
3.序列化和反序列化
4.协议化
5.读操作
3.客户端和服务端的业务逻辑
1.服务端
2.客户端
1. 协议的基础知识
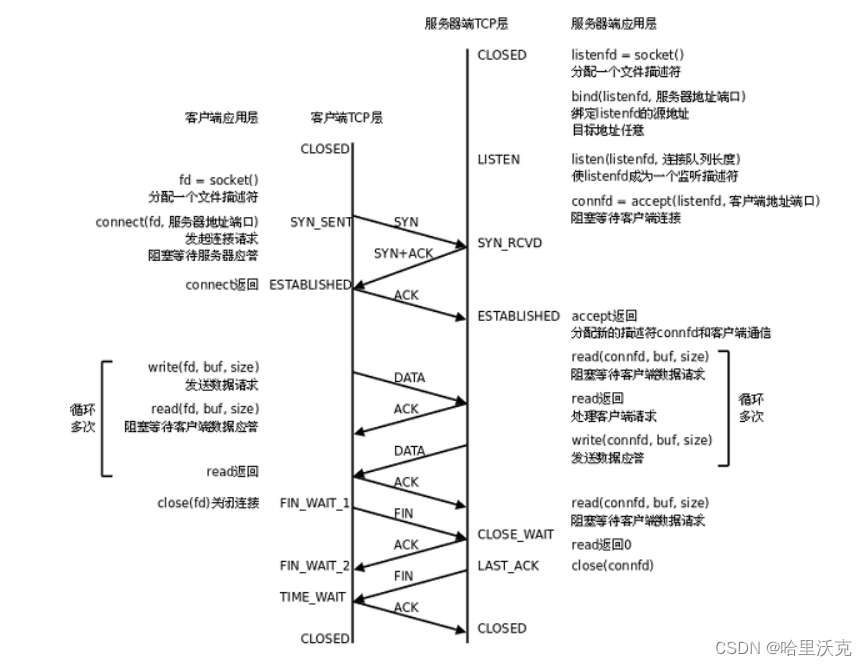
TCP协议通讯流程
1.不论是三次握手四次挥手还是数据的传输,其实都是操作系统进行执行的。那么两边的函数也只是操作系统的调用接口,操作系统依然是整体的执行者
2.那么我们不能简单的认为accept就是构建链接,因为链接的建立是操作系统提供的,accept更多的是以一种接收管理的姿态。那么三次握手有没有aceept其实不大有关系。
3.链接其实是一种结构体,该结构体是用于存储客户端连接服务器时对客户端的描述,毕竟连接服务端的不一定只有一个客户端,只要客户端多起来,就一定需要被管理,那么aceept的作用就是将接收到的链接进行描述管理
2.协议
1.介绍
1.协议是一种 "约定"。 socket api的接口,之前写的套接字在读写数据时, 都是按 "字节流" 的方式来发送接收的。
2.但是我们需要传输一些"结构化的数据",比如图片,视频之类的东西。设计为了这些功能的实现,我们将这些东西对应的字节流组成一个结构体,那么由该结构体存储,只要我们将这些字节流存储到结构体内,随后进行序列化得到一个字节流,之后传入到网络中去。接收方接收,得到的则是一个字节流,反序列化出结构体再将所有的数据拿出来,这样就实现了所有形式的数据都能被一个报文直接转发过来。
3.同时也要保证接收方收到一个完整的报文。udp不需要考虑,因为它面向数据报的;tcp不同,它是传输字节流的,需要考虑。
2.手写协议
1.内容
1.为了保证接收方收到一个完整的报文,我们需要自己设计报文和报文之间的边界。
2.除了物理层都没有返送和接收的直接连接,应用层的数据想要发送,其实这些数据都在应用层的缓冲区中,而发送的过程,其实是像tcp/ip层进行拷贝,把应用层的缓冲区拷贝到tcp/ip层的发送缓冲区,而另一边的主机则是通过tcp/ip层的接收缓冲区拷贝下层传上来的数据。这些数据最终是通过网络发送的。应用层的函数调用write和read接口都是拷贝函数。那考虑最终结果其实呈现出的是:C的发送缓冲区的数据拷贝到S的接收缓冲区,反之亦然。
3.由于两边都拥有发送和接收缓冲区,那么也就意味着两边同时的传输是不影响的,这种工作模式是全双工的
4.发送数据很多,并且对端不处理这些发送过来的数据,难免出现数据扎堆出现在缓冲区中,那么读取这些数据就想要分离出以一个报文为单位的数据。这种划分有三种方法:定长,定特殊符号或者这自描述方法
2.接口
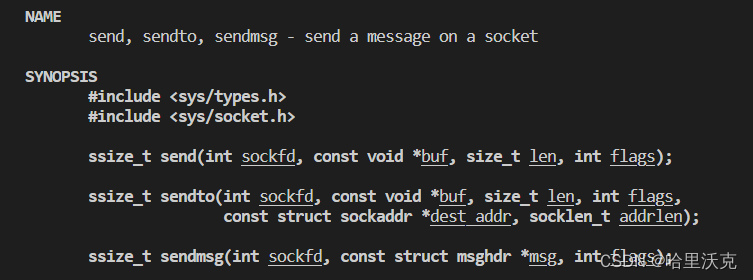
与read的作用一致,都是把字节流发送出去
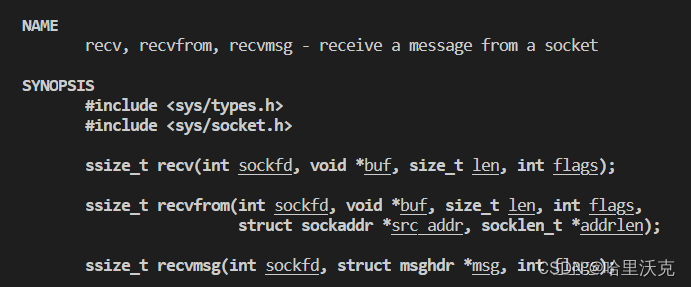
与write的作用一致,都是把字节流接收会来
3.序列化和反序列化
#define SEP " " #define SEP_LEN strlen(SEP) // 不要使用sizeof #define LINE_SEP "\r\n" #define LINE_SEP_LEN strlen(LINE_SEP) // 不要使用sizeof class Request { public: Request() { } Request(int x_, int y_, char op_) : x(x_), y(y_), op(op_) { } bool serialize(std::string *out) { *out = ""; std::string x_string = std::to_string(x); std::string y_string = std::to_string(y); *out = x_string; *out += SEP; *out += op; *out += SEP; *out += y_string; *out += LINE_SEP; } bool deserialize(const std::string &in) { auto left = in.find(SEP); auto right = in.find(SEP); if (left == std::string::npos || right == std::string::npos) return false; if (left == right) return false; if (right - (left + SEP_LEN)) return false; std::string x_string = in.substr(0, left); if (x_string.empty()) return false; std::string y_string = in.substr(right + SEP_LEN); if (y_string.empty()) return false; x = std::stoi(x_string); y = std::stoi(y_string); op = in[left + SEP_LEN]; return true; } public: int x; int y; char op; }; class Response { public: Response() { } Response(int exitcode_, int result_) : exitcode(exitcode_), result(result_) { } bool serialize(std::string *out) { *out = ""; std::string ec_string = std::to_string(exitcode); std::string res_string = std::to_string(result); *out = ec_string; *out += SEP; *out += res_string; *out += LINE_SEP; return true; } bool deserialize(const std::string &in) { auto mid = in.find(SEP); if (mid == std::string::npos) return false; std::string ec_string = in.substr(0, mid); std::string res_string = in.substr(mid + SEP_LEN); if (ec_string.empty() || res_string.empty()) return false; exitcode = std::stoi(ec_string); result = std::stoi(res_string); return true; } public: int exitcode; int result; };基于计算的业务处理逻辑下:
1.request表示请求,即接收方接收的数据
2.response表示应答,即发送方得到接收方处理结果后的数据
3.不论发送还是接收方,其request和response都是想要有序列化和反序列化的。想要注意的是,序列化和反序列化是一种结构化的类型,不表示协议,它是协议的有效载荷部分
4.序列化的逻辑:将当前存储的一系列想要被操作的数据,通过存储在out中。通过分隔符进行组合
5.反序列化的逻辑:接受到了in,将in的数据拆分回原来的结构,拆分的依据就是分隔符
4.协议化
std::string enLength(const std::string &text) { std::string send_string = std::to_string(text.size()); send_string += LINE_SEP; send_string += text; send_string += LINE_SEP; return send_string; } bool deLength(const std::string &package, std::string *text) { auto pos = package.find(LINE_SEP); if (pos == std::string::npos) return false; std::string text_len_string = package.substr(0, pos); int text_len = std::stoi(text_len_string); *text = package.substr(pos + LINE_SEP_LEN, text_len); return true; }1.规定的协议为:当前序列化的字节流长度大小作为前面的一个字节流且用\r\n来进行分隔序列化的字节流,大概模式为XXX\r\nYYY\r\n
2.加协议enLength:就是将传入的text之前算出text的大小,先加入大小后填入分隔符最后加入序列化的字节流
3.减协议deLength:先找到第一个分隔符,得到整个序列化字节流的大小,随后通过大小长度收录整个序列化的字节流
5.读操作
bool recvPackage(int sock, std::string &inbuffer,std::string *text) { char buffer[1024]; while (true) { ssize_t n = recv(sock, buffer, sizeof(buffer) - 1, 0); if (n > 0) { buffer[n] = 0; inbuffer += buffer; auto pos = inbuffer.find(LINE_SEP); if (pos == std::string::npos) continue; std::string text_len_string = inbuffer.substr(0, pos); int text_len = std::stoi(text_len_string); int total_len = text_len_string.size() + 2 * LINE_SEP_LEN + text_len; if (inbuffer.size() < total_len) continue; *text = inbuffer.substr(0, total_len); inbuffer.erase(0, total_len); break; } else return false; } return true; }3.客户端和服务端的业务逻辑
1.服务端
void handerEnter(int sock, func_t func) { std::string inbuffer; while (true) { // 1.读取 // 1.1读取完整的一个报文 std::string req_text; if (!recvRequest(sock, inbuffer, &req_text)) return; // 1.2读取完整的报文 std::string req_str; if (!deLength(req_text, &req_str)) return; // 2.反序列化 // 2.1得到一个结构化的请求对象 Request req; if (!req.deserialize(req_str)) return; // 3.计算业务 // 3.1得到一个结构化的响应 Response resp; func(req, resp); // 4.对响应进行序列化 // 4.1得到一个字符串 std::string resp_str; resp.serialize(&resp_str); // 5.然会发送给客户端一个响应 // 5.1构造新报文 std::string send_string = enLength(resp_str); send(sock, send_string.c_str(), send_string.size(), 0); } }2.客户端
void start() { // 5.要发起链接 struct sockaddr_in server; memset(&server, 0, sizeof server); server.sin_family = AF_INET; server.sin_port = htons(_serverport); server.sin_addr.s_addr = inet_addr(_serverip.c_str()); if (connect(_sock, (struct sockaddr *)&server, sizeof server) != 0) { std::cerr << "connect error: " << errno << " : " << strerror(errno) << std::endl; } else { std::string msg; std::string inbuffer; while (true) { std::cout << "mycal>>> "; std::getline(std::cin, msg); //msg要拆分 Request req(msg); std::string content; req.serialize(&content); std::string send_string = enLength(content); send(_sock, send_string.c_str(), send_string.size(), 0); std::string package, text; if (!recvPackage(_sock, inbuffer, &package)) continue; if (!deLength(package, &text)) continue; Response resp; resp.deserialize(text); std::cout << "exitcode: " << resp.exitcode << std::endl; std::cout << "result: " << resp.result << std::endl; } } }