无人驾驶中的检测框架

2D目标检测的思路
- 位置:先找到所有的ROI (Region of Interest, bounding box may containing object)
- 类别:对每一个ROI做分类获取类别信息
- 位置修正:Bounding box Regression
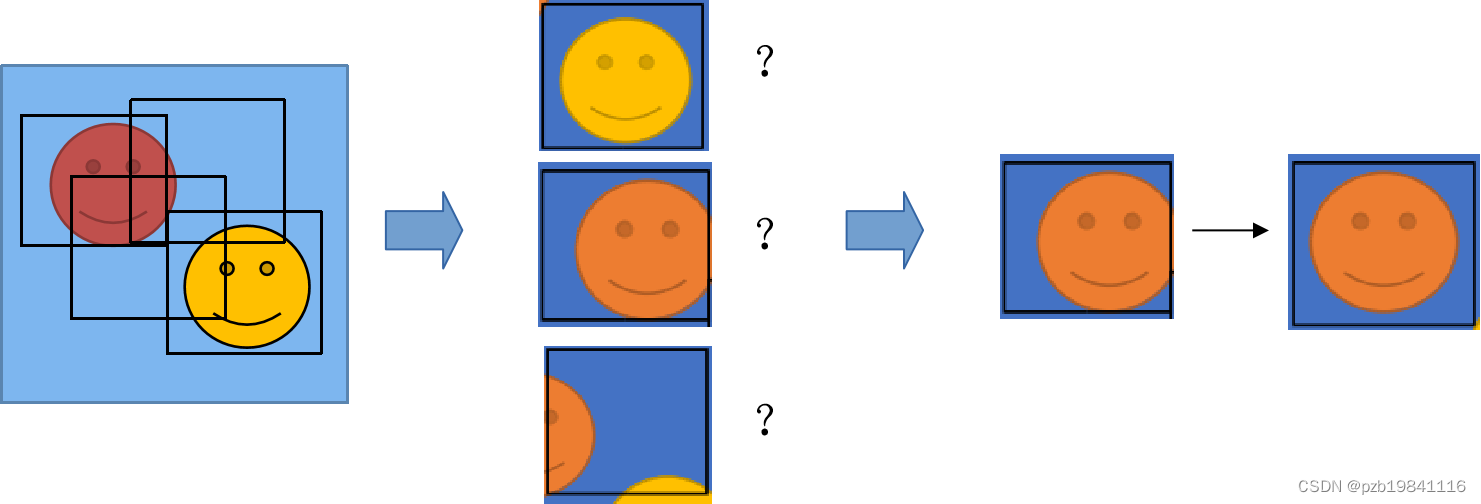
找寻ROI的方法
1.滑窗法。从左到右,从上到下,用不同的尺寸和横款比的窗口滑动。这种方法的效率较低,大量窗口是无效的,仅限于固定尺寸与长宽比的目标,如人脸和行人的检测;
2.候选区域(Region Proposal):通过分割等方法先找到预期对象,再合并相似的对象并拟合边框。可减少大量候选框,提升性能;
3.CNN的方法:用锚框,RPN等方法实现。
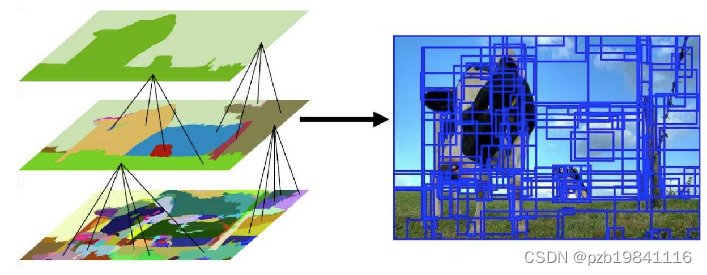
对ROI内容进行分类的方法:
1.提取特征:Haar、LBP、SIFT、SURF、HOG、DPM等,及深度学习CNN中的conv;
2.分类器:SVM、Adaboost及CNN中的Softmax;

CNN之前的方法:
- 位置:sliding window/region proposal
- 类别:HOG/DPM/Haar/SIFT/... + SVM/Adaboost/...
- 位置修正(Bbox Regression): Linear regression/...

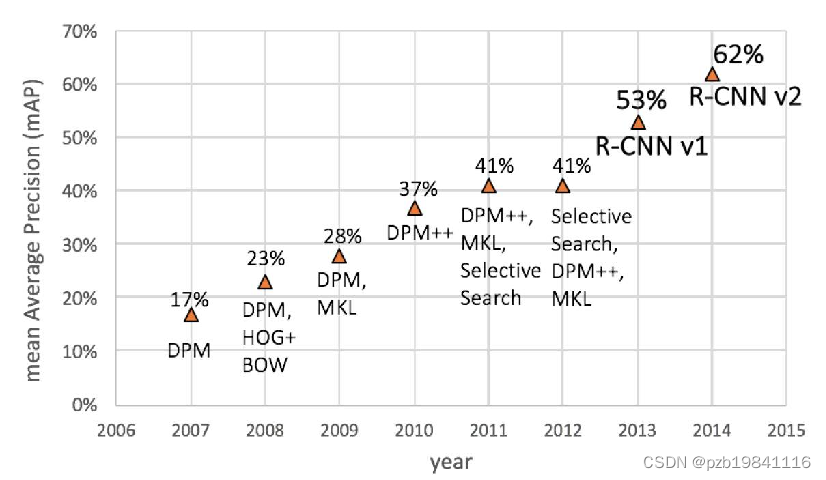
RCNN的方法
- 位置:Selective Search提取候选框
- 类别:CNN提取特征 + SVM分类
- 位置修正:Linear Regression

可以看出先提取候选框,每个候选框过一遍卷积,效率太低。
SPPNet
- 位置:Selective Search提取候选框
- 类别:CNN提取特征 + SVM分类
- 共享卷积:大大降低计算量
- SPP层:不同尺度的特征->固定特尺度特征(后接全链接层)
- 位置修正:Linear Regression


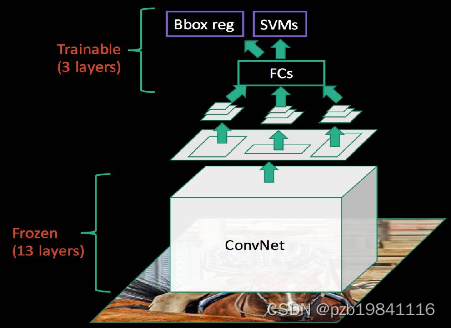
Fast R-CNN
- 位置:Selective Search提取候选框
- 类别:CNN提取特征 + CNN分类
- 分类和回归都用CNN实现:两种损失可以反传以实现联动调参(半end-to-end)
- SPP层->ROI pooling:加速计算
- 位置修正:CNN回归


Faster R-CNN
- 位置:CNN提取候选框
- RPN:Region Proposal Net
- feature点对应的原图感受野框处生成不同ratio/scale的anchor box
- 对anchor box 二分类+回归
- 类别:CNN提取特征 + CNN分类
- 位置修正:CNN回归

k是网格的个数,2k的得分是每个网格二分类,有物体和没有物体,4k是候选框的坐标。

two-step和one-step的方法对比(Faster RCNN 与 YOLO的对比)
- Faster-RCNN: feature点对应的原图感受野框处生成不同ratio/scale的anchor box 从anchor box中提取候选框(二分类+回归) 再对候选框做回归修正
- YOLO: 全图划分成7×7网格,每个网格对应有2个default box 没有候选框! 直接对default box做全分类+回归(box中心坐标的x,y相对于对应的网格归一化到0-1之间,w,h用图像的width和height归一化到0-1之间)

YOLO的特点
- 优点:实时性
- 缺点:准确率不高(不如Faster R-CNN):定位精度差(anchor box不够丰富且只回归修正一次) 小物体差:anchor的scale不够多样 不规则物体差:anchor的ratio不够多样

SSD
- 位置:借鉴RPN的anchor box机制:feature点对应的原图感受野框处生成不同ratio/scale的default box。没有候选框!直接对default box做全分类+回归
- 类别:CNN提取特征 + CNN分类,多感受野特征层输出:前面层感受野小适合小物体,后面层感受野大适合大物体。
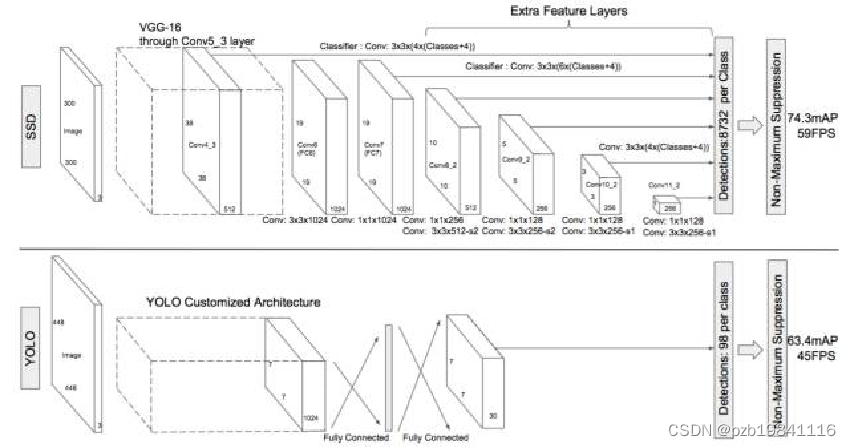
YOLO-V2
- 更丰富的default box,从数据集统计出default box(k-means): 随着k的增大IOU也在增大(高召回率)但是复杂度也在增加.最终选择K=5。可以看出boxj包含一定的先验知识。
- 更灵活的类别预测 把预测类别的机制从空间位置(cell)中解耦,由default box同时预测类别和坐标,有效解决物体重叠

从输出结果可以看出,V2对每个类都进行了分类的评估和边框的拟合。
YOLO-V3
- 更好的基础网络: darknet-19->darknet-53
- 多尺度:感受野多样性/anchor box(default box)多样性
- 多感受野特征层输出:上采样融合之后再输出(借鉴feature pyramid networks) 而SSD是直接输出不融合
- 更多default box: K=9, 被3个输出平分. 3*(5 + 80) = 255 3个box 5(x,y,w,h,confi) 80(coco class)
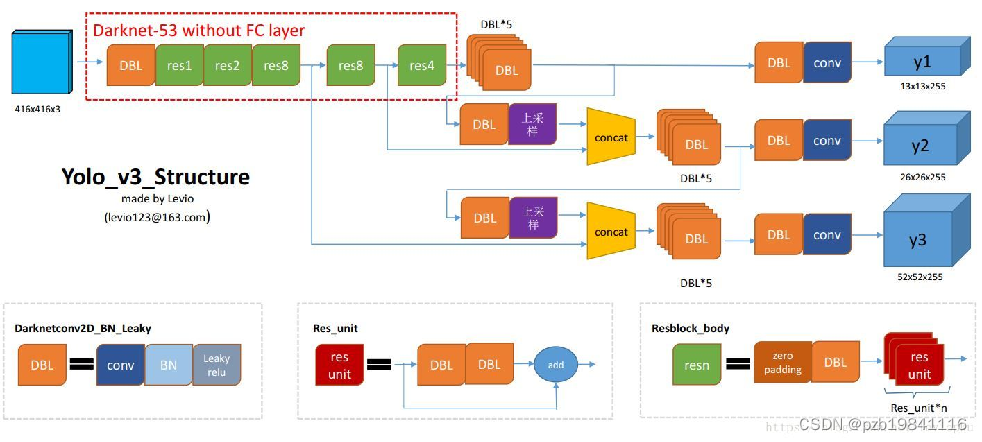
可以看出网络更深了,box也多了。