项目链接
https://github.com/Liu-Yuanqiu/acn_mindspore
项目描述
图像描述生成算法
人类可以轻易的使用语言来描述所看到的场景,但是计算机却很难做到,图像描述生成任务的目的就是教会计算机如何描述所看到的内容,其中涉及到了对视觉信息的处理以及如何生成符合人类语言习惯的语句,这两方面也分别对应的人工智能的两大领域——计算机视觉和自然语言处理。图像描述生成任务不仅仅在算法研究上具有重要的意义,同时在盲人助理、图文转换等实际应用场景也有广泛的应用。
胶囊网络
因为卷积是局部连接和参数共享的,并没有考虑到特征之间的相互关联和相互位置关系,即没有学习到特征之间的位姿信息;胶囊网络同时将空间信息和物体存在概率编码到胶囊向量中,通过动态路由决定当前胶囊输入到哪个更加高级的胶囊,并通过非线性激活函数在归一化的同时保持方向不变,从而使胶囊网络学习到有用的特征以及它们之间的关系。
网络结构
具体来说,图像描述生成算法通常使用编码器-解码器结构,如图1所示,其中编码器部分提取图片的视觉特征,通过多种注意力机制捕获视觉特征之间的关系并生成输出,其中包括了双线性池化模块和注意力胶囊模块,双线性池化模块通过对特征进行挤压-奖励操作获取特征之间的二阶交互,注意力胶囊模块将每一个视觉特征看作一个胶囊,从而捕获特征之间的相对位置关系;解码器部分根据视觉特征通过循环神经网络生成对应单词,解码器使用自回归方式解码,以上一时刻单词作为输入,逐个生成单词组成最终的描述语句。
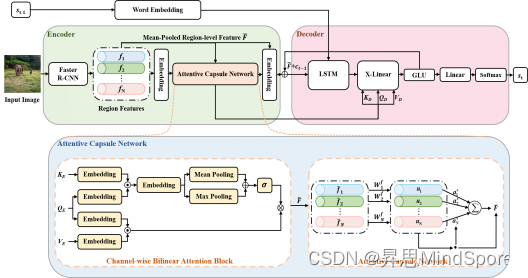
图1 使用胶囊网络的图像描述生成算法框架
算法使用交叉熵损失监督训练,损失函数表示为:
其中表示前i-1步生成的单词,表示图像特征,表示在两者基础上生成本时刻单词的概率。
开发流程
在具体实现过程中,我们先进行数据集适配,然后对网络模型进行开发,之后编写了训练代码。MindSpore拥有良好的基础算子支持和简洁的API接口,不管是底层的矩阵运算还是高层的网络模型封装都可以完美的支持,极大的方便了开发和调试的过程。
数据集适配
因为图像描述生成任务涉及到对图片和文本的处理,因此训练数据的格式也具有多种类型,其中图像特征是使用Faster RCNN预处理好的矩阵,词表以txt文件存储,描述语句使用数组进行存储,因此我们使用自定义数据集来生成训练批次,首先定义一个数据类,类中实现__getitem__作为可迭代对象返回数据,使用GeneratorDataset组装数据类,从而进行混洗和抽取批次。
coco_train_set = CocoDataset(image_ids_path = os.path.join(args.dataset_path, 'txt', 'coco_train_image_id.txt'),
input_seq = os.path.join(args.dataset_path, 'sent', 'coco_train_input.pkl'),
target_seq = os.path.join(args.dataset_path, 'sent', 'coco_train_target.pkl'),
att_feats_folder = os.path.join(args.dataset_path, 'feature', 'up_down_36'),
seq_per_img = args.seq_per_img,
max_feat_num = -1)
dataset_train = ds.GeneratorDataset(coco_train_set,
column_names=["indices", "input_seq", "target_seq", "att_feats"],
shuffle=True,
python_multiprocessing=True,
num_parallel_workers=args.works)
dataset_train = dataset_train.batch(args.batch_size, drop_remainder=True)网络模型开发
网络模型均使用nn.Cell作为基类进行开发,根据网络中模型的不同功能实现了模型整体类CapsuleXlan、编码器Encoder和解码器Decoder等等,其中涉及到线性层、激活层、矩阵操作、张量操作等等,具体网络结构定义如下。
其中CapsuleXlan中包含了Encoder和Decoder,通过Encoder编码视觉信息,通过Decoder生成描述语句;Encoder中包含多层CapsuleLowRankLayer,每一层CapsuleLowRankLayer对特征进行处理后输入Capsule进行计算,结果处理后返回上一层;对于Decoder来说同理。
对于具体的运算,以Decoder为例,首先我们定义子层和对应的线性层,提前需要使用的算子操作,然后在construct中使用预先定义的各个层对输入进行处理,计算结果经过线性层和层归一化后返回。
class Decoder(nn.Cell):
def __init__(self, layer_num, embed_dim, att_heads, att_mid_dim, att_mid_drop):
super(Decoder, self).__init__()
self.decoder = nn.CellList([])
for _ in range(layer_num):
sublayer = LowRankLayer(embed_dim=embed_dim, att_heads=8,
att_mid_dim=[128, 64, 128], att_mid_drop=0.9)
self.decoder.append(sublayer)
self.proj = nn.Dense(embed_dim * (layer_num + 1), embed_dim)
self.layer_norm = nn.LayerNorm([embed_dim])
self.concat_last = ops.Concat(-1)
def construct(self, gv_feat, att_feats, att_mask):
batch_size = att_feats.shape[0]
feat_arr = [gv_feat]
for i, decoder_layer in enumerate(self.decoder):
gv_feat = decoder_layer(gv_feat, att_feats, att_mask, gv_feat, att_feats)
feat_arr.append(gv_feat)
gv_feat = self.concat_last(feat_arr)
gv_feat = self.proj(gv_feat)
gv_feat = self.layer_norm(gv_feat)
return gv_feat, att_feats
同时,对交叉熵损失进行实现并将其和网络模型组装到一个类中:
class CapsuleXlanWithLoss(nn.Cell):
def __init__(self, model):
super(CapsuleXlanWithLoss, self).__init__()
self.model = model
self.ce = nn.SoftmaxCrossEntropyWithLogits(sparse=True)
def construct(self, indices, input_seq, target_seq, att_feats):
logit = self.model(input_seq, att_feats)
logit = logit.view((-1, logit.shape[-1]))
target_seq = target_seq.view((-1))
mask = (target_seq > -1).astype("float32")
loss = self.ce(logit, target_seq)
loss = ops.ReduceSum(False)(loss * mask) / mask.sum()
return loss训练
class CapsuleXlan(nn.Cell):
def __init__():
self.encoder = Encoder()
self.decoder = Decoder()
class Encoder(nn.Cell):
def __init__():
self.encoder = nn.CellList([])
for _ in range(layer_num):
sublayer = CapsuleLowRankLayer()
self.encoder.append(sublayer)
class Decoder(nn.Cell):
def __init__():
self.decoder = nn.CellList([])
for _ in range(layer_num):
sublayer = LowRankLayer()
self.decoder.append(sublayer)
class CapsuleLowRankLayer(nn.Cell):
def __init__():
self.attn_net = Capsule()
class LowRankLayer(nn.Cell):
def __init__():
self.attn_net = SCAtt()
class SCAtt(nn.Cell):
def __init__():
class Capsule(nn.Cell):
def __init__():数据集和网络模型都已经准备完毕,在训练过程中只需要将模型、优化器、数据集、回调函数装配起来即可,在这里我们首先定义优化器,使用Adam优化器进行优化,然后定义回调函数,使用LossMonitor、TimeMonitor、ModelCheckpoint和SummaryCollector分别监听损失函数、计算每一步所用时间、保存模型以及保存可视化数据。最终使用nn.Model将四部分装配在一起进行训练,并可以通过MindInsight观察训练损失和参数的变化。
net = CapsuleXlan()
net = CapsuleXlanWithLoss(net)
warmup_lr = nn.WarmUpLR(args.lr, args.warmup)
optim = nn.Adam(params=net.trainable_params(), learning_rate=warmup_lr, beta1=0.9, beta2=0.98, eps=1.0e-9)
model = ms.Model(network=net, optimizer=optim)
loss_cb = LossMonitor(per_print_times=1)
time_cb = TimeMonitor(data_size=step_per_epoch)
ckpoint_cb = ModelCheckpoint(prefix='ACN',
directory=os.path.join(args.result_folder, 'checkpoints'))
summary_cb = SummaryCollector(summary_dir=os.path.join(args.result_folder, 'summarys'))
cbs = [loss_cb, time_cb, ckpoint_cb, summary_cb]
model.train(epoch=args.epochs, train_dataset=dataset_train, callbacks=cbs)




![[附源码]Python计算机毕业设计SSM基于的冠状病毒疫情防控资讯交流推荐网站(程序+LW)](https://img-blog.csdnimg.cn/c8f24948235b44859154bbbf041279dd.png)