一、说明
深度学习(DL)很难训练,强化学习(RL)要差得多。在早期开发中,遵循与 DL 相同的策略:保持简单!消除任何妨碍您的花里胡哨的东西,并将不确定性降至最低。具体到RL,
- 对于新模型和算法,请选择简单的玩具实验进行早期开发。
- 首先简化问题,以便我们可以轻松快速地运行实验。
- 对超参数调优有耐心。RL 对超参数非常敏感(比 DL 更差)。
- 尝试不同的随机种子。
着眼低处。始终从有效的事物开始工作。
设置引用
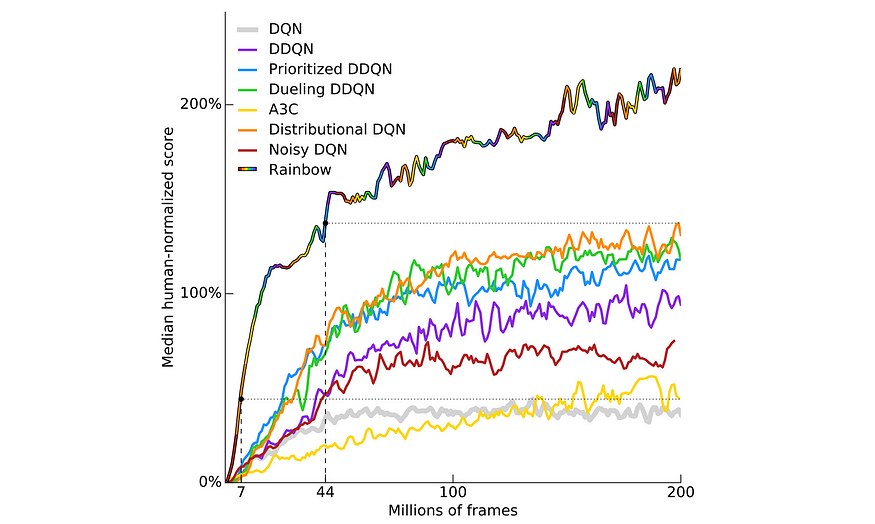
许多无模型算法在显示任何进展迹象之前都有很长的预热期。通常,他们需要数百万次迭代才能看到一些有希望的举措。为了解决不确定性,一种有效的方法是熟悉使用其他强化学习方法的玩具实验。然后我们使用它们来交叉引用我们的进度。例如,在培训的这个时候,动作或奖励看起来是否正常?作为下面的示例,该图显示了在 57 款雅达利游戏中使用不同 DQN 方法的汇总训练进度。这为我们提供了一些关于何时继续训练以及何时开始调试开发类似 DQN 的方法的指南。
源
输入要素
首先使任务更容易解决。如果从原始像素中学习速度很慢,请先使用手工制作的功能。例如,使用从机器人手臂或观察到的物体位置收集的状态,而不是从原始像素进行推断。图像的高维性大大增加了问题的复杂性。雅达利游戏的游戏规则相对简单,在提取通用特征方面与CNN网络配合良好。这可能不适用于其他 RL 任务。
二、RL 不完全是深度学习
不幸的是,深度学习中的许多成功,如监督学习,在强化学习中并不容易复制。让我们介绍一些问题。
I.I.D.
DL 和 RL 之间的一个主要区别是其训练输入的数据分布。在深度学习中,我们对输入进行随机化,使得每批训练数据都包含不同类别对象的良好平衡,并且每个样本都相互独立。我们无法从之前的样本中预测接下来可能会看到什么。

我们称之为i.i.d.(独立且相同分布)。我们希望样本分布相同。即每批样品的数据分布应相似。下面,所有示例都来自同一类。它的输入数据分布强烈偏向于对象类“0”。因此,它不是 i.i.d。
![]()
此示例批次不利于监督学习。我们不需要学习任何功能。相反,我们可以简单地将输出预测为“0”,而不考虑输入,以减少训练损失。
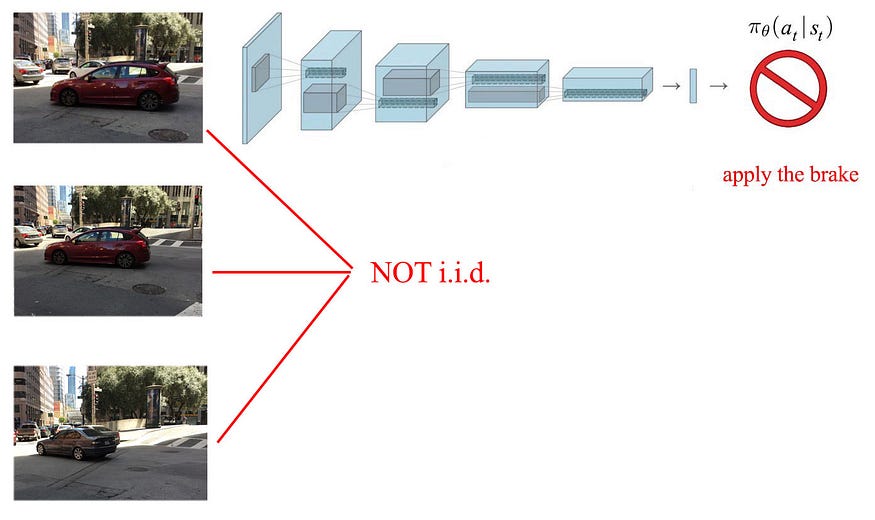
RL 中基于策略的方法
RL 中的样本可以在同一训练批次中高度相关。探索的空间在很大程度上取决于当前的政策。正如我们所知道的那样,我们改变了探索的地方。因此,跨批次的输入数据分布在不断发展。批次之间的训练样本分布不相同。此外,对于价值学习方法,输出目标值正在发生变化,因为我们对事物的了解越来越多。RL远未达到i.i.d。这是一场噩梦,给RL带来了一些重大挑战:
- 批处理规范化和 dropout 方法可能不适用于 RL。
- 很难调整学习率以实现适当的收敛。因此,我们需要更高级的优化器,如 AdamW 或 RMSProp。对于策略梯度方法,请查看利用信任区域的 PPO 等方法。
- 我们需要减缓输入和输出的变化,让它们有机会让模型学习和发展。
过拟合数据与过拟合任务
在 DL 中,我们使用正则化来避免过度拟合数据。对于RL,我们需要在更高的层次上思考。
首先,我们需要用许多场景来训练系统。例如,要训练机器人在室内飞行,我们应该创建尽可能多的房间和家具配置。为了最大化此类场景,我们可能需要创建仅用于训练目的的合成数据。

源
多样性总是有帮助的!以下视频训练具有不同地形和障碍物的多种类型的对象。随着环境变得越来越多样化,我们可能会认为不可能很好地训练模型。但相反,它避免了过度拟合特定任务,并开始探索所有这些场景下的复杂行为。因此,复杂的环境增强了培训,而不是阻止了培训。但如前所述,我们应该在早期开发中保持绝对简单。像这样的建议应该在编码首先完全调试后完成。
其次,使用不同的任务训练模型。
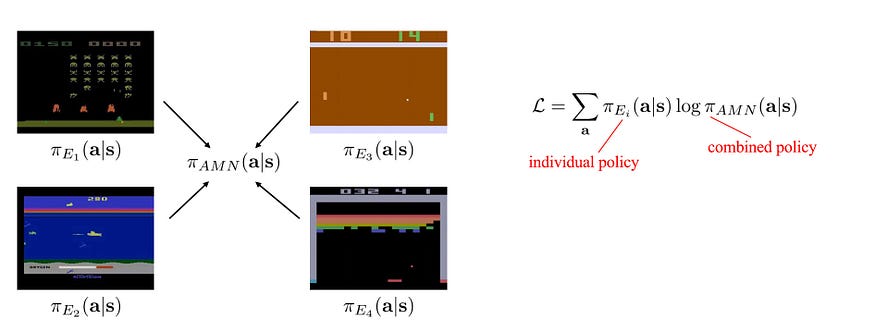
对于雅达利太空入侵者游戏,当外星人向我们开火时,我们会逃跑。如果我们只用这个游戏进行训练,我们的解决方案将无法很好地泛化。例如,在乒乓球比赛中,我们想击球但不逃跑。通过多项任务的培训,我们获得了更好、更基础的知识。当一个物体接近时,我们应该得到警报。但根据具体情况,我们的行为有所不同。例如,在吃豆人游戏中,我们想逃离幽灵。但是当我们只是捕获能量丸时,我们会追逐幽灵并吃掉它们。
不要过度拟合任务。训练许多任务,以对事物的工作原理有基本的了解。
DQN论文使用ε贪婪策略,即使在测试期间ε也等于0.05,以避免过度拟合。
通常,我们可以为环境过度拟合任务。但是,如果不使用其他方案和任务进行验证,高度优化的解决方案不太可能在其他情况下工作。因此,在没有此类验证的情况下,不要提交大量的超参数优化。将设计定位为对超参数不太敏感。超敏感超参数通常不能很好地泛化。
越大不一定越好
我们不能盲目地增加深度网络的容量,因为它有过度拟合的风险。在 DL 中处理过拟合和爆炸梯度问题的解决方案可能不适用于 RL。
基于模型的 RL 需要较少的样本来训练,并且特别容易受到过度拟合的影响。因此,这些模型需要简单得多。不幸的是,这限制了模型的表现力,并创造了次优解决方案的机会。
在RL中,瓶颈通常在于样品效率、稳定性和收敛性。因此,设计一个强大而富有表现力的网络可能是第二要务。如果您没有耐心调整模型,则尤其如此。
局部优化
RL的局部最优比DL严重得多。在下面的视频中,一旦半只猎豹被卡在倒置的位置,即使它可以跑得更快,它也无法再次向上行走。
首先,我们可以尝试不同的随机种子。不同的随机种子可能会达到不同的局部最优值。通过简单地更改随机种子,我们可以获得非常不同的性能结果。如下所示,以下性能之间的差异仅来自随机种子。不要低估它的影响!许多跑步的奖励可能只是因为随机种子。
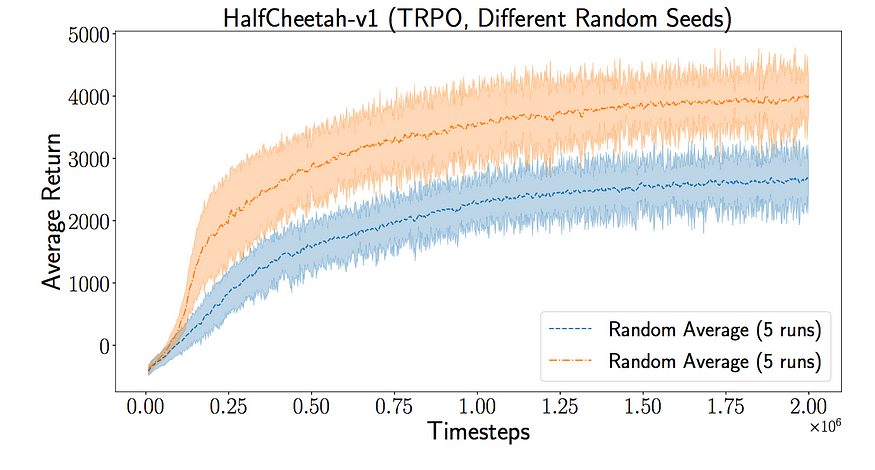
平均两组5个不同的随机种子。源
始终使用不同的随机种子在多个任务上测试算法或模型。
其次,在训练中尝试更好的探索方案。半猎豹问题表明我们的探索太短视。增加勘探与开发的机会。
第三,鼓励行动的多样性,以便我们可以从局部最优中脱颖而出。例如,在目标函数中添加激励,以鼓励操作的更高熵。
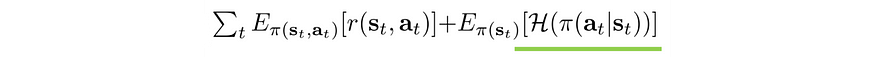
它还有助于我们更好地适应环境变化或摆脱僵局。
源
超参数调优
许多RL方法的收敛性远不如DL。在某些强化学习方法中,例如使用深度网络近似器进行价值学习,训练可能不稳定。为了解决这些缺点,我们在目标函数中添加了新的激励或惩罚。
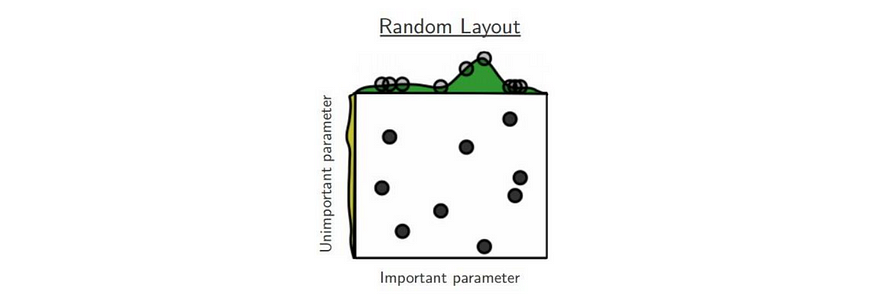
一般来说,我们在 RL 中比在 DL 中需要更多的耐心。通常,RL 方法处理范围很窄的超参数,需要大量搜索才能找到它们。这就是为什么,如前所述,设置一些参考点很重要。对于超参数搜索,可以使用随机布局(即随机搜索参数),特别是对于高维空间。
鲁棒性
不要对单个任务结果过于自信或悲观,除非改进不寻常。很难找到一种 RL 方法在所有任务中都能很好地工作。DQN擅长Atari游戏,但在CartPole等连续控制方面表现不佳。如果一个人在一项任务中表现不佳,并不意味着它会让其他人失望,反之亦然。
从简单的玩具实验开始。如果没有进展,请切换到其他人。之后,尝试中等大小的问题。构建实验以证明算法擅长什么并分析弱点。
以前,我们建议耐心调整超参数。这总是造成一个两难的境地,即我们是否应该进一步调整模型或尝试新的东西。更好的方法是自动化基准测试过程,以便可以并行测试和验证结果。
继续在不同任务中对算法进行基准测试。
三、重塑奖励功能
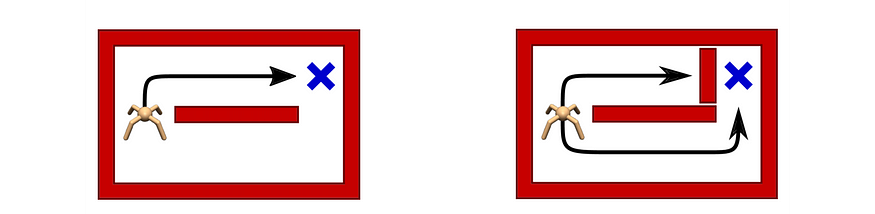
重新制定奖励函数,使其提供恒定且更好的中间反馈。例如,与其在对象到达目标时才给予奖励,不如建立更精细的目标。例如,当抓手靠近球时给予奖励。这提供了更多的学习信号来帮助培训。
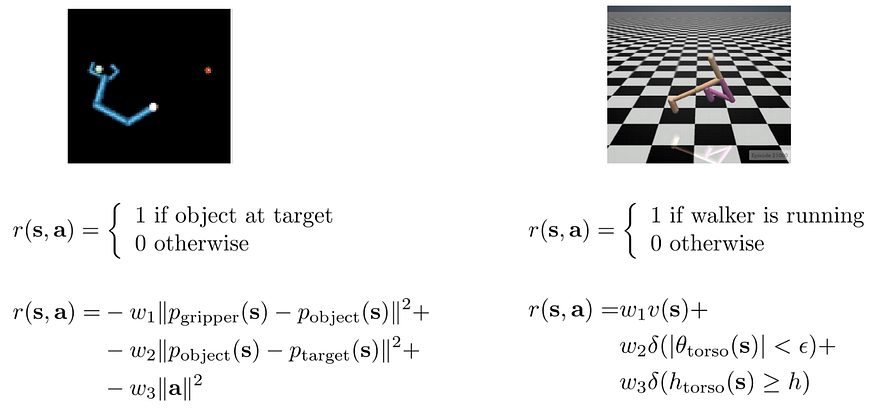
但重塑奖励函数可能会导致次优解决方案。在下面的视频中,它不是完成课程以获得大奖,而是永远循环收集 Turbo 奖励。所以一定要小心!就像深度学习一样,系统可能学到的东西可能会是一个很大的惊喜。因此,请花点时间评估它在新的奖励函数下试图实现的目标。
四、可行性研究
当我们对图像进行降采样或降低采样频率时,信息将丢失。我们可以自己查看图像,以确保它保留足够的信息来解决问题。如果我们不能解决它,RL 方法可能也不是。此外,对问题运行随机策略。检查我们是否偶尔会看到一些所需的行为模式。
4.1 数据预处理
与 DL 类似,我们希望输入特征以零为中心。应用
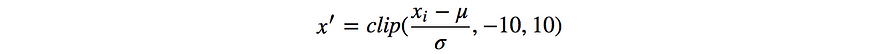
以剪辑大纲视图并标准化输入。对到目前为止看到的所有数据的μ和σ使用运行估计值。不要只使用一批样本来计算它们。同一批次中的样品在RL中高度相关。计算值不表示平均值和标准差。我们可能还希望标准化预测。但是,对于奖励,只需重新调整它,不要改变平均值。
4.2 监测
像DL一样,人们倾向于在收集足够的信息之前采取行动。验证猜测需要很长时间,根据我的经验,得出了许多错误的结论。为公平比较创建一个控制良好的环境并不明显。例如,我们将从不同的随机种子中获得不同的结果。因此,一些观察很容易误导我们。根据数据做出有根据的猜测。请务必先复制并验证您的信息。
在 RL 中,我们应该监控(如果适用):
- 值函数,
- 平均奖励,
- 国家访问与分配,
- 策略分布,
- 梯度范数,
- 参数更新中的大小,
- 目标值变化,
- 策略熵,以及
- KL-新政策与现行政策的分歧。
在直方图中可视化输入要素、输出和奖励。验证比例以及其是否正确居中。识别并删除任何异常值。
可视化一段时间内的数据和指标。绘制所收集数据的直方图。
识别任何不当行为,如参数振荡、梯度爆炸/消失和非平滑值函数。检查价值函数(如果适用)是否很好地预测了实际奖励。将结果与策略梯度等基线方法和 Q 学习(如 OpenAI 基线存储库中的方法)进行比较。
监控培训进度
监控剧集返回的最小/平均值/最大值/标准偏差。后期训练中的大方差意味着训练不稳定。剧集时间是衡量进度的另一种方式。即使你每次都可能输,但更长的情节意味着你正在进步。
4.3 调音
接下来,我们将讨论如何专门调整一些参数。
批大小/缓冲区大小
RL 通常使用比 DL 更大的批大小。较大的方差会破坏训练的稳定性,因此我们使用大批量来消除方差。如果学习没有进展,则增加批量大小。雅达利游戏上的 TRPO 的批量大小为 100K。
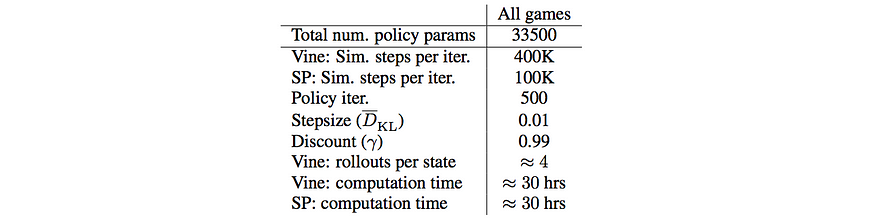
Source
对于 Atari 上的 DQN,当前网络和目标网络之间的更新频率为 10K,重放缓冲区大小为 1M 过渡帧。如果缓冲区大小的批大小不够大,则噪声将压倒训练。较大的批大小将提高性能,但会减慢计算速度。
折扣系数γ
γ需要足够大才能收集奖励。例如,如果 γ=0.99,它将忽略 100 个时间步之外的奖励。但是,如果奖励更频繁地给予,γ可能会更低。
如果使用TD(λ)来计算奖励,我们可以对γ使用更高的值。λ 值将 TD 与蒙特卡罗混合以减少方差。蒙特卡洛没有偏差,但方差很大。另一方面,TD具有高偏差但低方差。当λ从0减少到零时,我们向TD移动而不是蒙特卡洛。在实践中,我们主要希望蒙特卡洛结果,并得到TD的一些小帮助。在本文中,其中一个玩具实验在γ为98.0且λ为96.<>时达到最佳性能。
动作频率
我们不需要更改每个视频帧的操作。我们可以在采取下一步行动之前跳过帧。但我们需要首先用真正的玩家来验证它的影响。如果人类很难跳过这么多帧,那么程序可能会遇到类似的困难。
跳过帧实际上增加了探索。对于跳过帧,我们不会每次都遵循脚本(策略)。当我们跳过更多帧时,我们会探索更多。我们希望调整此值以查看探索可能如何进行。
五、消融
许多设计修改具有类似的效果,并且变得多余。例如,许多方法具有规范化输入或使优化更稳定的效果。逐个删除它们以简化设计(如果它没有显示性能下降)。简单的设计将更好地概括其他任务。
5.1 策略梯度训练提示
熵
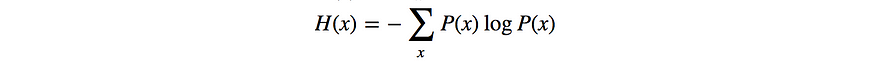
密切监控策略熵。
熵是随机性的度量。高熵与高随机性有关。如果熵很低,则策略非常确定,几乎没有探索。这对早期训练不利。开始时不应太低,结尾不应过高。如果训练过早地崩溃为确定性策略,则在目标中添加熵奖励以鼓励探索。我们还可以限制熵下降(可能通过信任区域),以避免策略中的激进更改。
KL-背离
激进的政策变化会增加做出错误决策的机会。密切监测新旧政策之间的KL分歧。将它们与使用既定方法的玩具实验进行比较。KL-散度为 0.01 是合理的,10 是异常的。对于较大的KL背离或较大的峰值,引入更大的KL背离惩罚。
监控KL背离。
解释方差
在许多情况下,我们尝试使用与基本事实相同的平均值进行预测,但也使用相同的方差。为了实现这一目标,我们需要引入一个名为解释方差的新指标。
解释的方差定义为:
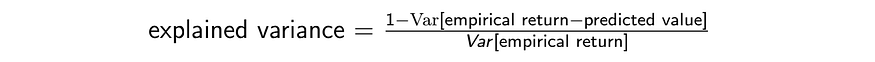
假设预期回报(经验回报)以零为中心,方差为 1。如果模型在任何情况下持续预测零,则上述解释的方差为零。对于性能不佳的模型,解释的方差可能是负的。相反,如果我们的预测当场是正确的,那么解释的方差在我们的示例中将是一个。因此,请密切监视它。
解释方差衡量我们的价值函数估计有多好。
策略初始化
策略模型的参数初始化甚至比监督学习更重要。它决定了我们如何探索环境。在AlphaGo中,它使用监督学习来预先训练策略。尽管它后来在AlphaGO Zero中被删除,但它显示了领先一步如何帮助我们推进项目。应用过去的经验,例如通过迁移学习,可能会在项目开发中消除很多未知数。这可以有很大帮助。
但是,当此类帮助不可用时,策略的最终层输出应为零或非常接近零。它最大化了熵和探索,而不是偏爱采取什么行动。
5.2 Q学习技巧
对于 Q 学习,请调整以下区域:
- 体验重放内存缓冲区大小:Q 学习可以使用大型体验回放来稳定训练。DQN纸张存储了Atari游戏的最后1万帧视频帧。值得对缓冲区大小进行一些实验,但要注意总内存消耗。
- 学习率时间表(学习率如何随时间衰减)。
- 探索时间表(例如贪婪ε方法中的ε)。从高探索开始,逐渐减少。
与策略梯度方法相比,Q学习需要更多的耐心。DQN收敛缓慢,开始时预热期很长,没有进展的迹象。在更简单的任务上测试实现,以证明代码首先正常工作。在 Atari 游戏中,需要 10-40M 帧才能找到看起来比随机操作更好的策略。此外,当使用深度网络逼近器时,价值学习方法无法保证收敛。它往往对超参数更敏感,通常需要广泛的搜索。
5.3 演职员表和参考资料
约翰·舒尔曼关于“深度强化学习研究的具体细节”的演讲
加州大学伯克利分校深度强化学习
加州大学伯克利分校深度RL训练营
大卫·西尔弗 UCL RL 课程
资源
Sutton&Barto,强化学习:简介
Dimitri Bertsekas,动态规划和优化控制
Martin Puterman,马尔可夫决策过程:离散随机动态规划
许志永