声明:该系列文章首发于公众号:Y1X1n安全,转载请注明出处!本公众号所分享内容仅用于每一个爱好者之间的技术讨论及教育目的,所有渗透及工具的使用都需获取授权,禁止用于违法途径,否则需自行承担,本公众号及作者不承担相应的后果。

文章目录
- 常用命令
- Tips
- 详细参数
- 详细用法示例
- -e 限定扫描后缀,如php\html\jsp等
- -r 递归,如果找到/admin会递归爆破/admin/*
- --max-recursion-depth 设置最大递归扫描深度
- --recursion-status 设置递归状态代码
- 强制递归
- -t 线程数
- 前缀/后缀
- --prefixes 为所有条目添加自定义前缀
- --suffixes 为所有条目添加自定义后缀
- 黑名单
- 过滤器:通过状态码、大小、文本、正则、重定向、特定响应内容等
- 排除扩展名
- 扫描子目录
- 代理
- 报告
- 关于字典
- 配置文件
常用命令
python dirsearch.py -u https://target --exclude-status 404,500 -r 2 --recursion-status 200-399
# 排除404,500,递归深度2,递归扫描的有效状态码200-399
python dirsearch.py -l target.txt --crawl --random-agent
# -l 批量扫描,在响应中爬取新路径,为每个请求选择一个随机用户代理
ctrl+c
# 暂停
python dirsearch.py -l target.txt -t 50 -o dir-result.txt --exclude-status 404,500
# 批量扫描,指定线程50,输出txt,排除404,500
python dirsearch.py -l target.txt -t 50 -o dir-result.txt --exclude-status 404,500 -r --recursion-status 200-399
# 批量扫描,指定线程50,输出txt,排除404,500,递归扫描的有效状态码200-399
python dirsearch.py -u https://target.com --exclude-status 403,404,500 -r 2 --recursion-status 200-399 --crawl --random-agent --subdirs /,cfgc/,collect/,userServer/,wealth/
# 扫描子目录(默认会扫描/)
python dirsearch.py -u https://target.com --exclude-status 403,404,500 -r 2 --recursion-status 200-399 --crawl --random-agent --subdirs /,cfgc/,collect/ -t 100 -w D:\Tool\dirsearch\dirsearch-master-20230714\db\sensitive_directory_dic.txt --log ./test_log.txt
# -w 指定字典 --log输出日志
【额外部分用法】
cat urls.txt | python3 dirsearch.py --stdin
# 从urls.txt文件中读取目标URL,并通过stdin输入传递给dirsearch。这样可以批量扫描urls.txt里的多个URL。
python3 dirsearch.py -u https://target --max-time 360
# 设置单个目标URL,并使用--max-time参数设置最长扫描时间为360秒。
python3 dirsearch.py -u https://target --auth admin:pass --auth-type basic
# 扫描设置basic认证,用户名为admin,密码为pass。可以用于测试需要认证的目录。
python3 dirsearch.py -u https://target --header-list rate-limit-bypasses.txt
# 使用--header-list参数从rate-limit-bypasses.txt文件中读取请求头,用来绕过防护的速率限制。
Tips
- 服务器有请求限制?这不好,你可以用–proxy-list随机代理来绕过它。
- 想找配置文件或备份吗?试试–suffixes ~ 和 --prefixes . 。
- 只想找文件夹/目录?可以结合使用 --remove-extensions 和 --suffixes /!。
- 混合使用–cidr、-F、-q可以最大限度减少CIDR暴力破解时的噪音和误报。
- 要扫描一批URL,但不想看到429错误洪水? --skip-on-status 429可以在遇到429时跳过目标。
- 服务器含有大文件导致扫描缓慢?可以用HEAD方法代替GET。
- CIDR暴力破解速度慢?可能忘了减小超时和重试次数了。建议:–timeout 3 --retries 1。
详细参数
选项
用法:dirsearch.py [-u|--url] 目标 [-e|--extensions] 扩展名 [选项]
选项:
--version 显示程序的版本号并退出
-h, --help 显示此帮助消息并退出
必选:
-u URL, --url=URL 目标URL,可以使用多个标志
-l PATH, --url-file=PATH URL列表文件
--stdin 从标准输入读取URL
--cidr=CIDR 目标CIDR
--raw=PATH 从文件加载原始HTTP请求(使用“--scheme”标志设置方案)
-s 会话文件, --session=会话文件
--config=PATH 配置文件路径(默认值:“DIRSEARCH_CONFIG”环境变量,否则为“config.ini”)
字典设置:
-w 单词表, --wordlists=单词表 自定义单词表(用逗号分隔)
-e 扩展名, --extensions=扩展名
扩展名列表,用逗号分隔(例如php,asp)
-f, --force-extensions
在每个单词表条目的末尾添加扩展名。默认情况下,dirsearch仅替换%EXT%关键字
-O, --overwrite-extensions
用您的扩展名(通过`-e`选择)覆盖单词表中的其他扩展名
--exclude-extensions=扩展名
排除扩展名列表,用逗号分隔(例如asp,jsp)
--remove-extensions
在所有路径中删除扩展名(例如admin.php -> admin)
--prefixes=前缀
在所有单词表条目添加自定义前缀(用逗号分隔)
--suffixes=后缀
在所有单词表条目添加自定义后缀,忽略目录(用逗号分隔)
-U, --uppercase 单词表大写
-L, --lowercase 单词表小写
-C, --capital 单词表首字母大写
常规设置:
-t 线程数, --threads=线程数
线程数
-r, --recursive 递归暴力破解
--deep-recursive 对每个目录深度执行递归扫描(例如api/users -> api/)
--force-recursive 对找到的每个路径进行递归暴力破解,不仅仅是目录
-R 深度, --max-recursion-depth=深度
最大递归深度
--recursion-status=CODES
执行递归扫描的有效状态码,支持范围(用逗号分隔)
--subdirs=子目录
扫描给定URL的子目录(用逗号分隔)
--exclude-subdirs=子目录
在递归扫描期间排除以下子目录(用逗号分隔)
-i 代码, --include-status=代码
包含状态码,用逗号分隔,支持范围(例如200,300-399)
-x 代码, --exclude-status=代码
排除状态码,用逗号分隔,支持范围(例如301,500-599)
--exclude-sizes=大小
按大小排除响应,用逗号分隔(例如0B,4KB)
--exclude-text=文本
通过文本排除响应,可以使用多个标志
--exclude-regex=正则表达式
通过正则表达式排除响应
--exclude-redirect=字符串
如果此正则表达式(或文本)与重定向URL匹配,则排除响应(例如'/index.html')
--exclude-response=路径
排除与此页面的响应类似的响应,路径作为输入(例如404.html)
--skip-on-status=代码
每当命中这些状态码之一时跳过目标,用逗号分隔,支持范围
请求设置:
-m 方法, --http-method=方法
HTTP方法(默认值:GET)
-d 数据, --data=数据
HTTP请求数据
--data-file=路径 包含HTTP请求数据的文件
-H 标头, --header=标头
HTTP请求标头,可以使用多个标志
--header-file=路径 包含HTTP请求标头的文件
-F, --follow-redirects
跟随HTTP重定向
--random-agent 为每个请求选择一个随机用户代理
--auth=凭据 认证凭据(例如user:password或bearer token)
--auth-type=类型 认证类型(basic,digest,bearer,ntlm,jwt,oauth2)
--cert-file=路径 包含客户端证书的文件
--key-file=路径 包含客户端证书私钥(未加密)的文件
--user-agent=用户代理
--cookie=Cookie
连接设置:
--timeout=超时 连接超时
--delay=延迟 请求之间的延迟
--proxy=代理 代理URL(HTTP/SOCKS),可以使用多个标志
--proxy-file=路径 包含代理服务器的文件
--proxy-auth=凭据 代理身份验证凭据
--replay-proxy=代理 重放找到的路径的代理
--tor 将Tor网络用作代理
--scheme=方案 原始请求的方案,如果URL中没有方案则使用该方案(默认值:自动检测)
--max-rate=速率 每秒最大请求数
--retries=重试次数 失败请求的重试次数
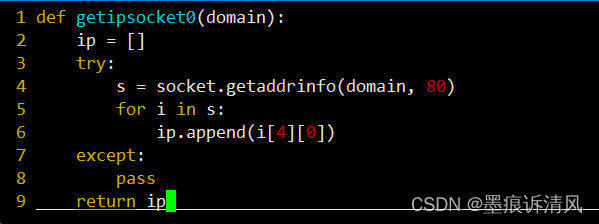
--ip=IP 服务器IP地址
高级设置:
--crawl 在响应中爬取新路径
查看设置:
--full-url 在输出中显示完整的URL(在安静模式下自动启用)
--redirects-history
显示重定向历史记录
--no-color 无彩色输出
-q, --quiet-mode 安静模式
输出设置:
-o 路径, --output=路径
输出文件
--format=格式 报告格式(可用的格式:simple, plain, json, xml, md, csv, html, sqlite)
--log=路径 日志文件
详细用法示例
-e 限定扫描后缀,如php\html\jsp等
python3 dirsearch.py -u https://daxue-userapi.58.com -e jsp
-r 递归,如果找到/admin会递归爆破/admin/*
python3 dirsearch.py -e php,html,js -u https://target -r
–max-recursion-depth 设置最大递归扫描深度
–recursion-status 设置递归状态代码
python3 dirsearch.py -e php,html,js -u https://target -r --max-recursion-depth 3 --recursion-status 200-399
强制递归
–force-recursive:暴力递归所有找到的路径,而不仅仅是以 / 结尾的路径
–deep-recursive:递归暴力破解路径的所有深度(a/b/c => 添加 a/, a/b/),即所有可能的路径目录
如果您不想递归地暴力破解某些子目录,请使用 --exclude-subdirs
python3 dirsearch.py -e php,html,js -u https://target -r --exclude-subdirs image/,media/,css/
-t 线程数
python3 dirsearch.py -e php,htm,js,bak,zip,tgz,txt -u https://target -t 20
前缀/后缀
–prefixes 为所有条目添加自定义前缀
python3 dirsearch.py -e php -u https://target --prefixes .,admin,_
# 比如目录字典为tool,会变成:tool、.tool、admintool、_tool。即添加前缀和原来的组合在一起的结果。
–suffixes 为所有条目添加自定义后缀
python3 dirsearch.py -e php -u https://target --suffixes ~
# 如字典内容为:index.php、internal
# 生成后缀:index.php、internal、index.php~、internal~
黑名单
在 - 的里面 db/文件夹中,有几个“黑名单文件”。 如果这些文件中的路径具有与文件名中提到的相同状态,则将从扫描结果中过滤掉这些路径。
示例:如果添加 admin.php进入 db/403_blacklist.txt,每当您进行扫描时 admin.php返回403,将从结果中过滤掉。
过滤器:通过状态码、大小、文本、正则、重定向、特定响应内容等
- 使用 -i | --include-status 和 -x | --exclude-status 选择允许和不允许的响应状态代码
对于更高级的过滤器: --exclude-sizes 、 --exclude-texts 、 --exclude-regexps 、 --exclude-redirects 和 --exclude-response
- 使用
--exclude-sizes选项来排除大于或小于指定大小的响应。 - 使用
--exclude-texts和--exclude-regexps选项来排除包含特定文本或匹配正则表达式的响应。 - 使用
--exclude-redirects选项来跳过重定向响应。 - 使用
--exclude-response选项来排除匹配特定响应头或正文的响应。
python3 dirsearch.py -e php,html,js -u https://target --exclude-sizes 1B,243KB
python3 dirsearch.py -e php,html,js -u https://target --exclude-texts "403 Forbidden"
python3 dirsearch.py -e php,html,js -u https://target --exclude-regexps "^Error$"
python3 dirsearch.py -e php,html,js -u https://target --exclude-redirects "https://(.*).okta.com/*"
python3 dirsearch.py -e php,html,js -u https://target --exclude-response /error.html
排除扩展名
使用 -X | --exclude-extensions 带有扩展名列表将删除单词列表中包含给定扩展名的所有路径
python3 dirsearch.py -u https://target -X jsp
扫描子目录
扫描子目录列表 从 URL 中,您可以使用–subdirs 。
python3 dirsearch.py -e php,html,js -u https://target --subdirs /,admin/,folder/
代理
dirsearch 支持 SOCKS 和 HTTP 代理,有两个选项:代理服务器或代理服务器列表。
python3 dirsearch.py -e php,html,js -u https://target --proxy 127.0.0.1:8080
python3 dirsearch.py -e php,html,js -u https://target --proxy socks5://10.10.0.1:8080
python3 dirsearch.py -e php,html,js -u https://target --proxylist proxyservers.txt
报告
支持的报告格式: simple , plain , json , xml , md , csv , html , sqlite
python3 dirsearch.py -e php -l URLs.txt --format plain -o report.txt
python3 dirsearch.py -e php -u https://target --format html -o target.json
关于字典
- Wordlist是一个文本文件,每一行是一个路径。%EXT%为占位符用来替换内容。
- dirsearch在替换%EXT%关键字时,只会替换使用-e标志指定的扩展名,这和其他工具不同。
- 如果Wordlist中没有%EXT%(像SecLists),需要使用-f或–force-extensions选项,将扩展名添加到Wordlist中的每个单词后面。
- 如果Wordlist中已经有了扩展名,想要对其应用新的扩展名,需要使用-O或–overwrite-extensions选项(注意某些扩展名如.log、.json、.xml等不会被覆盖)。
- 可以用逗号分隔多个Wordlist一起使用,例如wordlist1.txt,wordlist2.txt。
例子:
- 正常扩展 :
index.%EXT%
传递 asp 和 aspx 作为扩展名将生成以下字典:
index
index.asp
index.aspx
- 强制扩展 :
admin
使用 php 和 html 作为扩展传递 -f / –force-extensions 将生成以下字典:
admin
admin.php
admin.html
admin/
- 覆盖扩展名 :
login.html
使用 jsp 和 jspa 作为扩展传递 -O / –overwrite-extensions 将生成以下字典:
login.html
login.jsp
login.jspa
配置文件
默认情况下, config.inidirsearch 目录中的文件用作配置文件,但您可以通过以下方式选择另一个文件 --config标志或 DIRSEARCH_CONFIG环境变量。
# If you want to edit dirsearch default configurations, you can
# edit values in this file. Everything after `#` is a comment
# and won't be applied
[general]
# 线程数,默认为25
threads = 25
# 是否递归扫描,默认为False
recursive = False
# 深度递归扫描,默认为False
deep-recursive = False
# 强制递归扫描,默认为False
force-recursive = False
# 递归扫描的响应状态码范围,默认为200-399、401、403
recursion-status = 200-399,401,403
# 递归扫描最大深度,默认为0即无限制
max-recursion-depth = 0
# 排除扫描的子目录
exclude-subdirs = %%ff/,.;/,..;/,;/,./,../,%%2e/,%%2e%%2e/
# 使用随机user-agent,默认为False
random-user-agents = False
# 最大扫描时间(秒),默认为0即无限制
max-time = 0
# 遇到错误立即退出,默认为False
exit-on-error = False
# 要扫描的子目录示例
# subdirs = /,api/
# 包含的响应状态码,默认扫描所有状态码
# include-status = 200-299,401
# 排除的响应状态码
# exclude-status = 400,500-999
# 排除的响应大小
# exclude-sizes = 0b,123gb
# 排除包含特定文本的响应
# exclude-text = "Not found"
# 排除匹配指定正则表达式的响应
# exclude-regex = "^403$"
# 排除重定向到指定URL的响应
# exclude-redirect = "*/error.html"
# 排除指定响应
# exclude-response = 404.html
# 跳过指定状态码的响应
# skip-on-status = 429,999
[dictionary]# 扩展名及字典设置
# 默认扫描的扩展名
default-extensions = php,aspx,jsp,html,js
# 是否强制使用扩展名,默认False
force-extensions = False
# 是否重写后缀,默认False
overwrite-extensions = False
# 字典单词小写化,默认False
lowercase = False
# 字典单词大写化,默认False
uppercase = False
# 字典单词首字母大写,默认False
capitalization = False
# 排除的扩展名
# exclude-extensions = old,log
# 扫描的前缀
# prefixes = .,admin
# 扫描的后缀
# suffixes = ~,.bak
# 指定字典文件
# wordlists = /path/to/wordlist1.txt,/path/to/wordlist2.txt
[request] # 请求设置
# 请求方法,默认为GET
http-method = get
# 是否跟随重定向,默认False
follow-redirects = False
# 自定义请求头文件
# headers-file = /path/to/headers.txt
# 自定义user-agent
# user-agent = MyUserAgent
# 自定义cookie
# cookie = SESSIONID=123
[connection]
# 超时时间,默认7.5秒
timeout = 7.5
# 请求延迟,默认0秒
delay = 0
# 最大请求速率,默认0无限制
max-rate = 0
# 最大重试次数,默认1次
max-retries = 1
# 自动识别URI方案,无需手动设置
# scheme = http
# 代理设置
# proxy = localhost:8080
# 代理列表文件
# proxy-file = /path/to/proxies.txt
# 重放代理设置
# replay-proxy = localhost:8000
[advanced] # 高级设置
# 目录爬行,默认False
crawl = False
[view] # 结果显示设置
# 显示完整URL,默认False
full-url = False
# 安静模式,默认False
quiet-mode = False
# 彩色显示,默认开启
color = True
# 显示重定向历史,默认False
show-redirects-history = False
[output] # 输出设置
# 报告格式,默认plain文本
# 支持:plain, simple, json, xml, md, csv, html, sqlite
report-format = plain
# 自动保存报告,默认开启
autosave-report = True
# 报告保存文件夹,默认reports/
autosave-report-folder = reports/
# 日志文件
# log-file = /path/to/dirsearch.log
# 日志大小上限
# log-file-size = 50000000
📌 如果你对网络安全或编程感兴趣,可以搜索公众号“Y1X1n安全”,每天都会分享相关知识点,让我们一同加油!路漫漫其修远兮,吾将上下而求索。

![[学习笔记]3小时搞定DRF框架 | Django REST framework前后端分离框架实践](https://img-blog.csdnimg.cn/7abd7276c311419a9ff7c50e224c08bf.png)
![[openCV]基于拟合中线的智能车巡线方案V4V5](https://img-blog.csdnimg.cn/88b8ac115e794211abc7c15fc1e5d00c.png)