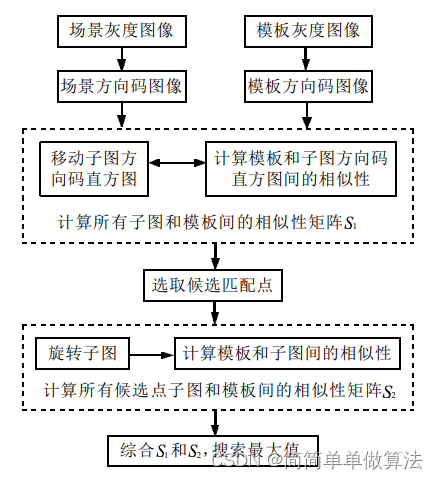
本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处
标题:Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
链接:Looking to listen at the cocktail party: a speaker-independent audio-visual model for speech separation: ACM Transactions on Graphics: Vol 37, No 4
译者注:原文标题中的“Cocktail Party”字面意思为“鸡尾酒会”。“鸡尾酒会效应"是一个在听觉科学中常用的术语,它是从人类对复杂声音环境的惊人处理能力中得出的概念。考虑一个繁忙的鸡尾酒会场景,人们可以专注于特定的对话或声音,同时忽略背景中的其他噪音。这就是我们通常所说的"听力选择性注意"或"鸡尾酒会效应”。
授权声明:
获得本作品部分或全部的数字或硬拷贝以供个人或教室使用的许可,只要不是为了盈利或商业利益,且拷贝上有此通知和完整引用于第一页,就无需支付费用。必须尊重本作品中第三方组件的版权。如需其他用途,请联系作品的所有者/作者。
© 2018 版权由所有者/作者持有。
0730-0301/2018/8-ART112
https://doi.org/10.1145/3197517.3201357
摘要
我们提出了一个联合的“音频-视觉模型”(joint audio-visual model),用于从混合声音(如其他讲话者和背景噪音)中分离出单一的语音信号。仅使用音频作为输入来解决这个任务极其具有挑战性,并且不能将分离出的语音信号与视频中的讲话者关联起来。
在这篇论文中,我们提出了一个基于深度网络的模型,它结合了视觉和听觉信号(incorporates both visual and auditory signals)来解决这个任务。
视觉特征被用来将音频“聚焦”在场景中期望的讲话者上,以提高语音分离的质量。为了训练我们的联合音频-视觉模型,我们引入了AVSpeech,这是一个新的数据集,由来自网络的数千小时的视频片段组成。
只需要用户指定他们想要隔离的视频中的人的脸,我们便证实了我们的方法适用于经典的语音分离任务,以及包含激烈的采访、嘈杂的酒吧和尖叫的孩子的现实世界情况。
在混合语音的情况下,我们的方法明显优于最新的仅音频语音分离。
此外,我们的模型是不依赖于讲话者的(speaker-independent)(训练一次,适用于任何讲话者),产生的结果优于最近的依赖于讲话者的音视频语音分离方法(需要为每个感兴趣的讲话者训练一个单独的模型)。
额外的关键词和短语
音频-视觉,源分离,语音增强,深度学习,卷积神经网络(CNN),双向长短期记忆(BLSTM)
ACM参考文献格式
Ariel Ephrat, Inbar Mosseri, Oran Lang, Tali Dekel, Kevin Wilson, Avinatan Hassidim, William T. Freeman, 和 Michael Rubinstein. 2018. Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation. ACM Trans. Graph. 37, 4, Article 112 (August 2018), 11 pages. https://doi.org/10.1145/3197517.3201357
1 引言
在嘈杂的环境中,人类有着将他们的听觉注意力集中在一个单一的声源上的令人惊叹的能力,同时降低(“静音”,muting)所有其他的声音和噪音。神经系统如何实现这一壮举,也就是所谓的鸡尾酒会效应 [Cherry 1953],仍然不清楚。
然而,研究已经表明,观察讲话者的脸部可以增强一个人在嘈杂环境中解决感知模糊性的能力 [Golumbic et al. 2013; Ma et al. 2009]。在本文中,我们实现了这种能力的计算表达。
第一作者作为实习生在谷歌完成了这项工作
自动语音分离,即将输入音频信号分离为各个独立的语音源,在音频处理文献中已有深入研究。由于该问题本质上是病态问题,为了得到合理的解决方案,需要先有先验知识或特殊的麦克风配置 [McDermott 2009]。
此外,纯音频语音分离面临一个根本性问题,即标签置换问题(label permutation problem) [Hershey et al. 2016]:没有简单的方法将每个分离的音频源与视频中对应的说话者关联起来 [Hershey et al. 2016; Yu et al. 2017]。
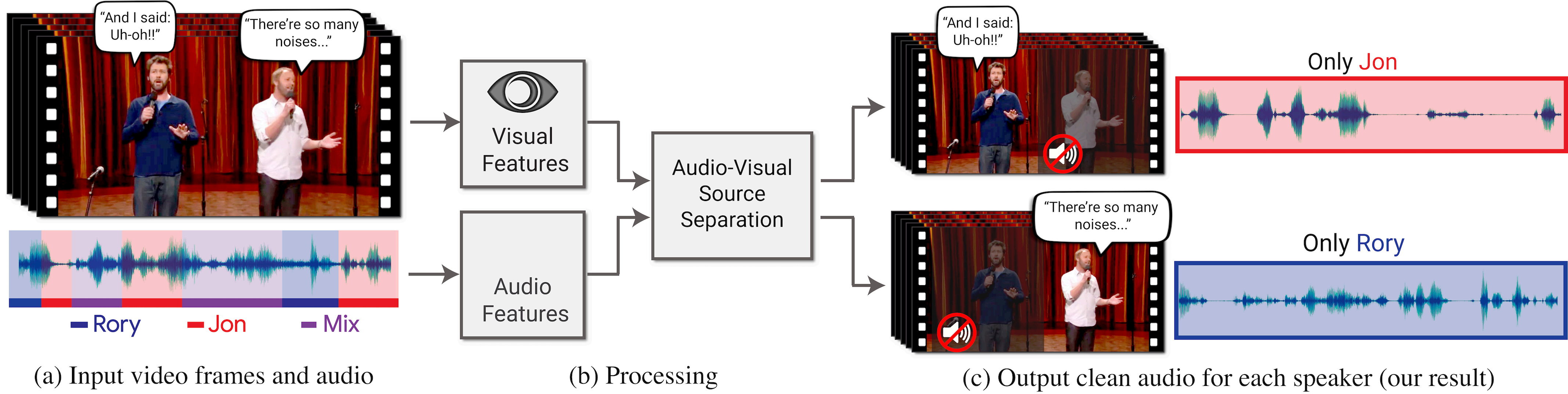
在这项工作中,我们提出了一种联合音频和视觉的方法,用于在视频中"聚焦"特定的说话者。输入视频可以重新组合,以增强与特定人物相关的音频,同时抑制所有其他声音(图1)。
图1:我们提出了一个模型,用于在视频中隔离和增强特定说话者的语音。(a) 输入是一个视频(帧 + 音频轨道),其中一个或多个人在说话,感兴趣的语音受到其他说话者和/或背景噪声的干扰。(b) 提取音频和视觉特征,并将其输入联合音频-视觉语音分离模型。输出是将输入音频轨道分解成干净的语音轨道,每个检测到的视频中的人一个轨道 ©。这使得我们能够合成视频,其中特定人的语音得到增强,而所有其他声音被抑制。
我们的模型是使用我们的新数据集AVSpeech中数千小时的视频片段进行训练的。图中的“Stand-Up”(类似“相声”)视频(a)由Team Coco提供。
具体而言,我们设计并训练了一个基于神经网络的模型,它以录制的混合声音和视频中每帧检测到的人脸的紧密裁剪图作为输入,并将混合物分割成每个检测到的说话者的独立音频流。
该模型利用视觉信息既可以提高源分离的质量(与仅使用音频的结果相比),又可以将分离的语音轨与视频中可见的说话者关联起来。用户所需做的就是指定希望从视频中的哪些人的脸听到说话。
为了训练我们的模型,我们从YouTube上收集了290,000个高质量的讲座、TED演讲和教程视频,然后自动从这些视频中提取了大约4700小时的带有可见说话者和干净语音(没有干扰声音)的视频剪辑(图2)。
图2:AVSpeech数据集:首先,我们收集了290,000个高质量的在线公共讲演和讲座视频(a)。从这些视频中,我们提取了带有干净语音的片段(例如没有混合音乐、听众声音或其他说话者),并且在帧中可见说话者(有关处理细节,请参阅第3节和图3)。这导致了4700小时的视频剪辑,每个剪辑都是单独一个人说话,没有背景干扰 (b)。这些数据涵盖了各种各样的人物、语言和脸部姿势,其分布如©所示(年龄和头部角度估计采用自动分类器;语言基于YouTube的元数据)。关于数据集中视频来源的详细列表,请参考项目网页。

我们将这个新数据集称为AVSpeech。有了这个数据集,我们接着生成了一个“合成鸡尾酒会”的训练集——将包含干净语音的人脸视频与其他说话者的音频轨道和背景噪声混合在一起。
我们通过两种方式展示了我们的方法相对于最近的语音分离方法的优势。
- 我们在纯语音混合物上与最先进的仅音频方法相比展示了卓越的结果。
- 我们展示了我们的模型在包含重叠语音和背景噪声的混合物中,在真实世界场景下产生增强声音流的能力。
总结起来,我们的论文提供了两个主要的贡献:
- 一个音频-视觉语音分离模型,在经典的语音分离任务中优于仅音频和音频-视觉模型,并适用于具有挑战性的自然场景。据我们所知,我们的论文是第一个提出面向说话人无关的音频-视觉语音分离模型的研究。
- 一个新的大规模音频-视觉数据集AVSpeech,经过精心收集和处理,其中包含视频片段,其中可听到的声音属于视频中单个可见的人,并且没有音频背景干扰。该数据集使我们能够在语音分离方面取得最先进的结果,并可能对研究社区进行进一步研究。
我们的数据集、输入输出视频以及其他补充材料都可以在项目网页上找到:http://looking-to-listen.github.io/。
2 相关工作
我们简要回顾了语音分离和音频-视觉信号处理领域的相关工作。
语音分离:语音分离是音频处理中的一个基本问题,近几十年来一直是广泛研究的课题。
-
Wang和Chen [2017]对近期基于深度学习的仅音频方法进行了全面的概述,这些方法涉及语音降噪 [Erdogan等人,2015; Weninger等人,2015] 和语音分离任务。
-
最近出现了两种解决前述**标签置换问题(label permutation problem)**的方法,用于在单声道情况下进行说话人无关的多说话人分离。
-
Hershey等人[2016]提出了一种称为"深度聚类(deep clustering)"的方法,其中使用经过判别式训练的语音嵌入来对不同的语音源进行聚类和分离。
-
Hershey等人[2016]还介绍了一种无置换或置换不变的损失函数的思想,但他们并没有发现它的效果很好。Isik等人[2016]和Yu等人[2017]随后提出了一种成功使用**置换不变的损失函数(permutation invariant loss function)**来训练深度神经网络的方法。
-
-
我们的方法相对于仅音频方法的优势有三点:
-
我们展示了我们的音频-视觉模型的分离结果质量比最先进的仅音频模型更高。
-
我们的方法在多说话者与背景噪声混合的情况下表现良好,据我们所知,目前还没有仅音频方法令人满意地解决这个问题。
-
我们联合解决了两个语音处理问题:语音分离和将语音信号与其对应的人脸进行关联,这两个问题到目前为止一直是分别独立处理的 [Hoover等人,2017; Hu等人,2015; Monaci,2011]。
-
音频-视觉信号处理:使用神经网络对听觉和视觉信号进行多模态融合,解决各种与语音相关的问题,正在引起越来越多的兴趣。
-
其中包括
-
音频-视觉语音识别 [Feng等人,2017; Mroueh等人,2015; Ngiam等人,2011]
-
从无声视频(唇读)中预测语音或文本 [Chung等人,2016; Ephrat等人,2017]
-
从视觉和语音信号中无监督学习语言 [Harwath等人,2016]。
这些方法利用了同时录制的视觉和听觉信号之间的自然同步关系。
-
-
音频-视觉(Audio-visual,AV)方法也已被用于
-
语音分离和增强 [Hershey等人,2004; Hershey和Casey,2002; Khan,2016; Rivet等人,2014]。
-
Casanovas等人[2010]使用稀疏表示进行AV源分离,但由于依赖于仅有活动的区域来学习源特征,并假设所有音频源都在屏幕上可见,因此受到限制。
-
近期的方法使用神经网络来执行这一任务。
-
Hou等人[2018]提出了一个基于多任务CNN的模型,该模型输出去噪的语音频谱图以及输入嘴部区域的重建。
-
Gabbay等人[2017]在视频上训练了一个语音增强模型,其中目标说话者的其他语音样本被用作背景噪声,他们将这个方案称为“无噪声训练(noise-invariant training)”。在并行工作中,Gabbay等人[2018]使用视频到音频合成方法来过滤嘈杂的音频。
-
-
这些AV语音分离方法的主要局限性在于它们是面向特定说话者的,意味着必须为每个说话者单独训练一个专用模型。虽然这些工作在设计上做出了特定的选择,限制了它们只适用于特定说话者的情况。但我们推测迄今为止没有广泛研究面向说话者无关的AV模型的主要原因是缺乏足够大和多样的数据集来训练这样的模型。而这正是我们在这项工作中构建并提供的数据集所具备的特点。
-
-
据我们所知,我们的论文是第一个解决面向无关说话者的AV语音分离问题的研究。我们的模型能够分离和增强它以前从未见过的说话者,说着不在训练集中的语言。此外,我们的工作独具特色,因为我们展示了在真实世界的例子中高质量的语音分离,这些设置是之前的仅音频和音频-视觉语音分离工作所未涉及的。
-
最近出现了许多独立和同时进行的工作,它们使用深度神经网络解决了音频-视觉声源分离的问题。
-
[Owens和Efros 2018]训练了一个网络来预测音频和视觉流是否在时间上对齐。从这个自监督模型中提取的学习特征随后用于条件化一个屏幕内外的说话者源分离模型。
-
Afouras等人[2018]通过使用一个网络来预测去噪语音频谱图的幅度和相位来进行语音增强。
-
Zhao等人[2018]和Gao等人[2018]解决了与此密切相关的问题,即分离多个屏幕内的对象的声音(例如乐器)。
-
音频-视觉数据集:大多数现有的AV数据集包含的视频只涉及少数主体,并且说的是来自有限词汇的单词。
-
例如,
-
CUAVE数据集[Patterson等人,2002]包含36个主体,每个主体分别说0到9的数字五次,每个数字共有180个示例。
-
另一个例子是由Hou等人[2018]介绍的普通话句子数据集,其中包含一个母语者说的320个普通话句子的视频录音。每个句子包含10个中文字符,其中的音素等分布。
-
TCD-TIMIT数据集[Harte和Gillen,2015]包括60名志愿者演讲者,每个演讲者约有200个视频。这些演讲者朗读来自TIMIT数据集[S Garofolo等人,1992]的各种句子,并使用面向前方和30度角的摄像机进行录制。
为了与之前的工作进行比较,我们在这三个数据集上评估了我们的结果。
-
-
最近,Chung等人[2016]引入了大规模唇读句子(LRS)数据集,其中包括各种不同的演讲者和更大词汇的单词。然而,该数据集不仅不公开,而且LRS视频中的语音不保证是干净的,而这对于训练语音分离和增强模型是至关重要的。
3 AVSpeech数据集
我们引入了一个新的大规模音频-视觉数据集,其中包含没有干扰背景信号的语音片段。这些片段的长度各不相同,介于3到10秒之间,每个片段中视频中唯一可见的脸和音频中的声音都属于同一个说话人。总共,该数据集包含大约4700小时的视频片段,涵盖约150,000个不同的说话者,涵盖了各种各样的人物、语言和脸部姿势。图2展示了一些代表性的帧、音频波形和一些数据集统计信息。
我们采用了自动收集数据集的方式,因为对于组建这样一个庞大的语料库,不依赖于大量的人工反馈是很重要的。我们的数据集创建流程从大约290,000个YouTube视频中收集了片段,这些视频包括讲座(例如TED演讲)和教程视频。对于这样的频道,大多数视频都只包含一个说话者,而且视频和音频通常质量较高。
数据集创建流程。我们的数据集收集过程有两个主要阶段,如图3所示。
图3:用于数据集创建的视频和音频处理:(a) 我们使用人脸检测和跟踪从视频中提取语音段候选,并拒绝那些人脸模糊或朝向不足够正面的帧。(b) 我们通过估计语音的信噪比(见第3节)来丢弃含有嘈杂语音的段落。图表旨在展示我们的语音信噪比估计器的准确性(从而反映数据集的质量)。我们将真实的语音信噪比与通过合成的纯净语音和非语音噪声在已知信噪比水平下生成的混合物的预测信噪比进行比较。预测的信噪比值(以分贝为单位)是在每个信噪比区间内进行60次生成混合物后进行平均的,误差条表示1个标准差。我们丢弃预测的语音信噪比低于17dB的段落(在图中由灰色虚线标记)。

-
首先,我们使用了Hoover等人[2017]的说话者跟踪方法,来检测视频中人们正在积极讲话并且脸部可见的段落。脸部帧如果模糊、光照不足或姿势极端,则会从段落中丢弃。如果一个段落中超过15%的脸部帧缺失,则整个段落会被丢弃。在此阶段,我们使用了Google Cloud Vision API1来进行分类器,以及计算图2中的统计数据。
-
构建数据集的第二个步骤是对语音段进行优化,只包含干净、无干扰的语音。这是一个关键的组成部分,因为这些段落在训练时作为基准真值。我们通过以下方式自动执行这一优化步骤,即通过估计每个段落的语音信噪比(主要语音信号与其他音频信号之间的对数比)来实现。
-
我们使用一个预训练的仅音频语音降噪网络,通过使用降噪输出作为干净信号的估计,来预测给定段落的语音信噪比。这个网络的架构与第5节中实现的仅音频语音增强基线的架构相同,它是在LibriVox公共领域音频书籍的语音数据上进行训练的。
-
对于那些估计的语音信噪比低于某个阈值的段落,我们将其丢弃。这个阈值是通过在不同已知信噪比水平下,使用纯净语音和非语音干扰噪声的合成混合物进行经验设置的2。这些合成混合物被输入到降噪网络中,然后将估计的(降噪后的)语音信噪比与基准真值信噪比进行比较(参见图3(b))。
-
我们发现,在低信噪比情况下,平均而言,估计的语音信噪比非常准确,因此可以被视为原始噪声水平的良好预测器。而在较高信噪比情况下(即原始语音信号几乎没有干扰的段落),该估计器的准确性会减弱,因为噪声信号变得微弱。这种减弱发生的阈值约为17dB,如图3(b)所示。我们随机抽取了通过此过滤的100个片段进行听取,发现其中没有一个含有明显的背景噪声。我们在补充材料中提供了来自数据集的样本视频片段。
-
4 音频-视觉语音分离模型
音频-视觉语音分离模型(AUDIO-VISUAL SPEECH SEPARATION MODEL)
从高层次来看,我们的模型由一个多流架构组成,它接受检测到的脸部的视觉流和带有噪声的音频作为输入,并输出复杂的频谱掩模,每个掩模对应视频中检测到的一个脸部(见图4)。
图4:我们模型的多流神经网络架构:视觉流接受视频中每帧检测到的脸部缩略图作为输入,而音频流接受视频的音轨作为输入,其中包含了语音和背景噪声的混合。视觉流使用预训练的人脸识别模型提取每个缩略图的人脸嵌入,然后使用扩张卷积神经网络学习视觉特征。音频流首先计算输入信号的短时傅里叶变换(STFT)以获得频谱图,然后使用类似的扩张卷积神经网络学习音频表示。然后通过连接学习到的视觉和音频特征来创建联合的音频-视觉表示,并通过双向LSTM和三个全连接层进一步处理。网络输出每个说话者的复杂频谱掩模,将其与噪声输入相乘,并转换回波形(waveforms)以获得每个说话者的独立语音信号。
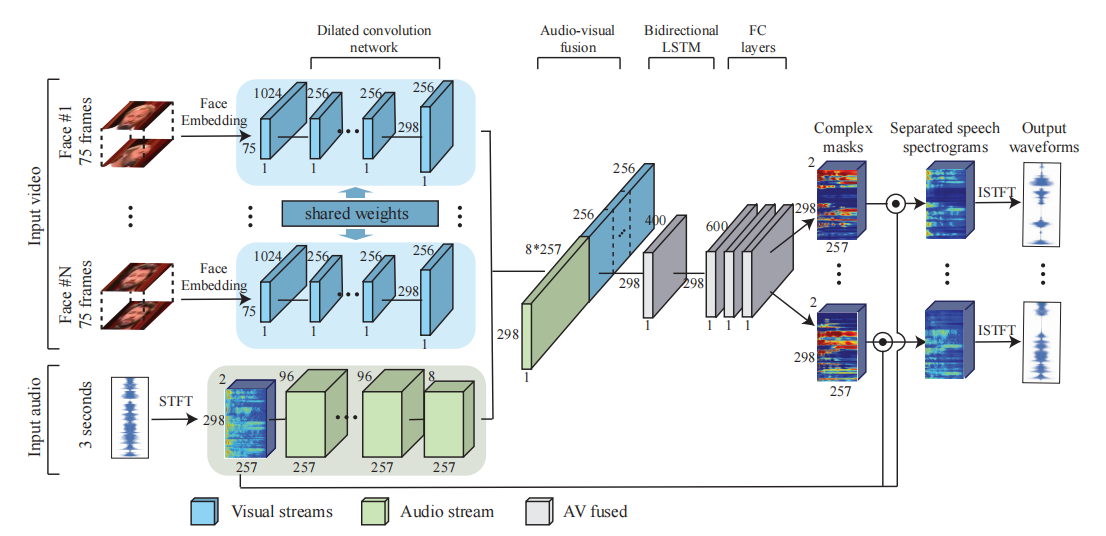
然后,将噪声输入频谱与掩模相乘,从而得到每个说话者的独立语音信号,并抑制其他所有干扰信号。
4.1 视频和音频表示
输入特征。我们的模型同时接受视觉和听觉特征作为输入。
-
对于包含多个说话者的视频剪辑,我们使用一个现成的人脸检测器(例如Google Cloud Vision API)在每帧中找到人脸(每个说话者总共有75个脸部缩略图,假设每个剪辑为3秒,帧率为25 FPS)。
-
我们使用预训练的人脸识别模型为每个检测到的脸部缩略图提取一个人脸嵌入。我们使用了网络中最低的不会空间变化的层,类似于Cole等人[2016]用于合成人脸的方法。这样做的理由是这些嵌入保留了识别数百万个人脸所需的信息,同时去除了图像之间的不相关变化,比如光照。
-
实际上,最近的研究还表明,可以从这些嵌入中恢复出面部表情[Rudd等人,2016]。我们还尝试了使用脸部图像的原始像素,但并未导致性能的提升。
-
-
至于音频特征,我们计算3秒音频片段的短时傅里叶变换(STFT)。每个时间-频率(TF)bin包含一个复数的实部和虚部,我们将它们作为输入。我们进行**幂次压缩(power-law compression)**来防止响亮的音频淹没了柔和的音频。同样的处理方式适用于噪声信号和干净参考信号。
-
在推断时,我们的分离模型可以应用于任意长的视频段。当在一帧中检测到多个说话者的脸部时,我们的模型可以接受多个脸部流作为输入,我们稍后将讨论这一点。
输出。我们模型的输出是一个乘法频谱掩模(multiplicative spectrogram mask),它描述了干净语音与背景干扰之间的时间-频率关系。
-
在之前的研究中[Wang and Chen 2017; Wang et al. 2014],乘法掩模被观察到比其他选择更有效,比如直接预测频谱幅度或直接预测时域波形。在源分离文献中存在许多基于掩模的训练目标[Wang and Chen 2017],我们尝试了其中的两种:比率掩模(RM)和复数比率掩模(cRM)。
-
理想的比率掩模(RM)被定义为干净频谱和噪声频谱之间的幅度比值,而且它被规范在0和1之间。
- 当使用比率掩模时,我们将预测的比率掩模和噪声频谱的幅度进行逐点乘法,然后与噪声原始相位一起进行逆短时傅里叶变换(ISTFT),得到去噪后的波形 [Wang and Chen 2017]。
-
复数理想比率掩模被定义为复数干净频谱和噪声频谱之间的比值。复数理想比率掩模有一个实部和一个虚部,这两部分在实域中分别进行估计。复数掩模的实部和虚部通常在-1和1之间,然而,我们使用sigmoid函数压缩将这些复数掩模值限制在0和1之间[Wang et al. 2016]。
- 当使用复数理想比率掩模进行掩蔽时,通过在预测的复数理想比率掩模和噪声频谱上进行复数乘法,然后对结果进行逆短时傅里叶变换(ISTFT),得到去噪后的波形。
-
-
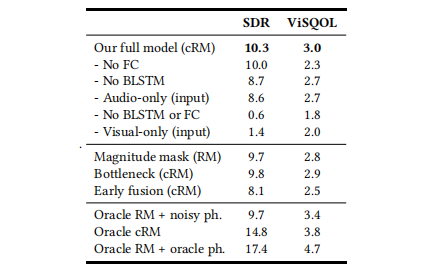
在给定多个检测到的说话者脸部流作为输入时,网络为每个说话者和背景干扰输出一个单独的掩模。在大多数实验中,我们使用cRM,因为我们发现使用cRM输出的语音质量明显优于RM。请参考表6,以获得这两种方法的定量比较。
表6:剔除实验(Ablation study):我们研究了我们模型在分离两个干净说话者混合的场景中的不同部分的贡献。信号混响比(SDR)与噪声抑制有很好的相关性,而ViSQOL则表明语音质量的水平(详见附录中的A节)。
4.2 网络架构
图4提供了我们网络中各个模块的高级概述,现在我们将详细介绍这些模块。
音频和视觉流(Audio and visual streams)。
我们模型中的音频流部分由扩张卷积层组成,其参数如表1所示。
表1:构成我们模型音频流的扩张卷积层。

-
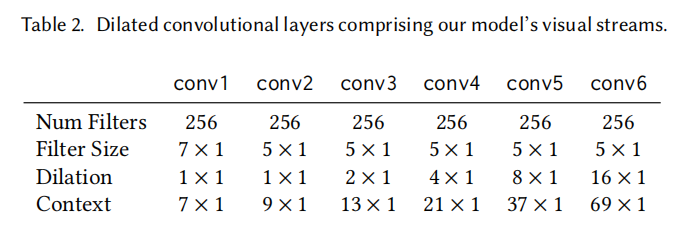
我们模型的视觉流用于处理输入的脸部嵌入(见第4.1节),并由表2中详细描述的扩张卷积组成。请注意,视觉流中的“空间”卷积和扩张是在时间轴上进行的(而不是在1024维的脸部嵌入通道上进行)。
表2:构成我们模型的视觉流的扩张卷积层。
-
为了补偿音频和视频信号之间的采样率差异,我们将视觉流的输出上采样以匹配频谱图的采样率(100 Hz)。这是通过在每个视觉特征的时间维度上使用简单的最近邻插值来完成的。
音频视觉融合(AV fusion)。
-
音频和视觉流(The audio and visual streams)
-
通过将每个流的特征图连接在一起进行合并
-
然后输入到一个BLSTM(双向长短时记忆网络),接着是三个全连接层。
-
最终输出由每个输入说话者的复杂掩模(两个通道,实部和虚部)组成。
-
-
相应的频谱图(The corresponding spectrograms)
-
是通过将噪声输入频谱图与输出掩模进行复数乘法得到的。
-
使用幂次压缩后的干净频谱图与增强频谱图之间的平方误差(L2损失)用作训练网络的损失函数。
-
最终输出的波形是通过逆短时傅里叶变换(ISTFT)得到的,如第4.1节所述。
-
多位说话者(Multiple speakers)。
我们的模型支持从视频中隔离出多个可见的说话者,每个说话者由一个视觉流表示,如图4所示。
-
针对每个可见说话者数量,训练一个单独的专用模型。
- 例如,一个带有一个视觉流的模型对应一个可见说话者,一个带有双视觉流的模型对应两个可见说话者,等等。
-
所有视觉流在卷积层上共享相同的权重。在这种情况下,每个视觉流的学习特征都与学习的音频特征连接在一起,然后继续进行BLSTM。
值得注意的是,在实践中,可以使用一个以单个视觉流作为输入的模型,以处理说话者数量未知或无法使用专用的多说话者模型的一般情况。
4.3 实现细节
我们的网络使用TensorFlow实现,其包含的操作用于控制波形和STFT转换。
-
ReLU激活函数在除最后一层(掩码)以外的所有网络层后面都会跟随,最后一层采用sigmoid。
-
在所有卷积层之后执行批归一化[Ioffe和Szegedy 2015]。
-
我们没有使用Dropout,因为我们在大量数据上进行训练,不会出现过拟合的情况。
-
我们使用批量大小(batch size)为6个样本,
-
并使用Adam优化器进行500万步(批次,batches)的训练,
-
学习率(learning rate)为 3 ⋅ 1 0 − 5 3\cdot10^{−5} 3⋅10−5,每180万步将其减半。
所有音频数据都被重新采样为16kHz,并且立体声音频将通过仅使用左声道转换为单声道。使用长度为25毫秒的Hann窗口、10毫秒的跳跃长度和FFT大小为512计算STFT,从而得到一个 257 × 298 × 2 257\times298\times2 257×298×2个标量的输入音频特征。采用 p = 0.3 p=0.3 p=0.3( A 0.3 A^{0.3} A0.3,其中 A A A是输入/输出音频频谱图)进行幂律压缩。
我们在训练和推断之前将所有视频的人脸嵌入重新采样为每秒25帧(FPS),通过删除或复制嵌入来实现。这样就得到了一个由75个人脸嵌入组成的输入视觉流。使用Cole等人[2016]描述的工具进行人脸检测、对齐和质量评估。当在特定样本中遇到缺失的帧时,我们使用一个零向量代替面部嵌入。
5 实验和结果
我们在各种条件下测试了我们的方法,并将结果与最先进的仅音频(AO)和音频-视觉(AV)语音分离和增强方法进行了定量和定性比较。
与仅音频相比较(Comparison with Audio-Only)。
-
目前没有公开可用的最先进的仅音频语音增强/分离系统,而且相对较少的公开可用数据集用于训练和评估仅音频语音增强。
-
虽然有大量关于音频信号盲源分离的文献[Comon和Jutten 2010],但大多数这些技术需要多个音频通道(多个麦克风),因此不适用于我们的任务。
出于这些原因,我们实现了一个仅音频基线的语音增强模型,其架构类似于我们的音频流模型(图4,当去除视觉流时)。当在广泛用于语音增强工作的CHiME-2数据集[Vincent等人2013]上进行训练和评估时,我们的仅音频基线实现了14.6分贝的信噪比,几乎与Erdogan等人[2015]报告的最先进单声道结果14.75分贝一样好。
因此,我们的仅音频增强模型被认为是近乎最先进的基线模型。
为了将我们的分离结果与最先进的仅音频模型进行比较,我们实现了由Yu等人[2017]引入的置换不变训练方法。
- 请注意,使用此方法进行语音分离需要事先知道录音中存在的源的数量,并且需要手动将每个输出通道分配给其对应说话者的面部(我们的AV方法会自动完成这个过程)。
我们在第5.1节的所有合成实验中都使用这些AO方法,并在第5.2节中对实际视频进行质量比较。
与最近的音频-视觉方法的比较(Comparison with Recent Audio-Visual Methods)。
-
由于现有的音频-视觉语音分离和增强方法是面向特定说话者的,我们无法在合成混合语音的实验(第5.1节)中轻松地与它们进行比较,也无法在自然视频中运行它们(第5.2节)。
-
然而,我们通过在那些论文中的视频上运行我们的模型,展示了与这些方法在现有数据集上的定量比较。我们将在第5.3节中更详细地讨论这个比较。
-
此外,我们在附录材料中展示了定性比较。
5.1 合成混合语音的定量分析
我们为几个不同的单声道语音分离任务生成了数据。每个任务都需要其独特的语音和非语音背景噪声混合配置。我们以下描述每个训练数据变体的生成过程,以及每个任务相关的模型,这些模型是从头开始训练的。
-
在所有情况下,干净的语音片段和对应的脸部图像都来自我们的AVSpeech (AVS)数据集。
-
非语音背景噪声来自AudioSet [Gemmeke et al. 2017],这是一个大规模的数据集,包含了从YouTube视频中手动标注的片段。
使用BSS Eval工具箱 [Vincent et al. 2006] 中的信号失真比(SDR)改进来评估分离后的语音质量,SDR是用于评估语音分离质量的常用指标(详见附录中的A节)。
我们从我们的数据集中提取了3秒不重叠的片段(例如,一个10秒的片段将会产生3个3秒的片段)。我们为所有的模型和实验生成了150万个合成混合语音。对于每个实验,生成的数据中的90%被用作训练集,剩余的10%用作测试集。我们没有使用任何验证集,因为没有进行参数调整或提前停止。
一个说话者+噪声(One speaker+noise (1S+Noise))。
这是一个经典的语音增强任务,其训练数据是通过线性组合未归一化的干净语音和AudioSet噪声生成的:
M
i
x
i
=
A
V
S
j
+
0.3
∗
A
u
d
i
o
S
e
t
k
Mix_i=AVS_j+0.3*AudioSet_k
Mixi=AVSj+0.3∗AudioSetk
其中:
- A V S j AVS_j AVSj是 A V S AVS AVS中的一个话语(utterance)
- A u d i o S e t k AudioSet_k AudioSetk是 A u d i o S e t AudioSet AudioSet中的一个片段,其幅度乘以0.3
- M i x i Mix_i Mixi是合成混合语音数据集中的一个样本
我们的纯音频模型在这种情况下表现得非常好,因为噪声的特征频率通常与语音的特征频率有很好的分离。我们的音频-视觉(AV)模型的性能与音频-只有(AO)基线相当,都具有16dB的SDR(见表3的第一列)。
表3:定量分析和与纯音频语音分离和增强的比较:质量改进(以SDR为单位,详见附录中的A节)作为输入视觉流数量的函数,使用不同的网络配置。第一行(纯音频)是我们实现的一种最先进的语音分离模型,并作为基准显示。

两个干净说话者(Two clean speakers (2S clean))。
用于这个两个说话者分离场景的数据集是通过混合来自我们的AVS数据集中两个不同说话者的干净语音生成的:
M
i
x
i
=
A
V
S
j
+
A
V
S
k
Mix_i=AVS_j+AVS_k
Mixi=AVSj+AVSk
其中:
-
A V S j AVS_j AVSj和 A V S k AVS_k AVSk是来自数据集中不同源视频的干净语音样本
-
M i x i Mix_i Mixi是合成混合语音数据集中的一个样本
除了我们的AO基准模型,我们在这个任务上训练了两种不同的AV模型:
-
(i)只接受一个视觉流作为输入,并且只输出其对应的去噪信号的模型。
在这种情况下,在推断时,每个说话者的去噪信号通过网络进行两次前向传递(每个说话者一次)获得。对该模型的SDR结果进行平均,相比我们的AO基准模型,可以提高1.3dB(表3的第二列)。
-
(ii)以两个分开的视觉流的形式同时接受两个说话者的视觉信息作为输入(如第4节所述)。
在这种情况下,输出由两个掩模组成,每个掩模对应一个说话者,并且推断只需要进行一次前向传递。使用这个模型获得额外的0.4dB提升,总共达到了10.3dB的SDR改进。直观地说,联合处理两个视觉流为网络提供了更多信息,并对分离任务施加了更多约束,从而改善了结果。
图5显示了这项任务中,基于输入SDR的改进SDR情况,包括仅音频基线模型和我们的双说话者音频-视觉模型( two-speaker audio-visual model)。
图5:输入SDR对比改进后的输出SDR:这是一个散点图,显示将两个干净说话者(2S clean)分离任务中的分离性能(SDR改进)作为原始(嘈杂)SDR的函数。每个点对应于测试集中的单个3秒音频视觉样本。

两个说话者+噪声(Two speakers+noise (2S+Noise))。
在这里,我们考虑从两个说话者和非语音背景噪声的混合中隔离出一个说话者的声音的任务。据我们所知,这个音频-视觉任务之前还没有被解决过。训练数据是通过将两个不同说话者的干净语音(如2S clean任务所生成的)与
A
u
d
i
o
S
e
t
AudioSet
AudioSet的背景噪声混合而成的:
M
i
x
i
=
A
V
S
j
+
A
V
S
k
+
0.3
∗
A
u
d
i
o
S
e
t
l
Mix_i=AVS_j+AVS_k+0.3*AudioSet_l
Mixi=AVSj+AVSk+0.3∗AudioSetl
在这种情况下,我们用三个输出来训练AO网络,分别对应每个说话者和背景噪声。
此外,我们训练了两种不同配置的模型,
-
一个接收一个视觉流作为输入
- 一个视觉流的AV模型的配置与前面实验中的模型(i)相同。
-
另一个接收两个视觉流作为输入
- 两个视觉流的AV模型输出三个信号,分别对应每个说话者和背景噪声。
正如表3(第三列)所示,一个视觉流的AV模型相对于仅音频的基准模型的SDR增益为0.1dB,两个视觉流的AV模型的增益为0.5dB,使总的SDR改进达到了10.6dB。
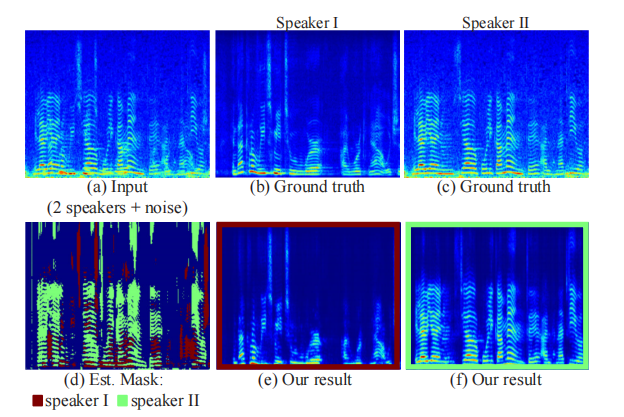
图6展示了来自这个任务的一个样本段的推断掩模和输出频谱图,以及它的噪声输入和真实频谱图。
图6:输入和输出音频的示例:顶部一行显示了我们训练数据中一个片段的音频频谱图,涉及两个说话者和背景噪声(a),以及每个说话者的真实、分离的频谱图(b,c)。在底部一行,我们展示了我们的结果:我们方法对该段的估计掩模,叠加在一个频谱图上,每个说话者使用不同的颜色表示(d),以及每个说话者相应的输出频谱图(e,f)。
三个干净说话者(Three clean speakers (3S clean))。
这个任务的数据集是通过将来自三个不同说话者的干净语音混合而成的:
M
i
x
i
=
A
V
S
j
+
A
V
S
k
+
A
V
S
l
Mix_i=AVS_j+AVS_k+AVS_l
Mixi=AVSj+AVSk+AVSl
与前面的任务类似,我们训练了一个接收一个、两个和三个视觉流作为输入的AV模型,并分别输出一个、两个和三个信号。
我们发现,即使使用单个视觉流,AV模型的性能也比AO模型更好,相比之下提高了0.5dB。两个视觉流的配置对AO模型也有相同的改进,而使用三个视觉流则导致1.4dB的增益,使总的SDR改进达到了10dB(表3的第四列)。
相同性别的分离(Same-gender separation)。
许多先前的语音分离方法在尝试分离包含相同性别语音的语音混合时表现下降[Delfarah and Wang 2017; Hershey et al. 2016]。
表4显示了我们根据不同性别组合的分离质量情况。
表4:**相同性别的分离。**这个表格中的结果来自2S clean实验,表明我们的方法对于从相同性别混合中分离语音具有鲁棒性。

有趣的是,我们的模型在女-女混合中表现最好(略微领先),但在其他组合中也表现良好,表明它对性别具有鲁棒性。
5.2 现实世界中的语音分离
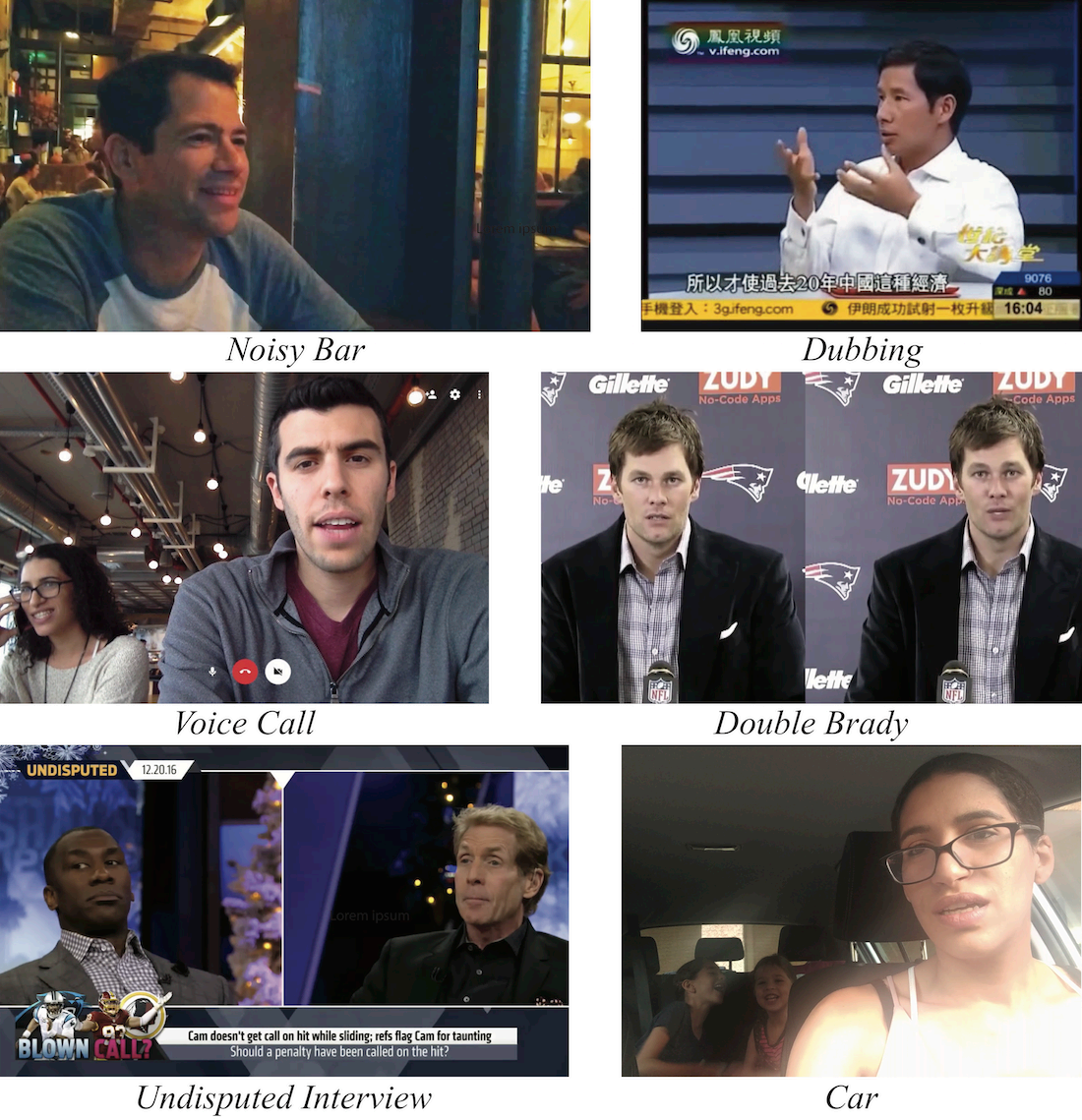
为了展示我们模型在现实场景中的语音分离能力,我们在包含激烈辩论和采访、嘈杂的酒吧和尖叫的孩子的各种视频中对其进行了测试(见图7)。
图7:野外语音分离:展示了在各种现实场景中应用我们方法的自然视频中的代表性帧。所有视频和结果可以在附录材料中找到。"不容置疑的采访(Undisputed Interview)"视频由福克斯体育提供。
在每个场景中,我们使用的训练模型的视觉输入流数量与视频中可见说话者的数量相匹配。
- 例如,对于一个有两个可见说话者的视频,我们使用了一个双说话者模型。
我们使用每个视频的单次前向传递进行分离,我们的模型支持这种操作,因为我们的网络架构从未强制施加特定的时间持续性。
- 这样可以避免需要在视频的较短片段上进行后处理和整合结果。
由于这些示例没有干净的参考音频,这些结果及其与其他方法的比较是定性评估的;它们将在我们的附录材料中呈现。
值得注意的是,我们的方法不支持实时处理,目前我们的语音增强更适合于视频后期处理阶段。
-
在我们的附录材料中的合成视频"Double Brady"凸显了我们模型对视觉信息的利用,因为仅通过音频中包含的特征语音频率在这种情况下很难进行语音分离。
-
在"嘈杂的酒吧(Noisy Bar)"场景中,我们的方法在从低信噪比混合中分离语音时显示出了一些局限性。在这种情况下,背景噪声几乎被完全抑制,但输出的语音质量明显下降。
- Sun等人[2017]观察到这一限制源于使用基于掩模的方法进行分离,而在这种情况下,直接预测去噪后的频谱图可能有助于克服这个问题。
- 在经典的语音增强情况下,即一个说话者和非语音背景噪声,我们的AV模型获得了与我们强大的AO基准模型类似的结果。我们怀疑这是因为噪声的特征频率通常与语音的特征频率明显分离,因此加入视觉信息并未提供额外的区分能力。
5.3 与先前的音频-视觉语音分离和增强工作进行比较
如果不将我们的结果与先前的音频-视觉语音分离和增强工作的结果进行比较,我们的评估将不完整。
表5中包含了在三个不同的音频-视觉数据集(Mandarin、TCD-TIMIT和CUAVE,见第2节)上进行的比较,使用了各自论文中描述的评估协议和指标。
表5:与现有音频-视觉语音分离工作的比较:我们将我们在几个数据集上的语音分离和增强结果与先前工作的结果进行了比较,使用了原始论文中报告的评估协议和客观得分。需要注意的是,先前的方法是依赖于说话者的,而我们的结果是通过使用通用的、不依赖于特定说话者的模型获得的。

报告的客观质量分数是PESQ [Rix et al. 2001]、STOI [Taal et al. 2010]和BSS eval工具包中的SDR [Vincent et al. 2006]。这些比较的定性结果可在我们的项目页面上找到。
需要注意的是,这些先前的方法要求为他们的数据集中的每个说话者单独训练一个专门的模型(说话者相关),而我们对他们的数据进行的评估是使用我们的通用AVS数据集上训练的模型(说话者无关)。尽管我们从未遇到过这些特定的说话者,但我们的结果明显优于原始论文中报告的结果,表明我们模型具有强大的泛化能力。
5.4 应用于视频转录
虽然本文的重点是语音分离和增强,但我们的方法也可以用于自动语音识别(ASR)和视频转录(video transcription)。
为了验证这个概念,我们进行了以下的定性实验。我们将“Stand-Up”视频的语音分离结果上传到YouTube,并将YouTube自动字幕生成的结果3与原始视频中混合语音的相应部分生成的结果进行了比较。对于原始“Stand-Up”视频的部分,ASR系统无法在视频的混合语音片段生成任何字幕。结果中包含了两位说话者的语音,导致了难以阅读的句子。
然而,对于我们分离后的语音结果产生的字幕明显更准确。我们在附录材料中展示了完整的字幕视频。
5.5 附加分析
我们还进行了大量实验,以更好地理解模型的行为以及其不同组件对结果的影响。
剔除实验(Ablation study)
为了更好地理解我们模型的不同部分的贡献,我们对从两个清晰说话者的混合中分离语音的任务(2S Clean)进行了剔除实验。除了剔除几个组合的网络模块(视觉和音频流,BLSTM和FC层),我们还研究了更高层次的变化,比如不同的输出掩模(幅度),减少学习的视觉特征到每个时间步的一个标量的效果,以及不同的融合方法(早期融合(early fusion))。
-
在早期融合模型中,我们没有单独的视觉和音频流,而是在输入时将两种模态组合起来。这是通过
- 使用两个全连接层将每个视觉嵌入的维度减少到与每个时间步的频谱图维度相匹配,
- 然后将视觉特征堆叠为第三个频谱图“通道”,并在整个模型中联合处理它们实现的。
为了更好地理解我们模型的不同部分的贡献,我们对从两个清晰说话者的混合中分离语音的任务(2S Clean)进行了剔除实验。除了剔除几个组合的网络模块(视觉和音频流,BLSTM和FC层),我们还研究了更高层次的变化,比如不同的输出掩模(幅度),减少学习的视觉特征到每个时间步的一个标量的效果,以及不同的融合方法(早期融合)。
-
在早期融合模型中,我们没有单独的视觉和音频流,而是在输入时将两种模态组合起来。这是通过首先使用两个全连接层将每个视觉嵌入的维度减少到与每个时间步的频谱图维度相匹配,然后将视觉特征堆叠为第三个频谱图“通道”,并在整个模型中联合处理它们实现的。
-
表6显示了我们的剔除实验的结果。该表包括使用SDR和ViSQOL [Hines等人,2015]进行评估,ViSQOL是一种旨在近似人类听众对语音质量的平均意见得分(MOS)的客观度量。ViSQOL分数是在我们测试数据的随机2000个样本子集上计算的。我们发现,SDR与分离后音频中剩余噪音的数量密切相关,而ViSQOL更好地表征输出语音的质量。有关这些得分的更多细节,请参阅附录的A部分。“Oracle” RMs和cRMs是如第4.1节所述获取的掩模,分别使用了地面真实的实值和复值频谱图。
本研究最有趣的发现是,使用实值幅度掩模而不是复值幅度掩模时,MOS的降低,以及将视觉信息压缩成每个时间步的一个标量出乎意料的有效,如下所述。
瓶颈特征(Bottleneck features)
在我们的剔除分析中,我们发现将视觉信息压缩为每个时间步的一个标量的网络(“Bottleneck (cRM)”)表现几乎与我们的完整模型(“Full model (cRM)”)相当(只差0.5dB)。后者在每个时间步使用了64个标量。
模型如何利用视觉信号?(How does the model utilize the visual signal?)
我们的模型使用人脸嵌入作为输入的视觉表示(第4.1节)。我们希望了解这些高级特征中捕获的信息,并确定模型用于分离语音的输入帧的哪些区域。为此,我们遵循类似于[Zeiler和Fergus 2014;Zhou等2014]的视觉网络感受野可视化协议。我们将该协议从2D图像扩展到3D(空间-时间)视频。更具体地说,我们使用一个空间-时间遮挡器(11px × 11px × 200ms的遮挡器(patch)4)以滑动窗口的方式。对于每个空间-时间遮挡器,我们将被遮挡的视频输入到我们的模型中,并将得到的语音分离结果Socc与原始(未被遮挡)视频的结果Sori进行比较。为了量化网络输出之间的差异,我们使用SNR,将没有遮挡的结果视为“信号”5。也就是说,对于每个空间-时间遮挡器,我们计算:
E
=
10
⋅
l
o
g
(
S
o
r
i
g
2
(
S
o
c
c
−
S
o
r
i
g
)
2
)
(1)
E=10\cdot{log(\frac{{S_{orig}}^2}{(S_{occ}-S_{orig})^2})}\tag{1}
E=10⋅log((Socc−Sorig)2Sorig2)(1)
对视频中的所有空间-时间遮挡器重复这个过程,会得到每个帧的热图。为了进行可视化,我们将热图归一化为视频的最大SNR:
E
~
=
E
m
a
x
−
E
\tilde{E}=E_{max}−E
E~=Emax−E
在
E
~
\tilde{E}
E~中,大值对应于对语音分离结果影响较大的遮挡器。
在图8中,我们展示了来自几个视频的代表性帧的热图结果(完整的热图视频可在我们的项目页面上找到)。如预期所示,对于贡献最大的人脸区域主要位于嘴巴周围,然而可视化结果显示其他区域,比如眼睛和脸颊也有一定的贡献。
图8:**模型如何利用视觉信号?**我们在来自几个视频的代表性输入帧上显示了叠加的热图,可视化不同区域对我们的语音分离结果的贡献(以分贝为单位,参见文本),从蓝色(低贡献)到红色(高贡献)。

缺失视觉信息的影响(Effect of missing visual information)
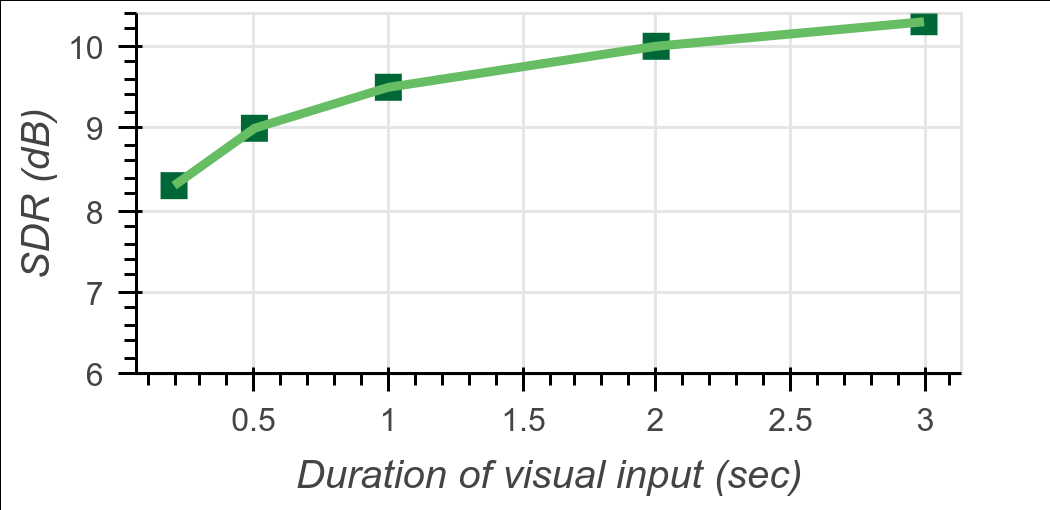
我们进一步通过逐渐去除视觉嵌入来测试视觉信息对模型的贡献。具体来说,我们首先运行模型,并使用完整的3秒视频进行评估,得到带有视觉信息的语音分离质量。然后,我们逐渐丢弃段落的两端的嵌入,并重新评估2秒、1秒、0.5秒和0.2秒的视觉持续时间的分离质量。
结果如图9所示。有趣的是,当在段落中丢弃多达2/3的视觉嵌入时,语音分离质量平均只下降了0.8 dB。这表明模型对缺失的视觉信息具有鲁棒性,在真实世界的场景中,由于头部运动或遮挡,可能会出现视觉信息的缺失。
图9:缺失视觉信息的影响:该图显示了视觉信息持续时间对于在2个干净说话者(2S clean)场景中输出SDR改进的影响。我们通过逐渐将输入的人脸嵌入从样本的两端逐渐置零来进行测试。结果显示,即使只有少数的视觉帧,也足以进行高质量的分离。
结论
我们提出了一种新颖的音频-视觉神经网络模型,用于单通道、说话人无关的语音分离。我们的模型在多种具有挑战性的场景中表现出色,包括具有背景噪声的多说话人混音。为了训练该模型,我们创建了一个新的音频-视觉数据集,其中包含从网络上收集的可见说话人和干净语音的数千小时的视频片段。我们的模型在语音分离方面取得了最先进的结果,并显示了在视频字幕和语音识别方面的潜在应用。我们还进行了大量实验,分析了我们的模型及其各个组件的行为和有效性。总体而言,我们的方法在音频-视觉语音分离和增强方面代表了重要的进展。
致谢
我们要感谢Yossi Matias和Google Research Israel对该项目的支持,以及John Hershey对我们宝贵的意见。我们还要感谢Arkady Ziefman对图表设计和视频编辑的帮助,以及Rachel Soh帮助我们获得结果中视频内容的许可。
参考文献
- T. Afouras, J. S. Chung, and A. Zisserman. 2018. 《对话:深度视听语音增强》. In arXiv:1804.04121.
- Anna Llagostera Casanovas, Gianluca Monaci, Pierre Vandergheynst, and Rémi Gribonval. 2010. 《基于稀疏冗余表示的盲音视频源分离》. IEEE多媒体交易期刊 12, 5 (2010), 358–371.
- E Colin Cherry. 1953. 《单耳和双耳识别语音的一些实验》. 美国声学学会杂志 25, 5 (1953), 975–979.
- Joon Son Chung, Andrew W. Senior, Oriol Vinyals, and Andrew Zisserman. 2016. 《野外唇读句子》. CoRR abs/1611.05358 (2016).
- Forrester Cole, David Belanger, Dilip Krishnan, Aaron Sarna, Inbar Mosseri, and William T Freeman. 2016. 《从面部身份特征合成规范化面部》. CVPR’17.
- Pierre Comon and Christian Jutten. 2010. 《盲源分离手册:独立分量分析及应用》. 学术出版社.
- Masood Delfarah and DeLiang Wang. 2017. 《混响环境中基于掩蔽的单声道语音分离的特征》. IEEE/ACM音频、语音和语言处理交易期刊 25 (2017), 1085–1094.
- Ariel Ephrat, Tavi Halperin, and Shmuel Peleg. 2017. 《从无声视频中改进的语音重建》. ICCV 2017计算机视觉工作坊.
- Hakan Erdogan, John R. Hershey, Shinji Watanabe, and Jonathan Le Roux. 2015. 《基于深度递归神经网络的相位敏感和增强语音分离》. IEEE国际声学、语音和信号处理会议(ICASSP) (2015).
- Weijiang Feng, Naiyang Guan, Yuan Li, Xiang Zhang, and Zhigang Luo. 2017. 《多模态递归神经网络的音频-视觉语音识别》. 2017年国际联合会议上的神经网络(IJCNN)。IEEE, 681–688.
- Aviv Gabbay, Ariel Ephrat, Tavi Halperin, and Shmuel Peleg. 2018. 《透过噪声看清:使用视觉派生的语音的说话人分离和增强》. IEEE国际声学、语音和信号处理会议(ICASSP) (2018).
- Aviv Gabbay, Asaph Shamir, and Shmuel Peleg. 2017. 《使用抗噪音训练的视觉语音增强》. arXiv预印本arXiv:1711.08789 (2017).
- R. Gao, R. Feris, and K. Grauman. 2018. 《通过观看未标记视频学习分离物体声音》. arXiv预印本arXiv:1804.01665 (2018).
- Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. 2017. 《音频集:音频事件的本体和人工标记数据集》. 2017年IEEE ICASSP会议文集。
- Elana Zion Golumbic, Gregory B Cogan, Charles E. Schroeder, and David Poeppel. 2013. 《视觉输入增强了“鸡尾酒会”中听觉皮层对选择性语音包络的跟踪》. 美国神经科学学会官方期刊《神经科学》33卷4期(2013),1417–26。
- Naomi Harte and Eoin Gillen. 2015. 《TCD-TIMIT:连续语音的音频-视觉语料库》. IEEE多媒体交易期刊 17, 5 (2015), 603–615。
- David F. Harwath, Antonio Torralba, and James R. Glass. 2016. 《带有视觉背景的无监督学习口语》. In NIPS.
- John Hershey, Hagai Attias, Nebojsa Jojic, and Trausti Kristjansson. 2004. 《语音处理的音频-视觉图形模型》. IEEE国际声学、语音和信号处理会议(ICASSP)。
- John R Hershey and Michael Casey. 2002. 《使用隐马尔可夫模型的音频-视觉声音分离》. Advances in Neural Information Processing Systems. 1173–1180.
- John R. Hershey, Zhuo Chen, Jonathan Le Roux, and Shinji Watanabe. 2016. 《深度聚类:分割和分离的鉴别嵌入》. IEEE国际声学、语音和信号处理会议(ICASSP) (2016),31–35。
- Andrew Hines, Eoin Gillen, Damien Kelly, Jan Skoglund, Anil C. Kokaram, and Naomi Harte. 2015. 《低比特率编解码器的客观音频质量度量ViSQOLAudio》. 《美国声学学会杂志》137卷6期(2015),EL449–55。
- Andrew Hines and Naomi Harte. 2012. 《使用神经图相似度指数测量的语音可懂度预测》. 《语音交际》54卷2期(2012),306–320。DOI: http://dx.doi.org/10.1016/j.specom.2011.09.004
- Ken Hoover, Sourish Chaudhuri, Caroline Pantofaru, Malcolm Slaney, and Ian Sturdy. 2017. 《面对声音:融合视频中的音频和视觉信号来确定说话者》. CoRR abs/1706.00079 (2017)。
- Jen-Cheng Hou, Syu-Siang Wang, Ying-Hui Lai, Jen-Chun Lin, Yu Tsao, Hsiu-Wen Chang, and Hsin-Min Wang. 2018. 《使用多模态深度卷积神经网络的音频-视觉语音增强》. 《IEEE计算智能新兴主题交易期刊》2卷2期(2018),117–128。
- Yongtao Hu, Jimmy SJ Ren, Jingwen Dai, Chang Yuan, Li Xu, and Wenping Wang. 2015. 《深度多模态说话者命名》. Proceedings of the 23rd ACM international conference on Multimedia. ACM, 1107–1110。
- Sergey Ioffe and Christian Szegedy. 2015. 《批量标准化:通过减少内部协变量转移加速深度网络训练》. 《国际机器学习会议》。
- Yusuf Isik, Jonathan Le Roux, Zhuo Chen, Shinji Watanabe, and John R Hershey. 2016. 《使用深度聚类的单声道多说话者分离》. Interspeech (2016),545–549。
- Faheem Khan. 2016. 《音频-视觉说话者分离》. 博士学位论文。东安格利亚大学。
- Wei Ji Ma, Xiang Zhou, Lars A. Ross, John J. Foxe, and Lucas C. Parra. 2009. 《在中等噪声下,通过高维特征空间的贝叶斯解释辅助词汇识别》. PLoS ONE 4卷(2009),233–252。
- Josh H McDermott. 2009. 《鸡尾酒会问题》. 《当代生物学》19卷22期(2009),R1024–R1027。
- Gianluca Monaci. 2011. 《实时音频视觉说话者定位的发展》. Signal Processing Conference,2011年第19届欧洲。IEEE,1055–1059。
- Youssef Mroueh, Etienne Marcheret, and Vaibhava Goel. 2015. 《用于音频-视觉语音识别的深度多模态学习》. In 2015年IEEE国际声学、语音和信号处理会议(ICASSP)。IEEE,2130–2134。
- Jiquan Ngiam, Aditya Khosla, Mingyu Kim, Juhan Nam, Honglak Lee, and Andrew Y. Ng. 2011. 《多模态深度学习》. In ICML.
- Andrew Owens and Alexei A Efros. 2018. 《使用自监督多感官特征的音频-视觉场景分析》。 (2018)。
- Eric K. Patterson, Sabri Gurbuz, Zekeriya Tufekci, and John N. Gowdy. 2002. 《CUAVE多模态语音语料库的移动说话人、说话人独立特征研究和基线结果》. 《欧拉西亚先进信号处理期刊》2002卷(2002),1189–1201。
- Jie Pu, Yannis Panagakis, Stavros Petridis, and Maja Pantic. 2017. 《使用低秩和稀疏性的音频-视觉对象定位和分离》. In 2017年IEEE国际声学、语音和信号处理会议(ICASSP)。IEEE,2901–2905。
- Bertrand Rivet, Wenwu Wang, Syed M. Naqvi, and Jonathon A. Chambers. 2014. 《音频-视觉说话者分离:关键方法概述》. IEEE信号处理杂志31期(2014),125–134。
- Antony W Rix, John G Beerends, Michael P Hollier, and Andries P Hekstra. 2001. 《语音质量的感知评估(PESQ)——一种用于电话网络和编解码器语音质量评估的新方法》. 《声学、语音和信号处理》2001年国际会议(ICASSP’01)。IEEE,749–752。
- Ethan M Rudd, Manuel Günther, and Terrance E Boult. 2016. 《Moon:用于识别面部属性的混合目标优化网络》. 《欧洲计算机视觉大会》。Springer,19–35。
- J S Garofolo, Lori Lamel, W M Fisher, Jonathan Fiscus, D S. Pallett, N L. Dahlgren, and V Zue. 1992. 《TIMIT语音语音语料库》。 (1992)。
- Lei Sun, Jun Du, Li-Rong Dai, and Chin-Hui Lee. 2017. 《基于LSTM-RNN的多目标深度学习语音增强》。在HSCMA。
- Cees H Taal, Richard C Hendriks, Richard Heusdens, and Jesper Jensen. 2010. 《用于时频加权噪声语音的短时客观可懂性测量》。在2010年IEEE国际声学、语音和信号处理会议(ICASSP)。IEEE,4214–4217。
- Emmanuel Vincent, Jon Barker, Shinji Watanabe, Jonathan Le Roux, Francesco Nesta, and Marco Matassoni. 2013. 《第二届“钟声”语音分离和识别挑战:数据集、任务和基线》。在2013年IEEE国际声学、语音和信号处理会议(ICASSP)。IEEE,126–130。
- E. Vincent, R. Gribonval, and C. Fevotte. 2006. 《盲音频源分离的性能测量》。《音频、语音和语言处理的交易》14卷4期(2006),1462–1469。
- DeLiang Wang and Jitong Chen. 2017. 《基于深度学习的监督语音分离:综述》。CoRR abs/1708.07524 (2017)。
- Yuxuan Wang, Arun Narayanan, and DeLiang Wang. 2014. 《用于监督语音分离的训练目标》。IEEE/ACM音频、语音和语言处理的交易(TASLP) 22卷12期(2014),1849–1858。
- Ziteng Wang, Xiaofei Wang, Xu Li, Qiang Fu, and Yonghong Yan. 2016. 《理想掩码的Oracle性能调查》。在IWAENC。
- Felix Weninger, Hakan Erdogan, Shinji Watanabe, Emmanuel Vincent, Jonathan Le Roux, John R. Hershey, and Björn W. Schuller. 2015. 《使用LSTM递归神经网络进行语音增强及其在噪声鲁棒性ASR中的应用》。在LVA/ICA。
- Dong Yu, Morten Kolbæk, Zheng-Hua Tan, and Jesper Jensen. 2017. 《用于说话者无关多说话者语音分离的深度模型的排列不变性训练》。在IEEE国际声学、语音和信号处理会议(ICASSP) (2017),241–245。
- Matthew D Zeiler and Rob Fergus. 2014. 《可视化和理解卷积网络》。在欧洲计算机视觉大会。Springer,818–833。
- Hang Zhao, Chuang Gan, Andrew Rouditchenko, Carl Vondrick, Josh McDermott, and Antonio Torralba. 2018. 《像素的声音》。 (2018)。
- Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. 2014. 《深度场景CNN中出现的物体探测器》。arXiv预印本arXiv:1412.6856 (2014)。
REFERENCES
- T. Afouras, J. S. Chung, and A. Zisserman. 2018. The Conversation: Deep Audio-Visual Speech Enhancement. In arXiv:1804.04121.
- Anna Llagostera Casanovas, Gianluca Monaci, Pierre Vandergheynst, and Rémi Gribonval. 2010. Blind audiovisual source separation based on sparse redundant representations. IEEE Transactions on Multimedia 12, 5 (2010), 358–371.
- E Colin Cherry. 1953. Some experiments on the recognition of speech, with one and with two ears. The Journal of the acoustical society of America 25, 5 (1953), 975–979.
- Joon Son Chung, Andrew W. Senior, Oriol Vinyals, and Andrew Zisserman. 2016. Lip Reading Sentences in the Wild. CoRR abs/1611.05358 (2016).
- Forrester Cole, David Belanger, Dilip Krishnan, Aaron Sarna, Inbar Mosseri, and William T Freeman. 2016. Synthesizing normalized faces from facial identity features. In CVPR’17.
- Pierre Comon and Christian Jutten. 2010. Handbook of Blind Source Separation: Independent component analysis and applications. Academic press.
- Masood Delfarah and DeLiang Wang. 2017. Features for Masking-Based Monaural Speech Separation in Reverberant Conditions. IEEE/ACM Transactions on Audio, Speech, and Language Processing 25 (2017), 1085–1094.
- Ariel Ephrat, Tavi Halperin, and Shmuel Peleg. 2017. Improved Speech Reconstruction from Silent Video. In ICCV 2017 Workshop on Computer Vision for Audio-Visual Media.
- Hakan Erdogan, John R. Hershey, Shinji Watanabe, and Jonathan Le Roux. 2015. Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2015).
- Weijiang Feng, Naiyang Guan, Yuan Li, Xiang Zhang, and Zhigang Luo. 2017. Audio-visual speech recognition with multimodal recurrent neural networks. In Neural Networks (IJCNN), 2017 International Joint Conference on. IEEE, 681–688.
- Aviv Gabbay, Ariel Ephrat, Tavi Halperin, and Shmuel Peleg. 2018. Seeing Through Noise: Speaker Separation and Enhancement using Visually-derived Speech. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2018).
- Aviv Gabbay, Asaph Shamir, and Shmuel Peleg. 2017. Visual Speech Enhancement using Noise-Invariant Training. arXiv preprint arXiv:1711.08789 (2017).
- R. Gao, R. Feris, and K. Grauman. 2018. Learning to Separate Object Sounds by Watching Unlabeled Video. arXiv preprint arXiv:1804.01665 (2018).
- Jort F. Gemmeke, Daniel P. W. Ellis, Dylan Freedman, Aren Jansen, Wade Lawrence, R. Channing Moore, Manoj Plakal, and Marvin Ritter. 2017. Audio Set: An ontology and human-labeled dataset for audio events. In Proc. IEEE ICASSP 2017.
- Elana Zion Golumbic, Gregory B Cogan, Charles E. Schroeder, and David Poeppel. 2013. Visual input enhances selective speech envelope tracking in auditory cortex at a “cocktail party”. The Journal of neuroscience: the official journal of the Society for Neuroscience 33 4 (2013), 1417–26.
- Naomi Harte and Eoin Gillen. 2015. TCD-TIMIT: An audio-visual corpus of continuous speech. IEEE Transactions on Multimedia 17, 5 (2015), 603–615.
- David F. Harwath, Antonio Torralba, and James R. Glass. 2016. Unsupervised Learning of Spoken Language with Visual Context. In NIPS.
- John Hershey, Hagai Attias, Nebojsa Jojic, and Trausti Kristjansson. 2004. Audio-visual graphical models for speech processing. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP).
- John R Hershey and Michael Casey. 2002. Audio-visual sound separation via hidden Markov models. In Advances in Neural Information Processing Systems. 1173–1180.
- John R. Hershey, Zhuo Chen, Jonathan Le Roux, and Shinji Watanabe. 2016. Deep clustering: Discriminative embeddings for segmentation and separation. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2016), 31–35.
- Andrew Hines, Eoin Gillen, Damien Kelly, Jan Skoglund, Anil C. Kokaram, and Naomi Harte. 2015. ViSQOLAudio: An objective audio quality metric for low bitrate codecs. The Journal of the Acoustical Society of America 137 6 (2015), EL449–55.
- Andrew Hines and Naomi Harte. 2012. Speech Intelligibility Prediction Using a Neurogram Similarity Index Measure. Speech Commun. 54, 2 (Feb. 2012), 306–320. DOI: http://dx.doi.org/10.1016/j.specom.2011.09.004
- Ken Hoover, Sourish Chaudhuri, Caroline Pantofaru, Malcolm Slaney, and Ian Sturdy. 2017. Putting a Face to the Voice: Fusing Audio and Visual Signals Across a Video to Determine Speakers. CoRR abs/1706.00079 (2017).
- Jen-Cheng Hou, Syu-Siang Wang, Ying-Hui Lai, Jen-Chun Lin, Yu Tsao, Hsiu-Wen Chang, and Hsin-Min Wang. 2018. Audio-Visual Speech Enhancement Using Multi-modal Deep Convolutional Neural Networks. IEEE Transactions on Emerging Topics in Computational Intelligence 2, 2 (2018), 117–128.
- Yongtao Hu, Jimmy SJ Ren, Jingwen Dai, Chang Yuan, Li Xu, and Wenping Wang. 2015. Deep multimodal speaker naming. In Proceedings of the 23rd ACM international conference on Multimedia. ACM, 1107–1110.
- Sergey Ioffe and Christian Szegedy. 2015. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In ICML.
- Yusuf Isik, Jonathan Le Roux, Zhuo Chen, Shinji Watanabe, and John R Hershey. 2016. Single-Channel Multi-Speaker Separation Using Deep Clustering. Interspeech (2016), 545–549.
- Faheem Khan. 2016. Audio-visual speaker separation. Ph.D. Dissertation. University of East Anglia.
- Wei Ji Ma, Xiang Zhou, Lars A. Ross, John J. Foxe, and Lucas C. Parra. 2009. Lip-Reading Aids Word Recognition Most in Moderate Noise: A Bayesian Explanation Using High-Dimensional Feature Space. PLoS ONE 4 (2009), 233 – 252.
- Josh H McDermott. 2009. The cocktail party problem. Current Biology 19, 22 (2009), R1024–R1027.
- Gianluca Monaci. 2011. Towards real-time audiovisual speaker localization. In Signal Processing Conference, 2011 19th European. IEEE, 1055–1059.
- Youssef Mroueh, Etienne Marcheret, and Vaibhava Goel. 2015. Deep multimodal learning for audio-visual speech recognition. In Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on. IEEE, 2130–2134.
- Jiquan Ngiam, Aditya Khosla, Mingyu Kim, Juhan Nam, Honglak Lee, and Andrew Y. Ng. 2011. Multimodal Deep Learning. In ICML.
- Andrew Owens and Alexei A Efros. 2018. Audio-Visual Scene Analysis with Self-Supervised Multisensory Features. (2018).
- Eric K. Patterson, Sabri Gurbuz, Zekeriya Tufekci, and John N. Gowdy. 2002. Moving-Talker, Speaker-Independent Feature Study, and Baseline Results Using the CUAVE Multimodal Speech Corpus. EURASIP J. Adv. Sig. Proc. 2002 (2002), 1189–1201.
- Jie Pu, Yannis Panagakis, Stavros Petridis, and Maja Pantic. 2017. Audio-visual object localization and separation using low-rank and sparsity. In Acoustics, Speech and Signal Processing (ICASSP), 2017 IEEE International Conference on. IEEE, 2901–2905.
- Bertrand Rivet, Wenwu Wang, Syed M. Naqvi, and Jonathon A. Chambers. 2014. Audio-visual Speech Source Separation: An overview of key methodologies. IEEE Signal Processing Magazine 31 (2014), 125–134.
- Antony W Rix, John G Beerends, Michael P Hollier, and Andries P Hekstra. 2001. Perceptual evaluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs. In Acoustics, Speech, and Signal Processing, 2001. Proceedings.(ICASSP’01). 2001 IEEE International Conference on, Vol. 2. IEEE, 749–752.
- Ethan M Rudd, Manuel Günther, and Terrance E Boult. 2016. Moon: A mixed objective optimization network for the recognition of facial attributes. In European Conference on Computer Vision. Springer, 19–35.
- J S Garofolo, Lori Lamel, W M Fisher, Jonathan Fiscus, D S. Pallett, N L. Dahlgren, and V Zue. 1992. TIMIT Acoustic-phonetic Continuous Speech Corpus. (11 1992).
- Lei Sun, Jun Du, Li-Rong Dai, and Chin-Hui Lee. 2017. Multiple-target deep learning for LSTM-RNN based speech enhancement. In HSCMA.
- Cees H Taal, Richard C Hendriks, Richard Heusdens, and Jesper Jensen. 2010. A short-time objective intelligibility measure for time-frequency weighted noisy speech. In Acoustics Speech and Signal Processing (ICASSP), 2010 IEEE International Conference on. IEEE, 4214–4217.
- Emmanuel Vincent, Jon Barker, Shinji Watanabe, Jonathan Le Roux, Francesco Nesta, and Marco Matassoni. 2013. The second ’chime’ speech separation and recognition challenge: Datasets, tasks and baselines. 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (2013), 126–130.
- E. Vincent, R. Gribonval, and C. Fevotte. 2006. Performance Measurement in Blind Audio Source Separation. Trans. Audio, Speech and Lang. Proc. 14, 4 (2006), 1462–1469.
- DeLiang Wang and Jitong Chen. 2017. Supervised Speech Separation Based on Deep Learning: An Overview. CoRR abs/1708.07524 (2017).
- Yuxuan Wang, Arun Narayanan, and DeLiang Wang. 2014. On training targets for supervised speech separation. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP) 22, 12 (2014), 1849–1858.
- Ziteng Wang, Xiaofei Wang, Xu Li, Qiang Fu, and Yonghong Yan. 2016. Oracle performance investigation of the ideal masks. In IWAENC.
- Felix Weninger, Hakan Erdogan, Shinji Watanabe, Emmanuel Vincent, Jonathan Le Roux, John R. Hershey, and Björn W. Schuller. 2015. Speech Enhancement with LSTM Recurrent Neural Networks and its Application to Noise-Robust ASR. In LVA/ICA.
- Dong Yu, Morten Kolbæk, Zheng-Hua Tan, and Jesper Jensen. 2017. Permutation invariant training of deep models for speaker-independent multi-talker speech separation. IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2017), 241–245.
- Matthew D Zeiler and Rob Fergus. 2014. Visualizing and understanding convolutional networks. In European conference on computer vision. Springer, 818–833.
- Hang Zhao, Chuang Gan, Andrew Rouditchenko, Carl Vondrick, Josh McDermott, and Antonio Torralba. 2018. The Sound of Pixels. (2018).
- Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. 2014. Object detectors emerge in deep scene cnns. arXiv preprint arXiv:1412.6856 (2014).
A 用于评估分离质量的客观度量指标
A.1 信噪比(SDR)
信号与失真比(Signal-to-Distortion Ratio,SDR)由Vincent等人于2006年引入,是一系列用于评估盲音频源分离(BASS)算法的指标之一,其中原始源信号作为基准事实存在。这些指标基于将每个估计的源信号分解为真实源部分(s_target)和对应于干扰(e_interf)、加性噪声(e_noise)以及算法造成的伪迹(e_artif)的误差项。
SDR是最通用的分数,常用于报告语音分离算法的性能。它以分贝(dB)为单位衡量,定义如下:
S
D
R
:
=
10
⋅
log
10
(
∣
∣
S
t
a
r
g
e
t
∣
∣
2
∣
∣
e
i
n
t
e
r
f
+
e
n
o
i
s
e
+
e
a
r
t
i
f
∣
∣
2
)
(2)
SDR:=10\cdot\log_{10}(\frac{||S_{target}||^{2}}{||e_{interf}+e_{noise}+e_ {artif}||^ {2}})\tag{2}
SDR:=10⋅log10(∣∣einterf+enoise+eartif∣∣2∣∣Starget∣∣2)(2)
我们将读者引用到原始论文中,以获取有关信号分解成其组成部分的详细信息。我们发现这个指标与分离后剩余噪声的数量之间有很好的相关性。
A.2 虚拟语音质量客观监听器(ViSQOL)
虚拟语音质量客观监听器(ViSQOL)是一种客观语音质量模型,由Hines等人[2015]提出。该指标使用参考(r)和降质(d)语音信号之间的谱时相似度测量来建模人类的语音质量感知,并基于Neurogram相似性指数测量(NSIM)[Hines和Harte 2012]。 NSIM的定义如下:
N
S
I
M
(
r
,
d
)
=
2
μ
r
μ
d
+
C
1
μ
r
2
+
μ
d
2
+
C
1
⋅
σ
r
d
+
C
2
σ
r
σ
d
+
C
2
(3)
NSIM(r,d)=\frac{2\mu_{r}\mu_{d}+C_{1}}{\mu_{r}^{2}+\mu^{2}_{d}+C_{1}}\cdot\frac{\sigma _{rd}+C_{2}}{\sigma_{r}\sigma_{d}+C_{2}}\tag{3}
NSIM(r,d)=μr2+μd2+C12μrμd+C1⋅σrσd+C2σrd+C2(3)
在这里,µs和σs分别是参考信号和降质信号之间的均值和相关系数,是在频谱图之间计算得出的。在ViSQOL中,NSIM是在参考信号的频谱图块及其对应的来自降质信号的图块上计算的。然后,该算法将NSIM得分聚合并转化为介于1到5之间的平均意见得分(MOS)。
DR是最通用的分数,常用于报告语音分离算法的性能。它以分贝(dB)为单位衡量,定义如下:
S
D
R
:
=
10
⋅
log
10
(
∣
∣
S
t
a
r
g
e
t
∣
∣
2
∣
∣
e
i
n
t
e
r
f
+
e
n
o
i
s
e
+
e
a
r
t
i
f
∣
∣
2
)
(2)
SDR:=10\cdot\log_{10}(\frac{||S_{target}||^{2}}{||e_{interf}+e_{noise}+e_ {artif}||^ {2}})\tag{2}
SDR:=10⋅log10(∣∣einterf+enoise+eartif∣∣2∣∣Starget∣∣2)(2)
我们将读者引用到原始论文中,以获取有关信号分解成其组成部分的详细信息。我们发现这个指标与分离后剩余噪声的数量之间有很好的相关性。
A.2 虚拟语音质量客观监听器(ViSQOL)
虚拟语音质量客观监听器(ViSQOL)是一种客观语音质量模型,由Hines等人[2015]提出。该指标使用参考(r)和降质(d)语音信号之间的谱时相似度测量来建模人类的语音质量感知,并基于Neurogram相似性指数测量(NSIM)[Hines和Harte 2012]。 NSIM的定义如下:
N
S
I
M
(
r
,
d
)
=
2
μ
r
μ
d
+
C
1
μ
r
2
+
μ
d
2
+
C
1
⋅
σ
r
d
+
C
2
σ
r
σ
d
+
C
2
(3)
NSIM(r,d)=\frac{2\mu_{r}\mu_{d}+C_{1}}{\mu_{r}^{2}+\mu^{2}_{d}+C_{1}}\cdot\frac{\sigma _{rd}+C_{2}}{\sigma_{r}\sigma_{d}+C_{2}}\tag{3}
NSIM(r,d)=μr2+μd2+C12μrμd+C1⋅σrσd+C2σrd+C2(3)
在这里,µs和σs分别是参考信号和降质信号之间的均值和相关系数,是在频谱图之间计算得出的。在ViSQOL中,NSIM是在参考信号的频谱图块及其对应的来自降质信号的图块上计算的。然后,该算法将NSIM得分聚合并转化为介于1到5之间的平均意见得分(MOS)。
https://cloud.google.com/vision/ ↩︎
这样的混合物很好地模拟了我们数据集中的干扰类型,通常涉及单个说话者受到非语音声音(如观众鼓掌或开场音乐)的干扰。 ↩︎
https://support.google.com/youtube/answer/6373554?hl=en ↩︎
我们使用200毫秒的长度来覆盖典型的音素持续时间范围:30-200毫秒。 ↩︎
我们建议读者参考补充材料,以验证我们对非遮挡视频进行语音分离后的结果,我们将其视为在这个例子中“正确”的结果,确实是准确的。 ↩︎




![[Docker实现测试部署CI/CD----Jenkins集成相关服务器(3)]](https://img-blog.csdnimg.cn/a403a6ebee2949b2bec1f6a16de79589.png)