以beam search为例,详解transformers中generate方法(下)
- 1. beam search原理回顾
- 2. 代码流程概览
- 3. BeamSearchScorer
- 4. BeamHypotheses
- 5. beam_search过程
- 5.1 beam score初始化
- 5.2 准备输入
- 5.3 前向forward
- 5.4 计算下一个step每个token的得分
- 5.5 选择next token
- 5.6 更新beam状态
- 5.7 后处理finalize
- 6. beam sample
- 7. 总结
在上一篇博客中,对generate方法的基本流程逻辑进行了介绍,本文将继续之前的内容,介绍最常用的采样策略beam search是如何实现的。
1. beam search原理回顾
Beam search的原理并不复杂,可以理解为在Greedy search的基础上扩大了搜索范围。Greedy search在每一步只保留概率最大的top-1的结果,而beam search则是在此基础上,每一步保留了beam_size个结果。
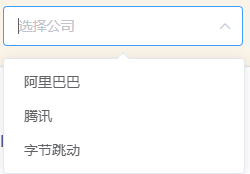
例如,词表空间内总共有这几个token:[‘早’, ‘上’, ‘好’]。设置k=2,则在每一步的生成中,保留概率最大的2个结果如图所示。

2. 代码流程概览
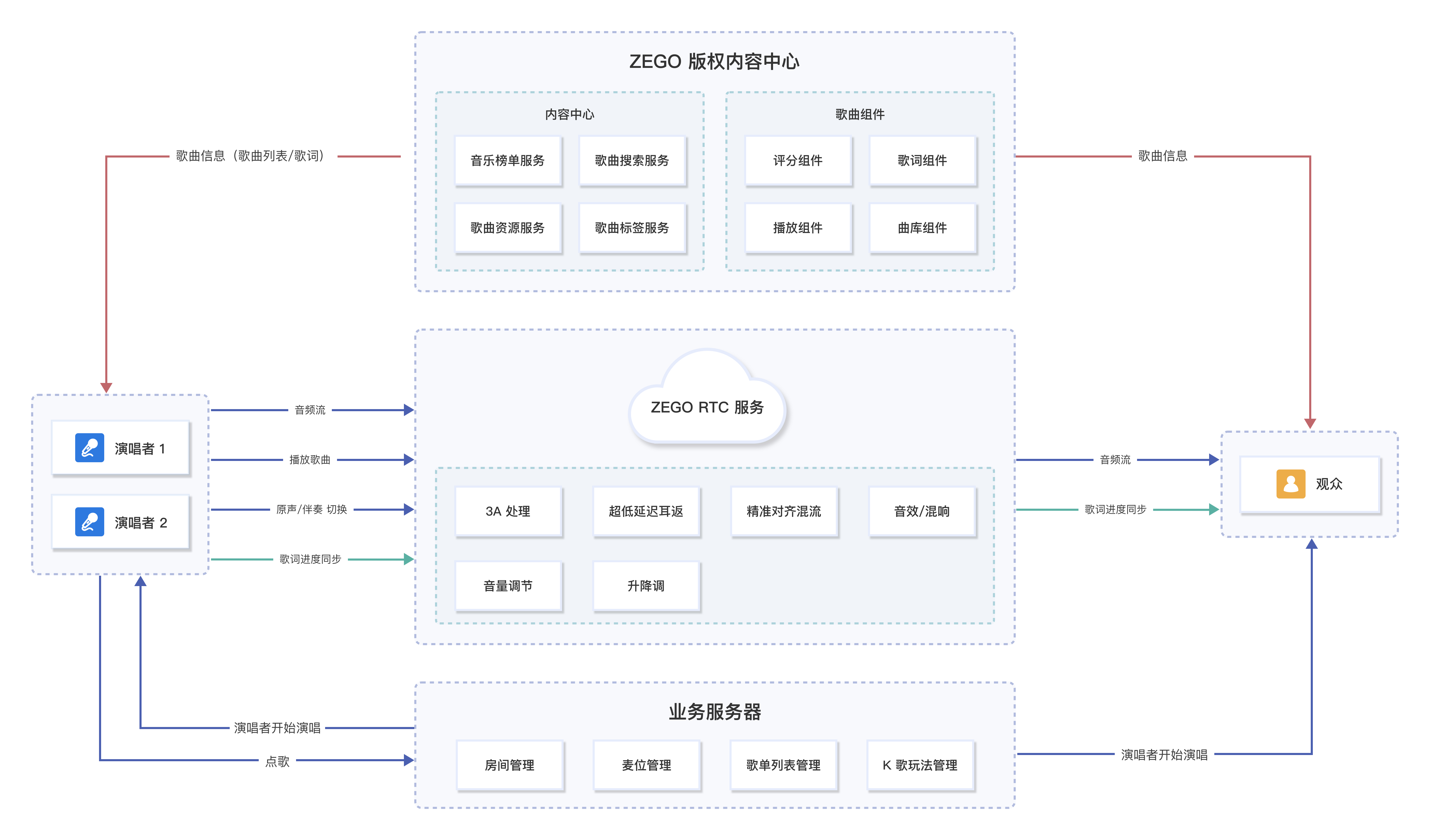
为了帮助大家阅读代码,这里把这部分代码的整体逻辑进行一下梳理,如下图所示:

总的来说,生成过程中不断重复调用模型的forward()计算出logits,以及调用BeamSearchScorer的process()来计算下一个位置每个token出现的得分,来生成下一个token及其概率分布,直到满足终止条件,结束生成。
3. BeamSearchScorer
BeamSearchScorer是在生成过程进行状态维护的类,它的作用是用来更新Beam得分,以及判断生成过程是否结束等。在这一节中,简单了解一下这个类的构造,具体的使用方法会在本篇的第5节中,结合beam search的整个流程的推进,进行更加详细的介绍。
先简单解释一下其参数:
| 参数名 | 类型 | 含义 |
|---|---|---|
| batch_size | int | 批量生成时一次处理多少条数据 |
| num_beams | int | 每一条数据在生成时保留几个beam |
| device | torch.device | cpu or cuda |
| length_penalty | Optional[float] | 控制倾向于生成更长的句子还是更短的句子 |
| do_early_stopping | Optional[Union[bool, str]] | 早停机制,是否生成达到num_beam后立即停止 |
| num_beam_hyps_to_keep | int | 最终返回多少个beam |
| num_beam_groups | int | 把所有的beam按照差异度分成多少组 |
| max_length | int | 生成的最大长度 |
这个类除了构造方法之外,只有两个方法和一个属性:
@property
def is_done(self) -> bool:
def process(
self,
input_ids: torch.LongTensor,
next_scores: torch.FloatTensor,
next_tokens: torch.LongTensor,
next_indices: torch.LongTensor,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[Union[int, List[int]]] = None,
beam_indices: Optional[torch.LongTensor] = None,
) -> Tuple[torch.Tensor]:
def finalize(
self,
input_ids: torch.LongTensor,
final_beam_scores: torch.FloatTensor,
final_beam_tokens: torch.LongTensor,
final_beam_indices: torch.LongTensor,
max_length: int,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[Union[int, List[int]]] = None,
beam_indices: Optional[torch.LongTensor] = None,
) -> Tuple[torch.LongTensor]:
-
其中is_done用来记录是否batch中所有数据都已经生成结束;
-
process是生成的每一个step都需要执行的状态更新过程,属于生成中的主干部分;
-
finalize是整个生成过程所有step都已经结束之后(出现EOS或达到stopping_criteria的终止条件),最终的后处理加工。
除此之外,这个类还有两个成员需要注意:
self.group_size是按照差异性对beam分组时,每一组的beam数量:
self.group_size = self.num_beams // self.num_beam_groups
self._beam_hyps是一组容器,用来容纳得分最高的 n n n个beam:
self._beam_hyps = [
BeamHypotheses(
num_beams=self.num_beams,
length_penalty=self.length_penalty,
early_stopping=self.do_early_stopping,
max_length=max_length,
)
for _ in range(batch_size)
]
接下来在第4节中,简单介绍一下这个BeamHypotheses类。
4. BeamHypotheses
BeamHypotheses,直接翻译过来就是“假说”,这个名称很容易引起迷惑,但其实把它看做是一个容器就好了,其容纳的内容就是 n n n个得分最高的beam。batch中的每个样本,对应一个BeamHypotheses。
从构造方法可以看出,其自身除了一个self.beams用来容纳得分最高的beam之外,还有若干固有的属性:
class BeamHypotheses:
def __init__(self, num_beams: int, length_penalty: float, early_stopping: bool, max_length: Optional[int] = None):
"""
Initialize n-best list of hypotheses.
"""
self.length_penalty = length_penalty # 与BeamScorer的length_penalty是同一个东西,用来控制倾向于生成长序列还是短序列
self.early_stopping = early_stopping # 与BeamScorer的early_stopping是同一个,控制是否采用早停机制
self.max_length = max_length # 与BeamScorer的max_length是同一个,控制生成序列的最大长度
self.num_beams = num_beams # 与BeamScorer的num_beams是同一个,生成过程中保留多少个beam
self.beams = [] # 在生成过程中,用来容纳至多num_beams个beam
self.worst_score = 1e9 # 当前状态下最差一个beam的得分
if not isinstance(self.early_stopping, bool) and self.max_length is None:
raise ValueError(
"When `do_early_stopping` is set to a string, `max_length` must be defined. Ensure it is passed to the"
" BeamScorer class instance at initialization time."
)
def __len__(self):
"""
Number of hypotheses in the list.
"""
return len(self.beams)
然后看一下BeamHypotheses的两个核心方法,add和is_done:
add方法用来将一个beam(对应的容器)添加到整个列表中:
def add(self, hyp: torch.LongTensor, sum_logprobs: float, beam_indices: Optional[torch.LongTensor] = None):
"""
Add a new hypothesis to the list.
"""
score = sum_logprobs / (hyp.shape[-1] ** self.length_penalty)
if len(self) < self.num_beams or score > self.worst_score:
self.beams.append((score, hyp, beam_indices))
if len(self) > self.num_beams:
# 如果超了设置的beam数量,则按照分数从小到大对beam进行排序
# 删除分数最小的对应的beam,然后把最小的分数更新
sorted_next_scores = sorted([(s, idx) for idx, (s, _, _) in enumerate(self.beams)])
del self.beams[sorted_next_scores[0][1]]
self.worst_score = sorted_next_scores[1][0]
else:
self.worst_score = min(score, self.worst_score)
is_done方法用来判断是否所有beam都已经完成了生成:
def is_done(self, best_sum_logprobs: float, cur_len: int) -> bool:
"""
If there are enough hypotheses and that none of the hypotheses being generated can become better than the worst
one in the heap, then we are done with this sentence.
"""
if len(self) < self.num_beams:
return False
# `True`: stop as soon as at least `num_beams` hypotheses are finished
if self.early_stopping is True:
return True
# `False`: heuristic -- compute best possible score from `cur_len`, even though it is not entirely accurate
# when `length_penalty` is positive. See the discussion below for more details.
# https://github.com/huggingface/transformers/pull/20901#issuecomment-1369845565
elif self.early_stopping is False:
highest_attainable_score = best_sum_logprobs / cur_len**self.length_penalty
ret = self.worst_score >= highest_attainable_score
return ret
# `"never"`: compute the best possible score, depending on the signal of `length_penalty`
else:
# `length_penalty` > 0.0 -> max denominator is obtaned from `max_length`, not from `cur_len` -> min
# abs(`highest_attainable_score`) is obtained -> `highest_attainable_score` is negative, hence we obtain
# its max this way
if self.length_penalty > 0.0:
highest_attainable_score = best_sum_logprobs / self.max_length**self.length_penalty
# the opposite logic applies here (max `highest_attainable_score` from `cur_len`)
else:
highest_attainable_score = best_sum_logprobs / cur_len**self.length_penalty
ret = self.worst_score >= highest_attainable_score
return ret
5. beam_search过程
beam_search与beam_sample分别对应了beam_gen_mode与beam_sample_gen_mode两个模式的主流程,二者的区别不是很大,先来看beam_search。
def beam_search(
self,
input_ids: torch.LongTensor,
beam_scorer: BeamScorer,
logits_processor: Optional[LogitsProcessorList] = None,
stopping_criteria: Optional[StoppingCriteriaList] = None,
max_length: Optional[int] = None,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[Union[int, List[int]]] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_scores: Optional[bool] = None,
return_dict_in_generate: Optional[bool] = None,
synced_gpus: Optional[bool] = False,
**model_kwargs,
) -> Union[BeamSearchOutput, torch.LongTensor]:
其中这些输入参数,多数在前一篇博客中已经介绍过,这里需要注意的是BeamScorer,这个类在本文的3.2中进行了详细的介绍,它是一个用来在生成过程中,对每一个step的概率得分进行计算,并且判断生成过程是否结束。
在这个方法中,有一个while true的循环,是其主体部分,也是beam search核心逻辑的体现。在这个while之前的部分基本都是些实例化初始化的内容,理解起来没有什么困难。唯一需要额外注意的,应该是beam score的初始化问题。
5.1 beam score初始化
beam score的初始化是一个比较细节的问题,并且是新版的代码对其进行了改进。
理论上,对于beam search的过程,需要维护一个beam score来记录生成过程中每个beam的得分即可,也就是维护一个(batch_size, num_beams)的tensor,然而在代码的实现中,却有这样一个细节:
# initialise score of first beam with 0 and the rest with -1e9. This makes sure that only tokens
# of the first beam are considered to avoid sampling the exact same tokens across all beams.
beam_scores = torch.zeros((batch_size, num_beams), dtype=torch.float, device=input_ids.device)
beam_scores[:, 1:] = -1e9
beam_scores = beam_scores.view((batch_size * num_beams,))
即batch中的每一条,对应的要生成的所有beam中,只有第1个beam的得分初始化为0,其余beam全部都初始化为-inf。代码的注释也对这样的用意进行了解释:防止在生成过程中,所有的beam产生的结果都是一样的。
这里举一个例子来对此进行说明。
假如有这样的场景,有这样的一个句子作为开头:“我的家在”,需要模型生成接下来的内容。
那么在下一个step,需要根据现有的序列“我的家在”,来计算词表中所有词的得分。
假如beam_size为2,那么就会保留了得分最高的两个,此时我们期望得到的两个beam可能分别为:
beam 1:“我的家在东”
beam 2:“我的家在北”
然后再一个step,这两个beam分别变成了:
beam 1:“我的家在东北”
beam 2:“我的家在北京”
然而实际情况却并非如此,实际上,每个beam是一个容器类BeamHypotheses,
在计算时,第一个beam的
下面直接通过while循环来看beam search的主体逻辑。
5.2 准备输入
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
prepare_inputs_for_generation这个方法在GenerationMixin中没有定义,需要在具体的模型中定义,举一个最简单的例子,在BART中,该方法仅仅是将(input_ids, **model_kwargs)做了简单的整理,而没有做更多的处理:
# 代码位置:
# transformers.models.bart.modeling_bart.py
def prepare_inputs_for_generation(
self,
decoder_input_ids,
past_key_values=None,
attention_mask=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
use_cache=None,
encoder_outputs=None,
**kwargs,
):
# cut decoder_input_ids if past_key_values is used
if past_key_values is not None:
decoder_input_ids = decoder_input_ids[:, -1:]
return {
"input_ids": None, # encoder_outputs is defined. input_ids not needed
"encoder_outputs": encoder_outputs,
"past_key_values": past_key_values,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": decoder_attention_mask,
"head_mask": head_mask,
"decoder_head_mask": decoder_head_mask,
"cross_attn_head_mask": cross_attn_head_mask,
"use_cache": use_cache, # change this to avoid caching (presumably for debugging)
}
而对于某些模型,则会对模型的输入提前做一些预处理,而预处理的部分就会写在prepare_inputs_for_generation中,例如ChatGLM。
5.3 前向forward
有了输入之后,自然要将输入传输给模型进行计算,也就是网络的前向传播阶段,这里的self是调用自身,也就是GenerationMixin这个类,而我们在之前的分析中知道,其实这个类是被实际调用的模型所继承的,所以实际上这里是使用了生成模型的forward方法。
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)
所以这个outputs,就是包含了loss,logits,以及可能包含attention与past_v_k等各种信息的计算结果。
还是以BART为例,在BartForConditionalGeneration可以看到,它主要就是先经过了transformer网络,得到一个形状为(seq_len, bsz, hidden)的hidden_states,然后将其映射到词表上,就得到了在词表空间上的概率分布,形状为(bsz, seq_len, vocab),也就是常说的logits。多数ConditionalGeneration模型都是这样的一个套路。
# 代码位置:
# transformers.models.bart.modeling_bart.py
def forward(
self,
input_ids: torch.LongTensor = None,
attention_mask: Optional[torch.Tensor] = None,
decoder_input_ids: Optional[torch.LongTensor] = None,
decoder_attention_mask: Optional[torch.LongTensor] = None,
head_mask: Optional[torch.Tensor] = None,
decoder_head_mask: Optional[torch.Tensor] = None,
cross_attn_head_mask: Optional[torch.Tensor] = None,
encoder_outputs: Optional[List[torch.FloatTensor]] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
decoder_inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.LongTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, Seq2SeqLMOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
(masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
Returns:
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if labels is not None:
if use_cache:
logger.warning("The `use_cache` argument is changed to `False` since `labels` is provided.")
use_cache = False
if decoder_input_ids is None and decoder_inputs_embeds is None:
decoder_input_ids = shift_tokens_right(
labels, self.config.pad_token_id, self.config.decoder_start_token_id
)
outputs = self.model(
input_ids,
attention_mask=attention_mask,
decoder_input_ids=decoder_input_ids,
encoder_outputs=encoder_outputs,
decoder_attention_mask=decoder_attention_mask,
head_mask=head_mask,
decoder_head_mask=decoder_head_mask,
cross_attn_head_mask=cross_attn_head_mask,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
decoder_inputs_embeds=decoder_inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
lm_logits = self.lm_head(outputs[0])
lm_logits = lm_logits + self.final_logits_bias.to(lm_logits.device)
masked_lm_loss = None
if labels is not None:
labels = labels.to(lm_logits.device)
loss_fct = CrossEntropyLoss()
masked_lm_loss = loss_fct(lm_logits.view(-1, self.config.vocab_size), labels.view(-1))
if not return_dict:
output = (lm_logits,) + outputs[1:]
return ((masked_lm_loss,) + output) if masked_lm_loss is not None else output
return Seq2SeqLMOutput(
loss=masked_lm_loss,
logits=lm_logits,
past_key_values=outputs.past_key_values,
decoder_hidden_states=outputs.decoder_hidden_states,
decoder_attentions=outputs.decoder_attentions,
cross_attentions=outputs.cross_attentions,
encoder_last_hidden_state=outputs.encoder_last_hidden_state,
encoder_hidden_states=outputs.encoder_hidden_states,
encoder_attentions=outputs.encoder_attentions,
)
5.4 计算下一个step每个token的得分
在上一小节中,前向计算的结果,有很多项,其中在生成过程中,最关键的就是logits,它直接关系到下一个step生成的token是什么。
-
- logits的形状为
(bsz, seq_len, vocab),所以下面代码中,第一行取的[:, -1, :],也就是取最后一个位置的概率分布,即用来生成下一个step的token。
- logits的形状为
-
- adjust_logits_during_generation是具体的模型定义的特殊方法,在生成过程中用来控制logits,如果不需要额外的控制,这个方法会默认返回logits本身。代码中的例子是在marian预训练模型中需要确保pad_token永远不被预测出,所以强行将其对应的logits设置为-inf(Marain是与BART非常类似的一个Encoder-Decoder模型,HF上最常用的翻译模型Helsinki系列就是用了这个结构)。
-
- 取log softmax(dim=-1)将logits变成vocab空间上的“概率”。
-
- 使用之前实例化的logits_processor对计算出的概率进行进一步的处理(logits_processor的介绍可以参考本文的上篇)
-
- 将processor处理之后的得分,与beam本身的得分相加算总分,即新的beam总分=原来的beam总分+即将生成的新token的分。这里可以回顾一下之前beam score初始化的细节,在while循环中的第一个step,只有第一个beam的分不是-inf,而之后的step中就不存在这个问题了。
next_token_logits = outputs.logits[:, -1, :]
# hack: adjust tokens for Marian. For Marian we have to make sure that the `pad_token_id`
# cannot be generated both before and after the `nn.functional.log_softmax` operation.
next_token_logits = self.adjust_logits_during_generation(next_token_logits, cur_len=cur_len)
next_token_scores = nn.functional.log_softmax(
next_token_logits, dim=-1
) # (batch_size * num_beams, vocab_size)
next_token_scores_processed = logits_processor(input_ids, next_token_scores)
next_token_scores = next_token_scores_processed + beam_scores[:, None].expand_as(next_token_scores)
这里还有一个细节,就是在最后一步中,为什么next_token_scores_processed与beam_scores可以直接相加,我的理解是,计算最大概率的beam,其基本的概率公式应该是每一个step的概率相乘:
S
c
o
r
e
c
u
r
=
p
0
∗
p
1
∗
.
.
.
∗
p
i
=
(
p
0
∗
p
1
∗
.
.
.
∗
p
i
−
1
)
∗
p
i
=
S
c
o
r
e
p
r
e
v
∗
p
i
Score_{cur}=p_0*p_1*...*p_i=\left(p_0*p_1*...*p_{i-1}\right)*p_i=Score_{prev}*p_i
Scorecur=p0∗p1∗...∗pi=(p0∗p1∗...∗pi−1)∗pi=Scoreprev∗pi
而由于在之前的得分计算中,已经取了对数,也就把原本乘性的问题变成了加性,二者自然可以直接相加了。
5.5 选择next token
在sample之前,有一个reshape的过程,将next_token_scores的形状从(batch_size * num_beams, vocab_size)变成了(batch_size, num_beams * vocab_size),也就是说,将num_beam展平在了vocab的维度上:

经过了这样的reshape,就把batch中的每一条样本,其包含的所有beam,放在一起进行对比了。更具体一点来讲,就是在
[
选择第1个beam的情况下,再选词表中第1个词,
选择第1个beam的情况下,再选词表中第2个词,
…,
选择第2个beam的情况下,再选词表中第1个词,
…,
选择第2个beam的情况下,再选词表中第6个词,
]
之中,选取概率最高的。由于这里介绍的是最基础的beam_gen_mode,所以还没涉及到top_k等超参数,这些部分在下文中会继续介绍。
在实际操作中,多采了一倍的token作为备选,以确保后续不会出问题。
接下来的torch.div的操作,是因为在topk之前,将beam展平在了vocab上,所以算出来的indices是在所有beam上的一个“绝对位置”,需要将它变成在每一个beam上的“相对位置”。
# Store scores, attentions and hidden_states when required
if return_dict_in_generate:
if output_scores:
scores += (next_token_scores_processed,)
if output_attentions:
decoder_attentions += (
(outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
)
if self.config.is_encoder_decoder:
cross_attentions += (outputs.cross_attentions,)
if output_hidden_states:
decoder_hidden_states += (
(outputs.decoder_hidden_states,)
if self.config.is_encoder_decoder
else (outputs.hidden_states,)
)
# reshape for beam search
vocab_size = next_token_scores.shape[-1]
next_token_scores = next_token_scores.view(batch_size, num_beams * vocab_size)
# Sample 2 next tokens for each beam (so we have some spare tokens and match output of beam search)
next_token_scores, next_tokens = torch.topk(
next_token_scores, 2 * num_beams, dim=1, largest=True, sorted=True
)
next_indices = torch.div(next_tokens, vocab_size, rounding_mode="floor")
next_tokens = next_tokens % vocab_size
5.6 更新beam状态
在这一步中,对beam的状态进行了更新,依赖BeamScorer的process方法。
# stateless
beam_outputs = beam_scorer.process(
input_ids,
next_token_scores,
next_tokens,
next_indices,
pad_token_id=pad_token_id,
eos_token_id=eos_token_id,
beam_indices=beam_indices,
)
这里就涉及到了scorer的process部分,对此进行详细的说明:
注意自此开始,代码跳转到transformers.generation.beam_search.BeamSearchScorer.process。
首先,将beam的数量,也就是BeamHypotheses容器的数量作为batch_size,对输入input_ids的形状做了检验,并且对下一个step的三项基本状态beam_scores,beam_tokens,beam_indices进行了初始化。
注意这三项既是process方法的输入,也是process最终的输出,作为下一次process的输入。
并且,在上一节的代码中可以看到,beam_scores在传入给process之前,已经在dim=1上做了排序,也就是在vocab_size的维度。
cur_len = input_ids.shape[-1]
batch_size = len(self._beam_hyps)
if not (batch_size == (input_ids.shape[0] // self.group_size)):
if self.num_beam_groups > 1:
raise ValueError(
f"A group beam size of {input_ids.shape[0]} is used as the input, but a group beam "
f"size of {self.group_size} is expected by the beam scorer."
)
else:
raise ValueError(
f"A beam size of {input_ids.shape[0]} is used as the input, but a beam size of "
f"{self.group_size} is expected by the beam scorer."
)
device = input_ids.device
next_beam_scores = torch.zeros((batch_size, self.group_size), dtype=next_scores.dtype, device=device)
next_beam_tokens = torch.zeros((batch_size, self.group_size), dtype=next_tokens.dtype, device=device)
next_beam_indices = torch.zeros((batch_size, self.group_size), dtype=next_indices.dtype, device=device)
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
接下来是process的主体部分,对每一个beam_hyp(即每一个进行生成中的束)进行遍历,过程的细节以注释的形式写在了代码里,这一部分的逻辑不算复杂,但是其中也涉及到了一些由分组运算而引发的细节问题:
for batch_idx, beam_hyp in enumerate(self._beam_hyps):
# 如果当前这一束已经被标记为完成了生成,则将三项输出结果进行padding
if self._done[batch_idx]:
if self.num_beams < len(beam_hyp):
raise ValueError(f"Batch can only be done if at least {self.num_beams} beams have been generated")
if eos_token_id is None or pad_token_id is None:
raise ValueError("Generated beams >= num_beams -> eos_token_id and pad_token have to be defined")
# pad the batch
next_beam_scores[batch_idx, :] = 0
next_beam_tokens[batch_idx, :] = pad_token_id
next_beam_indices[batch_idx, :] = 0
continue
# next tokens for this sentence
# 如果当前这一束还没有完成,则计算这一束的下一个token
beam_idx = 0
for beam_token_rank, (next_token, next_score, next_index) in enumerate(
zip(next_tokens[batch_idx], next_scores[batch_idx], next_indices[batch_idx])
):
# 由于在一开始输入到process时,next_tokens等,就是在vocab维度上排好序的
# 所以这里只需要按顺序添加即可
# 这里是将某个beam中的相对位置恢复为整个tensor中的绝对位置,注意看第5.5节中的图
batch_beam_idx = batch_idx * self.group_size + next_index
# add to generated hypotheses if end of sentence
# 最高得分是结束符的情况
if (eos_token_id is not None) and (next_token.item() in eos_token_id):
# if beam_token does not belong to top num_beams tokens, it should not be added
# 如果当前得分最高的是结束符则需要进行额外的一步判断
# 因为在计算得分的时候是将一组中所有beam放在一起计算的,所以即便是预测到了eos,
# 如果它不再前第num_beams个token范围内的话,那这个eos就不能算数
is_beam_token_worse_than_top_num_beams = beam_token_rank >= self.group_size
if is_beam_token_worse_than_top_num_beams:
continue
if beam_indices is not None:
beam_index = beam_indices[batch_beam_idx]
beam_index = beam_index + (batch_beam_idx,)
else:
beam_index = None
beam_hyp.add(
input_ids[batch_beam_idx].clone(),
next_score.item(),
beam_indices=beam_index,
)
else:
# add next predicted token since it is not eos_token
# 如果不是eos token的话,则直接添加即可
next_beam_scores[batch_idx, beam_idx] = next_score
next_beam_tokens[batch_idx, beam_idx] = next_token
next_beam_indices[batch_idx, beam_idx] = batch_beam_idx
beam_idx += 1
# once the beam for next step is full, don't add more tokens to it.
if beam_idx == self.group_size:
break
if beam_idx < self.group_size:
raise ValueError(
f"At most {self.group_size} tokens in {next_tokens[batch_idx]} can be equal to `eos_token_id:"
f" {eos_token_id}`. Make sure {next_tokens[batch_idx]} are corrected."
)
# Check if we are done so that we can save a pad step if all(done)
# 更新beam的完成状态
cur_len += 1 # add up to the length which the next_scores is calculated on
self._done[batch_idx] = self._done[batch_idx] or beam_hyp.is_done(
next_scores[batch_idx].max().item(), cur_len
)
return UserDict(
{
"next_beam_scores": next_beam_scores.view(-1),
"next_beam_tokens": next_beam_tokens.view(-1),
"next_beam_indices": next_beam_indices.view(-1),
}
)
以上就是BeamScorer的process过程,在计算出新的beam_scores等三项结果之后,还需要进行进一步的处理:
注意从这里开始,代码回到transformers.generation.utils.GenerationMixin.beam_search。
这一部分代码用来更新生成参数,保存past_key_values,以及判断是否满足停止条件。
beam_scores = beam_outputs["next_beam_scores"]
beam_next_tokens = beam_outputs["next_beam_tokens"]
beam_idx = beam_outputs["next_beam_indices"]
input_ids = torch.cat([input_ids[beam_idx, :], beam_next_tokens.unsqueeze(-1)], dim=-1)
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
if model_kwargs["past_key_values"] is not None:
model_kwargs["past_key_values"] = self._reorder_cache(model_kwargs["past_key_values"], beam_idx)
if return_dict_in_generate and output_scores:
beam_indices = tuple((beam_indices[beam_idx[i]] + (beam_idx[i],) for i in range(len(beam_indices))))
# increase cur_len
cur_len = cur_len + 1
if beam_scorer.is_done or stopping_criteria(input_ids, scores):
if not synced_gpus:
break
else:
this_peer_finished = True
5.7 后处理finalize
当生成终止后,还需要进行一个统一的后处理流程,以选择最佳的序列作为最终结果返回。
代码位于transformers.generation.beam_search.BeamSearchScorer.finalize。
在这个环节中,首先需要把没有完成的beam对应的token和score添加到容器中。回顾process部分的代码,可以看到,只有当预测出eos token,并且满足一定条件时,token和score才会被添加到beam_hyp容器中,而根据beam search的整体逻辑,每个step的状态更新完成时,不管是否添加到了容器中,都需要对结束状态进行判断,而判断时,stopping_criteria就会发挥作用了。这也就会造成存在这样一种情况,还没有结束生成的beam,由于满足了stopping_criteria的中止条件,而提前中止,此时的token和score并没有被添加到beam_hyp中,所以需要这样一个后处理的动作,来确保最终得到的beam数量,等于预先设置的num_beams。
batch_size = len(self._beam_hyps)
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
# finalize all open beam hypotheses and add to generated hypotheses
for batch_idx, beam_hyp in enumerate(self._beam_hyps):
if self._done[batch_idx]:
continue
# all open beam hypotheses are added to the beam hypothesis
# beam hypothesis class automatically keeps the best beams
for beam_id in range(self.num_beams):
batch_beam_idx = batch_idx * self.num_beams + beam_id
final_score = final_beam_scores[batch_beam_idx].item()
final_tokens = input_ids[batch_beam_idx]
beam_index = beam_indices[batch_beam_idx] if beam_indices is not None else None
beam_hyp.add(final_tokens, final_score, beam_indices=beam_index)
然后根据score从高到低对所有的束进行排序,保留得分最高的num_beam_hyps_to_keep个束。
# select the best hypotheses
sent_lengths = input_ids.new(batch_size * self.num_beam_hyps_to_keep)
best = []
best_indices = []
best_scores = torch.zeros(batch_size * self.num_beam_hyps_to_keep, device=self.device, dtype=torch.float32)
# retrieve best hypotheses
for i, beam_hyp in enumerate(self._beam_hyps):
sorted_hyps = sorted(beam_hyp.beams, key=lambda x: x[0])
for j in range(self.num_beam_hyps_to_keep):
best_hyp_tuple = sorted_hyps.pop()
best_score = best_hyp_tuple[0]
best_hyp = best_hyp_tuple[1]
best_index = best_hyp_tuple[2]
sent_lengths[self.num_beam_hyps_to_keep * i + j] = len(best_hyp)
# append hyp to lists
best.append(best_hyp)
# append indices to list
best_indices.append(best_index)
best_scores[i * self.num_beam_hyps_to_keep + j] = best_score
最后,对保留的所有束进行padding,已经添加eos结束符:
# prepare for adding eos
sent_lengths_max = sent_lengths.max().item() + 1
sent_max_len = min(sent_lengths_max, max_length) if max_length is not None else sent_lengths_max
decoded: torch.LongTensor = input_ids.new(batch_size * self.num_beam_hyps_to_keep, sent_max_len)
if len(best_indices) > 0 and best_indices[0] is not None:
indices: torch.LongTensor = input_ids.new(batch_size * self.num_beam_hyps_to_keep, sent_max_len)
else:
indices = None
# shorter batches are padded if needed
if sent_lengths.min().item() != sent_lengths.max().item():
assert pad_token_id is not None, "`pad_token_id` has to be defined"
decoded.fill_(pad_token_id)
if indices is not None:
indices.fill_(-1)
# fill with hypotheses and eos_token_id if the latter fits in
for i, (hypo, best_idx) in enumerate(zip(best, best_indices)):
decoded[i, : sent_lengths[i]] = hypo
if indices is not None:
indices[i, : len(best_idx)] = torch.tensor(best_idx)
if sent_lengths[i] < sent_max_len:
# inserting only the first eos_token_id
decoded[i, sent_lengths[i]] = eos_token_id[0]
return UserDict(
{
"sequences": decoded,
"sequence_scores": best_scores,
"beam_indices": indices,
}
)
以上就是beam search的完整流程了。在实际应用中,使用更多的方法一般是beam search的升级版,beam sample,在第6节中,将简单介绍一下beam sample模式与一般beam search的主要区别。
6. beam sample
Beam sample与一般的beam search相比,主要区别体现在其需要根据GenerationConfig的配置,创建若干logits warper,对计算出的next_token_scores进行进一步的加工。
从代码中来看,beam_sample方法与beam_search方法相比,区别主要在于while True的循环中,增加了logits_warper:
next_token_logits = self.adjust_logits_during_generation(next_token_logits, cur_len=cur_len)
next_token_scores = nn.functional.log_softmax(
next_token_logits, dim=-1
) # (batch_size * num_beams, vocab_size)
next_token_scores_processed = logits_processor(input_ids, next_token_scores)
next_token_scores = next_token_scores_processed + beam_scores[:, None].expand_as(next_token_scores)
# Note: logits warpers are intentionally applied after adding running beam scores. On some logits warpers
# (like top_p) this is indiferent, but on others (like temperature) it is not. For reference, see
# https://github.com/huggingface/transformers/pull/5420#discussion_r449779867
# 下边这一行是新增的:
next_token_scores = logits_warper(input_ids, next_token_scores)
# Store scores, attentions and hidden_states when required
if return_dict_in_generate:
if output_scores:
# beam_search中原本是这样的:
# scores += (next_token_scores_processed,)
# 下边这一行是beam_sample的:
scores += (logits_warper(input_ids, next_token_scores_processed),)
if output_attentions:
decoder_attentions += (
(outputs.decoder_attentions,) if self.config.is_encoder_decoder else (outputs.attentions,)
)
if self.config.is_encoder_decoder:
cross_attentions += (outputs.cross_attentions,)
if output_hidden_states:
decoder_hidden_states += (
(outputs.decoder_hidden_states,)
if self.config.is_encoder_decoder
else (outputs.hidden_states,)
)
在本文的上篇的4.11节中,对创建的logits warper进行了简单的介绍。这里就以其中一种logits wrapper为例进行介绍。
Temperature是生成过程中一项重要超参数,它控制着生成结果是否具有“创造性”。这个数值一般介于 [ 0.1 , 1 ] [0.1, 1] [0.1,1],该值越大,越倾向于生成概率不那么高的token,结果更具有“创造性”,等于1时,相当于原始的softmax得到的分布;而该值越小,则倾向于生成更加保守的结果,当接近于0时,则趋向于greedy search。
对应的wrapper实现如下:
class TemperatureLogitsWarper(LogitsWarper):
r"""
[`LogitsWarper`] for temperature (exponential scaling output probability distribution).
Args:
temperature (`float`):
The value used to module the logits distribution.
"""
def __init__(self, temperature: float):
if not isinstance(temperature, float) or not (temperature > 0):
raise ValueError(f"`temperature` has to be a strictly positive float, but is {temperature}")
self.temperature = temperature
def __call__(self, input_ids: torch.Tensor, scores: torch.Tensor) -> torch.FloatTensor:
scores = scores / self.temperature
return scores
从中可以看到,它只是将原来的得分除以temperature的数值。结合logits_warper在整体流程中的位置(warper的调用位于softmax之后),可以看出这一计算并没有在当前step生效,而是在下一个step时才会生效,这也符合带temperature的softmax的公式。
原始的softmax:
s
(
x
i
)
=
exp
x
i
∑
j
=
0
N
exp
x
j
s(x_i) = \frac{\exp^{x_i}} {\sum_{j=0}^N \exp^{x_j}}
s(xi)=∑j=0Nexpxjexpxi
增加temperature之后的softmax:
s
(
x
i
)
=
exp
x
i
t
∑
j
=
0
N
exp
x
j
t
s(x_i) = \frac{\exp^{\frac{x_i} {t}}} {\sum_{j=0}^N \exp^{\frac {x_j} {t}}}
s(xi)=∑j=0Nexptxjexptxi
其他的warper也是类似的使用方法,是作用在softmax计算完当前step的得分之后。
7. 总结
至此,transformers模块中generate相关的使用方法就已经全部介绍清楚了,随着代码的更新升级,其中的实现细节或许会发生些许变化,但只要NLG的大框架不被推翻,生成的基本逻辑就不会发生什么大的变化。在LLM迅速发展的当下,对于多数研究人员而言,或许并没有条件从头训练一个自己专属的模型,于是,如何利用好logits processor和stopping criteria,在已有模型的基础上灵活的进行生成,从代码实现的角度,理解模型是如何生成一个完整的序列,就格外重要了。
本文的写作花费了比较大的精力,期间由于个人原因搁置了一段时间,回过头来继续编写时,发现transformers源码已经发生了较大更新,无奈只好将代码部分重写。我的博客会持续不定期更新,分享近期热门人工智能相关知识技术,以及学习和实验过程中积累的体会心得,更新频率取决于我的业余时间是否充裕。写作纯属个人兴趣,没有任何收益来源,如果本文对你的学习或工作带来了帮助,麻烦留下一个免费的赞,大家的支持就是我更新的动力。
欢迎留言讨论,如需转载,请注明出处。