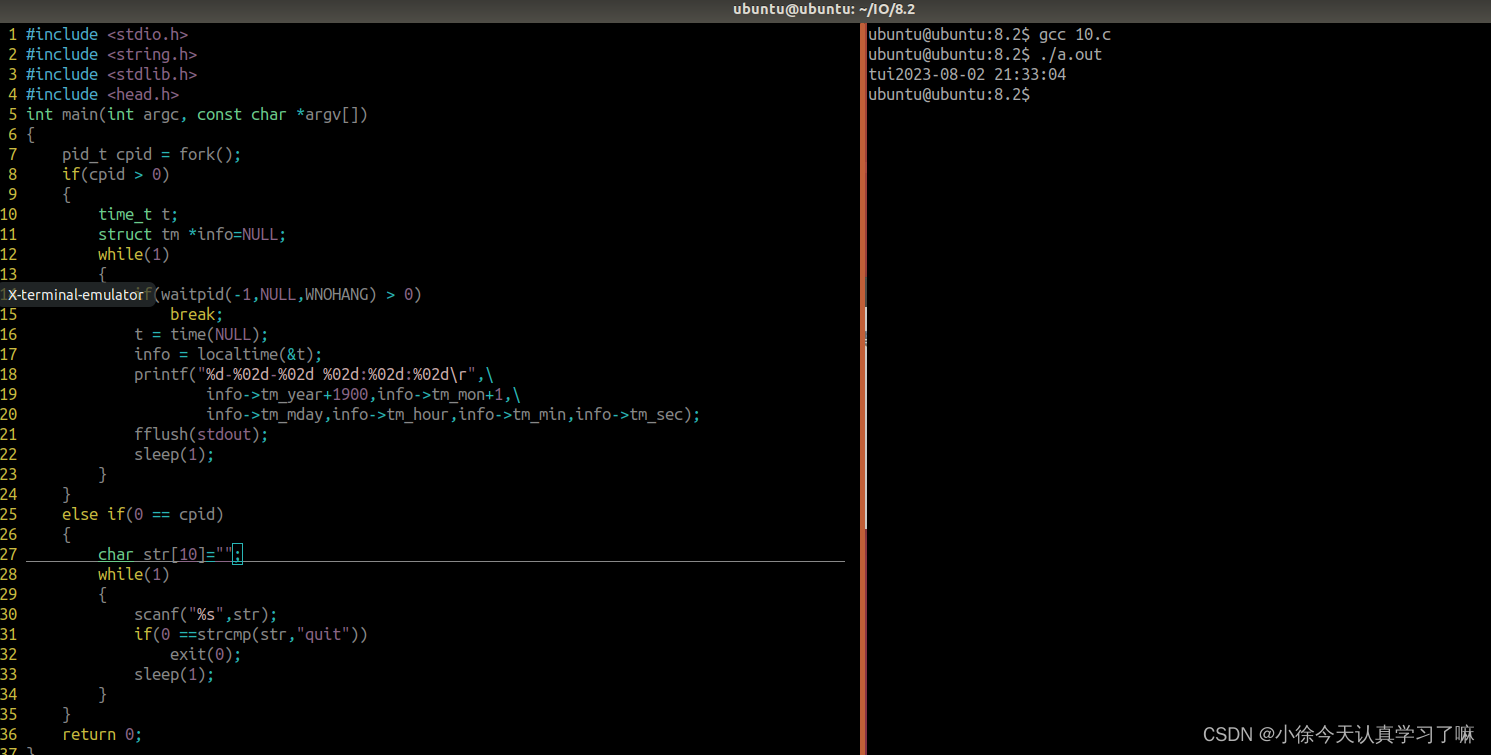
对于一次IO访问(以read为例),数据会先被拷贝到操作系统内核的缓冲区中,然后才会从操作系统内核的缓冲区拷贝到应用程序的地址空间。所以说,当一个read操作发生时,会经历两个阶段:
1、等待数据准备
2、将数据从内核拷贝到进程中
linux系统产生了下面五种网络模式的方案:
1、阻塞IO(blocking IO)
2、非阻塞IO(nonblocking IO)
3、IO多路复用(IO multiplexing)
4、信号驱动IO(signal driven IO)不常用
5、异步IO (asynchronous IO)
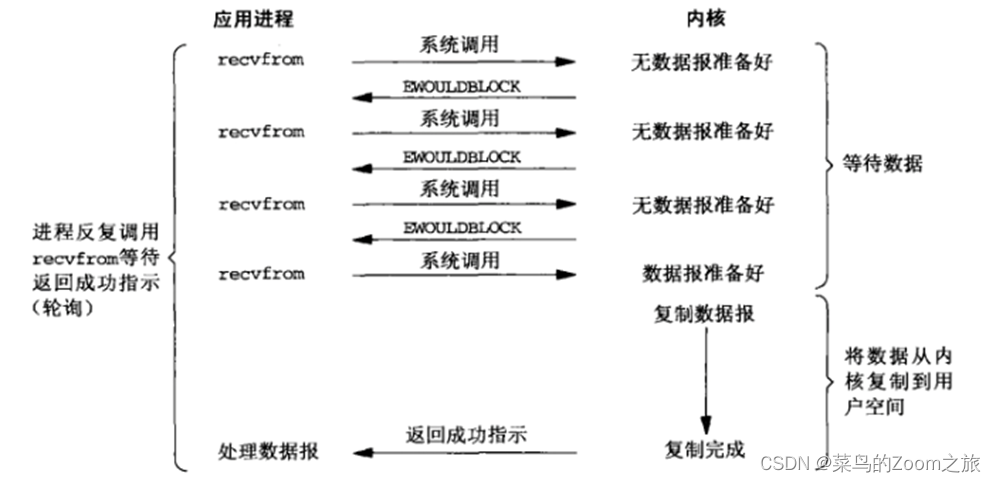
1、阻塞IO(blocking IO)
这种IO模型是同步的,在linux 中,默认情况下所有的socket都是blocking IO, 一个典型的读操作流程:

2、非阻塞IO(nonblocking IO)
非阻塞IO模型 只有是检查无数据的时候是非阻塞的,在数据到达的时候依然要等待复制数据到用户空间,因此它还是同步IO。
当用户线程发起一个read操作后,并不需要等待,而是马上就得到了一个结果。如果结果是一个error(errno == EAGAIN || EWOULDBLOCK)时,它就知道数据还没有准备好,于是它可以先做别的事情然后再次发送read操作。一旦内核中的数据准备好了,并且又再次收到了用户线程的请求,那么它马上就将数据拷贝到了用户线程,然后返回。
所以事实上,在非阻塞IO模型中,用户线程需要不断地询问内核数据是否就绪,也就说非阻塞IO不会交出CPU,而会一直占用CPU。
设置非阻塞常用方式:
方式一: 创建socket 时指定
int s = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, IPPROTO_TCP);方式二: 在使用前通过如下方式设定
fcntl(sockfd, F_SETFL, fcntl(sockfd, F_GETFL, 0) | O_NONBLOCK);3、IO多路复用
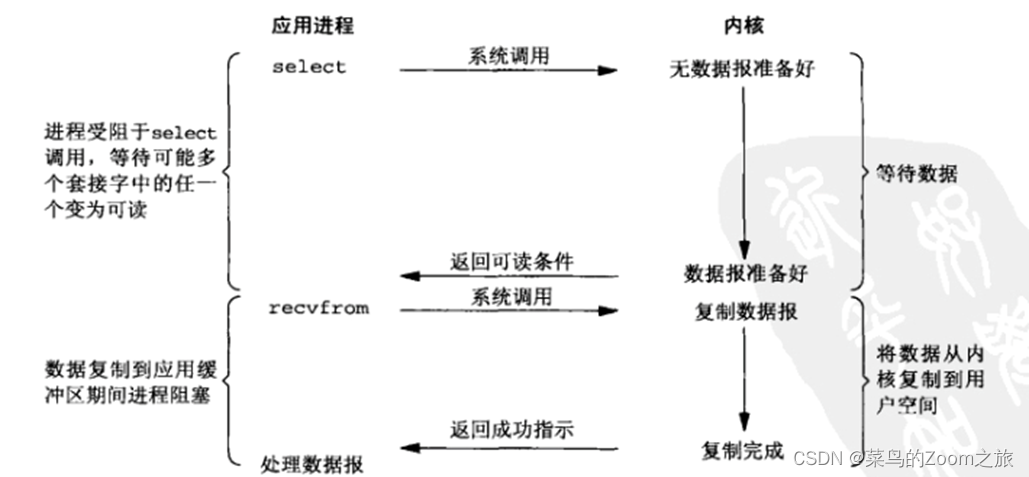
当用户进程调用了select,那么整个进程就会被block,而同时,kernel会 “监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
所以,IO多路复用的特点是通过一种机制,一个进程能同时等待多个文件描述符,而这些文件描述符(套接字描述符)其中的任意一个进入就绪状态,select()函数就可以返回。
这里需要使用两个system call(select 和 recvfrom),而blocking IO只调用了一个system call(recvfrom)。但是,用select的优势在于它可以同时处理多个connection。
如果处理的连接数不是很高的话,使用select/epoll的web server不一定比使用mutil-threading + blocking IO的web server性能更好,可能延迟还更大。
select/epoll 的优势并不是对于单个连接能处理得更好,而是在于能同时处理更多的连接。
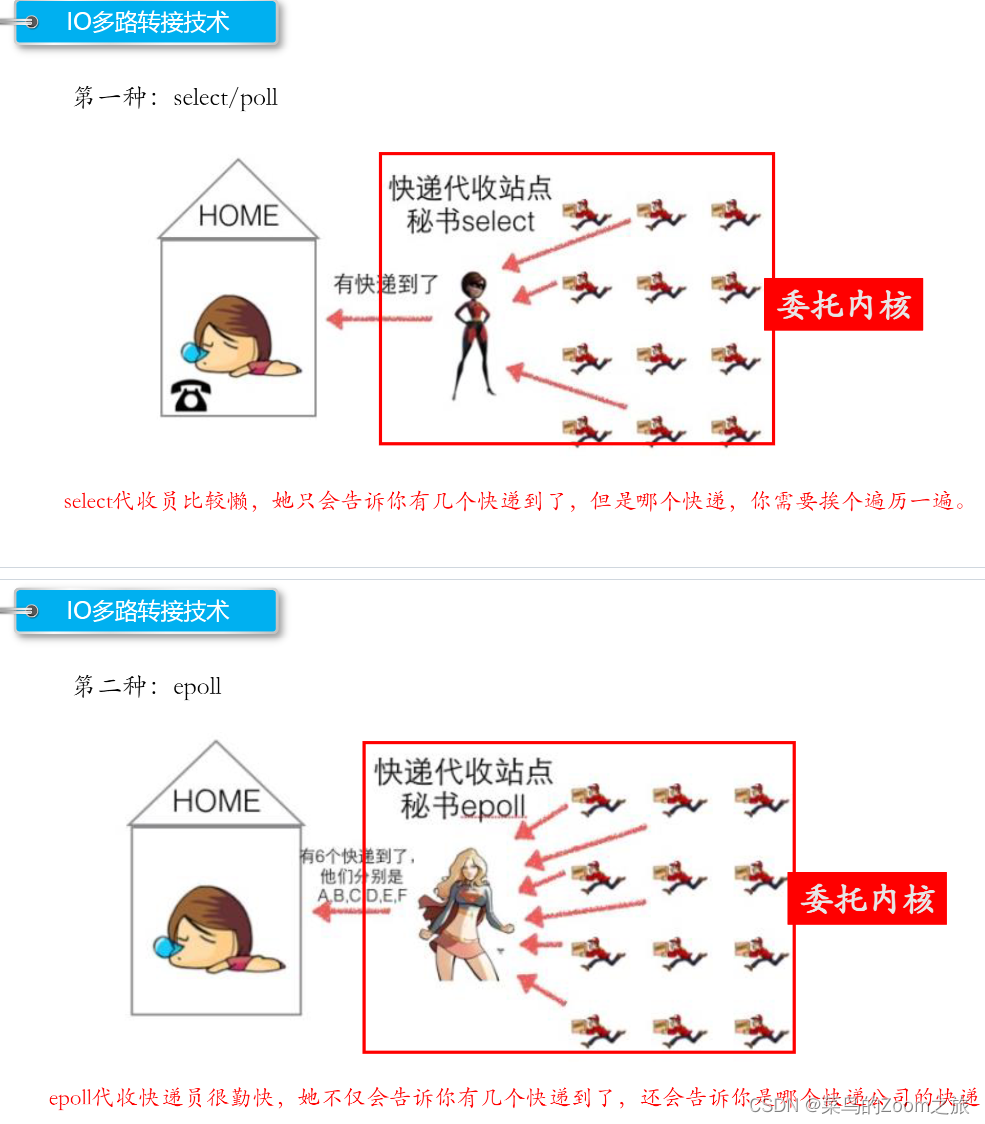
下面这幅图形象的说明了select/poll和epoll的区别。
select/poll
- 委托内核进行操作
- 只会通知有几个任务可用,但不知道具体哪几个任务,还需遍历
epoll
- 委托内核进行操作
- 会通知具体有哪几个任务可用
关于根据的IO多路复用问题,将在另外的文章做详细的说明。
4、信号驱动IO
使用信号驱动I/O时,当网络套接字可读后,内核通过发送SIGIO信号通知应用进程,于是应用可以开始读取数据。该方式并不是异步I/O,因为实际读取数据到应用进程缓存的工作仍然是由应用自己负责的。
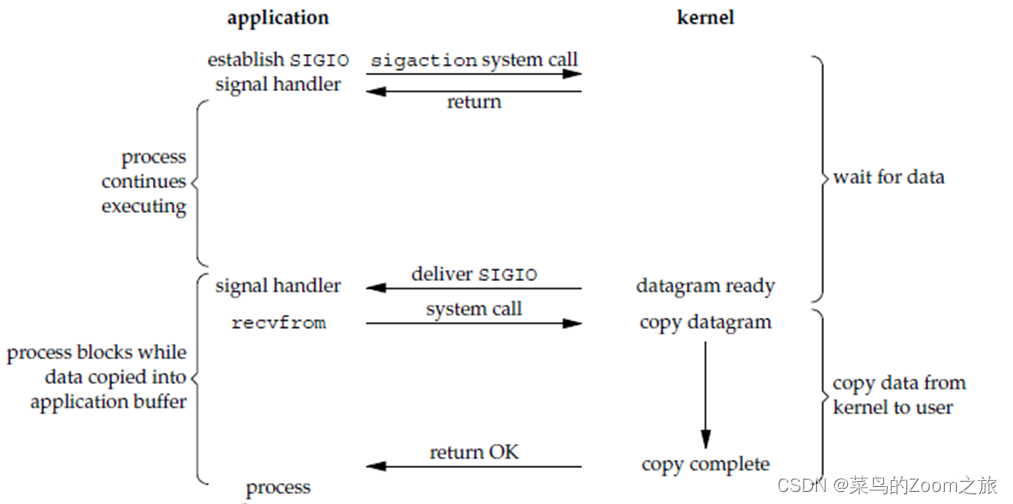
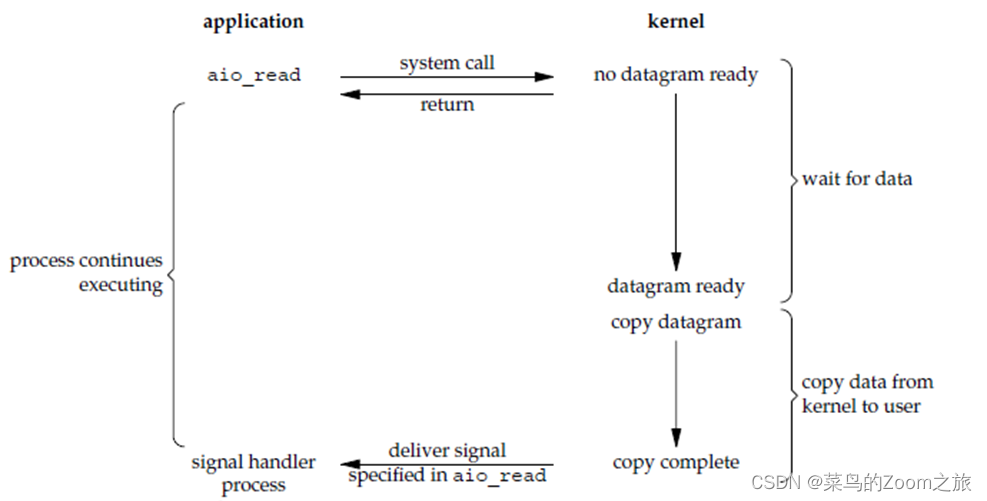
5、异步IO
当用户进程发起一个read操作后,内核收到该read操作后,首先它会立刻返回,所以不会对用户进程 阻塞,然后它会等待数据的准备完成,再把数据拷贝到用户内存,完成之后,它会给用户进程发送一个信号,告诉用户进程read操作已完成.