论文标题:Meta-Transformer: A Unified Framework for
Multimodal Learning
论文地址:https://arxiv.org/pdf/2307.10802.pdf
这里写目录标题
- 引言
- 基于Transformer的多模态发展
- Meta-Transformer框架
- 预备知识
- 数据到序列如何分词(Data-to-Sequence Tokenization)
- 统一编码器
- 任务特定输出头(下游微调)
- 实验结果
- 对于图像理解
- 对于点云理解
引言
多模态学习旨在构建能够处理和关联多种模态信息的模型。尽管该领域已经有多年的发展,但由于它们之间的差异,设计一个处理各种模态(例如自然语言) 、2D图像、3D点云、音频、视频、时间序列、表格数据)的统一网络仍然具有挑战性。
在这篇论文中,作者提出了一个名为"元变压器"的框架,该框架利用一个冻结的编码器在没有布局的情况下的多模态训练数据的情况下执行多模态采集。元变压器的目标是将来自不同模态的输入数据映射到共享的标记空间,以便后续的编码器可以提取输入数据的高级语义特征。
元变压器由三个主要组件组成:统一的数据标记器、统一的模态共享编码器和用于下游模态任务的特定任务头部。它是第一个在不同的基准测试的实验中可以通过模态数据在12种模态上执行统一学习的模型,元转换器可以处理广泛的任务,包括基本感知(文本、图像、点云、音频、视频)、实际应用(X射线、红外、高光谱和惯性测量)单元)、以及数据挖掘(图形、表格和时间序列)。
元转换器为使用变压器进行统一多模态智能的发展指明了一个有希望的未来。
代码将在https://github.com/invictus717/MetaTransformer 上

从上图表格观察,不难看出相比于现有工作,Meta-Transformer 可以利用统一的模态共享编码器来处理更多的模态,并且摆脱了多模态训练过程中对于配对数据的依赖性。
基于Transformer的多模态发展
在这一部分,将介绍目前基于Transformer的多模态感知方法,它利用Transformer的全局感受野和相似性建模优势来处理多模态数据。具体地,我们将介绍几种相关的技术,包括MCAN、VL-BERT、Oscar、BEiT-v3和MoMo。
- MCAN (Modular Co-Attention Networks):
MCAN是一种基于Transformer的网络,它专注于视觉和语言之间的交叉模态对齐。它利用深层模块化共同注意的机制,通过简洁地最大化交叉注意来实现跨模态对齐。这使得MCAN能够在视觉和语言之间建立有效的关联,从而提高多模态感知的性能。 - VL-BERT (Vision-Language BERT):
VL-BERT是一种使用MLM (Masked Language Modeling)范式的预训练模型,专注于实现视觉-语言的通用理解和模态对齐。它通过在视觉和文本内容中进行跨模态掩码,使得模型能够理解和对齐跨模态的表示。VL-BERT的创新性在于将Transformer应用于视觉-语言任务,并取得了显著的性能提升。 - Oscar:
Oscar是另一种基于Transformer的多模态模型,它专注于描述视觉和文本内容中的对象语义。Oscar的设计使得模型能够将视觉和文本信息进行有效地融合,从而实现更好的语义一致性。通过对对象语义的准确描述,Oscar在多模态任务中表现出色。 - BEiT-v3:
BEiT-v3是一种将图像视为外语的多模态模型。它采用更细粒度的跨模态掩码和重构过程,使得模型能够在图像和文本之间共享部分参数,从而提高模型的泛化能力。BEiT-v3的创新在于将图像和文本视为相似的信息源,通过共享参数来实现模态之间的有效连接。 - MoMo (Modality-agnostic Multimodal Encoder):
MoMo是一种同时处理图像和文本的多模态编码器。它进一步探索了训练策略和目标函数,使得模型能够更好地适应多模态任务。MoMo的独特之处在于使用相同的编码器来处理图像和文本,从而实现了模态之间的无缝连接。
尽管上述基于Transformer的多模态感知技术取得了一定的进展,但仍然存在一些重要的挑战。不同模态之间的差异导致了现有模型的局限性,而大部分研究工作集中在视觉和语言任务上,对于其他模态如3D点云理解和音频识别的挑战贡献较少。此外,现有多模态模型的可迁移性有限,难以充分利用一种模态的先验知识来帮助其他模态。因此,为了解决这些问题并实现多模态数据的统一学习,论文提出了一种全新的框架——Meta-Transformer。
Meta-Transformer框架
Meta-Transformer将来自不同模态的数据处理管道统一起来,使用共享编码器来编码文本、图像、点云、音频等8种模态的数据。
为了实现这一目标Meta-Transformer包含三个主要组件:数据到序列的分词器(data-to-sequence tokenizer)、模态不可知编码器(modality-agnostic encoder)和任务特定的输出头(task-specific heads),如下图所示

预备知识
在介绍模型之前,需要了解一些模型预先的知识。
Meta-Transformer框架结构将输入空间的n个模态表示为
{
X
1
,
X
2
,
⋅
⋅
⋅
,
X
n
}
\lbrace X_1, X_2, · · · , X_n \rbrace
{X1,X2,⋅⋅⋅,Xn},相应的标签空间为
{
Y
1
,
Y
2
,
⋅
⋅
⋅
,
Y
n
}
\lbrace Y_1, Y_2, · · · , Y_n \rbrace
{Y1,Y2,⋅⋅⋅,Yn}。假设每个模态都有一个有效的参数空间
Θ
i
\Theta_i
Θi,其中任何参数
θ
i
∈
Θ
i
\theta_i \in \Theta_i
θi∈Θi都可以用于处理来自该模态的数据
x
i
∈
X
i
x_i \in X_i
xi∈Xi。Meta-Transformer的核心思想是找到一个共享的参数
θ
∗
\theta^*
θ∗
让 θ ∗ θ^* θ∗满足以下条件:
θ
∗
∈
Θ
1
∩
Θ
2
∩
Θ
3
∩
⋅
⋅
⋅
Θ
n
\theta^∗ \in \Theta_1 \cap \Theta_2 \cap \Theta_3 \cap · · · \Theta_n
θ∗∈Θ1∩Θ2∩Θ3∩⋅⋅⋅Θn
并假设:
Θ 1 ∩ Θ 2 ∩ Θ 3 ∩ ⋅ ⋅ ⋅ Θ n ≠ ⊘ \Theta_1 \cap \Theta_2 \cap \Theta_3 \cap · · · \Theta_n \neq \oslash Θ1∩Θ2∩Θ3∩⋅⋅⋅Θn=⊘
多模态神经网络可以表示为一个统一的映射函数
F
:
x
∈
X
→
y
^
∈
Y
F:x \in X → \hat y \in Y
F:x∈X→y^∈Y
其中
x
x
x是来自任意模态
{
X
1
,
X
2
,
⋅
⋅
⋅
,
X
n
}
\lbrace X1, X2, · · · , Xn \rbrace
{X1,X2,⋅⋅⋅,Xn}的输入数据,
y
^
\hat y
y^表示网络的预测结果。我们将
y
y
y表示为真实标签,多模态管道可以表示为:
y
^
=
F
(
x
;
θ
∗
)
,
θ
∗
=
a
r
g
m
i
n
x
∈
X
[
L
(
y
^
,
y
)
]
\hat y = F(x; \theta^∗), \theta^∗ = argmin_{x\in X} [L(\hat y, y)]
y^=F(x;θ∗),θ∗=argminx∈X[L(y^,y)]。
数据到序列如何分词(Data-to-Sequence Tokenization)
论文提出了一种新颖的元分词方案,旨在将各种模态的数据转换为token嵌入,并将它们统一到一个共享的嵌入空间中。
该方案应用于分词,同时考虑到各个模态的特性,如下图所示。我们以文本、图像、点云和音频为例进行解释。

- 自然语言:对于文本数据,采用常见的BERT做法,使用包含30,000个词汇token的WordPiece嵌入。WordPiece将原始单词分割成子词。例如,原始句子:“The supermarket is hosting a sale”,在WordPiece的处理下可能变成:“_The _super market _is _host ing _a _sale”。
在这个例子中,单词“supermarket”被分割成两个子词“_super”和“market”,单词“hosting”被分割成“host”和“ing”,而其他单词保持不变,仍然是单个单位。每个原始单词的第一个字符前面会加上特殊字符“”,表示一个自然单词的开始。每个子词对应于词汇表中的一个唯一token,然后通过单词嵌入层将其投影到高维特征空间。因此,每个输入文本都被转换为一组token嵌入 x ∈ R n × D x \in R ^{n×D} x∈Rn×D,其中n是token数,D是嵌入的维度。
- 图像:为了适应2D图像,将图像 x ∈ R H × W × C x \in R^{H×W×C} x∈RH×W×C重塑为一系列展平的2D图像块 x p ∈ R N s × ( S 2 C ˙ ) x_p \in R^{N_s \times (S^2 \dot C)} xp∈RNs×(S2C˙),
其中
(
H
,
W
)
(H, W)
(H,W)表示原始图像分辨率,
C
C
C表示通道数;
S
S
S是图像块的大小,而
N
s
=
(
H
W
/
S
2
)
N_s = (HW/S^2)
Ns=(HW/S2)是生成的图像块数量。然后,使用投影层将嵌入维度投影为D:
x
I
∈
R
C
×
H
×
W
→
x
′
I
∈
R
N
s
×
(
S
2
C
˙
)
→
x
′
′
I
∈
R
N
s
×
D
x_I \in R^{C×H×W} → x′_I \in R^{N_s\times (S^2\dot C)} → x′′_I \in R^{N_s×D}
xI∈RC×H×W→x′I∈RNs×(S2C˙)→x′′I∈RNs×D。
- 点云:为了用Transformer学习3D模式,我们将点云从原始输入空间转换为token嵌入空间。 X = { x i } i = 1 P X = \lbrace x_i \rbrace^P_{i=1} X={xi}i=1P表示 P P P个点的点云,其中 x i = ( p i , f i ) x_i = (p_i, f_i) xi=(pi,fi), p i ∈ R 3 p_i \in R^3 pi∈R3表示3D坐标, f i ∈ R c f_i \in R^c fi∈Rc是第 i i i个点的特征。通常, f i f_i fi包含视觉提示,如颜色、视角、法向等。我们使用最远点采样(Farthest Point Sampling,FPS)操作以固定采样比率(1/4)对原始点云进行采样,然后使用K最近邻(K-Nearest Neighbor,KNN)来对邻近点进行分组。基于包含局部几何先验的分组集合,我们构建邻接矩阵,其中包含了分组子集的中心点,以进一步揭示3D物体和3D场景的全面结构信息。
- 音频频谱图:首先,使用对数Mel滤波器组(log Mel filterbank)对音频波形进行预处理,将音频波形转换为 l l l维滤波器组。然后,使用汉明窗口和步长ts来在频率fs上对原始波形进行切分,将原始波形分成 l l l个间隔。接着,将原始波形转换成频谱图。选择将整个频谱图按时间和频率维度划分成大小为 S S S的补丁(patch),不同于图像补丁,音频补丁在频谱图上有重叠。按照AST的做法,选择将整个频谱图划分成 N s = 12 [ ( 100 t − 16 ) / 10 ] N_s = 12[(100t - 16)/10] Ns=12[(100t−16)/10]个补丁,通过 S × S S \times S S×S的卷积将其展平成token序列。
最后,整个过程进行总结:
x
A
∈
R
T
×
F
→
x
′
A
∈
R
N
s
×
S
×
S
→
x
′
′
A
∈
R
(
N
s
⋅
D
/
S
2
)
×
D
x_A \in R^{T\times F} → x′_A \in R^{N_s \times S \times S} → x′′_A \in R^{(N_s·D/S^2) \times D}
xA∈RT×F→x′A∈RNs×S×S→x′′A∈R(Ns⋅D/S2)×D
其中,T和F分别表示时间和频率维度。
通过这种数据到序列的分词器,不同模态的数据都被转换为共享的嵌入空间中的token嵌入,从而实现了多模态数据的统一处理。
统一编码器
对上一步得到的的不同模态的 token 序列,利用一个具有固定参数的统一Transformer编码器来对来自不同模态的token序列进行编码。
- 预训练:使用ViT作为主干网络,并使用对比学习在LAION-2B数据集上对其进行预训练,以增强通用token编码的能力。在预训练之后,冻结主干网络的参数。另外,对于文本理解,利用CLIP的预训练文本分词器将句子分割为子词,并将子词转换为词嵌入。
- 模态不可知学习:按照BERT的常规做法,在token嵌入序列前添加一个可学习的特殊token x C L S x_{CLS} xCLS, x C L S x_{CLS} xCLS的最终隐藏状态 ( z L 0 ) (z^0_L) (zL0)作为输入序列的摘要表示,
通常用于执行识别任务,为了增强位置信息,将位置信息嵌入融入到token嵌入中。由于将输入数据分词成1D的嵌入,因此选择标准的可学习的1D位置嵌入。
Transformer编码器的深度为 L L L,由多个堆叠的多头自注意力(MSA)层和MLP块组成。首先,将输入token嵌入送入MSA层,然后是一个MLP块。然后,第 ( ℓ − 1 ) (ℓ-1) (ℓ−1)个MLP块的输出作为第 ℓ ℓ ℓ个MSA层的输入。在每个层之前添加Layer Normalization(LN),并在每个层之后应用残差连接。MLP包含两个线性全连接层和一个GELU非线性激活函数。
Transformer的公式如下:
z
0
=
[
x
C
L
S
;
E
x
1
;
E
x
2
;
⋅
⋅
⋅
;
E
x
n
]
+
E
p
o
s
,
E
∈
R
n
×
D
,
E
p
o
s
∈
R
(
n
+
1
)
×
D
z_0 = [x_{CLS}; E_{x_1}; E_{x_2}; · · · ; E_{x_n}] + E_{pos}, E \in R^{n \times D}, E_{pos} \in R^{(n+1) \times D}
z0=[xCLS;Ex1;Ex2;⋅⋅⋅;Exn]+Epos,E∈Rn×D,Epos∈R(n+1)×D
z
′
ℓ
=
M
S
A
(
L
N
(
z
ℓ
−
1
)
)
+
z
ℓ
−
1
,
ℓ
=
1...
L
z′_ℓ = MSA(LN(z_{ℓ−1})) + z_{ℓ−1}, ℓ = 1 . . . L
z′ℓ=MSA(LN(zℓ−1))+zℓ−1,ℓ=1...L
z
ℓ
=
M
L
P
(
L
N
(
z
′
ℓ
)
)
+
z
′
ℓ
,
ℓ
=
1...
L
z_ℓ = MLP(LN(z′_ℓ)) + z′_ℓ, ℓ = 1 . . . L
zℓ=MLP(LN(z′ℓ))+z′ℓ,ℓ=1...L
y
=
L
N
(
z
L
0
)
y = LN(z^0_L)
y=LN(zL0)
其中
E
x
E_x
Ex表示来自提议的分词器的token嵌入,n表示token的数量。论文将补丁嵌入和可学习的嵌入与位置嵌入Epos融合。
任务特定输出头(下游微调)
在获得学习表征后,研究人员将表征输入特定任务的头
h
(
⋅
;
θ
h
)
h(·;\theta_h)
h(⋅;θh),它主要由 MLP 组成,因模态和任务而异。Meta-Transformer 的学习目标可以概括为:
y
^
=
F
(
x
;
θ
∗
)
=
h
◦
g
◦
f
(
x
)
,
θ
∗
=
a
r
g
m
i
n
θ
L
(
y
^
,
y
)
\hat y = F(x; θ^∗) = h ◦ g ◦ f(x), θ^∗ = argmin_\theta L(\hat y, y)
y^=F(x;θ∗)=h◦g◦f(x),θ∗=argminθL(y^,y)
其中 h ( ・ ) h (・) h(・), g ( ・ ) g (・) g(・),与 f ( ・ ) f (・) f(・),分别表示 tokenizer,模型骨干网络,以及下游任务网络中的运算过程。
实验结果
Meta-Transformer 具有丰富且优秀的实验结果。下表展示了 Meta-Transformer 在不同模态上的实验内容。可以看出,Meta-Transformer 从 12 种模态中提取表征信息,能够有效地服务 16 个不同模态的下游任务,且拥有出色的性能。

对于图像理解
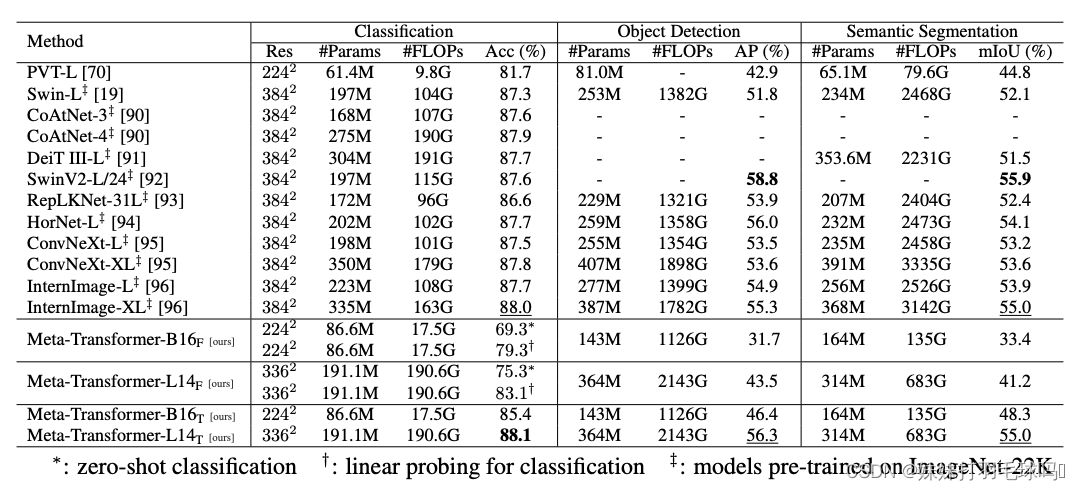
如下表所示,与 Swin Transformer 系列和 InternImage 相比,Meta-Transformer 在图像理解任务中表现突出。在分类任务中,Meta-Transformer 与 Meta-Transformer-B16F 和 Meta-Transformer-L14F 在零镜头分类下的表现非常好,分别达到了 69.3% 和 75.3%。与此同时,当调整预训练参数时,Meta-Transformer-B16T 和 Meta-Transformer-L14T 分别达到 85.4% 和 88. 1% 的准确率,超越了现有最先进的方法。在目标检测与语义分割方面,Meta-Transformer 也提供了出色的性能,进一步证明了其对图像理解的通用能力。
对于点云理解
下表展示了 Meta-Transformer 在点云上的实验结果。当在二维数据上进行预训练时,Meta-Transformer 在 ModelNet-40 上仅用 0.6M 可训练参数就达到了 93.6% 的总体准确率(OA),与表现最好的模型不相上下。此外,Meta-Transformer 在 ShapeNetPart 数据集中表现出色,仅训练 2.3M 参数的情况下,在实例 mIoU 和类别 mIoU 方面都获得了最好的实验结果,分别为 87.0% 和 85.2%。由此可见,Meta-Transformer 在点云理解任务中表现出了显著的优势,在可训练参数较少的情况下提供了具有竞争力的性能。