1、什么是wal buffer?
wal buffer是预写日志(wal)缓冲区
2、wal buffer的作用是什么
用于还未写入磁盘的 WAL 数据的共享内存。
每次变更事务提交时候,需要将变更事务日志落盘,在PG中为了提高性能,并非采用实时flush到磁盘,而是在PG中提供XLog Buffer空间临时存储提交的事务日志,然后定期flush到磁盘。一旦任何给定的 8kB 缓冲区的内容持久地保存在磁盘上,就可以重复使用该缓冲区 。由于插入和写入都是顺序的,因此 WAL 缓冲区实际上是一个环形缓冲区 。缓冲区填满时性能会受到影响:在当前刷新完成之前,无法再插入WAL 。当synchronous_commit未关闭时,每个事务提交都会等待其 WAL 记录刷新到磁盘,从而减轻了wal缓冲区的影响。
如果一个事务更新大型记录或大量行,或者大量客户端并发执行更新事务,导致WAL缓冲区被填满,则它需要去刷磁盘而不能插入WAL,进而影响了wal的写入次数,则适当增加wal_buffers ,可能会提高性能。一般当单事务的数据修改量很大,产生的日志大于wal_buffers时,可适当调大该值。当有比较多的并发短事务时,可与参数commit_delay及commit_siblings连用,并适当调大该值。
但是在每次事务提交时,WAL 缓冲区的内容被写到磁盘,因此太大的值可能也不是个明智之举。 总的来说,数据库参数的调优并不能为了迎合某一阶段的SQL或者几条SQL。必须从数据库的整体去考量,从整体去得出一个值,而且不要去轻易频繁改动,否则不利于数据库的稳定性,而且也有可能会影响业务的连续性和用户体验。
曾有人测试过在一个系统进行调优,发现wal_buffers=64MB 的性能比 wal_buffers=16MB 翻了一番。但是也有的人在调优的时候,无论怎么搭配参数,性能都没有比原本默认的1/32的自动调整的方式高出10%。因此更多还是看实际的场景,SQL情况,以及并发等。对于这个参数,在具有大量并发的环境,可能有一定的优化空间,尝试稍微高一点的值,特别是如果你有频繁的检查点(主要指检查点之后防止在崩溃时页裂的full page write,这些全页写会非常快速地填满WAL 缓冲区)。
曾经看过一篇文章,评论里有人想根据在一段时间内写入 WAL 的数据字节数来做估算。
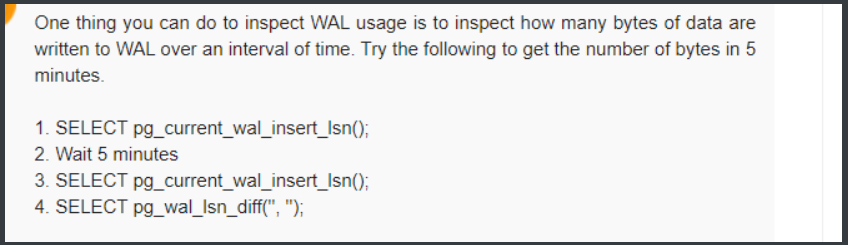
类似如下的方式,感兴趣的可以试试。
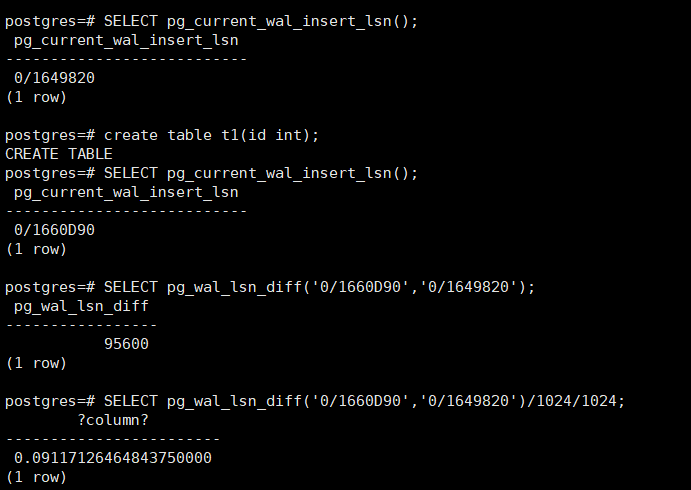
3、wal_buffers默认是怎么自动计算的
XLog Buffer的大小默认由参数wal_buffers决定,当这个参数设置为-1时候,PG会根据shared_buffers和wal_segment_size参数自动计算而得到。

正常情况下,wal_buffers设置为-1的时候,wal_buffers的大小为shared_buffers的1/32,这个比例也是Gregory Smith之前给出的建议(Gregory Smith是国际PostgreSQL服务公司2ndQuadrant在美国的首席顾问),在代码里是由 NBuffers/32 来展现的,因此通过对应比例调整shared_buffers其实可以获得适当的优化,而其实更高的值有时也可以显著提高性能 ,主要还是看实际的使用场景。
-B NBuffers 是可以作为 Postgres 运行时候的命令行参数所设置的。
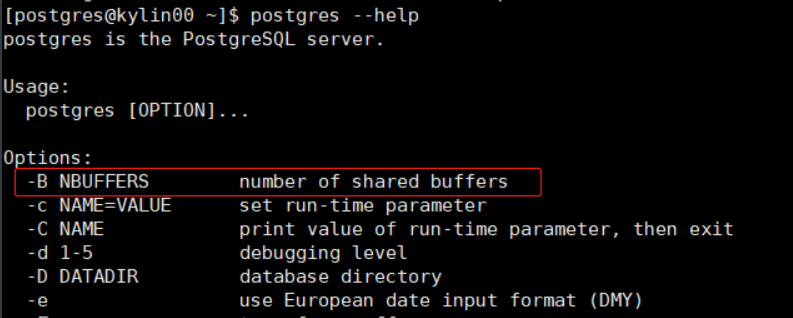
下边是这个参数的解释
-B nbuffersSets the number of shared buffers for use by the server processes. The default value of this parameter is chosen automatically by initdb. Specifying this option is equivalent to setting the shared_buffers configuration parameter.
nbuffers和shared_buffers是具备换算关系的,两者计算的字节数是一致的,以shared_buffers的单位为MB为例,具体的换算为 :
nbuffers=(shared_buffers*1024)/block_size
举个例子在进行换算的时候,比如10MB的shared_buffers,它占用的字节是shared_buffers*1024*1024,
而nbuffers占用的是 nbuffers*block_size*1024,所以我们想给shared_buffers设置为10MB,
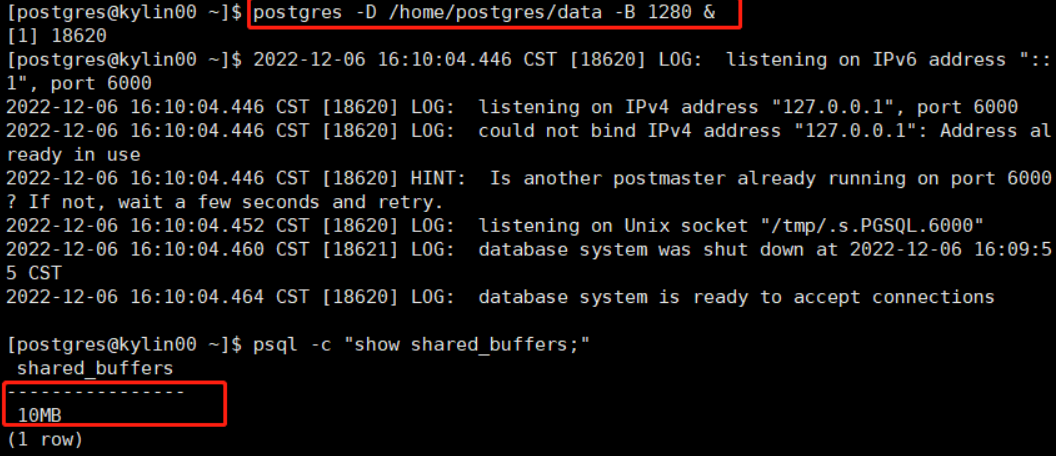
通过计算nbuffers=(shared_buffers*1024)/block_size=1280,我们通过如下启动postrges的时候
指定-B来进行检验。最终的结果和我们的换算是一致的。