MIT 6.S081 Lab Nine --- file system
- 引言
- File system
- Large files(moderate)
- 预备
- 看什么
- 你的工作
- 代码解析
- Symbolic links(moderate)
- 硬链接
- 代码解析
- 可选的挑战练习
引言
本文为 MIT 6.S081 2020 操作系统 实验九解析。
MIT 6.S081课程前置基础参考: 基于RISC-V搭建操作系统系列
File system
在本实验室中,您将向xv6文件系统添加大型文件和符号链接。
Attention
- 在编写代码之前,您应该阅读《xv6手册》中的《第八章:文件系统》,并学习相应的代码。
获取实验室的xv6源代码并切换到fs分支:
$ git fetch
$ git checkout fs
$ make clean
Large files(moderate)
在本作业中,您将增加xv6文件的最大大小。目前,xv6文件限制为268个块或268*BSIZE字节(在xv6中BSIZE为1024)。此限制来自以下事实:一个xv6 inode包含12个“直接”块号和一个“间接”块号,“一级间接”块指一个最多可容纳256个块号的块,总共12+256=268个块。
bigfile命令可以创建最长的文件,并报告其大小:
$ bigfile
..
wrote 268 blocks
bigfile: file is too small
$
测试失败,因为bigfile希望能够创建一个包含65803个块的文件,但未修改的xv6将文件限制为268个块。
您将更改xv6文件系统代码,以支持每个inode中可包含256个一级间接块地址的“二级间接”块,每个一级间接块最多可以包含256个数据块地址。结果将是一个文件将能够包含多达65803个块,或256*256+256+11个块(11而不是12,因为我们将为二级间接块牺牲一个直接块号)。
预备
mkfs程序创建xv6文件系统磁盘映像,并确定文件系统的总块数;此大小由kernel/param.h中的FSSIZE控制:
// kernel/params.h
#define FSSIZE 200000 // size of file system in blocks
您将看到,该实验室存储库中的FSSIZE设置为200000个块。您应该在make输出中看到来自mkfs/mkfs的以下输出:
nmeta 70 (boot, super, log blocks 30 inode blocks 13, bitmap blocks 25) blocks 199930 total 200000
这一行描述了mkfs/mkfs构建的文件系统:它有70个元数据块(用于描述文件系统的块)和199930个数据块,总计200000个块。
如果在实验期间的任何时候,您发现自己必须从头开始重建文件系统,您可以运行make clean,强制make重建fs.img。
MakeFile文件文件系统和内核文件构建流程注释版本:
# To compile and run with a lab solution, set the lab name in lab.mk
# (e.g., LB=util). Run make grade to test solution with the lab's
# grade script (e.g., grade-lab-util).
-include conf/lab.mk
K=kernel
U=user
# 构建内核代码的文件组成列表
OBJS =
$K/entry.o
$K/start.o
$K/console.o
$K/printf.o
$K/uart.o
$K/kalloc.o
$K/spinlock.o
$K/string.o
$K/main.o
$K/vm.o
$K/proc.o
$K/swtch.o
$K/trampoline.o
$K/trap.o
$K/syscall.o
$K/sysproc.o
$K/bio.o
$K/fs.o
$K/log.o
$K/sleeplock.o
$K/file.o
$K/pipe.o
$K/exec.o
$K/sysfile.o
$K/kernelvec.o
$K/plic.o
$K/virtio_disk.o
ifeq ($(LAB),pgtbl)
OBJS +=
$K/vmcopyin.o
endif
ifeq ($(LAB),$(filter $(LAB), pgtbl lock))
OBJS +=
$K/stats.o
$K/sprintf.o
endif
ifeq ($(LAB),net)
OBJS +=
$K/e1000.o
$K/net.o
$K/sysnet.o
$K/pci.o
endif
# riscv64-unknown-elf- or riscv64-linux-gnu-
# perhaps in /opt/riscv/bin
#TOOLPREFIX =
# Try to infer the correct TOOLPREFIX if not set
# 确定适用于 RISC-V 架构的交叉编译器的前缀
ifndef TOOLPREFIX
TOOLPREFIX := $(shell if riscv64-unknown-elf-objdump -i 2>&1 | grep 'elf64-big' >/dev/null 2>&1;
then echo 'riscv64-unknown-elf-';
elif riscv64-linux-gnu-objdump -i 2>&1 | grep 'elf64-big' >/dev/null 2>&1;
then echo 'riscv64-linux-gnu-';
elif riscv64-unknown-linux-gnu-objdump -i 2>&1 | grep 'elf64-big' >/dev/null 2>&1;
then echo 'riscv64-unknown-linux-gnu-';
else echo "***" 1>&2;
echo "*** Error: Couldn't find a riscv64 version of GCC/binutils." 1>&2;
echo "*** To turn off this error, run 'gmake TOOLPREFIX= ...'." 1>&2;
echo "***" 1>&2; exit 1; fi)
endif
# qemu模拟器可执行文件名称
QEMU = qemu-system-riscv64
# c编译器命令
CC = $(TOOLPREFIX)gcc
# 汇编器命令
AS = $(TOOLPREFIX)gas
# 链接器命令
LD = $(TOOLPREFIX)ld
# 目标文件复制工具命令
OBJCOPY = $(TOOLPREFIX)objcopy
# 目标文件反汇编工具命令
OBJDUMP = $(TOOLPREFIX)objdump
# 定义c编译器选项: -Wall -> 开启所有警告信息 , -Werror -> 将所有警告视为错误
# -O -> 启用基本的优化选项 , -fno-omit-frame-pointer -> 禁用省略帧指针优化
# --ggdb -> 生成适用于GDB调试器的调试信息
CFLAGS = -Wall -Werror -O -fno-omit-frame-pointer -ggdb
# -D选项用于在预处理阶段定义宏并设置其值
ifdef LAB
LABUPPER = $(shell echo $(LAB) | tr a-z A-Z)
XCFLAGS += -DSOL_$(LABUPPER) -DLAB_$(LABUPPER)
endif
# 继续追加定义C编译器相关选项
# 包含了在特定实验或解决方案中定义的宏 -- 如上面的LAB实验中定义的宏
CFLAGS += $(XCFLAGS)
# 在编译源文件时自动生成依赖关系文件。
# 这些依赖关系文件记录了每个源文件所依赖的头文件,以便在后续编译中自动处理文件间的依赖关系。
CFLAGS += -MD
# 设置代码模型(code model)为 medany,其中 medany 表示 "medium code model, any address" --> 地址无关的代码
# 这意味着编译器可以生成代码,适用于位于任何地址空间中的程序,但是有一些限制。这通常用于 64 位 RISC-V 架构
CFLAGS += -mcmodel=medany
# -ffreestanding: 生成独立运行的代码,即代码不依赖于标准库或操作系统提供的额外支持。通常用于裸机嵌入式系统或操作系统内核的开发
# -fno-common: 禁止编译器将未初始化的全局变量和函数定义放置在公共(common)段中。这是为了避免因为全局变量在多个源文件中重复定义而导致链接错误。
# -nostdlib: 不链接标准 C 库,因此代码必须自己实现所有必需的运行时函数
# -mno-relax: 不要使用指令重定位优化。在链接阶段可能会进行指令重定位,但该选项可以避免这种情况,确保代码的准确性
CFLAGS += -ffreestanding -fno-common -nostdlib -mno-relax
# 在当前目录中查找头文件,以便能够正确包含本地头文件
CFLAGS += -I.
# 检查编译器是否支持 -fno-stack-protector 选项。如果支持,则将其加入 CFLAGS 中。
# 这个选项用于禁用栈保护,即禁用编译器对栈溢出的保护措施。这在一些特定的裸机或操作系统内核开发场景中可能是必需的
CFLAGS += $(shell $(CC) -fno-stack-protector -E -x c /dev/null >/dev/null 2>&1 && echo -fno-stack-protector)
# -D选项用于在预处理阶段定义宏并设置其值
ifeq ($(LAB),net)
CFLAGS += -DNET_TESTS_PORT=$(SERVERPORT)
endif
# 检查编译器是否支持PIE(Position Independent Executable)选项,并根据检查结果添加对应的编译选项
# Disable PIE when possible (for Ubuntu 16.10 toolchain)
# PIE是一种在内存中加载程序时地址空间随机化的安全特性,它可以增加程序的安全性,防止某些类型的攻击。
# 如果编译器支持PIE选项,那么程序在编译和链接时会启用PIE特性,从而生成一个位置无关的可执行文件。
ifneq ($(shell $(CC) -dumpspecs 2>/dev/null | grep -e '[^f]no-pie'),)
# 如果编译器支持-fno-pie选项,就将-fno-pie和-no-pie添加到CFLAGS中。
# -fno-pie选项告诉编译器不要生成位置无关的可执行文件,而-no-pie选项告诉链接器不要生成位置无关的可执行文件
CFLAGS += -fno-pie -no-pie
endif
ifneq ($(shell $(CC) -dumpspecs 2>/dev/null | grep -e '[^f]nopie'),)
# 如果编译器支持-fno-pie选项,就将-fno-pie和-nopie添加到CFLAGS中。-nopie选项告诉链接器不要生成位置无关的可执行文件
CFLAGS += -fno-pie -nopie
endif
# 在链接时,它告诉链接器将生成的程序的最大页大小设置为4096字节(4KB)
LDFLAGS = -z max-page-size=4096
# 指定了生成 kernel 可执行文件的依赖关系。
# 它依赖于 OBJS 中列出的一系列目标文件(如:entry.o, start.o, console.o, 等等)、kernel.ld 文件和 U/initcode 文件
$K/kernel: $(OBJS) $K/kernel.ld $U/initcode
# 这是生成 kernel 可执行文件的命令。$(LD) 是链接器的路径和名称,$(LDFLAGS) 是链接器选项,
# -T $K/kernel.ld 指定链接器使用 kernel.ld 文件作为链接脚本,-o $K/kernel 指定输出文件名为 kernel,$(OBJS) 是链接的目标文件列表。
$(LD) $(LDFLAGS) -T $K/kernel.ld -o $K/kernel $(OBJS)
# 将 kernel 可执行文件的反汇编内容输出到 kernel.asm 文件中
$(OBJDUMP) -S $K/kernel > $K/kernel.asm
# 它从 kernel 可执行文件中提取符号表信息,并将其输出到 kernel.sym 文件中
$(OBJDUMP) -t $K/kernel | sed '1,/SYMBOL TABLE/d; s/ .* / /; /^$$/d' > $K/kernel.sym
# 指定了生成 initcode 目标文件的依赖关系。它依赖于 U/initcode.S 汇编代码文件
$U/initcode: $U/initcode.S
# 这是生成 initcode.o 目标文件的命令。
# $(CC) 是 C 编译器的路径和名称,$(CFLAGS) 是编译器选项,-march=rv64g 指定编译为 RV64G 架构(RISC-V 64-bit,带乘法/除法指令集)
# -nostdinc 禁止包含标准库头文件,-I. -Ikernel 指定头文件搜索路径
# -c $U/initcode.S -o $U/initcode.o 指定编译 U/initcode.S 并输出为 U/initcode.o 目标文件
$(CC) $(CFLAGS) -march=rv64g -nostdinc -I. -Ikernel -c $U/initcode.S -o $U/initcode.o
# 这是生成 initcode.out 文件的命令,-N 表示生成无符号的可执行文件,-e start 指定程序的入口地址为 start,-Ttext 0 指定代码段的起始地址为0
# -o $U/initcode.out 指定输出文件名为 initcode.out。
$(LD) $(LDFLAGS) -N -e start -Ttext 0 -o $U/initcode.out $U/initcode.o
# 将 initcode.out 文件中的内容复制到 initcode 文件中,并且去除了目标文件中的一些附加信息
# 使得 initcode 文件只包含可执行的初始化代码,而不包含目标文件的元数据和调试信息
$(OBJCOPY) -S -O binary $U/initcode.out $U/initcode
# 将 initcode.o 目标文件的反汇编内容输出到 initcode.asm 文件中
$(OBJDUMP) -S $U/initcode.o > $U/initcode.asm
# tags 目标是用来生成一个文本文件,其中包含了代码中定义的所有函数、变量、结构体等的标签信息。这个文件通常被用于代码编辑器进行代码导航和跳转。
tags: $(OBJS) _init
etags *.S *.c
# ULIB变量用来存储用户程序的依赖目标文件
ULIB = $U/ulib.o $U/usys.o $U/printf.o $U/umalloc.o
ifeq ($(LAB),$(filter $(LAB), pgtbl lock))
ULIB += $U/statistics.o
endif
# 匹配: 目标文件是以 _ 开头的,并且依赖于同名的 .o 文件和 ULIB 变量中的目标文件
_%: %.o $(ULIB)
# 将目标文件链接成一个没有可执行代码的目标文件,并指定程序入口地址为 main,并将输出文件的名称设置为当前规则的目标文件
$(LD) $(LDFLAGS) -N -e main -Ttext 0 -o $@ $^
# 将生成的可执行文件进行反汇编,并将反汇编的结果保存到同名的 .asm 文件中
$(OBJDUMP) -S $@ > $*.asm
# 将生成的可执行文件进行符号表提取,并将符号表保存到同名的 .sym 文件中。sed 命令用于过滤掉符号表中的不需要的信息
$(OBJDUMP) -t $@ | sed '1,/SYMBOL TABLE/d; s/ .* / /; /^$$/d' > $*.sym
# 根据 usys.pl 脚本生成 usys.S 汇编文件
$U/usys.S : $U/usys.pl
perl $U/usys.pl > $U/usys.S
# 将 usys.S 汇编文件编译成目标文件 usys.o
$U/usys.o : $U/usys.S
$(CC) $(CFLAGS) -c -o $U/usys.o $U/usys.S
# 将 forktest.o,ulib.o,usys.o 目标文件链接成一个可执行文件 _forktest
# 生成 _forktest 可执行文件的反汇编代码,并将结果输出到 forktest.asm 文件
$U/_forktest: $U/forktest.o $(ULIB)
# forktest has less library code linked in - needs to be small
# in order to be able to max out the proc table.
$(LD) $(LDFLAGS) -N -e main -Ttext 0 -o $U/_forktest $U/forktest.o $U/ulib.o $U/usys.o
$(OBJDUMP) -S $U/_forktest > $U/forktest.asm
# 将mkfs/mkfs.c文件编译成mkfs可执行文件
mkfs/mkfs: mkfs/mkfs.c $K/fs.h $K/param.h
gcc $(XCFLAGS) -Werror -Wall -I. -o mkfs/mkfs mkfs/mkfs.c
# Prevent deletion of intermediate files, e.g. cat.o, after first build, so
# that disk image changes after first build are persistent until clean. More
# details:
# http://www.gnu.org/software/make/manual/html_node/Chained-Rules.html
.PRECIOUS: %.o
# 构建用户程序lib库的文件组成列表
UPROGS=
$U/_cat
$U/_echo
$U/_forktest
$U/_grep
$U/_init
$U/_kill
$U/_ln
$U/_ls
$U/_mkdir
$U/_rm
$U/_sh
$U/_stressfs
$U/_usertests
$U/_grind
$U/_wc
$U/_zombie
ifeq ($(LAB),$(filter $(LAB), pgtbl lock))
UPROGS +=
$U/_stats
endif
ifeq ($(LAB),traps)
UPROGS +=
$U/_call
$U/_bttest
endif
ifeq ($(LAB),lazy)
UPROGS +=
$U/_lazytests
endif
ifeq ($(LAB),cow)
UPROGS +=
$U/_cowtest
endif
ifeq ($(LAB),thread)
UPROGS +=
$U/_uthread
$U/uthread_switch.o : $U/uthread_switch.S
$(CC) $(CFLAGS) -c -o $U/uthread_switch.o $U/uthread_switch.S
$U/_uthread: $U/uthread.o $U/uthread_switch.o $(ULIB)
$(LD) $(LDFLAGS) -N -e main -Ttext 0 -o $U/_uthread $U/uthread.o $U/uthread_switch.o $(ULIB)
$(OBJDUMP) -S $U/_uthread > $U/uthread.asm
ph: notxv6/ph.c
gcc -o ph -g -O2 notxv6/ph.c -pthread
barrier: notxv6/barrier.c
gcc -o barrier -g -O2 notxv6/barrier.c -pthread
endif
ifeq ($(LAB),lock)
UPROGS +=
$U/_kalloctest
$U/_bcachetest
endif
ifeq ($(LAB),fs)
UPROGS +=
$U/_bigfile
endif
ifeq ($(LAB),net)
UPROGS +=
$U/_nettests
endif
UEXTRA=
ifeq ($(LAB),util)
UEXTRA += user/xargstest.sh
endif
# 构建fs.img文件系统镜像文件
fs.img: mkfs/mkfs README $(UEXTRA) $(UPROGS)
# 传递个给mkfs可执行程序的参数,由mkfs可执行程序完成文件系统镜像构建功能
mkfs/mkfs fs.img README $(UEXTRA) $(UPROGS)
-include kernel/*.d user/*.d
# 清理掉所有编译生成的文件
clean:
rm -f *.tex *.dvi *.idx *.aux *.log *.ind *.ilg
*/*.o */*.d */*.asm */*.sym
$U/initcode $U/initcode.out $K/kernel fs.img
mkfs/mkfs .gdbinit
$U/usys.S
$(UPROGS)
# try to generate a unique GDB port
GDBPORT = $(shell expr `id -u` % 5000 + 25000)
# QEMU's gdb stub command line changed in 0.11
QEMUGDB = $(shell if $(QEMU) -help | grep -q '^-gdb';
then echo "-gdb tcp::$(GDBPORT)";
else echo "-s -p $(GDBPORT)"; fi)
# 设置QEMU模拟器启动时CPU数量
ifndef CPUS
CPUS := 3
endif
ifeq ($(LAB),fs)
CPUS := 1
endif
FWDPORT = $(shell expr `id -u` % 5000 + 25999)
# -machine virt: 这个选项指定虚拟机使用virtio模式运行,用于支持virtio设备的虚拟化。
# -bios none: 这个选项指定不使用BIOS固件,即不加载任何BIOS。
# -kernel $K/kernel: 这个选项指定虚拟机启动时使用的内核文件的路径和名称。其中$K是一个变量,代表内核文件所在的目录,kernel是内核文件的名称。
# -m 128M: 这个选项指定虚拟机的内存大小为128MB。
# -smp $(CPUS): 这个选项指定虚拟机的CPU核心数,$(CPUS)是一个变量,表示指定的CPU核心数。
# -nographic: 这个选项指定虚拟机以非图形化模式运行,即在命令行终端中显示输出,而不是使用图形界面。
QEMUOPTS = -machine virt -bios none -kernel $K/kernel -m 128M -smp $(CPUS) -nographic
# -drive file=fs.img,if=none,format=raw,id=x0: 这个选项指定虚拟机使用一个磁盘镜像文件作为虚拟硬盘。
# file=fs.img表示虚拟硬盘的文件路径和名称为fs.img
# if=none表示磁盘接口类型为none(即不使用默认接口)
# format=raw表示磁盘镜像文件的格式为raw(原始格式)
# id=x0表示为这个虚拟硬盘指定了一个唯一的标识符为x0。
QEMUOPTS += -drive file=fs.img,if=none,format=raw,id=x0
# -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0: 这个选项指定将一个virtio块设备连接到虚拟机上。
# virtio-blk-device表示设备类型为virtio块设备
# drive=x0表示将之前定义的虚拟硬盘x0连接到该设备上
# bus=virtio-mmio-bus.0表示设备连接到virtio总线的第一个MMIO总线上。
QEMUOPTS += -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0
ifeq ($(LAB),net)
QEMUOPTS += -netdev user,id=net0,hostfwd=udp::$(FWDPORT)-:2000 -object filter-dump,id=net0,netdev=net0,file=packets.pcap
QEMUOPTS += -device e1000,netdev=net0,bus=pcie.0
endif
# qemu目标依赖于内核文件和文件系统镜像构建完成
qemu: $K/kernel fs.img
# 启动qemu,参数就是QEMUOPTS定义的
$(QEMU) $(QEMUOPTS)
.gdbinit: .gdbinit.tmpl-riscv
sed "s/:1234/:$(GDBPORT)/" < $^ > $@
qemu-gdb: $K/kernel .gdbinit fs.img
@echo "*** Now run 'gdb' in another window." 1>&2
$(QEMU) $(QEMUOPTS) -S $(QEMUGDB)
...
mkfs程序源码注释:
- 工具类方法
// fsfd是fs.img文件系统镜像文件的文件描述符
// 将buf内容写入文件系统第sec个block中
void
wsect(uint sec, void *buf)
{
if(lseek(fsfd, sec * BSIZE, 0) != sec * BSIZE){
perror("lseek");
exit(1);
}
if(write(fsfd, buf, BSIZE) != BSIZE){
perror("write");
exit(1);
}
}
// 读取文件系统第sec个块到buf中
void
rsect(uint sec, void *buf)
{
if(lseek(fsfd, sec * BSIZE, 0) != sec * BSIZE){
perror("lseek");
exit(1);
}
if(read(fsfd, buf, BSIZE) != BSIZE){
perror("read");
exit(1);
}
}
// 更新磁盘上对应inode的信息
void
winode(uint inum, struct dinode *ip)
{
char buf[BSIZE];
uint bn;
struct dinode *dip;
// 获取当前inode所在的inode block number
bn = IBLOCK(inum, sb);
// 将该inode block读取到内存中来
rsect(bn, buf);
// 通过偏移得到buf中inode的地址
dip = ((struct dinode*)buf) + (inum % IPB);
// 将内存中Inode的值赋值为传入的ip
*dip = *ip;
// 重新将这块Block写入磁盘
wsect(bn, buf);
}
// 从磁盘上读取出对应inode的信息,然后赋值给ip
void
rinode(uint inum, struct dinode *ip)
{
char buf[BSIZE];
uint bn;
struct dinode *dip;
bn = IBLOCK(inum, sb);
rsect(bn, buf);
dip = ((struct dinode*)buf) + (inum % IPB);
*ip = *dip;
}
// 分配下一个空闲的inode
uint
ialloc(ushort type)
{
uint inum = freeinode++;
struct dinode din;
// 将dinode清零
bzero(&din, sizeof(din));
// 清零后,重新赋值
// inode类型,链接数和大小
din.type = xshort(type);
din.nlink = xshort(1);
din.size = xint(0);
// 将该inode写入磁盘
winode(inum, &din);
return inum;
}
// 分配bitmap block,used表示已经使用的block数量
void
balloc(int used)
{
uchar buf[BSIZE];
int i;
printf("balloc: first %d blocks have been allocatedn", used);
assert(used < BSIZE*8);
bzero(buf, BSIZE);
// 将已经使用的block,在bitmap block中对应为设置为1
for(i = 0; i < used; i++){
buf[i/8] = buf[i/8] | (0x1 << (i%8));
}
printf("balloc: write bitmap block at sector %dn", sb.bmapstart);
// 更新bitmap block到磁盘
wsect(sb.bmapstart, buf);
}
- iappend方法: 向某个inode代表的文件中追加数据
// xp是数据缓冲区,n是追加数据大小
void
iappend(uint inum, void *xp, int n)
{
char *p = (char*)xp;
uint fbn, off, n1;
struct dinode din;
char buf[BSIZE];
uint indirect[NINDIRECT];
uint x;
// 从磁盘读取出inum对应的inode信息到din中
rinode(inum, &din);
// 每个inode代表一个文件,size表示文件的已有的数据量大小
off = xint(din.size);
// printf("append inum %d at off %d sz %dn", inum, off, n);
// 如果写入数据量比较大,那么会分批次多次写入
while(n > 0){
// 计算写入地址在当前inode的blocks数组中对应的索引
fbn = off / BSIZE;
assert(fbn < MAXFILE);
// 1.定位数据需要写入到哪个block中
// 默认情况下,每个Inode都有12个直接块和1个间接块
// 如果处于直接块范畴
if(fbn < NDIRECT){
// 如果当前直接块条目的块号还没确定,那么赋值为当前空闲可用块的block number
if(xint(din.addrs[fbn]) == 0){
din.addrs[fbn] = xint(freeblock++);
}
// 获取这个直接块条目记录的block number
x = xint(din.addrs[fbn]);
} else {
// 如果属于间接块,并且该间接块条目的块号没有确定,那么赋值为当前空闲可用块的block number
if(xint(din.addrs[NDIRECT]) == 0){
din.addrs[NDIRECT] = xint(freeblock++);
}
// 从磁盘读取出这个间接块 --- 间接块中记录的都是block number
rsect(xint(din.addrs[NDIRECT]), (char*)indirect);
// 判断对应间接块中的条目是否为0,如果为0赋值为新的空闲块号
if(indirect[fbn - NDIRECT] == 0){
indirect[fbn - NDIRECT] = xint(freeblock++);
// 该间接块内容被修改了,需要重新写入磁盘
wsect(xint(din.addrs[NDIRECT]), (char*)indirect);
}
// 获得对应的间接块条目号记录的block number
x = xint(indirect[fbn-NDIRECT]);
}
// 2. 现在x记录着数据需要写入的block number,下一步将数据写入对应的Block中
// 在目标写入块剩余大小和当前要写入数据大小之间取较小者
n1 = min(n, (fbn + 1) * BSIZE - off);
// 读取对应目标块,然后在指定位置写入对应的数据,最后将目标块重新写入磁盘
rsect(x, buf);
bcopy(p, buf + off - (fbn * BSIZE), n1);
wsect(x, buf);
// 剩余写入数据量减少 -- 一次写不完,会分多次写入
n -= n1;
// 当前inode写入数据偏移量增加
off += n1;
// 源数据缓冲区写入指针前推
p += n1;
}
// 更新当前Inode的写入偏移量,然后写入磁盘
din.size = xint(off);
winode(inum, &din);
}
- 核心main方法
int
main(int argc, char *argv[])
{
int i, cc, fd;
uint rootino, inum, off;
struct dirent de;
char buf[BSIZE];
struct dinode din;
static_assert(sizeof(int) == 4, "Integers must be 4 bytes!");
if(argc < 2){
fprintf(stderr, "Usage: mkfs fs.img files...n");
exit(1);
}
assert((BSIZE % sizeof(struct dinode)) == 0);
assert((BSIZE % sizeof(struct dirent)) == 0);
// argv[1] 是 fs.img 文件系统镜像文件
fsfd = open(argv[1], O_RDWR|O_CREAT|O_TRUNC, 0666);
if(fsfd < 0){
perror(argv[1]);
exit(1);
}
// 1 fs block = 1 disk sector
// 元数据块数量 = boot block + sb block + log blocks + inode blocks + bit map blocks + data blocks
nmeta = 2 + nlog + ninodeblocks + nbitmap;
// 计算数据块数量
nblocks = FSSIZE - nmeta;
// 填充super block块内容
sb.magic = FSMAGIC; // 魔数
sb.size = xint(FSSIZE); // 总block数量
sb.nblocks = xint(nblocks); // 数据块数量
sb.ninodes = xint(NINODES); // inode块数量
sb.nlog = xint(nlog); // 日志块数量
sb.logstart = xint(2); // 第一个日志块块号
sb.inodestart = xint(2+nlog);// 第一个inode块块号
sb.bmapstart = xint(2+nlog+ninodeblocks); // 第一个bit map块块号
printf("nmeta %d (boot, super, log blocks %u inode blocks %u, bitmap blocks %u) blocks %d total %dn",
nmeta, nlog, ninodeblocks, nbitmap, nblocks, FSSIZE);
// 文件系统初始化情况下可用数据块起始块号
freeblock = nmeta; // the first free block that we can allocate
// 将文件系统所有block都清零
for(i = 0; i < FSSIZE; i++)
wsect(i, zeroes);
// 将buf清零
memset(buf, 0, sizeof(buf));
// 向buf写入super block内容
memmove(buf, &sb, sizeof(sb));
// 向文件系统编号为1的block写入buf的内容,也就是将super block内容写入到磁盘上
wsect(1, buf);
// 分配一个空闲的inode -- 该inode作为root inode的inode number
// 这里root ionde指的是根目录对应的inode
rootino = ialloc(T_DIR);
assert(rootino == ROOTINO);
// 每个目录下都默认存在两个目录条目项: . 和 ..
// 清空内存中直接块结构体
bzero(&de, sizeof(de));
// 清空后重新赋值 -- inode number 和 文件名
de.inum = xshort(rootino);
strcpy(de.name, ".");
// 把这个目录项追加到root目录对应Inode block的直接块中
iappend(rootino, &de, sizeof(de));
// 清空de inode,重用该结构体,向磁盘追加一个名为 .. 的目录文件
bzero(&de, sizeof(de));
de.inum = xshort(rootino);
strcpy(de.name, "..");
// 同样把这个目录项追加到对应的直接块中
iappend(rootino, &de, sizeof(de));
// 处理需要打包进文件系统镜像的剩余文件
// 主要是user目录下的文件
for(i = 2; i < argc; i++){
// get rid of "user/"
// 移除user目录下路径名的目录前缀 -- 如果有的话就移除
char *shortname;
if(strncmp(argv[i], "user/", 5) == 0)
shortname = argv[i] + 5;
else
shortname = argv[i];
assert(index(shortname, '/') == 0);
// 获取第i个用户lib库程序的文件描述符
if((fd = open(argv[i], 0)) < 0){
perror(argv[i]);
exit(1);
}
// Skip leading _ in name when writing to file system.
// The binaries are named _rm, _cat, etc. to keep the
// build operating system from trying to execute them
// in place of system binaries like rm and cat.
// 传递给mkfs程序的用户程序文件名都是_开头的二进制文件,这里将_移除
if(shortname[0] == '_')
shortname += 1;
// 分配一个空闲inode
inum = ialloc(T_FILE);
// 清空inode,然后填入本次获取的用户程序文件相关信息
bzero(&de, sizeof(de));
de.inum = xshort(inum);
strncpy(de.name, shortname, DIRSIZ);
// 所有用户程序文件都放置在root目录下,所以这里将当前文件对应目录项追加到root目录对应的直接块中
// 如果文件很多,可能会追加到间接块中
iappend(rootino, &de, sizeof(de));
// 将当前文件内容读取出来,追加到当前文件inode对应的block中
while((cc = read(fd, buf, sizeof(buf))) > 0)
iappend(inum, buf, cc);
close(fd);
}
// fix size of root inode dir
// 更新root inode的size大小
rinode(rootino, &din);
off = xint(din.size);
off = ((off/BSIZE) + 1) * BSIZE;
din.size = xint(off);
winode(rootino, &din);
// 更新bitmap block
balloc(freeblock);
exit(0);
}
看什么
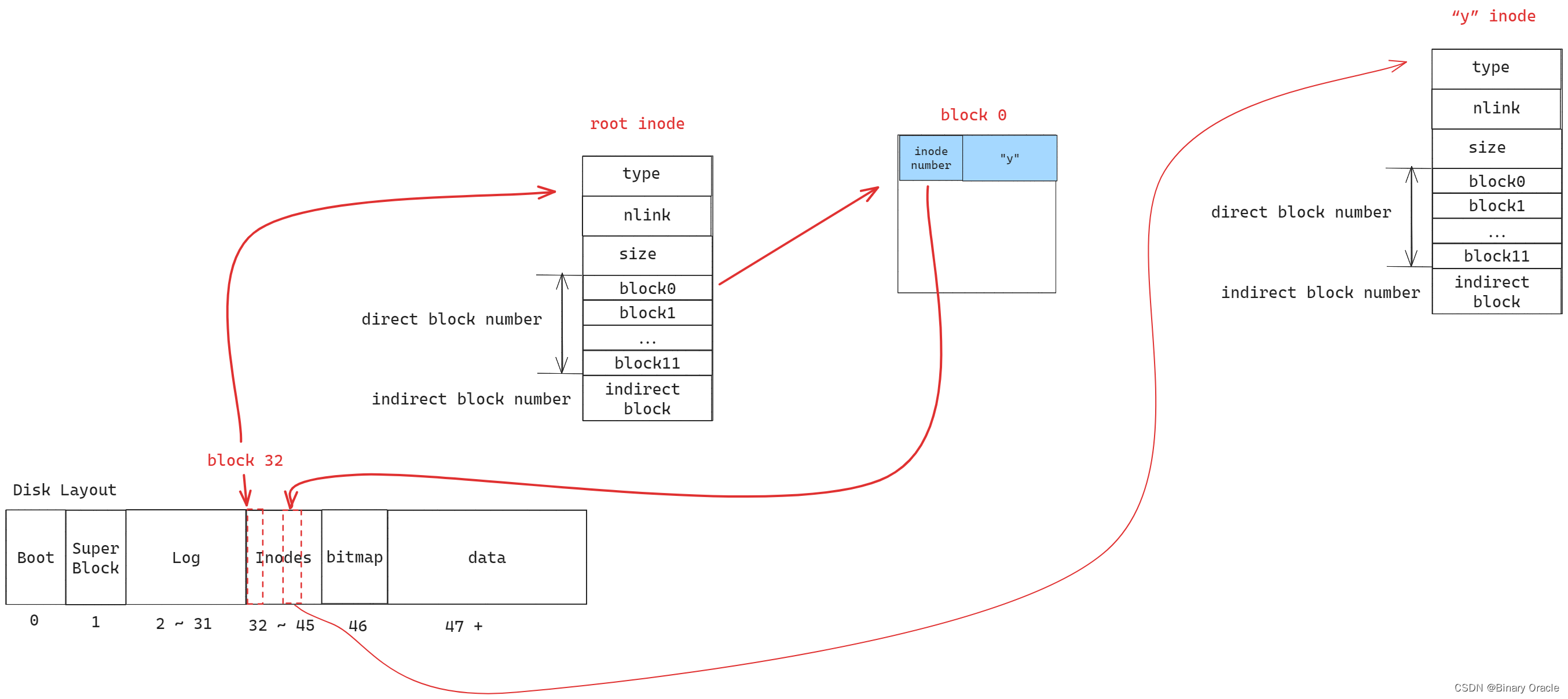
磁盘索引节点的格式由fs.h中的struct dinode定义。您应当尤其对NDIRECT、NINDIRECT、MAXFILE和struct dinode的addrs[]元素感兴趣。查看《XV6手册》中的图8.3,了解标准xv6索引结点的示意图。
// 磁盘上存储的inode结构
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+1]; // Data block addresses
};
// 目录block中存储的目录项结构
struct dirent {
ushort inum;
char name[DIRSIZ];
};
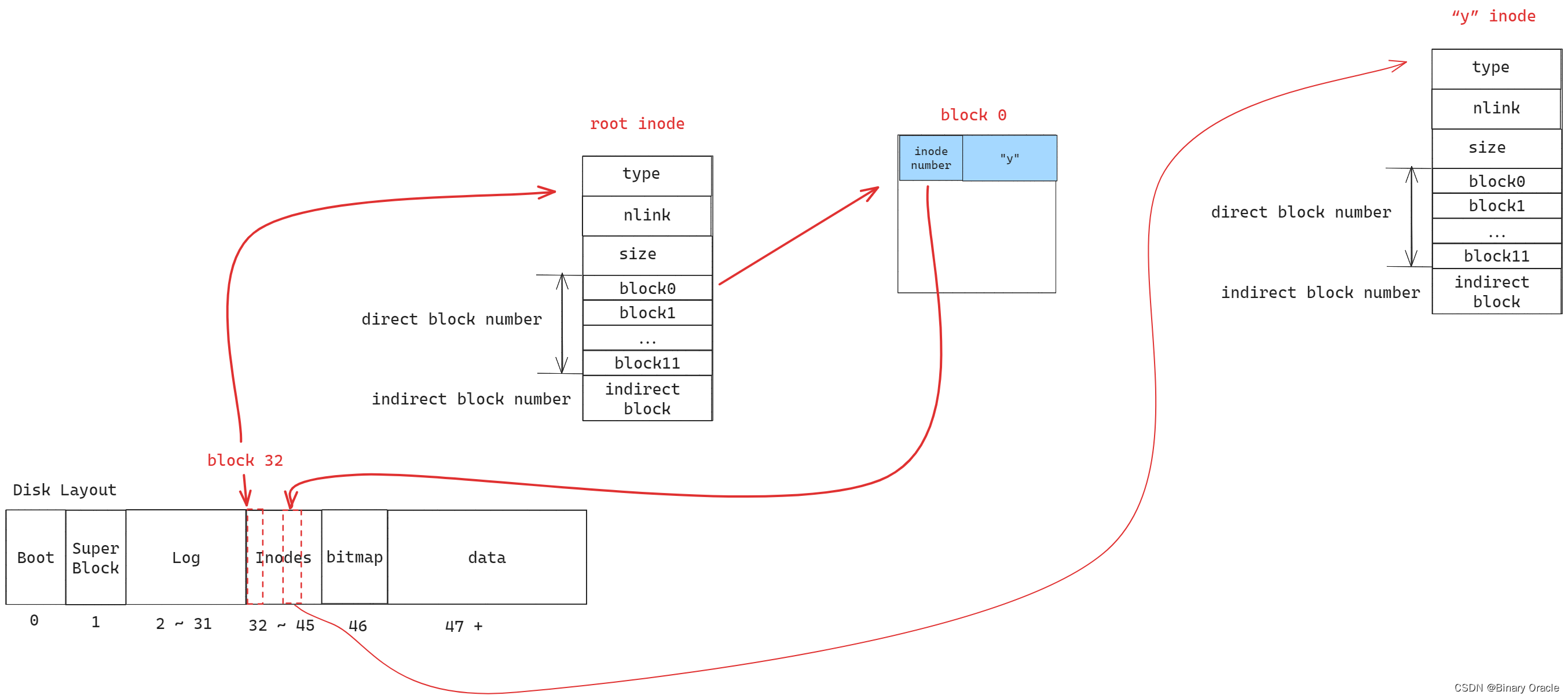
在磁盘上查找文件数据的代码位于fs.c的bmap()中。看看它,确保你明白它在做什么。在读取和写入文件时都会调用bmap()。写入时,bmap()会根据需要分配新块以保存文件内容,如果需要,还会分配间接块以保存块地址。
bmap()处理两种类型的块编号。bn参数是一个“逻辑块号”——文件中相对于文件开头的块号。ip->addrs[]中的块号和bread()的参数都是磁盘块号。您可以将bmap()视为将文件的逻辑块号映射到磁盘块号。
// Return the disk block address of the nth block in inode ip.
// If there is no such block, bmap allocates one.
// 传入inode和希望读取的逻辑块号,返回该逻辑块号对应的磁盘块号
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
// 如果逻辑块号指向的是直接块,然后直接块条目中存储的就是对应的磁盘块号
if(bn < NDIRECT){
// 如果直接块还没有分配,那么先调用balloc分配一个空闲的block
if((addr = ip->addrs[bn]) == 0)
ip->addrs[bn] = addr = balloc(ip->dev);
return addr;
}
bn -= NDIRECT;
// 如果逻辑块号指向的是间接块
if(bn < NINDIRECT){
// Load indirect block, allocating if necessary.
// 先定位到对应的间接块 -- 同样没分配就先进行分配
if((addr = ip->addrs[NDIRECT]) == 0)
ip->addrs[NDIRECT] = addr = balloc(ip->dev);
bp = bread(ip->dev, addr);
// 拿到间接块的数据
a = (uint*)bp->data;
// 那么在间接块block中定位到一级间接块条目存储的磁盘块号,并返回
if((addr = a[bn]) == 0){
// 没分配先分配,由于这里更改了间接块中某个一级间接条目的内容,所以需要记录log日志,等待后续刷脏
a[bn] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
panic("bmap: out of range");
}
你的工作
修改bmap(),以便除了直接块和一级间接块之外,它还实现二级间接块。你只需要有11个直接块,而不是12个,为你的新的二级间接块腾出空间;不允许更改磁盘inode的大小。ip->addrs[]的前11个元素应该是直接块;第12个应该是一个一级间接块(与当前的一样);13号应该是你的新二级间接块。当bigfile写入65803个块并成功运行usertests时,此练习完成:
$ bigfile
..................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
wrote 65803 blocks
done; ok
$ usertests
...
ALL TESTS PASSED
$
运行bigfile至少需要一分钟半的时间。
提示:
- 确保您理解
bmap()。写出ip->addrs[]、间接块、二级间接块和它所指向的一级间接块以及数据块之间的关系图。确保您理解为什么添加二级间接块会将最大文件大小增加256*256个块(实际上要-1,因为您必须将直接块的数量减少一个)。 - 考虑如何使用逻辑块号索引二级间接块及其指向的间接块。
- 如果更改
NDIRECT的定义,则可能必须更改file.h文件中struct inode中addrs[]的声明。确保struct inode和struct dinode在其addrs[]数组中具有相同数量的元素。 - 如果更改
NDIRECT的定义,请确保创建一个新的fs.img,因为mkfs使用NDIRECT构建文件系统。 - 如果您的文件系统进入坏状态,可能是由于崩溃,请删除fs.img(从Unix而不是xv6执行此操作)。
make将为您构建一个新的干净文件系统映像。 - 别忘了把你
bread()的每一个块都brelse()。 - 您应该仅根据需要分配间接块和二级间接块,就像原始的
bmap()。 - 确保
itrunc释放文件的所有块,包括二级间接块。
代码解析
(1). 在fs.h中添加宏定义
// 旧的值
// 直接块数量
#define NDIRECT 12
// 间接块中记录的block数量
#define NINDIRECT (BSIZE / sizeof(uint))
// 一个文件最多有多少个数据块
#define MAXFILE (NDIRECT + NINDIRECT)
// 新的值
// 直接块数量
#define NDIRECT 11
// 间接块中记录的block数量
#define NINDIRECT (BSIZE / sizeof(uint))
// 二级间接块能够记录的block数量
#define NDINDIRECT ((BSIZE / sizeof(uint)) * (BSIZE / sizeof(uint)))
// 一个文件最多能记录多少个数据块
#define MAXFILE (NDIRECT + NINDIRECT + NDINDIRECT)
// 一级间接块能够记录的block数量
#define NADDR_PER_BLOCK (BSIZE / sizeof(uint))
(2). 由于NDIRECT定义改变,其中一个直接块变为了二级间接块,需要修改inode结构体中addrs元素数量
// On-disk inode structure
struct dinode {
short type; // File type
short major; // Major device number (T_DEVICE only)
short minor; // Minor device number (T_DEVICE only)
short nlink; // Number of links to inode in file system
uint size; // Size of file (bytes)
uint addrs[NDIRECT+2]; // Data block addresses
};
// in-memory copy of an inode
struct inode {
uint dev; // Device number
uint inum; // Inode number
int ref; // Reference count
struct sleeplock lock; // protects everything below here
int valid; // inode has been read from disk?
short type; // copy of disk inode
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+2];
};
(3). 修改bmap支持二级索引
// Return the disk block address of the nth block in inode ip.
// If there is no such block, bmap allocates one.
// 传入inode和希望读取的逻辑块号,返回该逻辑块号对应的磁盘块号
static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
// 如果逻辑块号指向的是直接块,然后直接块条目中存储的就是对应的磁盘块号
if(bn < NDIRECT){
// 如果直接块还没有分配,那么先调用balloc分配一个空闲的block
if((addr = ip->addrs[bn]) == 0)
ip->addrs[bn] = addr = balloc(ip->dev);
return addr;
}
bn -= NDIRECT;
// 如果逻辑块号指向的是间接块
if(bn < NINDIRECT){
// Load indirect block, allocating if necessary.
// 先定位到对应的间接块 -- 同样没分配就先进行分配
if((addr = ip->addrs[NDIRECT]) == 0)
ip->addrs[NDIRECT] = addr = balloc(ip->dev);
bp = bread(ip->dev, addr);
// 拿到间接块的数据
a = (uint*)bp->data;
// 那么在间接块block中定位到一级间接块条目存储的磁盘块号,并返回
if((addr = a[bn]) == 0){
// 没分配先分配,由于这里更改了间接块中某个一级间接条目的内容,所以需要记录log日志,等待后续刷脏
a[bn] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
//========新增加的内容====================
bn-=NINDIRECT;
// 二级间接块的情况
if(bn < NDINDIRECT) {
int level2_idx = bn / NADDR_PER_BLOCK; // 要查找的块号位于二级间接块中的位置
int level1_idx = bn % NADDR_PER_BLOCK; // 要查找的块号位于一级间接块中的位置
// 读出二级间接块
if((addr = ip->addrs[NDIRECT + 1]) == 0)
ip->addrs[NDIRECT + 1] = addr = balloc(ip->dev);
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[level2_idx]) == 0) {
a[level2_idx] = addr = balloc(ip->dev);
// 更改了当前块的内容,标记以供后续写回磁盘
log_write(bp);
}
brelse(bp);
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if((addr = a[level1_idx]) == 0) {
a[level1_idx] = addr = balloc(ip->dev);
log_write(bp);
}
brelse(bp);
return addr;
}
panic("bmap: out of range");
}
(4). 修改itrunc释放所有块
// Truncate inode (discard contents).
// Caller must hold ip->lock.
void
itrunc(struct inode *ip)
{
int i, j;
struct buf *bp;
uint *a;
// 先释放直接块
for(i = 0; i < NDIRECT; i++){
if(ip->addrs[i]){
bfree(ip->dev, ip->addrs[i]);
ip->addrs[i] = 0;
}
}
// 释放一级间接块
if(ip->addrs[NDIRECT]){
bp = bread(ip->dev, ip->addrs[NDIRECT]);
a = (uint*)bp->data;
for(j = 0; j < NINDIRECT; j++){
if(a[j])
bfree(ip->dev, a[j]);
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT]);
ip->addrs[NDIRECT] = 0;
}
//=============新增加的内容===========
// 释放二级间接块
struct buf* bp1;
uint* a1;
if(ip->addrs[NDIRECT + 1]) {
bp = bread(ip->dev, ip->addrs[NDIRECT + 1]);
a = (uint*)bp->data;
for(i = 0; i < NADDR_PER_BLOCK; i++) {
// 每个一级间接块的操作都类似于上面的
// if(ip->addrs[NDIRECT])中的内容
if(a[i]) {
bp1 = bread(ip->dev, a[i]);
a1 = (uint*)bp1->data;
for(j = 0; j < NADDR_PER_BLOCK; j++) {
if(a1[j])
bfree(ip->dev, a1[j]);
}
brelse(bp1);
bfree(ip->dev, a[i]);
}
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT + 1]);
ip->addrs[NDIRECT + 1] = 0;
}
ip->size = 0;
iupdate(ip);
}
Symbolic links(moderate)
在本练习中,您将向xv6添加符号链接。符号链接(或软链接)是指按路径名链接的文件;当一个符号链接打开时,内核跟随该链接指向引用的文件。符号链接类似于硬链接,但硬链接仅限于指向同一磁盘上的文件,而符号链接可以跨磁盘设备。尽管xv6不支持多个设备,但实现此系统调用是了解路径名查找工作原理的一个很好的练习。
YOUR JOB
- 您将实现
symlink(char *target, char *path)系统调用,该调用在引用由target命名的文件的路径处创建一个新的符号链接。有关更多信息,请参阅symlink手册页(注:执行man symlink)。- 要进行测试,请将
symlinktest添加到Makefile并运行它。当测试产生以下输出(包括usertests运行成功)时,您就完成本作业了。
$ symlinktest
Start: test symlinks
test symlinks: ok
Start: test concurrent symlinks
test concurrent symlinks: ok
$ usertests
...
ALL TESTS PASSED
$
提示:
- 首先,为
symlink创建一个新的系统调用号,在user/usys.pl、user/user.h中添加一个条目,并在kernel/sysfile.c中实现一个空的sys_symlink。 - 向kernel/stat.h添加新的文件类型(
T_SYMLINK)以表示符号链接。 - 在kernel/fcntl.h中添加一个新标志(
O_NOFOLLOW),该标志可用于open系统调用。请注意,传递给open的标志使用按位或运算符组合,因此新标志不应与任何现有标志重叠。一旦将user/symlinktest.c添加到Makefile中,您就可以编译它。 - 实现
symlink(target, path)系统调用,以在path处创建一个新的指向target的符号链接。请注意,系统调用的成功不需要target已经存在。您需要选择存储符号链接目标路径的位置,例如在inode的数据块中。symlink应返回一个表示成功(0)或失败(-1)的整数,类似于link和unlink。 - 修改
open系统调用以处理路径指向符号链接的情况。如果文件不存在,则打开必须失败。当进程向open传递O_NOFOLLOW标志时,open应打开符号链接(而不是跟随符号链接)。 - 如果链接文件也是符号链接,则必须递归地跟随它,直到到达非链接文件为止。如果链接形成循环,则必须返回错误代码。你可以通过以下方式估算存在循环:通过在链接深度达到某个阈值(例如10)时返回错误代码。
- 其他系统调用(如
link和unlink)不得跟随符号链接;这些系统调用对符号链接本身进行操作。 - 您不必处理指向此实验的目录的符号链接。
硬链接
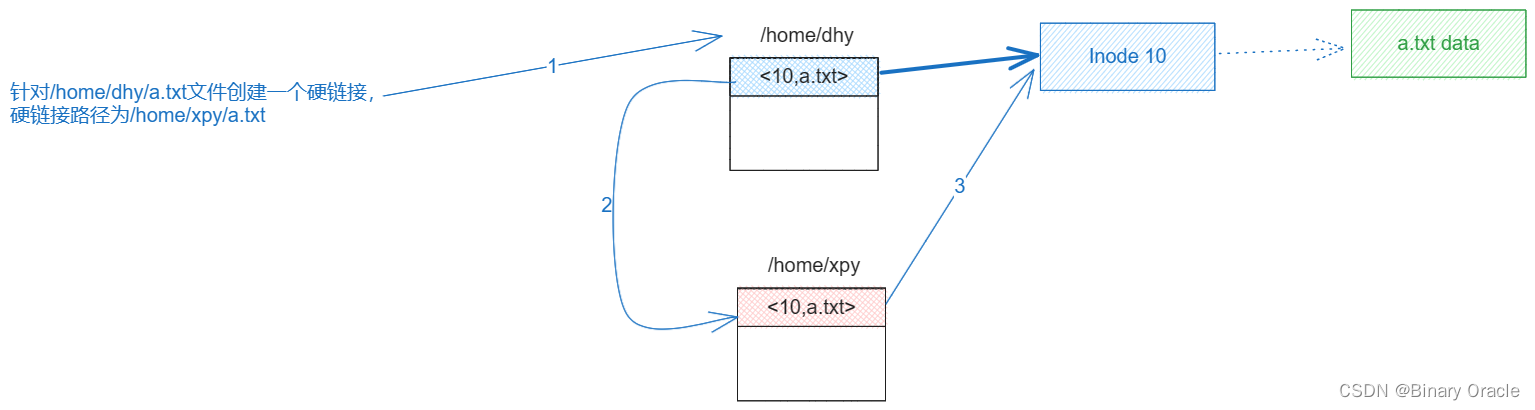
简单复习一下xv6中硬链接的实现:
在 xv6 中,硬链接是一种创建多个目录项指向同一个 inode 的方法,从而允许一个文件在文件系统中有多个不同的名称。这样,即使一个目录项被删除,文件本身仍然存在于文件系统中,只有当所有硬链接和原始文件都被删除后,inode 的数据块才会被释放。
uint64 sys_link(void) {
char name[DIRSIZ], new[MAXPATH], old[MAXPATH];
struct inode *dp, *ip;
// 从用户态获取参数 old 和 new,分别表示旧路径和新路径
if(argstr(0, old, MAXPATH) < 0 || argstr(1, new, MAXPATH) < 0)
return -1;
// 开始文件系统操作事务
begin_op();
// 根据旧路径名找到 inode
if((ip = namei(old)) == 0){
end_op();
return -1;
}
// 对 inode 进行加锁
ilock(ip);
// 检查旧路径对应的 inode 是否为目录,如果是目录则不能创建硬链接
if(ip->type == T_DIR){
iunlockput(ip); // 解锁 inode 并释放引用
end_op();
return -1;
}
// 增加 inode 的链接数,因为即将创建一个新的硬链接指向该 inode
ip->nlink++;
iupdate(ip); // 更新 inode 的磁盘信息
iunlock(ip); // 解锁 inode
// 解析新路径中的目录名和文件名
if((dp = nameiparent(new, name)) == 0)
goto bad;
// 对目录的 inode 进行加锁
ilock(dp);
// 检查新路径所在的目录的设备号与旧路径所在的设备号是否相同
// 如果不相同,或者在新路径所在的目录中无法创建新的目录项,说明创建硬链接失败
if(dp->dev != ip->dev || dirlink(dp, name, ip->inum) < 0){
iunlockput(dp); // 解锁目录的 inode 并释放引用
goto bad;
}
// 解锁目录的 inode 并释放引用
iunlockput(dp);
// 释放旧路径对应的 inode 的引用
iput(ip);
// 结束文件系统操作事务
end_op();
return 0;
bad:
// 创建硬链接失败时,需要回滚之前对旧路径 inode 的修改,即减少链接数
ilock(ip);
ip->nlink--;
iupdate(ip);
iunlockput(ip);
end_op();
return -1;
}
unlink系统调用是删除硬链接和删除普通文件的通用入口:
uint64 sys_unlink(void) {
struct inode *ip, *dp;
struct dirent de;
char name[DIRSIZ], path[MAXPATH];
uint off;
// 从用户态获取参数 path,表示要删除的文件路径
if(argstr(0, path, MAXPATH) < 0)
return -1;
// 开始文件系统操作事务
begin_op();
// 根据提供的路径,找到文件的父目录
if((dp = nameiparent(path, name)) == 0){
end_op();
return -1;
}
// 对父目录的 inode 进行加锁
ilock(dp);
// 不能删除 "." 或 ".." 目录项
if(namecmp(name, ".") == 0 || namecmp(name, "..") == 0)
goto bad;
// 根据文件名在父目录中查找对应的目录项
if((ip = dirlookup(dp, name, &off)) == 0)
goto bad;
// 对文件的 inode 进行加锁
ilock(ip);
if(ip->nlink < 1)
panic("unlink: nlink < 1");
// 如果要删除的是目录,需要确保目录为空
if(ip->type == T_DIR && !isdirempty(ip)){
iunlockput(ip); // 解锁 inode 并释放引用
goto bad;
}
// 清空目录项,并写回父目录
memset(&de, 0, sizeof(de));
if(writei(dp, 0, (uint64)&de, off, sizeof(de)) != sizeof(de))
panic("unlink: writei");
// 如果删除的是目录,需要更新父目录的链接数
if(ip->type == T_DIR){
dp->nlink--;
iupdate(dp);
}
iunlockput(dp); // 解锁父目录并释放引用
// 更新文件的链接数,并解锁文件的 inode 并释放引用
ip->nlink--;
iupdate(ip);
iunlockput(ip);
// 结束文件系统操作事务
end_op();
return 0;
bad:
// 删除操作失败时,需要解锁父目录并释放引用,并结束文件系统操作事务
iunlockput(dp);
end_op();
return -1;
}
iunlockput方法中调用iput方法来判断一个文件的硬链接数是否为0,如果为0则彻底删除该文件。
代码解析
(1). 配置系统调用的常规操作,如在user/usys.pl、user/user.h中添加一个条目,在kernel/syscall.c、kernel/syscall.h中添加相关内容
// usys.pl
entry("symlink");
// user.h
int symlink(const char*, const char*);
// syscall.h
#define SYS_symlink 22
// syscall.c
extern uint64 sys_symlink(void);
static uint64 (*syscalls[])(void) = {
...
[SYS_symlink] sys_symlink
};
(2). 添加提示中的相关定义,T_SYMLINK以及O_NOFOLLOW
// fcntl.h
#define O_NOFOLLOW 0x004
// stat.h
#define T_SYMLINK 4
(3). 在kernel/sysfile.c中实现sys_symlink,这里需要注意的是create返回已加锁的inode,此外iunlockput既对inode解锁,还将其引用计数减1,计数为0时回收此inode
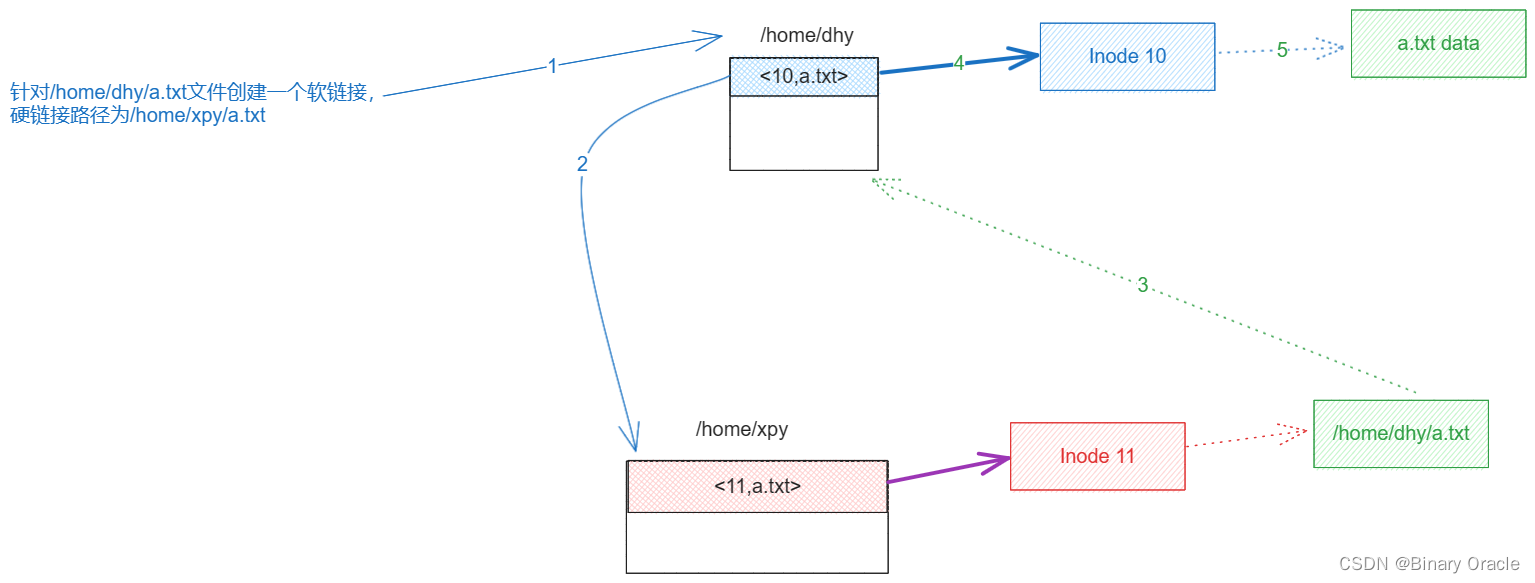
软链接(Symbolic Link)是一种特殊类型的文件,它包含指向另一个文件或目录的路径。与硬链接不同,软链接是一个独立的文件,它的数据块中存储的是目标文件的路径名,而不是指向目标文件的 inode。当用户访问软链接时,实际上是通过软链接文件中存储的路径名找到目标文件。
uint64 sys_symlink(void) {
char target[MAXPATH], path[MAXPATH];
struct inode* ip_path;
// 从用户态获取参数 target 和 path,分别表示软链接的目标路径和软链接的路径
if(argstr(0, target, MAXPATH) < 0 || argstr(1, path, MAXPATH) < 0) {
return -1;
}
// 开始文件系统操作事务
begin_op();
// 创建一个新的 inode,类型为 T_SYMLINK,即软链接类型
// create 函数返回锁定的 inode
ip_path = create(path, T_SYMLINK, 0, 0);
if(ip_path == 0) {
end_op();
return -1;
}
// 向 inode 数据块中写入目标路径(target),即将软链接指向的文件或目录的路径
if(writei(ip_path, 0, (uint64)target, 0, MAXPATH) < MAXPATH) {
iunlockput(ip_path); // 解锁 inode 并释放引用
end_op(); // 结束文件系统操作事务
return -1;
}
iunlockput(ip_path); // 解锁 inode 并释放引用
end_op(); // 结束文件系统操作事务
return 0;
}
(4). 修改sys_open支持打开符号链接
uint64 sys_open(void) {
char path[MAXPATH];
int fd, omode;
struct file *f;
struct inode *ip;
int n;
// 从用户态获取参数 path 和 omode,分别表示文件路径和打开模式
if((n = argstr(0, path, MAXPATH)) < 0 || argint(1, &omode) < 0)
return -1;
// 开始文件系统操作事务
begin_op();
if(omode & O_CREATE) {
// 如果打开模式包含 O_CREATE,则创建一个新文件,并返回一个对应的 inode
ip = create(path, T_FILE, 0, 0);
if(ip == 0){
end_op();
return -1;
}
} else {
// 否则,根据路径找到文件对应的 inode
if((ip = namei(path)) == 0){
end_op();
return -1;
}
ilock(ip);
if(ip->type == T_DIR && omode != O_RDONLY){
// 如果是目录,并且打开模式不是 O_RDONLY(只读),则不能打开
iunlockput(ip);
end_op();
return -1;
}
}
if(ip->type == T_DEVICE && (ip->major < 0 || ip->major >= NDEV)){
// 如果是设备文件,但是设备号超出范围,则不能打开
iunlockput(ip);
end_op();
return -1;
}
// 处理符号链接
if(ip->type == T_SYMLINK && !(omode & O_NOFOLLOW)) {
// 若符号链接指向的仍然是符号链接,则递归地跟随它,直到找到真正指向的文件
// 但深度不能超过 MAX_SYMLINK_DEPTH
for(int i = 0; i < MAX_SYMLINK_DEPTH; ++i) {
// 读出符号链接指向的路径
if(readi(ip, 0, (uint64)path, 0, MAXPATH) != MAXPATH) {
iunlockput(ip);
end_op();
return -1;
}
iunlockput(ip);
ip = namei(path);
if(ip == 0) {
end_op();
return -1;
}
ilock(ip);
if(ip->type != T_SYMLINK)
break;
}
// 超过最大允许深度后仍然为符号链接,则返回错误
if(ip->type == T_SYMLINK) {
iunlockput(ip);
end_op();
return -1;
}
}
// 分配一个新的文件表项(file),并分配一个文件描述符(fd)
if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){
if(f)
fileclose(f);
iunlockput(ip);
end_op();
return -1;
}
// 设置文件表项的属性
if(ip->type == T_DEVICE){
f->type = FD_DEVICE;
f->major = ip->major;
} else {
f->type = FD_INODE;
f->off = 0;
}
f->ip = ip;
f->readable = !(omode & O_WRONLY);
f->writable = (omode & O_WRONLY) || (omode & O_RDWR);
// 如果打开模式包含 O_TRUNC,并且是一个普通文件,则截断文件
if((omode & O_TRUNC) && ip->type == T_FILE){
itrunc(ip);
}
// 解锁 inode,并结束文件系统操作事务
iunlock(ip);
end_op();
// 返回文件描述符
return fd;
}

可选的挑战练习
实现三级间接块