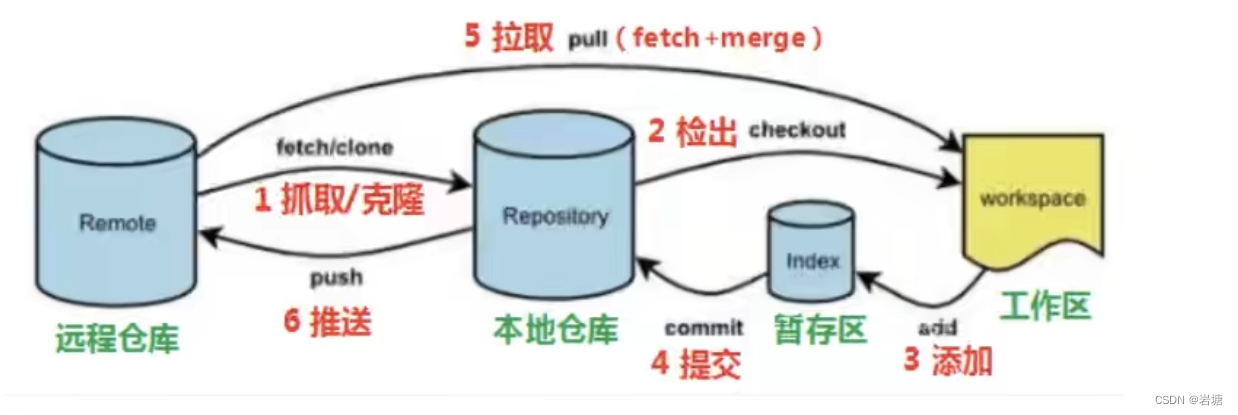
PyTorch深度学习实战(8)——批归一化
- 0. 前言
- 1. 批归一化原理
- 2. 批归一化优势
- 3. 批归一化对模型训练的影响
- 3.1 未使用批归一化,且输入值较小
- 3.2 使用批归一化,且输入值较小
- 3.3 使用批归一化,且输入值较大
- 小结
- 系列链接
0. 前言
批归一化( Batch Normalization )是一种常用的神经网络优化技术,用于在神经网络的训练过程中对每批输入进行归一化操作。它的主要目的是缓解梯度消失或梯度爆炸的问题,并且加速模型的收敛。在本节中,首先介绍批归一化的基本原理,然后通过实验观察其在网络训练过程中的重要作用。
1. 批归一化原理
我们已经了解到,如果不缩放输入数据,则权重优化的速度很慢。这是由于当面临以下情况时,隐藏层的值可能会很高:
- 输入数据值高
- 权重值高
- 权重和输入的乘积很高
任何一种情况都可能导致隐藏层具有较大输出值。隐藏层可以视为输出层的输入层。因此,当隐藏层值也很大时,同样会导致网络优化缓慢。接下来,我们考虑当输入值非常小,Sigmoid 输出随权重的变化情况:
| 输入 | 权重 | Sigmoid 输出 |
|---|---|---|
| 0.01 | 0.00001 | 0.500 |
| 0.01 | 0.0001 | 0.500 |
| 0.01 | 0.001 | 0.500 |
| 0.01 | 0.01 | 0.500 |
| 0.01 | 0.1 | 0.500 |
| 0.01 | 0.2 | 0.500 |
| 0.01 | 0.3 | 0.501 |
| 0.01 | 0.4 | 0.501 |
| 0.01 | 0.5 | 0.501 |
| 0.01 | 0.6 | 0.501 |
| 0.01 | 0.7 | 0.502 |
| 0.01 | 0.8 | 0.502 |
| 0.01 | 0.9 | 0.502 |
| 0.01 | 1 | 0.502 |
当输入值非常小时,Sigmoid 输出的变化幅度较小,从而会对权重值产生较大变化。此外,我们已经看到较大的输入值会对训练准确率有负面影响,这表明输入值既不能过小,也不能过大值。
除了输入值外,当前网络层可以视为下一网络层的输入层,因此同样可能会出现过大或过小的情况,从而导致网络优化缓慢。我们已经了解到,当输入值很高时,我们将执行缩放以减小输入值。批归一化是用于在神经网络中对每个批次的输入数据进行归一化处理,它可以加速模型的训练,提高模型的稳定性和泛化能力。批归一化的算法流程如下:
- 对于每个批次的输入数据,计算其均值和方差。可以通过求取批次内样本的均值和方差的无偏估计来计算
- 对于每个特征,将其均值归一化为
0,方差归一化为1。这可以通过减去均值并除以标准差来完成 - 引入可学习的参数 γ \gamma γ 和 β \beta β,用于缩放和平移归一化后的数据。这两个参数允许模型自动学习适当的尺度和偏移,以便更好地拟合数据
批归一化使用以下公式缩放每个批次的输入数据值:
B
a
t
c
h
m
e
a
n
μ
B
=
1
m
∑
i
=
1
m
x
i
B
a
t
c
h
V
a
r
i
a
n
c
e
σ
2
B
=
1
m
∑
i
=
1
m
(
x
i
−
μ
B
)
2
N
o
r
m
a
l
i
z
e
d
i
n
p
u
t
x
‾
i
=
(
x
i
−
μ
B
)
σ
B
2
+
ϵ
B
a
t
c
h
n
o
r
m
a
l
i
z
e
d
i
n
p
u
t
=
γ
x
‾
i
+
β
Batch\ mean\ \mu_B=\frac 1 m\sum_{i=1}^mx_i \\ Batch\ Variance\ \sigma_2^B=\frac 1m\sum_{i=1}^m(x_i-\mu_B)^2 \\ Normalized\ input\ \overline x_i=\frac {(x_i-\mu_B)}{\sqrt {\sigma_B^2+\epsilon}}\\ Batch\ normalized\ input=\gamma \overline x_i+\beta
Batch mean μB=m1i=1∑mxiBatch Variance σ2B=m1i=1∑m(xi−μB)2Normalized input xi=σB2+ϵ(xi−μB)Batch normalized input=γxi+β
通过每个输入数据减去批数据输入的平均值,然后将其除以批数据方差,可以将一个节点处所有批数据点归一化到一个固定范围,通过引入
γ
γ
γ 和
β
β
β 参数,可以让网络识别最佳归一化参数。
批归一化在训练和预测阶段的计算方式是不同的,在训练阶段,批归一化使用当前批次的均值和方差进行归一化;而在预测阶段,使用训练过程中计算得到的整体均值和方差来归一化输入数据。
2. 批归一化优势
批归一化的具有以下优势:
- 加速模型收敛:通过减少内部协变量偏移(
Internal Covariate Shift),即每层输入分布的变化,批归一化有助于加快模型的收敛速度。这意味着我们可以使用更大的学习率,并在更短的时间内达到更好的性能。 - 提高模型稳定性:批归一化可以减少网络对输入数据中小的批量统计变化的敏感性,从而使得模型更加稳定。这有助于减轻梯度消失或梯度爆炸等训练过程中的问题。
- 增强模型泛化能力:批归一化具有正则化的效果,类似于
Dropout等常用的正则化技术。它可以稍微减少对其他正则化方法的依赖,并提高模型的泛化能力。
3. 批归一化对模型训练的影响
为了了解批归一化对模型训练的影响,观察使用以下设定时,训练和验证数据集的损失和准确率值,以及隐藏层值的分布:
- 未使用批归一化,且输入值较小
- 使用批归一化,且输入值较小
3.1 未使用批归一化,且输入值较小
我们通常将输入数据缩放到 0 到 1,在本节中,我们将更进一步将其缩放到 0 到 0.0001 之间,以便了解缩放数据的影响。我们已经知道,即使权重值变化很大,小的输入值也无法改变 Sigmoid 值。
为了缩放输入数据集,我们通常在 FMNISTDataset 类中执行缩放操作,通过将输入像素值除以 (255*10000) 来缩小输入像素值的范围,将输入值的范围缩放至 0 到 0.0001:
class FMNISTDataset(Dataset):
def __init__(self, x, y):
x = x.float()/(255.*10000)
x = x.view(-1,28*28)
self.x, self.y = x, y
def __getitem__(self, ix):
x, y = self.x[ix], self.y[ix]
return x.to(device), y.to(device)
def __len__(self):
return len(self.x)
重新定义 get_model() 函数,以便获取模型的预测及隐藏层的值:
def get_model():
class neuralnet(nn.Module):
def __init__(self):
super().__init__()
self.input_to_hidden_layer = nn.Linear(28*28,1000)
self.hidden_layer_activation = nn.ReLU()
self.hidden_to_output_layer = nn.Linear(1000,10)
def forward(self, x):
x = self.input_to_hidden_layer(x)
x1 = self.hidden_layer_activation(x)
x2= self.hidden_to_output_layer(x1)
return x2, x1
model = neuralnet().to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-3)
return model, loss_fn, optimizer
在以上代码中,定义了神经网络类,它返回输出层值 (x2) 和隐藏层的激活值 (x1)。
由于修改后的 get_model() 会返回两个输出,我们同样需要修改 train_batch() 和 val_loss() 函数,在这两个函数中我们只需要获取输出层的值,而无需隐藏层值。由于输出层值位于模型返回的第 0 个索引中,我们需要修改函数使其仅获取第 0 个预测索引:
def train_batch(x, y, model, optimizer, loss_fn):
prediction = model(x)[0]
batch_loss = loss_fn(prediction, y)
batch_loss.backward()
optimizer.step()
optimizer.zero_grad()
return batch_loss.item()
def accuracy(x, y, model):
with torch.no_grad():
prediction = model(x)[0]
max_values, argmaxes = prediction.max(-1)
is_correct = argmaxes == y
return is_correct.cpu().numpy().tolist()
训练模型后,得到训练和验证数据集中的准确率和损失值在训练过程中的变化:

可以看到,即使在 100 个 epoch 之后,模型也没有获得优异性能(只有大约 85% 的验证准确率),而在以上部分中,模型在 10 个 epoch 内的验证数据集上可以获得大约 90% 的准确率。
通过探索隐藏值的分布以及参数分布来了解当输入值范围较小时,模型性能不佳的原因:

第一个分布表示隐藏层中值的分布(可以看到这些值的范围非常小),此外,由于输入和隐藏层值的范围都非常小,权重(包括将输入连接到隐藏层的权重和将隐藏层连接到输出层的权重)必须有大幅度的变化。
我们已经了解了当输入值的范围非常小时,网络就不能很好地训练,接下来我们将学习批归一化如何帮助增大隐藏层内的值范围。
3.2 使用批归一化,且输入值较小
在本节中,我们在上一小节的代码基础上增加批归一化,修改后的 get_model() 函数如下:
from torch.optim import SGD, Adam
def get_model():
class neuralnet(nn.Module):
def __init__(self):
super().__init__()
self.input_to_hidden_layer = nn.Linear(784,1000)
self.batch_norm = nn.BatchNorm1d(1000)
self.hidden_layer_activation = nn.ReLU()
self.hidden_to_output_layer = nn.Linear(1000,10)
def forward(self, x):
x = self.input_to_hidden_layer(x)
x0 = self.batch_norm(x)
x1 = self.hidden_layer_activation(x0)
x2= self.hidden_to_output_layer(x1)
return x2, x1
model = neuralnet().to(device)
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=1e-3)
return model, loss_fn, optimizer
在以上代码中,我们声明了一个执行批归一化 (nn.BatchNorm1d) 的变量 (batch_norm),由于隐藏层中每个图像的输出维度为 1,000,因此执行 nn.BatchNorm1d(1000)。此外,在前向传播方法 forward() 中,在 ReLU 激活之前通过批归一化传递隐藏层值的输出。
训练和验证数据集的准确率和损失随时间的变化如下:

可以看到模型训练过程与输入值范围不是很小时的训练过程非常相似。观察隐藏层值的分布和权重分布:
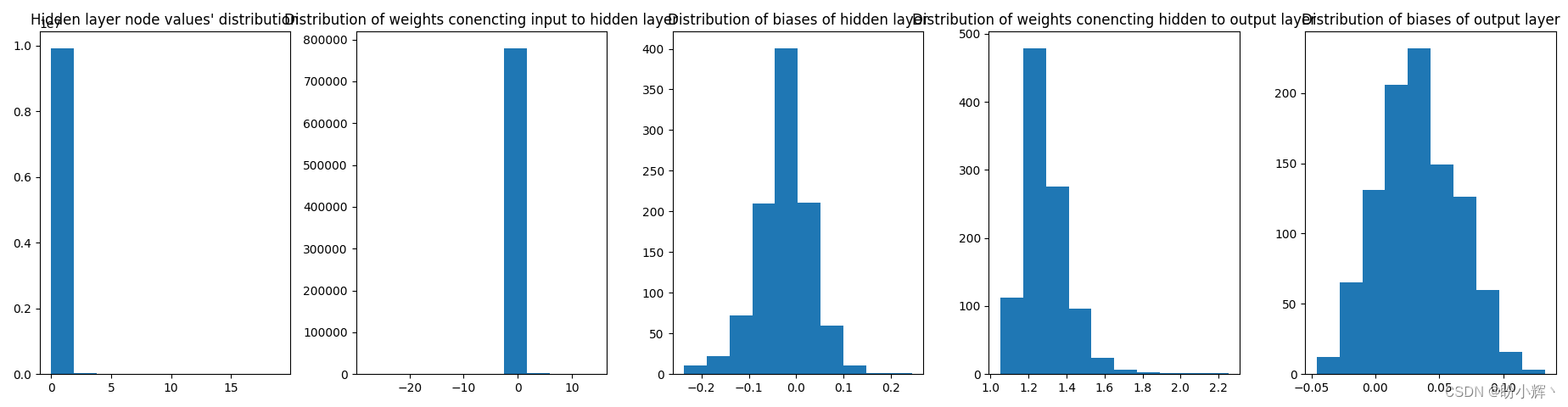
可以看到,进行批归一化时,隐藏层值的分布更大,而连接隐藏层和输出层的权重分布更小,模型的训练结果与较优。批归一化在训练深度神经网络时极为有效,它可以帮助模型避免因梯度变得太小而无法更新权重的问题。
3.3 使用批归一化,且输入值较大
为了进一步了解批归一化,在上一小节的代码基础上修改输入数据范围,修改后如下:
class FMNISTDataset(Dataset):
def __init__(self, x, y):
x = x.float()/(255.)
x = x.view(-1,28*28)
self.x, self.y = x, y
def __getitem__(self, ix):
x, y = self.x[ix], self.y[ix]
return x.to(device), y.to(device)
def __len__(self):
return len(self.x)
训练模型后,得到训练和验证数据集中的准确率和损失值在训练过程中的变化:

观察隐藏层值的分布和权重分布:

小结
批归一化是一种通过标准化神经网络层的输入数据,加速模型训练并提高泛化能力的技术。它在深度学习中广泛应用,是构建高效、稳定的神经网络模型的重要方法。本节介绍了批归一化的基本概念及其优点,并通过实战了解了批归一化对模型训练的影响。
系列链接
PyTorch深度学习实战(1)——神经网络与模型训练过程详解
PyTorch深度学习实战(2)——PyTorch基础
PyTorch深度学习实战(3)——使用PyTorch构建神经网络
PyTorch深度学习实战(4)——常用激活函数和损失函数详解
PyTorch深度学习实战(5)——计算机视觉基础
PyTorch深度学习实战(6)——神经网络性能优化技术
PyTorch深度学习实战(7)——批大小对神经网络训练的影响