【BASH】回顾与知识点梳理 二
- 二. Shell 的变量功能
- 2.1 什么是变量?
- 2.2 变量的取用与设定: echo, 变量设定规则: set/unset
- 2.3 环境变量的功能
- 用 set 观察所有变量 (含环境变量与自定义变量)
- export: 自定义变量转成环境变量
- 那如何将环境变量转成自定义变量呢?declare / typeset
- 2.4 影响显示结果的语系变量 :locale
- 2.5 变量的有效范围
- 2.6 变量键盘读取、数组: read、 array
- 2.7 与文件系统及程序的限制关系: ulimit
- 2.8 变量内容的删除、取代与替换 (Optional)
- 变量内容删除(从前向后开始删除变量内容)
- 变量内容删除(从后向前开始删除变量内容)
- 变量的测试与内容替换
二. Shell 的变量功能
变量是 bash 环境中非常重要的一个玩意儿,我们知道 Linux 是多人多任务的环境,每个人登入系统都能取得一个 bash shell, 每个人都能够使用 bash 下达 mail 这个指令来收受『自己』的邮件等等。问题是, bash 是如何得知你的邮件信箱是哪个文件? 这就需要『变量』的帮助啦!所以,你说变量重不重要呢?底下我们将介绍重要的环境变量、变量的取用与设定等数据, 呼呼!动动脑时间又来到啰!
2.1 什么是变量?
那么,什么是『变量』呢?简单的说,就是让某一个特定字符串代表不固定的内容就是了。举个大家在国中都会学到的数学例子, 那就是:『 y = ax + b 』这东西,在等号左边的(y)就是变量,在等号右边的(ax+b)就是变量内容。 要注意的是,左边是未知数,右边是已知数喔! 讲的更简单一点,我们可以『用一个简单的 “字眼” 来取代另一个比较复杂或者是容易变动的数据』。这有什么好处啊?最大的好处就是『方便!』。
- 影响 bash 环境操作的变量
某些特定变量会影响到 bash 的环境喔!举例来说,我们前面已经提到过很多次的那个 PATH 变数!你能不能在任何目录下执行某个指令,与 PATH 这个变量有很大的关系。例如你下达 ls 这个指令时,系统就是透过 PATH 这个变量里面的内容所记录的路径顺序来搜寻指令的呢!如果在搜寻完PATH 变量内的路径还找不到 ls 这个指令时, 就会在屏幕上显示『 command not found 』的错误讯息了。
由于在 Linux System 下面,所有的线程都是需要一个执行码, 而就如同上面提到的,你『真正以 shell 来跟 Linux 沟通,是在正确的登入 Linux 之后!』这个时候你就有一个 bash 的执行程序,也才可以真正的经由 bash 来跟系统沟通啰!而在进入 shell 之前,也正如同上面提到的,由于系统需要一些变量来提供他数据的存取 (或者是一些环境的设定参数值, 例如是否要显示彩色等等的) ,所以就有一些所谓的『环境变量』 需要来读入系统中了!这些环境变量例如 PATH、HOME、MAIL、SHELL 等等,都是很重要的, 为了区别与自定义变量的不同,环境变量通常以大写字符来表示呢!
- 脚本程序设计 (shell script) 的好帮手
这些还都只是系统默认的变量的目的,如果是个人的设定方面的应用呢:例如你要写一个大型的script 时,有些数据因为可能由于用户习惯的不同而有差异,比如说路径好了,由于该路径在 script 被使用在相当多的地方,如果下次换了一部主机,都要修改 script 里面的所有路径,那么我一定会疯掉! 这个时候如果使用变量,而将该变量的定义写在最前面,后面相关的路径名称都以变量来取代,嘿嘿!那么你只要修改一行就等于修改整篇 script 了!方便的很!所以,良好的程序设计师都会善用变量的定义!
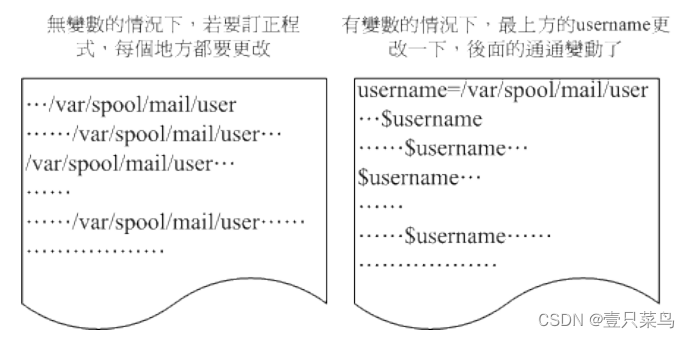
最后我们就简单的对『什么是变量』作个简单定义好了: 『变量就是以一组文字或符号等,来取代一些设定或者是一串保留的数据!』
2.2 变量的取用与设定: echo, 变量设定规则: set/unset
可以利用 echo 这个指令来取用变量, 但是,变量在被取用时,前面必须要加上钱字号『 $ 』才行,或者是以 ${变量} 的方式来取用都可以,举例来说,要知道 PATH 的内容,该如何是好?
- 变量的取用:echo
[root@node-135 /]# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/jdk-11.0.19/bin:/root/bin
- 变量的设定:
=
如何『设定』或者是『修改』 某个变量的内容啊?很简单啦!用『等号(=)』连接变量与他的内容就好啦
[root@node-135 /]# a=123
[root@node-135 /]# echo $a
123
[root@node-135 /]# a=321
[root@node-135 /]# echo $a
321
在 bash 当中,当一个变量名称尚未被设定时,预设的内容是『空』的。
[root@node-135 /]# echo $b
[root@node-135 /]#
各位读者注意喔,每一种 shell 的语法都不相同~在变量的使用上,bash 在你没有设定的变量中强迫去 echo 时,它会显示出空的值。 在其他某些 shell 中,随便去 echo 一个不存在的变量,它是会出现错误讯息的喔!要注意!要注意!
变量在设定时,还是需要符合某些规定的,否则会设定失败喔!这些规则如下所示
- 等号两边不能直接接空格符,如下所示为错误:
[root@node-135 /]# a = 456 -bash: a: command not found [root@node-135 /]# a=345 456 -bash: 456: command not found - 变量名称只能是英文字母与数字,但是开头字符不能是数字,如下为错误:
[root@node-135 /]# 1a=456 -bash: 1a=456: command not found - 变量内容若有空格符可使用双引号『
"』或单引号『'』将变量内容结合起来,但- 双引号内的特殊字符如
$等,可以保有原本的特性,如下所示:[root@node-135 /]# var="lang is $LANG" [root@node-135 /]# echo $var lang is en_US.UTF-8 - 单引号内的特殊字符则仅为一般字符 (纯文本),如下所示:
[root@node-135 /]# var='lang is $LANG' [root@node-135 /]# echo $var lang is $LANG
- 双引号内的特殊字符如
- 可用跳脱字符『 \ 』将特殊符号(如
[Enter], $, \, 空格符, '等)变成一般字符,如:myname=VBird\ Tsai - 在一串指令的执行中,还需要藉由其他额外的指令所提供的信息时,可以使用反单引号『`指令`』或 『$(指令)』。特别注意,那个 ` 是键盘上方的数字键 1 左边那个按键,而不是单引号! 例如想要取得核心版本的设定:
version=$(uname -r) #或 version=`uname -r` echo $version 3.10.0-229.el7.x86_64 - 若该变量为扩增变量内容时,则可用
"$变量名称"或${变量}累加内容,如下所示:PATH="$PATH":/home/bin #或 PATH=${PATH}:/home/bin - 若该变量需要在其他子程序执行,则需要以 export 来使变量变成环境变量:
export PATH - 通常大写字符为系统默认变量,自行设定变量可以使用小写字符,方便判断 (纯粹依照使用者兴趣与嗜好)
- 取消变量的方法为使用 unset :『unset 变量名称』例如取消 myname 的设定:
unset myname
2.3 环境变量的功能
环境变量可以帮我们达到很多功能~包括家目录的变换啊、提示字符的显示啊、执行文件搜寻的路径啊等等的, 还有很多很多啦!那么,既然环境变量有那么多的功能,问一下,目前我的 shell 环境中, 有多少默认的环境变量啊?我们可以利用两个指令来查阅,分别是 env 与 export 呢!
#列出目前的 shell 环境下的所有环境变量与其内容。
[dmtsai@study ~]$ env
HOSTNAME=study.centos.vbird <== 这部主机的主机名
TERM=xterm <== 这个终端机使用的环境是什么类型
SHELL=/bin/bash <== 目前这个环境下,使用的 Shell 是哪一个程序?
HISTSIZE=1000 <== 『记录指令的笔数』在 CentOS 默认可记录 1000 笔
OLDPWD=/home/dmtsai <== 上一个工作目录的所在
LC_ALL=en_US.utf8 <== 由于语系的关系,鸟哥偷偷丢上来的一个设定
USER=dmtsai <== 使用者的名称啊!
LS_COLORS=rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:
or=40;31;01:mi=01;05;37;41:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:
*.tar=01... <== 一些颜色显示
MAIL=/var/spool/mail/dmtsai <== 这个用户所取用的 mailbox 位置
PATH=/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin:/home/dmtsai/bin
PWD=/home/dmtsai <== 目前用户所在的工作目录 (利用 pwd 取出!)
LANG=zh_TW.UTF-8 <== 这个与语系有关,底下会再介绍!
HOME=/home/dmtsai <== 这个用户的家目录啊!
LOGNAME=dmtsai <== 登入者用来登入的账号名称
_=/usr/bin/env <== 上一次使用的指令的最后一个参数(或指令本身
[root@node-135 /]# export
declare -x CLASSPATH=".:/jre/lib/rt.jar:/opt/jdk-11.0.19/lib/dt.jar:/opt/jdk-11.0.19/lib/tools.jar"
declare -x HISTCONTROL="ignoredups"
declare -x HISTSIZE="1000"
declare -x HOME="/root"
declare -x HOSTNAME="node-135"
declare -x JAVA_HOME="/opt/jdk-11.0.19"
declare -x LANG="en_US.UTF-8"
declare -x LESSOPEN="||/usr/bin/lesspipe.sh %s"
declare -x LOGNAME="root"
declare -x LS_COLORS="rs=0:di=01;34:ln=01;36:mh=00:pi=40;33:so=01;35:do=01;35:bd=40;33;01:cd=40;33;01:or=40;31;01:mi=01;05;37;41:su=37;41:sg=30;43:ca=30;41:tw=30;42:ow=34;42:st=37;44:ex=01;32:*.tar=01;31:*.tgz=01;31:*.arc=01;31:*.arj=01;31:*.taz=01;31:*.lha=01;31:*.lz4=01;31:*.lzh=01;31:*.lzma=01;31:*.tlz=01;31:*.txz=01;31:*.tzo=01;31:*.t7z=01;31:*.zip=01;31:*.z=01;31:*.Z=01;31:*.dz=01;31:*.gz=01;31:*.lrz=01;31:*.lz=01;31:*.lzo=01;31:*.xz=01;31:*.bz2=01;31:*.bz=01;31:*.tbz=01;31:*.tbz2=01;31:*.tz=01;31:*.deb=01;31:*.rpm=01;31:*.jar=01;31:*.war=01;31:*.ear=01;31:*.sar=01;31:*.rar=01;31:*.alz=01;31:*.ace=01;31:*.zoo=01;31:*.cpio=01;31:*.7z=01;31:*.rz=01;31:*.cab=01;31:*.jpg=01;35:*.jpeg=01;35:*.gif=01;35:*.bmp=01;35:*.pbm=01;35:*.pgm=01;35:*.ppm=01;35:*.tga=01;35:*.xbm=01;35:*.xpm=01;35:*.tif=01;35:*.tiff=01;35:*.png=01;35:*.svg=01;35:*.svgz=01;35:*.mng=01;35:*.pcx=01;35:*.mov=01;35:*.mpg=01;35:*.mpeg=01;35:*.m2v=01;35:*.mkv=01;35:*.webm=01;35:*.ogm=01;35:*.mp4=01;35:*.m4v=01;35:*.mp4v=01;35:*.vob=01;35:*.qt=01;35:*.nuv=01;35:*.wmv=01;35:*.asf=01;35:*.rm=01;35:*.rmvb=01;35:*.flc=01;35:*.avi=01;35:*.fli=01;35:*.flv=01;35:*.gl=01;35:*.dl=01;35:*.xcf=01;35:*.xwd=01;35:*.yuv=01;35:*.cgm=01;35:*.emf=01;35:*.axv=01;35:*.anx=01;35:*.ogv=01;35:*.ogx=01;35:*.aac=01;36:*.au=01;36:*.flac=01;36:*.mid=01;36:*.midi=01;36:*.mka=01;36:*.mp3=01;36:*.mpc=01;36:*.ogg=01;36:*.ra=01;36:*.wav=01;36:*.axa=01;36:*.oga=01;36:*.spx=01;36:*.xspf=01;36:"
declare -x MAIL="/var/spool/mail/root"
declare -x MAVEN_HOME="/usr/local/maven/apache-maven-3.9.3"
declare -x OLDPWD="/home/quick_location-master/ngx_on_cpu"
declare -x PATH="/usr/local/sonar-scanner/bin:/usr/local/maven/apache-maven-3.9.3/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/jdk-11.0.19/bin:/root/bin"
declare -x PWD="/"
declare -x SHELL="/bin/bash"
declare -x SHLVL="1"
declare -x SSH_CLIENT="192.168.17.1 51805 22"
declare -x SSH_CONNECTION="192.168.17.1 51805 192.168.17.135 22"
declare -x SSH_TTY="/dev/pts/0"
declare -x TERM="xterm"
declare -x USER="root"
declare -x XDG_RUNTIME_DIR="/run/user/0"
declare -x XDG_SESSION_ID="2"
上面这些变量有些什么功用呢?底下我们就一个一个来分析分析!
-
HOME
代表用户的家目录。还记得我们可以使用 cd ~ 去到自己的家目录吗?或者利用 cd 就可以直接回到用户家目录了。那就是取用这个变量啦~ 有很多程序都可能会取用到这个变量的值! -
SHELL
告知我们,目前这个环境使用的 SHELL 是哪支程序? Linux 预设使用 /bin/bash 的啦! -
HISTSIZE
这个与『历史命令』有关,亦即是, 我们曾经下达过的指令可以被系统记录下来,而记录的『笔数』则是由这个值来设定的。 -
MAIL
当我们使用 mail 这个指令在收信时,系统会去读取的邮件信箱文件 (mailbox)。 -
PATH
就是执行文件搜寻的路径啦~目录与目录中间以冒号(:)分隔,由于文件的搜寻是依序由 PATH 的变量内的目录来查询,所以,目录的顺序也是重要的喔。 -
LANG
这个重要!就是语系数据啰~很多讯息都会用到他, 举例来说,当我们在启动某些 perl 的程序语言文件时,他会主动的去分析语系数据文件, 如果发现有他无法解析的编码语系,可能会产生错误喔!一般来说,我们中文编码通常是 zh_TW.Big5 或者是 zh_TW.UTF-8,这两个编码偏偏不容易被解译出来,所以,有的时候,可能需要修订一下语系数据。 -
RANDOM
这个玩意儿就是『随机随机数』的变量啦!目前大多数的 distributions 都会有随机数生成器,那就是/dev/random 这个文件。 我们可以透过这个随机数文件相关的变量 ($RANDOM) 来随机取得随机数值喔。在 BASH 的环境下,这个 RANDOM 变量的内容,介于 0~32767 之间,所以,你只要echo $RANDOM时,系统就会主动的随机取出一个介于0~32767的数值。万一我想要使用0~9之间的数值呢?呵呵~利用declare 宣告数值类型, 然后这样做就可以了:declare -i number=$RANDOM*10/32768 ; echo $number 7linux系统上的随机数生成器: /dev/random:仅从熵池中返回随机数,随机数用尽,阻塞 /dev/urandom:从熵池中返回随机数,随机数用尽,会利用软件生成伪随即数,非阻塞 伪随即数并不安全 熵池:内核在内存中维护的一个空间,空间内存储大量随机数,熵池中的随机数来源: 硬盘IO中断时间间隔 键盘IO中断时间间隔 如果随机数用尽,可以拷贝大数据到硬盘,产生大量IO --> 马哥
用 set 观察所有变量 (含环境变量与自定义变量)
bash 可不只有环境变量喔,还有一些与 bash 操作接口有关的变量,以及用户自己定义的变量存在的。 那么这些变量如何观察呢?这个时候就得要使用 set 这个指令了。 set 除了环境变量之外, 还会将其他在 bash 内的变量通通显示出来哩!信息很多,底下鸟哥仅列出几个重要的内容:
[dmtsai@study ~]$ set
BASH=/bin/bash <== bash 的主程序放置路径
BASH_VERSINFO=([0]="4" [1]="2" [2]="46" [3]="1" [4]="release" [5]="x86_64-redhat-linux-gnu")
BASH_VERSION='4.2.46(1)-release' <== 这两行是 bash 的版本啊!
COLUMNS=90 <== 在目前的终端机环境下,使用的字段有几个字符长度
HISTFILE=/home/dmtsai/.bash_history <== 历史命令记录的放置文件,隐藏档
HISTFILESIZE=1000 <== 存起来(与上个变量有关)的文件之指令的最大纪录笔数。
HISTSIZE=1000 <== 目前环境下,内存中记录的历史命令最大笔数。
IFS=$' \t\n' <== 预设的分隔符
LINES=20 <== 目前的终端机下的最大行数
MACHTYPE=x86_64-redhat-linux-gnu <== 安装的机器类型
OSTYPE=linux-gnu <== 操作系统的类型!
PS1='[\u@\h \W]\$ ' <== PS1 就厉害了。这个是命令提示字符,也就是我们常见的
[root@www ~]# 或 [dmtsai ~]$ 的设定值啦!可以更动的!
PS2='> ' <== 如果你使用跳脱符号 (\) 第二行以后的提示字符也
$ <== 目前这个 shell 所使用的 PID
? <== 刚刚执行完指令的回传值。
一般来说,不论是否为环境变量,只要跟我们目前这个
shell 的操作接口有关的变量, 通常都会被设定为大写字符,也就是说,『基本上,在 Linux 预设的情况中,使用{大写的字母}来设定的变量一般为系统内定需要的变量』
那么上头那些变量当中,有哪些是比较重要的?大概有这几个吧!
-
PS1:(提示字符的设定)
这是 PS1 (数字的 1 不是英文字母),这个东西就是我们的『命令提示字符』喔! 当我们每次按下 [Enter] 按键去执行某个指令后,最后要再次出现提示字符时,就会主动去读取这个变数值了。上头 PS1 内显示的是一些特殊符号,这些特殊符号可以显示不同的信息, 每个 distributions 的bash 默认的 PS1 变量内容可能有些许的差异,不要紧,『习惯你自己的习惯』就好了。你可以用 man bash (注 3)去查询一下 PS1 的相关说明,以理解底下的一些符号意义。- \d :可显示出『星期 月 日』的日期格式,如:“Mon Feb 2”
- \H :完整的主机名。举例来说,鸟哥的练习机为『study.centos.vbird』
- \h :仅取主机名在第一个小数点之前的名字,如鸟哥主机则为『study』后面省略
- \t :显示时间,为 24 小时格式的『HH:MM:SS』
- \T :显示时间,为 12 小时格式的『HH:MM:SS』
- \A :显示时间,为 24 小时格式的『HH:MM』
- @ :显示时间,为 12 小时格式的『am/pm』样式
- \u :目前使用者的账号名称,如『dmtsai』;
- \v :BASH 的版本信息,如鸟哥的测试主机版本为 4.2.46(1)-release,仅取『4.2』显示
- \w :完整的工作目录名称,由根目录写起的目录名称。但家目录会以 ~ 取代;
- \W :利用 basename 函数取得工作目录名称,所以仅会列出最后一个目录名。
- # :下达的第几个指令。
- $ :提示字符,如果是 root 时,提示字符为 # ,否则就是 $ 啰~
怎么用呢?
临时修改:[root@node-135 ~]# echo $PS1 [\u@\h \W]\$ [root@node-135 14:32:49 ~] #PS1="[\u@\h \t \W]# " [root@node-135 14:32:57 ~]# ls anaconda-ks.cfg加了时间变量
永久修改:
修改/etc/profile,在文件的最后一行加上:PS1="\[\e[36;1m\][\u@\h \w]# \[\e[0m\]"重启后就修改成功了
-
$:(关于本 shell 的 PID)
钱字号本身也是个变量喔!这个咚咚代表的是『目前这个 Shell 的线程代号』,亦即是所谓的 PID (Process ID)。想要知道我们的 shell 的 PID ,就可以用:『 echo $$ 』即可!出现的数字就是你的 PID 号码。[root@node-135 14:33:04 ~]# echo $$ 79534 -
?:(关于上个执行指令的回传值)
这个变数是:『上一个执行的指令所回传的值』, 上面这句话的重点是『上一个指令』与『回传值』两个地方。当我们执行某些指令时,这些指令都会回传一个执行后的代码。一般来说,如果成功的执行该指令,则会回传一个 0 值,如果执行过程发生错误,就会回传『错误代码』才对!一般就是以非为 0 的数值来取代。 -
OSTYPE, HOSTTYPE, MACHTYPE:(主机硬件与核心的等级)
目前个人计算机的 CPU 主要分为 32/64 位,其中 32 位又可分为 i386, i586, i686,而 64 位则称为 x86_64。 由于不同等级的CPU 指令集不太相同,因此你的软件可能会针对某些 CPU 进行优化,以求取较佳的软件性能。所以软件就有 i386, i686 及 x86_64 之分。以目前 的主流硬件来说,几乎都是 x86_64 的天下! 因此 CentOS 7 开始,已经不支持 i386 兼容模式的安装光盘了~哇呜!进步的太快了!较高阶的硬件通常会向下兼容旧有的软件,但较高阶的软件可能无法在旧机器上面安装! 你可以在 x86_64 的硬件上安装 i386 的Linux 操作系统,但是你无法在 i686 的硬件上安装 x86_64 的 Linux 操作系统!这点得要牢记在心!
export: 自定义变量转成环境变量
谈了 env 与 set 现在知道有所谓的环境变量与自定义变量,那么这两者之间有啥差异呢?其实这两者的差异在于『 该变量是否会被子程序所继续引用』
当你登入 Linux 并取得一个 bash 之后,你的 bash 就是一个独立的程序,这个程序的识别使用的是一个称为程序标识符,被称为 PID 的就是。 接下来你在这个 bash 底下所下达的任何指令都是由这个 bash 所衍生出来的,那些被下达的指令就被称为子程序了。
[root@node-135 /]# ps -f
UID PID PPID C STIME TTY TIME CMD
root 8258 8254 0 Jul27 pts/0 00:00:00 -bash
root 79831 8258 0 15:04 pts/0 00:00:00 ps -f
注意观察79831这个进程的父进程是8258
简易模型:
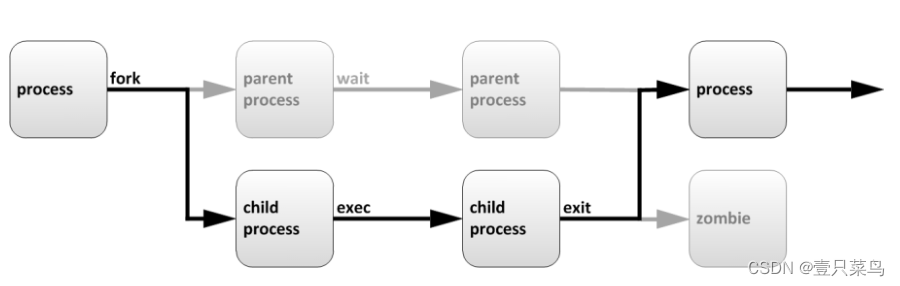
这个程序概念与变量有啥关系啊?关系可大了!因为子程序仅会继承父程序的环境变量, 子程序不会继承父程序的自定义变量啦!所以你在原本 bash 的自定义变量在进入了子程序后就会消失不见,一直到你离开子程序并回到原本的父程序后,这个变量才会又出现!
换个角度来想,也就是说,如果我能将自定义变量变成环境变量的话,那不就可以让该变量值继续存在于子程序了? 呵呵!没错!此时,那个 export 指令就很有用啦!如你想要让该变量内容继续的在子程序中使用,那么就请执行
[dmtsai@study ~]$ export 变量名称
这东西用在『分享自己的变量设定给后来呼叫的文件或其他程序』
那如何将环境变量转成自定义变量呢?declare / typeset
declare 或 typeset 是一样的功能,就是在『宣告变量的类型』。如果使用 declare 后面并没有接任何参数,那么 bash 就会主动的将所有的变量名称与内容通通叫出来,就好像使用 set 一样啦! 那么declare 还有什么语法呢?看看先:
[dmtsai@study ~]$ declare [-aixr] variable
选项与参数:
-a :将后面名为 variable 的变量定义成为数组 (array) 类型
-i :将后面名为 variable 的变量定义成为整数数字 (integer) 类型
-x :用法与 export 一样,就是将后面的 variable 变成环境变量;
-r :将变量设定成为 readonly 类型,该变量不可被更改内容,也不能 unset
-p :可以单独列出变量的类型
#范例二:让变量 sum 进行 100+300+50 的加总结果
[dmtsai@study ~]$ sum=100+300+50
[dmtsai@study ~]$ echo ${sum}
100+300+50 <==咦!怎么没有帮我计算加总?因为这是文字型态的变量属性啊!
[dmtsai@study ~]$ declare -i sum=100+300+50
[dmtsai@study ~]$ echo ${sum}
450
由于在默认的情况底下, bash 对于变量有几个基本的定义:
1. 变量类型默认为『字符串』,所以若不指定变量类型,则 1+2 为一个『字符串』而不是『计算式』。 所以上述第一个执行的结果才会出现那个情况的;
2. bash 环境中的数值运算,预设最多仅能到达整数形态,所以 1/3 结果是 0;
现在你晓得为啥你需要进行变量宣告了吧?如果需要非字符串类型的变量,那就得要进行变量的宣告才行啦! 底下继续来玩些其他的 declare 功能。
#范例二:将 sum 变成环境变量
[dmtsai@study ~]$ declare -x sum
[dmtsai@study ~]$ export | grep sum
declare -ix sum="450" <==果然出现了!包括有 i 与 x 的宣告!
#范例三:让 sum 变成只读属性,不可更动!
[dmtsai@study ~]$ declare -r sum
[dmtsai@study ~]$ sum=tesgting
-bash: sum: readonly variable <==老天爷~不能改这个变数了!
#范例四:让 sum 变成非环境变量的自定义变量吧!
[dmtsai@study ~]$ declare +x sum <== 将 - 变成 + 可以进行『取消』动作
[root@node-135 /]# export | grep sum
[root@node-135 /]#
[dmtsai@study ~]$ declare -p sum <== -p 可以单独列出变量的类型
declare -ir sum="450" <== 看吧!只剩下 i, r 的类型,不具有 x 啰!
此时再去看看export命令输出,是不是对前缀declare -x有些了然了呢
[root@node-135 /]# export
declare -x CLASSPATH=".:/jre/lib/rt.jar:/opt/jdk-11.0.19/lib/dt.jar:/opt/jdk-11.0.19/lib/tools.jar"
declare -x HISTCONTROL="ignoredups"
declare -x HISTSIZE="1000"
...
2.4 影响显示结果的语系变量 :locale
当我们使用 man command 的方式去查询某个数据的说明文件时,该说明档的内容可能会因为我们使用的语系不同而产生乱码。 另外,利用 ls 查询文件的时间时,也可能会有乱码出现在时间的部分。那个问题其实就是语系的问题啦。
目前大多数的 Linux distributions 已经都是支持日渐流行的万国码了,也都支持大部分的国家语系。那么我们的 Linux 到底支持了多少的语系呢?这可以由 locale 这个指令来查询到喔!
[root@node-135 /]# locale -a|head -5
aa_DJ
aa_DJ.iso88591
aa_DJ.utf8
aa_ER
aa_ER@saaho
我们如何修改这些编码呢
[dmtsai@study ~]$ locale <==后面不加任何选项与参数即可!
LANG=en_US <==主语言的环境
LC_CTYPE="en_US" <==字符(文字)辨识的编码
LC_NUMERIC="en_US" <==数字系统的显示讯息
LC_TIME="en_US" <==时间系统的显示数据
LC_COLLATE="en_US" <==字符串的比较与排序等
LC_MONETARY="en_US" <==币值格式的显示等
LC_MESSAGES="en_US" <==讯息显示的内容,如菜单、错误讯息等
LC_ALL= <==整体语系的环境
....(后面省略)....
基本上,你可以逐一设定每个与语系有关的变量数据,但事实上,如果其他的语系变量都未设定, 且你有设定 LANG 或者是 LC_ALL 时,则其他的语系变量就会被这两个变量所取代! 这也是为什么我们在 Linux 当中,通常说明仅设定 LANG 或 LC_ALL 这两个变量而已,因为他是最主要的设定变量! 好了,那么你应该要觉得奇怪的是,为什么在 Linux 主机的终端机接口 (tty1 ~ tty6) 的环境下,如果设定『 LANG=zh_TW.utf8 』这个设定值生效后,使用 man 或者其他讯息输出时, 都会有一堆乱码,尤其是使用ls -l这个参数时?
因为在 Linux 主机的终端机接口环境下是无法显示像中文这么复杂的编码文字, 所以就会产生乱码了。也就是如此,我们才会必须要在 tty1 ~ tty6 的环境下, 加装一些中文化接口的软件,才能够看到中文啊!不过,如果你是在 MS Windows 主机以远程联机服务器的软件联机到主机的话,那么,嘿嘿!其实文字接口确实是可以看到中文的。 此时反而你得要在 LC_ALL 设定中文编码才好呢!
无论如何,如果发生一些乱码的问题,那么设定系统里面保有的语系编码, 例如:
en_US 或 en_US.utf8 等等的设定,应该就 OK 的啦!好了,那么系统默认支持多少种语系呢? 当我们使用 locale 时,系统是列出目前 Linux 主机内保有的语系文件, 这些语系文件都放置在: /usr/lib/locale/ 这个目录中。所有的文字都记录在locale-archive,建议别打开了,太多了
[root@node-135 /]# ll /usr/lib/locale/
total 103660
-rw-r--r--. 1 root root 106176928 Jul 14 11:08 locale-archive
-rw-r--r--. 1 root root 0 Jul 14 11:08 locale-archive.tmpl
你当然可以让每个使用者自己去调整自己喜好的语系,但是整体系统默认的语系定义在哪里呢? 其实就是在 /etc/locale.conf 啰!这个文件在 CentOS 7.x 的内容有点像这样:
[root@node-135 /]# cat /etc/locale.conf
LANG="en_US.UTF-8"
临时修改
[dmtsai@study ~]$ LANG=en_US.utf8; locale
[dmtsai@study ~]$ export LC_ALL=en_US.utf8; locale # 你就会看到与上头有不同的语系啰!
2.5 变量的有效范围
在某些不同的书籍会谈到『全局变量, global variable』与『局部变量, local variable』。 在鸟哥的这个章节中,基本上你可以这样看待:
- 环境变量=全局变量
- 自定义变数=局部变量
为什么环境变量的数据可以被子程序所引用呢?这是因为内存配置的关系!理论上是这样的:
- 当启动一个 shell,操作系统会分配一记忆区块给 shell 使用,此内存内之变量可让子程序取用
- 若在父程序利用 export 功能,可以让自定义变量的内容写到上述的记忆区块当中(环境变量);
- 当加载另一个 shell 时 (亦即启动子程序,而离开原本的父程序了),子 shell 可以将父 shell 的环境变量所
在的记忆区块导入自己的环境变量区块当中。
2.6 变量键盘读取、数组: read、 array
我们上面提到的变量设定功能,都是由指令列直接设定的,那么,可不可以让用户能够经由键盘输入?什么意思呢?是否记得某些程序执行的过程当中,会等待使用者输入 “yes/no” 之类的讯息啊? 在bash 里面也有相对应的功能喔!此外,我们还可以宣告这个变量的属性,例如:数组或者是数字等等的。底下就来看看吧!
- read
要读取来自键盘输入的变量,就是用 read 这个指令了。这个指令最常被用在 shell script 的撰写当中,想要跟使用者对谈?用这个指令就对了。
[dmtsai@study ~]$ read [-pt] variable
选项与参数:
-p :后面可以接提示字符!
-t :后面可以接等待的『秒数!』这个比较有趣~不会一直等待使用者啦!
#范例一:让用户由键盘输入一内容,将该内容变成名为 atest 的变量
[dmtsai@study ~]$ read atest
This is a test <==此时光标会等待你输入!请输入左侧文字看看
[dmtsai@study ~]$ echo ${atest}
This is a test <==你刚刚输入的数据已经变成一个变量内容!
#范例二:提示使用者 30 秒内输入自己的大名,将该输入字符串作为名为 named 的变量内容
[dmtsai@study ~]$ read -p "Please keyin your name: " -t 30 named
Please keyin your name: VBird Tsai <==注意看,会有提示字符喔!
[dmtsai@study ~]$ echo ${named}
VBird Tsai <==输入的数据又变成一个变量的内容了!
read 之后不加任何参数,直接加上变量名称,那么底下就会主动出现一个空白行等待你的输入(如范例一)。 如果加上 -t 后面接秒数,例如上面的范例二,那么 30 秒之内没有任何动作时, 该指令就会自动略过了~如果是加上 -p ,嘿嘿!在输入的光标前就会有比较多可以用的提示字符给我们参考!
- 数组 (array) 变量类型
目前我们 bash 提供的是一维数组。老实说,如果您不必写一些复杂的程序, 那么这个数组的地方,可以先略过,等到有需要再来学习即可!因为要制作出数组, 通常与循环或者其他判断式交互使用才有比较高的存在意义!
#范例:设定上面提到的 var[1] ~ var[3] 的变数。
[dmtsai@study ~]$ var[1]="small min"
[dmtsai@study ~]$ var[2]="big min"
[dmtsai@study ~]$ var[3]="nice min"
[dmtsai@study ~]$ echo "${var[1]}, ${var[2]}, ${var[3]}"
small min, big min, nice min
[root@node-135 /]# echo $var
lang is $LANG
数组的变量类型比较有趣的地方在于『读取』,一般来说,建议直接以 ${数组} 的方式来读取,比较正确无误的啦!这也是为啥鸟哥一开始就建议你使用 ${变量} 来记忆的原因!
2.7 与文件系统及程序的限制关系: ulimit
想象一个状况:我的 Linux 主机里面同时登入了十个人,这十个人不知怎么搞的, 同时开启了 100 个文件,每个文件的大小约 10MBytes ,请问一下, 我的 Linux 主机的内存要有多大才够?1010010 = 10000 MBytes = 10GBytes … 老天爷,这样,系统不挂点才有鬼哩!为了要预防这个情况的发生,所以我们的 bash 是可以『限制用户的某些系统资源』的,包括可以开启的文件数量, 可以使用的 CPU 时间,可以使用的内存总量等等。如何设定?用 ulimit 吧!
[dmtsai@study ~]$ ulimit [-SHacdfltu] [配额]
选项与参数:
-H :hard limit ,严格的设定,必定不能超过这个设定的数值;
-S :soft limit ,警告的设定,可以超过这个设定值,但是若超过则有警告讯息。
在设定上,通常 soft 会比 hard 小,举例来说,soft 可设定为 80 而 hard
设定为 100,那么你可以使用到 90 (因为没有超过 100),但介于 80~100 之间时,
系统会有警告讯息通知你!
-a :后面不接任何选项与参数,可列出所有的限制额度;
-c :当某些程序发生错误时,系统可能会将该程序在内存中的信息写成文件(除错用),
这种文件就被称为核心文件(core file)。此为限制每个核心文件的最大容量。
-f :此 shell 可以建立的最大文件容量(一般可能设定为 2GB)单位为 Kbytes
-d :程序可使用的最大断裂内存(segment)容量;
-l :可用于锁定 (lock) 的内存量
-t :可使用的最大 CPU 时间 (单位为秒)
-u :单一用户可以使用的最大程序(process)数量。
-n :限制用于控制一个进程可以同时打开的文件数
#范例一:列出你目前身份(假设为一般账号)的所有限制数据数值
[dmtsai@study ~]$ ulimit -a
core file size (blocks, -c) 0 <==只要是 0 就代表没限制
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited <==可建立的单一文件的大小
pending signals (-i) 4903
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024 <==同时可开启的文件数量
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 4096
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
#范例二:限制用户仅能建立 10MBytes 以下的容量的文件
[dmtsai@study ~]$ ulimit -f 10240
[dmtsai@study ~]$ ulimit -a | grep 'file size'
core file size (blocks, -c) 0
file size (blocks, -f) 10240 <==最大量为 10240Kbyes,相当 10Mbytes
[dmtsai@study ~]$ dd if=/dev/zero of=123 bs=1M count=20
File size limit exceeded (core dumped) <==尝试建立 20MB 的文件,结果失败了!
[dmtsai@study ~]$ rm 123 <==赶快将这个文件删除啰!同时你得要注销再次的登入才能解开 10M 的限制
单一 filesystem 能够支持的单一文件大小与block 的大小有关。但是文件系统的限制容量都允许的太大了!如果想要让使用者建立的文件不要太大时, 我们是可以考虑用 ulimit 来限制使用者可以建立的文件大小喔!利用 ulimit -f 就可以来设定了!例如上面的范例二,要注意单位喔!单位是 Kbytes。 若改天你一直无法建立一个大容量的文件,记得瞧一瞧 ulimit 的信息喔!
笔者经常帮同事设定文件描述符和最大进程数
临时修改:
[root@node-135 /]# ulimit -u 9999
[root@node-135 /]# ulimit -n 9999
[root@node-135 /]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 7183
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 9999
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 9999
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
永久修改限制值,可以在系统配置文件/etc/security/limits.conf中增加以下内容:
* soft nofile 65535
* hard nofile 65535
其中,soft表示软限制(即进程能够自己修改的限制),hard表示硬限制(即只有超级用户才能修改的限制)。“*”表示对所有用户生效。
修改后,需要重启才能生效,不过有的系统sysctl -p可以立即生效。
2.8 变量内容的删除、取代与替换 (Optional)
变量除了可以直接设定来修改原本的内容之外,有没有办法透过简单的动作来将变量的内容进行微调呢? 举例来说,进行变量内容的删除、取代与替换等!是可以的!我们可以透过几个简单的小步骤来进行变量内容的微调喔! 底下就来试试看!
变量内容删除(从前向后开始删除变量内容)
变量的内容可以很简单的透过几个咚咚来进行删除喔!我们使用 PATH 这个变量的内容来做测试好了。 请你依序进行底下的几个例子来玩玩,比较容易感受的到鸟哥在这里想要表达的意义
#范例一:先让小写的 path 自定义变量设定的与 PATH 内容相同
[dmtsai@study ~]$ path=${PATH}
[dmtsai@study ~]$ echo ${path}
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin:/home/dmtsai/bin
#范例二:假设我不喜欢 local/bin,所以要将前 1 个目录删除掉,如何显示?
[dmtsai@study ~]$ echo ${path#/*local/bin:}
/usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin:/home/dmtsai/bi
上面这个范例很有趣的!他的重点可以用底下这张表格来说明:
${variable#/*local/bin:}
- ${…}上面的特殊字体部分是关键词!用在这种删除模式所必须存在的
- variable这就是原本的变量名称,以上面范例二来说,这里就填写 path 这个『变量名称』啦!
- #(井号)这是重点!代表『从变量内容的最前面开始向右删除』,且仅删除最短的那个
/*local/bin:代表要被删除的部分,由于 # 代表由前面开始删除,所以这里便由开始的 / 写起。
需要注意的是,我们还可以透过通配符 * 来取代 0 到无穷多个任意字符以上面范例二的结果来看, path 这个变量被删除的内容如下所示:
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin:/home/dmtsai/bin
很有趣吧!这样了解了 # 的功能了吗?接下来让我们来看看底下的范例三!
#范例三:我想要删除前面所有的目录,仅保留最后一个目录
[dmtsai@study ~]$ echo ${path#/*:}
/usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin:/home/dmtsai/bin
由于一个#仅删除掉最短的那个,因此他删除的情况可以用底下的删除线来看:
/usr/local/bin: /usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin:/home/dmtsai/bin
[dmtsai@study ~]$ echo ${path##/*:}
/home/dmtsai/bin
嘿!多加了一个#变成##之后,他变成『删除掉最长的那个数据』!亦即是:
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin: /home/dmtsai/bin
非常有趣!不是吗?因为在 PATH 这个变量的内容中,每个目录都是以冒号『:』隔开的, 所以要从头删除掉目录就是介于斜线 (/) 到冒号 (:) 之间的数据!但是 PATH 中不止一个冒号 (:) 啊! 所以 # 与 ## 就分别代表:
#:符合取代文字的『最短的』那一个;##:符合取代文字的『最长的』那一个
笔者认为鸟叔这里说的
# ... 最短的并不准确,或者大陆和台湾对“最短的”理解不太一样,换成“第一个”应该会好理解些吧
变量内容删除(从后向前开始删除变量内容)
上面谈到的是『从前面开始删除变量内容』,那么如果想要『从后面向前删除变量内容』呢? 这个时候就得使用百分比 (%) 符号了!来看看范例四怎么做吧!
#范例四:我想要删除最后面那个目录,亦即从 : 到 bin 为止的字符串
[dmtsai@study ~]$ echo ${path%:*bin}
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin
注意啊!最后面一个目录不见去!
这个 % 符号代表由最后面开始向前删除!所以上面得到的结果其实是来自如下:
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin :/home/dmtsai/bin
#范例五:那如果我只想要保留第一个目录呢?
[dmtsai@study ~]$ echo ${path%%:*bin}
/usr/local/bin
同样的, %% 代表的则是最长的符合字符串,所以结果其实是来自如下:
/usr/local/bin :/usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin:/home/dmtsai/bin
由于我是想要由变量内容的后面向前面删除,而我这个变量内容最后面的结尾是『/home/dmtsai/bin』,所以你可以看到上面我删除的数据最终一定是『bin』,亦即是『:*bin』那个 * 代表通配符! 至于 % 与 %% 的意义其实与 # 及 ## 类似!这样理解否?
实用示例
假设你是 dmtsai ,那你的 MAIL 变量应该是 /var/spool/mail/dmtsai 。假设你只想要保留最后面那个档名
(dmtsai), 前面的目录名称都不要了,如何利用 $MAIL 变量来达成?
题意其实是这样『/var/spool/mail/ dmtsai 』,亦即删除掉两条斜线间的所有数据(最长符合)。 这个时候你就可
以这样做即可:
[root@node-135 /]# echo $MAIL
/var/spool/mail/dmtsai
[root@node-135 /]# echo ${MAIL##/*/}
dmtsai
相反的,如果你只想要拿掉文件名,保留目录的名称,亦即是『/var/spool/mail/dmtsai』 (最短符合)。但假设你并不知道结尾的字母为何,此时你可以利用通配符来处理即可,如下所示:
[root@node-135 /]# echo ${MAIL%/*}
/var/spool/mail
将 path 的变量内容内的 sbin 取代成大写 SBIN:
[root@node-135 /]# echo ${path}
/usr/local/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/home/dmtsai/.local/bin:/home/dmtsai/bin
[root@node-135 /]# echo ${path/sbin/SBIN}
/usr/local/bin:/usr/bin:/usr/local/SBIN:/usr/sbin:/home/dmtsai/.local/bin:/home/dmtsai/bin
这个部分就容易理解的多了!关键词在于那两个斜线,两斜线中间的是旧字符串后面的是新字符串,所以结果就会出现如上述的特殊字体部分啰!
[root@node-135 /]# echo ${path//sbin/SBIN}
/usr/local/bin:/usr/bin:/usr/local/SBIN:/usr/SBIN:/home/dmtsai/.local/bin:/home/dmtsai/bin
如果是两条斜线,那么就变成所有符合的内容都会被取代喔!
总结
| 变量设定方式 | 说明 |
|---|---|
| ${变量#关键词} | 若变量内容从头开始的数据符合『关键词』,则将符合的第一个数据删除 |
| ${变量##关键词} | 若变量内容从头开始的数据符合『关键词』,则将符合的最长数据删除 |
| ${变量%关键词} | 若变量内容从尾向前的数据符合『关键词』,则将符合的第一个数据删除 |
| ${变量%%关键词} | 若变量内容从尾向前的数据符合『关键词』,则将符合的最长数据删除 |
| ${变量/旧字符串/新字符串} | 若变量内容符合『旧字符串』则『第一个旧字符串会被新字符串取代』 |
| ${变量//旧字符串/新字符串} | 若变量内容符合『旧字符串』则『全部的旧字符串会被新字符串取代』 |
变量的测试与内容替换
在某些时刻我们常常需要『判断』某个变量是否存在,若变量存在则使用既有的设定,若变量不存在则给予一个常用的设定。 我们举底下的例子来说明好了,看看能不能较容易被你所理解呢!
#范例一:测试一下是否存在 username 这个变量,若不存在则给予 username 内容为 root
[dmtsai@study ~]$ echo ${username}
<==由于出现空白,所以 username 可能不存在,也可能是空字符串
[dmtsai@study ~]$ username=${username-root}
[dmtsai@study ~]$ echo ${username}
root <==因为 username 没有设定,所以主动给予名为 root 的内容。
[dmtsai@study ~]$ username="vbird tsai" <==主动设定 username 的内容
[dmtsai@study ~]$ username=${username-root}
[dmtsai@study ~]$ echo ${username}
vbird tsai <==因为 username 已经设定了,所以使用旧有的设定而不以 root 取代
在上面的范例中,重点在于减号『 - 』后面接的关键词!基本上你可以这样理解:
新的变量,主要用来取代旧变量。新旧变量名称其实常常是一样的
new_var=${old_var-content}
这是本范例中的关键词部分!必须要存在的哩!
new_var=${ old_var-content }
旧的变量,被测试的项目!
new_var=${old_var-content}
变量的『内容』,在本范例中,这个部分是在『给予未设定变量的内容』
new_var=${old_var -content}
不过这还是有点问题!因为 username 可能已经被设定为『空字符串』了!果真如此的话,那你还可以使用底下的范例来给予 username 的内容成为 root 喔!
#范例二:若 username 未设定或为空字符串,则将 username 内容设定为 root
[dmtsai@study ~]$ username=""
[dmtsai@study ~]$ username=${username-root}
[dmtsai@study ~]$ echo ${username}
<==因为 username 被设定为空字符串了!所以当然还是保留为空字符串!
[dmtsai@study ~]$ username=${username:-root}
[dmtsai@study ~]$ echo ${username}
root <==加上『 : 』后若变量内容为空或者是未设定,都能够以后面的内容替换!
在大括号内有没有冒号『:』的差别是很大的!加上冒号后,被测试的变量未被设定或者是已被设定为空字符串时, 都能够用后面的内容来替换与设定 (本例中是使用 root 为内容)!
鸟哥将他整理如下:
说明:var 与 str 为变量,我们想要针对 str 是否有设定来决定 var 的值喔! 一般来说, str: 代表『str 没设定或为空的字符串时』;至于 str 则仅为『没有该变数』。
| 变量设定方式 | str 没有设定 | str 为空字符串 | str 已设定非为空字符串 |
|---|---|---|---|
| var=${str-expr} | var=expr | var= | var=$str |
| var=${str:-expr} | var=expr | var=expr | var=$str |
| var=${str+expr} | var= | var=expr | var=expr |
| var=${str:+expr} | var= | var= | var=expr |
| var=${str=expr} | str=expr/var=expr | str 不变/var= | str 不变/var=$str |
| var=${str:=expr} | str=expr/var=expr | str=expr/var=expr | str 不变/var=$str |
| var=${str?expr} | expr 输出至 stderr | var= | var=$str |
| var=${str:?expr} | expr 输出至 stderr | expr 输出至 stderr | var=$str |
示例
#测试:先假设 str 不存在 (用 unset) ,然后测试一下减号 (-) 的用法:
[dmtsai@study ~]$ unset str; var=${str-newvar}
[dmtsai@study ~]$ echo "var=${var}, str=${str}"
var=newvar, str= <==因为 str 不存在,所以 var 为 newvar
#测试:若 str 已存在,测试一下 var 会变怎样?:
[dmtsai@study ~]$ str="oldvar"; var=${str-newvar}
[dmtsai@study ~]$ echo "var=${var}, str=${str}"
var=oldvar, str=oldvar <==因为 str 存在,所以 var 等于 str 的内容
#测试:先假设 str 不存在 (用 unset) ,然后测试一下等号 (=) 的用法:
[dmtsai@study ~]$ unset str; var=${str=newvar}
[dmtsai@study ~]$ echo "var=${var}, str=${str}"
var=newvar, str=newvar <==因为 str 不存在,所以 var/str 均为 newvar
#测试:如果 str 已存在了,测试一下 var 会变怎样?
[dmtsai@study ~]$ str="oldvar"; var=${str=newvar}
[dmtsai@study ~]$ echo "var=${var}, str=${str}"
var=oldvar, str=oldvar <==因为 str 存在,所以 var 等于 str 的内容
#测试:若 str 不存在时,则 var 的测试结果直接显示 "无此变量"
[dmtsai@study ~]$ unset str; var=${str?无此变数}
-bash: str: 无此变量 <==因为 str 不存在,所以输出错误讯息
#测试:若 str 存在时,则 var 的内容会与 str 相同!
[dmtsai@study ~]$ str="oldvar"; var=${str?novar}
[dmtsai@study ~]$ echo "var=${var}, str=${str}"
var=oldvar, str=oldvar <==因为 str 存在,所以 var 等于 str 的内容
总结:
- 减号(
-)的测试并不会影响到旧变量的内容。 如果你想要将旧变量内容也一起替换掉的话,那么就使用等号 (=) 吧! - 如果旧变量不存在时,整个测试就告知我『有错误』,此时就能够使用问号『
?』的帮忙啦