摘要
人类视觉系统有显著的能力去毫不费力的从零样本示例中学习新颖概念。机器学习视觉系统上模仿相同的行为是一个有趣的非常具有挑战性的研究问题,这些研究问题有许多实际的优势在真实世界视觉应用上。在这篇文章中,我们目标是去设计一个零样本视觉学习系统。
(a few-shot visual learning system).
在整个测试阶段,其有能力从一些训练数据中有效的学习新颖类别。于此同时,其将不会遗忘其被训练的初始类别。
To achieve that goal we propose (a) to extend an object recognition system with an attention based few-shot classification weight generator, and (b) to redesign the classifier of a ConvNet model as the cosine similarity function between feature representations
and classification weight vectors
摘要提取关键词
The human visual system.
learn novel concepts from only a few examples.。
这篇论文的目标:
devise a few-shot visual learning system 其有能力去有效的学习:
learn novel categories from only a few training data while at the same time it will not forget the inital categories.(base categories)
目标实现方法
-
to extend an object recognition system with an attention based few-shot classification weight generator.
-
redesign the classifier of a ConvNet model as the consine similarity function between feature representations and classification weight vectors.
-
unifying the recognition of both novel and base categories.
-
feature representations that generalize better on unseen categories.
-
evaluate our method on Mini-ImageNet
介绍
deep convolutional nerual networks.(ConvNets)
应用在 image classification tasks、object recognition or scene classification.
ConvNet: recognize a set of visual categories.(object categories or scene types)
要求
manually collect and label thousands of training examples per target category and to apply on them an iterative gradient based optimizations ,routine.(迭代梯度)
这种方法计算资源相当昂贵。
而且。the ConvNet model can recognize remains fixed after training.
-
for novel categories to collect training data.
在曾倩的训练集中,重新开始上述昂贵的训练程序。 -
我们将会避免灾难性干扰。
关键点: -
有足够的新类别的训练数据至关重要,否则很容易产生过拟合。
应用
developing real_time interactive vision application for portable devices.
(portable devices 便携式设备)
许多方法未满足两个非常重要的要求:
- the learning of the novel categories needs to be fast.
- to not sacrifice any recognition accuracy on the inital categories.
that the ConvNet was trained. to not forget。 - the sole input 唯一输入,
- 我们想要开发的目标识别学习系统:
not only to recognize these base categories but also learns to dynamically recognize novel categories from only a few training examples.(provided only at test time), while also not forgetting the base ones or requiring to be re-trained on them
(dynamic few-shot learning without forgetting)
为了实现目标,我们提出两个新颖性的技术。
Few-shot classification-weight generator based on attention
- A typical ConvNet based recoginition model.
- first extracts a hight level feature representation from it.
- computes per category classifiction scores by applyiing a set of classification weight vectors to the feature.
- 为了有能力去识别新颖类别,be able to generaate classification weight vectors for them.
第一个新颖技术的工作
we enhance a typical object recognition system with an extra component.called few-shot classification weight generator :accepts as input a few training examples of a novel category. *
- generates a classification weight vector. for that novel category.
其明确要求:利用:the acquired past knowledge about the visual world.by incorporating an attention mechanism over the classifcation weight vectors of the base categories.
(基类别的权重向量中加入注意力机制)
注意力机制有有显著的提升效果
Cosine-similarity based ConvNet recognition model.
the ConvNet Model 有能力同时处理 the classification weight vectors of both base and novel categories.
这不是可行的,the typical dot-product based classifier.
(the last linear layer of a classification neural network).
- 为了克服这些严重的问题,第二个新颖的技术:
to implement the classifier as a consine similarity funciton between the feature representaions and the classification weight vectors.
验证方式:简单训练一个 by simply training a consine-similarity based ConvNet recognition model.
- learn feature extractors that when used for image matching they surpass prior state-of-the art approaches .在零样本识别任务上。
贡献
- 提出了一个 a few shot object recognition sysetm.
这有能力从小训练数据中动态学习新颖类别,并没有遗忘训练的基类。 - 实现两个新颖的技术:
- an attention based few-shot classification weight generator.
- to implement the classifier of a ConvNet model as a consine similarity function between feature representations and classification vectors.
- evaluate 目标识别系统在on Mini-ImageNet,
相关工作
- Meta-learning based approaches
- invove a meta-learner model
- Ravi and Larochelle: a LSTM based meta-learner
- Finn et a 简化了,a LSTM based meta-learner model
- Mishra et al :提出了a generic temporal convolutional network.
- 我们的系统也会包含元学习网络成分,the few-shot classification weight generator
- Metric-learning based approaches
- 试图去学习特征表示:preseve the class neighborhood st加粗样式ructure.
- Koch et al:formulated the one-shot object recognition task as image matching and train Siamese neural networks to compute the similarity between a training example of a novel category and a test example。
- Vinyals et al:推出 Matching Networks。
- Mensink et al 提出了一个相似性的方法:Prototypical Networks an adaption of that work for ConvNets。
- 我们的零样本分类权重迭代器也包括:a feature averaging mechansim.
- 利用带有注意力机制视觉世界的过去的机制。
- Bharath and Girshick 提出了一个 a l 2 l_2 l2 regularization loss on the feature presentation.使其能够更好的产生不可见类别。
- the cosine-similarity based classifier
方法
目标识别学习系统的输入:假设存在一个数据集基类
a dataset of
K
b
a
s
e
K_{base}
Kbase base categories:
D
t
r
a
i
n
=
⋃
b
=
1
K
b
a
s
e
{
x
b
,
i
}
i
=
1
N
b
D_{train} = \bigcup^{K_{base}}_{b = 1} \{x_{b,i}\}^{N_b}_{i = 1}
Dtrain=b=1⋃Kbase{xb,i}i=1Nb
参数解释
N
b
N_b
Nb: the b-th categroy训练例子的数量。
x
b
,
i
x_{b,i}
xb,i: its i-th training example. 使用这个当做输入。
我们的工作的目标是有能力去准确识别基类和以动态的方式去优化新颖类别的零样本学习。在没有忘记the base ones.

其包含两个主要成分:
- a ConvNet-based recognition model.
- a few-shot classification weight generator:在测试时间为新颖类别动态的产生权重向量。
ConvNet-based recognition model
-
a feature extractor F ( . ∣ θ ) F(.| \theta) F(.∣θ) (学习参数 θ \theta θ)
这能够提取一个 a d-dimensional feature vector:
z = F ( x ∣ θ ) ∈ R d z = F(x|\theta) \in R^{d} z=F(x∣θ)∈Rd 从一个输入图像 x x x。 -
一个分类器 C ( . ∣ W ∗ ) C(.|W^{*}) C(.∣W∗):在这里 W ∗ = { w k ∗ ∈ R d } k = 1 K ∗ W^{*} = \{w_k^{*} \in R^d\}^{K^{*}}_{k = 1} W∗={wk∗∈Rd}k=1K∗
这里是a set of K ∗ K^{*} K∗ classification weight vectors. :one per object category. -
input the feature representation z z z and return a K ∗ K^{*} K∗-dimensional vectors.概率分布得分: p = C ( z ∣ W ∗ ) p = C(z|W^{*}) p=C(z∣W∗) of the K ∗ K^{*} K∗
categories. -
a typical convolutional neural network the feature extractor:是网路的一部分,starts from the first layer and ends at the last hidden layer.
-
the classifier is the last classification layer.
总计:这个ConvNet model will be able to recognize the base object categories.
Few-shot classification weight generator
这包括一个:a meta-learning mechanism
input: a set of
K
n
o
v
e
l
K_{novel}
Knovel novel categories.
D
n
o
v
e
l
=
⋃
n
=
1
K
n
o
v
e
l
{
X
n
,
i
^
}
i
=
1
N
^
n
D_{novel} = \bigcup^{K_{novel}}_{n = 1}\{\hat{X_{n,i}}\}^{\hat{N}_n}_{i = 1}
Dnovel=n=1⋃Knovel{Xn,i^}i=1N^n
公式解释
- N n ^ \hat{N_n} Nn^ the number of training examples of the n-th novel category.
-
x
n
,
i
^
\hat{x_{n,i}}
xn,i^:its i-th training example.
o dynamically assimilate the novel categories on the
repertoire of the above ConvNet model - each novel category n ∈ [ 1 , N n o v e l ] n \in [1, N_{novel}] n∈[1,Nnovel]
- the few-shot classification weight generator : G ( . . , . ∣ ϕ ) G(..,.|\phi) G(..,.∣ϕ)
- 输入特征向量 Z n ^ = { Z n , i ^ } i = 1 N n ^ \hat{Z_n} = \{\hat{Z_{n,i}}\}^{\hat{N_n}}_{i = 1} Zn^={Zn,i^}i=1Nn^
- Z n , i ^ = F ( x n , i ∣ θ ^ ) \hat{Z_{n,i}} = F(\hat{x_{n,i} | \theta}) Zn,i^=F(xn,i∣θ^)
- 基类的分类权重向量: W b a s e W_{base} Wbase
- 产生一个分类权重向量: w n ^ = G ( Z n W b a s e ∣ ϕ ^ ) \hat{w_n} = G(\hat{Z_n W_base | \phi}) wn^=G(ZnWbase∣ϕ^) for novel category.
-
ϕ
\phi
ϕ是 the learnable parameters of the few-shot weight generator
这个参数在我们框架的单一训练阶段中学习。 - W n o v e l = { w n ^ } n = 1 K n o v e l W_{novel} =\{\hat{w_n}\}^{K_{novel}}_{n = 1} Wnovel={wn^}n=1Knovel
- the few-shot weight generator产生的新颖类别的分类权重向量。
- W ∗ = W b a s e ⋃ W n o v e l W^{\ast} = W_{base} \bigcup W_{novel} W∗=Wbase⋃Wnovel
- C ( . ∣ W ∗ ) C(.|W^{\ast}) C(.∣W∗):the ConvNet model 去识别基类和新颖类。
Cosine-similarity based recognition model
the standard setting for classification neural networks.:
-
after the extracted the feature vector z z z。
-
计算每个类别的分类得分 s k s_k sk 去估计分类概率向量:
p = C ( z ∣ W ∗ ) p = C(z|W^{\ast}) p=C(z∣W∗) -
k ∈ [ 1 , K ∗ ] k \in [1,K^{\ast}] k∈[1,K∗] 使用点积操作:
-
s k = z T w k ∗ s_k = z^{T}w^{\ast}_k sk=zTwk∗
在所有 K ∗ K^{\ast} K∗操作上应用softmax scores。
p k = s o f t m a x ( s j ) p_k = softmax(s_j) pk=softmax(sj)
p k p_k pk is the k-th classification probablity of p p p
w K ∗ w_K^{\ast} wK∗could come both from the category
w K ∗ ∈ W b a s e w^{\ast}_K \in W_{base} wK∗∈Wbase -
small SGD steps.
-
问题:the weight values in those
two cases (i.e., base and novel classification weights) can be
completely different, and so the same applies to the raw classification scores computed with the dot-product operation,
which can thus have totally different magnitudes depending
on whether they come from the base or the novel categories.
This can severely impede the training process and, in general,
does not allow to have a unified recognition of both type of
categories. -
修改这个分类器 C ( . ∣ W ∗ ) C(.|W^{\ast}) C(.∣W∗) 使用余弦相似操作来计算分类得分:
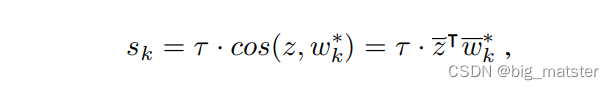

另外这个以上的修改,我们也选择删除了 t h e R e L U n o n − l i n e a r i t y the ReLU non-linearity theReLUnon−linearity
after the last hidden layer of the feature extractor.
z z z to take both positive and negative values.similar to the classification weight vectors.
l 2 l_2 l2-normalize the feature vectors.
Advantages of cosine-similarity based classifier
- o minimize the classification loss of a cosine-similarity based ConvNet model
- the l 2 l_2 l2 normailized feature vector of an image.
- low intraclass variance:类内方差。
- the cosine-similarity-based ConvNet form more compact and distinctive category-specific clusters
Few-shot classification weight generator
- the cosine similarity based classifier of the ConvNet model
- 学习这些类簇的表示特征向量:

最终类的权重向量,我们仅使用the feature averaging mechanism
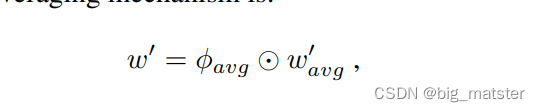
⨀ \bigodot ⨀ is the the Hadamard product
ϕ a v g ∈ R d \phi_{avg} \in R^d ϕavg∈Rd is a learnable weight vector.
Attention-based weight inference
feature averaging mechanism with an attention based
mechanism that composes novel classification weight vectors by looking at a memory that contains the base classification weight vectors.
W
b
a
s
e
=
{
w
b
}
b
=
1
K
b
a
s
e
W_{base} = \{w_b\}^{K_{base}}_{b = 1}
Wbase={wb}b=1Kbase
- an extra attention-based classification weight vector
w
a
t
t
^
\hat{w_{att}}
watt^
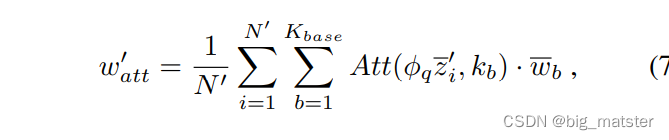

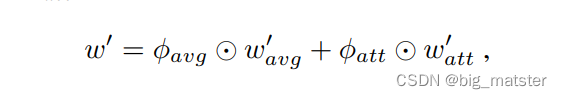
在这里 ⨀ \bigodot ⨀是the Hadamard product
ϕ a v g ϕ a t t ∈ R d \phi_{avg} \phi_{att} \in R^d ϕavgϕatt∈Rd 是可学习的权重向量。
Why using an attention-based weight composition?
(为什么使用基于注意力机制的权重成分)
- the cosine-similarity based classifier
- the base classification weight vectors
- the base classification weight vectors also encode visual similarity
训练步骤
-
learn the ConvNet-based recognition model
-
the feature extractor F ( . ∣ θ ) F(.|\theta) F(.∣θ)
-
C ( . ∣ W ∗ ) ) C(.|W^{\ast})) C(.∣W∗))
-
the few-shot classification weight generator G ( . , . ∣ ϕ ) G(.,.|\phi) G(.,.∣ϕ)
-
单一的输入:
D t r a i n = ⋃ b = 1 K b a s e { x b , i } i = 1 N b D_{train} = \bigcup^{K_{base}}_{b = 1}\{x_{b,i}\}^{N_b}_{i =1} Dtrain=b=1⋃Kbase{xb,i}i=1Nb
of K b a s e K_{base} Kbase base categories. -
将训练程序切分为2个阶段:每个阶段:
-
minimize a different cross-entropy loss
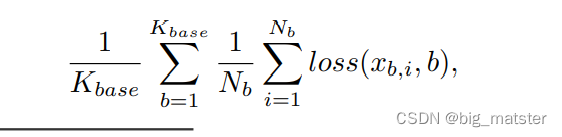

1st training stage
- learn the ConvNet recognition model without the few-shot classification weight generator.
- 特征提取器的参数 θ \theta θ F ( . ∣ θ ) F(.|\theta) F(.∣θ)
- the base classification weight vectors: W b a s e = { w b } b = 1 K b a s e W_{base} = \{w_b\}^{K_{base}}_{b = 1} Wbase={wb}b=1Kbase
- W ∗ 等 价 于 W b a s e W^{\ast}等价于W_{base} W∗等价于Wbase
2nd training stage


实验结果
Mini-ImageNet experiments
Evaluation setting for recognition of novel categories.
在
t
h
e
M
i
n
i
−
I
m
a
g
e
N
e
t
d
a
t
a
s
e
t
the Mini-ImageNet dataset
theMini−ImageNetdataset 数据集上评估我们的零样本目标识别系统
(few-shot object recognition system).
数据集介绍
- dataset that includes 100 different categories,with 600 images per category.
- each of size 84 × 84 84 \times 84 84×84
- 64 categories for training.
- 16 categories for validation.
- 20 categories for testing.
- first sampling K n o v e l K_{novel} Knovel categories and one or five training example per category1-(1-shot and 5-shot settings respectively)
Evaluation setting for the recognition of the base categories.
- the proposed few-shot object recognition system has the ability to not forget the base categoris.
- 目标
- evaluate the recognition performance of our model on those base categories
措施
- **sampled 300 extra images for each training categories.**that we use as validation image set for the evaluation of the recognition performance of the base categories.
- and also anthor 300 extra images that are used for the same reason as test image set.
Ablation study
想确定这个结构是否有利于最终结果,那就要去掉该结构的网络与加上该结构的网络层的结果进行对比,这就是Ablation study。
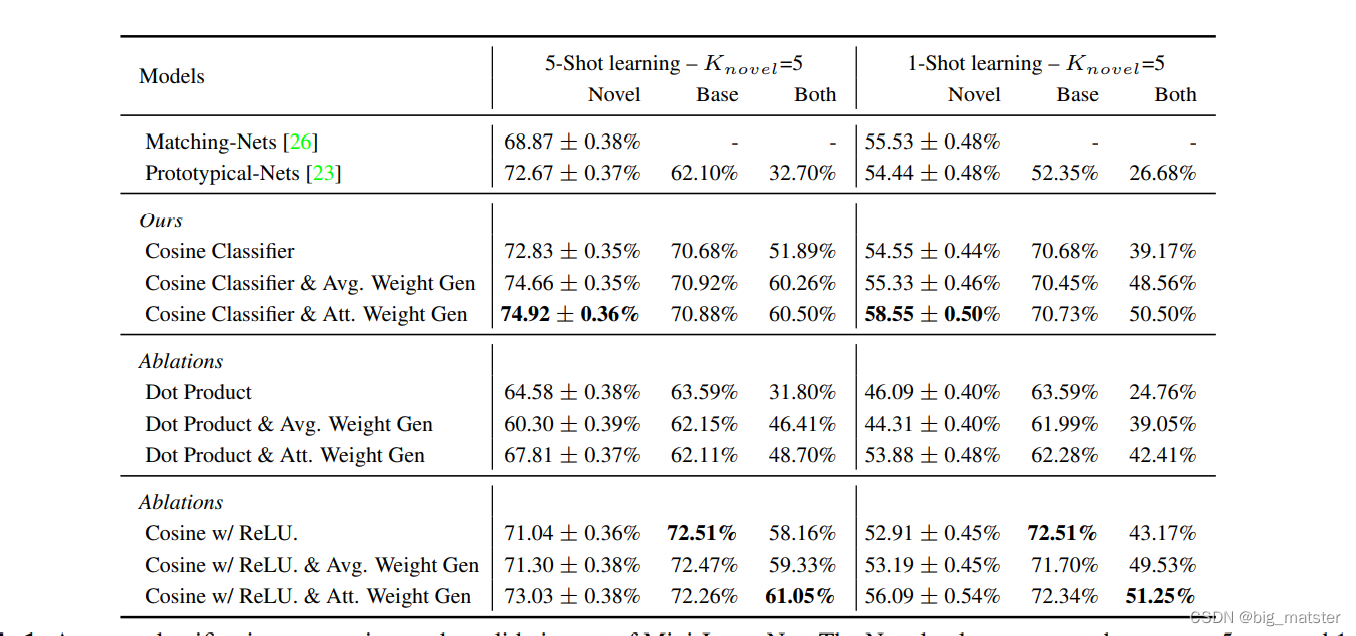
在 on the validation set of mini-ImageNet上进行Ablation study。
比较:two prior state-of-the-art approaches :
Prototypical Networks and Matching Nets。
-
The feature extractor:
- is a ConvNet model that has 4 convolutional modules
- with 3 × 3 3 \times 3 3×3 convolutions.
- followed by batch normalization
- ReLU nonlinearity.
- 2 × 2 2 \times 2 2×2 max-pooling
- Given as input images of size 84 × 84 84 \times 84 84×84
- it yields feature maps with spiatal size 5 × 5 5 \times 5 5×5
- The first two convolutional layers have 64 feature channels.
- the latter two have 128 feature channels.
Cosine-similarity based ConvNet model.
*未训练权重生成器情况下, 查看the cosine-simiarity based ConvNet model (entry Consine Classifier)的效果
- perform the 1st training stage
- 为了测试新颖类别的效果:
- estimate classification weight vectors.using feature averaging.
*** the cosine-similarity based ConvNet models** (Cosine Classifier entries - ConvNet models:模型中引入余弦相似度和dot-product做对比,比较其优劣。
Removing the last ReLU unit
- remove the last ReLU non-linearity from the feature extractor.when using a cosine classifier.
Few-shot classification weight generator
use both the feature averaging and the attention based mechansim.
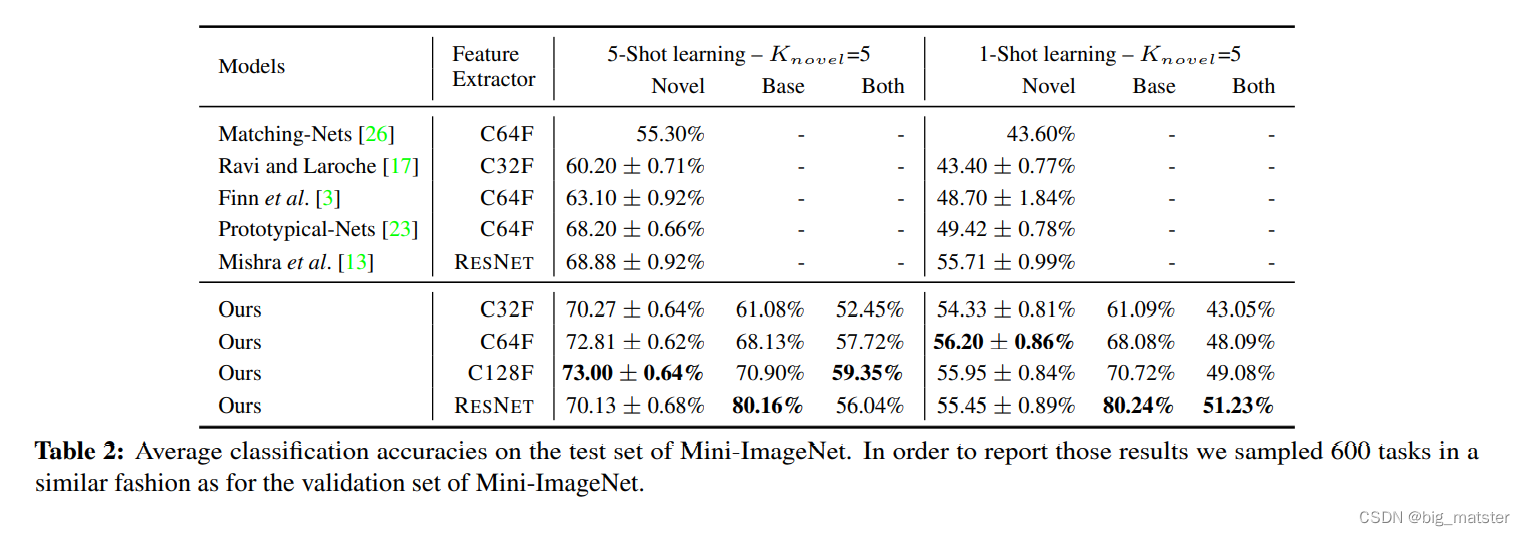
Comparison with state-of-the-art
Explored feature extractor architectures
- a 4 module ConvNet network
- the ResNet [5] like network
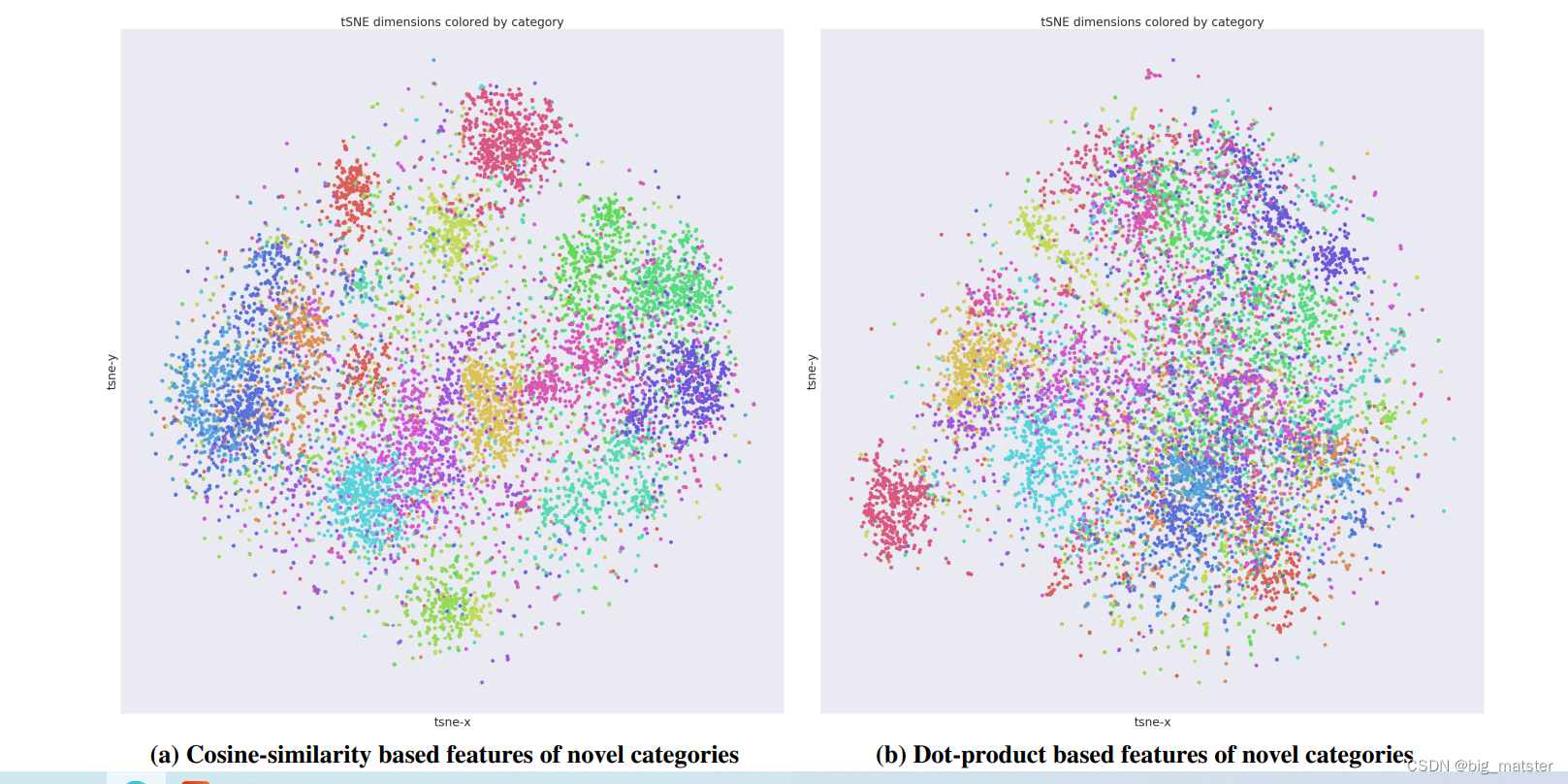
Qualitative evaluation with t-SNE scatter plots
-
cosine-similarity based ConvNet recognition model
-
the typical dot-product based ConvNet recognition model
-
the t − S N E t-SNE t−SNE scatter plots
可视化 the local-structures of the feature representations learned in those two cases。 -
可视化the l 2 l_2 l2-normalized features.这些特征能够被特征提取器所实际用到。
Few-shot benchmark of Bharath & Girshick
- on the ImageNet based few-shot benchmark
- 将数据集切分成389 base categories. and 611 novel categories.
- 193 of the base categories and 300 of the novel categories are used for cross validation and the remaining 196 base categories and 311 novel categories are used for the final evaluation.
- sampling ourselves N ^ \hat{N} N^ training images per novel category.
- evaluate using the images in the validation set of ImageNet。
- repeat the above experiment 100 times
Comparison to prior and concurrent work
- Prototypical-Nets
- Matching Networks
- the work of Bharath and Girshick。
Feature extractor
- a ResNet-10 [5] network architecture
gets as input images of 224 × 224 224 \times 224 224×224 size> - apply dropout with 0.5 probability on the feature vectors generated by the feature extractor.
结论
- a cosine-similarity based ConvNet classifier.
- learn feature representation with better generalization capabilities.
概括
继续下一篇,将其完全的搞明白,全部都将其理解透彻,理解彻底。然后开始搞代码。
针对以零样本为中心开始研究自己的模型及框架,全部都将其搞定都行啦的样子与打算。
*
总结
会自己发现通过啥技术来设计啥目标,以及通过啥如何根据自己的技术来设计优化自己的目标。都行啦的回事与打算。
会根据自己的优化目标,来设计自己的新颖技术。
- 会判断什么技术可行不可行。会自己的判断都行啦的样子与打算。
- 会自己比较方法, d o t − p r o d u c t dot-product dot−product可行还是 t h e c o s i n e − s i m i l a r i t y the cosine-similarity thecosine−similarity
- 会自己高明白,啥操作产生啥效果,全部狗将其搞定都行啦的理由与打算。
-
- 会自己根据运行代码,并结合论文来进行观察与查看,整个复现代码,好好的将其研究透彻,研究彻底都行的样子与打算。慢慢的将其搞定都行啦的理由与障碍。
- 会将两个网络一起训练,然后将其做对比。比较其模型效果的优劣。