这里写目录标题
- 总体思路
- 获取数据集
-
- 下载cifar10数据
- 解压包
- 文件介绍
- 加载图片数字化信息
- 查看数据信息
- 数据读取
- 自定义dataset
- 使用loader加载
- 建模
- 训练
- 测试
-
- 建测试数据的loader
- 测试准确性
- 测试一张图片
-
- 读取一张图片
- 加载模型
- 预测图片类型
- 创建一个预测函数
- 随便来张马的图片
- 结果
- 其他
-
- 打开一个图片
-
- 基础信息查看
- 数据转图片
总体思路
生成数据dataset
使用loader加载dataset
建模
训练
测试
参考:
https://blog.csdn.net/HcViking/article/details/126688941
import numpy
获取数据集
下载cifar10数据
下载地址
http://www.cs.toronto.edu/~kriz/cifar.html
# !wget http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
解压包
# !tar -zxvf cifar-10-python.tar.gz
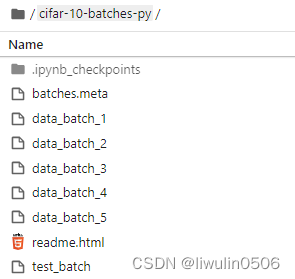
文件介绍
总共有六个文件
五个cifar-10-batches-py/data_batch_1 2 3 4 5
一个测试集cifar-10-batches-py/test_batch
分类分别是[“airplane”,“automobile”,“bird”,“cat”,“deer”,“dog”,“frog”,“horse”,“ship”,“truck”]
加载图片数字化信息
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dic=unpickle("./cifar-10-batches-py/data_batch_1")
查看数据信息
dic.keys()
dict_keys([b'batch_label', b'labels', b'data', b'filenames'])
dic.get(b'filenames')[0:10]
[b'leptodactylus_pentadactylus_s_000004.png',
b'camion_s_000148.png',
b'tipper_truck_s_001250.png',
b'american_elk_s_001521.png',
b'station_wagon_s_000293.png',
b'coupe_s_001735.png',
b'cassowary_s_001300.png',
b'cow_pony_s_001168.png',
b'sea_boat_s_001584.png',
b'tabby_s_001355.png']
len(dic.get(b'filenames'))
10000
X = dic[ b'data']
Y = dic[b'labels']
X[5],type(X),X[5].shape
(array([159, 150, 153, ..., 14, 17, 19], dtype=uint8),
numpy.ndarray,
(3072,))
## 其他信息-concatenate
nparray=numpy.array([[1,2,3,4,5],[1,4,5,6,7]])
print(nparray)
xx=numpy.concatenate(nparray)
xx
[[1 2 3 4 5]
[1 4 5 6 7]]
array([1, 2, 3, 4, 5, 1, 4, 5, 6, 7])
数据读取
import os
import numpy as np
import pickle
#读一个批次
def load_cifar_batch(filename):
with open(filename,'rb') as f:
data_dict=pickle.load(f,encoding='bytes')
images =data_dict[b'data']
labels=data_dict[b'labels']
print("data shape is {0} and type is {1}".format(images.shape,type(images)))
print("labels shape is {0} and type is {1}".format(len(labels),type(labels)))
# 把3072列分成3个32*32的数据
images=images.reshape(10000,3,32,32)
print("after data reshape is {0} and type is {1}".format(images.shape


![[Docker实现测试部署CI/CD----相关服务器的安装配置(2)]](https://img-blog.csdnimg.cn/dd0fb3641ac34319b2e118e7082e0e02.png)





![P3855 [TJOI2008] Binary Land(BFS)(内附封面)](https://img-blog.csdnimg.cn/b49d79b520d7417f89716345fdbbd79e.png)